From Diffusion To Flow: Efficient Motion Generation In MotionGPT3
Recent text-driven motion generation methods span both discrete token-based approaches and continuous-latent formulations. MotionGPT3 exemplifies the latter paradigm, combining a learned continuous motion latent space with a diffusion-based prior for…
Authors: Jaymin Ban, JiHong Jeon, SangYeop Jeong
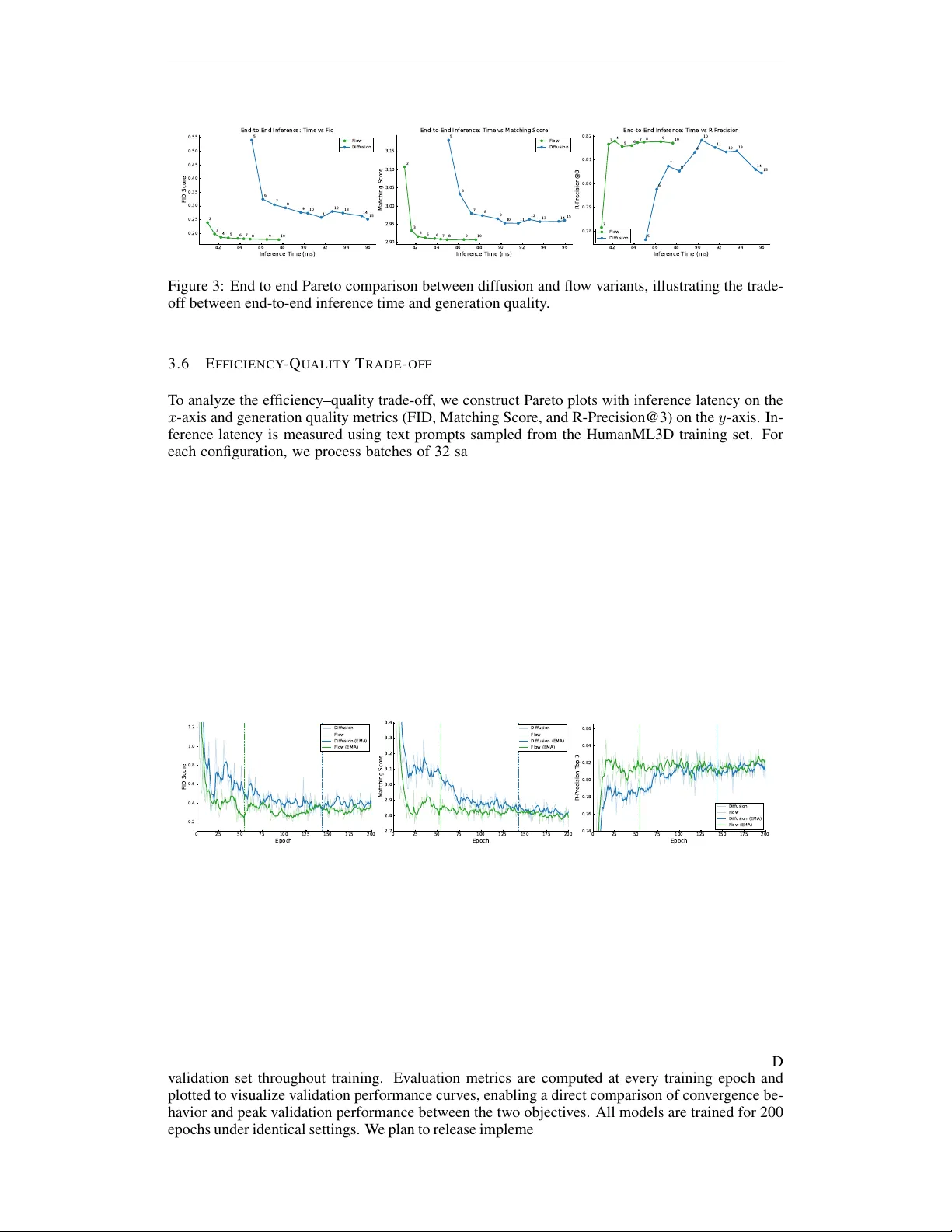
Published at the ReALM-GEN W orkshop at ICLR 2026 F R O M D I FF U S I O N T O F L O W : E FFI C I E N T M O T I O N G E N - E R A T I O N I N M O T I O N G P T 3 Jaymin Ban ∗ JiHong Jeon † SangY eop Jeong † Department of Applied Artificial Intelligence Seoul National Univ ersity of Science and T echnology { jayminban, gaebalja626, yeobi5840 } @seoultech.ac.kr https://github.com/jayminban/diffusion-to-flow-MotionGPT3 A B S T R AC T Recent text-dri ven motion generation methods span both discrete tok en-based ap- proaches and continuous-latent formulations. MotionGPT3 ex emplifies the latter paradigm, combining a learned continuous motion latent space with a diffusion- based prior for text-conditioned synthesis. While rectified flow objecti ves hav e recently demonstrated fav orable con ver gence and inference-time properties rela- tiv e to diffusion in image and audio generation, it remains unclear whether these advantages transfer cleanly to the motion generation setting. In this work, we conduct a controlled empirical study comparing diffusion and rectified flow ob- jectiv es within the MotionGPT3 frame work. By holding the model architecture, training protocol, and ev aluation setup fixed, we isolate the effect of the genera- tiv e objectiv e on training dynamics, final performance, and inference efficiency . Experiments on the HumanML3D dataset sho w that rectified flow con verges in fewer training epochs, reaches strong test performance earlier , and matches or ex- ceeds diffusion-based motion quality under identical conditions. Moreover , flow- based priors e xhibit stable behavior across a wide range of inference step counts and achiev e competitiv e quality with fe wer sampling steps, yielding improv ed efficienc y–quality trade-offs. Overall, our results suggest that se veral kno wn ben- efits of rectified flow objecti ves do extend to continuous-latent te xt-to-motion gen- eration, highlighting the importance of the training objecti ve choice in motion priors. 1 I N T R O D U C T I O N T ext-dri ven motion generation has seen significant progress through two parallel paradigms. One prominent approach relies on discrete latent representations, where motion sequences are quantized into symbolic tokens using V ector-Quantized V ariational Autoencoders (VQ-V AEs) (Jiang et al., 2023; Guo et al., 2023; van den Oord et al., 2018). By treating motion as a foreign language, these methods hav e successfully leveraged the po werful autoregressi ve capabilities of large language mod- els (LLMs). Howe ver , discretization introduces inherent limitations, including quantization artif acts and a reconstruction gap, which can suppress high-frequency details and fluid motion characteris- tics important for natural human movement, as noted in MotionGPT3 (Zhu et al., 2025). As an alternativ e to discrete tokenization, MotionGPT3 adopts a continuous-latent formulation by pairing a pretrained GPT -2–based text encoder with a continuous motion latent space and a text-conditioned diffusion prior for generation (see Figure 1). This design avoids explicit motion tokenization while retaining the semantic expressi veness of pretrained language representations, offering a compelling pathway to ward continuous text-to-motion synthesis. While diffusion-based priors hav e demonstrated strong performance in this setting, recent work in image and audio generation has sho wn that rectified flow objecti ves can e xhibit fav orable optimiza- tion and inference-time properties relative to dif fusion(Esser et al., 2024; Prenger et al., 2018). These ∗ Corresponding author . Contact: jayminban@gmail.com † Equal contribution 1 Published at the ReALM-GEN W orkshop at ICLR 2026 Figure 1: Ov erview of the MotionGPT -3 architecture with alternative motion priors. The dual- stream GPT -2 backbone produces text-conditioned motion latents, which are fed into either a diffusion-based or flow-based motion prior . The and symbols indicate frozen and trainable modules, respectiv ely . include earlier con vergence during training and improved ef ficiency–quality trade-of fs at inference. Whether such objective-le vel advantages transfer cleanly to continuous-latent