GTS: Inference-Time Scaling of Latent Reasoning with a Learnable Gaussian Thought Sampler
Inference-time scaling (ITS) in latent reasoning models typically relies on heuristic perturbations, such as dropout or fixed Gaussian noise, to generate diverse candidate trajectories. However, we show that stronger perturbations do not necessarily …
Authors: Minghan Wang, Ye Bai, Thuy-Trang Vu
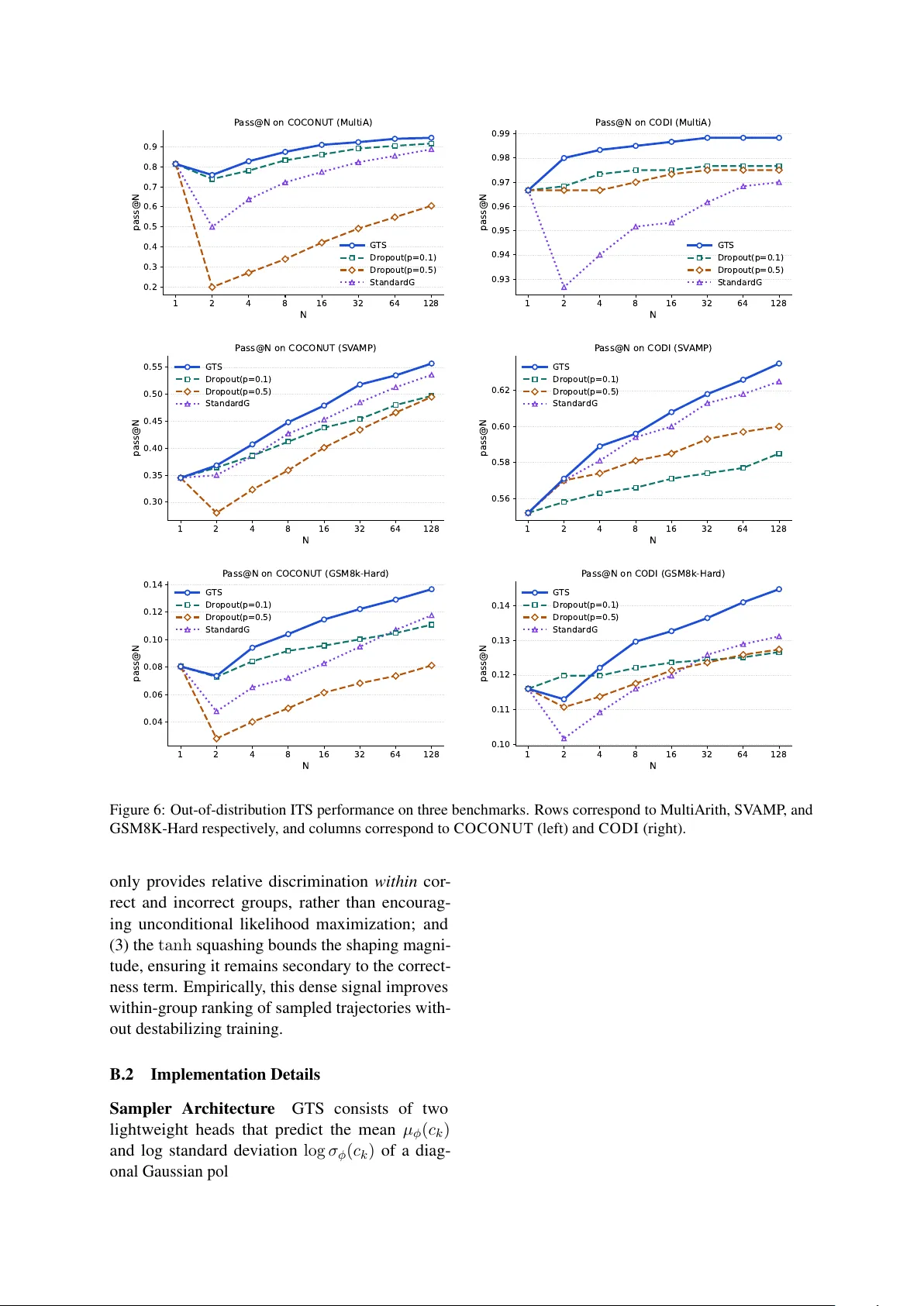
GTS: Infer ence-T ime Scaling of Latent Reasoning with a Learnable Gaussian Thought Sampler Minghan W ang 1 , Y e Bai 2 , Thuy-T rang V u 1 , Ehsan Shareghi 3 , Gholamreza Haffari 1 1 Department of Data Science & AI, Monash Uni versity 2 Faculty of Medicine Dentistry and Health Sciences, Uni v ersity of Melbourne 3 Department of Computer Science, Uni versity Colle ge London {minghan.wang,trang.vu1,gholamreza.haffari}@monash.edu ye.bai2@student.unimelb.edu.au ehsan.shareghi@ucl.ac.uk Abstract Inference-time scaling (ITS) in latent reasoning models typically relies on heuristic perturba- tions, such as dropout or fixed Gaussian noise, to generate div erse candidate trajectories. Ho w- ev er , we show that stronger perturbations do not necessarily yield better sampling quality: they often induce lar ger distribution shifts with- out producing more useful reasoning paths or better final decisions. A key limitation is that these perturbations inject stochasticity without defining an explicit conditional sampling dis- tribution, making latent exploration difficult to control or optimize. T o address this, we propose the Gaussian Thought Sampler (GTS), a lightweight module that reformulates latent exploration as sampling from a learned con- ditional distribution ov er continuous reason- ing states. GTS predicts context-dependent perturbation distributions and is trained with GRPO-style policy optimization while keeping the backbone frozen, turning heuristic perturba- tion into an explicit probabilistic sampling pol- icy . Experiments across multiple benchmarks and two latent reasoning architectures show that GTS yields more reliable inference-time scaling than heuristic baselines, suggesting that effecti ve latent ITS requires better-controlled and optimizable sampling rather than simply amplifying stochasticity . 1 1 Introduction Inference-time scaling (ITS) has emerged as a cen- tral mechanism for enhancing the reasoning per- formance of large language models (LLMs). By allocating additional test-time compute to generate and select among multiple reasoning trajectories, approaches such as self-consistency and best-of- N sampling significantly improve accuracy without modifying model parameters ( W ang et al. , 2023 , 2024 ; Cobbe et al. , 2021 ; Lightman et al. , 2024 ). 1 Code and data will be av ailable with publication. In discrete, token-based LLMs, such scaling is nat- urally supported by explicit conditional distrib u- tions ov er next tokens. Sampling strategies such as temperature scaling or nucleus sampling operate directly on these distrib utions, implicitly trading of f di versity and likelihood under a probabilistic frame work. Recent adv ances in continuous latent reasoning introduce a dif ferent computational regime. These models perform multi-step reasoning directly in hidden state space, refining latent thought repre- sentations without generating intermediate textual tokens ( Hao et al. , 2024 ; Shen et al. , 2025 ; Sui et al. , 2025 ; Zhu et al. , 2025 ). While this paradigm im- prov es reasoning ef ficiency and expressi vity , it also remov es the explicit token-le vel probability distri- butions that enable principled sampling in discrete models. As a result, ITS in latent reasoning models typically relies on heuristic perturbations, such as dropout or injecting fixed Gaussian noise ( W ang et al. , 2025 ; Y ou et al. , 2026 ). These perturbations introduce stochasticity , but they do not define an explicit sampling distrib ution over latent thoughts. W e therefore re visit sampling in ITS through the lens of exploration over r easoning trajectories at inference time 2 , which raises a fundamental ques- tion: what constitutes effective exploration in continuous r easoning space? Our analysis (§ 2 and § 5 ) rev eals that the key challenge in latent ITS is not simply ho w much perturbation to inject, but ho w e xploration is properly controlled. Existing methods, such as dropout or fix ed Gaussian noise, rely on manually chosen perturbation scales that are highly sensitiv e to the backbone, task, and latent geometry , making them prone to under- or ov er- exploration (i.e., ov erly concentrated or e xcessiv ely dif fuse search). Moreover , these methods mainly alter sampling di versity , whereas effecti ve ITS de- pends not only on div ersity , but also on whether 2 W e formalize this notion of exploration in § 2.1 . 1 sampling shifts the model’ s belief to ward regions that better support the correct answer , as illustrated in Figure 1 . Finally , heuristic perturbations do not define an explicit conditional sampling distrib ution, leaving latent thought sampling as a hand-crafted stochastic process rather than a principled, optimiz- able policy . T o address this limitation, we reformulate latent exploration as conditional sampling ov er continu- ous thought representations. Specifically , we in- troduce a Gaussian Thought Sampler (GTS), a lightweight module that goes beyond fixed noise scaling by predicting context-dependent Gaussian perturbation distributions ov er latent reasoning states. This turns latent exploration from a heuristic perturbation mechanism into an explicit probabilis- tic sampling policy , bringing latent ITS closer to the distrib utional perspecti ve that underlies token- le vel inference-time scaling. Across multiple latent reasoning backbones and benchmarks, GTS consis- tently improv es scaling performance over dropout- based and standard Gaussian perturbations, sho w- ing that ef fective latent ITS requires not just more stochasticity , but better -guided sampling. Our con- tributions are as follo ws: • W e identify a key limitation of heuristic latent ITS: effecti ve scaling requires controlling sam- pling quality , not just injecting stochasticity . • W e propose GTS to reformulate latent pertur- bation as conditional sampling, turning heuristic perturbation into an explicit and optimizable sam- pling policy . • Across multiple backbones and benchmarks, we sho w that this principled sampling view consis- tently outperforms dropout-based and standard Gaussian perturbations. 2 Diagnostic Analysis of Heuristic Sampling 2.1 Exploration as T rajectory Sampling in ITS ITS improves reasoning by allocating additional test-time compute to generate multiple candidate trajectories and then selecting or aggreg ating their resulting answers ( W ang et al. , 2023 ). This proce- dure is closely related to e xploration in reinforce- ment learning (RL): during rollout, a stochastic pol- icy samples multiple trajectories, and performance improv es when exploration increases the chance of reaching a better outcome ( Sutton and Barto , 1998 ; Stiennon et al. , 2022 ; DeepSeek-AI et al. , 2025 ). Moti vated by this parallel, we formalize ITS as ex- ploration over reasoning trajectories at inference time. Giv en an input x , let T ( x ) denote the set of v alid reasoning trajectories for x , and let π ( τ | x ) be the stochastic policy used in the inference-time sampling procedure. Under an exploration budget of N , ITS draws τ (1) , . . . , τ ( N ) ∼ π ( · | x ) , τ ( i ) ∈ T ( x ) , (1) and produces the final prediction by selecting or aggregating the answers decoded from these tra- jectories. Unlike RL, ITS does not update π using re ward feedback; exploration is used only to gener- ate candidate trajectories, while performance gains arise from selecting among the sampled outcomes. This perspectiv e also clarifies the role of sam- pling in dif ferent reasoning regimes. In text-based reasoning models, π ( τ | x ) is directly induced by token-le vel stochastic decoding from e xplicit conditional distributions, i.e., by sampling discrete actions from a categorical policy over the vocab- ulary at each reasoning step. In latent reasoning models, in contrast, intermediate reasoning steps are typically generated by deterministic state tran- sitions, h det t +1 = f θ ( h det t , x ) , (2) which do not directly define a stochastic trajec- tory distribution (where f θ is the LLM and h det is the deterministic hidden state). Existing methods, therefore, introduce stochasticity by perturbing la- tent dynamics, for example ˜ h t +1 = f θ ( ˜ h t , x ) + z t , (3) where z t is a stochastic perturbation. Such pertur- bations induce trajectory sampling in latent space and thereby enable exploration. Under finite budgets, the central issue is not merely whether exploration produces dif ferent tra- jectories, but whether it produces useful ones. W e therefore focus on exploration quality : whether the induced sampling policy tends to generate rea- soning trajectories that move the model’ s predic- ti ve belief toward the correct answer , rather than merely introducing random variation. This leads to the core question of this section: do heuristic perturbations provide effective exploration in latent reasoning models, or do they mostly add stochasticity without improving the chance of finding a correct answer? T o answer this, we iso- late and ev aluate sampling quality independently of end-task accuracy . 2 2.2 Experimental Setup Models W e e v aluate a text-based reasoning model, i.e., GPT -2 ( Radford et al. , 2019 ) fine-tuned on GSM8K-Aug ( Deng et al. , 2023 ), and a la- tent reasoning model, C O C O N U T , b uilt on the same backbone. GPT -2 produces textual reason- ing follo wed by the delimiter " ### “ before answer generation. C O C O N U T performs K = 6 latent reasoning steps, following prior implementation details ( Hao et al. , 2024 ). Sampling Protocol For each input x in the GSM8K-test ( Cobbe et al. , 2021 ) dataset, we gen- erate N = 32 reasoning trajectories by applying sampling only to the reasoning stage. For each trajectory τ , we quantify the predictive probabil- ity of the first ground-truth answer tok en y ⋆ 1 using teacher forcing after appending the answer pre- fix. Since GSM8K answers are numeric, we focus on y ⋆ 1 to reduce multi-token noise while preserv- ing decision information. GPT -2 uses token-le vel sampling (temperature 1 . 0 ) and dropout sampling ( p ∈ { 0 . 1 , 0 . 5 } ). C O C O N U T applies dropout- based perturbations in latent space. 2.3 Measuring Sampling Quality Let τ det denote the deterministic reasoning trajec- tory , and let p ( y ⋆ 1 | x, τ ) be the predictiv e probabil- ity of the first correct answer token. Sampling Gain (SG) W e define trajectory-lev el gain as the change in log-odds of the correct an- swer: ∆( τ ) = s ( τ ) − s ( τ det ) , (4) s ( τ ) = log p ( y ⋆ 1 | x, τ ) 1 − p ( y ⋆ 1 | x, τ ) (5) Positi ve ∆( τ ) indicates improved decision confi- dence relativ e to the deterministic baseline. T o reflect best-of- N selection, we define SG( x ) = max k ≤ N ∆( τ k ) , (6) and report the dataset-le vel mean SG. Sampling Gain Rate W e additionally report the fraction of inputs with SG( x ) > 0 . 5 , correspond- ing to a substantial increase in decision odds. Distribution Shift W e quantify how much sam- pling shifts the answer distrib ution using the Jensen–Shannon di vergence (JS) between answer - token distrib utions: JS( τ ) = JS p ( · | x, τ ) ∥ p ( · | x, τ det ) . (7) Sampling SG ↑ SG > 0.5 ↑ JS GPT -2 T oken (temp=1.0) 9 . 94 0 . 62 0 . 29 Dropout ( p = 0 . 1 ) 9 . 64 0 . 58 0 . 30 Dropout ( p = 0 . 5 ) 3 . 89 0 . 57 0 . 67 C O C O N U T Dropout ( p = 0 . 1 ) 1 . 09 0 . 61 0 . 05 Dropout ( p = 0 . 5 ) − 0 . 87 0 . 40 0 . 28 T able 1: Preliminary sampling quality analysis on GPT - 2 and C O C O N U T. W e report SG, SG rate, and distri- bution shift (JS). Higher is better for SG and SG rate. Mean JS reflects how strongly sampling alters the model’ s answer distribution, independent of whether such changes are beneficial. 2.4 Results T able 1 rev eals a consistent pattern across both models. For GPT -2, token sampling achiev es the highest SG and SG rate while inducing only mod- erate JS. This suggests that probabilistic token sampling can improve the probability of the cor- rect answer while keeping distribution shift mod- erate under finite budgets. Increasing dropout strength produces a dif ferent effect. While mild dropout ( p = 0 . 1 ) can approximate token sam- pling, stronger dropout ( p = 0 . 5 ) substantially in- creases JS but sharply reduces SG. Larger pertur- bations therefore induce greater distribution shift without reliably impro ving sampling quality . The ef fect is more pronounced in C O C O N U T. Mild latent dropout yields positiv e SG with minimal JS, whereas stronger dropout leads to negati ve SG de- spite increased di vergence. Overall, higher distribution shift does not nec- essarily imply better sampling quality . Across both models, stronger perturbations consistently increase di vergence from the deterministic trajec- tory , but this does not translate into higher SG and can ev en reduce it. This mismatch is especially pronounced in latent reasoning, where heuristic perturbations are more likely to move sampling aw ay from decision-improving regions. These re- sults suggest that effecti ve latent ITS requires more than simply increasing stochasticity , and instead calls for better-controlled sampling mechanisms. 3 Gaussian Thought Sampler 3.1 Overview W e augment a frozen latent reasoning backbone with a learnable, conte xt-conditioned sampling pol- 3 Prompt Latent Reasoning Model with Heuristic Sampling e.g. Dropout / Fixed Gaussian Noise Key Finding: Perturbation strength alone CANNOT reliably determine sampling quality Prompt GTS Sampler (T rainable MLPs, ) Frozen Latent Reasoning Model hidden state Sampled Perturbation GTS learns where and how much to perturb the latent state at each step T oo weak: Restricted paths (Under-exploration) T oo strong: Dispersed paths (Over-exploration) Fail to target decision-improving regions ( ) I. Limitation of Heuristic Sampling II. GTS Sampling Policy III. T raining with Reinforcement Learning ### 32 ### 36 ### 48 ### 32 1.0 + 0.2 = 1.2 -1.0 - 0.3 = -1.3 -1.0 - 0.1 = -1.1 1.0 + 0.1 = 1.1 Sampled T rajectory Reward Correctness ± Confidence Update Policy GRPO Loss Decoded Answer Answer Confidence High GRPO trains GTS toward ITS-improving perturbations High Low Low Rollout Figure 1: Overvie w of GTS . Left: Heuristic latent perturbations cannot reliably control sampling quality: weak noise under -explores, while strong noise o ver-disperses trajectories. Middle: GTS predicts a context-dependent Gaussian perturbation distribution from the deterministic latent state at each step. Right: T rajectories are scored by correctness and confidence, and GRPO trains GTS to fa vor perturbations that improv e inference-time scaling. icy o ver hidden-state perturbations. Instead of injecting heuristic noise into deterministic latent reasoning, GTS models e xploration as an explicit conditional density ov er continuous perturbations. This reformulates inference-time e xploration as a probabilistic modeling problem and enables direct optimization of the sampling mechanism. 3.2 Conditional Latent Sampling Problem Setup Gi ven an input question x , a la- tent reasoning model parameterized by θ performs K latent reasoning steps and then produces an an- swer distribution: p θ ( y | x, h 1: K ) (8) where h k ∈ R d denotes the backbone hidden state at step k . Our goal is to introduce a learnable con- ditional sampling distribution ov er latent perturba- tions while keeping θ fixed. Perturbation V ariable W e introduce a continu- ous perturbation v ariable z k ∈ R d at each reason- ing step and define: ˜ h k = h det k + z k , (9) where h det k is the deterministic hidden state. The perturbed state ˜ h k is fed back into the backbone for subsequent reasoning, yielding a sampled latent trajectory: τ = { ˜ h 1 , . . . , ˜ h K } . Context-Conditioned Gaussian P olicy W e pa- rameterize a conditional Gaussian policy o ver per- turbations: q ϕ ( z k | c k ) = N µ ϕ ( c k ) , diag ( σ 2 ϕ ( c k )) , (10) where c k denotes the conditioning context at step k (in practice, the backbone hidden state h det k ). Sam- pling follo ws the reparameterization: z k = µ ϕ ( c k ) + σ ϕ ( c k ) ⊙ ϵ k , ϵ k ∼ N ( 0 , I ) . (11) Because Equation ( 9 ) defines an af fine transfor- mation with unit Jacobian, the change of variables preserves density . Therefore, learning q ϕ ( z k | c k ) is equiv alent to learning an explicit conditional den- sity over perturbed thought representations ˜ h k . The backbone computation remains unchanged, while GTS governs how perturbations are sampled during latent reasoning. 3.3 Policy Lear ning GTS defines an explicit conditional density o ver la- tent perturbation trajectories. A natural alternativ e would be likelihood-based training, e.g., ELBO- style v ariational objectiv es ( Kingma and W elling , 2022 ). Howe ver , our goal is not to model a latent posterior , but to directly optimize inference-time exploration under task-le vel re wards. The quality of a perturbation trajectory is determined by ITS performance, which are non-differentiable with re- spect to the sampler parameters. W e therefore treat latent perturbations as continuous actions and opti- mize the policy via reinforcement learning. 4 T rajectory Policy F or an input x , a perturbation trajectory τ = { z 1 , . . . , z K } defines a factorized Gaussian policy: log q ϕ ( τ | x ) = K X k =1 log q ϕ ( z k | c k ) . (12) For a diagonal Gaussian, the per-step log-density admits a closed-form expression: log q ϕ ( z k | c k ) = (13) − 1 2 D X d =1 h z k,d − µ k,d σ k,d 2 + 2 log σ k,d + log (2 π ) i . This closed-form density is essential: it enables exact computation of policy likelihoods and density ratios, making policy-gradient optimization well- defined in continuous latent space. Reward Design For each input x , we sample N trajectories and decode answers { a ( i ) } N i =1 during rollout. Let y ⋆ denote the ground-truth answer . The re ward for trajectory i is defined as r ( i ) = r 0 2 I [ a ( i ) = y ⋆ ] − 1 + α s ( i ) , (14) where the first term pro vides a symmetric correct- ness signal and s ( i ) is a confidence-based shaping term deri ved from the normalized log-probability of the generated answer . The shaping term en- courages high-confidence correct trajectories and discourages high-confidence incorrect ones, while remaining secondary to correctness. See Ap- pendix B.1 for more details. GRPO-Style P olicy Optimization T o stabilize policy updates, we maintain a reference sampler q ϕ ref as an exponential mo ving av erage of the cur - rent policy ( Schulman et al. , 2017 ; Ouyang et al. , 2022 ). For trajectory τ ( i ) , we compute the density ratio: ρ ( i ) = q ϕ ( τ ( i ) | x ) q ϕ ref ( τ ( i ) | x ) . (15) Follo wing GRPO-style clipped optimiza- tion ( DeepSeek-AI et al. , 2025 ), the policy gradient objecti ve is: L PG = (16) − E h min ρ ( i ) A ( i ) , clip( ρ ( i ) , 1 − ϵ c , 1 + ϵ c ) A ( i ) i , where A ( i ) denotes the group-normalized adv an- tage computed within each prompt, and 1 ± ϵ c defines the clipping range. W e further regularize the sampler via a KL penalty between the current and reference Gaussian policies: L KL = β E KL q ϕ ( z k | c k ) ∥ q ϕ ref ( z k | c k ) , (17) which also admits a closed-form solution. The final objecti ve is: L GTS = L PG + L KL . (18) This formulation directly optimizes the inference- time exploration distribution in continuous latent space while leaving the base language model un- changed. 4 Experiments 4.1 Experimental Setup Data W e use the GSM8K-aug training corpus adopted in prior latent reasoning work ( Deng et al. , 2023 ). From the full augmented set (386k), we uniformly sample 20k training instances and train all samplers for one epoch. Evaluation is performed on the standard GSM8K ( Cobbe et al. , 2021 ) test set (1319 samples). T o further assess generalization beyond the training distribution, we additionally e valuate the same trained samplers on three out- of-distribution arithmetic reasoning benchmarks: MultiArith ( Roy and Roth , 2015 ), SV AMP ( Patel et al. , 2021 ), and GSM8K-Hard ( Gao et al. , 2023 ). No additional training or hyperparameter tuning is performed for these datasets; all samplers are applied directly at inference time under the same settings as the main experiments. Models W e ev aluate GTS on two latent reason- ing models: C O C O N U T ( Hao et al. , 2024 ) and C O D I ( Shen et al. , 2025 ). For C O C O N U T , we follo w the architecture and protocol described in Hao et al. ( 2024 ), using a GPT -2 backbone with K = 6 latent reasoning steps. For C O D I , we use a L L A M A - 3 . 2 - 1 B ( Grattafiori et al. , 2024 ) back- bone with 6 latent reasoning steps and its recurrent filtering module. In all cases, backbone parameters are frozen and only the Gaussian sampler is trained. GTS Architectur e The sampler consists of lightweight mean and log-standard-deviation heads parameterizing a diagonal Gaussian policy ov er la- tent perturbations. T o av oid premature collapse to a deterministic policy , we enforce a minimum log- standard-de viation during training ( log σ > − 2 . 0 ). 5 1 2 4 8 16 32 64 128 N 0.2 0.3 0.4 0.5 pass@N P ass@N on COCONUT G TS Dr opout(p=0.1) Dr opout(p=0.5) Standar dG 1 2 4 8 16 32 64 128 N 0.42 0.44 0.46 0.48 0.50 0.52 0.54 0.56 0.58 pass@N P ass@N on CODI G TS Dr opout(p=0.1) Dr opout(p=0.5) Standar dG Figure 2: ITS performance under different sampling strategies. Pass@N on C O C O N U T (left) and C O D I (right) as a function of sampling b udget N . All methods coincide at N = 1 , corresponding to deterministic latent reasoning. As N increases, GTS achiev es stronger scaling beha vior than dropout-based sampling and standard Gaussian noise (StandardG), indicating more ef fectiv e exploration of the latent reasoning space. More results of our out-of-distribution e valuation on the other 3 benchmarks can be found in § A.1 . Latent perturbations are injected only during recur- si ve latent reasoning steps (from to ), ensuring that stochasticity only af- fects the reasoning dynamics rather than the final aggregation stage. Additional implementation de- tails are provided in Appendix B.2 . T raining For each prompt, we sample N = 32 perturbation trajectories during rollout. Unless oth- erwise stated, training runs for 10K optimization steps with batch size set as 32 and a learning rate of 1 × 10 − 4 with linear warmup. Other hyperpa- rameters can be found in Appendix B.2 . Baselines W e compare GTS against two stochas- tic inference baselines: • Dropout Sampling Dropout ( p ∈ { 0 . 1 , 0 . 5 } ) is enabled during latent reasoning steps while remaining disabled during prompt prefilling and answer generation. • Standard Gaussian Noise At each latent step, we add isotropic Gaussian noise ϵ ∼ N ( 0 , I ) to the hidden state without context conditioning or learned parameters. Evaluation W e e v aluate ITS perfor - mance by varying the sampling budget N ∈ { 1 , 2 , 4 , 8 , 16 , 32 , 64 , 128 } . When N = 1 , all methods reduce to deterministic inference. For N ≥ 2 , stochasticity is applied exclusi vely to latent reasoning, and answers are decoded greedily to isolate the ef fect of thought sampling. Our primary metric is pass@ N . 4.2 Main Results Overall scaling beha vior Figure 2 shows pass@N curves on C O C O N U T and C O D I . As the sampling budget N increases, all stochastic methods impro ve o ver deterministic inference, con- firming that sampling latent thoughts can enable ITS. Howe ver , these gains are not strictly mono- tonic at very small budgets. In particular , GTS and the standard Gaussian noise baseline (StandardG) can slightly reduce performance at N = 2 , sug- gesting that a small amount of stochasticity may initially disrupt trajectory quality before the benefit of multi-sample selection becomes apparent. Comparison with baselines Heuristic perturba- tion methods sho w substantially different behav- iors across settings. Dropout with a mild rate ( p = 0 . 1 ) provides stable gains on both models and remains a relativ ely strong baseline, especially at small-to-moderate budgets. In contrast, stronger dropout ( p = 0 . 5 ) consistently performs worse, most clearly on C O C O N U T , where it causes a sharp small-b udget degradation and remains well belo w the other methods throughout. StandardG is also less stable, with weaker small-budget beha v- ior and less consistent scaling than mild dropout. T aken together, these results suggest that fixed heuristic perturbations can help, but their effec- ti veness is highly sensitiv e to perturbation strength and model dynamics. Effectiveness of GTS GTS achiev es the strongest scaling beha vior at moderate-to-large budgets on both backbones, and is the best- performing method overall. Compared with heuristic baselines, its adv antage becomes clearer as N gro ws, indicating that the learned sampler produces more useful trajectory di versity under finite inference budgets. The relative gain is lar ger on C O C O N U T than on C O D I , suggesting that the benefit of learned perturbation control may depend 6 1 2 4 8 16 32 64 128 N 2 4 6 8 Answer Diversity Number of unique answers per pr ompt (COCONUT) G TS Dr opout(p=0.1) Dr opout(p=0.5) Standar dG 1 2 4 8 16 32 64 128 N 1.00 1.25 1.50 1.75 2.00 2.25 2.50 2.75 3.00 Answer Diversity Number of unique answers per pr ompt (CODI) G TS Dr opout(p=0.1) Dr opout(p=0.5) Standar dG Figure 3: A verage number of unique decoded answers per prompt. Sampling SG ↑ SG > 0.5 ↑ JS C O C O N U T Dropout ( p = 0 . 1 ) 1 . 09 0 . 61 0 . 05 Dropout ( p = 0 . 5 ) − 0 . 87 0 . 40 0 . 28 StandardG 0 . 34 0 . 51 0 . 20 GTS 1 . 84 0 . 82 0 . 11 C O D I Dropout ( p = 0 . 1 ) 0 . 53 0 . 31 0 . 01 Dropout ( p = 0 . 5 ) 0 . 47 0 . 39 0 . 06 StandardG 0 . 11 0 . 38 0 . 15 GTS 1 . 15 0 . 70 0 . 10 T able 2: Sampling quality analysis for latent reasoning models on GSM8K. W e report SG, SG rate, and dis- tribution shift (measured by JS di ver gence). Higher is better for SG and SG rate. on the latent reasoning dynamics of the backbone; we provide further analysis in Appendix C.1 . In addition, from Appendix A.1 , out-of-distribution results on three benchmarks show the same ov erall pattern, with GTS remaining more consistent than heuristic perturbations. Overall, these results show that learning a context-conditioned perturbation policy yields more effecti ve latent ITS than globally fixed stochastic perturbations. 5 Analysis 5.1 On Sampling Quality W e revisit sampling quality using the diagnostic metrics introduced in § 2 . Follo wing the same pro- tocol and dataset, we ev aluate SG, SG rate, and distribution shift on both C O C O N U T and C O D I , together with StandardG as a Gaussian perturba- tion baseline consistent with the ITS setup in Sec- tion 4.1 . F ailure modes of heuristic perturbations T a- ble 2 sho ws that the mismatch between distrib ution shift and sampling quality observ ed in § 2 persists across both latent reasoning backbones. W e sum- marize this behavior with tw o recurring regimes: • Under -exploration refers to perturbations that are too weak to mov e sampling meaningfully aw ay from the deterministic trajectory , yielding limited distribution shift and only modest g ains. • Over -exploration refers to perturbations that are too strong and disrupt decision-relev ant informa- tion, producing lar ge distrib ution shift b ut limited or ev en negati ve SG, together with reduced SG rate. These regimes are clearly reflected in T able 2 . F or C O C O N U T , mild dropout remains in the under- exploration re gime, while stronger dropout moves into ov er-exploration, sharply increasing distribu- tion shift b ut dri ving SG negati ve. For C O D I , the same pattern appears more mildly: stronger per- turbations again increase distribution shift with- out proportional gains in sampling quality . Across both backbones, GTS avoids these extremes and achie ves positiv e SG with relativ ely controlled dis- tribution shift. Overall, effecti ve latent ITS depends not simply on increasing stochasticity , but on keep- ing perturbations within a useful regime. Heuris- tic methods do not control this trade-of f explicitly , whereas GTS learns a context-dependent pertur- bation policy that balances di versity and decision improv ement more reliably under finite budgets. 5.2 On Sampling Beha vior Answer -level di versity Figure 3 reports the av er- age number of unique decoded answers per prompt in the main experiment. Compared to distribu- tion shift in T able 2 , which measures changes in the answer distrib ution, answer div ersity captures discrete branching behavior after greedy decod- ing. Higher di versity does not necessarily imply stronger sampling gain or better pass@ N scal- ing. In particular , StandardG often produces more 7 Step 0.2 0.4 0.6 0.8 1.0 SNR COCONUT - G TS SNR Step 0.2 0.4 0.6 0.8 1.0 SNR CODI- G TS SNR Figure 4: Step-wise distribution of signal-to-noise ratio (SNR) across latent reasoning steps. Each violin shows the distribution o ver prompts; markers denote medians. unique decoded answers than GTS at moderate bud- gets, yet this additional branching does not trans- late into higher SG or stronger pass@N scaling. This again sho ws that more div erse outputs are not necessarily more decision-useful ones. Step-wise signal-to-noise ratio T o analyze ho w stochastic interv ention e volves across latent reason- ing steps, we measure a step-wise signal-to-noise ratio (SNR). At latent step t , the sampler predicts a mean vector µ t ∈ R D and diagonal log standard de viation log σ t ∈ R D . W e define: SNR t = q 1 D ∥ µ t ∥ 2 2 q 1 D P D i =1 σ 2 t,i . (19) SNR measures the relati ve strength of determinis- tic steering versus injected noise. V alues below 1 indicate noise-dominated steps, while larger v alues indicate stronger deterministic influence. W e e valu- ate on GSM8K-test, sampling N = 32 trajectories per prompt and av eraging SNR at the prompt lev el. Dataset-le vel distributions are sho wn in Figure 4 . For C O C O N U T , SNR alternates across adja- cent latent steps, forming a saw-tooth pattern with moderate magnitudes. Deterministic and stochastic components remain comparable throughout reason- ing, indicating interleaved refinement and variation. For C O D I, deterministic strength concentrates early (peaking at ) and remains lower in later steps, suggesting a more front-loaded adjust- ment pattern. Ov erall, GTS does not impose a fixed stochastic schedule. Instead, the balance between deterministic and stochastic components adapts to 1 2 4 8 16 32 64 128 N 0.35 0.40 0.45 0.50 0.55 pass@N R ewar d Ablation with pass@N COCONUT (G TS R ewar d) CODI (G TS R ewar d) COCONUT (A cc R ewar d) CODI (A cc R ewar d) Figure 5: Ablation study on the reward shaping. Pass@N of the GTS trained with the accuracy-only rew ard and the dense reward introduced in § 3.3 . the latent reasoning dynamics of the underlying backbone. See more discussions in Appendix C.2 . 5.3 Ablation on Reward Shaping W e compare GTS trained with the full dense re- ward in Section 3.3 ag ainst an accuracy-only v ari- ant. In the simplified setting, the shaping term is remov ed by setting α = 0 , reducing the reward to r ( i ) = {− 1 , 1 } . All other training configura- tions remain identical. Figure 5 sho ws pass@ N curves on GSM8K-test for both C O C O N U T and C O D I . The dense rew ard consistently outperforms the accurac y-only v ariant, and the performance gap widens as N increases. The shaping term effec- ti vely provides additional within-group discrimina- tion, improving the quality of sampled candidate sets. In contrast, the accuracy-only rew ard treats all correct (and incorrect) samples equally , limiting refinement during training. 6 Related W ork 6.1 ITS in Discrete Space ITS improves reasoning by allocating additional test-time compute to generate and select among multiple reasoning paths. A representati ve ap- proach is self-consistency ( W ang et al. , 2023 ), which samples multiple Chain-of-Thought (CoT) solutions and aggregates them via majority voting. This idea has been extended through best-of- N sampling and reranking, where candidate trajecto- ries are scored by likelihood, confidence signals, or external v erifiers. Beyond unstructured sampling, structured prompting frameworks introduce explicit search ov er the discrete reasoning space. Least-to- Most ( Zhou et al. , 2023 ), T ree-of-Thoughts ( Y ao et al. , 2023 ), and Graph-of-Thoughts ( Besta et al. , 2024 ) formulate reasoning as systematic explo- ration ov er branching intermediate states. 8 Another complementary direction de velops V er - ifier or Process Rew ard Models (PRMs) to e valuate intermediate reasoning steps. Math- Shepherd ( W ang et al. , 2024 ) automatically gener- ates step-lev el supervision from CoT outputs, while subsequent work improves robustness and gener- alization of process-le vel feedback ( Zhang et al. , 2025b ). OpenPRM ( Zhang et al. , 2025a ) further e x- tends process supervision to open-domain settings through preference-based e v aluation. Collecti vely , these methods rely on explicit token-le vel distrib u- tions and scoring signals, making e xploration and selection relati vely controllable in discrete space. 6.2 Continuous Space Reasoning Continuous CoT reasoning performs multi-step in- ference directly i n latent space, refining hidden rep- resentations without emitting intermediate textual tokens ( Sui et al. , 2025 ). By operating on con- tinuous manifolds, this paradigm aims to impro ve reasoning efficienc y and representational expres- si vity ( Zhu et al. , 2025 ), e.g., CoT2 ( Gozeten et al. , 2025 ) demonstrates that LLMs can maintain multi- ple reasoning traces in parallel within continuous states. Most existing work focuses on learning sta- ble and compact latent representations during training. CODI ( Shen et al. , 2025 ) aligns stu- dent and teacher hidden states via self-distillation, while CCO T ( Cheng and Durme , 2024 ) introduces v ariable-length latent embeddings with optional decoding for interpretability . Hybrid approaches such as T oken Assorted ( Su et al. , 2025 ) com- bine discrete tokens with latent reasoning. C O - C O N U T ( Hao et al. , 2024 ) further sho ws that com- plex reasoning can be executed primarily within hidden state space. While these works advance latent representa- tion learning, they lar gely assume static inference passes. Systematically scaling test-time computa- tion within continuous manifolds remains relatively under-e xplored. 6.3 ITS in Continuous Space Recent ef forts begin to explore ITS directly in con- tinuous space. One direction promotes di versity in latent trajectories. For example, SoftCoT++ ( Xu et al. , 2025 ) generates multiple “soft thoughts” from distinct initial tokens using contrastive ob- jecti ves. Another direction samples and aggre- gates multiple trajectories. CoT2 ( Gozeten et al. , 2025 ) represents parallel reasoning paths as super - positions of continuous tokens, while Zhang et al. ( 2026 ) employ self-verification signals based on proximity to a latent centroid. W ang et al. ( 2025 ); Y ou et al. ( 2026 ) introduce Monte Carlo Dropout to induce stochasticity and aggre gate sampled tra- jectories with a learned re ward model. Despite these adv ances, most e xisting ap- proaches rely on heuristic perturbations, such as dropout or fix ed Gaussian noise to induce diver - sity . Because such stochasticity is not e xplicitly conditioned on semantic conte xt, its magnitude is dif ficult to calibrate and may shift sampling aw ay from decision-rele vant regions, particularly under larger sampling budgets. Similar limitations hav e been noted in prior analysis ( W ang et al. , 2025 ). T o address this gap, we propose GTS, which reformulates latent perturbation as conditional sam- pling from an explicit, learnable Gaussian distri- bution over latent representations. By modeling exploration through a parameterized density , GTS enables explicit and optimizable test-time explo- ration, providing a principled alternati ve to heuris- tic noise injection. 7 Conclusion W e study inference-time scaling in latent reason- ing models through the lens of conditional sam- pling in continuous thought space. Our analysis sho ws that heuristic perturbations do not reliably produce effecti ve exploration: larger distribution shift or higher answer di versity does not necessar - ily translate into better sampling quality , and fixed perturbation schemes can easily fall into under - or ov er-exploration. T o address this limitation, we in- troduce GTS, a lightweight Gaussian sampler that models latent perturbation as an explicit, conte xt- conditioned sampling policy . Across two latent rea- soning architectures, GTS yields stronger and more reliable scaling under finite b udgets than heuristic baselines. Overall, our results suggest that effecti ve latent ITS requires not just more stochasticity or di versity , but better -controlled sampling that more reliably supports correct final decisions. Limitations This work has several limitations. Although we e valuate GTS beyond the training distribution on multiple arithmetic reasoning benchmarks, our em- pirical scope remains limited to relativ ely short, answer-focused math tasks and does not yet cov er more open-ended, long-form, or non-mathematical 9 reasoning settings. W e restrict the sampling policy to a diagonal Gaussian distrib ution and do not ex- plore broader perturbation families that may of fer dif ferent flexibility-stability trade-offs. Our anal- ysis of sampling behavior remains empirical and does not provide a formal theoretical characteri- zation of exploration in high-dimensional latent spaces. Finally , we study two representati ve la- tent reasoning architectures, and the behavior of learnable perturbation policies may differ under alternati ve continuous reasoning formulations. W e leav e broader task coverage, distributional exten- sions, and theoretical analysis to future work. References Maciej Besta, Nils Blach, Ales Kubicek, Robert Ger- stenberger , Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, T omasz Lehmann, Hubert Nie wiadom- ski, Piotr Nyczyk, and T orsten Hoefler . 2024. Graph of thoughts: Solving elaborate problems with large language models . Pr oceedings of the AAAI Confer- ence on Artificial Intelligence , 38(16):17682–17690. Jeffre y Cheng and Benjamin V an Durme. 2024. Com- pressed chain of thought: Efficient reasoning through dense representations . Pr eprint , Karl Cobbe, V ineet Kosaraju, Mohammad Bav arian, Mark Chen, Heew oo Jun, Lukasz Kaiser, Matthias Plappert, Jerry T worek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. T raining verifiers to solve math word prob- lems . Pr eprint , DeepSeek-AI, Daya Guo, Dejian Y ang, Haowei Zhang, and Junxiao Song et al. 2025. Deepseek-r1: Incen- tivizing reasoning capability in llms via reinforce- ment learning . Pr eprint , Y untian Deng, Kiran Prasad, Roland Fernandez, Paul Smolensky , V ishrav Chaudhary , and Stuart Shieber . 2023. Implicit chain of thought reasoning via knowl- edge distillation . Pr eprint , Y arin Gal and Zoubin Ghahramani. 2016. Dropout as a bayesian approximation: Representing model uncer- tainty in deep learning . Pr eprint , Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Y iming Y ang, Jamie Callan, and Gra- ham Neubig. 2023. Pal: Program-aided language models . Pr eprint , Halil Alperen Gozeten, M. Emrullah Ildiz, Xuechen Zhang, Hrayr Harutyunyan, Ankit Singh Raw at, and Samet Oymak. 2025. Continuous chain of thought enables parallel exploration and reasoning . Preprint , Aaron Grattafiori, Abhimanyu Dube y , Abhinav Jauhri, Abhinav P andey , Abhishek Kadian, and Ahmad Al- Dahle et al. 2024. The llama 3 herd of models . Pr eprint , Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason W eston, and Y uandong T ian. 2024. T raining large language models to reason in a contin- uous latent space . Pr eprint , Diederik P Kingma and Max W elling. 2022. Auto-encoding v ariational bayes . Preprint , Hunter Lightman, V ineet K osaraju, Y uri Burda, Harri- son Edwards, Bowen Baker , T eddy Lee, Jan Leike, John Schulman, Ilya Sutskev er, and Karl Cobbe. 2024. Let’ s verify step by step . In The T welfth In- ternational Confer ence on Learning Representations, ICLR 2024, V ienna, Austria, May 7-11, 2024 . Open- Revie w .net. Long Ouyang, Jeff W u, Xu Jiang, Diogo Almeida, Car- roll L. W ainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray , John Schulman, Jacob Hilton, Fraser Kelton, Luk e Miller , Maddie Simens, Amanda Askell, Peter W elinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. T raining language models to follow instructions with human feedback . Pr eprint , Arkil Patel, Satwik Bhattamishra, and Navin Goyal. 2021. Are NLP models really able to solve simple math word problems? In Pr oceedings of the 2021 Confer ence of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies , pages 2080–2094, Online. Association for Computational Linguistics. Alec Radford, Jeffrey W u, Rewon Child, David Luan, Dario Amodei, and Ilya Sutske ver . 2019. Language models are unsupervised multitask learners. OpenAI Blog . Subhro Roy and Dan Roth. 2015. Solving general arith- metic word problems . In Pr oceedings of the 2015 Confer ence on Empirical Methods in Natural Lan- guage Pr ocessing , pages 1743–1752, Lisbon, Portu- gal. Association for Computational Linguistics. John Schulman, Filip W olski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov . 2017. Prox- imal policy optimization algorithms . Pr eprint , Zhenyi Shen, Hanqi Y an, Linhai Zhang, Zhanghao Hu, Y ali Du, and Y ulan He. 2025. Codi: Compress- ing chain-of-thought into continuous space via self- distillation . Pr eprint , Nisan Stiennon, Long Ouyang, Jeff W u, Daniel M. Ziegler , Ryan Lo we, Chelsea V oss, Alec Radford, Dario Amodei, and P aul Christiano. 2022. Learn- ing to summarize from human feedback . Preprint , 10 DiJia Su, Hanlin Zhu, Y ingchen Xu, Jiantao Jiao, Y uandong Tian, and Qinqing Zheng. 2025. T o- ken assorted: Mixing latent and text tokens for improv ed language model reasoning . Pr eprint , Y ang Sui, Y u-Neng Chuang, Guanchu W ang, Jiamu Zhang, Tian yi Zhang, Jiayi Y uan, Hongyi Liu, An- drew W en, Shaochen Zhong, Hanjie Chen, and Xia Hu. 2025. Stop overthinking: A survey on effi- cient reasoning for large language models . Preprint , Richard S. Sutton and Andrew G. Barto. 1998. Re- infor cement learning - an intr oduction . Adaptiv e computation and machine learning. MIT Press. Minghan W ang, Thuy-Trang V u, Ehsan Shareghi, and Gholamreza Haf fari. 2025. T owards inference-time scaling for continuous space reasoning . Preprint , Peiyi W ang, Lei Li, Zhihong Shao, R. X. Xu, Damai Dai, Y ifei Li, Deli Chen, Y . W u, and Zhifang Sui. 2024. Math-shepherd: V erify and reinforce llms step-by-step without human annotations . Pr eprint , Xuezhi W ang, Jason W ei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery , and Denny Zhou. 2023. Self-consistenc y improv es chain of thought reasoning in language models . Pr eprint , Y ige Xu, Xu Guo, Zhiwei Zeng, and Chunyan Miao. 2025. Softcot++: T est-time scaling with soft chain- of-thought reasoning . Pr eprint , Shunyu Y ao, Dian Y u, Jeffre y Zhao, Izhak Shafran, Thomas L. Griffiths, Y uan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliber- ate problem solving with lar ge language models . Pr eprint , Runyang Y ou, Y ongqi Li, Meng Liu, W enjie W ang, Liqiang Nie, and W enjie Li. 2026. Parallel test- time scaling for latent reasoning models . Pr eprint , Kaiyan Zhang, Jiayuan Zhang, Haoxin Li, Xuekai Zhu, Ermo Hua, Xingtai Lv , Ning Ding, Biqing Qi, and Bowen Zhou. 2025a. OpenPRM: Building open- domain process-based reward models with preference trees . In The Thirteenth International Conference on Learning Repr esentations . Nonghai Zhang, W eitao Ma, Zhanyu Ma, Jun Xu, Jiu- chong Gao, Jinghua Hao, Renqing He, and Jingwen Xu. 2026. Silence the judge: Reinforcement learn- ing with self-verifier via latent geometric clustering . Pr eprint , Zhenru Zhang, Chujie Zheng, Y angzhen W u, Beichen Zhang, Runji Lin, Bowen Y u, Dayiheng Liu, Jin- gren Zhou, and Junyang Lin. 2025b. The lessons of dev eloping process rew ard models in mathematical reasoning . Pr eprint , Denny Zhou, Nathanael Schärli, Le Hou, Jason W ei, Nathan Scales, Xuezhi W ang, Dale Schuurmans, Claire Cui, Oli vier Bousquet, Quoc Le, and Ed Chi. 2023. Least-to-most prompting enables complex reasoning in large language models . Preprint , Rui-Jie Zhu, Tianhao Peng, Tianhao Cheng, Xingwei Qu, Jinfa Huang, Da wei Zhu, Hao W ang, Kaiwen Xue, Xuanliang Zhang, Y ong Shan, Tianle Cai, T ay- lor Kerg an, Assel Kembay , Andre w Smith, Chenghua Lin, Binh Nguyen, Y uqi Pan, Y uhong Chou, Zefan Cai, and 14 others. 2025. A surv ey on latent reason- ing . Pr eprint , 11 A ppendix A Additional Experimental Results A.1 Out of Distribution Ev aluation T o examine whether the learned exploration pol- icy generalizes beyond the training distribution, we e valuate the samplers trained on GSM8K-Aug on three out-of-distribution arithmetic reasoning benchmarks: MultiArith ( Roy and Roth , 2015 ) (600 samples), SV AMP ( Patel et al. , 2021 ) (1000 samples), and GSM8K-Hard ( Gao et al. , 2023 ) (1319 samples). No additional training or hyperpa- rameter tuning is performed for these datasets; the samplers are applied directly at inference time un- der the same settings used in the main experiments in Section 4.1 . Figure 6 reports the resulting pass@N curves for both C O C O N U T and C O D I . Across all three benchmarks, GTS consistently achiev es stronger scaling behavior than heuristic baselines, including dropout-based sampling and standard Gaussian per- turbations. The improvement is particularly clear at moderate-to-large sampling budgets, indicating that the learned perturbation policy transfers more consistently to unseen arithmetic benchmarks and continues to yield stronger scaling behavior than heuristic baselines. In contrast, heuristic sampling methods e xhibit noticeably inconsistent behavior across bench- marks. The same perturbation configuration can perform reasonably well on one dataset but degrade significantly on another (e.g., CODI-StandardG on MultiA and SV AMP). This v ariability suggests that fix ed heuristic perturbations are sensitive to dif ferences in problem difficulty , input distribu- tion, and task characteristics. Overall, these re- sults further support the central moti vation of this work: ef fectiv e latent inference-time scaling re- quires better -controlled, context-aware sampling rather than globally fixed stochastic perturbations. B Additional Details about GTS B.1 Reward Shaping For each input x , we sample a group of N latent perturbation trajectories and obtain N decoded an- swers. Let a ( i ) denote the i -th decoded answer , and let I [ a ( i ) = y ⋆ ] be the exact-match indicator with respect to the ground-truth answer y ⋆ . The reward for trajectory i is defined as r ( i ) = r 0 (2 I [ a ( i ) = y ⋆ ] − 1) + α s ( i ) , (20) where r 0 > 0 controls the base correctness magni- tude and α scales a lightweight shaping term. Base Correctness T erm The first term assigns + r 0 to correct answers and − r 0 to incorrect ones. This symmetric formulation ensures that correct- ness remains the dominant optimization signal. When α = 0 , the objecti ve reduces to accuracy- only re ward. Confidence Scor e For each trajectory , we com- pute a scalar confidence score c ( i ) using the length- normalized log-probability of the generated an- swer: c ( i ) = 1 | a ( i ) | | a ( i ) | X t =1 log p θ a ( i ) t | x, τ ( i ) , a ( i ) through . The final latent token influences the output only through attention to and does not re-enter the latent autore gressive loop. Specifically , the subsequent token is provided via teacher forcing when predicting the answer prefix, meaning that af fects decod- ing through key-v alue cache interactions but is not recursi vely fed back as a ne w latent state. Inject- ing perturbations at would therefore not fully propagate through the reasoning dynamics. T o ensure that stochasticity consistently influences autoregressi ve latent refinement, we restrict pertur- bations to the first fi ve latent steps. Policy Optimization Details The reference sam- pler q ϕ ref is updated as an exponential moving av- erage (EMA) of the current policy with decay rate 0 . 999 . The KL regularization coefficient is set to β = 0 . 001 . Adv antages are normalized at the prompt lev el: for each prompt, the N = 32 rollout rew ards are standardized before computing the policy objectiv e. W ith batch size 32 prompts, each optimization step processes 32 × 32 sampled trajectories jointly . When computing trajectory log densities, a diagonal Gaussian formally requires summation ov er dimensions. Howe ver , summing o ver high- dimensional latent v ectors can produce large- magnitude log-density v alues, leading to unstable density ratios. T o improv e numerical stability , we av erage over dimensions instead of summing. This modification preserves relati ve likelihood ordering while keeping ratio magnitudes well-scaled for op- timization. For the clipped GRPO objecti ve, the density ra- tio is clipped to the range [ − 20 , 20] . Because trajec- tory log-probabilities are accumulated across latent steps (rather than computed at a single step le vel), their scale differs from standard token-lev el PPO formulations. The wider clipping interv al empiri- cally stabilizes training without restricting useful policy updates. T raining Configuration Unless otherwise stated, GTS is trained for 10K optimization steps with learning rate 1 × 10 − 4 and linear warmup. The re ward shaping coefficient is α = 0 . 2 . All exper- iments are conducted on a single NVIDIA A100 GPU. B.3 Design Choices f or the Sampling Policy Diagonal Gaussian Policy W e adopt a diagonal Gaussian parameterization for the perturbation dis- tribution. This choice provides a fav orable trade-off between expressi veness and stability . A diagonal policy allows dimension-wise scaling and direc- tional steering while preserving closed-form log- density and KL div ergence expressions, which are essential for stable GRPO optimization. In con- trast, a full-cov ariance Gaussian would introduce O ( D 2 ) parameters and substantially increase both memory cost and numerical instability , especially in high-dimensional latent spaces. Giv en that the backbone representations already encode rich cross- dimensional correlations, a diagonal perturbation distribution is suf ficient to provide flexible yet con- trollable exploration. Additive P erturbation Formulation W e model latent e xploration through additi ve perturbations ˜ h k = h det k + z k . This formulation preserves the original backbone dynamics and ensures that per - turbations act as local steering signals rather than replacing latent representations. Additiv e noise also yields a unit Jacobian transformation, allo wing the perturbation density to be directly interpreted as a distribution o ver latent thought states. More com- plex transformations (e.g., multiplicati ve gating or learned flo ws) could increase flexibility b ut would entangle exploration with backbone dynamics and complicate policy density computation. Relation to Dr opout-Based Bayesian Sampling Dropout has been interpreted as approximate Bayesian inference, where Bernoulli masking cor - responds to a variational approximation o ver model weights and enables predicti ve uncertainty estima- tion via Monte Carlo sampling ( Gal and Ghahra- mani , 2016 ). Under this perspectiv e, stochastic forward passes primarily serve to quantify epis- temic uncertainty and improv e calibration in weight space. ITS in latent reasoning, howe ver , constitutes a search problem: the objectiv e is to increase the probability of obtaining at least one correct reason- ing trajectory under a fix ed sampling b udget. Accu- rate posterior uncertainty estimation does not nec- 14 essarily imply optimal trajectory-le vel exploration for decision correction. Our method therefore does not aim to approximate a weight posterior , but in- stead learns a rew ard-aligned perturbation policy ov er latent states tailored to the inference-time ob- jecti ve. C Additional Analysis C.1 Further Discussion on Main Results Beyond absolute pass@N improvements, we ob- serve that the r elative gains brought by GTS differ across backbone architectures. On C O C O N U T, the improv ement spans a wider margin (approxi- mately 35 → 55 ), whereas on C O D I the gains are more moderate (approximately 48 → 58 ). W e hy- pothesize that this discrepancy reflects structural dif ferences in model scale and latent representation geometry . Model Scale and Latent Dimensionality C O - C O N U T , built on a GPT -2 backbone, operates in a lower -dimensional latent space ( D = 768 ) with fe wer layers. In such a regime, perturba- tions added to latent states can propagate more directly through subsequent reasoning steps, al- lo wing moderate steering signals to produce visi- ble changes in downstream predictions. By con- trast, C O D I employs a deeper architecture with substantially higher dimensional latent representa- tions ( D = 2048 ). In higher-dimensional spaces, meaningful directional steering becomes inherently more challenging: the action space gro ws with D , while the relativ e magnitude of any single pertur- bation component diminishes. Moreo ver , deeper networks possess stronger internal correction dy- namics, which can dampen or redistribute injected perturbations across layers. As a result, while GTS remains effecti ve on C O D I , its relativ e gains are naturally smaller than those observed on the lo wer- dimensional backbone. Sampler Capacity Relative to Backbone Size Although the sampler architecture adopts the same two-layer design in both settings, its r elative capac- ity differs with respect to the backbone. As reported in Section B.2 , GTS introduces approximately 1.8% additional parameters for C O C O N U T and 1.2% for C O D I. While the absolute sampler size in- creases with latent dimension, the backbone grows more substantially in the higher-dimensional model. Consequently , the sampler-to-backbone capacity ratio becomes smaller in C O D I . Moreov er, the ef fecti ve control problem scales with latent dimensionality . A diagonal Gaussian policy in D = 2048 dimensions operates ov er a substantially larger action space than in D = 768 , increasing the difficulty of learning precise conte xt- conditioned steering directions. The same archi- tectural design therefore f aces a more demanding control landscape in larger latent manifolds. From this perspecti ve, the reduced relati ve gain on C O D I does not indicate diminished ef fec- ti veness of structured perturbation, b ut rather re- flects the increased comple xity of steering higher- dimensional reasoning dynamics. Future work may explore model-specific sampler architectures, in- cluding deeper sampler heads or layer-wise per - turbation mechanisms, to better match backbone scale. In the present work, ho wev er, we deliber - ately keep the sampler lightweight to isolate and v alidate the core idea of learnable, controlled latent exploration. On the Small- N Beha vior W e also observe a mild performance drop at very small sampling budgets (e.g., N = 2 ). This phenomenon is not unique to GTS and reflects a general exploration- exploitation trade-off: when only a few samples are av ailable, ev en structured perturbations may temporarily disrupt otherwise correct deterministic reasoning. As N increases, the probability that at least one trajectory meaningfully impro ves the in- ternal decision state grows rapidly , leading to the observed reco very and scaling gains. Importantly , this small- N degradation is not fun- damental. One could introduce an explicit b udget- aw are scaling factor on the perturbation magnitude (e.g., modulating z as a function of N ) to suppress exploration at v ery small budgets. W e deliberately av oid such adaptive scheduling to ensure a fair comparison across methods and sampling budgets. Designing budget-sensiti ve e xploration control re- mains an interesting direction for improving ITS in continuous reasoning space. C.2 Further Discussion on Sampling Behavior T o better understand the structural diff erences ob- served in the step-wise SNR distrib utions (Fig- ure 4 ), we relate them to the underlying training objecti ves and latent reasoning formulations of the two models. C O C O N U T : Paired Latent-Step Dynamics For C O C O N U T , SNR e xhibits a clear saw-tooth 15 pattern across adjacent latent steps. Median v al- ues remain in a moderate range (approximately 0 . 3 – 0 . 5 ), indicating that deterministic steering and stochastic v ariation are comparable in magnitude throughout reasoning. This alternating structure is consistent with C O - C O N U T ’ s training design. C O C O N U T is trained via curriculum learning that progressiv ely com- presses textual reasoning into latent thought repre- sentations. Importantly , its original training formu- lation contains three ef fective reasoning steps, each composed of two latent thought vectors. W ithin each pair , the first sub-step primarily consolidates information, while the second refines or expands upon it. The SNR plot suggests that GTS adapts to this internal structure. The first sub-step within each ef fective reasoning pair tends to e xhibit relati vely stronger deterministic steering, while the second al- lo ws comparatively greater stochastic exploration. Rather than imposing a rigid perturbation schedule, GTS could align with the base model’ s intrinsic rea- soning rhythm, preserving the alternation between consolidation and v ariation. C O D I : Front-Loaded Deterministic Adjust- ment In contrast, C O D I displays a front-loaded SNR profile. Deterministic strength peaks at the second latent step and then transitions into a sus- tained lo wer-SNR regime for subsequent steps. Later reasoning steps therefore operate in a more exploration-dominated setting. This behavior is consistent with C O D I’ s training objecti ve. Unlike C O C O N U T , which compresses intermediate textual reasoning through staged cur - riculum learning, C O D I relies on distillation to align latent reasoning with the text reasoning an- swer prefix at the final step. As a result, its latent trajectory is trained to e volve more smoothly and coherently across steps, without an explicit paired- step structure. Under this formulation, a single early determin- istic adjustment may be suf ficient to steer the trajec- tory tow ard a promising region of latent space, after which controlled exploration can proceed without further strong intervention. The observed SNR profile therefore reflects how GTS adapts to the more continuous and globally aligned reasoning dynamics of C O D I . Adaptive Rather Than Prescriptiv e Control T aken together , these patterns indicate that GTS does not enforce a uniform perturbation sched- ule across architectures. Instead, the balance be- tween deterministic steering and stochastic varia- tion emerges from interaction with each model’ s latent reasoning dynamics. The SNR distributions thus suggest that context-dependent perturbations can adapt to model-specific latent dynamics, rather than uniformly amplifying or suppressing stochas- ticity across all reasoning steps. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment