단일 객체로부터 장면 맥락 추론하기
본 논문은 마스크 처리된 배경 없이 단일 객체만을 제시했을 때, 최신 비전‑언어 모델(VLM)이 장면 카테고리와 실내·실외와 같은 상위 맥락을 얼마나 정확히 추론할 수 있는지를 체계적으로 조사한다. 실험 결과, 두 모델(LLaVA 1.5‑13B, InternVL 3.5‑14B)은 객체만으로도 위 수준의 맥락 정보를 위계적으로 활용하지만, 정확도와 내부 메커니즘은 모델마다 크게 다르며, 객체 정체성 자체와는 부분적으로 독립적인 경로를 통해 맥락이…
저자: Martina G. Vilas, Timothy Schaumlöffel, Gemma Roig
**연구 배경 및 목적**
인간은 단일 물체만 보고도 해당 물체가 주로 등장하는 장면을 빠르게 추론한다는 것이 심리학 연구에서 잘 알려져 있다. 이러한 인간의 능력이 인공지능, 특히 비전‑언어 모델(VLM)에도 존재하는지, 그리고 그 메커니즘이 어떻게 구현되는지는 아직 명확히 밝혀지지 않았다. 본 논문은 “단일 객체만으로 장면 맥락을 추론할 수 있는가?”라는 질문을 행동적(성능)과 기계적(내부 표현) 두 차원에서 체계적으로 탐구한다.
**관련 연구**
기존 연구는 주로 배경이 있는 상황에서 객체 인식이 어떻게 향상·저해되는지를 다루었으며, 컨텍스트 불일치가 VLM의 객체 인식에 미치는 영향을 조사했다. 반면, 본 연구는 배경을 완전히 제거하고 객체 자체가 제공하는 통계적 단서가 VLM의 장면·상위 맥락 추론에 어떤 역할을 하는지에 초점을 맞춘다. 또한, 이미지 토큰이 언어 어휘와 어떻게 매핑되는지에 대한 최근 연구를 차용해, 객체 토큰이 맥락 정보를 어떻게 보유하고 있는지 분석한다.
**데이터 및 실험 설계**
- **데이터**: Greene(2013)에서 추출한 2,392개의 객체‑장면 쌍을 사용했으며, 1,004개의 고유 이미지에 대해 8가지 장면 카테고리(욕실, 침실, 주방, 거실, 해변, 숲, 산, 스카이라인)를 선정했다. 각 객체에 대해 ‘빈도’, ‘특이도’, ‘크기’, ‘객체 유형(앵커 vs. 로컬)’ 네 가지 속성을 사전 계산하였다.
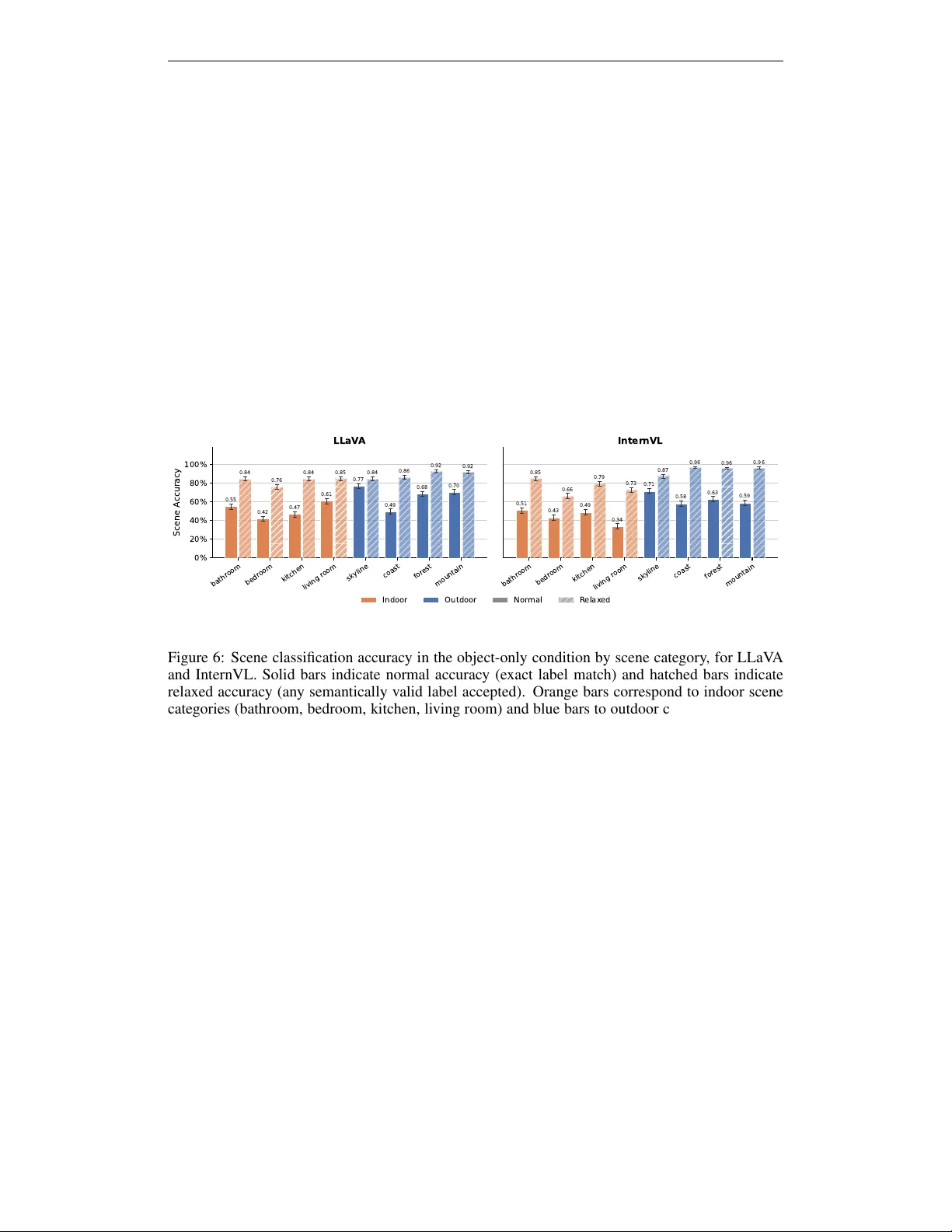
- **조건**: (1) Full‑scene: 원본 이미지, (2) Object‑only: 객체만 남기고 나머지를 회색 마스크 처리.
- **과업**: (A) 장면 카테고리 8선택, (B) 실내·실외 상위 카테고리 2선택, (C) 객체 정체성 8선택(정답 객체 + 각 다른 장면에서 추출된 7개의 오답).
- **평가**: 장면 카테고리는 ‘정확도(normal)’와 ‘완화 정확도(relaxed)’ 두 가지 지표를 사용했다. 완화 정확도는 객체가 등장한 다른 장면이라도 정답으로 인정한다.
**주요 결과**
1. **전체 성능**
- Full‑scene에서는 두 모델 모두 96‑97% 수준의 거의 완벽한 장면 인식 정확도를 기록.
- Object‑only에서는 장면 카테고리 정확도가 LLaVA 58.6%, InternVL 53.4%로 크게 감소했지만, 완화 정확도는 각각 85.5%와 84.7%에 달해, 모델이 ‘가능성 있는’ 장면을 잘 추론함을 보여준다.
- 실내·실외 구분은 object‑only에서도 93.8% (LLaVA)와 85.0% (InternVL)로 높은 유지율을 보이며, 인간의 상위 맥락 판단과 유사한 패턴을 나타낸다.
2. **객체 속성의 영향**
- 다변량 로지스틱 회귀 결과, 장면 카테고리 예측에서는 ‘특이도’가 가장 큰 양의 β(≈0.78)값을 가지며, ‘빈도’와 ‘크기’도 유의미하게 기여한다.
- 상위 카테고리(실내·실외)에서는 ‘크기’가 압도적인 β(≈1.80)값을 보여, 큰 객체가 실외/실내 구분에 핵심적인 단서임을 확인했다. ‘빈도’도 양의 영향을 주지만, ‘특이도’는 InternVL에서 오히려 부정적(β≈‑0.25)으로 나타나, 특정 장면에 강하게 결부된 객체가 상위 맥락 일반화에 방해가 될 수 있음을 시사한다.
- ‘객체 유형’은 두 과업 모두에서 통계적으로 유의하지 않아, 앵커와 로컬 객체의 차이가 다른 속성과 겹쳐서 별도 효과를 내지 못한다는 결론을 얻었다.
3. **객체 정체성과 맥락 추론의 관계**
- 객체를 정확히 맞춘 경우와 틀린 경우를 별도로 분석한 결과, 올바른 객체 인식이 장면 정확도를 20‑30%p 상승시켰지만, 객체가 오인식된 상황에서도 여전히 30‑40%p 수준의 장면 추론이 가능했다. 이는 맥락 스키마가 객체 정체성과는 부분적으로 독립적인 경로로 존재함을 의미한다.
- 실내·실외 구분에서도 동일한 경향이 관찰돼, 객체 정체성에 의존하지 않는 상위 맥락 정보가 별도 인코딩된다는 점을 뒷받침한다.
4. **내부 토큰 표현 분석**
- 객체 패치에 대응하는 이미지 토큰을 추출하고, 배경 유무에 따른 토큰 변화량을 측정했다. 배경이 사라져도 변동이 적은 ‘stable tokens’가 높은 맥락 추론 정확도와 강한 상관관계를 보였다. 이는 해당 토큰이 객체 자체에 내재된 장면 정보를 보존한다는 증거다.
- 장면 카테고리 정보는 네트워크 전 층에 걸쳐 분산되어 나타나는 반면, 실내·실외와 같은 상위 카테고리 정보는 후반부 레이어에서만 뚜렷이 나타나거나 전혀 나타나지 않았다. 이는 두 수준의 맥락이 서로 다른 깊이의 표현을 통해 인코딩된다는 의미다.
5. **모델 간 차이점**
- LLaVA는 object‑only 상황에서 객체 인식 정확도가 오히려 상승(62%→71%)했으며, 이는 배경이 오히려 방해 요소였을 가능성을 시사한다. 반면 InternVL은 배경이 있을 때 객체 인식이 더 높아(91%→76%) 모델마다 배경 활용 방식이 다름을 보여준다.
- InternVL은 특이도가 높은 객체에 대해 상위 카테고리 추론이 감소하는 부정적 회귀계수를 보이며, 특정 장면에 강하게 결부된 객체가 상위 맥락 일반화에 방해가 될 수 있음을 드러낸다.
**의의 및 향후 연구**
본 연구는 VLM이 단일 객체만으로도 장면 및 상위 맥락 정보를 부분적으로 추론할 수 있음을 실증했으며, 그 메커니즘이 ‘객체‑맥락’ 경로와 ‘상위‑맥락’ 경로로 구분된다는 새로운 관점을 제시한다. 이는 모델의 견고성 평가, 오류 진단, 그리고 더 나은 맥락 인식을 위한 설계(예: 객체‑맥락 디코더 별도 구축, 상위 맥락 전용 토큰 흐름 강화) 등에 실질적인 인사이트를 제공한다. 향후 연구에서는 다양한 도메인(예: 의료·위성 영상)과 더 큰 규모의 VLM을 대상으로 동일한 분석을 확장하고, 객체‑맥락 관계를 학습시키는 사전 훈련 전략을 탐색함으로써, 인간 수준의 맥락 추론 능력에 한층 가까운 모델을 개발할 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기