LogicDiff: Logic-Guided Denoising Improves Reasoning in Masked Diffusion Language Models
Masked diffusion language models (MDLMs) generate text by iteratively unmasking tokens from a fully masked sequence, offering parallel generation and bidirectional context. However, their standard confidence-based unmasking strategy systematically de…
Authors: Shaik Aman
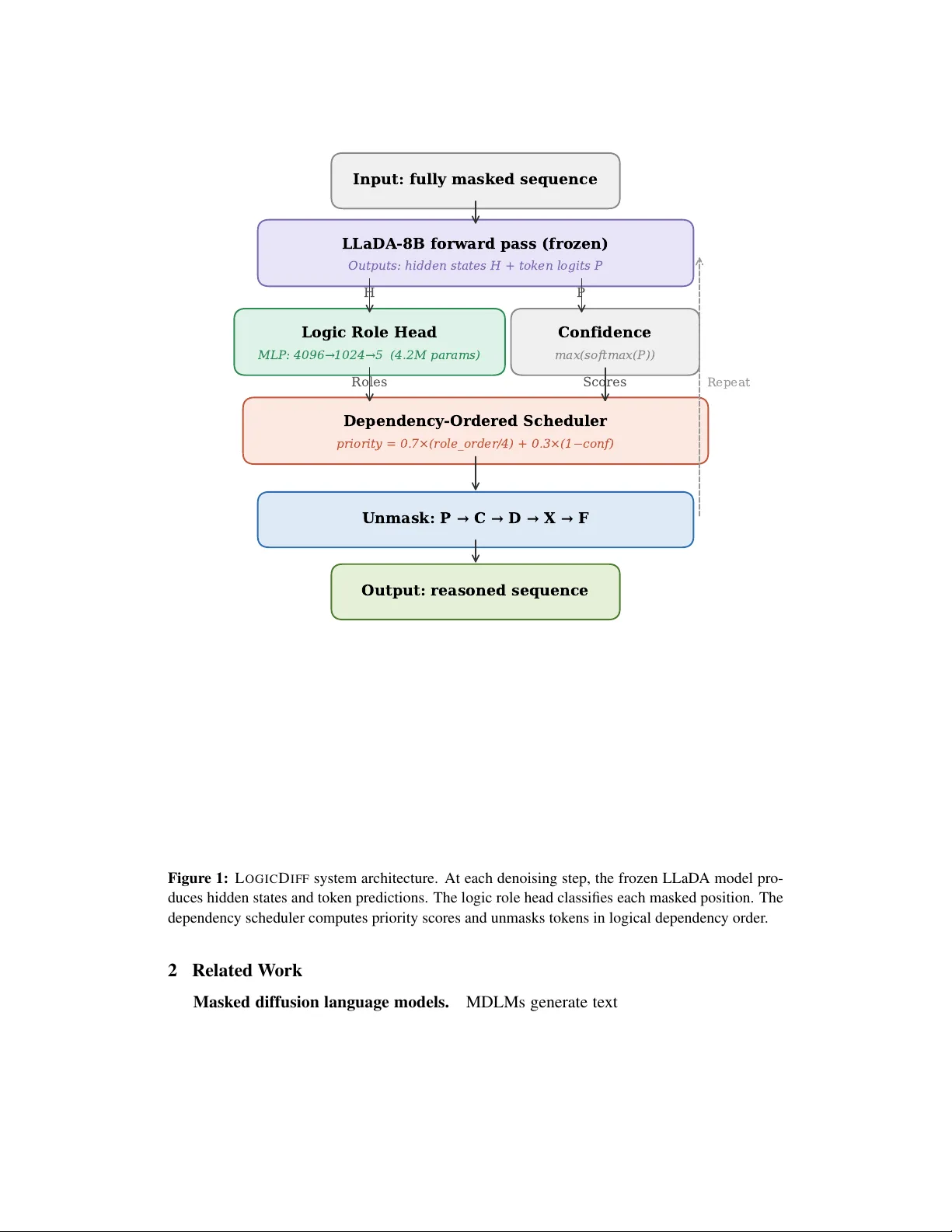
LogicDiff: Logic-Guided Denoising Impr ov es Reasoning in Masked Diffusion Language Models Shaik Aman Independent Researcher Nellore, Andhra Pradesh, India amanabdul21@gmail.com Abstract Masked dif fusion language models (MDLMs) generate text by iterativ ely unmasking tokens from a fully masked sequence, offering parallel generation and bidirectional context. Howe v er , their stan- dard confidence-based unmasking strate gy systematically defers high-entrop y logical connecti ve tokens—the critical branching points in reasoning chains—leading to sev erely degraded reasoning performance. W e introduce L O G I C D I FF , an inference-time method that replaces confidence-based unmasking with logic-r ole-guided unmasking . A lightweight classification head (4.2M parameters, 0.05% of the base model) predicts the logical role of each masked position—premise, connectiv e, deriv ed step, conclusion, or filler—from the base model’ s hidden states with 98.4% accuracy . A dependency-ordered scheduler then unmasks tokens in logical dependency order: premises first, then connectiv es, then deriv ed steps, then conclusions. W ithout modifying a single parameter of the base model and without any reinforcement learning or task-specific training, L O G I C D I FF im- prov es LLaD A-8B-Instruct accuracy from 22.0% to 60.7% on GSM8K ( +38.7 pp ) and from 23.6% to 29.2% on MA TH-500 ( +5.6 pp ), with less than 6% speed overhead. Our results demonstrate that a substantial portion of the reasoning deficit in MDLMs is attributable to suboptimal tok en unmasking order , not to limitations of the model’ s learned representations. 1 Introduction The dominant paradigm in language modeling uses autoregressiv e (AR) generation, where tokens are produced left-to-right with each token conditioned on all preceding to- kens. A fundamentally different approach has emerged with Masked Diffusion Language Models (MDLMs) [ 10 – 12 ], which generate text through iterati ve denoising: starting from a fully masked sequence, tokens are progressiv ely re vealed over multiple steps until the output is complete. MDLMs offer sev eral advantages, including parallel token generation, bidirectional conte xt modeling, and the unique ability to re vise pre viously generated tokens through remasking. Despite these architectural advantages, MDLMs exhibit a striking weakness: they can- not reason ef fectiv ely . On mathematical reasoning benchmarks, MDLMs dramatically underperform comparably-sized AR models. LLaD A-8B-Instruct [ 10 ], the lar gest open MDLM, achiev es only ∼ 22% on GSM8K [ 3 ], compared to > 70% for AR models of simi- lar size. Recent work by Ni et al. [ 9 ] identified the root cause as the Flexibility T rap : MDLMs use confidence-based token selection during denoising, which systematically a v oids gener - 1 ating high-entropy tokens in early steps. These high-entropy tokens correspond precisely to logical connectiv e words (“therefore, ” “because, ” “thus, ” “since”) that serve as critical branching points where reasoning chains div erge into distinct solution paths. By deferring these tokens, the model fills in surrounding context first, collapsing the reasoning solution space before the logical structure is established. All existing approaches to this problem require expensi ve post-training: JustGRPO [ 9 ] forces AR order during RL training ( ∼ 89 . 1% GSM8K b ut requires a full RL pipeline), d1 [ 16 ] and SAPO [ 14 ] modify the model through reinforcement learning, and A TPO [ 2 ] adapti vely allocates gradient budget. These methods change the model’ s weights and re- quire task-specific training. W e propose L O G I C D I FF , a fundamentally dif ferent approach: rather than retraining the model, we fix the gener ation strate gy . L O G I C D I FF operates entirely at inference time with three components: 1. A Logic Role Classification Head : a 2-layer MLP (4.2M parameters) that classifies each masked position into fi v e logical roles using hidden states, achie ving 98.4% v ali- dation accuracy . 2. A Dependency-Ordered Scheduler : unmasks tokens in logical dependency order— premises before connectives before deri ved steps before conclusions—while preserv- ing parallel generation within each role group. 3. A Priority Scoring Function : a weighted combination of role-based priority and con- fidence that determines the unmasking order at each step. W ithout modifying a single parameter of LLaDA-8B-Instruct, L O G I C D I FF improves GSM8K accuracy from 22.0% to 60.7% ( +38.7 pp ) and MA TH-500 from 23.6% to 29.2% ( +5.6 pp ). This demonstrates that the MDLM’ s knowledge is sufficient for reasoning—the bottleneck was the order in which that kno wledge was accessed. An ov ervie w of the system is sho wn in Figure 1 . 2 Input: fully masked sequence LLaDA-8B forward pass (frozen) Outputs: hidden states H + token logits P H P Logic Role Head MLP : 4096 1024 5 (4.2M params) Confidence max(softmax(P)) Roles Scores Dependency-Ordered Scheduler priority = 0.7×(role_order/4) + 0.3×(1 conf) Unmask: P C D X F Output: reasoned sequence Repeat Figure 1: L O G I C D I FF system architecture. At each denoising step, the frozen LLaDA model pro- duces hidden states and token predictions. The logic role head classifies each masked position. The dependency scheduler computes priority scores and unmasks tokens in logical dependenc y order . 2 Related W ork Masked diffusion language models. MDLMs generate text by iterati vely denoising a masked sequence. LLaD A [ 10 ] demonstrated competitiv e general language performance using a Llama-3 backbone with bidirectional attention. ReFusion [ 8 ] introduced slot-lev el parallel decoding with AR infilling within slots. Dream [ 4 ] and Block Dif fusion [ 1 ] ex- plored hybrid AR–dif fusion architectures. A3 [ 5 ] showed that AR models with two-stream attention can ri val dif fusion models at an y-order generation. 3 Reasoning in MDLMs via reinf orcement learning . The d1 framework [ 16 ] first integrated policy gradient RL with MDLMs using a mean-field approximation, achiev- ing ∼ 84 . 5% on GSM8K. JustGRPO [ 9 ] simplified this by treating the MDLM as an AR model during RL training, reaching 89.1%. SAPO [ 14 ] introduced process-based rew ards. A TPO [ 2 ] identified “zones of confusion” and adaptiv ely allocated gradient budget. All require modifying model weights. Inference-time approaches. Dif fusion-of-Thought [ 15 ] distributes CoT reasoning across timesteps b ut requires training from scratch. Diffusion Stitching [ 13 ] uses PRM-scored step selection. Most relev ant, DOS [ 17 ] uses attention matrices as dependency proxies. L O G - I C D I FF differs fundamentally: we use an explicitly trained classifier predicting semantic logical r oles , not statistical attention patterns. Theoretical analysis. Feng et al. [ 6 ] proved MDLMs need Ω ( L ) steps for low se- quence error rate, suggesting that improving unmasking or der is a promising direction. 3 Method 3.1 Preliminaries In MDLMs, gi v en prompt q , the model initializes x ( 0 ) = [ MASK ] L g . At step t , it produces H ( t ) ∈ R L × D and P ( t ) ∈ R L ×| V | . Standard decoding unmasks the K positions with highest conf ( i ) = max v P i , v . 3.2 Logic Role Classification Head W e introduce f φ : R D → R R predicting R = 5 logical roles: ID Role Definition 0 P R E M I S E Giv en facts, known values, problem conditions 1 C O N N E C T I V E Logical links: “therefore, ” “so, ” “because” 2 D E R I V E D Computed or inferred values 3 C O N C L U S I O N Final answer or result 4 F I L L E R Articles, punctuation, formatting Architecture (2-layer MLP with input LayerNorm): f φ ( h ) = W 2 · Dropout GELU ( W 1 · LayerNorm ( h ) + b 1 ) + b 2 (1) W 1 ∈ R ( D / 4 ) × D , W 2 ∈ R R × ( D / 4 ) . For LLaD A-8B ( D = 4096, R = 5): ∼ 4 . 2M params (0.05% of base). T raining data. T wo-pass labeling of 7,473 GSM8K solutions (891,432 tokens): (1) sentence- le vel role classification; (2) token-le v el connectiv e ov erride. Distribution: D E R I V E D 93.6%, C O N C L U S I O N 3.9%, C O N N E C T I V E 1.3%, P R E M I S E 0.8%, F I L L E R 0.4%. Class-weighted CE with 10 × for C O N N E C T I V E . T raining. Base model frozen. Random masking, forward pass, train f φ on hidden states. 30 min on 1 × H100. 98.4% validation accurac y . 3.3 Dependency-Ordered Scheduler Priority score for masked position i : priority ( i ) = w r · role_order ( r i ) R − 1 + w c · 1 − conf ( i ) (2) 4 role_order: P R E M I S E = 0, C O N N E C T I V E = 1, D E R I V E D = 2, C O N C L U S I O N = 3, F I L L E R = 4. W e use w r = 0 . 7, w c = 0 . 3. Select K = ⌈ L g / N ⌉ lo west-priority positions per step. Default (confidence-ordered) Step 1: 5 2 3 3 Numbers first Step 2: apples = the answer is Nouns, fillers Step 3: so Connectives LAST! LogicDiff (role-ordered) Step 1 [P]: 5 apples 2 Premises first Step 2 [C]: so Connectives second Step 3 [D]: = 3 Derived third Step 4 [X]: the answer is 3 Conclusion last Premise Connective Derived Conclusion Filler Figure 2: Unmasking order comparison. T op: Default confidence-based unmasking generates num- bers first and defers connectiv es (“so”) to the last step—reasoning direction is locked prematurely . Bottom: L O G I C D I FF unmasks premises first, then connectives, then deriv ed results, then conclu- sions, establishing logical structure before committing to values. 3.4 Generation Algorithm 3.5 Why Unmasking Order Matters In MDLMs, bidirectional attention means ev ery token attends to ev ery other token. What gets unmasked first becomes the context for e verything that follo ws. Default un- masking builds context by statistical confidence—essentially random with respect to logical structure. L O G I C D I FF builds conte xt in logical dependency order: premises establish f acts, connecti ves set the reasoning direction, deriv ed steps compute results, and conclusions fol- lo w . See Figure 2 for a concrete example. 