잠재 추론의 추론시간 확장, 가우시안 사고 샘플러로 제어하기
본 논문은 기존 잠재 추론 모델에서 추론시간 확장(ITS)을 위해 사용되던 드롭아웃·고정 가우시안 노이즈와 같은 휴리스틱 교란이 단순히 변동성을 높이는 데는 도움이 되지만, 실제로는 올바른 추론 경로를 찾는 데 효율적이지 않음을 실험적으로 입증한다. 이를 해결하기 위해 저자는 Gaussian Thought Sampler(GTS)라는 경량 모듈을 제안한다. GTS는 숨겨진 상태에 대한 조건부 가우시안 분포를 학습해 상황에 맞는 교란 규모와 방향을…
저자: Minghan Wang, Ye Bai, Thuy-Trang Vu
**1. 서론 및 배경**
추론시간 확장(ITS)은 테스트 단계에서 추가 연산을 할당해 여러 추론 경로를 생성하고, 그 중 최적의 답을 선택함으로써 LLM의 성능을 향상시키는 기법이다. 토큰 기반 LLM에서는 다음 토큰에 대한 명시적 확률 분포가 존재해 온도, nucleus sampling 등으로 직접 탐색을 제어한다. 그러나 최근 연속 잠재 추론 모델(예: COCO‑NUT, 기타 latent reasoning 프레임워크)은 중간 단계가 숨겨진 상태의 결정적 변환으로 이루어져, 확률적 정책이 자연스럽게 정의되지 않는다. 이 때문에 기존 연구들은 드롭아웃, 고정 가우시안 노이즈와 같은 휴리스틱 교란을 삽입해 stochasticity를 부여했지만, 이는 “어디를 탐색할지”에 대한 명시적 지시가 없으므로 탐색 품질이 보장되지 않는다.
**2. 휴리스틱 교란의 한계 분석**
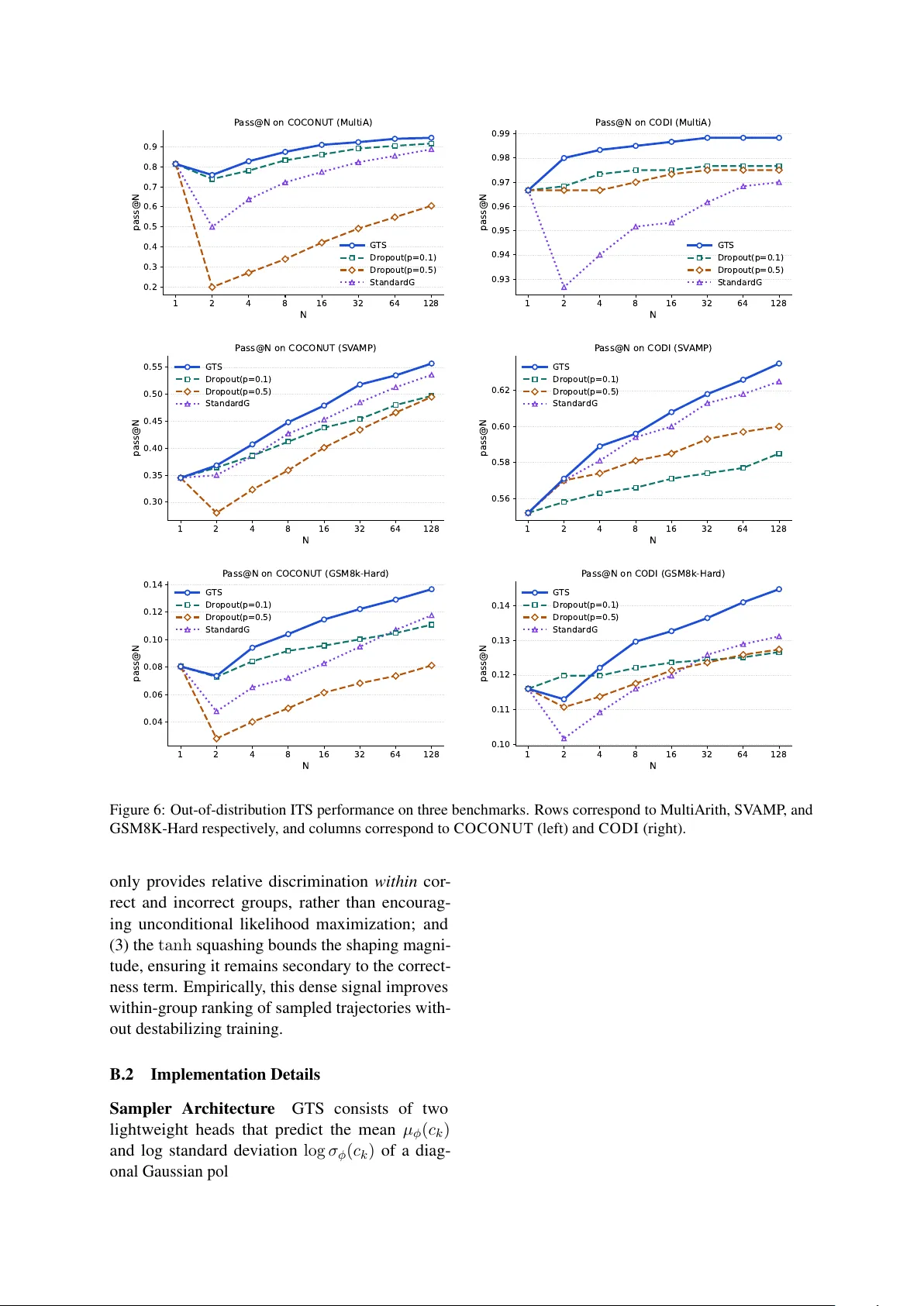
논문은 두 모델(GPT‑2 기반 텍스트 추론, COCO‑NUT 기반 잠재 추론)에서 다양한 교란 강도(p=0.1, 0.5)와 고정 노이즈를 적용해 샘플링 품질을 정량화한다. 측정 지표는 (1) Sampling Gain(SG): 정답 토큰에 대한 로그오즈 변화, (2) SG Rate: SG>0인 입력 비율, (3) Jensen‑Shannon Divergence(JS): 교란이 만든 답변 분포와 원본 분포 간 차이. 결과는 강한 교란이 JS를 크게 증가시키지만, SG와 SG Rate는 오히려 감소함을 보여준다. 즉, 분포 이동이 크다고 해서 올바른 답을 찾는 데 도움이 되지 않는다. 특히 잠재 모델에서는 강한 드롭아웃이 오히려 성능을 저하시킨다.
**3. Gaussian Thought Sampler(GTS) 설계**
GTS는 각 추론 단계 k에서 현재 결정적 숨겨진 상태 h_det^k를 입력으로 받아, 평균 µ_ϕ(c_k)와 표준편차 σ_ϕ(c_k)를 출력하는 MLP 기반 가우시안 정책 q_ϕ(z_k|c_k)를 학습한다. 여기서 z_k는 h_det^k에 더해지는 교란이며, 재파라미터화(z_k = µ + σ⊙ε, ε~N(0,I))를 통해 미분 가능하게 만든다. 교란 후의 상태 ˜h_k = h_det^k + z_k는 그대로 백본에 전달돼 다음 단계 연산에 사용된다. 이렇게 하면 백본은 완전히 동결된 채, GTS만이 탐색 정책을 제어한다.
**4. 정책 학습 방법**
탐색 정책은 연속 행동(z_k)으로 간주하고, 강화학습 프레임워크에서 보상을 정의한다. 보상 r(i) = 2·I
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기