Do Multilingual VLMs Reason Equally? A Cross-Lingual Visual Reasoning Audit for Indian Languages
Vision-language models score well on mathematical, scientific, and spatial reasoning benchmarks, yet these evaluations are overwhelmingly English. I present the first cross-lingual visual reasoning audit for Indian languages. 980 questions from MathV…
Authors: Swastik R
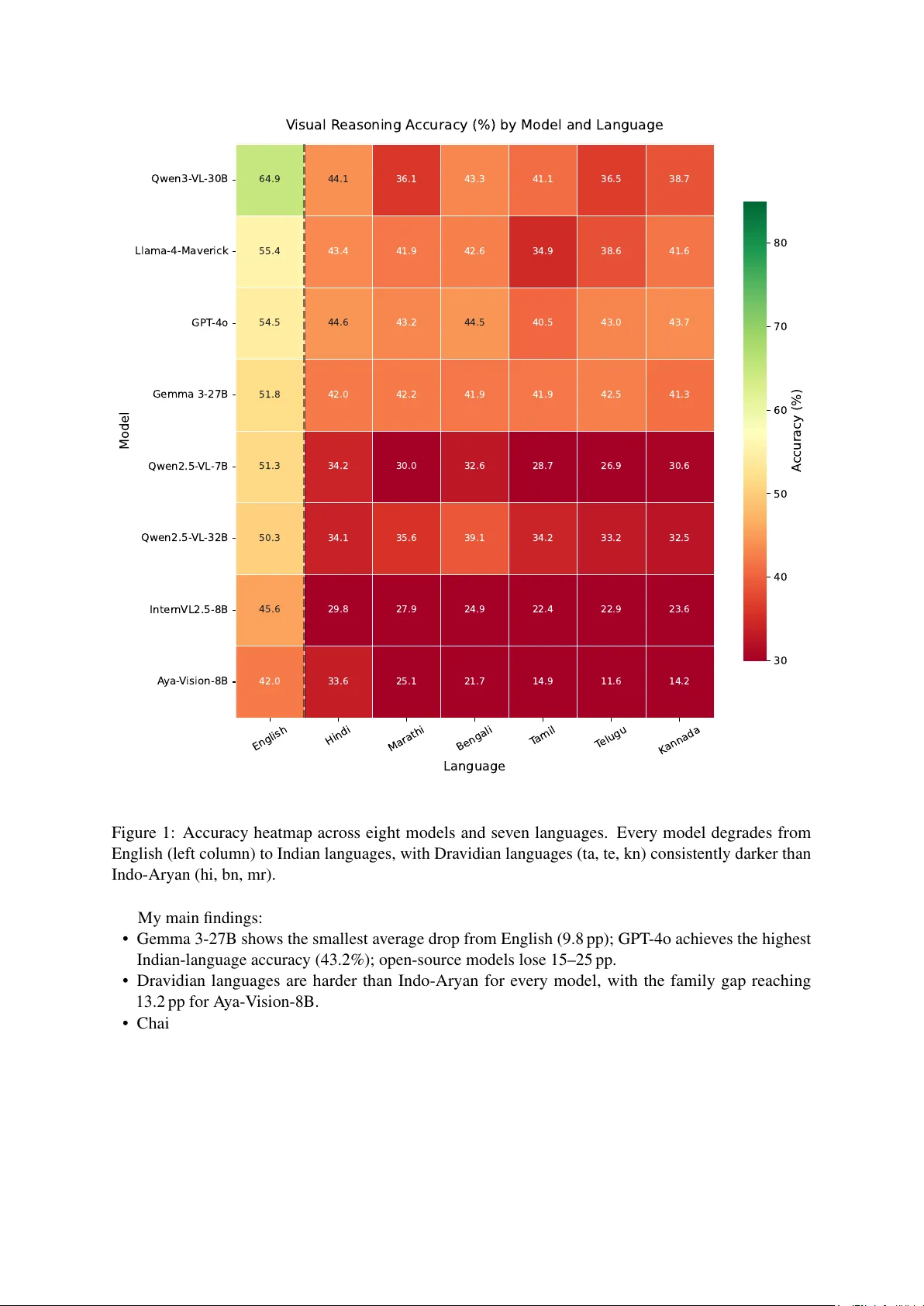
Do Multilingual VLMs Reason Equally? A Cross-Lingual V isual Reasoning Audit for Indian Languages Swastik R Indian Institute of Information T echnology , Raichur Abstract V ision-language models score well on mathematical, scientific, and spatial reasoning benchmarks, yet these e valuations are ov erwhelmingly English. I present the first cross-lingual visual reasoning audit for Indian languages. 980 questions from MathV ista, ScienceQA, and MMMU are translated into Hindi, T amil, T elugu, Bengali, Kannada, and Marathi using IndicTrans2, with Gemini 2.0 Flash cross-verification on 50 samples per language (inter-translator agreement 0.79–0.84). Eight VLMs, from 7B open-source models to GPT -4o, are e v aluated across all se ven languages, yielding 68,600 inference records that include text-only and chain-of-thought ablations. I find accuracy drops of 9.8–25 percentage points when switching from English to an Indian language, with Dravidian languages suffering up to 13.2 pp more than Indo-Aryan. Chain-of-thought prompting de grades Bengali ( − 14.4 pp ) and Kannada ( − 11.4 pp ) rather than helping, exposing English-centric reasoning chains. A ya-V ision-8B, b uilt for 23 languages, still drops 28.5 pp on Dravidian scripts; multilingual pretraining alone does not transfer visual reasoning. I release the translated benchmark and all model outputs. 1 1 Intr oduction India’ s 260 million school-age children study predominantly in regional-medium schools where the language of instruction is Hindi, T amil, T elugu, Bengali, Kannada, or Marathi [ Ministry of Human Resource Dev elopment, Gov ernment of India , 2020 ]. EdT ech platforms are beginning to integrate vision- language models (VLMs) for automated tutoring and assessment, raising a practical question: can these models reason about mathematics and science in the student’ s own language ? Existing benchmarks do not answer this. Indian-language VLM ev aluations probe cultural under- standing [ Surana et al. , 2026 , Maji et al. , 2025 ], factual VQA [ F araz et al. , 2025 ], or broad multilingual proficiency [ Khan et al. , 2025 ], b ut none isolate mathematical, scientific, or spatial reasoning. India- focused VLM architectures such as Chitrarth [ Khan et al. , 2025 ] have been proposed, yet no benchmark exists to test whether the y , or any other model, can actually solve Kannada science problems or T amil geometry . I address this gap by translating 980 visual reasoning questions from MathV ista [ Lu et al. , 2024 ], ScienceQA [ Lu et al. , 2022 ], and MMMU [ Y ue et al. , 2024a ] into six Indian languages with Indic- T rans2 [ Gala et al. , 2023 ]. The images stay fixed across languages; only the question text changes. Eight VLMs are e v aluated (GPT -4o, Gemma 3-27B, Llama-4-Mav erick, Qwen3-VL-30B, Qwen2.5-VL-32B, Qwen2.5-VL-7B, InternVL2.5-8B, and A ya-V ision-8B), together with te xt-only and chain-of-thought ablations on Qwen2.5-VL-7B, for a total of 68,600 inference records (Figure 1 ). 1 Code and data: https://github.com/QuantumByte- 01/multilingual- vlm- reasoning- audit ; Hug- gingFace: https://huggingface.co/datasets/Swastikr/multilingual- vlm- reasoning 1 English Hindi Marathi Bengali T amil T elugu K annada Language Qwen3- VL -30B Llama-4-Maverick GPT -4o Gemma 3-27B Qwen2.5- VL -7B Qwen2.5- VL -32B Inter nVL2.5-8B A ya- V ision-8B Model 64.9 44.1 36.1 43.3 41.1 36.5 38.7 55.4 43.4 41.9 42.6 34.9 38.6 41.6 54.5 44.6 43.2 44.5 40.5 43.0 43.7 51.8 42.0 42.2 41.9 41.9 42.5 41.3 51.3 34.2 30.0 32.6 28.7 26.9 30.6 50.3 34.1 35.6 39.1 34.2 33.2 32.5 45.6 29.8 27.9 24.9 22.4 22.9 23.6 42.0 33.6 25.1 21.7 14.9 11.6 14.2 V isual R easoning A ccuracy (%) by Model and Language 30 40 50 60 70 80 A ccuracy (%) Figure 1: Accuracy heatmap across eight models and sev en languages. Every model degrades from English (left column) to Indian languages, with Dravidian languages (ta, te, kn) consistently darker than Indo-Aryan (hi, bn, mr). My main findings: • Gemma 3-27B sho ws the smallest av erage drop from English (9.8 pp ); GPT -4o achie ves the highest Indian-language accuracy (43.2%); open-source models lose 15–25 pp. • Dravidian languages are harder than Indo-Aryan for ev ery model, with the family gap reaching 13.2 pp for A ya-V ision-8B. • Chain-of-thought prompting backfires in Indian languages: Bengali accuracy falls 14.4 pp and Kannada 11.4 pp relati ve to the standard prompt, indicating that the model’ s reasoning chains are locked to English. • Removing the i mage costs English 15.5 pp but only 4.9–9.7 pp for Indian languages, implying that models under-e xploit visual information when text comprehension is weak. • Scaling from 7B to 32B within the Qwen2.5-VL f amily gains 4.3 pp on Indian languages while losing 1.0 pp on English; scale broadens linguistic coverage without impro ving reasoning. 2 2 Related W ork Indian-language VLM benchmarks. IndicV isionBench [ Faraz et al. , 2025 ] covers 10 Indian languages with ov er 37K QA pairs b ut tar gets cultural understanding and OCR, not reasoning. The BharatBench frame work introduced in Khan et al. [ 2025 ] spans speech, OCR, and embeddings without isolating STEM tasks. VIRAASA T [ Surana et al. , 2026 ] and DRISHTIK ON [ Maji et al. , 2025 ] e v aluate cultural kno wledge and geographic div ersity . Chitrarth [ Khan et al. , 2025 ] introduces an India-focused VLM architecture but no reasoning-specific e valuation. This work differs by holding the image fixed and v arying only the question language, so that any accurac y change is directly attributable to language. Multilingual VLM ev aluation beyond India. MaR VL [ Liu et al. , 2021 ] tests visually grounded reason- ing in fi ve languages, including T amil, but relies on culturally situated images and predates current VLMs. xGQA [ Pfeif fer et al. , 2022 ] e xtends GQA to se ven languages, none Indian. VLURes [ Atuhurra et al. , 2025 ] benchmarks four languages including Urdu. ALM-Bench [ V ayani et al. , 2024 ] and CVQA [ Romero et al. , 2024 ] include partial Indian-language cov erage b ut do not focus on reasoning. P angea [ Y ue et al. , 2024b ], a 39-language multimodal LLM, is the closest open-source multilingual effort, though it too lacks a reasoning-focused benchmark. V isual reasoning benchmarks. MathV ista [ Lu et al. , 2024 ] ev aluates mathematical reasoning in visual contexts; MA TH-V ision [ W ang et al. , 2024 ] extends this to competition-lev el problems. ScienceQA [ Lu et al. , 2022 ] covers K-12 science with diagrams. MMMU [ Y ue et al. , 2024a ] targets college-le vel STEM across 30 subjects. All three are English-only; I e xtend them cross-lingually . Multilingual reasoning in LLMs. Shi et al. [ 2023 ] showed that English chain-of-thought outperforms nati ve-language CoT on grade-school math in 10 languages, b ut without images. Ahuja et al. [ 2023 ] broadened multilingual generativ e ev aluation across tasks and languages. Saji et al. [ 2025 ] study multilingual reasoning in language reasoning models on text-only benchmarks (MGSM, GPQA), finding that models default to English reasoning chains re gardless of prompt language. This paper extends this line of inquiry to the visual domain, where images may partly compensate for weak text comprehension. Indian NLP resour ces. IndicT rans2 [ Gala et al. , 2023 ] provides open-source neural machine translation for all 22 scheduled Indian languages and outperforms Google T ranslate and NLLB-54B. I use it as the primary translation system, complemented by the broader Indic NLP infrastructure described by Doddapaneni et al. [ 2023 ]. 3 Methodology 3.1 Dataset Construction I assemble 980 visual reasoning questions from three sources: • MathV ista [ Lu et al. , 2024 ]: 400 questions from the testmini split covering geometry , algebra, statistics, chart interpretation, and word problems. Language-independent pattern-matching items (e.g., IQ-test sequences) were excluded. • ScienceQA [ Lu et al. , 2022 ]: 400 natural-science questions with images, spanning K-12 physics, chemistry , and biology . • MMMU [ Y ue et al. , 2024a ]: 180 STEM questions at the college level (mathematics, physics, engineering). Each question is paired with an image that remains identical across languages; only the text changes. 3 T able 1: T arget languages with script, family , and approximate L1 speaker population. Language Code Script Family L1 (M) English en Latin — — Hindi hi Dev anagari Indo-Aryan 340 Bengali bn Bengali Indo-Aryan 265 Marathi mr De vanagari Indo-Aryan 83 T amil ta T amil Dravidian 75 T elugu te T elugu Dravidian 75 Kannada kn Kannada Dravidian 44 T able 2: Inter-translator agreement between IndicT rans2 and Gemini 2.0 Flash on 50 random samples per language. hi ta bn te kn mr Agreement 0.844 0.811 0.806 0.803 0.791 0.791 3.2 Languages I select six Indian languages spanning tw o major families and fi ve scripts (T able 1 ). Hindi and Marathi share the De vanag ari script but dif fer as languages, enabling us to separate vocabulary and training-data ef fects from script-le vel ef fects. T amil and Kannada share the Dra vidian family b ut use distinct scripts, providing a complementary control. 3.3 T ranslation All 980 questions are translated into each tar get language with IndicT rans2 [ Gala et al. , 2023 ]. Mathemat- ical symbols ( π , √ , = ), Arabic numerals, SI units, and answer labels (A/B/C/D) are preserved, consistent with con v entions in Indian STEM education. T echnical terms are translated by IndicTrans2; instruction text is fully translated per language to test multilingual instruction follo wing. T ranslation quality is verified by independently translating 50 random samples per language with Gemini 2.0 Flash and computing inter-translator agreement (T able 2 ). Scores range from 0.79 (Kannada, Marathi) to 0.84 (Hindi), all abov e a 0.65 acceptance threshold. 3.4 Models Eight VLMs are ev aluated (T able 3 ). Three open-source models (Qwen2.5-VL-7B, InternVL2.5-8B, A ya-V ision-8B) are served with vLLM on an AMD MI300X 192 GB GPU in bfloat16. Cloud models are accessed through Google AI (Gemma 3-27B), DeepInfra (Qwen2.5-VL-32B, Qwen3-VL-30B, Llama-4- Mav erick in FP8), and OpenAI (GPT -4o). T wo ablations use Qwen2.5-VL-7B as a representativ e open-source model: (i) No-image , where the image is removed and only the question text is pro vided; (ii) Chain-of-thought (CoT), where “Think step by step” is appended to the prompt in the target language. 3.5 Evaluation Protocol Each model recei ves the translated question, the original image, and a language-specific instruction asking for a letter answer (A–D) for MCQs or a number for free-form questions. T emperature is set to 0 for reproducibility . For multiple-choice questions (762 of 980), I extract the first standalone letter A–D from the response, also recognizing De v anagari and other script-specific option labels. For free-form numerical questions (218 of 980), script-specific numerals (De v anagari, Bengali, T amil, T elugu, Kannada) are con verted to 4 T able 3: Models ev aluated. “Overall” is the macro-a verage accurac y across all se ven languages. Model Access Params Overall (%) GPT -4o [ OpenAI , 2024 ] OpenAI API — 44.8 Qwen3-VL-30B [ Bai et al. , 2025a ] DeepInfra 30B 43.5 Gemma 3-27B [ Gemma T eam, Google DeepMind , 2025 ] Google AI 27B 43.4 Llama-4-Mav erick [ Meta AI , 2025 ] DeepInfra 17B × 128E 42.6 Qwen2.5-VL-32B [ Bai et al. , 2025b ] DeepInfra 32B 37.0 Qwen2.5-VL-7B [ Bai et al. , 2025b ] MI300X (vLLM) 7B 33.5 InternVL2.5-8B [ Chen et al. , 2024 ] MI300X (vLLM) 8B 28.1 A ya-V ision-8B [ Dash et al. , 2025 ] MI300X (vLLM) 8B 23.3 Arabic digits and a ± 5% tolerance is applied. Extraction failure rates are non-trivial for some models (33.9% for A ya-V ision-8B, 25.0% for InternVL2.5-8B); reported accuracies for these models should be interpreted as lo wer bounds. All accuracies are accompanied by 95% bootstrap confidence interv als ( N =2 , 000 resamples). P air- wise comparisons between English and each Indian language use McNemar’ s test; all are significant at p < 0 . 001 . 4 Results 4.1 Overall Accuracy T able 4 presents the full results. GPT -4o achieves the highest av erage accuracy on Indian languages (43.2%), while Gemma 3-27B, despite lo wer English accuracy , drops only 9.8 pp —the best language robustness among all models tested. At the other extreme, Qwen3-VL-30B posts the highest English accuracy (64.9%) but loses 24.9 pp when switching to Indian languages, indicating that strong English performance does not automatically generalize cross-lingually . Among the 7–8B open-source models, accuracy drops range from 20.4 pp (InternVL2.5-8B) to 21.9 pp (A ya-V ision-8B). Refusal rates remain below 3% across all models and languages, so the accuracy losses reflect genuine reasoning failures rather than model refusals. 4.2 Language Family Effect T able 5 and Figure 2 disaggregate the accuracy drop by language family and language respectively . Dravidian languages (T amil, T elugu, Kannada) consistently lose more accuracy than Indo-Aryan (Hindi, Bengali, Marathi). The gap is modest for GPT -4o (1.7 pp ) and essentially absent for Gemma 3-27B (0.1 pp ), but reaches 13.2 pp for A ya-V ision-8B, a model whose pretraining e xplicitly co vers sev eral Indian languages. A model trained on Indian languages can still exhibit a 13 pp family gap, suggesting that the bottleneck lies in reasoning transfer rather than surface-le vel language co v erage. 5 T able 4: Accuracy (%) per model and language. 95% bootstrap CIs are shown for the English column; all non-English comparisons are significant at p < 0 . 001 (McNemar’ s test). “Drop” is the difference between English accuracy and the mean accurac y across the six Indian languages. Model en hi ta te bn kn mr Drop Qwen3-VL-30B 64.9 [61.9–68.0] 44.1 41.1 36.5 43.3 38.7 36.1 24.9 pp Llama-4-Mav erick 55.4 [52.2–58.6] 43.4 34.9 38.6 42.7 41.6 41.9 14.9 pp GPT -4o 54.5 [51.4–57.6] 44.6 40.5 43.0 44.5 43.7 43.2 11.3 pp Gemma 3-27B 51.8 [48.9–55.0] 42.0 41.9 42.5 41.9 41.3 42.2 9.8 pp Qwen2.5-VL-7B 51.3 [48.2–54.4] 34.2 28.7 26.9 32.7 30.6 30.0 20.8 pp Qwen2.5-VL-32B 50.3 [47.1–53.5] 34.1 34.2 33.2 39.1 32.5 35.6 15.5 pp InternVL2.5-8B 45.6 [42.5–48.9] 29.8 22.4 22.9 24.9 23.6 27.9 20.4 pp A ya-V ision-8B 42.0 [38.8–45.0] 33.6 14.9 11.6 21.7 14.2 25.1 21.9 pp Ablations (Qwen2.5-VL-7B) No-image 35.8 26.0 19.0 20.7 24.5 23.7 25.1 12.7 pp Chain-of-thought 49.5 25.0 29.7 22.8 18.3 19.2 33.3 24.8 pp T able 5: Accuracy drop from English ( pp ), a veraged within each language f amily . “Gap” is Dravidian drop minus Indo-Aryan drop. Model Indo-Aryan Dravidian Gap A ya-V ision-8B 15.2 28.5 +13.2 InternVL2.5-8B 18.1 22.7 +4.6 Llama-4-Mav erick 12.8 17.0 +4.3 Qwen2.5-VL-7B 19.1 22.6 +3.5 Qwen2.5-VL-32B 14.1 17.0 +3.0 Qwen3-VL-30B 23.7 26.1 +2.4 GPT -4o 10.4 12.1 +1.7 Gemma 3-27B 9.8 9.9 ∼ 0 Hindi Marathi Bengali T amil T elugu K annada Language 0 5 10 15 20 25 A ccuracy Dr op (per centage points) 13.8% 16.7% 15.7% 19.7% 20.1% 18.7% A verage A ccuracy Dr op fr om English (A cr oss All Models) Indo - Aryan Dravidian Figure 2: A verage accuracy drop from English, per language, av eraged across models. Dravidian languages (ta, te, kn) consistently suf fer larger drops than Indo-Aryan (hi, bn, mr). 6 T able 6: Accuracy drop ( pp) from English to av erage Indian-language accuracy , by source dataset. Model MathVista ScienceQA MMMU GPT -4o 17.2 7.0 7.3 Gemma 3-27B 24.3 − 2.7 5.4 Llama-4-Mav erick 15.2 15.7 12.3 Qwen3-VL-30B 29.3 21.5 22.8 Qwen2.5-VL-32B 10.2 23.2 10.3 Qwen2.5-VL-7B 20.5 24.8 12.9 InternVL2.5-8B 8.1 36.8 11.4 A ya-V ision-8B 9.3 38.4 13.1 Script v ersus language. Hindi and Marathi both use De vanagari, yet Marathi drops an a verage of 3.0 pp more than Hindi across models. The gap persists ev en for A ya-V ision-8B, where Marathi accuracy is 8.5 pp lo wer than Hindi despite sharing the same script. T raining data volume, rather than script encoding, appears to be the dominant factor . 4.3 Per -Dataset Patter ns T able 6 and Figure 3 break accuracy drops down by source dataset. T wo patterns stand out. First, MathV ista produces the largest drops for high-performing models (Qwen3-VL-30B loses 29.3 pp ), consistent with math word problems requiring precise language comprehension. Second, Gemma 3-27B sho ws a ne gative ScienceQA drop ( − 2.7 pp ): its Indian-language accurac y slightly exceeds English. A plausible explanation is that ScienceQA ’ s biology and physics diagrams carry enough visual signal for the correct answer regardless of question language, and Gemma’ s post-training alignment is particularly ef fectiv e at e xploiting this. At the other end, A ya-V ision-8B and InternVL2.5-8B lose 36–38 pp on ScienceQA, pointing to hea vy reliance on English science vocab ulary . GPT -4o Gemma3-27B Llama4-Mav Qwen3-30B Qwen2.5-32B Qwen2.5-7B Inter nVL -8B A ya- V -8B 0 20 40 60 80 100 A ccuracy (%) MathV ista English Indian avg GPT -4o Gemma3-27B Llama4-Mav Qwen3-30B Qwen2.5-32B Qwen2.5-7B Inter nVL -8B A ya- V -8B 0 20 40 60 80 100 A ccuracy (%) ScienceQA English Indian avg GPT -4o Gemma3-27B Llama4-Mav Qwen3-30B Qwen2.5-32B Qwen2.5-7B Inter nVL -8B A ya- V -8B 0 20 40 60 80 100 A ccuracy (%) MMMU English Indian avg Per-Dataset Accuracy: English vs. A verage Indian Languages Figure 3: Per -dataset accuracy for English versus the a v erage across Indian languages. MathV ista shows the largest drops for most models. Gemma 3-27B achiev es a negati ve drop on ScienceQA (Indian languages outperform English). Figure 4 complements the above by sho wing per-language accuracy across all three datasets simulta- neously . Hindi and Bengali consistently outperform Dravidian languages on MathV ista and MMMU, while the gap narrows on ScienceQA where diagram-lev el visual signals partially compensate for weaker language understanding. 7 MathV ista ScienceQA MMMU 20 40 60 80 100 R easoning T ype P erfor mance by Language English Hindi T amil K annada Figure 4: Radar chart of accuracy per source dataset for each language (av eraged over all models). English sets the outer reference; Dra vidian languages (T amil, T elugu, Kannada) cluster closer to the centre on MathV ista and MMMU, confirming that reasoning-heavy tasks suf fer the most. 4.4 Cross-Lingual Consistency For each question, I check whether the model produces the same extracted answer across all languages for which a valid answer w as obtained (restricting to questions with at least four successful extractions out of se ven). Observed agreement rates range from 67.1% (A ya-V ision-8B) to 80.8% (Llama-4-Ma verick), well abov e the near-zero le vel expected from independent random guessing on four -choice MCQs (Figure 5 ). All models engage in non-trivial cross-lingual reasoning, but the least consistent models are the same ones with the highest accurac y drops, suggesting that language-dependent instability and accuracy loss share a common cause. 8 GPT -4o Gemma3-27B Llama4-Mav Qwen3-30B Qwen2.5-32B Qwen2.5-7B Inter nVL -8B A ya- V -8B 0 20 40 60 80 100 Cr oss-Lingual Consistency (%) 80.2% 79.4% 80.8% 78.3% 72.5% 73.8% 71.2% 67.1% Cross-Lingual Consistency: % Questions with Same Answer Across All 7 Languages R andom guess (4-choice MCQ, 25%) Figure 5: Cross-lingual consistency: percentage of questions receiving the same extracted answer across all languages with v alid extractions ( ≥ 4 of 7). 4.5 Ablation: Image Removal and Chain-of-Thought Figure 6 sho ws per-language accurac y for the three Qwen2.5-VL-7B v ariants. English Hindi T amil T elugu Bengali K annada Marathi 0 10 20 30 40 50 60 70 A ccuracy (%) Qwen2.5- VL-7B Ablation: Standard vs. No-Image vs. Chain-of - Thought Standar d No -Image (te xt- only) Chain- of - Thought Figure 6: Ablation results for Qwen2.5-VL-7B. Removing the image hurts all languages; chain-of-thought hurts most Indian languages while leaving English roughly unchanged. Image remov al. Stripping the image from the prompt reduces English accuracy by 15.5 pp (from 51.3% to 35.8%). Indian-language accuracy drops less, between 4.9 pp (Marathi) and 9.7 pp (T amil). The asymmetry is informati ve: models e xtract more from the image when the y understand the text well; when text comprehension is weaker (as in Indian languages), the image is already under-utilized, so remo ving it costs less. 9 Chain-of-thought. Appending “Think step by step” barely changes English accuracy ( − 1.8 pp ) but se verely de grades Bengali ( − 14.4 pp ), Kannada ( − 11.4 pp ), and Hindi ( − 9.2 pp ). An interesting e xcep- tion is Marathi, where CoT actually impr oves accuracy by 3.3 pp , possibly reflecting stronger De v anagari- script training data for reasoning tasks. In general, the model cannot sustain coherent step-by-step reasoning in languages where it lacks fluency; forcing it to do so produces garbled intermediate steps that corrupt the final answer . This mirrors the te xt-only finding of Shi et al. [ 2023 ] that English CoT outperforms nati ve-language CoT , and extends it to visual reasoning. 4.6 Effect of Scale Comparing Qwen2.5-VL-7B with Qwen2.5-VL-32B (same architecture family) shows that the larger model gains 4.3 pp on Indian languages while losing 1.0 pp on English. The English-to-Indian-language drop shrinks from 20.8 pp (7B) to 15.5 pp (32B): a meaningful reduction, b ut f ar from closing the gap. Scale appears to broaden linguistic co verage without fundamentally impro ving cross-lingual reasoning transfer . 5 Analysis Figure 7 plots each model’ s Indo-Aryan drop against its Dravidian drop; all points lie above the diagonal, confirming that Dravidian languages are consistently harder . 0 5 10 15 20 25 30 A ccuracy Dr op: Indo - Aryan (hi/mr/bn) pp 0 5 10 15 20 25 30 A ccuracy Dr op: Dravidian (ta/te/kn) pp GPT -4o Gemma3-27B Llama4-Mav Qwen3-30B Qwen2.5-32B Qwen2.5-7B Inter nVL -8B A ya- V -8B Indo-Aryan vs. Dravidian Accuracy Drop (above diagonal = Dravidian harder) GPT -4o Gemma3-27B Llama4-Mav Qwen3-30B Qwen2.5-32B Qwen2.5-7B Inter nVL -8B A ya- V -8B Dravidian = Indo - Aryan Figure 7: Accuracy drop ( pp ) from English, Indo-Aryan vs. Dravidian. Points abo ve the diagonal mean Dravidian languages are harder . Gemma 3-27B is the only model near the diagonal. 10 5.1 English T oken Leak T o probe for covert English reasoning, I measure the fraction of ≥ 3 -letter English words in non-English responses (Figure 8 ). Llama-4-Ma verick stands out with 32% English tok ens on a verage across Indian- language responses. It e vidently reasons in English and switches to the target script only superficially , yet it achie ves the highest cross-lingual consistenc y (80.8%), meaning its English-leaked reasoning is often corr ect . At the opposite end, A ya-V ision-8B produces only 0.8% English tok ens b ut has the lo west consistency (67.1%). F aithfully generating in the target script does not entail correct reasoning. GPT -4o Gemma3-27B Llama4-Mav Qwen3-30B Qwen2.5-32B Qwen2.5-7B Inter nVL -8B A ya- V -8B 0 5 10 15 20 25 30 35 English T ok en R atio (%) English T ok en Leak Rate in Non-English Responses Hindi T amil T elugu Bengali K annada Marathi Figure 8: English token leak in non-English responses (percentage of ≥ 3-letter English words). Llama-4- Mav erick code-switches hea vily at 32%. 5.2 Language Confusion I flag responses longer than 15 characters that contain no characters from the expected Unicode script range (Figure 9 ). Qwen3-VL-30B (1.2% confusion) and A ya-V ision-8B (2.5%) consistently respond in the target script. GPT -4o registers 45% apparent confusion, but this is largely an artifact of its terse single-letter MCQ answers (e.g., “B”), which contain no script-specific characters by construction. 11 Hindi Marathi Bengali T amil T elugu K annada GPT -4o Gemma3-27B Llama4-Mav Qwen3-30B Qwen2.5-32B Qwen2.5-7B Inter nVL -8B A ya- V -8B 65% 19% 11% 82% 67% 28% 44% 2% 1% 6% 2% 28% 32% 42% 36% 39% 42% 37% 1% 1% 1% 2% 0% 2% 13% 26% 4% 9% 57% 47% 63% 15% 1% 11% 1% 56% 18% 9% 9% 12% 19% 13% 0% 0% 1% 5% 7% 2% Language Confusion Rate: % Responses Missing T arget Script 0 10 20 30 40 50 60 70 80 Language Confusion (%) Figure 9: Language confusion rate: percentage of verbose ( > 15 character) responses containing no characters from the expected Unicode script range. 5.3 Response-Length Patterns Response length rev eals strategy differences across models (Figure 10 ). Llama-4-Mav erick generates uniformly verbose output ( ∼ 840–1,070 characters) regardless of language; it always writes out full reasoning. A ya-V ision-8B produces long er responses in Indian languages (310–514 characters) than in English (123 characters), possibly reflecting lo wer confidence and compensatory over -generation. InternVL2.5-8B sho ws the rev erse: 6-character English responses (single-letter MCQ answers) but full-sentence Indian-language output, which partly explains its ele v ated confusion rate. 12 GPT -4o Gemma3-27B Llama4-Mav Qwen3-30B Qwen2.5-32B Qwen2.5-7B Inter nVL -8B A ya- V -8B 0 5 10 15 20 25 30 35 R esponse L ength R atio (lang / English) Response Length Ratio per Language vs. English Same as English Hindi T amil T elugu Bengali K annada Marathi Figure 10: Response length ratio relativ e to English. V alues abov e 1 indicate longer responses in the target language. 5.4 MCQ versus Free-F orm Questions Free-form numerical questions suffer disproportionately . Qwen2.5-VL-32B reaches 63.9% on MCQs but only 2.8% on free-form numerical questions in English: it generates extended reasoning without a clean final number , causing extraction f ailures. This 61 pp MCQ–free-form gap is the largest in the set and highlights that reported accuracy is heavily influenced by answer e xtraction quality . InternVL2.5-8B sho ws a similar pattern (52.5% MCQ vs. 21.6% free-form). 6 Discussion Educational implications. India’ s National Education Policy 2020 [ Ministry of Human Resource De velopment, Go vernment of India , 2020 ] mandates mother -tongue instruction through Grade 5. If the best av ailable VLM drops 11.3 pp on STEM reasoning when asked in an Indian language, and open-source alternati ves drop 15–25 pp , deploying these models as tutoring tools in re gional-medium schools risks systematically disadv antaging non-English students. The problem is most acute in Dravidian-medium schools, where drops reach 12–28 pp depending on model. Multilingual pretraining is not enough. A ya-V ision-8B is trained on 23 languages, se veral of them Indian. It faithfully responds in tar get scripts (0.8% English leak) and rarely refuses. Y et it drops 28.5 pp on Dravidian languages and has the lowest cross-lingual consistenc y . The model can produce T amil text; it cannot reason in T amil. Closing this gap likely requires multilingual r easoning fine-tuning on STEM-specific data, not simply broader pretraining corpora. Gemma 3-27B as an outlier . Gemma 3-27B is the only model with a near-zero Dravidian–Indo-Aryan gap (0.1 pp ) and actually gains accuracy on ScienceQA when switching from English. While the full training recipe is not public, this suggests that targeted multilingual alignment during post-training can ef fectiv ely equalize performance across language families, a concrete design goal for future models. Chain-of-thought: handle with care. Chain-of-thought prompting is widely assumed to be beneficial for reasoning tasks. The results sho w it is counterproductiv e in Indian languages, with the e xception of Marathi. The reasoning chain becomes a bottleneck when the model lacks the fluency to sustain coherent 13 logic in the target language. Practitioners deploying VLMs in multilingual settings should avoid CoT prompting unless the model has been specifically tuned for non-English reasoning chains. The hidden-English pattern. Llama-4-Ma verick’ s combination of 32% English token leak and 80.8% cross-lingual consistency points to a strategy where the model reasons internally in English and translates at the surface. This yields correct MCQ answers b ut would lik ely break do wn for generati ve tasks such as tutoring, explanation, and feedback, which require fluent tar get-language output. 7 Limitations The translations rely on IndicT rans2 with Gemini 2.0 Flash cross-verification (agreement 0.79–0.84). Machine translation errors, particularly for technical terms, may introduce noise; nati ve-speaker validation on a larger sample would strengthen the benchmark. Only 6 of India’ s 22 scheduled languages are covered; lo w-resource languages lik e Odia and Assamese, and the o ver 100 non-scheduled languages, remain untested. The source benchmarks were designed for English speakers and may carry cultural or curricular biases that af fect all translations equally . High extraction f ailure rates for A ya-V ision-8B (33.9%) and InternVL2.5-8B (25.0%) mean that these models’ true reasoning capability may be higher than the reported numbers. API-based models may be updated ov er time; the results reflect a snapshot taken in March 2026. 8 Conclusion This audit—980 questions, sev en languages, eight models, 68,600 inference records—documents a systematic 9.8–25 pp accuracy penalty when VLMs reason in Indian languages instead of English. Dravidian l anguages are consistently harder than Indo-Aryan. Chain-of-thought prompting backfires in most Indian languages; multilingual pretraining alone does not transfer reasoning; and scale narrows b ut does not close the gap. These findings argue for mandatory multilingual reasoning ev aluation before VLMs are deployed in Indian educational settings. The translated benchmark, model outputs, and e valuation code are publicly a v ailable at https: //github.com/QuantumByte- 01/multilingual- vlm- reasoning- audit and on Hug- gingFace. 2 Acknowledgments Open-source model inference was conducted on an AMD Instinct MI300X GPU with 192 GB HBM3 memory . Cloud inference used the Google AI, DeepInfra, and OpenAI APIs. Refer ences Kabir Ahuja, Harshita Diddee, Rishav Hada, Millicent Ochieng, Krithika Ramesh, Prachi Jain, Akshay Nambi, T anuja Ganu, Sameer Segal, Maxamed Axmed, Kalika Bali, and Sunayana Sitaram. MEGA: Multilingual e valuation of generati ve AI. In Pr oceedings of EMNLP , 2023. Jesse Atuhurra et al. VLURes: Benchmarking VLM visual and linguistic understanding in low-resource languages. arXiv pr eprint arXiv:2510.12845 , 2025. Shuai Bai, Y uxuan Cai, Ruizhe Chen, et al. Qwen3-VL technical report. arXiv pr eprint arXiv:2511.21631 , 2025a. 2 https://huggingface.co/datasets/Swastikr/multilingual- vlm- reasoning 14 Shuai Bai et al. Qwen2.5-VL technical report. arXiv pr eprint arXiv:2502.13923 , 2025b. Zhe Chen, Jiannan W u, W enhai W ang, W eijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, T ong Lu, Y u Qiao, and Jifeng Dai. InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Pr oceedings of CVPR , 2024. Saurabh Dash, Y iyang Nan, John Dang, Arash Ahmadian, et al. A ya vision: Adv ancing the frontier of multilingual multimodality . arXiv pr eprint arXiv:2505.08751 , 2025. Sumanth Doddapaneni et al. T o wards lea ving no Indic language behind: Building monolingual corpora, benchmark and models for Indic languages. In Pr oceedings of ACL , 2023. Ali Faraz et al. IndicV isionBench: Benchmarking cultural and multilingual understanding in VLMs. arXiv pr eprint arXiv:2511.04727 , 2025. Jay Gala, Pranjal A. Chitale, Ragha v an, A K, V arun Gumma, Sumanth Doddapaneni, Aswanth Kumar , Janki Nawale, Anupama Sujatha, Ratish Puduppully , V iv ek Raghav an, Pratyush Kumar , Mitesh M. Khapra, Raj Dabre, and Anoop Kunchukuttan. IndicT rans2: T o wards high-quality and accessible machine translation models for all 22 scheduled Indian languages. T ransactions on Machine Learning Resear c h , 2023. Gemma T eam, Google DeepMind. Gemma 3 technical report. arXiv pr eprint arXiv:2503.19786 , 2025. Shaharukh Khan et al. Chitrarth: Bridging vision and language for a billion people. arXiv pr eprint arXiv:2502.15392 , 2025. Fangyu Liu, Emanuele Bugliarello, Edoardo Maria Ponti, Siv a Reddy , Nigel Collier , and Desmond Elliott. V isually grounded reasoning across languages and cultures. In Pr oceedings of EMNLP , 2021. Pan Lu, Swaroop Mishra, T ony Xia, Liang Qiu, Kai-W ei Chang, Song-Chun Zhu, Oyvind T afjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. In Advances in Neural Information Pr ocessing Systems , 2022. Pan Lu, Hritik Bansal, T ony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-W ei Chang, Michel Galley , and Jianfeng Gao. MathV ista: Ev aluating mathematical reasoning of foundation models in visual contexts. In Pr oceedings of ICLR , 2024. Arijit Maji et al. DRISHTIKON: A multimodal multilingual benchmark for testing language models’ understanding on Indian culture. In Pr oceedings of the MAINS W orkshop at EMNLP , 2025. Meta AI. The Llama 4 herd: The beginning of a new era of nati vely multimodal AI innov ation. https://ai.meta.com/blog/llama- 4- multimodal- intelligence/ , 2025. Ministry of Human Resource Development, Gov ernment of India. National education policy 2020. https://www.education.gov.in/sites/upload_files/mhrd/files/NEP_ Final_English_0.pdf , 2020. OpenAI. GPT -4o system card. T echnical report, 2024. Jonas Pfeif fer , Gregor Geigle, Aishw arya Kamath, Jan-Martin Steitz, Stefan Roth, Ivan V uli ´ c, and Iryna Gure vych. xGQA: Cross-lingual visual question answering. In F indings of ACL , 2022. David Romero et al. CVQA: Culturally-di verse multilingual visual question answering benchmark. In Advances in Neural Information Pr ocessing Systems , 2024. Alan Saji, Raj Dabre, Anoop K unchukuttan, and Ratish Puduppully . The reasoning lingua franca: A double-edged sword for multilingual AI. arXiv pr eprint arXiv:2510.20647 , 2025. 15 Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi W ang, Suraj Sriv ats, Soroush V osoughi, Hyung W on Chung, Y i T ay , Sebastian Ruder , Denn y Zhou, Dipanjan Das, and Jason W ei. Language models are multilingual chain-of-thought reasoners. In Pr oceedings of ICLR , 2023. Harshul Raj Surana et al. VIRAASA T: T raversing no vel paths for Indian cultural reasoning. arXiv pr eprint arXiv:2602.18429 , 2026. Ashmal V ayani et al. All languages matter: Ev aluating LMMs on culturally di verse 100 languages. arXiv pr eprint arXiv:2411.16508 , 2024. K e W ang et al. Measuring multimodal mathematical reasoning with MA TH-V ision dataset. arXiv pr eprint arXiv:2402.14804 , 2024. Xiang Y ue, Y uansheng Ni, Kai Zhang, T ian yu Zheng, Ruoqi Liu, Ge Zhang, Samuel Ste vens, Dongfu Jiang, W eiming Ren, Y uxuan Sun, et al. MMMU: A massiv e multi-discipline multimodal understanding and reasoning benchmark for expert A GI. In Pr oceedings of CVPR , 2024a. Xiang Y ue et al. Pangea: A fully open multilingual multimodal LLM for 39 languages. arXiv preprint arXiv:2410.16153 , 2024b. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment