Beyond Static Visual Tokens: Structured Sequential Visual Chain-of-Thought Reasoning
Current multimodal LLMs encode images as static visual prefixes and rely on text-based reasoning, lacking goal-driven and adaptive visual access. Inspired by human visual perception-where attention is selectively and sequentially shifted from the mos…
Authors: Guangfu Guo, Xiaoqian Lu, Yue Feng
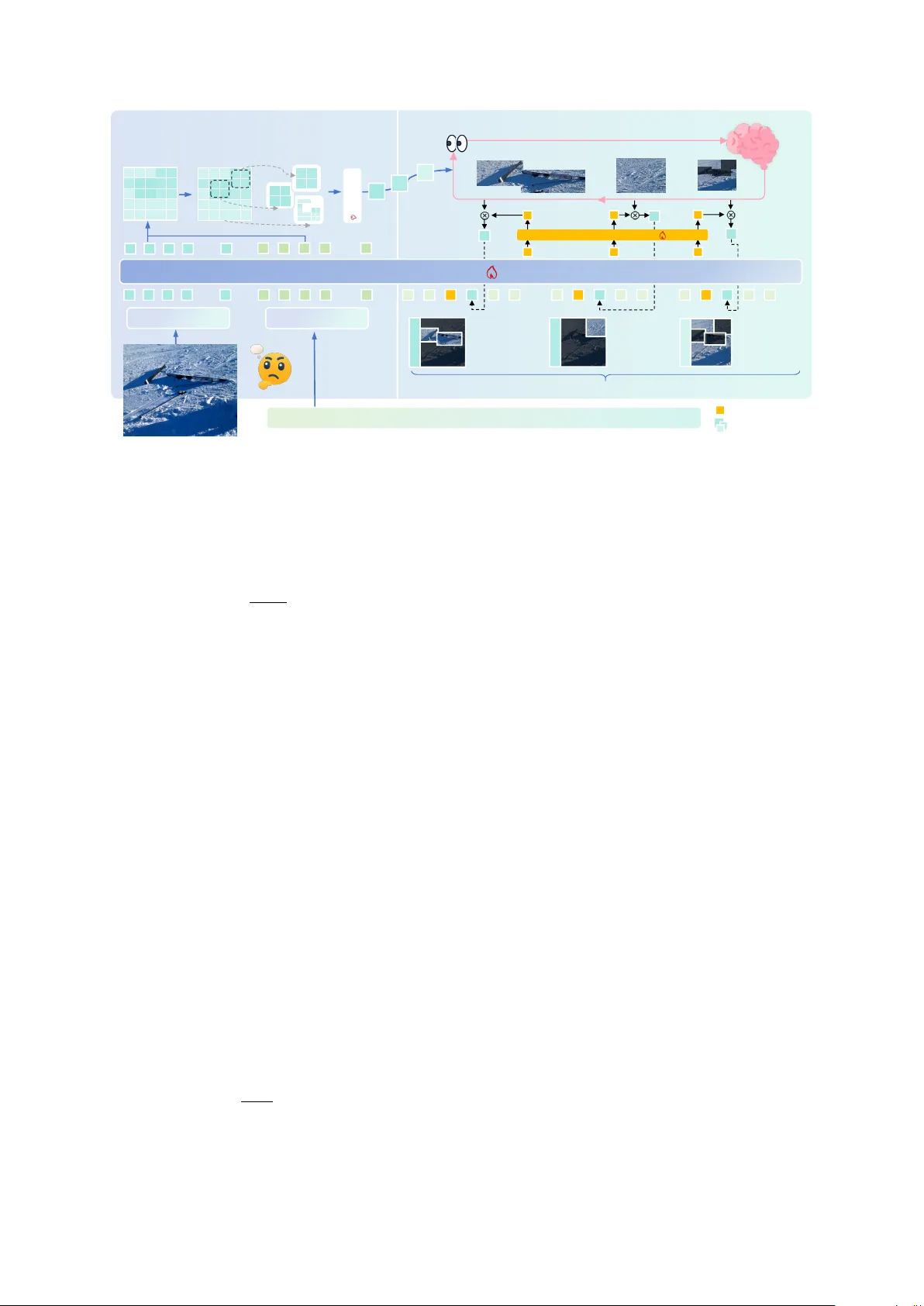
Bey ond Static V isual T okens: Structur ed Sequential V isual Chain-of-Thought Reasoning Guangfu Guo 1 , 3 * † fs23990@bristol.ac.uk Xiaoqian Lu 3 * fd23007@bristol.ac.uk Y ue F eng 2 y.feng.6@bham.ac.uk Mingming Sun 1 sunmingming@bimsa.cn 1 Beijing Institute of Mathematical Sciences and Applications 2 Uni versity of Birmingham 3 Uni versity of Bristol Abstract Current multimodal LLMs encode images as static visual prefixes and rely on te xt-based reasoning, lacking goal-driv en and adaptive visual access. Inspired by human visual perception—where attention is selectiv ely and sequentially shifted from the most informativ e regions to secondary cues—we propose Struc- tural Sequential V isual CoT (SSV -CoT) . First, a question-relev ant saliency map identifies and organizes k ey visual re gions, explicitly model- ing the spatial distrib ution of visual importance. Second, reasoning is performed following this discriminativ e order , inducing a curriculum- like semantic progression from primary to sec- ondary cues. This method is trained end-to-end, using text cot and answer supervision, without relying on region-le vel annotations or special- ized external tools. Experiments on div erse visual reasoning benchmarks sho w gains, v al- idating structured and sequential visual cogni- tion. 1 Introduction Despite rapid adv ances in multimodal LLMs ( Alayrac et al. , 2022 ; Liu et al. , 2023 ; Li et al. , 2023 ; Dai et al. , 2023 ), current systems still suf- fer from a fundamental limitation in ho w vision is integrated into reasoning. Most architectures en- code an image once into visual tokens or a global embedding and inject it into the LLM as static con- text ( Alayrac et al. , 2022 ; Li et al. , 2023 ; Liu et al. , 2023 ). Reasoning then unfolds purely in text space: as the chain-of-thought gro ws, the model increas- ingly ignores the image, cannot revisit or operate on visual content, and lacks goal-directed visual actions such as selecting, refocusing, or comparing regions. As a result, visual perception and language reasoning remain lar gely disentangled, and vision * Equal contribution. † This work was completed during an internship at the Beijing Institute of Mathematical Sciences and Applications. Step 1: Focu s on the sa lient region Ski equipment; large areas of sh ade → Snow-covered ski resort Step 2: Examin e other cue sunlight , n o falling snow → Sunny ANSWER: SUNNY ANSWER: SNOWY Reasoning: The image shows snow-cover ed ground with ski equipm ent scattered on it, which strongly suggests winter conditions. Sno w presence implies co ld temperatures, and there are no signs of fog, mi st, or overcast skies. The correct answer is: " It is cold and snowy. " What can you inf er about the curr ent weat her cond itions? MLLM-CoT Ignoring visual cues SSV-COT Inconsistent logic Figure 1: MLLM lacks visual analysis, while SSV inte grates cues through structured sequential reasoning to reach the cor- rect answer . functions as a passiv e prefix rather than an activ e part of cognition. Existing attempts to mitigate this gap face signif- icant drawbacks. External tool pipelines introduce cropping or detection b ut require complex orches- tration ( W u et al. , 2023 ; Chen et al. , 2023 ). Re gion- based supervision depends on costly annotations ( Lin et al. , 2022 ; Khan et al. , 2022 ). Generati ve visual-token or image synthesis is inefficient and poorly aligned with reasoning needs ( Esser et al. , 2021 ; Ding et al. , 2022 ). Latent-space alignment methods learn global correspondences yet provide no explicit visual access steps ( Radford et al. , 2021 ; Li et al. , 2023 ). Interlea ved chain-of-thought meth- ods re-inject visual tokens but enable passi ve re- attention ov er a large patch space, without model- ing where to look next ( Zhang et al. , 2024b ). None of these approaches support internal, sequential, goal-conditioned visual cognition. As illustrated in Fig. 1 , humans rarely solve vi- sual tasks by processing an entire scene uniformly . Instead, they first form a coarse global impression and then sequentially attend to task-rele vant re- gions as reasoning unfolds, a pattern well docu- mented in studies of human visual attention and e ye mov ements ( Y arbus , 1967 ; Itti et al. , 1998 ). In the example, the left approach (MLLM-CoT) fixates on the presence of sno w-cov ered ground and ski equipment, ignores critical cues such as strong sun- light and sharp shado ws, and arri v es at an incorrect conclusion. In contrast, the right approach (SSV - CoT) explicitly guides visual attention through a structured sequence: it first focuses on salient re- gions (e.g., ski equipment and shado ws) and then integrates additional cues (e.g., lighting conditions) to refine the hypothesis, ultimately reaching the correct answer . This comparison highlights a fun- damental limitation of existing multimodal large language models, which typically compress images into a fixed set of visual tokens and perform rea- soning purely in text space ( Alayrac et al. , 2022 ; Li et al. , 2023 ). While recent work on chain-of- thought reasoning has sho wn the benefits of e xplicit intermediate reasoning in language models ( W ei et al. , 2022 ), visual perception in current MLLMs remains largely passi ve and decoupled from the reasoning process. This disconnect between per- ception and cognition motiv ates our central ques- tion: can a model learn not only what to look at, but also when and in whic h order to look, driven directly by its ongoing reasoning? Inspired by human visual cognition, we propose SSV -CoT , a multimodal reasoning framew ork that couples structured visual representation with se- quential, goal-conditioned visual access. Giv en an image–question pair , SSV -CoT performs a single forward pass through a vision encoder and MLLM to construct a structured visual representation: a question-aw are saliency map is generated, bina- rized, and decomposed via connected component analysis, yielding a bank of candidate region em- beddings together with a global scene embedding. Conditioned on the e volving reasoning state, a vi- sual cognition policy scores candidate regions and selects one region (or the global embedding) at each step, injecting its embedding into the MLLM, so that reasoning unfolds as an interleaved process of visual querying and textual inference. T o re- flect human attentional control, SSV -CoT further incorporates an adapti ve stopping mechanism that dynamically determines whether to continue visual access, balancing evidence suf ficiency against re- dundant queries. The method is trained end-to-end from image– question—text cot-answer without g aze traces, bounding boxes, or e xternal tools: a heuristic su- pervised stage initializes the policy by imitating a question-conditioned salienc y ordering deri ved from the pretrained MLLM, follo wed by a GRPO reinforcement learning stage that optimizes visual selection using answer-le v el rew ards with a visual- budget regularizer . Overall, SSV -CoT replaces one-shot visual token injection with a structured, sequential, and adapti ve visual reasoning process aligned with human cogniti ve principles. Our main contributions are three-fold: • W e model visual access in multimodal rea- soning as a human-inspir ed, goal-conditioned process ov er structured visual units, rather than passi ve visual token injection. • W e propose a training frame work that learns visual selection order from task-lev el feed- back using text-cot and answer supervision, without region-le vel annotations. • W e introduce an adaptive, b udget-awar e vi- sual reasoning mechanism that decides when to continue or stop visual querying during chain-of-thought reasoning. 2 Related W ork 2.1 V isual Reasoning A broad class of methods augments MLLMs with external visual tools for cropping, detection, or region selection ( Schick et al. , 2023 ; Chen et al. , 2023 ; Y ang et al. , 2023 ; Aissi et al. , 2025 ), but these rely on complex, non-differentiable pipelines with manually designed actions decoupled from in- ternal reasoning. Another line of w ork introduces region-le vel supervision via bounding boxes, cap- tions, or grounding annotations ( Li et al. , 2022 ; Y ang et al. , 2022 ; Kamath et al. , 2021 ; Liu et al. , 2024a ), which improves controllability but requires costly labeling and exposes all regions upfront, pre- venting sequential selection. Related se gmentation- based or re gion-lev el abstractions, such as SAM- deri ved masks or region-le vel V iTs ( Kirillov et al. , 2023 ; Chen et al. , 2022 ; Ravi et al. , 2024 ), pro- vide structured features but are typically used as static inputs rather than a decision space. Overall, these approaches treat vision as fixed or e xternally controlled and do not enable internal, learnable, sequential visual cognition in MLLMs. 2.2 Interlea ved V isual Reasoning Interleav ed chain-of-thought methods reintroduce visual tokens during reasoning to alleviate image forgetting ( Zhang et al. , 2024b ; Chen et al. , 2025a ; Shao et al. , 2024 ; Zhang et al. , 2024a ; Li and Ma , 2025 ). While ef fectiv e for multi-hop visual question answering and chart reasoning, these ap- proaches repeatedly attend to the same static patch set and perform passiv e re-attention, without mod- eling where to look next or how visual access should ev olve over time. Relatedly , sequential perception models such as glimpse networks and acti ve-vision agents ( Mnih et al. , 2014 ; Ba et al. , 2015 ; Jaegle et al. , 2022 ) demonstrate the benefits of goal-conditioned sequential inspection, b ut typ- ically rely on small-scale vision architectures or reinforcement learning pipelines that do not scale to LLM-level multimodal reasoning. Overall, al- though recurrent and interleav ed methods improv e visual reasoning, they fail to support task-driv en, autoregressi ve visual access that is tightly coupled with the reasoning process, leaving dynamic visual cognition largely unaddressed. 3 Methodology 3.1 Overview Existing interleav ed reasoning methods repeatedly inject dense patch-le vel visual tokens, often caus- ing redundant signals and unstable reasoning. In contrast (Fig. 2 ), we first abstract the image into a compact set of question-conditioned visual re- gions and then perform sequential visual access ov er this region space. W e introduce SSV -CoT , which decomposes multimodal reasoning into two stages: (1) Structured V isual Cognition , con- structing salient question-aware region embeddings in a single forward pass; and (2) Sequential V isual Access , where a lightweight policy dynamically selects regions at each reasoning step. 3.2 Problem F ormulation and Infer ence Process Gi ven an image x and question q txt , the model gen- erates an answer by interlea ving textual reasoning with selectiv e visual access. V isual reasoning is for - mulated as a sequence of re gion-selection actions, where each step selects a re gion or terminates. At each reasoning step, the model queries a structured region embedding bank based on the current rea- soning state until a STOP action produces the final answer . Formally , while conv entional multimodal CoT methods generate purely text-based reasoning steps s (1) , s (2) , . . . , s ( K ) , y = LLM( V , T ) , (1) where V = v τ N τ =1 denotes static visual tok ens ex- tracted from the image and T is the input question, our approach explicitly models reasoning as an in- terleav ed decision process: a 1 , s (1) , a 2 , s (2) , . . . , a T , s ( T ) , y = LLM( E , T ) , (2) where each action a t selects a region embedding from the structured visual space E (or triggers STOP ), grounding each reasoning step in task- rele vant visual e vidence. 3.3 Structured V isual Cognition The first stage builds a compact, question- conditioned, and spatially structured image repre- sentation (Fig. 2 ), aiming to identify a small set of discriminati ve regions relev ant to the question with- out region-le vel supervision. Re gion geometry and base features come from the pretrained vision en- coder , while region importance is inferred through question-conditioned multimodal interactions. Question-conditioned saliency map. Gi ven an image x , we extract patch-le vel features h v = z ij using a vision encoder , where z ij denotes patch embeddings on an H × W grid. W e then run the pretrained MLLM on the image–question pair ( x, q txt ) and obtain the final textual representation q together with multimodal visual tokens ˜ z ij . Since they lie in a shared embedding space, we compute a question-conditioned saliency score for each patch via S ij = sim( q , ˜ z ij ) , (3) which reflects the rele v ance of each spatial loca- tion to the question. The saliency map is further normalized to improv e robustness: ˜ S ij = S ij − min( S ) max( S ) − min( S ) . (4) Binary masking and connected component anal- ysis. W e con vert the normalized salienc y map ˜ S into a binary mask by thresholding: M ( i, j ) = I ˜ S ij ≥ τ , (5) where τ is an adaptiv e threshold (e.g., Otsu’ s method) and I [ · ] denotes the indicator function. W e then apply connected-component analysis on M under an 8-neighborhood connectivity criterion to obtain a set of candidate regions {R k } . Each re- gion R k consists of a connected set of salient patch indices. Small components below a minimum area threshold are discarded to remov e spurious noise. Global complement embedding. T o ensure full image cov erage and provide rob ustness against im- perfect saliency estimation, all remaining patches Vision Encoder 1.Structured Visual Cognit ion Text Encoder Signal Token Human-Ins pired Visua l Cognitio n–Driven R easoning Sim_Scores 1.Questio n-aware Saliency Map Region-level Emb edding Bank Discriminant Scoring 2. Binary Mask Top-1 Step1: Focus o n salient region Ski equipment; large areas of shade ->Snow-covered ski resort Top-2 Step2: Examin e other c ue sunlight, no falling snow -> Sunny REMAIN Step3: Final check The images showed no signs of snowfall; the weather was sunny. 3. Connec ted Component Analysis ... ... ... ... ... ... ... Region Embeddi ng 2.Sequential Visual Access X X X X X X X X X X X X X X X X X Visual Projector X X X X X X X X X X X X X X X X X Hidden St ate Human-inspired Saliency-driven Region Perception Question: What can you infer about the current weather conditions? Signal Projector MLLM Sim_Scores Figure 2: Overvie w of the SSV -CoT framework. The model first constructs question-aw are structured visual regions, then performs sequential visual access during chain-of-thought reasoning to progressively inte grate visual evidence and generate the final answer . not cov ered by the T op- N regions are aggregated into a single global complement region: e global = 1 |I rest | X ( i,j ) ∈I rest z ij . (6) Discriminative r egion construction. Gi ven the connected components {R k } from the binary saliency mask, we treat each R k as a candidate vi- sual region and collect its patch-lev el visual tokens { v j } m j =1 . W e adopt an adapti ve token compression strategy with a fix ed budget n = 48 . If m ≤ n , all tokens are preserved and projected indi vidually via a visual projector . Otherwise, we select the top- n tokens by salienc y and apply k -means clustering to obtain representati ve re gion tokens. F ormally , the region representation is a set of projected tok ens: E k = g pro j { z ij | ( i, j ) ∈ R k } , k = 1 , . . . , N , (7) where g pro j ( · ) denotes a permutation-in variant re- gion projector that produces a fix ed-size set of re- gion tokens. After obtaining region embeddings, we quantify the discriminativ eness of each region by computing a region-le vel score as the average of the normal- ized saliency v alues within the region: ρ k = 1 |R k | X ( i,j ) ∈R k ˜ S ij . (8) This score measures the overall saliency consis- tency of the re gion with respect to the gi ven ques- tion. Regions are then ranked according to ρ k , and the T op- N highest-scoring regions are selected as discriminati ve local regions for subsequent sequen- tial visual reasoning. The final output of structured visual cognition is a compact region embedding bank: E = { e 1 , . . . , e N , e global } , (9) which provides a structured, question-conditioned abstraction of the image and serves as the candi- date visual space for subsequent sequential visual access. The structured region construction—including Otsu-based thresholding, binary masking, connected-component analysis, and T op-N selection—is treated as a deterministic, non- learnable preprocessing step performed at inference time, while all learnable parameters are confined to the projector , polic y module, and the MLLM. 3.4 Sequential V isual Access The second stage performs task-dri ven, step- aligned visual reasoning over the structured re gion space, corresponding to the right part of Figure 2 . Step-aware triggering . During chain-of-thought decoding, we treat the ne wline character \n as an implicit step boundary . Each time a ne wline is generated, the model completes a reasoning step and triggers a visual selection decision. Let h t ∈ R D L denote the final-layer hidden state of the ne wline token at step t . This hidden state summarizes the current reasoning context and serves as the query for visual selection. Similarity-based region scoring. At each rea- soning step t , we obtain the hidden state of the signal token h t ∈ R D L , which summarizes the cur- rent reasoning conte xt. W e first project the signal token through a signal projector: ˜ h t = W sig h t ∈ R D L . (10) Similarly , each region token embedding e k ∈ R D v is projected into the language space via a visual projector: ˜ e k = W vis e k ∈ R D L . (11) W e then compute similarity scores between the projected signal token and all projected region em- beddings: s t,k = sim( ˜ h t , ˜ e k ) , k ∈ { 1 , . . . , K } . (12) T o enable adaptiv e termination of visual access, we additionally include a learnable STOP embed- ding, which is scored in the same manner as re gion tokens. Policy and action execution. The policy head g θ induces a distribution o ver actions: π θ ( a t = k | s t ) = softmax( s t ) k , (13) where k ∈ { 1 , . . . , K , STOP } . If a t = k , the corre- sponding re gion embedding is injected to condition subsequent reasoning; if a t = STOP , the model produces the final answer without further visual input. 3.5 T raining Pr ocedure W e train SSV -CoT with a two-stage protocol using image–question–textual CoT –answer data, with- out any supervision on visual regions or access order . T o mitigate noisy early saliency estimates, we adopt a probabilistic curriculum that gradually shifts from random visual access to structured, dis- criminati ve re gion reasoning. The pipeline consists of (1) heuristic supervised fine-tuning to initialize the visual access policy aligned with te xtual chain- of-thought reasoning, and (2) GRPO-based rein- forcement learning to refine the visual cognition order using answer-le vel rew ards. Stage I: Heuristic Supervised Fine-T uning with Probabilistic Curriculum The goal of the first stage is to teach the model how to interlea ve textual reasoning with visual region access, rather than to learn a perfect visual selection strate gy . Howe v er , saliency maps estimated from a pretrained MLLM are often noisy at early training stages, which may lead to unstable optimization if directly used as supervision. T o stabilize training, we adopt a probabilistic curriculum learning strategy . Specifically , we de- fine a curriculum coef ficient λ e ∈ [0 , 1] for epoch e , which linearly increases from 0 to 1 during a warm-up period of E warm epochs: λ e = min 1 , e E warm . (14) For each training sample ( x, q txt , a gold ) , we con- struct a pseudo-expert region ordering as follo ws: W ith probability 1 − λ e , we sample re gions using a random region strate gy , which selects spatially contiguous image blocks independent of the ques- tion. W ith probability λ e , we apply the proposed question-conditioned discriminativ e region selec- tion method described in Section 3.3 , and rank the resulting regions by their salienc y scores. The resulting region sequence ( r 1 , . . . , r T ) is treated as a heuristic viewing trajectory . During SFT , we perform behavior cloning on the visual access polic y by minimizing the cross-entropy loss: L SFT = − T X t =1 log π θ ( a t = r t | s t ) , (15) where s t denotes the policy state at reasoning step t . This curriculum-guided SFT initializes the pol- icy with stable region–te xt interlea ving behav- ior while av oiding overfitting to unreliable early saliency signals. Stage II: GRPO-Based Reinfor cement Learn- ing with Mixed Exploration While the heuristic policy learned in Stage I provides a stable initial- ization, it is not directly optimized for end-task performance. In the second stage, we refine the visual access policy using reinforcement learning with answer-le vel supervision. Gi ven a training sample ( x, q txt , a gold ) , we fix the image and question and sample a group of K trajectories using a mixed sampling polic y: π mix = (1 − λ e ) π rand + λ e π θ , (16) where π rand denotes a random region selection pol- icy and π θ is the current learned policy . The same curriculum coefficient λ e is used to gradually shift from exploration to e xploitation. Each trajectory i yields a region access sequence g ( i ) , a generated answer ˆ a ( i ) , and a scalar reward R ( i ) computed solely based on answer quality . W ithin each group, we compute the group-relati ve adv antage: A ( i ) = R ( i ) − 1 K K X j =1 R ( j ) . (17) The policy is optimized using the GRPO objec- ti ve: L RL = − K X i =1 T i X t =1 A ( i ) log π θ ( a ( i ) t | s ( i ) t ) . (18) T o prev ent large deviations from the SFT - initialized policy , we additionally apply a KL regu- larization term: L KL = E s KL π θ ( · | s ) ∥ π SFT ( · | s ) . (19) The final optimization objecti ve is: min θ L RL + β L KL . (20) The re ward is a linear combination of four terms: r = r task + λ 1 r format − λ 2 r length − λ 3 r vision . (21) Here, r task is the task re ward: for multiple-choice or numeric questions, it is 1 if the answer is ex- actly correct and 0 otherwise; for open-ended math reasoning, we use exact match with numerical- tolerance checking. The format reward r format en- courages compliance with a predefined reasoning– answer output template, and in v alid formatting or missing a final answer is penalized. The length penalty r length is proportional to the number of gen- erated tokens to discourage o verly v erbose reason- ing. The vision penalty r vision is proportional to the number of visual access steps (or queried re- gions) to discourage e xcessiv e visual reliance and promote discriminativ e, budget-a ware visual usage with adapti ve stopping. 4 Experiments 4.1 Experimental Datasets W e ev aluate our method on a di verse set of visual reasoning benchmarks. For commonsense visual reasoning, we use M3CoT ( Zhang et al. , 2024b ), ScienceQA ( Lu et al. , 2022 ), and LLaV A-Bench In- the-W ild (LLaV A-W) ( Liu et al. , 2023 ). M3CoT fo- cuses on multi-domain, multi-step multimodal rea- soning, ScienceQA serves as a standard benchmark for general VLM reasoning, and LLaV A-W ev al- uates fine-grained visual understanding via long- form answers with GPT -4V references. For mathe- matical visual reasoning, we adopt MathV ista ( Lu et al. , 2024a ) and MathV ision ( W ang et al. , 2024a ), which require both fine-grained visual perception and multi-step mathematical reasoning. For training data, we use the M3CoT train- ing set and the LLaV A-CoT -100k ( Xu et al. , 2025 ) training set for commonsense visual reason- ing. For mathematical visual reasoning, we adopt MathV360K ( Shi et al. , 2024 ), from which we care- fully select ov er 50K diverse samples and generate textual chain-of-thought annotations using GPT - 4V . All the above datasets contain textual chain-of- thought annotations and do not include an y visual grounding or visual token-le vel annotations. 4.2 Compared Methods For commonsense visual reasoning , we com- pare our method with sev eral representati ve rea- soning strategies, all instantiated on the same Q W E N 2 - V L - 7 B backbone for fairness. Multi- modal CoT ( Zhang et al. , 2024b ) generates text- only intermediate reasoning steps before producing the final answer . CCoT ( Mitra et al. , 2024 ) con- structs a scene graph to capture compositional ob- ject relations and uses it to guide answer generation. DDCoT ( Zheng et al. , 2023 ) decomposes the ques- tion into sub-questions and answers them using a VLM. SCAFFOLD ( Lei et al. , 2024 ) ov erlays co- ordinate grids onto images to expose fine-grained spatial information and guides reasoning with these coordinates. ICoT ( Gao et al. , 2025 ) repeatedly re-injects visual tokens during CoT while treating visual patches uniformly . For mathematical visual reasoning , we com- pare our method against a set of strong recent vision-language models, including MiniCPM-V - 2.6 ( Y ao et al. , 2024 ), VIT A-1.5 ( Fu et al. , 2025 ), LLaV A-CoT ( Xu et al. , 2025 ), Qwen2-VL- 7B ( W ang et al. , 2024b ), InternVL2.5 ( Chen et al. , 2025b ), POINTS ( Liu et al. , 2024b ), Ovis ( Lu et al. , 2024b ), and TVC-Qwen2-VL-7B ( Sun et al. , 2025 ). TVC-Qwen2-VL-7B mitigates visual for getting in multimodal long-chain reasoning by periodically reintroducing compressed visual inputs during rea- soning. 4.3 Model Implementation W e use Qwen2-VL-7B as the base model in our experiments. Both projectors are implemented as Methods M3CoT ScienceQA LLaV A-W A CC. ↑ A CC. ↑ R OUGE-L ↑ Qwen2-VL-7B 43.6 56.3 32.7 MultimodalCoT 40.1 51.3 30.7 CCoT 43.3 56.4 29.4 DDCoT 42.6 55.2 31.2 SCAFFOLD 41.7 53.7 31.8 ICoT 44.1 56.8 34.2 SSV -CoT (Ours) 44.9 57.3 35.7 T able 1: Commonsense visual reasoning results. Compar - ison of SSV -CoT applied to Qwen2-VL-7B with CoT -based methods (including No-CoT , MultimodalCoT , CCoT , DDCoT , SCAFFOLD, and ICoT) on M3CoT (Accurac y), ScienceQA (Accuracy), and LLaV A-W (R OUGE-L). The best result for each benchmark is highlighted in bold. Model MathV ista MathVision A verage Acc. ↑ Acc. ↑ Acc. ↑ MiniCPM-V -2.6 60.8 18.4 39.6 VIT A-1.5 66.2 19.5 42.9 LLaV A-CoT 52.5 19.9 36.2 Qwen2-VL-7B 60.9 16.3 38.6 InternVL2.5 64.5 17.0 40.8 POINTS 1.5 66.4 22.0 44.2 Ovis1.6-Gemma2 70.2 20.6 45.4 TVC-Qwen2-VL-7B 68.1 22.7 45.4 SSV -CoT (Ours) 72.2 23.5 47.9 T able 2: Mathematical visual reasoning results. Com- parison of SSV -CoT applied to Qwen2-VL-7B with vision- language models on MathV ista (Accuracy) and MathV ision (Accuracy). The best results are highlighted in bold. single-layer linear modules, and we uniformly set the similarity filtering threshold to θ = 0 . 7 . See the appendix for detailed settings. 4.4 Overall P erformance Overall, the e xperimental results indicate that SSV - CoT leads to consistent improv ements in long- context multimodal reasoning across both common- sense and mathematical tasks. For commonsense visual reasoning (T able 1 ), SSV -CoT sho ws moderate gains o ver the Qwen2- VL-7B backbone, with impro vements of +1.3 Ac- curacy on M3CoT , +1.0 Accuracy on ScienceQA, and +3.0 R OUGE-L on LLaV A-W . Compared with ICoT , which interlea ves visual tokens while treat- ing image patches uniformly , SSV -CoT better pre- serves task-relev ant visual information through goal-conditioned and sequential visual selection, resulting in more stable performance across bench- marks. For mathematical visual reasoning (T able 2 ), SSV -CoT also improv es upon the Qwen2-VL-7B baseline, increasing the a verage score from 38.6 to 47.9. In comparison to TVC, which alleviates Methods M3CoT ScienceQA LLaV A-W A CC. ↑ A CC. ↑ R OUGE-L ↑ SSV -CoT 44.9 57.3 35.7 w/o SR 43.5 ( -1.4 ) 56.1 ( -1.2 ) 33.9 ( -1.8 ) w/o SS 43.8 ( -1.1 ) 56.4 ( -0.9 ) 34.2 ( -1.5 ) w/o AS 44.3 ( -0.6 ) 56.9 ( -0.4 ) 35.0 ( -0.7 ) T able 3: Ablation study of SSV -CoT on commonsense vi- sual reasoning benchmarks. SR denotes Structured Regions, SS denotes Sequential Selection, and AS denotes Adaptive Stopping. Numbers in parentheses denote performance degra- dation compared with the full model. visual forgetting by periodically reintroducing com- pressed visual inputs, SSV -CoT further aligns vi- sual selection with reasoning objectiv es, supporting more effecti v e use of visual information in multi- step mathematical reasoning. Overall, these results suggest that SSV -CoT helps mitigate visual for getting and supports task- aw are visual grounding, contrib uting to improv ed performance across diverse visual reasoning sce- narios. 5 Discussion 5.1 Ablation Experiment W e ablate SSV -CoT to assess the cont ribution of its core components across three commonsense visual reasoning benchmarks (T able 3 ), with the follow- ing settings: (1) w/o Structur ed Re gions : the model does not construct question-conditioned structured regions and directly injects raw visual tokens, re- sembling patch-le vel interlea ved reasoning; (2) w/o Sequential Selection : all region embeddings are injected at once, removing the sequential visual access order; (3) w/o Adaptive Stopping : the model is forced to attend to a fixed number of regions without dynamically deciding when to stop visual querying. The results sho w that all components contribute to SSV -CoT . Remo ving structured re gions causes the largest performance drop, while disabling se- quential selection also consistently degrades per- formance. In contrast, removing adapti ve stopping leads to smaller but stable declines. Performance drops are more pronounced on M3CoT and LLaV A- W than on ScienceQA, reflecting their stronger re- liance on fine-grained visual information. 5.2 In-depth Analysis Structure and order ar e mutually reinf orcing . T able 4 jointly ablates visual structure and cog- What is the most lik ely activity that peopl e in this location engag e in? A Gardening B Riding ATVs C Boating D Playing sports Text-CoT : .. the gr assland and woodland sc enery, .. shows several all-terrain vehicles ( ATVs) : one parked ... , and sever al others strapped into the bed of a pickup t ruck. .. a small boat is also visible o n a trailer , ... T he concentr ation of multiple AT Vs suggests .. comm on activity here is riding AT Vs ... Answer : Riding ATVs . SSV-CoT : Step 1 : .. most promi nent element .. is a b oat being tow ed by a trai ler , and the boat is .. lo aded onto the trailer. Step 2: .. all-terrain ve hicles (ATVs) are .. visible, .. placed beh ind the trailers, .. for transport. Step 3: .. the bac kground .. woods .. gr asslands, .. boat is .. close to .. trailer h itch, ... with travel pre parations than gardening or play ing sports. Answ er: Boating . The solid area in the image is comp osed of 8 identical cubes. W hat does the solid area l ook like from abo ve? Option: A, B, C , D, E Text-CoT : From the front, .. a colu mn of 3 squares (vertically) on .. l eft. In the middle lay er, .. a section extending to the right . Th e top layer has a squar e to the left of center . .. , the left column o nly shows one cell width in the top view; .. two sq uares exten ding to .. right f orm an "L" s hape .. . Answe r: A. SSV-CoT: Step 1: Projec t from top to botto m. ... The whole figure .. w idth .. 2 .. length .. 4 , .. Step 2: .. three consecutiv e position s in the le ft column .. Ste p 3: At the rearmost positio n, it extends one unit to the right. Ste p 4: Above this right-side position, .. is one more unit , f orming a corner shape w ith one extra unit on to p. Answer: C . Region Embed ding Region Embedding Figure 3: Comparison of T ext-CoT and SSV -CoT on Qwen2-VL-7B for visual reasoning. Errors are shown in red. Only selected regions are displayed, and numbers indicate the token injection order . Order (Acc@1 %) V isual repr . Random Cognition Patch subset 63.1 65.4 Saliency re gions 68.0 72.2 T able 4: 2 × 2 ablation of visual structure and cognition order on MathV ista. Each cell reports Acc@1 (%). All variants share the same visual token b udget and maximum steps K . Strategy Acc@1 (%) A vg #regions Fixed- K =2 (Seq) 68.5 2.0 Fixed- K =3 (Seq) 71.0 3.0 Fixed- K =4 (Seq) 71.3 4.0 Adaptiv e- K (Ours) 72.2 2.7 T able 5: V isual budget analysis on MathV ista. Fixed- K vari- ants always query e xactly K regions. Our adaptive- K policy learns when to stop via a action, achie ving compara- ble or better accuracy with fe wer region queries on a verage. nition order on MathV ista. Using unstructured patch subsets with a random schedule ( P atch sub- set, Random ) gives the weakest performance. In- troducing a learned access order on top of the same patches ( P atch subset, Cognition ) yields a modest gain (63.1 → 65.4), suggesting that sequential, goal- conditioned access helps ev en with weak visual units. Replacing patches with saliency-based re- gions under a random order ( Saliency re gions, Ran- dom ) brings a larger improvement (63.1 → 68.0), sho wing that structured, semantically coherent re- gions are crucial on their own. Our full model ( Saliency r e gions, Cognition ) combines both ingre- dients and achie ves the best accurac y (72.2), with gains that exceed either modification in isolation. This pattern indicates that region structure and cog- nition order are complementary: the policy needs good regions to reason over , and good regions are used most effecti vely when queried in a learned sequence. Adaptive visual budget. T able 5 analyzes ho w the visual budget interacts with the sequential pol- icy . Increasing the fixed number of re gion queries from K =2 to K =3 substantially improv es perfor- mance (68.5 → 71.0), but further raising the b udget to K =4 yields only mar ginal gains (71.3) while forcing the model to inspect more regions. In contrast, our adaptiv e- K v ariant, equipped with a learned action, reaches the highest ac- curacy (72.2) while using 2.7 regions on average. This shows that the model not only learns wher e and in which order to look, b ut also how much vi- sual e vidence is needed for a given question, yield- ing more accurate reasoning with a tighter and au- tomatically controlled visual budget. 5.3 Case Study This Fig. 3 compares the performance of T ext-CoT and Structured V isual Reasoning (SSV -CoT) in two typical cases: common-sense visual reasoning (top) and mathematical visual reasoning (bottom). In the common-sense case, T e xt-CoT focuses on salient but incomplete clues (e.g., multiple A TVs) while ignoring finer conte xtual details, leading to incor - rect conclusions. In contrast, SSV -CoT sequen- tially focuses on task-relev ant areas (boat, trailer, background), progressi vely integrating e vidence to arriv e at the correct answer . In the mathemati- cal case, T ext-CoT relies on a holistic description of the structure, misinterpreting the spatial layout. Ho wev er , SSV -CoT explicitly selects and infers ke y areas (projection, column continuity , extension, and height), enabling accurate spatial reasoning. 6 Conclusion W e introduce SSV -CoT , which frames visual cog- nition in multimodal reasoning as a structured, sequential process instead of static token injec- tion. Trained with chain-of-thought supervision and answer -lev el re wards, SSV -CoT learns visual selection and stopping without re gion annotations or e xternal tools. Empirical results across common- sense and math benchmarks demonstrate consis- tent improv ements and highlight the importance of structured regions and adapti ve visual access. Limitations SSV -CoT introduces additional computation due to sequential visual access compared with one-shot visual token injection. Moreo ver , its effecti veness depends on the quality of question-conditioned saliency , which may be less reliable in visually ambiguous scenes. Extending the method to more complex settings such as videos remains future work. Ethical Considerations SSV -CoT is trained on existing vision-language datasets and does not require additional annota- tions or external tools. Like other vision-language models, it may inherit biases from the training data. Care should be taken when applying the method in real-world or high-stakes scenarios. References Mohamed Salim Aissi, Clemence Grislain, Mohamed Chetouani, et al. 2025. V iper: V isual perception and explainable reasoning for sequential decision-making . CoRR , abs/2503.15108. Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, et al. 2022. Flamingo: a visual language model for few- shot learning. In Advances in Neur al Information Pr ocessing Systems . Jimmy Ba, V olodymyr Mnih, and K oray Kavukcuoglu. 2015. Multiple object recognition with visual at- tention. In International Confer ence on Learning Repr esentations . Poster . Chun-Fu Chen, Rameswar Panda, and Quanfu Fan. 2022. Region vit: Regional-to-local attention for vi- sion transformers. In International Conference on Learning Repr esentations . Keqin Chen, Zhao Zhang, W eili Zeng, et al. 2023. Shikra: Unleashing multimodal llm’ s referential dia- logue magic . CoRR , abs/2306.15195. Xinyan Chen, Renrui Zhang, Dongzhi Jiang, et al. 2025a. Mint-cot: Enabling interleav ed visual tokens in mathematical chain-of-thought reasoning . CoRR , abs/2506.05331. Zhe Chen, W eiyun W ang, Y ue Cao, et al. 2025b. Ex- panding performance boundaries of open-source mul- timodal models with model, data, and test-time scal- ing . CoRR , abs/2412.05271. W enliang Dai, Junnan Li, Dongxu Li, et al. 2023. In- structblip: T owards general-purpose vision-language models with instruction tuning. In Advances in Neu- ral Information Pr ocessing Systems . Ming Ding, W endi Zheng, W enyi Hong, and Jie T ang. 2022. Cogview2: Faster and better text-to-image generation via hierarchical transformers . CoRR , abs/2204.14217. Patrick Esser , Robin Rombach, and Björn Ommer . 2021. T aming transformers for high-resolution image syn- thesis . CoRR , abs/2012.09841. Chaoyou Fu, Haojia Lin, Xiong W ang, et al. 2025. V ita- 1.5: T ow ards gpt-4o le vel real-time vision and speech interaction . CoRR , abs/2501.01957. Jun Gao, Y ongqi Li, Ziqiang Cao, and W enjie Li. 2025. Interleaved-modal chain-of-thought . CoRR , abs/2411.19488. L. Itti, C. Koch, and E. Niebur . 1998. A model of saliency-based visual attention for rapid scene anal- ysis . IEEE T r ansactions on P attern Analysis and Machine Intelligence , 20(11):1254–1259. Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, et al. 2022. Perceiv er io: A general architec- ture for structured inputs & outputs. In International Confer ence on Learning Repr esentations . Aishwarya Kamath, Mannat Singh, Y ann LeCun, et al. 2021. Mdetr – modulated detection for end-to-end multi-modal understanding . CoRR , abs/2104.12763. Aisha Urooj Khan, Hilde Kuehne, Chuang Gan, et al. 2022. W eakly supervised grounding for vqa in vision- language transformers . CoRR , abs/2207.02334. Alexander Kirillov , Eric Mintun, Nikhila Ravi, et al. 2023. Segment anything. In Pr oceedings of the IEEE/CVF International Confer ence on Computer V ision , pages 3992–4003. Xuanyu Lei, Zonghan Y ang, Xinrui Chen, et al. 2024. Scaffolding coordinates to promote vision-language coordination in large multi-modal models . CoRR , abs/2402.12058. Junnan Li, Dongxu Li, Silvio Sav arese, and Ste ven C. H. Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Pr oceedings of the 40th Inter- national Conference on Machine Learning , pages 19730–19742. Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, et al. 2022. Grounded language-image pre-training. In Pr oceedings of the IEEE/CVF Conference on Com- puter V ision and P attern Recognition , pages 10955– 10965. Xiping Li and Jianghong Ma. 2025. Aimcot: Active information-driv en multimodal chain-of-thought for vision-language reasoning . CoRR , abs/2509.25699. Y uanze Lin, Y ujia Xie, Dongdong Chen, et al. 2022. Revi ve: Regional visual representation matters in knowledge-based visual question answering . CoRR , abs/2206.01201. Haotian Liu, Chun yuan Li, Qingyang W u, and Y ong Jae Lee. 2023. V isual instruction tuning . CoRR , abs/2304.08485. Shilong Liu, Zhaoyang Zeng, T ianhe Ren, et al. 2024a. Grounding dino: Marrying dino with grounded pre- training for open-set object detection. In Eur opean Confer ence on Computer V ision , pages 38–55. Y uan Liu, Le T ian, Xiao Zhou, et al. 2024b. Points1.5: Building a vision-language model to wards real w orld applications . CoRR , abs/2412.08443. Pan Lu, Hritik Bansal, T ony Xia, et al. 2024a. Math- vista: Evaluating mathematical reasoning of foun- dation models in visual contexts. In International Confer ence on Learning Repr esentations . Pan Lu, Sw aroop Mishra, T ony Xia, et al. 2022. Learn to explain: Multimodal reasoning via thought chains for science question answering. In Advances in Neu- ral Information Pr ocessing Systems . Shiyin Lu, Y ang Li, Qing-Guo Chen, et al. 2024b. Ovis: Structural embedding alignment for multimodal lar ge language model . CoRR , abs/2405.20797. Chancharik Mitra, Brandon Huang, Tre v or Darrell, and Roei Herzig. 2024. Compositional chain-of-thought prompting for large multimodal models . CoRR , abs/2311.17076. V olodymyr Mnih, Nicolas Heess, Alex Grav es, et al. 2014. Recurrent models of visual attention. In Ad- vances in Neural Information Processing Systems , pages 2204–2212. Alec Radford, Jong W ook Kim, Chris Hallacy , et al. 2021. Learning transferable visual models from nat- ural language supervision . CoRR , abs/2103.00020. Nikhila Ra vi, V alentin Gabeur , Y uan-Ting Hu, et al. 2024. Sam 2: Segment anything in images and videos . CoRR , abs/2408.00714. T imo Schick, Jane Dwiv edi-Y u, Roberto Dessì, et al. 2023. T oolformer: Language models can teach them- selves to use tools. In Advances in Neural Informa- tion Pr ocessing Systems . Hao Shao, Shengju Qian, Han Xiao, et al. 2024. V isual cot: Advancing multi-modal language models with a comprehensiv e dataset and benchmark for chain-of- thought reasoning . CoRR , abs/2403.16999. W enhao Shi, Zhiqiang Hu, Y i Bin, et al. 2024. Math-llav a: Bootstrapping mathematical reasoning for multimodal large language models . CoRR , abs/2406.17294. Hai-Long Sun, Zhun Sun, Houwen Peng, and Han-Jia Y e. 2025. Mitigating visual forgetting via take-along visual conditioning for multi-modal long cot reason- ing . CoRR , abs/2503.13360. Ke W ang, Junting Pan, W eikang Shi, et al. 2024a. Measuring multimodal mathematical reasoning with math-vision dataset. In Advances in Neural Informa- tion Pr ocessing Systems . Peng W ang, Shuai Bai, Sinan T an, et al. 2024b. Qwen2- vl: Enhancing vision-language model’ s perception of the world at any resolution . CoRR , abs/2409.12191. Jason W ei, Xuezhi W ang, Dale Schuurmans, et al. 2022. Chain-of-thought prompting elicits reasoning in lar ge language models. In Advances in Neural Information Pr ocessing Systems . Chenfei W u, Shengming Y in, W eizhen Qi, et al. 2023. V isual chatgpt: T alking, drawing and editing with visual foundation models . CoRR , abs/2303.04671. Guowei Xu, Peng Jin, Ziang W u, et al. 2025. Llava- cot: Let vision language models reason step-by-step . CoRR , abs/2411.10440. Zhengyuan Y ang, Zhe Gan, Jianfeng W ang, et al. 2022. Unitab: Unifying text and box outputs for grounded vision-language modeling. In Eur opean Confer ence on Computer V ision , pages 521–539. Zhengyuan Y ang, Linjie Li, Jianfeng W ang, et al. 2023. Mm-react: Prompting chatgpt for multimodal reason- ing and action . CoRR , abs/2303.11381. Y uan Y ao, Tian yu Y u, Ao Zhang, et al. 2024. Minicpm- v: A gpt-4v lev el mllm on your phone . CoRR , abs/2408.01800. Alfred L. Y arbus. 1967. Eye Movements and V ision . Plenum Press, New Y ork. Daoan Zhang, Junming Y ang, Hanjia L yu, et al. 2024a. Cocot: Contrastiv e chain-of-thought prompting for large multimodal models with multiple image inputs . CoRR , abs/2401.02582. Zhuosheng Zhang, Aston Zhang, Mu Li, et al. 2024b. Multimodal chain-of-thought reasoning in language models. T ransactions on Machine Learning Re- sear ch . Ge Zheng, Bin Y ang, Jiajin T ang, et al. 2023. Dd- cot: Duty-distinct chain-of-thought prompting for multimodal reasoning in language models . CoRR , abs/2310.16436. A Algorithm Algorithm 1: Question-aw are Discrimina- ti ve Region Selection with Adapti v e T oken Compression Require: Image x , text query q , multimodal model M , number of regions N , token b udget n Ensure: Region set R = { R 1 , . . . , R N } and region tokens { E k } N k =1 V ← V isionEncoder M ( x ) ,; t ← T extEncoder M ( q ) A ( i, j ) ← sim( v i,j , t ) ,; ˜ A ← Normalize( A ) M ← ˜ A ≥ OtsuThreshold( ˜ A ) { R k } ← ConnectedComp onents( M ) Compute ρ k = 1 | R k | P ( i,j ) ∈ R k ˜ A ( i, j ) Select top ( N − 1) regions by ρ k R N ← Ω \ S N − 1 k =1 R k for eac h r e gion R k do Collect region tokens { v j } m j =1 if m ≤ n then E k ← { Pro j( v j ) } m j =1 else Select top- n tokens by saliency Cluster selected tokens with k -means E k ← { Pro j( ¯ v i ) } n i =1 retur n {R , E k } N k =1 Algorithm 1 describes the question-aware re gion selection process. W e compute a query-conditioned saliency map o ver visual patches, apply adapti ve thresholding and connected-component analysis to obtain candidate regions, and select the top N − 1 regions by av erage saliency , with the remaining area treated as background. B K ey Implementation Details Region Embedding Injection. Giv en an input image x and question q , we first obtain N discrimi- nati ve regions {R k } N k =1 and compute a region em- bedding e k ∈ R d v for each region. Each region embedding is projected to the LLM hidden dimen- sion via a linear projector: ˆ e k = Pro j( e k ) ∈ R d LM . The projected region embeddings are concatenated as additional visual prefix tokens and prepended to the original multimodal input. The final input sequence is: [ ˆ e 1 , . . . , ˆ e N , , ] . Region tokens are injected only at the input stage as fixed prefix es; they neither replace nor accumulate ov er the original visual tokens, and the number of region tok ens is fixed to N during inference. Region Selection and Hyper parameters. W e set the default number of re gions to N = 5 , con- sisting of N − 1 discriminati ve regions and one background region. Regions are generated via Otsu-based adaptive thresholding ov er a similar- ity heatmap, followed by connected-component analysis. Components with area smaller than α = 0 . 01 × H W (where H , W denote the fea- ture map resolution) are discarded. The remaining regions are ranked by their a verage activ ation score ρ k , and the top N − 1 re gions are selected. GRPO Reward Design. W e train the model using GRPO, where the reward is defined as a weighted sum: r = r task + λ 1 r format − λ 2 r length − λ 3 r vision . Here, r task measures answer correctness, r format enforces valid output structure, r length penalizes ov erly long generations, and r vision penalizes e xces- si ve visual access. W e set the weights to λ 1 = 0 . 2 , λ 2 = 0 . 01 , λ 3 = 0 . 05 . T raining Configuration. W e use Qwen2-VL- 7B as the base multimodal lar ge language model (MLLM) in our experiments. Both projectors are implemented as single-layer linear modules. The training procedure consists of two stages: (1) Su- pervised Fine-T uning (SFT), where we train for 3 epochs with a learning rate of 1 × 10 − 6 and a batch size of 64 ; and (2) Reinforcement Learning (RL), where we train for 700 steps with group size G = 4 , a weighting factor λ = 0 . 02 , a learning rate of 1 × 10 − 6 , and a batch size of 16 . During training, the vision encoder is kept frozen, while all remaining model parameters (including the pro- jector layers) are unfrozen and optimized.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment