Real-Time Stream Compaction for Sparse Machine Learning on FPGAs
Machine learning algorithms are being used more frequently in the first-level triggers in collider experiments, with Graph Neural Networks pushing the hardware requirements of FPGA-based triggers beyo
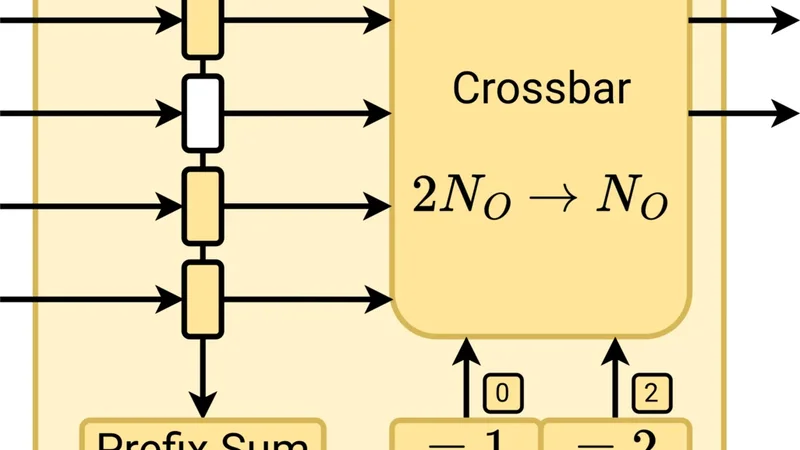
Machine learning algorithms are being used more frequently in the first-level triggers in collider experiments, with Graph Neural Networks pushing the hardware requirements of FPGA-based triggers beyond the current state of the art. To meet the stringent demands of high-throughput and low-latency environments, we propose a concept for latency-optimized preprocessing of sparse sensor data, enabling efficient GNN hardware acceleration by removing dynamic input sparsity. Our approach rearranges data coming from a large number of First-In-First-Out interfaces, typically sensor frontends, to a smaller number of FIFO interfaces connected to a machine learning hardware accelerator. In order to achieve high throughput while minimizing the hardware utilization, we developed a hierarchical sparsity compression pipeline optimized for FPGAs. We implemented our concept in the Chisel design language as an open-source hardware generator. For demonstration, we implemented one configuration of our module as preprocessing stage in a GNN-based first-level trigger for the Electromagnetic Calorimeter inside the Belle II detector. Additionally we evaluate latency, throughput, resource utilization, and scalability for a wide range of parameters, to enable broader use for other large scale scientific experiments.
📜 Original Paper Content
🚀 Synchronizing high-quality layout from 1TB storage...