motion generation, howe ver , remains an open question. MotionGPT3 provides a natural testbed for in vestigating this question, as it isolates the motion prior within an otherwise fixed continuous-latent architecture. In this work, we conduct a controlled empirical study comparing diffusion and rectified flow ob- jectiv es within the MotionGPT3 framew ork. W e replace the dif fusion objecti ve with a rectified flow objective (Liu et al., 2023) while holding the model architecture, dataset, and ev aluation pro- tocol fixed, allowing us to isolate the ef fect of the generati ve objective on training dynamics, final performance, and inference-time behavior . Unlike diffusion, which learns to reverse a stochastic noising process, rectified flow models a direct ODE trajectory between noise and data, providing a conceptually simpler optimization path. 2 Published at the ReALM-GEN W orkshop at ICLR 2026 Our experiments on the HumanML3D dataset suggest that several properties commonly associated with rectified flow in other generati ve domains also emer ge in the motion generation setting: • Earlier Con ver gence: Rectified flow reaches strong test performance in fewer training epochs under matched training conditions. • Comparable or Improved Final Perf ormance: Flow-based priors match or exceed diffusion-based motion quality in terms of R-Precision and FID. • Inference-Time Robustness: Generation quality remains stable across a wide range of inference step counts, with reduced sensitivity to step selection. • Improved Efficiency–Quality T rade-offs: Competitiv e generation quality is achieved with fewer sampling steps, enabling lo wer inference latency . T aken together , these findings highlight the importance of the generati ve training objecti ve in continuous-latent text-to-motion models. Within the MotionGPT3 framework, our results indicate that rectified flo w constitutes a practical alternati ve to dif fusion-based priors, particularly in settings where training efficienc y and inference-time latency are ke y considerations. 2 R E L A T E D W O R K T ext-to-Motion Dataset and Evaluation Protocol HumanML3D (Guo et al., 2022a) is the cur- rent standard dataset for text-driv en motion generation, providing a large-scale collection of paired motion–language data. Along with the dataset, the authors introduced a standardized ev aluation framew ork utilizing a learned joint text–motion embedding space. This frame work enables the calculation of retriev al-based metrics—such as R-Precision (R@K) and Matching Score—and has become the primary e valuation for assessing the performance and cross-modal alignment of motion generation models. Motion Generation Paradigms. Discrete motion generation methods rely on vector-quantized representations combined with autore gressiv e sequence models (Zhang et al., 2023; Guo et al., 2023; Jiang et al., 2023). These approaches benefit from language-model-style generation but may be con- strained by quantization artifacts. In contrast, continuous-latent approaches model motion directly in a continuous space, av oiding explicit tokenization and enabling finer-grained temporal represen- tations (T ev et et al., 2023; Chen et al., 2023; Zhang et al., 2024). Diffusion and Flow-Based Objecti ves. Dif fusion models have demonstrated strong performance for conditional generativ e modeling across multiple domains, including motion generation (Ho et al., 2020; T e vet et al., 2023; Zhang et al., 2024). Howe ver , diffusion-based sampling relies on iterativ e stochastic denoising, which can incur significant inference-time cost. Rectified flow matching (Liu et al., 2023) has been proposed as an alternati ve objecti ve that learns a deterministic vector field transporting noise to data, and has been shown in image generation to enable efficient sampling with fewer inference steps (Esser et al., 2024). Although flow-based objecti ves have been explored in motion generation, prior work typically introduces simultaneous architectural or training changes, making it difficult to isolate the ef fect of the generati ve objecti ve itself (Hu et al., 2023). 3 M E T H O D T o ev aluate the ef fect of the generative training objectiv e in isolation, we adopt the MotionGPT3 architecture (Zhu et al., 2025) as our experimental baseline. All architectural components, training hyperparameters, and data processing steps are kept identical to the original MotionGPT3 setup. The only modification is the choice of motion prior objectiv e: we replace the diffusion-based prior with a rectified flow formulation, both applied to the same text-conditioned motion latents. This design enables a controlled comparison between stochastic denoising and deterministic probability flow objecti ves with respect to training dynamics, motion quality , and inference efficiency . 3 Published at the ReALM-GEN W orkshop at ICLR 2026 3 . 1 A R C H I T E C T U R A L O V E RV I E W As illustrated in Figure 1, MotionGPT3 treats human motion as a trajectory within a continuous latent space and consists of three primary components: 1. Motion Latent Space: A v ariational autoencoder (V AE) that compresses raw motion se- quences into a continuous latent representation. 2. T ext Conditioning: A dual-stream GPT -2 backbone that encodes natural language prompts into a rich conditioning embedding, c . 3. Motion Prior Network: The motion prior of the system, mapping Gaussian noise ϵ ∼ N (0 , I ) to motion latents z conditioned on the text embedding c . Generated latents are decoded by the V AE to produce motion feature representations, which are subsequently con verted to 3D joint coordinates through a deterministic kinematic post-processing step. 3 . 2 T R A I N I N G P R O T O C O L All experiments are conducted on the HumanML3D dataset (Guo et al., 2022a) with a batch size of 50. Each training epoch corresponds to a full pass over the training split of HumanML3D. For each sample, four timesteps are independently sampled per iteration, producing four loss terms that are averaged to form the final training objectiv e for both diffusion-based and flow-based models. W e train the motion prior using the AdamW optimizer with a learning rate of 2 × 10 − 4 , β 1 = 0 . 9 , and β 2 = 0 . 99 . Under identical training configurations, each of the dif fusion and rectified flo w models requires approximately 13 hours of training on a single NVIDIA R TX 5090 GPU. The original MotionGPT3 training pipeline consists of three stages (Zhu et al., 2025). In this work, we focus exclusi vely on Stage 1 training, as the primary objecti ves of Stage 2 and Stage 3 are aimed at improving motion understanding rather than motion generation. The original MotionGPT3 study reports only marginal gains in motion generation quality from these later stages, and their associated objectiv es do not directly in volv e the motion prior . Accordingly , all results reported in this paper are obtained from models trained solely under the Stage 1 setting. 3 . 3 D I FF U S I O N - B A S E D M O T I O N P R I O R ( B A S E L I N E ) The motion prior is trained using a denoising diffusion probabilistic model (DDPM) objecti ve, which learns to predict Gaussian noise added to continuous motion latents. Follo wing standard DDPM practice, a scaled linear noise schedule with a fixed number of diffusion steps is employed. During training, a timestep t is sampled from the noise schedule and Gaussian noise ϵ ∼ N (0 , I ) is added to a clean motion latent x to obtain a noisy latent x t . The diffusion model predicts the noise compo- nent ϵ conditioned on the noisy latent x t , the timestep t , and the text conditioning representation c produced by the GPT -2 encoder . The training objecti ve is defined as: L diff = E x,ϵ,t ∥ ϵ − ϵ θ ( x t , t, c ) ∥ 2 , (1) where ϵ θ denotes the noise prediction network. At inference time, motion latents are generated via iterativ e ancestral sampling following the DDPM rev erse process, progressi vely denoising from pure Gaussian noise conditioned on the input text embedding. 3 . 4 F L O W - B A S E D M OT I O N P R I O R W e replace the diffusion-based training objecti ve with a rectified flow objective, while keeping the motion prior architecture, conditioning mechanism, and data pipeline unchanged. Follo wing prior work on rectified flow training, timesteps are sampled from a logit-normal distribution, which con- centrates probability mass around intermediate v alues (e.g., t ≈ 0 . 5 ) and has been shown to improve training stability in large-scale generativ e models (Esser et al., 2024). Given a clean motion latent x 0 and a noise sample x 1 ∼ N (0 , I ) , an interpolated latent state is constructed as x t = (1 − t ) x 1 + tx 0 . (2) 4 Published at the ReALM-GEN W orkshop at ICLR 2026 T able 1: Comparison of te xt-to-motion generation methods on HumanML3D. Arro ws indicate whether higher ( ↑ ) or lower ( ↓ ) values are better . Real denotes statistics computed from ground- truth motion data. Bold v alues indicate the best performance for each metric. Methods R@1 ↑ R@2 ↑ R@3 ↑ FID ↓ MMDist ↓ Div ersity ↑ MModality ↑ Real 0.511 0.703 0.797 0.002 2.974 9.503 – T2M-GPT (Zhang et al., 2023) 0.491 0.680 0.775 0.116 3.118 9.761 1.856 Div erseMotion (Lou et al., 2023) 0.515 0.706 0.802 0.072 2.941 9.683 1.869 MoMask (Guo et al., 2023) 0.521 0.713 0.807 0.045 2.958 9.620 1.241 MotionGPT (Jiang et al., 2023) 0.492 0.681 0.733 0.232 3.096 9.528 2.00 TM2T (Guo et al., 2022b) 0.424 0.618 0.729 1.501 3.467 8.589 2.424 MotionGPT3 (Reported) 0.533 0.731 0.826 0.239 2.797 9.688 1.560 MotionGPT3(Diffusion, ep. 142) 0.520 0.716 0.807 0.240 2.918 9.479 2.277 MotionGPT3(Flow . ep. 54) 0.544 0.740 0.828 0.192 2.837 9.340 2.366 Under this formulation, the target velocity field is constant along the interpolation path and is giv en by v true = x 0 − x 1 . (3) The motion prior network takes the interpolated latent x t , timestep t , and text conditioning repre- sentation c as input, and predicts a velocity field v θ ( x t , t, c ) . The rectified flo w objectiv e minimizes the squared error between the predicted and target v elocities: L flow = E h ∥ v θ ( x t , t, c ) − v true ∥ 2 i . (4) At inference time, motion latents are generated by integrating the learned velocity field using a nu- merical ODE solver . Unlike diffusion-based sampling, which relies on iterative stochastic denoising, rectified flow performs deterministic transport from noise to data. 3 . 5 E V A L U A T I O N M E T R I C S W e e valuate motion generation quality using standard text-to-motion metrics computed in a learned joint text–motion embedding space, following the ev aluation protocol introduced with the Hu- manML3D dataset (Guo et al., 2022a). Fr ´ echet Inception Distance (FID) measures the distribu- tional similarity between generated and ground-truth motions in this feature space, where lo wer v al- ues indicate closer alignment with the ground-truth distribution. R-Precision ev aluates text–motion semantic alignment by measuring how often a generated motion retrie ves its corresponding text de- scription among a set of 32 candidates, reported as top-1, top-2, and top-3 retrie val accurac y; higher values indicate stronger alignment. Matching Score computes the average Euclidean distance be- tween correctly paired motion and text embeddings, with lo wer values indicating tighter semantic correspondence. Div ersity measures the overall variability of the generated motion distrib ution by computing the av erage pairwise distance between randomly sampled motion embeddings. Multi- modality e v aluates the diversity of multiple motions generated from the same text prompt, reflecting the model’ s ability to produce varied outputs. All reported results in T able 1 are computed using these metrics. 2 4 6 8 10 12 14 16 Infer ence T ime (ms) 0.20 0.25 0.30 0.35 0.40 0.45 0.50 0.55 FID Scor e 2 3 4 5 6 7 8 9 10 5 6 7 8 9 10 11 12 13 14 15 Motion P rior Only Infer ence: T ime vs F id Flow Diffusion 2 4 6 8 10 12 14 16 Infer ence T ime (ms) 2.90 2.95 3.00 3.05 3.10 3.15 Matching Scor e 2 3 4 5 6 7 8 9 10 5 6 7 8 9 10 11 12 13 14 15 Motion P rior Only Infer ence: T ime vs Matching Scor e Flow Diffusion 2 4 6 8 10 12 14 16 Infer ence T ime (ms) 0.78 0.79 0.80 0.81 0.82 R -P r ecision@3 2 3 4 5 6 7 8 9 10 5 6 7 8 9 10 11 12 13 14 15 Motion P rior Only Infer ence: T ime vs R P r ecision Flow Diffusion Figure 2: Motion-prior-only inference Pareto comparison between diffusion and flo w variants, illus- trating the trade-off between inference time and generation quality . 5 Published at the ReALM-GEN W orkshop at ICLR 2026 82 84 86 88 90 92 94 96 Infer ence T ime (ms) 0.20 0.25 0.30 0.35 0.40 0.45 0.50 0.55 FID Scor e 2 3 4 5 6 7 8 9 10 5 6 7 8 9 10 11 12 13 14 15 End-to -End Infer ence: T ime vs F id Flow Diffusion 82 84 86 88 90 92 94 96 Infer ence T ime (ms) 2.90 2.95 3.00 3.05 3.10 3.15 Matching Scor e 2 3 4 5 6 7 8 9 10 5 6 7 8 9 10 11 12 13 14 15 End-to -End Infer ence: T ime vs Matching Scor e Flow Diffusion 82 84 86 88 90 92 94 96 Infer ence T ime (ms) 0.78 0.79 0.80 0.81 0.82 R -P r ecision@3 2 3 4 5 6 7 8 9 10 5 6 7 8 9 10 11 12 13 14 15 End-to -End Infer ence: T ime vs R P r ecision Flow Diffusion Figure 3: End to end Pareto comparison between diffusion and flow variants, illustrating the trade- off between end-to-end inference time and generation quality . 3 . 6 E FFI C I E N C Y - Q U A L I T Y T R A D E - O FF T o analyze the efficienc y–quality trade-off, we construct Pareto plots with inference latency on the x -axis and generation quality metrics (FID, Matching Score, and R-Precision@3) on the y -axis. In- ference latency is measured using text prompts sampled from the HumanML3D training set. For each configuration, we process batches of 32 samples, performing 3 warmup iterations for CUD A memory allocation and cache stabilization, followed by 10 timed iterations. W e report the av erage latency per batch across the timed runs. T wo timing modes are measured: (1) motion-prior-only inference Figure 2, which isolates the latent motion generation step; and (2) end-to-end inference Figure 3, comprising the LLM forward pass for conditioning, motion prior sampling and V AE de- coding. Inference latency is controlled by varying the number of motion prior inference steps. F or the flow-based model, motion latents are generated by inte grating the learned v elocity field using a fixed-step forward Euler solver , with the number of inte gration steps ranging from 2 to 15. For the diffusion baseline, we vary the number of denoising steps from 4 to 15. The diffusion model is trained with a 1000-step noise schedule; during inference, reduced step counts are obtained by uniformly subsampling this schedule (e.g., 100 inference steps correspond to a stride of 10). For each step configuration, generation quality is ev aluated on the HumanML3D test set using the standard ev aluation protocol described in Section 3.5. 0 25 50 75 100 125 150 175 200 Epoch 0.2 0.4 0.6 0.8 1.0 1.2 FID Scor e Diffusion Flow Diffusion (EMA) Flow (EMA) 0 25 50 75 100 125 150 175 200 Epoch 2.7 2.8 2.9 3.0 3.1 3.2 3.3 3.4 Matching Scor e Diffusion Flow Diffusion (EMA) Flow (EMA) 0 25 50 75 100 125 150 175 200 Epoch 0.74 0.76 0.78 0.80 0.82 0.84 0.86 R -P r ecision T op 3 Diffusion Flow Diffusion (EMA) Flow (EMA) Figure 4: V alidation metrics across training epochs for dif fusion- and flo w-based v ariants. W e report FID, Matching Score, and R-Precision (R@3). F aded curves indicate ra w v alidation measurements, while solid curves sho w exponential moving a verages computed with a span of fiv e epochs to high- light ov erall training trends. 4 E X P E R I M E N T S T o compare training dynamics and the best v alidation performance achie ved under different genera- tiv e objecti ves, we e valuate both diffusion-based and flo w-based motion priors on the HumanML3D validation set throughout training. Evaluation metrics are computed at e very training epoch and plotted to visualize v alidation performance curv es, enabling a direct comparison of con ver gence be- havior and peak validation performance between the two objectives. All models are trained for 200 epochs under identical settings. W e plan to release implementation details to support reproducibility . 6 Published at the ReALM-GEN W orkshop at ICLR 2026 4 . 1 V A L I D A T I O N M E T R I C D Y N A M I C S During training, we analyze the ev olution of validation metrics under the HumanML3D ev aluation protocol. Figure 4 illustrates the v alidation trends for diffusion and flow-based objectives. Across all metrics, rectified flow exhibits steeper early-stage improvement, reaching competitiv e performance significantly earlier than diffusion. V alidation performance for the flow objecti ve saturates after ap- proximately 50 epochs, whereas diffusion continues to improve until around 100 epochs. W e further observe that additional training stages (Stage 2 and Stage 3) yield only mar ginal improv ements in motion generation performance for both objectiv es, suggesting that the majority of representational capacity is acquired during the initial training phase. 4 . 2 T E S T S E T P E R F O R M A N C E U N D E R M A T C H E D C O N D I T I O N S T o compare the best test performance achie ved by each training objectiv e under a fixed training b ud- get, we sav e model checkpoints at ev ery epoch ov er 200 training epochs and e valuate each check- point on a held-out test set that remains fully isolated throughout training. For both diffusion- and flow-based objecti ves, the epoch at which peak test performance is attained dif fers substantially . The flow-based model achieves its best test performance at epoch 54 (T able 1), after which additional training yields diminishing returns. In contrast, the dif fusion-based model reaches its peak perfor- mance considerably later , at epoch 143. These trends are consistent with the v alidation dynamics observed during training. The vertical dashed lines in Figure 4 indicate the epochs correspond- ing to peak test-set performance for each objective. At their respecti ve peak epochs, MotionGPT3 trained with the flow objecti ve achiev es approximately a 3% relati ve improv ement in R-Precision across R@1, R@2, and R@3, along with an approximately 5% reduction in FID compared to the diffusion-based counterpart. Differences in Matching Score are comparati vely small. 4 . 3 I N F E R E N C E L ATE N C Y A N D S P E E D – Q U A L I T Y T R A D E - O FF Beyond training ef ficiency , we ev aluate inference-time latenc y by v arying the number of sampling steps used by the motion prior . Figure 2 reports P areto curv es that characterize the trade-off between generation quality and inference cost attrib utable solely to the motion prior across dif ferent sampling step counts. Under identical hardware and batch-size settings, the flow-based motion prior reaches near-peak ev aluation performance with as fe w as four inference steps, whereas the diffusion-based prior requires approximately eight denoising steps to attain comparable quality . In addition, even at matched step counts, diffusion incurs higher wall-clock latency due to auxiliary post-processing operations performed after each network in vocation. In contrast, flow-based inference relies on a lightweight numerical ODE solver with lo wer per-step o verhead. As a result, diffusion e xhibits approximately 15–20% longer wall-clock inference time than the flow-based Euler solver at equiv alent step counts. While the flow-based formulation reduces the computational cost of the motion prior , end-to-end latency improvements are partially constrained by fixed pipeline components, including te xt encoding and V AE decoding, which are independent of the generativ e objectiv e. W e additionally ev aluated higher-order numerical solvers, such as fourth- order Runge–Kutta (RK4); howe ver , these did not yield meaningful impro vements in e valuation quality nor reduce the ef fecti ve number of inference steps in this setting. T o account for full-pipeline effects, we further report end-to-end speed–quality trade-of fs that include te xt encoding, motion prior inference, and V AE decoding. As sho wn in Figure 3, these fixed components constitute a non-negligible fraction of total inference time, reducing the relative latency gap between dif fusion and flo w . Nev ertheless, the flow-based formulation consistently achie ves comparable or superior generation quality at lower end-to-end inference cost. 5 D I S C U S S I O N The experimental results indicate that, within the MotionGPT3 framew ork, replacing the diffusion- based motion prior with a rectified flo w formulation is associated with faster con ver gence, impro ved sampling stability , and reduced inference latency under matched training and ev aluation settings, while maintaining comparable overall performance. In this section, we discuss possible explana- tions for the observed optimization beha vior , analyze the resulting effic iency–quality trade-of fs, and clarify the scope and limitations of the proposed approach. 7 Published at the ReALM-GEN W orkshop at ICLR 2026 5 . 1 I N T E R P R E TA T I O N O F F A S T E R C O N V E R G E N C E As shown in Figure 4, the motion prior trained with a rectified flow objecti ve reaches strong val- idation performance in fewer training epochs than its diffusion-based counterpart across multiple metrics. In particular, flo w-based training exhibits earlier stabilization of validation curv es, indicat- ing faster con vergence under matched training conditions. This behavior is consistent with the de- terministic vector -field formulation of rectified flow , which models a continuous transport between noise and data distributions rather than learning to inv ert a stochastic noising process. By av oid- ing stochastic denoising trajectories during training, rectified flo w reduces gradient noise associated with timestep sampling and may yield a more stable optimization landscape, allowing informative gradients to emerge earlier in training (Liu et al., 2022). T aken together, these results suggest that some of the con vergence advantages previously observed for rectified flow objectives in other generativ e settings(Song et al., 2023) can transfer to motion priors operating in continuous latent spaces. 5 . 2 E FFI C I E N C Y – Q U A L I T Y T R A D E - O FF S In our experiments, flow-based inference attains near-peak generation quality with as few as four Euler integration steps, whereas dif fusion-based sampling requires approximately eight denoising steps to achiev e comparable performance. This difference highlights a fundamental contrast in how the two objecti ves model the transformation from noise to data in continuous motion latent space. Interestingly , we observe that the dif fusion-based DDPM sampler also exhibits performance satu- ration with fewer than ten denoising steps. This behavior suggests that the underlying denoising trajectory in this domain is relati vely smooth, reducing the need for long, iterativ e refinement pro- cesses. In such settings, the optimal transport path between noise and data distrib utions appears close to linear , fa voring objecti ves that directly model straight or lo w-curvature trajectories. Rectified flow explicitly parameterizes this transport as a deterministic vector field and thus can approximate the required transformation with a small number of integration steps. In contrast, diffusion-based models learn the same mapping implicitly through stochastic denoising, requiring multiple refinement steps to progressively remov e injected noise. As a result, flow-based inference can reach comparable solution quality with fewer steps, while dif fusion must compensate through additional iterations. Beyond step count, flow-based inference also e xhibits more stable generation quality across a range of inference steps, whereas diffusion-based sampling is noticeably more sensiti ve to the number of denoising steps. W e attribute this sensitivity to the stochastic nature of diffusion sampling and the complexity of each denoising update. Each dif fusion step in volves predicting noise, con verting it to a clean latent estimate, computing timestep-dependent posterior statistics, retrie ving variance coefficients from predefined schedules, and injecting additional Gaussian noise. These operations introduce sensitivity to step discretization, which accumulate across inference iterations. In contrast, flow-based inference consists of a single netw ork e valuation followed by a simple, deterministic up- date at each step. This structural simplicity results in lo wer per -step latency and more predictable behavior , enabling stable performance across a wider range of step counts. Ov erall, these observa- tions indicate that flow-based objecti ves shift the quality–efficienc y Pareto frontier in continuous- latent motion generation, achieving comparable or impro ved generation quality with fe wer inference steps. 5 . 3 L I M I TA T I O N S A N D F U T U R E W O R K Our study focuses on a controlled comparison of generati ve objectiv es within a single continuous- latent framew ork, MotionGPT3. While this design choice enables isolation of the training objecti ve, it also limits the generality of our conclusions. In particular, it remains an open question whether the observed conv ergence and efficienc y benefits of rectified flow transfer to alternativ e text-to-motion architectures, substantially larger motion priors, or different conditioning backbones. Additionally , MotionGPT3 operates on a relativ ely compact motion latent space, which constrains the absolute latency reduction achiev able through sampling step reduction alone. End-to-end inference time is further bounded by fixed pipeline components, including text encoding and V AE decoding, which 8 Published at the ReALM-GEN W orkshop at ICLR 2026 are unaf fected by the choice of generati ve objective. As a result, ef ficiency gains at the motion-prior lev el may be partially masked when measured at the full-pipeline le vel. Despite these limitations, the impro ved sampling robustness and reduced sensitivity to inference step counts of fered by flow-based priors e xpand the design space for latency-sensiti ve motion generation systems, such as interacti ve applications and real-time embodied agents. While it remains unclear whether the observed benefits persist uniformly as model capacity increases, scaling the motion prior represents a promising direction for future inv estigation. In particular , lar ger or more expressiv e motion priors may allow efficiency gains at the objecti ve level to translate more directly into end-to- end improv ements. Finally , current standardized text-to-motion ev aluations predominantly rely on explicitly motion- descriptiv e prompts. Extending ev aluation protocols to include more implicit, narrativ e, or goal- oriented language—such as instructions deriv ed from visual media or natural human interac- tions—would better reflect real-world deployment scenarios and place greater emphasis on ef ficient inference. Dev eloping datasets and ev aluation metrics aligned with such settings represents an im- portant direction for future research. 6 C O N C L U S I O N In this work, we in vestigated how the choice of generati ve training objecti ve influences optimiza- tion beha vior , inference efficiency , and motion generation quality within a continuous-latent text-to- motion frame work. Our results show that rectified flow exhibits fav orable optimization and infer - ence properties in continuous-latent motion generation, including faster con ver gence during training, stable performance across a range of inference step counts, and competitiv e or improved genera- tion quality under matched conditions. In particular , flow-based motion priors achieve comparable quality with fewer inference steps than diffusion-based counterparts, yielding improved ef ficiency– quality trade-offs. T aken together , these findings suggest that sev eral benefits previously observed for flo w-based gen- erativ e modeling in image and video domains transfer to text-dri ven motion generation when oper- ating in continuous latent spaces. W ithin the MotionGPT3 frame work, rectified flo w constitutes a practical and computationally efficient alternati ve to diffusion-based priors, particularly for latency- sensitiv e applications. W e hope this study encourages further in vestig ation of objecti ve-le vel design choices in motion generation models and their interaction with model capacity , architecture, and downstream deplo yment constraints. A C K N O W L E D G E M E N T S In preparing this paper , we used a large language model to assist with code de velopment and to refine the manuscript’ s writing. All technical content, e xperiments, and conclusions were de veloped and verified by the authors. R E F E R E N C E S Xin Chen, Biao Jiang, W en Liu, Zilong Huang, Bin Fu, T ao Chen, and Gang Y u. Executing your commands via motion diffusion in latent space. In Pr oceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition (CVPR) , 2023. Patrick Esser , Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨ uller , Harry Saini, Y am Levi, Dominik Lorenz, Axel Sauer , Frederic Boesel, Dustin Podell, T im Dockhorn, Zion En- glish, Kyle Lacey , Alex Goodwin, Y annik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis, 2024. URL 2403.03206 . Chuan Guo, Shihao Zou, Xinxin Zuo, Sen W ang, W ei Ji, Xingyu Li, and Li Cheng. Generating div erse and natural 3d human motions from text. In Pr oceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition (CVPR) , pp. 5152–5161, June 2022a. 9 Published at the ReALM-GEN W orkshop at ICLR 2026 Chuan Guo, Xinxin Zuo, Sen W ang, and Li Cheng. Tm2t: Stochastic and tokenized modeling for the reciprocal generation of 3d human motions and texts, 2022b. URL abs/2207.01696 . Chuan Guo, Y uxuan Mu, Muhammad Gohar Ja ved, Sen W ang, and Li Cheng. Momask: Generati ve masked modeling of 3d human motions, 2023. URL 00063 . Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Pr ocessing Systems , volume 33, pp. 6840–6851, 2020. V incent T ao Hu, W enzhe Y in, Pingchuan Ma, Y unlu Chen, Basura Fernando, Max W elling, Cees G.M. Snoek, and Angela Y ao. Motion flow matching for human motion synthesis and editing. In NeurIPS , 2023. Biao Jiang, Xin Chen, W en Liu, Jingyi Y u, Gang Y u, and T ao Chen. Motiongpt: Human motion as a foreign language, 2023. URL . Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow , 2022. URL . Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow . In International Confer ence on Learning Representations , 2023. Y unhong Lou, Linchao Zhu, Y axiong W ang, Xiaohan W ang, and Y i Y ang. Div ersemotion: T owards div erse human motion generation via discrete diffusion, 2023. URL abs/2309.01372 . Ryan Prenger , Rafael V alle, and Bryan Catanzaro. W ave glow: A flow-based generati ve netw ork for speech synthesis, 2018. URL . Y ang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskev er . Consistency models, 2023. URL https://arxiv.org/abs/2303.01469 . Guy T evet, Sigal Raab, Brian Gordon, Y oni Shafir , Daniel Cohen-Or, and Amit H Bermano. Human motion diffusion model. In International Conference on Learning Representations , 2023. Aaron van den Oord, Oriol V inyals, and Koray Ka vukcuoglu. Neural discrete representation learn- ing, 2018. URL . Jianrong Zhang, Y angsong Zhang, Xiaodong Cun, Shaoli Huang, Y ong Zhang, Hongwei Zhao, Hongtao Lu, and Xi Shen. T2m-gpt: Generating human motion from textual descriptions with discrete representations, 2023. URL . Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Y ang, and Ziwei Liu. Motiondiffuse: T ext-dri ven human motion generation with diffusion model. IEEE T ransac- tions on P attern Analysis and Machine Intelligence , 2024. Bingfan Zhu, Biao Jiang, Sunyi W ang, Shixiang T ang, T ao Chen, Linjie Luo, Y ouyi Zheng, and Xin Chen. Motiongpt3: Human motion as a second modality , 2025. URL abs/2506.24086 . 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment