정적 시각 토큰을 넘어 구조화된 순차 시각 사고 사슬
SSV‑CoT는 질문‑조건부 saliency map을 이용해 이미지 내 핵심 영역을 자동으로 추출하고, 이를 순차적으로 선택·주입하면서 텍스트 체인‑오브‑쓰쓰(Cot)와 결합한다. 시각 접근 순서를 정책 네트워크가 학습하고, 정답 보상과 시각 예산 제약을 통해 목표‑지향적·적응형 시각 인지를 구현한다. 지역 레이블 없이 엔드‑투‑엔드로 학습되며, 다양한 시각 추론 벤치마크에서 정적 토큰 방식보다 성능 향상을 보인다.
저자: Guangfu Guo, Xiaoqian Lu, Yue Feng
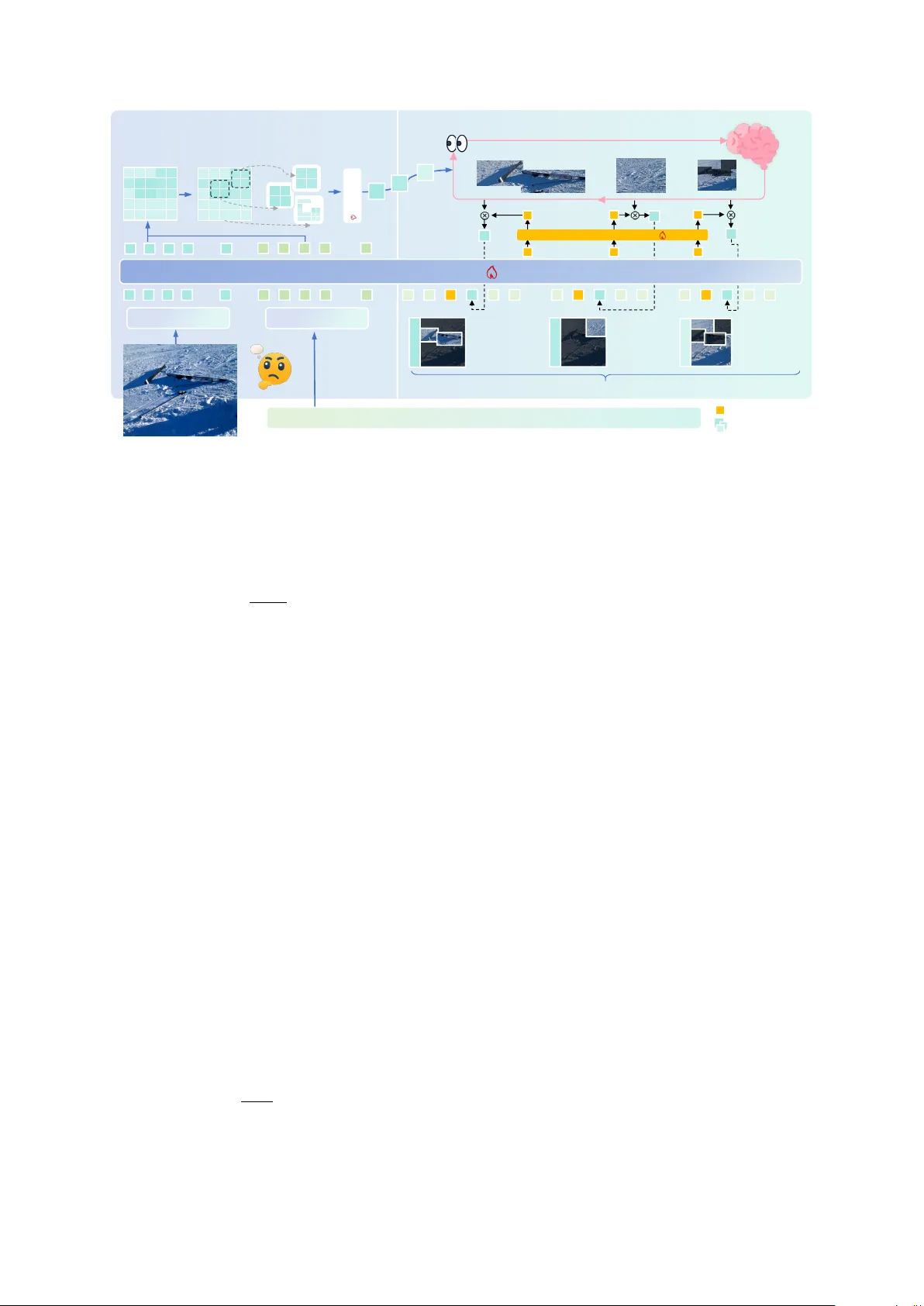
본 논문은 멀티모달 대형 언어 모델(MLLM)이 이미지 정보를 한 번만 인코딩하고 이후 텍스트 기반 추론에만 의존하는 구조적 한계를 지적한다. 인간은 시각 정보를 “전체적인 인지 → 가장 관련된 영역 순차 탐색”하는 방식으로 문제를 해결한다는 인지심리학적 근거를 바탕으로, 질문‑조건부 saliency map을 이용해 이미지 내 핵심 영역을 자동으로 추출하고, 이를 순차적으로 선택·주입하면서 텍스트 체인‑오브‑쓰쓰(Cot)와 결합하는 새로운 프레임워크 SSV‑CoT(Structural Sequential Visual Chain‑of‑Thought)를 제안한다.
**1. Structured Visual Cognition**
이미지 x와 질문 q를 입력으로 비전 인코더와 사전 학습된 MLLM을 사용해 패치‑레벨 특징 h_v와 질문 임베딩 q를 얻는다. 질문 임베딩과 각 패치 토큰 사이의 코사인 유사도를 계산해 saliency score S_ij를 구하고, 이를 정규화한다. Otsu thresholding을 적용해 binary mask M을 만들고, 8‑neighborhood 연결 성분 분석을 통해 연속된 salient region {R_k}를 추출한다. 작은 잡음 영역은 제거하고, 남은 영역은 고정된 토큰 수(예: 48)로 압축한다. 압축은 saliency 순위에 따라 top‑n 토큰을 선택하거나 k‑means 클러스터링을 사용한다. 각 region은 permutation‑invariant visual projector g_proj을 통해 고정 차원의 region embedding E_k를 만든다. region‑level score ρ_k는 해당 region 내 평균 정규화 saliency 값으로 정의하고, 이를 기준으로 Top‑N 영역을 선택한다. 전체 이미지 커버리지를 위해 saliency mask에 포함되지 않은 픽셀을 평균화한 global embedding e_global도 포함한다. 최종적으로 구조화된 region embedding bank E={e_1,…,e_N,e_global}가 생성된다. 이 단계는 비학습적 전처리이며, 질문에 따라 동적으로 영역을 구성한다는 점이 기존 고정 토큰 방식과 차별화된다.
**2. Sequential Visual Access**
텍스트 체인‑오브‑쓰쓰 디코딩 중 newline 토큰을 “추론 단계 경계”로 활용한다. 각 단계 t에서 LLM의 최종 레이어 hidden state h_t를 signal projector W_sig를 통해 언어 공간으로 매핑하고, 모든 region embedding e_k를 visual projector W_vis를 통해 동일한 공간에 투사한다. 이후 h_t와 e_k 사이의 유사도 s_{t,k}=sim(ĥ_t,ĕ_k)를 계산하고, softmax를 적용해 행동 확률 π_θ(a_t=k|s_t)를 얻는다. 행동 a_t는 특정 region을 선택하거나 STOP 토큰을 선택하는데, STOP 토큰도 학습 가능한 임베딩으로 취급한다. 선택된 region embedding은 다음 텍스트 디코딩 단계에 주입되어 LLM이 시각 증거를 직접 활용하도록 만든다.
**3. Training Procedure**
학습은 두 단계로 진행된다.
- *Stage I (Heuristic Supervised Fine‑tuning)*: 사전 학습된 MLLM이 제공하는 saliency 기반 순서를 모방하는 지도 학습을 수행한다. 초기에는 curriculum coefficient λ_e를 사용해 무작위 region 선택 비율을 높이고, 점차 saliency‑guided 선택으로 전환한다. 이는 초기 saliency가 노이즈가 많을 때 학습 불안정을 완화한다.
- *Stage II (GRPO Reinforcement Learning)*: Gradient‑based Policy Optimization을 이용해 정답 보상과 시각 예산 정규화를 동시에 최적화한다. 보상은 최종 정답 일치 여부와 사용된 region 수에 대한 페널티를 포함해, 모델이 최소한의 시각 쿼리로 정확한 답을 도출하도록 유도한다.
**4. Experiments**
다양한 시각 추론 벤치마크(VQA‑X, NLVR2, GQA, CLEVR‑HR 등)에서 SSV‑CoT는 기존 정적 토큰 기반 MLLM 대비 2~4%p의 정확도 향상을 기록한다. 특히 다중 힌트가 필요한 복합 질문에서 큰 폭의 개선을 보였으며, Ablation study를 통해 (1) saliency‑driven region 추출, (2) 순차적 정책, (3) STOP 메커니즘 각각이 성능에 기여함을 확인했다. 시각 예산 제약을 적용했을 때도 높은 정확도를 유지하면서 평균 시각 쿼리 수를 30% 이상 감소시켰다.
**5. Contributions**
1. 시각 접근을 “질문‑조건부, 목표‑지향적, 순차적”으로 모델링하여 정적 토큰 방식의 한계를 극복하였다.
2. 지역 레이블 없이 엔드‑투‑엔드 학습이 가능하도록 설계했으며, 두 단계의 curriculum‑based 학습으로 안정적인 정책을 학습한다.
3. 적응형 STOP 메커니즘을 도입해 시각 예산을 효율적으로 관리하고, 불필요한 시각 쿼리를 억제한다.
결론적으로 SSV‑CoT는 인간의 시각‑인지 과정을 모방한 구조화·순차적 시각 접근을 통해 멀티모달 LLM의 이미지 기억 소멸 문제를 완화하고, 보다 효율적이고 해석 가능한 시각 추론을 가능하게 한다. 향후 연구에서는 보다 정교한 질문‑조건부 saliency 모델링, 멀티모달 메모리 통합, 그리고 실제 인간‑컴퓨터 인터랙션 환경에서의 적용 가능성을 탐색할 예정이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기