5 Algorithm 1 L O G I C D I FF Generation Require: Prompt q , frozen model M θ , role head f φ , steps N , length L g 1: x ← [ q ; MASK L g ] {Initialize} 2: K ← ⌈ L g / N ⌉ {T okens per step} 3: for t = 1 to N do 4: H , P ← M θ ( x ) {Forw ard pass} 5: M ← { i : x i = MASK } 6: if | M | = 0 then 7: break 8: end if 9: f or i ∈ M do 10: r i ← arg max f φ ( h i ) {Predict role} 11: s i ← 0 . 7 · role_order ( r i ) 4 + 0 . 3 · ( 1 − max v P i , v ) 12: end f or 13: U ← bottom-K ( { s i } ) {Lo west scores} 14: f or i ∈ U do 15: x i ← arg max v P i , v {Unmask} 16: end f or 17: end for 18: return x 4 Experiments 4.1 Setup Base model. LLaD A-8B-Instruct [ 10 ] (8B params, Llama-3 with bidirectional atten- tion). All parameters frozen. Role head. T rained on 7,473 GSM8K solutions. Same checkpoint for all benchmarks. Benchmarks. (1) GSM8K [ 3 ]: 1,319 grade-school math problems. (2) MA TH- 500 [ 7 ]: 500 competition-lev el math problems. Settings. 256 denoising steps, 256 max ne w tokens. 4.2 Main Results T able 1: Main results. L O G I C D I FF uses frozen LLaD A-8B-Instruct with no RL, no fine-tuning, no task-specific training. The role head is trained once on GSM8K and used for both benchmarks. Method GSM8K MA TH-500 Base Modified Speed LLaD A Baseline 22.0% (290/1319) 23.6% (118/500) No 0.18 ex/s L O G I C D I FF + Consistency 3.0% (3/100) † — No 0.09 ex/s L O G I C D I FF 60.7% (800/1319) 29.2% (146/500) No 0.17 ex/s Impr ovement: +38.7 pp +5.6 pp < 6% slo wer † 100-example subset; disabled due to catastrophic failure. 6 GSM8K (1,319) MA TH-500 (500) 0 10 20 30 40 50 60 70 Accuracy (%) 22.0% 23.6% 60.7% 29.2% +38.7 pp +5.6 pp Baseline LogicDiff Figure 3: Accuracy comparison on GSM8K and MA TH-500. L O G I C D I FF improv es over the base- line by +38.7 percentage points on GSM8K and +5.6 pp on MA TH-500, using the same frozen model with no RL. L O G I C D I FF achiev es 60.7% on GSM8K (+38.7 pp over baseline)—510 additional prob- lems solved with < 6% speed ov erhead. On MA TH-500, +5.6 pp using the same role head without retraining. 4.3 Comparison with Existing Methods T able 2: Comparison. L O G I C D I FF is the only method requiring no base model modification and no RL. Method GSM8K MA TH RL Modifies Base T rain Cost LLaD A Baseline 22.0% 23.6% No No 0 DOS [ 17 ] — — No No 0 d1 [ 16 ] ∼ 84.5% ∼ 41.0% Y es Y es Days (8 × A100) JustGRPO [ 9 ] 89.1% 45.1% Y es Y es Days (8 × A100) L O G I C D I FF (ours) 60.7% 29.2% No No 30 min (1 × H100) While JustGRPO achie ves higher absolute accuracy (89.1% vs. 60.7%), it requires full RL training at orders of magnitude higher compute. L O G I C D I FF and RL methods are com- plementary : our sampler could be applied on top of RL-trained models. 4.4 Role Head Statistics 5 Analysis GSM8K vs. MA TH-500 gap. GSM8K follo ws a clear premise → inference → conclusion pattern that maps cleanly onto our taxonomy . MA TH-500 in v olves complex algebraic ma- nipulation where premise–conclusion boundaries are less clear . The +5.6 pp still demon- strates generalization beyond the training domain. 7 T able 3: Training data and role head performance. Role Count Distribution W eight P R E M I S E 7,512 0.8% 1.0 C O N N E C T I V E 11,453 1.3% 10.0 D E R I V E D 834,290 93.6% 1.0 C O N C L U S I O N 34,581 3.9% 2.0 F I L L E R 3,596 0.4% 0.5 T otal 891,432 V alidation accuracy 98.4% Comparison with DOS. DOS [ 17 ] uses attention matrices as statistical proxies (content- agnostic). L O G I C D I FF uses an explicitly trained classifier predicting semantic roles (content- aw are). Our stronger results suggest e xplicit semantic understanding provides a more po w- erful signal for unmasking decisions. Consistency checker failure. CE-threshold remasking drops accuracy from 64% to 3%. The checker remasks contextually unusual but correct tokens, creating a destructiv e cycle. Future work should explore PRM-guided remasking. 6 Discussion and Limitations Implications. The +38.7 pp from a sampler change implies future work should jointly consider model capability and generation strategy , not just RL. Complementarity . L O G I C D I FF could be combined with RL-trained models (Just- GRPO, d1), potentially achie ving additiv e gains. Limitations. (1) Role head trained on GSM8K only; broader taxonomies would help. (2) Fi v e roles are coarse. (3) Ev aluated only on LLaD A-8B. (4) Consistency check er f ailed. Future work. (1) L O G I C D I FF + JustGRPO combination. (2) Reasoning-adapti ve slots with ReFusion. (3) PRM-guided remasking. 7 Conclusion W e presented L O G I C D I FF , an inference-time method improving reasoning in masked dif fusion LMs by replacing confidence-based unmasking with logic-role-guided unmask- ing. A 4.2M-parameter head predicts logical roles; a dependency-ordered scheduler un- masks premises before conclusions. W ithout modifying LLaDA-8B-Instruct, L O G I C D I FF improv es GSM8K from 22.0% to 60.7% (+38.7 pp) and MA TH-500 from 23.6% to 29.2% (+5.6 pp). How tokens are unmasked matters as much as what the model has learned. References [1] M. Arriola et al. Block diffusion: Interpolating between autore gressi ve and diffusion language models. In ICLR (Oral) , 2025. [2] Y . Chen et al. Reasoning in diffusion LLMs is concentrated in dynamic confusion zones. arXiv:2511.15208 , 2025. [3] K. Cobbe et al. Training v erifiers to solve math w ord problems. , 2021. 8 [4] Dream: Discrete denoising diffusion language model. GitHub: DreamLM/Dream, 2025. [5] T . Du et al. Autoregressi ve models riv al diffusion models at any-order generation. arXiv:2601.13228 , 2026. [6] Y . Feng et al. Theoretical benefit and limitation of dif fusion language model. In ICLR , 2026. [7] D. Hendrycks et al. Measuring mathematical problem solving with the MA TH dataset. In NeurIPS , 2021. [8] Z. Li et al. ReFusion: A diffusion LLM with parallel autore gressiv e decoding. In ICLR , 2026. [9] Z. Ni et al. The flexibility trap: Why arbitrary order limits reasoning potential in diffusion LLMs. , 2026. [10] S. Nie et al. Large language dif fusion models. , 2025. [11] S. Sahoo et al. Simple and effecti ve mask ed dif fusion language models. In NeurIPS , 2024. [12] J. Shi et al. Simplified and generalized masked diffusion for discrete data. In NeurIPS , 2024. [13] T est-time scaling with diffusion LMs via re ward-guided stitching. , 2026. [14] T . Xie et al. Step-aware policy optimization for reasoning in diffusion LLMs. arXiv:2510.01544 , 2025. [15] J. Y e et al. Diffusion of thoughts: CoT reasoning in dif fusion language models. In NeurIPS , 2024. [16] Z. Zhao et al. d1: Scaling reasoning in diffusion LLMs via RL. , 2025. [17] X. Zhou et al. DOS: Dependency-oriented sampler for masked diffusion LMs. arXiv:2603.15340 , 2026. 9
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment