Contextual inference from single objects in Vision-Language models
How much scene context a single object carries is a well-studied question in human scene perception, yet how this capacity is organized in vision-language models (VLMs) remains poorly understood, with direct implications for the robustness of these m…
Authors: Martina G. Vilas, Timothy Schaumlöffel, Gemma Roig
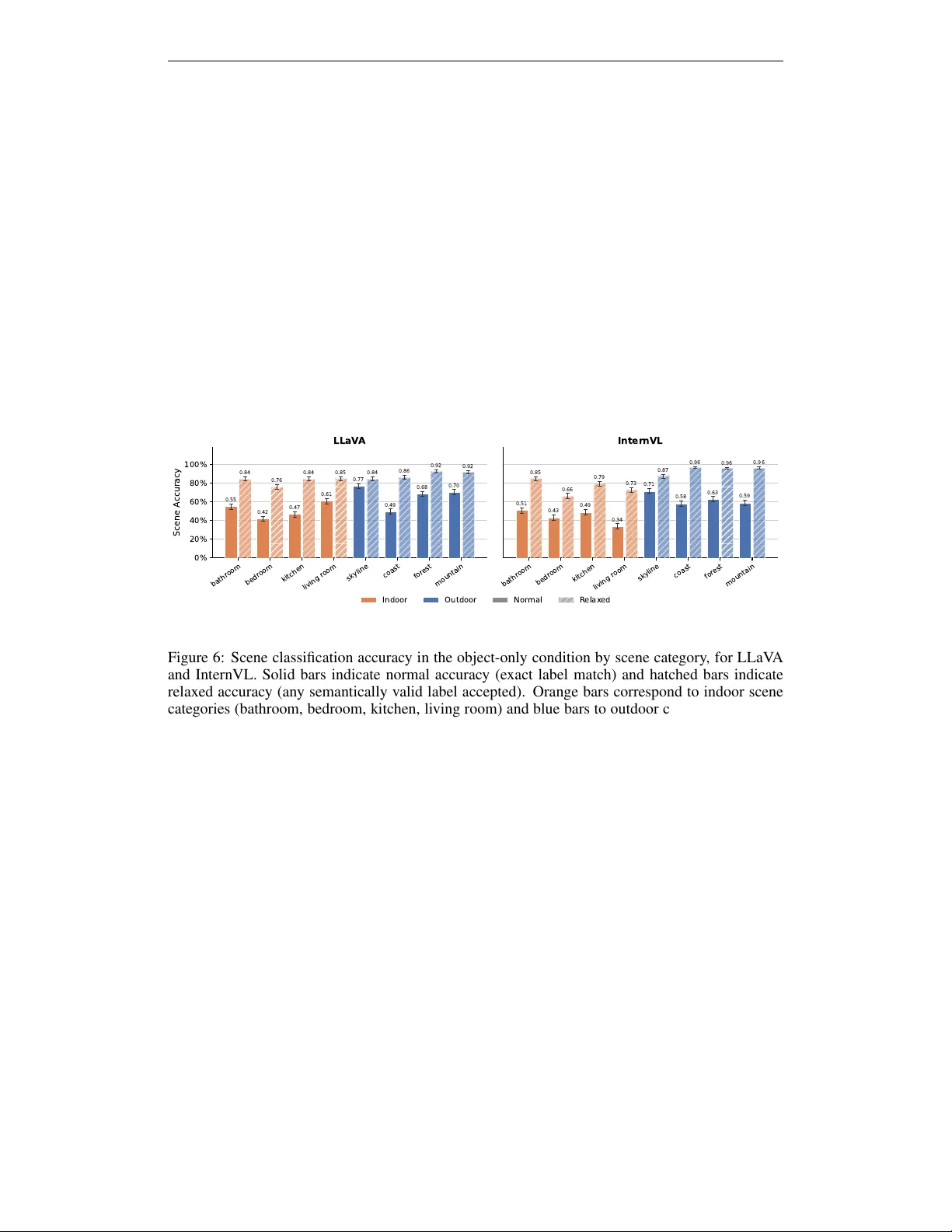
C O N T E X T UA L I N F E R E N C E F R O M S I N G L E O B J E C T S I N V I S I O N - L A N G UA G E M O D E L S Martina G. V ilas 1 ∗ Timoth y Schauml ¨ offel 1,2* Gemma Roig 1,2 1 Goethe Univ ersity Frankfurt 2 The Hessian Center for AI A B S T R AC T How much scene conte xt a single object carries is a well-studied question in hu- man scene perception, yet how this capacity is or ganized in vision-language mod- els (VLMs)s remains poorly understood, with direct implications for the robust- ness of these models. W e in vestig ate this question through a systematic behavioral and mechanistic analysis of contextual inference from single objects. Presenting VLMs with single objects on masked backgrounds, we probe their ability to infer both fine-grained scene category and coarse superordinate context (indoor vs. out- door). W e found that single objects support above-chance inference at both le vels, with performance modulated by the same object properties that predict human scene categorization. Object identity , scene, and superordinate predictions are partially dissociable: accurate inference at one level neither requires nor guaran- tees accurate inference at the others, and the degree of coupling differs markedly across models. Mechanistically , object representations that remain stable when background context is remov ed are more predicti ve of successful contextual infer - ence. Scene and superordinate schemas are grounded in fundamentally different ways: scene identity is encoded in image tokens throughout the network, while superordinate information emerges only late or not at all. T ogether , these results rev eal that the organization of contextual inference in VLMs is more complex than accuracy alone suggests, with behavioral and mechanistic signatures dissociating in ways that dif fer substantially across models. 1 I N T RO D U C T I O N VLM A. Scene 1. ba thro om B. Superordina te 2. ind oor C. Object 8. b ath tub (3) Model (4) Answer A. Scene Infer the sce ne c atego ry. 1 . ba throo m 2. kit chen .. . 8. coas t B. Superordina te Infer the sce ne c atego ry. 1 . ou tdoo r 2. ind oor C. Object Iden tify the obj ect . 1 . so fa 2. tree .. . 8. bath tub 1. Full Scene (2) Prompt (1) Image 2. Object Only mask Figure 1: Experimental design. Each image condition (full scene or object-only) is paired with three prompt types: (A) scene category , (B) superordinate category , and (C) object identity . W e analyze the intermediate image tok en represen- tations corresponding to the objects (shown in black). A central question in scene percep- tion research is whether contextual understanding is an emergent prop- erty of object representations. Cogni- tiv e studies hav e shown that humans can rapidly infer contextual informa- tion from single objects, and this ca- pacity is modulated by object prop- erties that reflect the statistical struc- ture of object-scene relationships in natural images (W iesmann & V ˜ o, 2023). Whether the same holds for artificial multimodal systems remains largely unexplored. Understanding how VLMs perform conte xtual infer- ence from single objects is not only a theoretical question but one with di- rect practical consequences. It is es- sential for diagnosing model failures, assessing generalization, and b uilding more robust VLMs. ∗ Equal contribution 1 W e address this question through a beha vioral and mechanistic in v estigation. W e present two VLMs with images of single objects either embedded in their full scene or isolated on a masked background (see Figure 1). W e probe the behavior and internal representations of these models across two levels of contextual abstraction – scene cate gory and superordinate category (indoor vs. outdoor) – to ask: • Do single objects carry scene-level and superordinate information independently of back- ground context? • Is contextual inference modulated by the same object properties that predict human scene categorization? • Is contextual inference partially independent of object identification? • Are scene-lev el and superordinate schemas processed through the same internal pathways, or do they arise from distinct mechanisms? • Is contextual information encoded in object-patch representations, and how does the pres- ence or absence of background context modulate these representations? Our results show that single objects activ ate scene and superordinate schemas, with performance modulated by the same object properties that predict human scene cate gorization. Howe ver , we found important distinctions in how this capacity is organized and grounded across tasks, object properties, and models. Scene and superordinate inference draw on different object properties and are grounded differently in image token representations. Contextual inference is partially indepen- dent of object identification, and the two models differ substantially in how tightly object, scene, and superordinate information are integrated. 2 R E L A T E D W O R K Contextual effects on object recognition in VLMs. The ef fect of contextual information on ob- ject recognition in VLMs has been previously studied. Rajaei et al. (2025) ask whether VLMs exhibit human-like contextual facilitation: if objects embedded in coherent scenes are recognized better than objects in phase-scrambled scenes, as they are for humans. Similarly , Li et al. (2025) show that contextual incongruity (objects appearing in unexpected scenes) systematically degrades object recognition in VLMs, with models hallucinating contextually expected but absent objects. Merlo et al. (2025) examine how scene context around an object affects the model’ s language gen- eration about that object, and uses attention patterns as a proxy for mechanistic insight. W e go in the opposite direction: we remov e the scene and ask what the object alone tells the model about its contect, and explain ho w this inference is grounded mechanistically . Mechanistic Interpr etability of VLMs. Previous work has found that image token representa- tions in VLMs become progressi vely interpretable in the vocab ulary space, with object informa- tion spatially localized in tokens corresponding to the object’ s image region (Neo et al., 2025; Schauml ¨ offel et al., 2026). W e adopt the same technique to in v estigate how contextual informa- tion is grounded in object tokens when the scene background is absent. 3 M E T H O D S 3 . 1 M O D E L S A N D S T I M U L I W e e valuate two widely used lar ge vision-language models (VLMs): LLaV A 1.5-13B (Liu et al., 2024) and InternVL3.5-14B (W ang et al., 2025) (see Appendix A for details). W e use a curated subset of the dataset introduced by Greene (2013), comprising N = 2 , 392 object- scene pairs drawn from 1 , 004 unique images across eight scene categories (bathroom, bedroom, kitchen, living room, coast, forest, mountain, and skyline). Each image contains multiple objects, but each instance selected for analysis focuses on a single foreground object for which a segmentation mask is available. Full details on the instance selection procedure are pro vided in Appendix B. For each object instance we record four scene-relev ant properties previously in vestigated in human scene categorization research (W iesmann & V ˜ o, 2023): 2 • Frequency : P ( object | scene ) – the proportion of images within the associated scene cat- egory that contain the object, irrespecti ve of how many times the object appears within a single image. • Specificity : P ( scene | object ) – the proportion of images containing the object that belong to the associated scene category , capturing how e xclusi vely the object predicts that scene. • Size : The fraction of the image area covered by the object mask. • Object T ype : Follo wing W iesmann & V ˜ o (2023), we distinguish between two object types. Anchor objects are lar ge, typically stationary objects that predict the presence and location of smaller objects in their vicinity (e.g., a stove predicting the presence of a pan). Local objects, by contrast, are the smaller objects whose position and identity are predicted by anchors (e.g., the pan). W e extract the object type annotations from T urini & V ˜ o (2022). Frequency and specificity are computed using the ADE20K dataset (Zhou et al., 2019), as its sub- stantially larger size pro vides more reliable estimates of object–scene co-occurrence statistics. 3 . 2 E X P E R I M E N T A L C O N D I T I O N S Each image is presented to each VLM under two viewing conditions: (1) Full scene : the original unmodified image; (2) Object only : only the object is sho wn, with the rest of the image replaced by a grey background. 3 . 3 T A S K S The VLMs are queried with three successiv e forced-choice prompts, constructed independently per image. All prompts use an enumerated format in which answer options are listed with numerical indices, presented in randomized order . Model responses were generated greedily , to ensure repro- ducibility . Full prompt templates are provided in Appendix C. The tasks are: (1) Scene classification: The model is asked to infer the scene category from one of the eight options. In the object-only condition, the prompt explicitly indicates that the background is masked, and the model must infer the scene from the visible object alone. (2) Superordinate classification: The model classifies the scene as indoor or outdoor . (3) Object classification: The model identifies the target object from eight options: the target object plus one distractor sampled from each of the remaining scene categories, drawn from a pre-compiled list of scene-typical objects. For the scene classification task, accuracy is scored in two ways. Normal accur acy requires an exact match of the tar get scene label in the model response. Relaxed accur acy counts a response as correct if any scene category associated with the queried object appears in the answer , where association is defined as the object ha ving appeared in at least one image of that scene cate gory in the dataset. This accounts for cases where the model correctly identifies a plausible scene that is not the ground-truth scene for the specific image but is semantically v alid gi ven the object. 4 E X P E R I M E N T S A N D R E S U LT S 4 . 1 S I N G L E O B J E C T S C A R RY PA RT I A L C O N T E X T UA L I N F O R M A T I O N As Figure 2 sho ws, scene classification accurac y is near ceiling for both models under the full-scene condition (LLaV A: 96.2%; InternVL: 97.0%), confirming that scene recognition is robust. When the background is remov ed and the model must rely solely on the visible object, performance drops substantially (LLaV A: 58.6%; InternVL: 53.4% under normal scoring). Ho wev er , the gap between normal and relaxed accuracy in the object-only condition suggests that models frequently retrieve a scene that is semantically consistent with the object but does not match the ground-truth scene (LLaV A relaxed: 85.5%; InternVL: 84.7%). This pattern indicates that a single object activ ates plausible scene-level associations, but those associations are not sufficiently specific to identify the exact scene depicted. W e additionally find that scene classification accuracy in the object-only condition varies systematically by scene type (see Appendix D). Outdoor scenes are consistently and substantially easier than indoor scenes for both models. The relaxed–normal accuracy gap is considerably larger for indoor scenes, reflecting greater cate gory ambiguity . 3 Superordinate classification is markedly more rob ust than scene classification, with LLaV A reaching 93.8% and InternVL 85.0% in the object-only condition. The asymmetry between superordinate and scene-lev el accuracies mirrors findings from human scene categorization, where superordinate in- door/outdoor discrimination from objects also exceeds fine-grained scene-level classification (W ies- mann & V ˜ o, 2023). Object classification reveals a dissociation between the performance of the two models. In LLaV A, object recognition accuracy is higher when the scene background is absent than when it is present (full-scene: 62%; object-only: 71%), suggesting that background context introduces conflicting or distracting visual information that interferes with object identification in this model. InternVL shows the opposite pattern: accuracy drops when the full scene is unav ailable (full-scene: 91%; object- only: 76%), although it still maintains a similar accuracy to LLaV A. This suggests background information aids recognition of objects in this model. Scene Super or dinate Object T ask 0% 20% 40% 60% 80% 100% A ccuracy 0.96 0.59 0.85 1.00 0.94 0.62 0.71 LLaV A Scene Super or dinate Object T ask 0.97 0.53 0.85 1.00 0.85 0.91 0.76 InternVL F ull Scene Object Only Nor mal R elax ed Figure 2: Classification accuracy across image conditions and tasks. Bars sho w accuracy under the full-scene (original image), and object-only (single fore ground object on a masked background) conditions. For scene classification, solid bars indicate normal accuracy (exact label match) and hatched bars indicate relaxed accuracy (any semantically valid label accepted). Error bars denote the standard error of the mean. 4 . 2 C O N T E X T U A L I N F E R E N C E I S M O D U L ATE D B Y O B J E C T D I AG N O S T I C P RO P E RT I E S T o identify which object properties drive scene and superordinate inference from single objects, we quantify the independent contribution of each property to classification accuracy in the object-only condition using multi variate logistic re gression, follo wing the approach of W iesmann & V ˜ o (2023): log P ( correct ) 1 − P ( correct ) = β 0 + β 1 z ( frequency ) + β 2 z ( specificity ) + β 3 z ( size ) + β 4 1 [ type ] + ε (1) where z ( · ) denotes z-scoring (all continuous predictors are z-scored prior to fitting) and 1 [ type ] is an indicator v ariable for object type (anchor vs. local). Separate regressions are fit for each task and model, and we report log-odds coefficients (Figure 3). Scene classification. Object frequency , specificity , and size each independently and significantly predict scene classification accuracy in both models (all p < . 001 ). Under normal scoring, speci- ficity is the strongest predictor in both LLaV A ( ˆ β spec = 0 . 78 ) and InternVL ( ˆ β spec = 0 . 70 ), follo wed by frequency (LLaV A: ˆ β freq = 0 . 54 ; InternVL: ˆ β freq = 0 . 45 ) and size (LLaV A: ˆ β size = 0 . 51 ; In- ternVL: ˆ β size = 0 . 57 ). Object type (anchor vs. local) does not significantly predict scene accuracy in either model once other continuous properties are controlled, suggesting that their distinction does not contribute independently beyond the statistical properties it correlates with. This finding also mirrors that of humans reported in W iesmann & V ˜ o (2023). Superordinate classification. The predictor structure shifts markedly for the indoor/outdoor discrimination. Size is the dominant predictor in both models (LLaV A: ˆ β size = 1 . 80 ; InternVL: ˆ β size = 1 . 09 , both p < . 001 ), and frequency contributes positi vely in both (LLaV A: ˆ β freq = 0 . 31 , p < . 01 ; InternVL: ˆ β freq = 0 . 47 , p < . 001 ). 4 Size F r eq. Spec. T ype 0.4 0.2 0.0 0.2 0.4 0.6 0.8 1.0 1.2 L og- Odds Coefficient *** *** *** *** *** *** Scene Size F r eq. Spec. T ype 0.5 0.0 0.5 1.0 1.5 2.0 2.5 3.0 *** ** *** *** *** Superordinate LLaV A Inter nVL Figure 3: Log-odds coef ficients from multivariate logistic re- gression predicting classification accuracy in the object-only condition, as a function of object size, frequency (Freq.), speci- ficity (Spec.), and object type (anchor vs. local). Error bars de- note 95% confidence intervals. Significance levels: ∗∗ p < . 01 , ∗∗∗ p < . 001 . Specificity is non-significant for LLaV A but becomes a signifi- cant ne gati ve predictor for In- ternVL ( ˆ β spec = − 0 . 25 , p < . 001 ). This suggests that objects highly diagnostic of a single fine- grained scene are acti vely disad- vantageous for InternVL ’ s super- ordinate categorization once size and frequency are controlled, pos- sibly because such objects are strongly associated with a spe- cific indoor or outdoor scene in a way that does not generalize to the broader category level. Object type does not significantly predict superordinate accuracy in either model. 4 . 3 C O N T E X T U A L P R E D I C T I O N S A R E PA RT I A L L Y D I S S O C I A B L E F RO M O B J E C T I D E N T I T Y The analyses in Section 4.1 and Section 4.2 establish that objects carry partial scene and super- ordinate information, and that this information is modulated by object properties. Here we ask a complementary question: when models fail, do their errors re veal a systematic relationship between object identity and scene-lev el inference? W e examine this from two angles: whether correct ob- ject identification is necessary for correct scene and superordinate inference (Section 4.3.1), and whether the model’ s scene and superordinate predictions are compatible with its object prediction (Section 4.3.2). 4 . 3 . 1 C O N T E X T UA L I N F E R E N C E D O E S N O T R E Q U I R E C O R R E C T O B J E C T I D E N T I FI C A T I O N T o assess whether scene and superordinate inference depend on correct object identification, we computed classification accuracy in the object-only trials conditioned on whether the model cor- rectly identified the presented object. W e thus compare the scene and superordinate classification ac- curacy when the object was correctly identified, when it w as incorrectly identified, and the marginal (unconditioned) accuracy across all trials (see T able 1). Correct object identification is associated with higher scene accuracy in both models (LLaV A: 65.6% vs. 41.8%; InternVL: 60.4% vs. 31.0%), under both normal and relaxed scoring. This associ- ation is stronger in InternVL, which shows a larger g ap between object-correct and object-incorrect trials than LLaV A (29.4% vs. 23.8% under normal scoring; 24.9% vs. 15.4% under relaxed scor- ing). A similar pattern holds for superordinate classification, though accuracy is generally higher ov erall: correct object identification is associated with higher superordinate accuracy in both models (LLaV A: 96.0% vs. 88.7%; InternVL: 90.6% vs. 67.1%), and the gap is again larger in InternVL. Critically , the link is not perfect in either model: scene and superordinate accuracy remain well abov e zero e ven when the object is misidentified, and below ceiling even when it is correct. This indicates that scene and superordinate schemas are not strictly contingent on correct object identi- fication: the models can retrieve scene-lev el information ev en when they fail to name the object, pointing to scene information being encoded in a partially independent representational pathway . 4 . 3 . 2 C O N T E X T UA L A N D O B J E C T P R E D I C T I O N S A R E N O T A LW A Y S C O M PA T I B L E T o assess whether the model responds coherently across tasks, we assess whether the model’ s pre- dicted scene and predicted superordinate are ones that can plausibly contain the predicted object in the same trial. For example, if in the object classification task the model incorrectly predicted the presence of a bed, it should predict ”bedroom” and ”indoor” in the other classification tasks for the same trial. Inconsistency indicates that the three inferences are not derived from the same underlying representation. 5 T able 1: Scene and superordinate accuracy conditioned on object identification correctness in the object-only condition. Model T ask Obj. correct Obj. incorrect Marginal LLaV A Scene 65.6% (+7.0%) 41.8% (-16.8%) 58.6% Scene (relaxed) 90.0% (+4.5%) 74.6% (-10.9%) 85.5% Superordinate 96.0% (+2.2%) 88.7% (-5.1%) 93.8% InternVL Scene 60.4% (+7.0%) 31.0% (-22.4%) 53.4% Scene (relaxed) 90.6% (+5.9%) 65.7% (-19.0%) 84.7% Superordinate 90.6% (+5.6%) 67.1% (-17.9%) 85.0% Both models show above-chance consistency . In LLaV A, the predicted superordinate is consistent with the predicted object in 71% of trials, and the predicted scene is consistent with the predicted object in 62% of trials. InternVL shows substantially higher consistency across both measures (su- perordinate: 90%; scene: 84%), indicating that its scene and superordinate predictions more often correspond to plausible conte xts for the object it identified. The gap between the two models is con- siderable: InternVL ’ s scene and superordinate predictions are compatible with its object prediction roughly 20% more often than LLaV A ’ s. Consistency is nonetheless imperfect ev en in InternVL, indicating that the predicted scene and super- ordinate are not always compatible with the predicted object. This residual inconsistency , combined with the partial dissociation between object recognition accuracy and scene inference reported in Section 4.3.1, suggests that scene and superordinate predictions are not strictly deriv ed from the object prediction alone, and different pathw ays are used to answer the tasks. 4 . 4 C O N T E X T U A L I N F E R E N C E I S G RO U N D E D I N O B J E C T - PA T C H R E P R E S E N T A T I O N S The analyses so far characterize what information objects carry about scenes and superordinate categories, and how errors in contextual inference relate to object identity . W e now turn to the question of how this information is grounded mechanistically: where in the network does scene and superordinate information reside, and how does the presence or absence of background context modulate the object’ s internal representation? W e address this through two complementary analyses. Section 4.4.1 examines representational stability (the degree to which object-patch hidden states change when background context is removed) and tests whether this stability predicts classification accuracy across layers. Section 4.5 then asks whether scene and superordinate information is directly decodable from the image vocab ulary space, and at which processing depth it emerges. 4 . 4 . 1 R E P R E S E N TA T I O NA L S TA B I L I T Y P R E D I C T S C O N T E X T U A L I N F E R E N C E A C C U R AC Y The behavioral results establish that objects carry partial scene and superordinate information, and that this is modulated by object properties. A natural mechanistic question follows: does the object’ s internal representation actually change when background context is removed, and if so, does the degree of that change predict whether scene and superordinate inference succeeds? An object whose representation is robust to context removal, meaning one whose hidden-state activ ations are similar whether or not the background is present, can be said to carry self-sufficient scene information intrinsically , independent of contextual support. Con v ersely , an object whose representation shifts substantially when background is removed relies more heavily on contextual integration with the object representation. W e operationalize this notion as repr esentational stability and test whether it predicts classification accuracy across layers and tasks. T o assess whether object representations are modulated by background context, we computed the cosine similarity between hidden-state activ ations of object-patch tokens under the full-scene and object-only conditions across all transformer layers: CosSim ( ℓ ) i = 1 | P i | X p ∈ P i cos h ( ℓ ) i,p, full , h ( ℓ ) i,p, object (2) 6 where P i is the set of patch indices corresponding to the foreground object of image i , determined by projecting the foreground mask onto the image patch grid and retaining only patches fully covered by the object mask, and h ( ℓ ) i,p is the hidden state of patch p at layer ℓ . A high cosine similarity indi- cates that the object’ s representation is stable re gardless of whether the surrounding scene context is present. InternVL sho ws higher representational stability overall than LLaV A (mean cosine similarity: LLaV A = 0 . 57 ; InternVL = 0 . 68 ), indicating that its object-patch representations are less modulated by the presence or absence of background context. The two models also show distinct layer-wise profiles: InternVL ’ s cosine similarity decreases across layers, while LLaV A ’ s increases (Figure 4; first panel). T o determine whether representational stability predicts classification accuracy , we computed at each layer the difference in mean cosine similarity between correctly and incorrectly classified trials, as- sessing statistical significance via a two-sided permutation test (1,000 permutations) in which trial labels were randomly shuffled to generate a null distribution of mean differences. Correctly classi- fied trials show higher representational stability than incorrectly classified trials across all tasks and both models (Figure 4; second panel): objects whose representations are robust to context remov al carry more self-sufficient scene and superordinate information. The layer at which this dif ference peaks differs between models: in LLaV A the peak occurs in later layers, consistent with context- dependence being primarily a late-layer phenomenon in this model. In InternVL the peak occurs in middle layers, where the overall decrease in cosine similarity across layers is most pronounced, suggesting that the processing stages at which object representations are most sensiti ve to context remov al are also those most critical for correct scene and superordinate inference Notably , object identification accuracy is also positiv ely associated with representational stability , particularly in InternVL, suggesting that context-independent object representations benefit not only scene-lev el inference but object recognition itself. 0 10 20 30 40 Layer 0.5 0.6 0.7 0.8 Cosine similarity 0 10 20 30 40 Layer 0.00 0.05 0.10 0.15 Cosine Similarity 0 10 20 30 40 Layer 0.00 0.02 0.04 0.06 0.08 0.10 0.12 Representational stability Stability: correct vs. incorrect LLaV A InternVL LLaV A Inter nVL Scene Super or dinate Object Figure 4: Representational stability of object-patch tokens across transformer layers. Left: Mean cosine similarity between hidden-state activ ations of object patches under the full-scene and object- only conditions, averaged across all images, for LLaV A and InternVL. Higher values indicate that object representations are less modulated by the presence of background context. Center and right: Difference in mean cosine similarity between correctly and incorrectly classified trials ( ∆ cosine similarity) at each layer . V alues above zero indicate that correctly classified trials hav e more stable object representations. Shaded regions denote 95% confidence interv als. Since cosine similarity is averaged ov er object patches, objects occupying a larger image area con- tribute more patches and could yield more reliable estimates by construction. T o rule out this con- found, we included z-scored object size as a cov ariate in a logistic regression predicting task ac- curacy from z-scored cosine similarity . Cosine similarity remained a significant positiv e predictor of performance across all tasks and both models after controlling for object size (all p < . 001 ; see T able 2 in Appendix). 4 . 5 C O N T E X T U A L I N F O R M AT I O N E M E R G E S D I FF E R E N T LY AC R O S S TA S K S A N D M O D E L S Prior work has shown that semantic information is grounded in image tokens and can be decoded using output v ocabulary projection methods (Neo et al., 2025; Schauml ¨ offel et al., 2026). Here, 7 we use this technique to ask the following question: does this scene and superordinate information emerge directly in the image-patch-le vel v ocabulary space, and if so, at which processing depth? For each image in the object-only condition, we project image patch representations at each layer to the vocab ulary space using the unembedding matrix, and identify the three patches with the highest logit value for the correct scene or superordinate label. W e then compute the mean logit across these top-3 patches as a layer-wise measure of how strongly the correct label is encoded in image tokens. T o test whether logit strength continuously predicts classification accuracy , we computed the R OC-A UC between the mean logits and binary accuracy at each layer . Statistical significance was assessed via a one-sided Mann-Whitney U test comparing logit strength between correctly and incorrectly classified trials at each layer . 0 5 10 15 20 25 30 35 40 Layer 0.3 0.4 0.5 0.6 0.7 0.8 ROC- AUC LLaV A 0 5 10 15 20 25 30 35 40 Layer InternVL Scene Super or dinate Figure 5: R OC-A UC between top-3 patch logit strength and binary classification accuracy at each transformer layer . V al- ues abov e the dashed line indicate that logit strength in im- age patch tokens is predictiv e of classification accuracy at that layer . Markers indicate statistically significant layers. W e found that scene logit strength is a strong and consistent predictor of scene classification accuracy in both models from the v ery first trans- former layer (LLaV A: AU C = 0 . 67 ; InternVL: AU C = 0 . 63 ), increas- ing to a peak of approximately 0 . 81 and 0 . 79 respectiv ely in mid-to-late layers (Figure 5). The signal is sig- nificant across nearly all layers in both models, indicating that scene- discriminativ e information is present in image tok ens throughout the entire depth of the network. Superordinate accuracy tells a dif ferent story . In LLaV A, superordinate A UC remains below chance for the majority of the network, only crossing chance le vel in the final fe w layers, indicating that the vocab ulary projection of image tokens is not predictiv e of superordinate categorization for most of the netw ork’ s depth. In InternVL, superordinate A UC be gins near chance, then rises steadily to 0 . 85 around layers 25–28, ev entually exceeding scene A UC at its peak before declining. Superordinate information thus emerges in image tok ens in InternVL, but later than scene information. These results rev eal a fundamental dissociation in how scene and superordinate schemas are grounded in image tokens. Scene identity is encoded in the patch-le vel vocab ulary space from the earliest layers and persists throughout processing in both models. Superordinate categoriza- tion, by contrast, is not meaningfully encoded in this space in LLaV A at any depth, suggesting it is computed through a different mechanism. In InternVL, superordinate information does eventually emerge in image tokens, but through a slower , depth-dependent process distinct from scene encod- ing. T ogether, these findings provide mechanistic e vidence that scene and superordinate schemas are not co-localized in image token representations, and that model architecture critically deter- mines whether and where superordinate information becomes accessible in the visual processing stream of the VLM. 5 D I S C U S S I O N A central question in scene perception research is whether scene understanding is an emergent prop- erty of object representations, or whether it requires holistic scene-level processing that cannot be reduced to indi vidual objects. W ork in human psychophysics has established that single objects can support above-chance scene categorization and that this capacity is modulated by the same statistical properties that predict object-scene co-occurrence in natural images (Wiesmann & V ˜ o, 2023). Our results show that VLMs exhibit a qualitativ ely similar capacity: single objects activ ate scene-level and superordinate schemas above chance, with performance modulated by the same object prop- erties as humans. This con ver gence suggests that the statistical structure of natural scene-object relationships is internalized during training of VLMs in a way that recapitulates key properties of human perceptual learning. In addition, our findings sho w that scene inference is partially independent of object identification: scene and superordinate accuracy remain well above zero even when the model fails to identify the 8 object, and scene and superordinate predictions are not always compatible with the object prediction ev en in InternVL, which shows the highest internal consistency . This suggests that contextual in- ference draws at least partially on representational pathways that are distinct from those underlying object identification. W e also found e vidence that scene and superordinate classification in v olve different processing. Behaviorally , scene and superordinate performance differ . Moreov er , scene accuracy is driv en by specificity and frequency , while superordinate is dominated by object size. The dependence on correct object identification also dif fers: correctly identifying the object yields a lar ger boost for scene than for superordinate classification in both models. Mechanistically , scene identity is encoded in image tokens from the first layer throughout the network, while superordinate information is absent from LLaV A ’ s image tokens at an y depth and emerges only late in InternVL. Finally , the two models differ in how tightly all of these lev els are integrated, and this difference is visible across every analysis. InternVL shows stronger coupling between object identification and contextual inference, higher behavioral consistency across tasks, higher representational stability , and evidence of both scene and superordinate being grounded in image tokens. LLaV A processes the three tasks with greater modularity: its object recognition is disrupted by scene context, its predictions are less internally coherent, its representational stability is more brittle to contextual remov al, and its superordinate representations are not grounded in the vocab ulary space of image tokens. Critically , these differences form a coherent pattern. A model that binds object, scene, and superordinate information into a more integrated representational structure makes more internally coherent errors, shows stronger behavioral coupling across tasks, and grounds more of its predic- tions in visual rather than purely linguistic processing. Understanding what drives this dif ference in integration, whether through architecture, pretraining data, or instruction-tuning, is a key direction for future work, and may illuminate what computational conditions are necessary for the kind of integrated scene-object processing. 5 . 1 L I M I TA T I O N S In this work, we ev aluate a fixed set of eight scene categories; while these were selected to be repre- sentativ e of both indoor and outdoor environments, generalizability to a broader or more fine-grained taxonomy remains to be tested. Second, we ev aluate two models; while LLaV A and InternVL were chosen as widely used representati ves that remain architecturally distinct, the degree to which the results generalize across other model families warrants further inv estigation. Finally , while our find- ings parallel human scene categorization in se veral respects, a direct comparison with human behav- ioral data on the same stimuli would be needed to quantify the degree of alignment more precisely , and would open the door to testing the speculative predictions about representational entanglement raised in this work. Similarly , further mechanistic work is needed to characterize the nature of the distinct internal representations underlying object identification, scene inference, and superordinate categorization within the network. R E F E R E N C E S W ei-Lin Chiang, Zhuohan Li, Zi Lin, et al. V icuna: An open-source chatbot impress- ing gpt-4 with 90%* chatgpt quality , March 2023. URL https://lmsys.org/blog/ 2023- 03- 30- vicuna/ . Michelle R. Greene. Statistics of high-lev el scene context. F r ontier s in Psychology , 4, 2013. ISSN 1664-1078. doi: 10.3389/fpsyg.2013.00777. URL https://doi.org/10.3389/fpsyg. 2013.00777 . Jonathan Huang, V i vek Rathod, Chen Sun, Menglong Zhu, Aliroop K orattikara, Alireza Fathi, Ian Fischer , Zbigniew W ojna, Y ang Song, Sergio Guadarrama, and Ke vin Murphy . Speed/accuracy trade-offs for modern con volutional object detectors. In Pr oceedings of the IEEE Conference on Computer V ision and P attern Recognition , pp. 7310–7311, 2017. Zhaoyang Li, Zhan Ling, Y uchen Zhou, Litian Gong, Erdem Bıyık, and Hao Su. ORIC: Bench- marking object recognition under contextual incongruity in large vision-language models. arXiv pr eprint arXiv:2509.15695 , 2025. 9 Haotian Liu, Chun yuan Li, Y uheng Li, and Y ong Jae Lee. Improv ed baselines with visual instruction tuning. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recogni- tion , 2024. Filippo Merlo, Ece T akmaz, W enkai Chen, and Albert Gatt. Common objects out of context (COOCo): In v estigating multimodal context and semantic scene violations in referential com- munication. arXiv preprint , 2025. Clement Neo, Luke Ong, Philip T orr, Mor Gev a, David Krueger , and Fazl Barez. T owards inter- preting visual information processing in vision-language models. In International Confer ence on Learning Repr esentations , pp. 25461–25478, 2025. Karim Rajaei, Radoslaw Martin Cichy , and Hamid Soltanian-Zadeh. Does human-like contextual object recognition emerge from language supervision and language-guided inference? bioRxiv , 2025. doi: 10.1101/2025.07.24.666375. T imothy Schauml ¨ offel, Martina G. V ilas, and Gemma Roig. Mechanisms of object localization in vision–language models. In Pr oceedings of the Computer V ision and P attern Recognition Confer ence (CVPR) , June 2026. Jacopo T urini and Melissa Le-Hoa V ˜ o. Hierarchical organization of objects in scenes is re- flected in mental representations of objects. Scientific Reports , 12(1):20068, 2022. ISSN 2045-2322. doi: 10.1038/s41598- 022- 24505- x. URL https://doi.org/10.1038/ s41598- 022- 24505- x . W eiyun W ang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang W ei, Zhaoyang Liu, et al. Intern vl3.5: Advancing open-source multimodal models in versatility , reasoning, and effi- ciency . arXiv preprint , 2025. Sandro L. W iesmann and Melissa L.-H. V ˜ o. Disentangling diagnostic object properties for human scene categorization. Scientific Reports , 13(1):5912, 2023. doi: 10.1038/s41598- 023- 32385- y. An Y ang, Anfeng Li, Baosong Y ang, et al. Qwen3 technical report, 2025. URL https://arxiv. org/abs/2505.09388 . Bolei Zhou, Hang Zhao, Xavier Puig, T ete Xiao, Sanja Fidler, Adela Barriuso, and Antonio T orralba. Semantic understanding of scenes through the ade20k dataset. International J ournal of Computer V ision , 127(3):302–321, 2019. A M O D E L D E TA I L S W e compare two vision-language models (VLMs): LLaV A 1.5-13B (Liu et al., 2024) ( llava-hf/llava-1.5-13b-hf ) and InternVL3.5-14B (W ang et al., 2025) ( OpenGVLab/InternVL3 5-14B-HF ), both accessed via the HuggingFace Transformers library . LLaV A-1.5-13B. LLaV A connects a visual backbone to a lar ge language model (LLM) via a two- layer MLP projection. Input images are padded to a square aspect ratio and resized to 336 × 336 pixels. The visual backbone produces 24 × 24 patch embeddings, which are projected into the LLM embedding space, yielding 576 visual tokens per image. InternVL3.5-14B. InternVL follows a similar architectural principle but extends LLaV A in two key ways. First, the visual encoder accepts higher-resolution 448 × 448 pixel inputs. Second, each 2 × 2 block of visual tokens is compressed into a single token via pixel shuffling before being forwarded to the LLM, reducing the spatial grid from 32 × 32 to 16 × 16 tok ens (256 tokens total). InternVL also supports dynamic high-resolution processing, in which an image is split into multiple sub-images that are each encoded independently . Since our inputs are generally small, we restrict this to a single view for all e xperiments. 10 B D A TA S E T P R E P R O C E S S I N G W e apply fi v e sequential filtering steps to obtain a clean and balanced set of object–scene pairs (with corresponding segmentation masks) from Greene (2013): 1. Scene category selection . Only annotations belonging to eight scene categories (bath- room, bedroom, kitchen, living room, coast, forest, mountain, skyline) are retained. These categories provide a representati ve spread of both indoor and outdoor en vironments with high between-category discriminability . 2. Occlusion removal . Images in which any anchor object’ s segmentation mask is covered by ≥ 50% of surrounding local object masks are discarded. This ensures that anchor objects are not heavily occluded and remain recognizable. 3. Rare object remov al . Object categories appearing in fewer than 10 images are discarded. This av oids including object categories that are too infrequent in natural scene statistics. 4. Minimum size threshold . Objects whose segmentation mask cov ers ≤ 3% of the image area are remov ed, as objects of this size provide insuf ficient visual information for reliable recognition (Huang et al., 2017). 5. Balanced per-category subsampling . For each scene category , up to 150 anchor objects and 150 local objects are randomly sampled, ensuring comparable sample sizes across categories. C C L A S S I FI C AT I O N T A S K D E T A I L S Each image w as presented to the model with three successive forced-choice prompts, constructed in- dependently per image. All prompts used an enumerated format, in which answer options were listed with numerical indices and the model was instructed to respond in the exact format [number]. [category name] . Scene classification prompt. The eight scene category labels were randomly shuffled on each trial and presented as a numbered list. The full prompt read: Infer the scene cate gory fr om the imag e. A vailable cate gories: 1. [cate gory σ (1) ] . . . 8. [cate gory σ (8) ] Respond in this exact format: [number]. [category name] For the object-only condition, the preamble was replaced with: “The image shows a se gmented object with the backgr ound masked in gray . Infer the scene category fr om the pr esented object. ” A response was scored as correct if either the ground-truth category name or its assigned index appeared in the model’ s output. Superordinate classification pr ompt. The two options ( indoor , outdoor ) were randomly shuf fled on each trial and presented in the same enumerated format: Infer the scene cate gory fr om the imag e. A vailable cate gories: 1. [indoor or outdoor] 2. [outdoor or indoor] Respond in this exact format: [number]. [category name] Object classification prompt. The candidate set consisted of the target object plus one distractor randomly sampled from each of the remaining scene categories, drawn from a pre-compiled list of scene-typical objects. This yielded N scenes options in total, which were randomly shuf fled and presented in enumerated format: 11 Identify the object cate gory pr esent in the image . A vailable cate gories: 1. [object σ (1) ] . . . N . [object σ ( N ) ] Respond in this exact format: [number]. [category name] For the object-only condition the preamble read: “The image shows a se gmented object with the backgr ound masked in gray . Identify the object category pr esent in the ima ge. ” Implementation details. All random shuffling and distractor sampling used a fix ed global random seed (seed = 42 ), set once before the dataset loop, ensuring reproducibility across runs. Model responses were generated greedily . D S C E N E C L A S S I FI C A T I O N A C C U R A C Y B Y S C E N E T Y P E bathr oom bedr oom kitchen living r oom sk yline coast for est mountain 0% 20% 40% 60% 80% 100% Scene A ccuracy 0.55 0.42 0.47 0.61 0.77 0.49 0.68 0.70 0.84 0.76 0.84 0.85 0.84 0.86 0.92 0.92 LLaV A bathr oom bedr oom kitchen living r oom sk yline coast for est mountain 0.51 0.43 0.49 0.34 0.71 0.58 0.63 0.59 0.85 0.66 0.79 0.73 0.87 0.96 0.96 0.96 InternVL Indoor Outdoor Nor mal R elax ed Figure 6: Scene classification accuracy in the object-only condition by scene category , for LLaV A and InternVL. Solid bars indicate normal accuracy (exact label match) and hatched bars indicate relaxed accuracy (any semantically valid label accepted). Orange bars correspond to indoor scene categories (bathroom, bedroom, kitchen, living room) and blue bars to outdoor categories (skyline, coast, forest, mountain). Error bars denote the standard error of the mean. D . 0 . 1 C O N T E X T UA L I N F E R E N C E F RO M S I N G L E O B J E C T S H A S P OT E N T I A L F O R I M P RO V E M E N T T o quantify how much room exists for improving object-only contextual inference in VLMs, we establish a reference by measuring how well scene and superordinate categories can be inferred from the object label alone. W e compare two variants: a mean-token baseline, which replaces the image with a semantically uninformativ e av erage visual token while providing the object name in the prompt, and a pure LLM baseline, which uses the LLM backbone of the VLM model that was trained exclusi vely on language data. For LLaV A this is V icuna-13B (Chiang et al., 2023) ( lmsys/vicuna-13b-v1.5 ), and for InternVL this is Qwen3-14B (Y ang et al., 2025) ( Qwen/Qwen3-14B ). As prompts for the baselines, the object name is inserted into the prompt in place of the image, with scene and superordinate classification prompts otherwise unchanged. Thus, the prompt takes the form of: The image shows a [object]. [scene classification pr ompt or super or dinate classification pr ompt] . For scene classification, relaxed scoring provides the more meaningful comparison: because a single object label is naturally consistent with multiple scene categories, normal scoring penalizes valid associations and systematically underestimates label-based inference. Under relaxed scoring, both models fall short of the mean-token baseline (LLaV A: 0.85 vs. 0.90; InternVL: 0.85 vs. 0.95). Relativ e to each model’ s own LLM baseline, the pattern differs: LLaV A exceeds it (0.85 vs. 0.79), indicating that the visual token adds scene-associative information beyond what LLaV A ’ s language 12 backbone recov ers from the label alone, while InternVL falls below it (0.85 vs. 0.94), indicating that InternVL ’ s visual token fails to match what its stronger language backbone infers from the label. For superordinate classification, both models f all belo w at least one baseline (LLaV A: 0.94 vs. MT 0.95, LLM 0.99; InternVL: 0.85 vs. MT 0.94, LLM 0.93), with InternVL again showing the largest gap. T ogether , these results indicate that current VLMs lea ve meaningful performance on the table in object-only contextual inference, pointing to substantial room for impro vement. Scene Super or dinate 0% 20% 40% 60% 80% 100% A ccuracy 0.59 0.85 0.59 0.90 0.52 0.79 0.94 0.95 0.99 LLaV A Scene Super or dinate 0.53 0.85 0.67 0.95 0.64 0.94 0.85 0.96 0.93 InternVL VLM Object Only VLM Mean T ok ens LLM Nor mal R elax ed (Scene only) Figure 7: Scene and superordinate classification accuracy for the object-only condition compared to label-based baselines. VLM Object Only sho ws VLM performance when only the foreground object is visible. VLM Mean T okens replaces the image with a semantically uninformative a verage visual token while providing the object name in the prompt. LLM receiv es the object name but no image. For scene classification, solid bars indicate normal accuracy and hatched bars indicate relaxed accu- racy . Superordinate classification uses normal scoring only . Error bars denote the standard error of the mean. E O B J E C T - S I Z E C O N T RO L I N R E P R E S E N T A T I O NA L S T A B I L I T Y T able 2: Logistic regression predicting task accuracy from cosine similarity and object size (both z-scored). Coef ficients are log-odds. Object size is included as a control for the number of patches contributing to the cosine similarity estimate. Model T ask Predictor ˆ β SE z p LLaV A Scene Cosine sim. 0.487 0.051 9.54 < . 001 Object size 0.385 0.061 6.30 < . 001 Superordinate Cosine sim. 1.017 0.109 9.36 < . 001 Object size 1.344 0.302 4.46 < . 001 Object Cosine sim. 0.728 0.058 12.57 < . 001 Object size -0.373 0.056 -6.71 < . 001 InternVL Scene Cosine sim. 0.465 0.051 9.06 < . 001 Object size 0.443 0.058 7.59 < . 001 Superordinate Cosine sim. 0.567 0.069 8.16 < . 001 Object size 0.916 0.141 6.51 < . 001 Object Cosine sim. 0.910 0.066 13.73 < . 001 Object size 0.161 0.080 2.01 . 044 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment