인공지능 인사 평가: LLM 기반 후보자 분석과 리스트형 순위화
본 논문은 대형 언어 모델(LLM)을 활용해 채용 과정의 후보자 평가와 순위 산정을 자동화하는 모듈형 프레임워크를 제안한다. 직무 설명을 기반으로 맞춤형 평가 루브릭을 생성하고, 이 루브릭을 토대로 이력서·인터뷰·HR 피드백 등 다양한 데이터를 통합해 구조화된 평가 보고서를 만든다. 특히 후보자를 소규모 그룹(미니 토너먼트)으로 동시에 평가하고, 그 결과를 Plackett‑Luce 모델로 통합하는 리스트형 토너먼트와 활성 학습 메커니즘을 도입해…
저자: Kamer Ali Yuksel, Abdul Basit Anees, Ashraf Elneima
본 논문은 대형 언어 모델(LLM)을 활용한 후보자 평가 및 순위화 시스템을 설계·구현하고, 이를 실제 채용 워크플로우에 적용 가능한 형태로 제시한다. 전체 구조는 다단계 모듈 파이프라인으로 구성되며, 각 단계는 전용 LLM 에이전트와 맞춤형 프롬프트에 의해 구동된다.
1. **루브릭 자동 생성 (Criteria Generation Agent)**
- 입력: 직무명·직무 상세 설명.
- 출력: 12~20개의 세부 평가 항목을 포함하는 YAML 스키마. 각 항목은 기술·비기술 역량을 모두 포괄하고, Low·Medium·High 3단계 평가 기준과 구체적 정의를 제공한다.
- 특징: 일반적인 ‘리더십·커뮤니케이션’ 같은 공통 항목을 유지하면서, 직무 특성에 맞는 세부 항목(예: 머신러닝 모델 설계, 클라우드 인프라 운영 등)을 자동 삽입한다.
2. **비디오 질문·답변 생성 (Video Question Generation Agent)**
- 직무 루브릭에 기반해 후보자에게 맞춤형 비디오 인터뷰 질문을 생성하고, 응답을 자동 전사·분석한다.
3. **다중 모달 데이터 통합 및 평가 (Assessment Generator Agent)**
- 후보자의 이력서, 비디오 전사본, HR 코멘트, 내부 추천서 등을 하나의 프롬프트에 결합한다.
- LLM은 루브릭을 기준으로 각 항목별 증거를 추출하고, 해당 증거가 왜 특정 등급에 해당하는지를 단계별 논리와 함께 마크다운 형식으로 출력한다.
- 비디오 분석 모듈은 얼굴 표정·음성 톤·바디 랭귀지를 정량화해 비언어적 역량을 텍스트 기반 평가와 융합한다.
4. **보고서 자동 생성 (Formatter Agent)**
- 평가 결과를 구조화된 마크다운 보고서로 포맷한다. 보고서는 (① 직무·후보 요약, ② 항목별 등급·증거, ③ 종합 적합도, ④ 문화 적합성·개발 필요 영역, ⑤ 대체 직무 제안·신뢰도 지표) 로 구성된다.
5. **비교·순위화 (Comparison Agent, Ranking Agent)**
- 후보자 간 비교를 위해 ‘리스트형 토너먼트’ 방식을 도입한다. K(5~10)명의 후보를 동시에 LLM에 제시하고, LLM은 내부 추론 후 순위 리스트만 반환한다.
- 각 리스트는 K·(K‑1)/2 개의 암묵적 pairwise 관계를 포함한다.
6. **Plackett‑Luce 기반 전역 순위 추정**
- 수집된 모든 리스트형 순위를 PL 모델에 입력해 잠재적 ‘후보 적합도 유틸리티’를 추정한다.
- 로그우도 최적화를 통해 전역 유틸리티 벡터를 얻고, 라플라스 근사로 후방 분산을 계산한다. 이 분산은 후보 간 불확실성을 정량화한다.
7. **활성 학습 루프**
- PL 모델 업데이트 후, 불확실성이 큰 후보군을 식별한다.
- MC‑KG, posterior disagreement sampling, KL‑UCB 등 다양한 획득 함수를 사용해 가장 정보 이득이 큰 후보 서브셋을 선택하고, 새로운 리스트형 토너먼트를 수행한다.
- 이를 반복함으로써 LLM 호출 횟수를 최소화하면서도 전역 순위의 수렴 속도를 높인다.
8. **피드백 통합 (Feedback Integration Module)**
- 채용 후 성과 리뷰·이직률·팀 피드백 등을 수집해 루브릭·프롬프트·PL 모델을 재학습한다. 이는 시스템이 실제 업무 성과와 지속적으로 정렬되도록 만든다.
**실험 및 평가**
- 대상 직무: AI Research Scientist, Staff ML Engineer, VP of Product, CTO 등 4가지 직무, 각각 30~50명의 후보자.
- 인간 평가자는 동일 루브릭을 사용해 Low/Medium/High 등급을 부여했다.
- 시스템 평가와 인간 평가 간의 일치도는 전체 차원에서 87%가 ±1 등급 내에 머물렀으며, 특히 ‘리더십·팀워크’와 같은 비기술 항목에서 높은 일관성을 보였다.
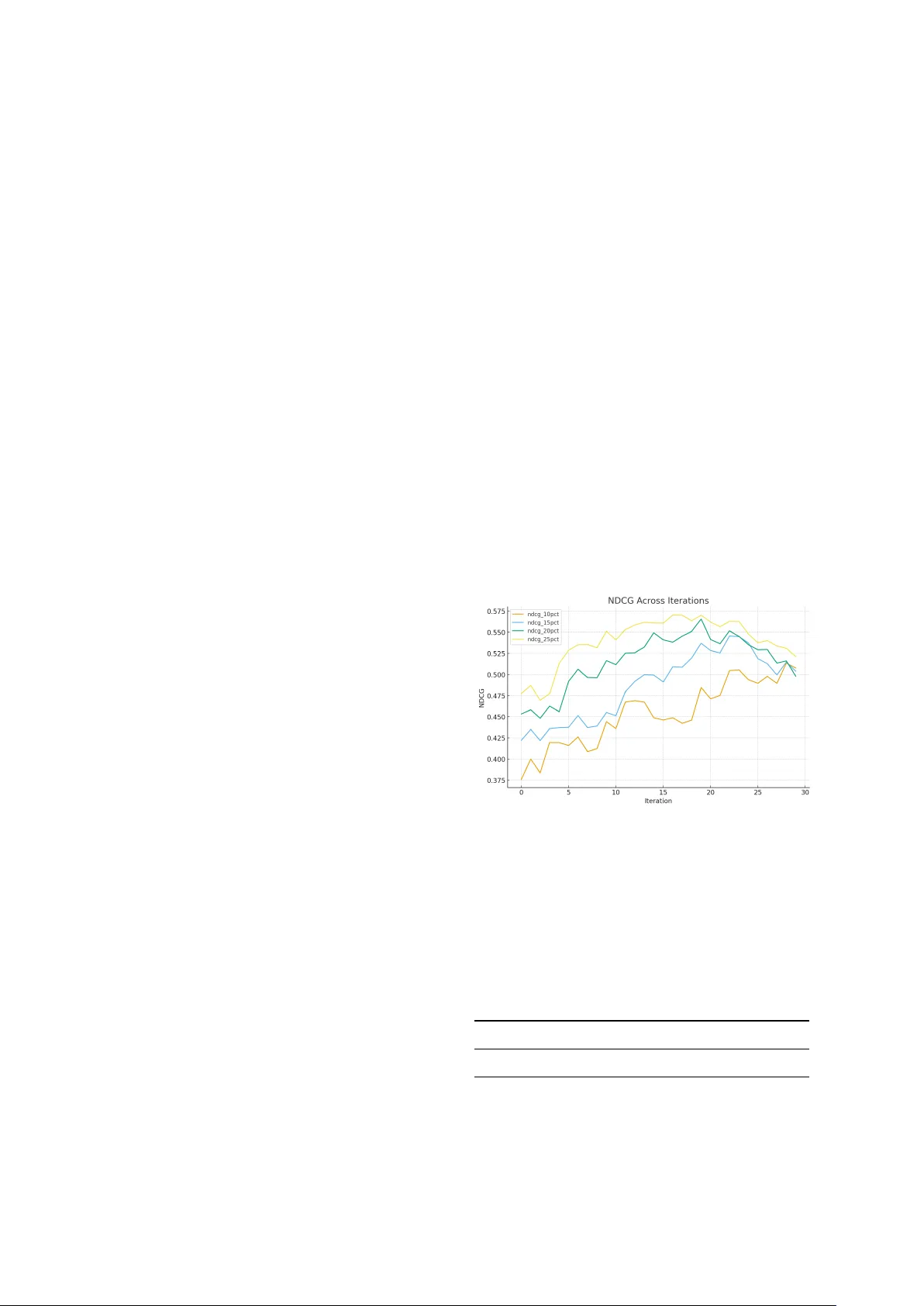
- 리스트형 토너먼트 기반 순위는 전통적인 점수 기반 순위보다 NDCG@10이 12% 상승했으며, 활성 학습을 적용했을 때 전체 LLM 호출 수가 약 40% 감소했다.
- 사례 분석에서는 시스템이 인간 평가자가 놓친 미세 차이를 포착해 후보자 간 차별화 포인트를 제공한 점이 강조되었다.
**시사점 및 한계**
- 투명성: 루브릭·보고서·PL 유틸리티 모두 구조화된 형태로 제공돼 감사 가능성이 높다.
- 확장성: 모듈형 설계와 플러그인 방식 덕분에 기업별 HR 시스템에 손쉽게 통합 가능하다.
- 비용 효율성: 활성 학습을 통한 LLM 호출 최소화는 실제 운영 비용을 크게 낮춘다.
- 한계: LLM의 프롬프트 민감도와 ‘hallucination’ 위험은 여전히 존재하며, 고위험 직무(예: 의료·보안)에서는 추가 검증 단계가 필요하다.
**결론**
본 연구는 LLM을 활용해 후보자 평가를 루브릭 기반으로 구조화하고, 리스트형 토너먼트와 Plackett‑Luce 모델을 결합해 통계적으로 일관된 전역 순위를 제공한다. 다중 모달 데이터 통합·활성 학습·피드백 루프를 통해 평가 정확도와 비용 효율성을 동시에 달성했으며, 실제 HR 워크플로우에 적용 가능한 실용적인 시스템을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기