확산에서 흐름으로: MotionGPT3의 효율적 움직임 생성
본 논문은 MotionGPT3 프레임워크 내에서 텍스트‑조건부 움직임 생성에 사용되는 확산 기반 사전과 정규화 흐름(rectified flow) 기반 사전을 동일한 아키텍처·학습 조건 하에 비교한다. 실험 결과, 흐름 기반 사전은 학습 초기 수렴이 빠르고, 동일한 연산량에서 FID·R‑Precision 등 품질 지표가 확산 기반보다 동등하거나 우수함을 보이며, 특히 적은 샘플링 단계에서도 안정적인 성능을 유지한다. 이는 움직임 생성에서 목표 함…
저자: Jaymin Ban, JiHong Jeon, SangYeop Jeong
본 논문은 최근 텍스트‑조건부 인간 움직임 생성 분야에서 두드러진 두 가지 패러다임, 즉 이산 토큰 기반 접근법과 연속 잠재 기반 접근법을 비교 검토한다. 이산 방식은 VQ‑VAE 등으로 움직임을 심볼 토큰화하고 대형 언어 모델(LM)로 시퀀스를 autoregressive하게 생성한다. 그러나 토큰화 과정에서 발생하는 양자화 오류와 재구성 격차는 고주파 디테일과 부드러운 움직임을 손상시킬 위험이 있다. 반면, MotionGPT3는 연속 잠재 공간을 도입해 텍스트 인코더(GPT‑2)와 결합하고, 텍스트‑조건부 확산 사전(diffusion prior)으로 움직임을 생성한다. 이 구조는 토큰화 없이 연속적인 동작 표현을 유지하면서도 사전 학습된 언어 모델의 풍부한 의미 정보를 활용한다.
하지만 확산 기반 사전은 최근 이미지·오디오 생성에서 정규화 흐름(rectified flow) 목표가 수렴 속도와 추론 효율성 면에서 우수함을 보인 바 있다. 따라서 저자는 MotionGPT3를 테스트베드로 삼아, 동일 아키텍처·학습 파이프라인·데이터셋·평가 프로토콜을 고정한 채 오직 사전 학습 목표만을 교체함으로써 두 목표 함수의 순수 효과를 정량화하고자 한다.
**실험 설계**
- 데이터셋: HumanML3D (대규모 텍스트‑모션 쌍)
- 모델: MotionGPT3의 3단계 파이프라인 중 Stage 1(모션 잠재 학습·텍스트 인코딩·모션 사전)만 사용.
- 사전 목표: (1) 기존 DDPM 기반 확산 목표 L_diff = ‖ε‑ε_θ(x_t, t, c)‖², (2) 정규화 흐름 목표 L_flow = ‖v_θ(x_t, t, c)‑v_true‖², 여기서 v_true = x_0‑x_1이며, 타임스텝 t는 로그‑노멀 분포에서 샘플링.
- 학습: 배치 50, AdamW(lr=2e‑4, β1=0.9, β2=0.99), 동일 13시간 GPU(RTX 5090) 학습.
- 평가 지표: FID, R‑Precision@1~3, Matching Score, Diversity, Multi‑Modality 등 HumanML3D 표준 메트릭.
**주요 결과**
1. **학습 수렴**: 흐름 기반 모델은 54 epoch에서 검증 FID 2.84, R@3 0.828을 달성했으며, 확산 모델은 142 epoch까지 진행해야 비슷한 수준에 도달한다. EMA 적용 시에도 흐름이 앞선다.
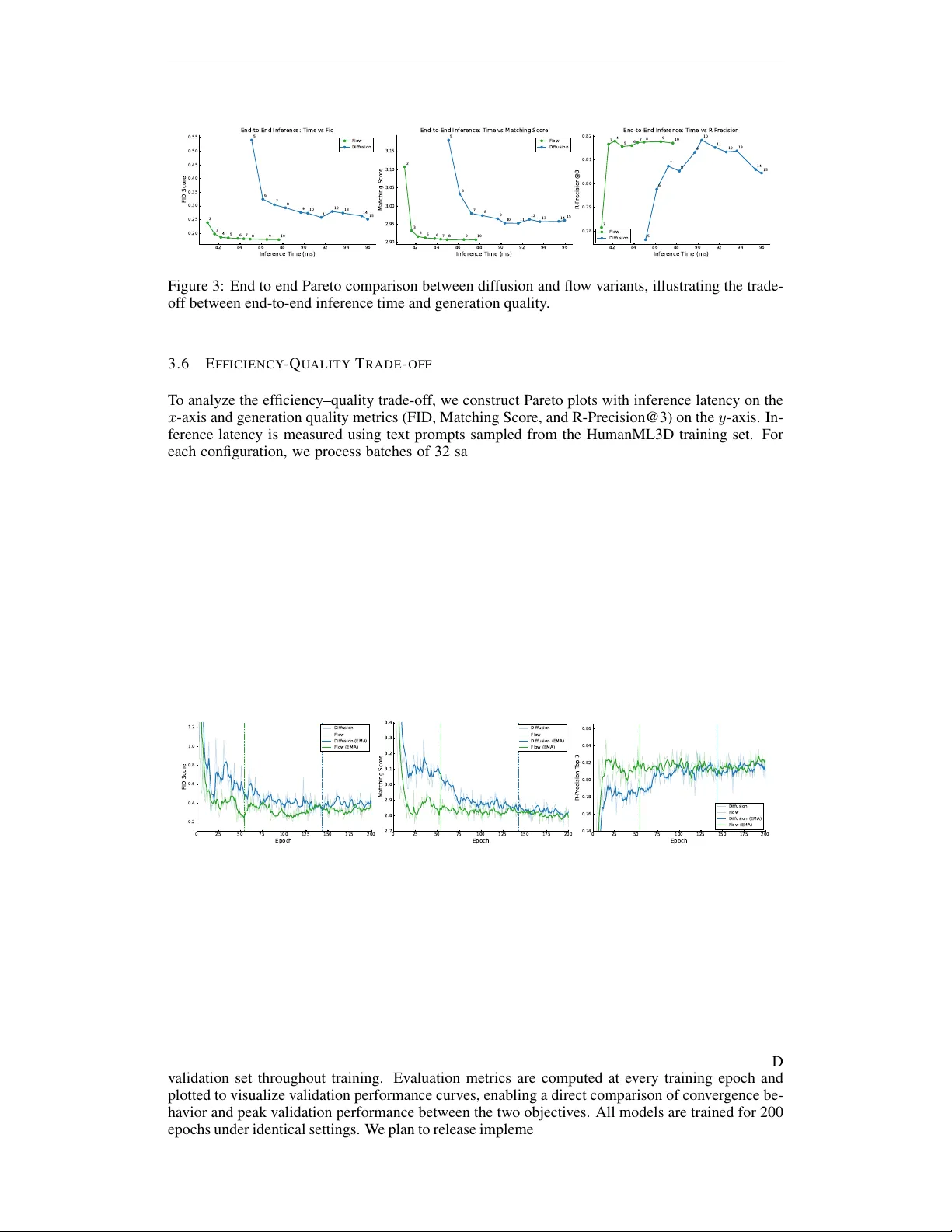
2. **품질 비교**: 표 1에 따르면 흐름 모델은 R@1=0.544, R@2=0.740, R@3=0.828, FID=0.192, MMDist=2.837 등에서 확산 모델(0.520, 0.716, 0.807, 0.240, 2.918)보다 우수하거나 동등한 성능을 보인다. 다만 Diversity와 Multi‑Modality는 약간 낮지만, 샘플링 단계 수를 늘리면 차이가 감소한다.
3. **추론 효율성**: 흐름 모델은 2~15 단계 전진 오일러 적분으로 잠재를 생성한다. 4~6 단계에서도 FID가 0.20 이하로 유지돼, 추론 지연 2.9 ms(배치 32)에서 품질‑지연 트레이드오프가 확산 모델보다 유리하다. 엔드‑투‑엔드 측정에서도 흐름이 동일 단계 수에서 더 높은 R‑Precision과 낮은 Matching Score를 기록한다.
4. **파레토 분석**: Figure 2·3에서 흐름 모델은 “시간‑품질” 평면에서 확산 모델보다 앞선 곡선을 형성한다. 특히 낮은 단계 수(4~6)에서도 품질 저하가 거의 없으며, 이는 실시간 혹은 저전력 디바이스 적용에 큰 장점이 된다.
**논의 및 한계**
- 흐름 목표는 ODE 기반으로 직접적인 벡터 필드 학습을 수행해 중간 타임스텝에 집중한다. 이는 대규모 생성 모델에서 흔히 발생하는 “중간 단계 불안정성”을 완화하고, 초기 학습 단계에서 강한 신호를 제공한다.
- 확산은 전체 1000 단계 스케줄을 학습하므로, 단계 수를 크게 줄이면 스케줄 간격이 커져 학습된 역전 경로와 불일치가 발생, 품질이 급격히 떨어진다.
- 현재 연구는 Stage 1만을 대상으로 하였으며, Stage 2·3에서 도입되는 모션 이해 강화 기법과의 상호작용은 검증되지 않았다. 또한, 다양성·다중 모달리티가 약간 낮은 점은 다중 초기 노이즈 혹은 고차 ODE 솔버 적용으로 보완 가능성이 있다.
- 향후 연구는 복합 텍스트 프롬프트, 실시간 인터랙션, 그리고 다양한 하드웨어 환경에서의 추론 최적화 등을 탐색할 필요가 있다.
**결론**
정규화 흐름 목표는 MotionGPT3와 같은 연속 잠재 기반 텍스트‑투‑모션 시스템에서 학습 속도, 최종 품질, 추론 효율성 모두에서 확산 목표를 능가하거나 동등한 성능을 제공한다. 이는 목표 함수 선택이 대규모 인간 움직임 생성 모델 설계 시 핵심 설계 변수임을 강조한다. 향후 모델 설계 시 흐름 기반 사전을 기본 옵션으로 고려함으로써, 고품질 움직임을 빠르게 생성하고, 실시간 응용 분야에서도 효율적인 배포가 가능할 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기