다국어 VLM의 시각적 추론 능력 인도 언어에서 균등할까
본 논문은 MathVista, ScienceQA, MMMU에서 추출한 980개의 시각적 추론 문제를 힌디어, 타밀어, 텔루구어, 벵골어, 칸나다어, 마라티어로 번역하고, 8개의 최신 비전‑언어 모델을 평가한다. 영어 대비 9.8~25 pp의 정확도 감소가 관찰되며, 특히 드라비다어군이 인도-아리안어군보다 최대 13.2 pp 더 큰 손실을 보인다. 체인‑오브‑쓰(Chain‑of‑Thought) 프롬프트는 벵골어와 칸나다어에서 오히려 성능을 저하시…
저자: Swastik R
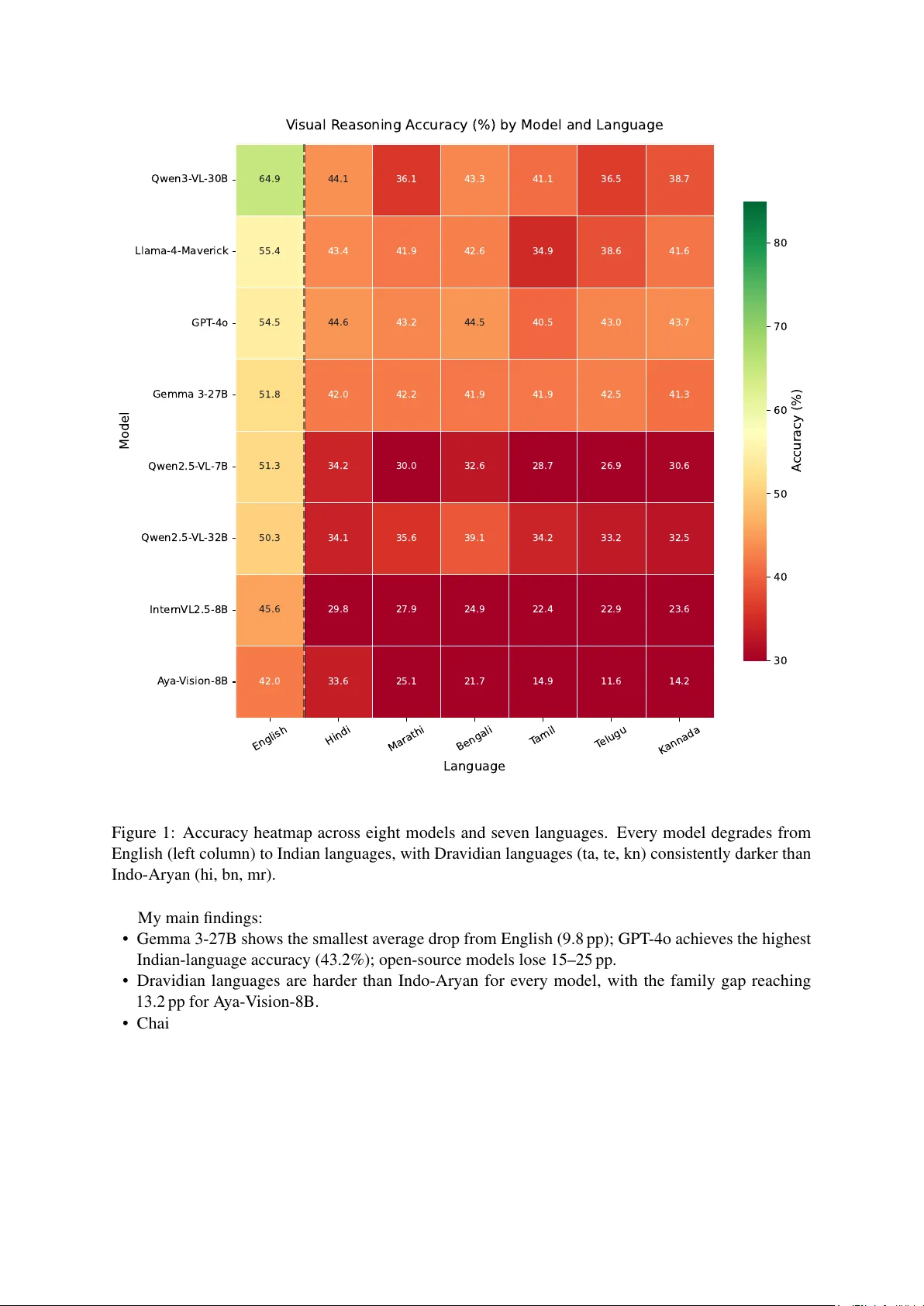
본 논문은 인도 교육 현장에서 시각‑언어 모델(VLM)이 지역 언어로 수학·과학·공간 추론을 수행할 수 있는지를 체계적으로 검증한다. 연구자는 MathVista(400문제), ScienceQA(400문제), MMMU(180문제)에서 총 980개의 시각적 추론 질문을 선정하고, 이미지 자체는 변하지 않으며 질문 텍스트만을 힌디어, 마라티어, 벵골어, 타밀어, 텔루구어, 칸나다어로 번역했다. 번역은 최신 인도어 NMT 시스템 IndicTrans2를 사용했으며, Gemini 2.0 Flash와의 50개 샘플 교차 검증을 통해 0.79~0.84의 높은 상호 일치를 확보했다.
평가에 사용된 VLM은 8가지이며, 오픈소스 모델(Qwen2.5‑VL‑7B, InternVL2.5‑8B, Aya‑Vision‑8B, Qwen3‑VL‑30B, Qwen2.5‑VL‑32B, Llama‑4‑Maverick, Gemma‑3‑27B)과 클라우드 기반 GPT‑4o를 포함한다. 각 모델은 동일한 프롬프트(온도 0, MCQ는 A‑D, 자유형은 숫자)로 모든 언어에 대해 실행되었으며, 총 68,600개의 추론 기록이 수집되었다.
주요 실험 결과는 다음과 같다.
1. **전체 정확도 감소**: 영어 대비 평균 정확도 감소폭은 모델마다 9.8 pp(Gemma‑3‑27B)에서 24.9 pp(GPT‑4o)까지 다양했다. 특히 Qwen3‑VL‑30B는 영어에서 64.9 %를 기록했지만 인도 언어에서는 36.1 %로 급락했다.
2. **언어군 차이**: 드라비다어(타밀, 텔루구, 칸나다)에서는 인도‑아리안어(힌디, 벵골어, 마라티)보다 평균 4.6~13.2 pp 더 큰 정확도 감소가 관찰되었다. Aya‑Vision‑8B와 같이 다국어 사전학습을 수행한 모델에서도 드라비다어군에서 28.5 pp의 큰 손실이 나타났다.
3. **체인‑오브‑쓰(CoT) 프롬프트**: 영어에서는 CoT가 성능에 큰 영향을 주지 않았지만, 벵골어와 칸나다어에서는 각각 -14.4 pp, -11.4 pp의 급격한 감소가 발생했다. 이는 현재 VLM의 추론 흐름이 영어에 고정돼 있어, 다른 언어로 전환 시 논리적 연결이 깨지는 현상을 보여준다.
4. **이미지 제거(ablation)**: 이미지 없이 텍스트만 제공했을 때 영어 정확도가 15.5 pp 감소했지만, 인도 언어에서는 4.9~9.7 pp 감소에 그쳤다. 이는 텍스트 이해도가 낮은 경우 모델이 시각 정보를 충분히 활용하지 못한다는 점을 시사한다.
5. **모델 규모 효과**: Qwen2.5‑VL 시리즈에서 7B→32B로 스케일업했을 때 인도 언어 정확도가 평균 4.3 pp 상승했지만, 영어에서는 1 pp 감소했다. 즉, 파라미터 규모가 언어 커버리지는 확대하지만, 복잡한 STEM 추론 능력은 자동으로 향상되지 않는다.
6. **스크립트 vs 언어**: 힌디어와 마라티어는 동일한 데바나가리 스크립트를 사용하지만, 마라티어는 힌디어보다 평균 3 pp 더 큰 정확도 감소를 보였다. 이는 스크립트보다 학습 데이터 양과 어휘 다양성이 성능에 더 큰 영향을 미친다.
7. **데이터셋별 특성**: MathVista는 고난이도 수학 문제로, 대부분의 모델에서 큰 정확도 감소를 보였다. 반면, Gemma‑3‑27B는 ScienceQA에서 -2.7 pp의 마이너스 감소(즉, 인도 언어가 영어보다 약간 우수) 를 기록했으며, 이는 시각적 다이어그램이 충분히 강력한 신호를 제공하고, 모델의 정렬 단계가 이를 잘 활용했기 때문으로 해석된다.
8. **다국어 일관성**: 질문당 최소 4개 언어에서 동일 답을 도출한 비율은 67.1 %(Aya‑Vision‑8B)에서 80.8 %(Llama‑4‑Maverick)까지 다양했으며, 정확도 손실이 큰 모델일수록 일관성도 낮았다.
연구자는 번역된 벤치마크와 68,600개의 모델 출력 데이터를 공개함으로써, 향후 인도 언어에 특화된 VLM 개발 및 평가를 위한 기반을 제공한다. 논문의 결론은 현재 다국어 VLM이 영어 중심 설계에 크게 의존하고 있으며, 특히 드라비다어군과 같은 언어에서는 시각‑언어 통합 추론 능력이 현저히 낮다는 점이다. 교육용 자동 튜터링 시스템을 실제 현장에 적용하려면, 언어별 사전 학습 데이터 확대, 스크립트·언어 특화 토크나이저, 그리고 영어‑전용 CoT를 넘어서는 다언어 추론 체계가 필요하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기