LogicDiff: 논리 역할 기반 마스크 해제로 추론 능력 대폭 향상
LogicDiff는 마스크된 확산 언어 모델(MDLM)의 토큰 해제 순서를 논리적 역할에 따라 재구성하는 추론‑시점 기법이다. 4.2 M 파라미터의 경량 분류 헤드가 각 마스크 위치를 전제·연결어·유도·결론·필러 중 하나로 98.4 % 정확도로 예측하고, 논리 의존도 순서에 따라 토큰을 차례로 해제한다. LLaDA‑8B‑Instruct에 적용했을 때 GSM8K 정확도가 22 %→60.7 %(+38.7 pp), MATH‑500이 23.6 %→29…
저자: Shaik Aman
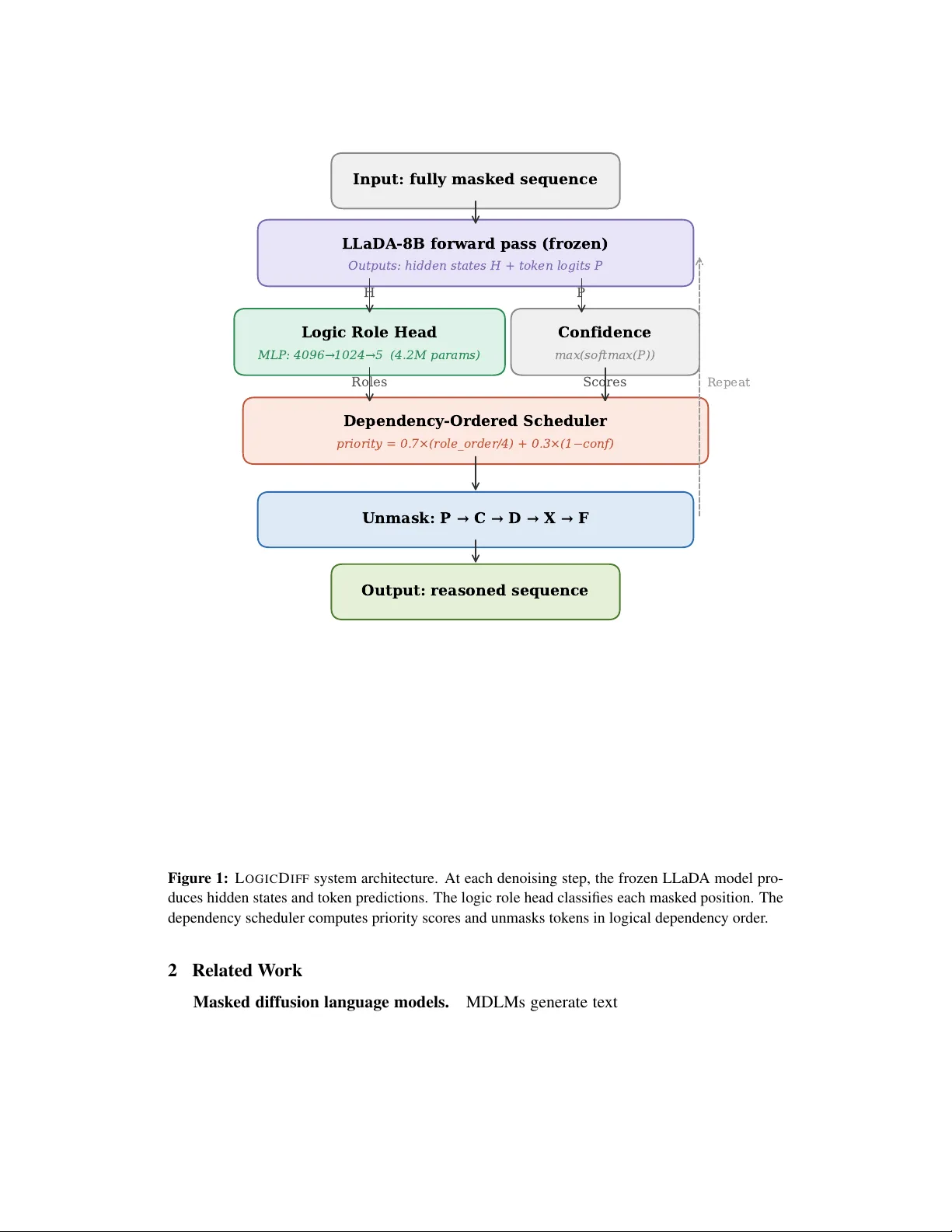
본 논문은 마스크된 확산 언어 모델(Masked Diffusion Language Model, MDLM)의 핵심 약점인 추론 능력 저하를 토큰 해제 순서의 비효율성에서 찾는다. 기존 MDLM은 confidence‑based 전략으로 가장 확신이 높은 토큰을 먼저 해제하는데, 이 과정에서 논리적 연결어와 같은 고엔트로피 토큰이 뒤로 밀려난다. 이러한 연결어는 추론 흐름을 갈라놓는 ‘분기점’ 역할을 하므로, 초기에 해제되지 않으면 모델이 주변 문맥만을 기반으로 답을 고정시켜 버린다. Ni et al.이 제시한 “Flexibility Trap”을 해결하기 위해, 저자는 전혀 모델 파라미터를 수정하지 않는 inference‑time 방법인 LogicDiff를 제안한다.
LogicDiff는 세 단계로 구성된다. 첫 번째 단계는 논리 역할 분류 헤드이다. 이 헤드는 frozen LLaDA‑8B‑Instruct의 은닉 상태를 입력으로 받아, 각 마스크 위치를 전제(Premise), 연결어(Connective), 유도(Derived), 결론(Conclusion), 필러(Filler) 중 하나로 5‑class 분류한다. 헤드는 2‑layer MLP(입력 LayerNorm → Linear → GELU → Dropout → Linear) 구조이며, 파라미터 수는 약 4.2 M(전체 모델 대비 0.05 %)에 불과하다. 학습 데이터는 GSM8K 풀이 7,473개를 두 번에 걸쳐 라벨링한 것으로, 전제·연결어·유도·결론·필러 비율이 크게 불균형하지만, 연결어에 10배 가중치를 부여해 클래스 불균형을 보정한다. 검증 정확도는 98.4 %에 달한다.
두 번째 단계는 의존도‑ordered 스케줄러이다. 각 토큰에 대해 role_order(전제 0, 연결어 1, 유도 2, 결론 3, 필러 4)를 정의하고, confidence(softmax max)와 결합해 우선순위 점수를 계산한다. 구체적으로 priority(i) = w_r·role_order(r_i)/(R‑1) + w_c·(1‑conf(i))이며, w_r=0.7, w_c=0.3으로 설정해 논리적 순서를 크게 강조한다. 매 디노이징 단계마다 전체 마스크 토큰 중 우선순위가 가장 낮은 K개를 선택해 해제한다. K는 전체 길이 L_g를 단계 수 N으로 나눈 값(⌈L_g/N⌉)이며, 이는 단계당 일정량의 토큰을 병렬적으로 처리하면서도 역할 그룹 내에서는 기존 confidence‑based 선택을 유지한다.
세 번째 단계는 실제 토큰 해제이다. 선택된 K개의 위치에 대해 기존 MDLM이 출력한 토큰 확률분포에서 가장 높은 확률을 가진 토큰을 채워 넣는다. 이렇게 하면 전제 → 연결어 → 유도 → 결론 순서대로 논리 구조가 점진적으로 구축되며, 이후 단계에서 값(token)들을 채워 넣는 것이 가능해진다.
실험 설정은 다음과 같다. 기본 모델은 LLaDA‑8B‑Instruct(8 B 파라미터, Llama‑3 기반)이며, 모든 파라미터를 고정한다. 역할 헤드는 GSM8K 풀이에 대해 30분(1 × H100) 학습한다. 평가 벤치마크는 GSM8K(1,319 문제)와 MATH‑500(500 문제)이며, 256 디노이징 단계와 최대 256 신규 토큰을 허용한다.
주요 결과는 표 1에 요약된다. LogicDiff를 적용한 경우 GSM8K 정확도가 22.0 %→60.7 %(+38.7 pp)로 크게 상승했으며, MATH‑500에서도 23.6 %→29.2 %(+5.6 pp)로 개선되었다. 속도는 기존 0.18 ex/s 대비 0.17 ex/s로 6 % 미만의 오버헤드만 발생했다. 비교 대상인 RL 기반 방법(d1, JustGRPO 등)은 수일 간의 대규모 GPU 클러스터(8 × A100)를 필요로 하고 모델 파라미터를 변경하지만, 최고 정확도는 89.1 %(GSM8K)까지 도달한다. LogicDiff는 비용 효율성 측면에서 큰 장점을 가지며, RL 기반 샘플러와 결합하면 추가적인 시너지 효과가 기대된다.
추가 분석에서는 역할 분포와 성능 간의 관계를 살펴보았다. GSM8K는 전제→추론→결론 구조가 명확해 역할 분류가 잘 맞아 높은 성능 향상을 보였지만, MATH‑500은 복잡한 대수적 변형이 많아 전제·결론 경계가 흐릿해 상대적으로 낮은 향상을 보였다. 그럼에도 불구하고 5가지 역할만으로도 일반화가 가능함을 확인했다. 또한, 기존 DOS
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기