Agentic AI for Human Resources: LLM-Driven Candidate Assessment
In this work, we present a modular and interpretable framework that uses Large Language Models (LLMs) to automate candidate assessment in recruitment. The system integrates diverse sources, including job descriptions, CVs, interview transcripts, and …
Authors: Kamer Ali Yuksel, Abdul Basit Anees, Ashraf Elneima
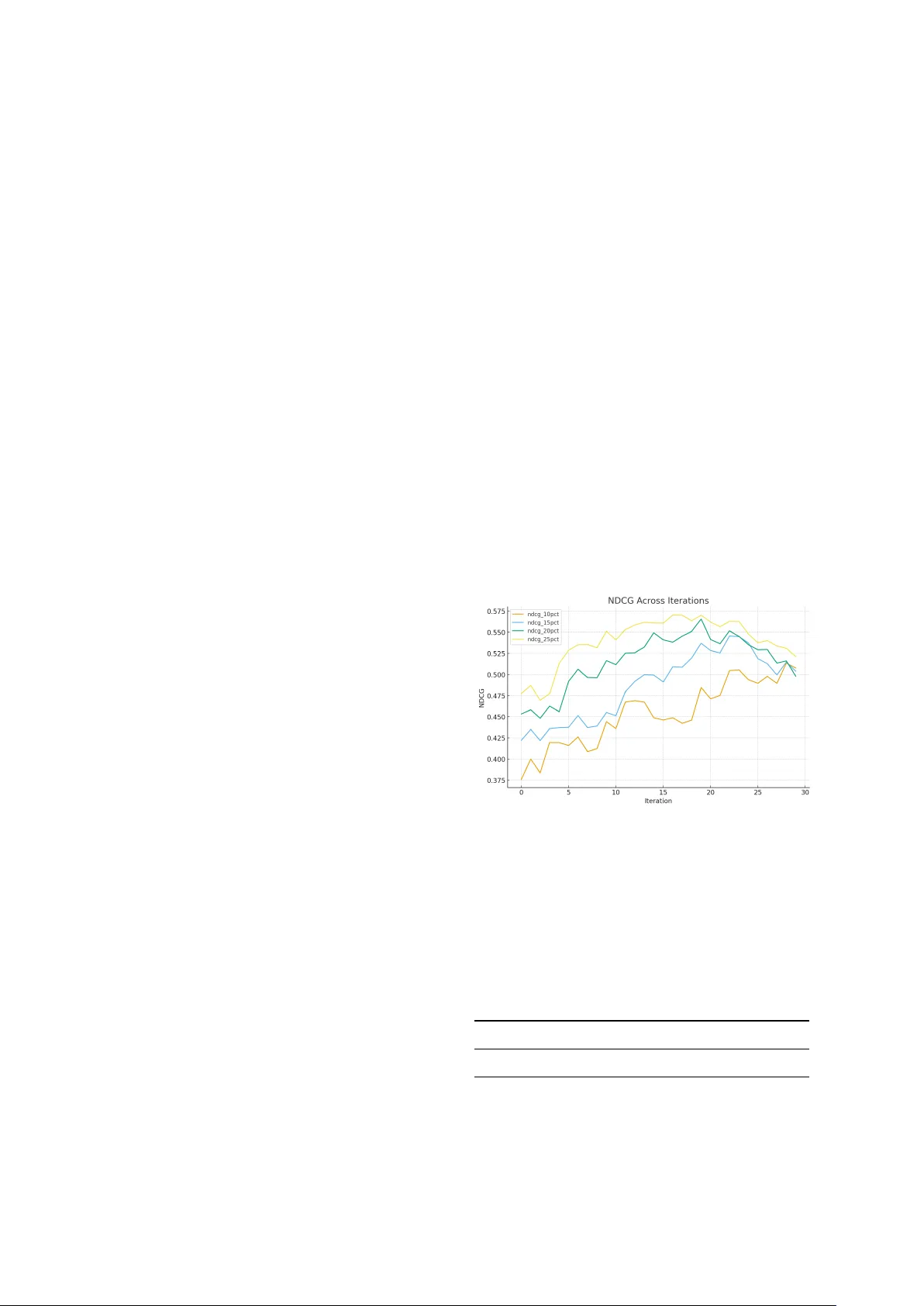
Agentic AI f or Human Resour ces: LLM-Driv en Candidate Assessment Kamer Ali Y uksel, Abdul Basit Anees, Ashraf Elneima Sanjika Hewa vitharana, Mohamed Al-Badrashiny , Hassan Sawaf aiXplain, Inc., San Jose, CA, USA {kamer,abdul.anees,ashraf.hatim,sanijka,mohamed,hassan}@aixplain.com Abstract In this work, we present a modular and in- terpretable frame work that uses Large Lan- guage Models (LLMs) to automate candidate assessment in recruitment. The system in- tegrates div erse sources—including job de- scriptions, CVs, interview transcripts, and HR feedback—to generate structured ev aluation reports that mirror expert judgment. Unlike traditional A TS tools that rely on keyw ord matching or shallo w scoring, our approach employs role-specific, LLM-generated rubrics and a multi-agent architecture to perform fine- grained, criteria-driv en ev aluations. The frame- work outputs detailed assessment reports, can- didate comparisons, and ranked recommenda- tions that are transparent, auditable, and suit- able for real-world hiring workflo ws. Beyond rubric-based analysis, we introduce an LLM-Dri ven Acti ve Listwise T ournament mechanism for candidate ranking. Instead of noisy pairwise comparisons or inconsistent independent scoring, the LLM ranks small candidate subsets (“mini-tournaments”), and these listwise permutations are aggre gated us- ing a Plackett–Luce model. An activ e-learning loop selects the most informati ve subsets, pro- ducing globally coherent and sample-ef ficient rankings. This adaptation of listwise LLM preference modeling—pre viously explored in financial asset ranking ( Y uksel and Sawaf , 2025 )—provides a principled and highly inter - pretable methodology for large-scale candidate ranking in talent acquisition. 1 Introduction The process of e v aluating job candidates remains one of the most critical and resource-intensi v e tasks in human resource management. Despite adv ances in digital recruitment platforms, organizations still HR Manager is online: https://hrmanager .aixplain.com struggle to identify and select the most suitable can- didates, particularly when faced with high volumes of applicants or highly specialized roles ( Ragha v an et al. , 2020 ; V aishampayan et al. , 2025 ). Current systems tend to over -rely on heuristics, rigid fil- ters, or shallo w keyw ord-based screening, leading to missed opportunities and inconsistent e valua- tions. Human revie wers, while in valuable, often face cogniti ve o verload, inter-rater inconsistencies, and implicit biases that compromise the objectivity and reproducibility of hiring decisions ( Quillian et al. , 2017 ). T o address these limitations, we introduce a ro- bust, LLM-based candidate assessment system de- signed to enhance the precision, fairness, and scal- ability of talent e valuations. Our system lev erages the generativ e reasoning capabilities of state-of- the-art language models to generate, apply , and explain fine-grained ev aluation criteria specific to each job role. This approach ensures a high degree of alignment between role requirements and candi- date e valuations, enabling both depth and breadth in assessments. The system also supports multi- source inte gration, allo wing it to analyze struc- tured and unstructured data from resumes, inter- vie ws, recommendation letters, and internal HR notes. Through its modular and extensible archi- tecture, our framework lays the groundwork for a new paradigm in AI-assisted hiring: one that is grounded in interpretability , adaptability , and deci- sion support rather than opaque automation. Beyond generating structured assessments, our system introduces a new paradigm for ranking can- didates: treating the LLM as a listwise fuzzy judge. Rather than comparing two candidates at a time, the model ev aluates small groups of candidates simultaneously and produces a relati ve ordering. These listwise rankings contain richer information per query and mirror how human hiring committees make decisions when re vie wing shortlists. W e ag- V ideo demonstration: https://youtu.be/qwcSmWNOHRk gregate these orders using a Plackett–Luce model ( Plackett , 1975 ) to estimate global latent “candidate utilities”, and emplo y an activ e-learning ( Liang and Grauman , 2014 ) mechanism to adaptiv ely select the most informati ve candidate groups for ev alua- tion. This approach transforms candidate ranking from an ad-hoc or score-based process into a statis- tically principled, scalable inference. 2 Related W ork Prior efforts in automating candidate assessment hav e focused primarily on three domains: resume parsing and semantic matching, AI-based video or audio intervie ws, and the use of predicti ve analyt- ics to estimate candidate performance. Resume parsing tools such as T extKernel and So vren ha ve made strides in extracting structured information from unstructured resumes, enabling preliminary filtering. Ho wev er , these tools often lack con- textual understanding and fail to capture the nu- ances of role-specific competencies ( Kanikar et al. , 2025 ). Similarly , semantic matchers like Eight- fold and LinkedIn T alent Insights attempt to align job descriptions with candidate profiles using em- beddings and cosine similarity measures, b ut tend to prioritize surface-le vel alignment ov er deeper e valuati ve reasoning ( Bev ara et al. , 2025 ). Recent de velopments in LLMs ha ve enabled fe w- shot and zero-shot task performance across a wide range of domains. These capabilities hav e opened up ne w a venues for generating assessments, feed- back, and structured ev aluations. Ho wev er , there remains a significant gap in applying LLMs to the hiring domain in a way that is structured and ex- plainable ( Ghosh and Sadaphal , 2023 ). Our work bridges this gap by building a layered frame work that combines LLM-based reasoning with a robust set of e valuation dimensions, customized prompts, and a focus on output format alignment for real- world usability . Recent work in LLM-based preference learning, including pairwise comparison framew orks such as P AIRS and PoE Bradley–T erry models, demon- strates that LLMs can act as noisy b ut meaningful preference oracles when aggregated statistically ( Qin et al. , 2024 ). Ho we ver , nearly all such ap- proaches rely on pairwise comparisons, which are noisy , vulnerable to prompt instability , and do not scale well to large candidate pools ( Zeng et al. , 2024 ; W ang et al. , 2025 ). Our work is among the first to apply listwise LLM judgments—far more informati ve than pairwise labels—to candidate as- sessment. Through listwise tournaments and PL aggregation, we introduce a stable, globally coher - ent ranking mechanism tailored to HR w orkflows, bridging the gaps between LLM reasoning, struc- tured e valuation, and hiring decision support. 3 Architectur e The proposed system is designed as a multi-stage, modular pipeline where each stage is responsible for a distinct phase in the candidate ev aluation life- cycle. At the core of the system is a suite of LLM- po wered agents ( Guo et al. , 2024 ), each guided by prompt templates and domain-specific heuristics. These agents interact in a sequential yet modular fashion, allowing for plug-and-play flexibility in enterprise settings. The process begins with the Criteria Genera- tion Agent, which takes as input a job title and description and produces a finely detailed assess- ment rubric. This rubric is not generic; it is cus- tomized to reflect the specific competencies, re- sponsibilities, and context described in the job posting. The rubric includes both technical and non-technical dimensions, and is structured to dif- ferentiate candidates not just by qualifications b ut by demonstrated competencies and gro wth poten- tial. The system also includes a dedicated V ideo Question Generation Agent, which tailors reflec- ti ve and dimension-specific interview questions for video-based responses. Candidate answers are then transcribed and fused with other input modalities to provide a full-spectrum e v aluation. Next, the Assessment Generator Agent uses this rubric to e v aluate candidate profiles. This agent synthesizes data from candidate CVs, HR recommendations, structured intervie w transcripts, and chat-based conv ersations. It maps candidate achie vements and responses to the rubric and gen- erates a markdown-based report with explicit rat- ings (Low , Medium, High) for each dimension, supported by detailed justifications. These justifi- cations not only cite specific evidence from inputs but also interpret the rele vance of that e vidence in the context of the role. T o enhance the richness and reliability of assessment, the system integrates multimodal analysis through a video intervie w anal- ysis module. This component le verages computer vision and audio processing techniques to assess facial e xpressions, vocal tone, and body language from recorded intervie ws. These non-verbal cues are fused with the LLM-generated textual insights, of fering a holistic picture of a candidate’ s interper- sonal dynamics, emotional intelligence, and pre- sentation skills—traits often critical in leadership and client-facing roles. The system also incorporates a Feedback Inte- gration Module that closes the loop between pre- hire assessments and post-hire outcomes. Data such as performance re vie ws, retention metrics, and team feedback are used to retroactiv ely v alidate model predictions and refine the scoring logic and rubric generation prompts. This continuous learn- ing mechanism ensures that the system e volv es to better predict candidate success, based on empiri- cal e vidence. Other agents in the system include a Formatter Agent, which ensures compliance with HR documentation standards; a Comparison Agent, which conducts side-by-side ev aluations across top candidates; and a Ranking Agent, which integrates ne w candidates into existing ranked lists while pre- serving order consistency . 3.1 Prompt Engineering Prompt engineering is central to the success of this system ( K ojima et al. , 2023 ). Each agent is pow- ered by a dedicated prompt template designed to elicit high-quality , context-sensiti ve output from the language model. The prompts are carefully structured to ensure that outputs are not only infor- mati ve b ut aligned with HR practices. The Criteria Generation Prompt guides the model to rewrite and enrich default assessment rubrics based on job- specific information. It instructs the model to retain general competencies such as leadership or commu- nication, while augmenting or refining them with role-specific details. The result is a Y AML schema that defines e valuation criteria in granular terms, often including 12 to 20 dimensions, each with clear definitions and expectations for v arious rating scales. The Assessment Prompt is the heart of the e valuation pipeline. It consolidates inputs from multiple sources—including candidate summaries, HR notes, interviews, and prior assessments—and guides the model to produce a structured report. The prompt enforces a markdown format and man- dates explanations for each rating. The prompt also incorporates an internal logic to cross-check dimensions, ensuring coherence and consistenc y in the assessment. Comparison and Ranking Prompts are designed to simulate the work of hiring com- mittees. They use structured reasoning to e valu- ate candidates across dimensions and recommend ranked lists, justifying the positioning of each can- didate. All prompts are calibrated to av oid hallu- cination, reduce bias, and maintain a professional tone aligned with corporate communication. For tournament-based ranking, we design a ded- icated Listwise Ranking Prompt that instructs the LLM to e valuate a small group of candidates to- gether , using the job-specific rubric as the ev al- uation lens. The prompt requires the model to internally reason step-by-step b ut output only a per - mutation of candidates from strongest to weak est. This ensures consistency and av oids verbose expla- nations during the tournament phase. Additional prompts support activ e learning by incorporating weak prior orderings from the PL model, enabling the LLM to refine its comparisons based on pre vi- ous rounds while av oiding bias amplification. 3.2 Evaluation Dimensions The assessment criteria generated by the system cov er a wide spectrum of attributes required for professional success. These dimensions are not static but tailored dynamically for each job role using the Criteria Generation Agent. T ypical cate- gories include domain expertise, technical skill sets, interpersonal ef fectiv eness, leadership capabilities, and career moti v ation. For example, the Industry- Specific Fit dimension e valuates the extent to which a candidate’ s experience aligns with the sector tar - geted by the role. Functional Fit assesses the can- didate’ s technical proficiency or domain fluency concerning the job’ s day-to-day responsibilities. Soft skills are also included, with dimensions like Motiv ation, Driv e, and Continuous Learning assessing intrinsic traits and gro wth mindset. The system ensures that each dimension includes rubric definitions for each level of proficiency . This en- ables consistent application across candidates and increases inter-rater reliability when used in h ybrid human-AI workflo ws. Listwise tournaments rely on these dimensions as implicit comparison crite- ria. During tournament ranking, the LLM e valuates subsets of candidates holistically across all rubric dimensions, weighing tradeof fs (e.g., strong tech- nical skill but weak er communication) at a group le vel. This mirrors human holistic reasoning and produces richer preference signals than indepen- dent per-candidate scoring. 3.3 Report Generation The output of the system is designed to be imme- diately useful to recruiters, hiring managers, and talent committees. Each assessment report is gen- erated in structured markdown format and adheres to a consistent schema that balances detail with readability . Reports begin with a concise introduc- tion outlining the role and the candidate’ s context. The core of the report is the dimension-wise assess- ment, where each dimension is e valuated with a rating and a supporting explanation. These expla- nations are not generic. They explicitly refer to the candidate’ s background, citing projects, metrics, or behavioral indicators found in resumes or inter - vie ws. This creates a transparent trail that hiring teams can audit. Follo wing the detailed assessment, the system synthesizes an o verall readiness e valuation, a cul- tural fit analysis, and flags areas where the candi- date may require support or dev elopment. It also suggests alternativ e roles if the candidate is deemed not optimal for the original role, a feature especially v aluable in internal mobility or v olume hiring set- tings. The report concludes with a summary recom- mendation and a confidence indicator , which can be weighted based on the richness of the input data. While the listwise tournament mechanism is used to compute global rankings, its outcomes also influence report generation. Candidates’ latent util- ity v alues, stability across tournament rounds, and ke y dimensions driving their placement can be sur- faced in the final report, allowing hiring teams to understand why a candidate ranks above peers and to audit the consistency of the e v aluation pipeline. 3.4 Methodology T o complement rubric-driv en candidate ev aluation, our system introduces an active listwise ranking mechanism that treats the LLM as a fuzzy multi- candidate judge. Instead of independently scor- ing each candidate or performing unstable pairwise comparisons, the system repeatedly ev aluates small groups of candidates using LLM-driv en listwise tournaments. This produces richer comparativ e in- formation and enables a principled, data-ef ficient approach to building a globally coherent ranking ov er large applicant pools. The methodology con- sists of three components: (1) listwise LLM com- parisons, (2) probabilistic Plackett–Luce aggre ga- tion, and (3) activ e subset selection via uncertainty . At each iteration, the system samples a sub- set of K candidates (typically between 5 and 10) and presents them to the LLM with a structured prompt. The model is instructed to ev aluate all can- didates simultaneously , using the role-specific as- sessment rubric as the decision lens, perform step- by-step reasoning internally , and output only an ordered list from strongest to weakest fit for the job . The prompt explicitly prohibits justification during these tournament rounds to reduce verbosity and stabilize comparisons. Each listwise ranking en- codes K ( K − 1) 2 implied pairwise relations and cap- tures cross-dimensional tradeoffs that only emer ge when candidates are ev aluated side-by-side, imitat- ing human hiring committees. Each LLM-generated permutation is treated as a noisy observ ation of latent “candidate suitability utilities. ” T o infer these utilities, we fit a Plack ett– Luce (PL) model over all collected tournament results. For each ranking π t from subset S t , the PL likelihood f actorizes over positions in the per - mutation, allo wing ef ficient optimization. The re- sulting utility v ector u provides a globally consis- tent ranking across all candidates, stabilizes noise in raw LLM outputs, and reconciles conflicting preferences across tournament rounds. Posterior v ariances over u i are approximated via a diagonal Laplace approximation for uncertainty estimates essential in acti ve learning and tar geted querying. Rather than sampling candidate subsets uni- formly , we employ an activ e learning loop that prioritizes the most informati ve groups. After each PL update, posterior v ariances highlight candidates with uncertain latent utilities. New subsets are formed to probe contested regions— such as boundaries between “shortlist” and “re- ject” tiers. Acquisition strategies, including Monte- Carlo Knowledge Gradient (MC–KG) ( Balandat et al. , 2020 ), posterior disagreement sampling ( Se- ung et al. , 1992 ), and KL-UCB heuristics ( Garivier and Cappé , 2011 ), determine which subsets max- imize expected information gain. This approach sharply reduces the number of LLM queries re- quired and accelerates con ver gence toward a stable global ranking. Unlike standalone ranking algorithms, the list- wise tournament system utilizes the same role- specific rubric that guides the Criteria Generation and Assessment Generator agents. This ensures that tournament comparisons align with the compe- tency framework used in detailed candidate reports, that latent utilities reflect holistic role fit rather than superficial similarities, and that ranking outcomes remain interpretable and auditable. The final rank- ing is thus grounded in the same structured criteria used for individual assessments, enabling consis- tent and transparent decision-making across both comparati ve and descripti ve e v aluation modes. 4 Case Studies W e applied the system to a set of roles spanning multiple industries and seniority lev els to ev alu- ate its generalizability and precision. These in- cluded technical roles like AI Research Scientist and Staf f Machine Learning Engineer , as well as leadership roles such as VP of Product and CTO for startup en vironments. Human experts inde- pendently rated candidates using the three-level rubric (Low/Medium/High) generated by the Crite- ria Generation Agent, and the system produced its o wn ratings using the same rubric. Agreement was computed per dimension, counting cases where the system’ s rating was within one le vel of the human score. Across all ev aluations, 87% of system rat- ings fell within one band of human scores. In cases where candidates appeared similar , the system was able to surface distinctions that human revie wers later confirmed. Although not directly captured by ranking metrics, qualitati ve inspection of interme- diate outputs re veals se veral desirable beha viors: • Rubric refinement yields clearer , more struc- tured, and more discriminati ve e v aluation. • Subtle distinctions in candidates (e.g., leader- ship maturity , communication style, depth of reasoning) emerge earlier in iterations. • The system frequently suggests alternativ e roles for candidates whose strengths are mis- aligned with the target position. These findings show that the system not only learns a stable ranking b ut also produces nuanced, actionable insights for talent ev aluation workflo ws. 4.1 Experiments W e ev aluate the proposed LLM-dri ven acti v e list- wise tournament frame work on a real candidate- ranking task using the full pipeline with iterative criteria refinement. In this configuration, the sys- tem not only performs listwise tournaments and Plackett–Luce aggre gation b ut also refines the scor- ing rubric at each iteration based on LLM critique. The goal of this experiment is to measure ranking fidelity relati ve to human expert judgments, assess con v ergence beha vior , and characterize how acti ve learning improv es ranking stability . W e run 30 iterations of activ e listwise querying ov er a fixed pool of candidates. Each consists of: 1. Refining the assessment rubric via LLM- based critique. 2. Selecting next candidate subset using Monte- Carlo Kno wledge Gradient (MC–KG). 3. Obtaining a listwise ranking from the LLM for the selected subset. 4. Updating global candidate utilities through Plackett–Luce optimization. W e ev aluate performance using NDCG@K for K = { 10% , 15% , 20% , 25% } using human rank- ing as reference, and con ver gence metrics that mea- sure the stability of the ranking updates , where higher values mean the ranking is stabilizing and the system is no longer making large structural ad- justments. Figure 1 shows the e volution of NDCG across cutof fs during the activ e-learning process. Figure 1: NDCG@K% progression across 30 iterations. Across all cutoffs, NDCG improv es steadily during the first ~20 iterations, with NDCG@25% achie ving the highest value. This shows that the acti ve listwise tournament mechanism extracts a ranking structure aligning with human preferences. T able 1: Peak NDCG@K values across cut-of f ratios. Cutoff 10% 15% 20% 25% NDCG@K 0.5134 0.5455 0.5655 0.5703 T o assess conv ergence, we track tw o indicators: 1. K endall- τ between successive iterations , capturing ho w similar the ranking at iterations t is to iterations t − 1 . 2. Utility movement ∆ u , defined as the norm of the change in the global PL utility vector . Since these metrics operate on different scales, each is independently normalized to [0 , 1] for visu- alization. Figure 2 shows their joint progression. The K endall- τ curve rises sharply during early it- erations, indicating rapid stabilization of the rank- ing. Meanwhile, ∆ u decreases substantially after iteration 10, showing that the underlying utility estimates con ver ge. T ogether , these trends demon- strate that activ e querying helps the system quickly settle into a stable, high-confidence ranking. Figure 2: Conv ergence metrics o ver 30 iterations. Both Kendall- τ (stability between iterations) and ∆ u (norm of utility change) are independently scaled to [0 , 1] . 5 Discussion The LLM-based candidate assessment system presents a significant adv ancement in the intersec- tion of AI and human capital management. By combining rigorous prompt engineering, dynamic rubric generation, and structured reasoning, the sys- tem of fers a scalable alternati ve to traditional can- didate e valuations. It provides or ganizations with an interpretable, customizable, and reproducible method for ev aluating talent, while also supporting di versity , equity , and inclusion through the criteria. Nonetheless, there are challenges. The system’ s accuracy is influenced by the quality of the input data. Poorly written job descriptions or ambiguous candidate materials can reduce the effecti veness of the ev aluation. Additionally , while the system addresses many soft skill dimensions through tex- tual inputs, it can currently recognize facial expres- sions but cannot yet interpret broader non-verbal cues—such as tone of voice or full-body language. Finally , ongoing prompt tuning is needed to en- sure domain-specific rele vance in niche or highly specialized roles. The addition of listwise LLM tournaments in- troduces a po werful inference layer that helps ad- dress a persistent challenge in hiring: ranking can- didates with overlapping profiles. By modeling can- didate ev aluation as a probabilistic ranking prob- lem—rather than independent scoring—we gain stability , interpretability , and resistance to prompt noise. Howe ver , this approach also requires careful control of rubric drift and must av oid reinforcing biases across rounds of activ e querying. These chal- lenges moti vate future work combining fairness- aw are constraints with PL-model aggregation. 6 Conclusion This paper introduces a novel, LLM-driv en can- didate assessment system that transforms the w ay org anizations ev aluate talent. By uniting the power of language models with structured rubric gener- ation, contextual analysis, and transparent report- ing, we offer a frame work that is both scalable and interpretable. The system addresses critical limita- tions in existing hiring workflo ws by enabling fine- grained, reproducible assessments that align closely with job-specific expectations. W ith a focus on real-world usability , modular design, and human- centered out puts, our framework lays a strong foun- dation for the future of AI-assisted hiring. By extending the Activ e Listwise T ournament frame work from financial asset ranking ( Y uksel and Saw af , 2025 ) to candidate e v aluation, we sho w that LLMs can serv e not only as rubric-based asses- sors but also as structured preference oracles. The combination of listwise e valuations, probabilistic PL aggregation, and activ e learning yields glob- ally coherent candidate rankings that scale to large applicant pools and outperform traditional scor- ing pipelines. This fusion of LLM reasoning and ranking theory provides a principled foundation for next-generation hiring decision support systems. Another promising direction is the dev elopment of a real-time intervie w assistant that can suggest probing questions to human interviewers based on li ve candidate responses. This would create a hy- brid workflow where AI augments rather than re- places human judgment, preserving the richness of interpersonal ev aluations while enhancing struc- ture and consistency . W e also plan to de velop a feedback loop that integrates hiring outcomes and performance re vie ws into the system, enabling it to refine its prompts and scoring models ov er time. Limitations While the proposed framew ork offers significant adv ancements in candidate assessment, it is not without limitations. First, although the integration of LLMs and multimodal analysis allows for nu- anced e valuation, the system’ s performance is still bounded by the quality and completeness of can- didate input data. Sparse or low-quality resumes, brief intervie w responses, or poorly recorded video inputs can reduce the accuracy of assessments. Second, although the system supports multilin- gual e valuation and localization, the depth of cul- tural adaptation is currently limited to language and structural format. Subtle sociocultural dynamics or communication norms may still be misinterpreted by the LLM or the multimodal modules. Lastly , while interpretability is a design princi- ple, some of the underlying reasoning from the LLM remains opaque, especially in complex judg- ment tasks that inv olv e implicit contextual infer- ence. Efforts ha ve been made to structure outputs and provide rationale, but full transparency into model reasoning is still an open challenge. Ethics Statement This system aims to democratize access to fair can- didate assessments, reducing reliance on subjectiv e heuristics and increasing transparency . Ho we ver , it also raises se veral ethical considerations. First, while the system seeks to mitigate bias, LLMs are trained on large-scale internet data that may contain embedded societal biases. If unchecked, these biases can influence rubric gener- ation, assessments, and candidate rankings. Second, there is the risk of o ver -reliance on au- tomated systems in critical decision-making. Our system is designed to augment human judgment, not replace it. Recommendations should always be re viewed by qualified HR personnel who contextu- alize the outputs with domain-specific insight. Finally , deploying this system at scale across regions and cultures requires sensitivity to local labor laws, cultural practices, and f airness norms. While these challenges are non-trivial, we be- lie ve that the benefits of a well-designed, transpar - ent, and modular AI-assisted ev aluation system can meaningfully improv e hiring outcomes—if de vel- oped and deployed responsibly . References Maximilian Balandat, Brian Karrer , Daniel R. Jiang, Samuel Daulton, Benjamin Letham, Andrew Gordon W ilson, and Eytan Bakshy . 2020. Botorch: A frame- work for ef ficient monte-carlo bayesian optimization . R. V . K. Bev ara, N. R. Mannuru, S. P . Karedla, B. Lund, T . Xiao, H. Pasem, S. C. Dronav alli, and S. Rudreshkumar . 2025. Resume2vec: Transforming applicant tracking systems with intelligent resume embeddings for precise candidate matching . Elec- tr onics , 14(4):794. Aurélien Gari vier and Olivier Cappé. 2011. The kl- ucb algorithm for bounded stochastic bandits and beyond. In Pr oceedings of the 24th Annual Confer- ence on Learning Theory (COLT 2011) , volume 19 of Proceedings of Machine Learning Resear ch , pages 359–376. Preetam Ghosh and V aishali Sadaphal. 2023. Jo- brecogpt – explainable job recommendations using llms . T aicheng Guo, Xiuying Chen, Y aqi W ang, Ruidi Chang, Shichao Pei, Nitesh V . Chawla, Olaf W iest, and Xi- angliang Zhang. 2024. Large language model based multi-agents: A survey of progress and challenges . Darsh Kanikar, Pratyush Jain, Siddhi Jain, and Lalit Purohit. 2025. Systematic revie w of methods for analysis of resumes. In Pr oceedings of the Interna- tional Confer ence on Computer Science and Commu- nication Engineering , pages 301–308. Atlantis Press. Systematic survey of resume analyzers, including commercial tools such as T extkernel. T akeshi K ojima, Shixiang Shane Gu, Machel Reid, Y u- taka Matsuo, and Y usuke Iwasawa. 2023. Large lan- guage models are zero-shot reasoners . Lucy Liang and Kristen Grauman. 2014. Beyond com- paring image pairs: Setwise activ e learning for rel- ativ e attributes. In IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) , pages 2856– 2863. L. Plackett, R. ˙ 1975. The analysis of permutations . Jour - nal of the Royal Statistical Society: Series C (Applied Statistics) , 24(2):193–202. Zhen Qin, Rolf Jagerman, Kai Hui, Honglei Zhuang, Junru W u, Le Y an, Jiaming Shen, Tianqi Liu, Jialu Liu, Donald Metzler, Xuanhui W ang, and Michael Bendersky . 2024. Large language models are ef fec- tiv e text rankers with pairwise ranking prompting . In F indings of the Association for Computational Linguistics: NAA CL 2024 , page 1504–1518. Lincoln Quillian, Dev ah Pager , Ole Hexel, and Arn- finn H. Midtbøen. 2017. Meta-analysis of field ex- periments sho ws no change in racial discrimination in hiring ov er time . Pr oceedings of the National Academy of Sciences , 114(41):10870–10875. Manish Raghav an, Solon Barocas, Jon Kleinberg, and Karen Le vy . 2020. Mitigating bias in algorithmic hir- ing: Evaluating claims and practices . In Proceedings of the 2020 Conference on F airness, Accountability , and T ranspar ency (F A T* / F AccT) , pages 469–481. A CM. H. Sebastian Seung, Manfred Opper, and Haim Som- polinsky . 1992. Query by committee . Pr oceedings of the F ifth Annual W orkshop on Computational Learn- ing Theory (COLT) , pages 287–294. Swanand V aishampayan, Hunter Leary , Y oseph Berhanu Alebachew , Louis Hickman, Brent Ste venor , W eston Beck, and Chris Brown. 2025. Human and llm-based resume matching: An observational study . In F indings of the Association for Computational Linguistics: NAA CL 2025 , pages 4808–4823. Y idong W ang, Y unze Song, T ingyuan Zhu, Xuanwang Zhang, Zhuohao Y u, Hao Chen, Chiyu Song, Qiufeng W ang, Cunxiang W ang, Zhen W u, Xinyu Dai, Y ue Zhang, W ei Y e, and Shikun Zhang. 2025. T rustjudge: Inconsistencies of llm-as-a-judge and how to alleviate them. arXiv pr eprint . Kamer Ali Y uksel and Hassan Sawaf. 2025. Llm- driv en active listwise tournaments for portfolio selection in large asset univ erses . SSRN Elec- tr onic Journal . Preprint; A v ailable at SSRN: https://ssrn.com/abstract=5764903. Y ifan Zeng, Ojas T endolkar, Raymond Baartmans, Qingyun W u, Lizhong Chen, and Huazheng W ang. 2024. Llm-rankfusion: Mitigating intrinsic inconsis- tency in llm-based ranking. arXiv preprint (cs.IR) .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment