Sample-efficient evidence estimation of score based priors for model selection
The choice of prior is central to solving ill-posed imaging inverse problems, making it essential to select one consistent with the measurements $y$ to avoid severe bias. In Bayesian inverse problems, this could be achieved by evaluating the model ev…
Authors: Frederic Wang, Katherine L. Bouman
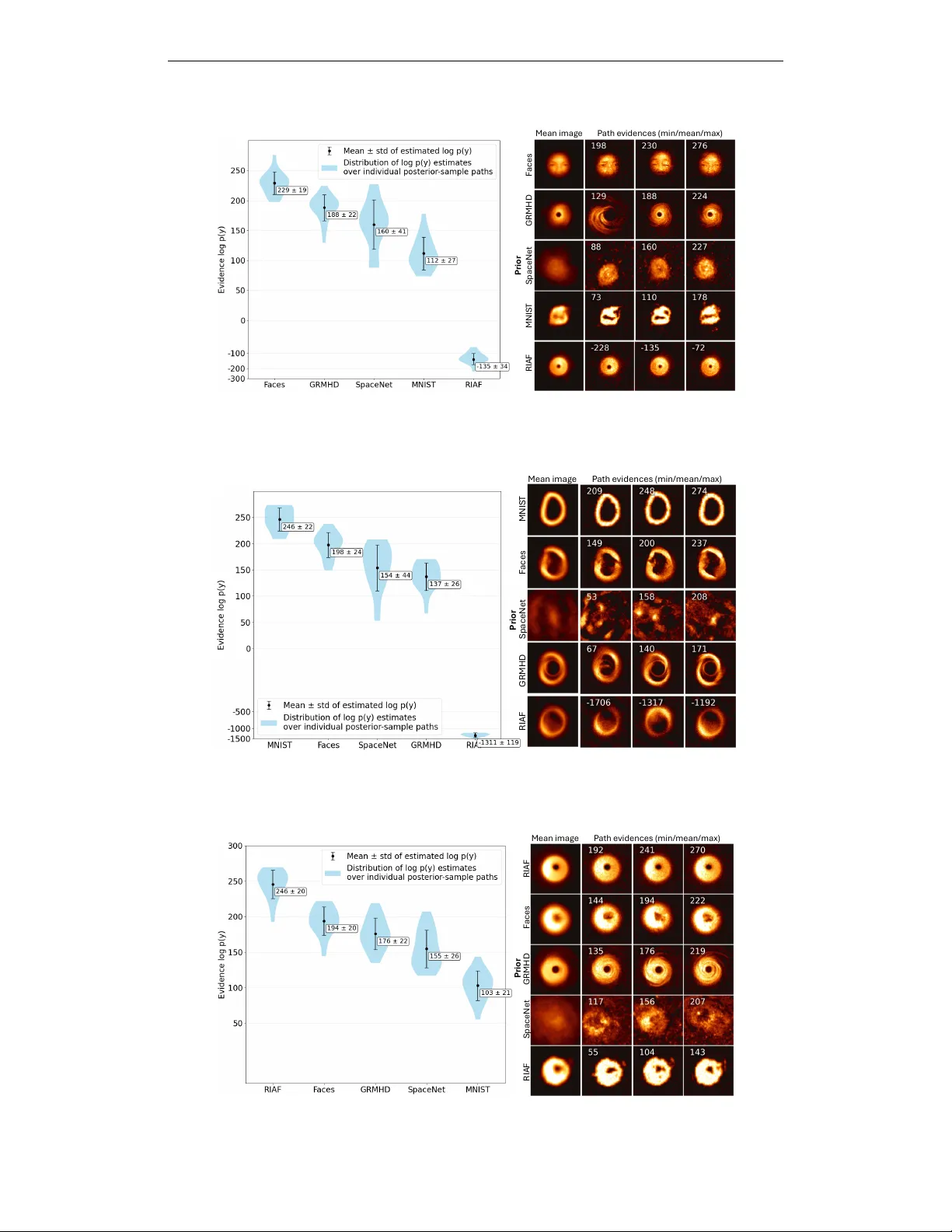
Published as a conference paper at ICLR 2026 S A M P L E - E FFI C I E N T E V I D E N C E E S T I M A T I O N O F S C O R E B A S E D P R I O R S F O R M O D E L S E L E C T I O N Frederic W ang & Katherine L. Bouman ∗ Department of Computing and Mathematical Sciences Caltech Pasadena, CA 91125, USA { fzwang, klbouman } @caltech.edu A B S T R A C T The choice of prior is central to solving ill-posed imaging in verse problems, mak- ing it essential to select one consistent with the measurements y to av oid se vere bias. In Bayesian in verse problems, this could be achieved by ev aluating the model evidence p ( y | M ) under different models M that specify the prior and then se- lecting the one with the highest v alue. Diffusion models are the state-of-the-art approach to solving in verse problems with a data-driv en prior; howe ver , directly computing the model e vidence with respect to a dif fusion prior is intractable. Fur - thermore, most existing model e vidence estimators require either many pointwise ev aluations of the unnormalized prior density or an accurate clean prior score. W e propose DiME , an estimator of the model evidence of a dif fusion prior by inte grat- ing over the time-marginals of posterior sampling methods. Our method lev erages the large amount of intermediate samples naturally obtained during the reverse diffusion sampling process to obtain an accurate estimation of the model e vidence using only a handful of posterior samples (e.g., 20). W e also demonstrate how to implement our estimator in tandem with recent diffusion posterior sampling methods. Empirically , our estimator matches the model evidence when it can be computed analytically , and it is able to both select the correct diffusion model prior and diagnose prior misfit under different highly ill-conditioned, non-linear in verse problems, including a real-world black hole imaging problem. 1 I N T R O D U C T I O N In Bayesian in verse imaging problems across science and engineering, the chosen prior distribution p ( x ) plays a piv otal role in shaping the posterior p ( x | y ) from which candidate solutions are drawn (Feng et al., 2024; Stuart, 2010). In ill-posed settings, the prior acts as a regularizer , steering reconstructions to ward solutions consistent with expected image properties. If the ground truth image lies outside the support of the chosen prior , the resulting reconstruction can be sev erely biased. A central challenge in Bayesian inference is how to select a prior to use when the true distribution is unknown. Consequently , the priors used in practice are often chosen somewhat arbitrarily . If the likelihood of a prior could be easily e valuated, it would provide a principled basis for prior selection. Specifically , given a set of potential models { M i } that specify the prior p ( x | M i ) , we would like to find the most likely candidate model by computing p ( M i | y ) ∝ p ( y | M i ) p ( M i ) . It is commonly assumed that p ( M i ) is uniform, so it suffices to compute the (log) model evidence , log p ( y | M i ) . Model e vidence is not only useful for selecting the best prior for reconstruction, but also for quantifying epistemic uncertainty and assessing the assumptions underlying a model or physical theory (T rotta, 2007). Although the model evidence provides a principled way to select the best prior for reconstruction, computing it generally requires ev aluating an intractable integral over the full prior: log p ( y | M i ) = log R p ( y | x , M i ) p ( x | M i ) d x . This motiv ates the de velopment of estimation methods, such ∗ Use footnote for providing further information about author (webpage, alternative address)— not for ac- knowledging funding agencies. Funding acknowledgements go at the end of the paper . 1 Published as a conference paper at ICLR 2026 as sequential Monte Carlo (Del Moral et al., 2006; Chen et al., 2024), nested sampling (Skilling, 2006; Cai et al., 2022), annealed importance sampling Neal (2001); Doucet et al. (2022), and har- monic mean estimators (Newton & Raftery, 1994; McEwen et al., 2021; Polanska et al., 2023; Spurio Mancini et al., 2023). Ho wever , these methods rely on sampling using the clean prior score ∇ x log p ( x ) or the unnormalized density log p ( x ) , which may be inaccurate for out-of-distribution x , expensi ve to e valuate, and can lead to slo w mixing due to the ill-conditioned data geometry . Bayesian in verse imaging solvers achieve state-of-the-art performance with diffusion-based priors (Song et al., 2020; Ho et al., 2020; Song et al., 2021b; Jalal et al., 2021; Mardani et al., 2023), yet an accurate model evidence remains intractable using existing methods. Diffusion models generate unconditional samples by denoising a sequence of intermediate noised images, each corresponding to a time-marginal distribution between pure noise and the clean image. Dif fusion-based poste- rior sampling methods adhere to intermediate posterior time-marginals instead (Chung et al., 2022; Song et al., 2023; Li et al., 2024; Zhu et al., 2023; W u et al., 2024; Zhang et al., 2025). While efficient diffusion density estimators have been proposed (Skreta et al., 2024), density-based estima- tion methods are still typically high-variance for high dimensional problems and require thousands of posterior samples, which is computationally challenging with diffusion models. Furthermore, as diffusion models learn the score of intermediate noised priors, their estimates of the clean prior score are usually less accurate and/or highly ill-conditioned, making it difficult for traditional methods to explore the full distrib ution, while using their score from a higher noise lev els can add bias. As a result, existing estimators are not suitable for or gi ve biased estimates for dif fusion-based priors. Our contribution: W e propose the Dif fusion Model Evidence ( DiME ) estimator , a method for es- timating the model e vidence under a diffusion model prior that does not require the prior score or density . W e derive the estimator for posterior sampling methods that anneal along the standar d (pos- terior) mar ginals p ( x t | y ) , as well as a generalized estimator for any arbitrary path of marginals that anneal to the true posterior . By integrating along these posterior time-marginals, DiME accu- rately estimates the model evidence using intermediate samples already generated during posterior sampling. DiME thus only requires a small number of posterior samples (e.g., 20) for accurate esti- mation. W e also describe how to practically implement DiME alongside a state-of-the-art posterior sampling method Decoupled Annealing Posterior Sampling (D APS). W e perform se veral experiments v alidating our method. W e first test in a mixture of Gaussian setting where an analytic evidence can be deriv ed, and find that DiME provides nearly unbiased estimates of the evidence and performs comparably to baselines sequential Monte Carlo, annealed importance sampling, and thermodynamic integration despite not using the prior score. W e also test DiME on two non-con vex in verse problems, Gaussian and Fourier phase retrie val. DiME consistently selects the correct prior from a set of 10 diffusion models trained on MNIST (Deng, 2012) digits given a single noisy measurement of one MNIST digit, while the baselines fail to do so. Finally , we use our method to perform both model selection and v alidation on real M87* black hole observations from the Event Horizon T elescope (EHTC, 2019a;b). DiME indicates that a prior deriv ed from synthetic black hole images generated using General-Relativistic Magnetohydrody- namics (GRMHD) (Mizuno, 2022) has higher likelihood compared to the Radiatively Inefficient Accretion Flow (RIAF) (Broderick et al., 2011) black hole prior , a prior trained on general space images (Alam et al., 2024), a prior trained on faces (Liu et al., 2015), and a prior trained on MNIST digit 0s. Furthermore, we diagnose the validity of the GRMHD prior by prior predicti ve checking on the model evidence. Our results suggest that the M87* observ ations are statistically in-distribution with respect to the GRMHD prior , while still leaving room in the model for refinement. 2 B A C K G R O U N D 2 . 1 D I FF U S I O N M O D E L S Giv en a clean image x 0 ∼ p 0 ( x 0 ) , the diffusion forw ard process at time t ∈ [0 , T ] is given by: x t = a t x 0 + σ t z t , z t ∼ N (0 , I ) (1) where a t is the signal scaling, σ t is noise scaling, and a ′ t , σ ′ t are the time deri vati ves. W e can sample from the clean image distribution by discretizing the re verse SDE: d x t = h a ′ t a t x t − g 2 t ∇ x t log p t ( x t ) i dt + g t d w t (2) 2 Published as a conference paper at ICLR 2026 where g 2 t = 2 σ t σ ′ t − a ′ t a t σ 2 t , w t is Brownian motion and ∇ x t log p t ( x t ) is learned. W e can also obtain the posterior mean via T weedie’ s formula (Efron, 2011): E [ x 0 | x t ] = 1 α t x t + σ 2 t ∇ x t log p ( x t ) . (3) 2 . 2 D I FF U S I O N - BA S E D P O S T E R I O R S A M P L I N G M E T H O D S Most dif fusion posterior sampling methods fall broadly under two cate gories: (1) explicitly approx- imating the intractable likelihood score ∇ x t log p t ( y | x t ) as guidance during re verse diffusion, and (2) methods that explicitly anneal along a path of specified intermediate marginals, using techniques such as sequential Monte Carlo (Cardoso et al., 2023; W u et al., 2023), gradient-based optimization (Moufad et al., 2024), or Lange vin dynamics (Zhang et al., 2025; W u et al., 2024; Zhu et al., 2023). The approximation errors of (1) compound o ver the sampling process, resulting in intermediate time-marginals with no tractable form and a biased posterior , while (2) corrects these errors by ad- hering to a specified mar ginal path, allowing for their time-marginals to anneal to the true posterior . As a result, in this work we focus on two different sampling methods of (2) that have demonstrated strong performance for solving physical in verse problems (Zheng et al., 2025). Concretely , giv en measurements y from an in verse problem y = A ( x ) + ε we introduce two likelihood terms. The first, p ( y | x t ) = R p ( y | x 0 ) p ( x 0 | x t ) d x 0 is the marginal likelihood of y conditioned on the current diffusion state x t . The second, q ( y | x t ) := p ( y | x 0 = x t ) is a time-independent data likelihood term that assumes x t is the clean image. The Decoupled Annealing P osterior Sampling (DAPS) method (Zhang et al., 2025) alternates be- tween noising and sampling from the posterior . Given initial noise samples x T ∼ N (0 , I ) and N -step annealing schedule [ t 1 , . . . , t N ] , we sample from the clean image posterior using Lange vin dynamics before re-adding noise according to the diffusion process: ˜ x 0 ∼ p ( x 0 | x t k , y ) ∝ p ( y | x 0 ) p ( x 0 | x t k ) (4) x t k − 1 ∼ p ( x t k − 1 | ˜ x 0 ) (5) Zhang et al. (2025) proposes two approaches: Gaussian appr oximation D APS , where p ( x 0 | x t ) is approximated via a Gaussian N ( E [ x 0 | x t ] , Σ x 0 | x t ) and the cov ariance Σ x 0 | x t is heuristically chosen as σ 2 t , and exact DAPS , where the prior score is computed using the diffusion model at a tiny noise lev el ∇ log p ( x 0 ) ≈ ∇ log p ( x , σ min ) . The unconditional distribution of intermediate samples closely match the standar d mar ginals : x t ∼ p ( x t | y ) ∝ p ( y | x t ) p ( x t ) for all times t . The Plug-and-Play Diffusion Models (PnP-DM) sampling method (W u et al., 2024) takes inspira- tion from the Split Gibbs Sampler (V ono et al., 2019) by splitting each annealing iteration into a likelihood step and a prior step. In particular, given N -step annealing schedule [ t 1 , . . . , t N ] and clean image initialization ˆ x 0 , we alternate between running Langevin dynamics to obtain a sample from the next time-marginal posterior and using the diffusion model to sample a clean image. W e rewrite the updates for one timestep t k in terms of standard diffusion notation: x t k ∼ q ( x t k | y , ˆ x 0 ) ∝ q ( y | x t k ) p ( x t k | ˆ x 0 ) (6) ˆ x 0 ∼ p ( x 0 | x t k ) (7) where x t k is sampled from a joint distrib ution of the noised ˆ x 0 and the time-independent likelihood q . W e write q ( y | x t k ) to emphasize this proxy likelihood applies the measurement model directly to a noisy rather than clean image. W e refer to the resulting unconditional distributions of intermediate samples as PnP-DM mar ginals , denoted by x t ∼ q ( x t | y ) ∝ q ( y | x t ) p ( x t ) for all t . 2 . 3 E X I S T I N G M O D E L E V I D E N C E E S T I M A T O R S The simplest estimator approximates the evidence by av eraging p ( y | x ) over samples x ∼ p ( x ) , though this requires exponentially many samples in high dimensions. The standard harmonic mean estimator (Newton & Raftery, 1994) mitig ates this issue b ut has infinite v ariance. Learned harmonic mean estimators (McEwen et al., 2021; Polanska et al., 2023; Spurio Mancini et al., 2023) stabilize 3 Published as a conference paper at ICLR 2026 the variance by importance sampling with a surrogate neural density , under the assumption that the prior density is known. Howe ver , surrogate training requires thousands of posterior samples and importance sampling requires a similar amount of density ev aluations ev en in medium-dimensional settings, making these approaches infeasible for diffusion-based priors. Nested sampling (Skilling, 2006; Cai et al., 2022) re-parametrizes the model evidence into a one- dimensional integral ov er the prior volume, but still requires the score or density and is limited to log-con ve x likelihoods. Thermodynamic integration (TI) (Lartillot & Philippe, 2006), annealed im- portance sampling (AIS) (Neal, 2001) and sequential Monte Carlo (SMC) (Del Moral et al., 2006) compute the evidence by integrating over a path of distributions p β , with 0 ≤ β ≤ 1 . For diffusion priors, accurately sampling from arbitrary p β ( x ) is computationally difficult as we lack a clean prior score. Rev erse diffusion Monte Carlo (RDMC) (Huang et al., 2023) methods simulate the dif fusion process to sample from unnormalized densities, using a Monte Carlo approach to approximate the noised scores. Guo et al. (2025) independently derived an evidence estimator for the reverse dif- fusion process under very dif ferent assumptions: they rely on a closed-form posterior score, obtain exact posterior marginals directly from an analytic diffusion that is not learned, and provide only theoretical con ver gence results without experimental v alidation. 3 E S T I M A T I N G T H E M O D E L E V I D E N C E A L O N G T H E S T A N D A R D M A R G I N A L S W e introduce DiME to estimate model e vidence from the standard marginals p ( x t | y ) , aligning closely with the annealing path of D APS. All proofs in this section are shown in Appendix A. A general model e vidence estimator for arbitrary marginals annealing to the true posterior is deri ved in Appendix B, and an unnormalized model evidence estimator that instead uses the PnP-DM marginals ( DiME-PnPDM ) is deriv ed and implemented in Appendix B.1. Proposition 1 ( DiME : Model e vidence estimation along the standard marginals) . Given diffusion pr ocess x t = a t x 0 + σ t z t , z t ∼ N (0 , I ) , posterior mar ginals p ( x t | y ) ∝ p ( x t ) R p ( y | x 0 ) p ( x 0 | x t ) d x 0 , and timesteps 0 = t 0 < · · · < t N = T , the model evidence can be estimated via: log p ( y ) = E x 0 ∼ p ( x 0 | y ) log p ( y | x 0 ) − D KL ( p ( x 0 | y ) || p ( x 0 )) . (8) The log-likelihood term can be estimated with posterior samples 1 , and the KL diver gence with: D KL ( p ( x 0 | y ) || p ( x 0 )) ≈ N X i =1 c t i ∆ t i E x t i ∼ p ( x t i | y ) ∥∇ x t i log p ( y | x t i ) ∥ 2 (9) wher e c t i = σ ′ t i σ t i − σ 2 t i a ′ t i a t i is dependent on the diffusion sc hedule and ∆ t i = t i − t i − 1 . The sum across each sample-path { x t i } i =0 ,...,N can be viewed as the distance of the resulting pos- terior sample x 0 to the prior . In the remainder of the section, we sho wcase ho w to practically implement DiME in tandem with the D APS method but with two modifications: in Section 3.1 we design an impro ved covariance approximation 2 for p ( x 0 | x t ) if the Gaussian approximation D APS is used, and in Section 3.2 we propose to sample two ˜ x 0 ∼ p ( x 0 | x t , y ) for each x t to estimate ∥∇ x t log p ( y | x t ) ∥ 2 needed for Eq. 9. The full algorithm can be seen in Algorithm 1. 3 . 1 A N I M P ROV E D A P P RO X I M A T I O N F O R T H E P O S T E R I O R C OV A R I A N C E While the exact D APS sampler can be used for accurate sampling of ˜ x 0 ∼ p ( x 0 | x t , y ) ∝ p ( y | x 0 ) p ( x 0 | x t ) (Eq. 4), Gaussian approximation D APS provides a significantly cheaper alternati ve by approximating p ( x 0 | x t ) ≈ N ( E [ x 0 | x t ] , σ 2 t ) . Howe ver , this cov ariance heuristic only ac- counts for p ( x t | x 0 ) and ignores p ( x 0 ) . While this heuristic is accurate at low noise lev els, it ov erestimates the variance in the high noise regimes: at the terminal noise lev el t = T , we expect p ( x 0 | x T ) ≈ p ( x 0 ) with a co variance that should match the prior Cov( x 0 ) , but the heuristic giv es 1 For likelihoods with Gaussian noise, if the posterior and prior hav e enough ov erlap such that posterior samples hav e a data fit of χ 2 ≈ 1 , this term essentially becomes constant under the same likelihood function. 2 While approximating p ( x 0 | x t ) is necessary for the standard marginals annealing path, it is not necessary for many annealing paths under the generalized frame work introduced in Appendix B. 4 Published as a conference paper at ICLR 2026 Θ !"# ( # 𝑥 $ ) ! 𝑥 ! 𝔼[𝑥 ! ∣ 𝑥 " ] ! 𝑥 ! Θ %&'% ( # 𝑥 $ ) In Distri bution Out of Distribution ! 𝑥 ! Θ %&'% ( # 𝑥 $ ) ! 𝑥 ! Θ !"# ( # 𝑥 $ ) d iffusion timest ep Large t Small t Legend: 𝑝(𝑥 ! |𝑥 " ) 𝑝(𝑦|𝑥 ! ) ! 𝑥 ! ~𝑝 𝑦 𝑥 ! 𝑝(𝑥 ! |𝑥 " ) 𝑝(𝑥 ! ) estimat ors of ∇ ( ! log 𝑝(𝑦 |𝑥 ) ) 𝔼[𝑥 ! ∣ 𝑥 " ] 𝑡 = 0 𝑡 = 𝑇 Figure 1: V isualization of the unbiased estimators Θ hig h , Θ low of the likelihood score ∇ x t log p ( y | x t ) described in Lemma 2 for both in-distribution (left) and out-of-distribution (right) measurements y . At large diffusion time steps, the high noise estimator (top) uses the distance between ˜ x 0 and E [ x 0 | x t ] . At small dif fusion time steps, the lo w noise estimator (bottom) uses the likelihood score at ˜ x 0 . The estimator is larger (longer arrows) when y is out-of-distrib ution, as there greater KL div ergence from the posterior to the prior; this results in DiME computing a lower evidence. Note the scaling factors a t σ 2 t and Σ x 0 | x t of the estimator are not shown. Co v ( x 0 | x T ) ≈ σ 2 T ≫ Cov( x 0 ) . This mismatch at high noise was also observed empirically in Zhang et al. (2025). Since DiME uses all time-marginals it is important to accurately estimate p ( x 0 | x t ) for all t . Therefore, we include knowledge of p ( x 0 ) by approximating it as Gaussian N ( µ 0 , Σ 0 ) , using an empirical cov ariance computed from the training data similar to the cov ari- ance approximation introduced in Linhart et al. (2024). Introducing an approximate prior provides a more accurate representation of p ( x 0 | x t ) , which remains a Gaussian approximation as it is now the product of two Gaussians. The resulting cov ariance is given by: Lemma 1. Suppose we have dif fusion pr ocess x t = a t x 0 + σ t z t , z t ∼ N (0 , I ) . Let x t ∼ p ( x t ) and suppose p ( x 0 ) ≈ N ( µ 0 , Σ 0 ) . Then we can expr ess the posterior covariance Σ x 0 | x t as Σ x 0 | x t = Σ − 1 0 + a 2 t σ 2 t I − 1 . (10) For lar ge images where computing a full cov ariance matrix is intractable, a diagonal approximation in a transform basis has also been demonstrated to work well (Peng et al., 2024), and for linear in verse problems, an analytic local cov ariance is computable (Boys et al., 2023). Our approximation aligns the annealing path more closely with p ( x t | y ) for all t . It is worth noting that D APS re-samples at every annealing step, ensuring that these Gaussian approximation errors are ne ver compounded. As shown in Sections 4.1 and 4.3.1, using the proposed improv ed approximation leads to nearly unbiased evidence estimates for both a multimodal Gaussian toy example with varying local curvature as well as real-w orld scientific priors. 3 . 2 E S T I M A T I N G T H E S Q UA R E D L I K E L I H O O D S C O R E While directly computing ∇ x t log p ( y | x t ) is intractable, DiME only requires an unbiased estimate as seen in Eq. 9. Estimators using unconditional samples of x 0 | x t are high-variance: these samples usually have low likelihood p ( y | x 0 ) resulting in volatile scores. Thankfully , D APS provides samples of ˜ x 0 ∼ p ( x 0 | x t , y ) , which we can use to create estimators with lower variance: Lemma 2. Suppose we have diffusion pr ocess x t = a t x 0 + σ t z t , z t ∼ N (0 , I ) and sample ˜ x 0 ∼ p ( x 0 | x t , y ) . Under the assumption that p ( x 0 | x t ) ≈ N ( E [ x 0 | x t ] , Σ x 0 | x t ) , both Θ hig h ( ˜ x 0 ) 5 Published as a conference paper at ICLR 2026 and Θ low ( ˜ x 0 ) are unbiased estimator s of ∇ x t log p ( y | x t ) with Θ hig h ( ˜ x 0 ) = a t σ 2 t ( ˜ x 0 − E [ x 0 | x t ]) . (11) Θ low ( ˜ x 0 ) = a t σ 2 t Σ x 0 | x t ∇ ˜ x 0 log p ( y | ˜ x 0 ) . (12) Under low diffusion noise ( a t → 1 , σ t → 0) , V ar(Θ low ) → 0 b ut V ar(Θ hig h ) = O ( 1 σ 2 t ) . Under high noise ( a t → 0 , σ t → 1) , V ar(Θ hig h ) → 0 b ut V ar(Θ low ) = O ( σ 4 t σ 4 y V ar(Θ hig h )) . A proof of these bounds is displayed in Appendix A.1. The lack of the measurement y in the high noise estimator bounds the worst possible case, where the data is weak; when the measurement con- tains a lot of information, the variance would be much lower . As such, Θ hig h is used more towards the beginning of the sampling process while Θ low is used tow ards the end. As both estimators are cheap to compute, we can simply ev aluate both and choose the lower v ariance estimator at each timestep. Finally , as we want an unbiased estimate of the squar ed likelihood score, squaring the estimator is biased: E ∥ Θ ∥ 2 = ∥ E Θ ∥ 2 + T r (Cov(Θ)) . Therefore, for each intermediate sample x t , we propose to sample two i.i.d ˜ x (1) 0 , ˜ x (2) 0 ∼ p ( x 0 | x t , y ) , giving us the follo wing unbiased esti- mator: Θ( ˜ x (1) 0 ) T Θ( ˜ x (2) 0 ) . The full method is displayed in Algorithm 1, and a visualization for both in-distribution and out-of-distrib ution measurements is visualized in Figure 1. Algorithm 1 One posterior sample-path of DiME implemented with DAPS Require: Score-based model s θ , measurement y , noise schedule σ t , ( t i ) i ∈{ 1 ,...,N } 1: Sample x t N ∼ N (0 , σ 2 t N I ) . 2: Initialize the integral sum, f = 0 . 3: for i = N , N − 1 , . . . , 1 do 4: Compute ˆ x = E [ x 0 | x t ] using T weedie’ s formula and s θ . 5: Sample ˜ x (1) 0 , ˜ x (2) 0 ∼ p ( x 0 | x t i , y ) using Lange vin with p ( x 0 | x t ) = N ( ˆ x , Σ x 0 | x t ) . (3.1) 6: Sample x t i − 1 ∼ N ( a t i − 1 ˜ x (1) 0 , σ 2 t i − 1 I ) . 7: f i = arg min Θ ∈{ Θ low , Θ high } V ar(Θ( ˜ x (1) 0 ) T Θ( ˜ x (2) 0 )) computed using all sample-paths. (3.2) 8: Update the integral sum f ← f + ( t i − t i − 1 ) σ ′ t σ t − σ 2 t a ′ t a t f i . 9: end f or 10: return x 0 , − f + log p ( y | x 0 ) 4 E X P E R I M E N T S W e compare DiME and DiME-PnPDM with fi ve baselines: naiv e Monte Carlo (Nai ve MC), thermo- dynamic integration (TI), annealed importance sampling (AIS), Sequential Monte Carlo (SMC), and the original DAPS cov ariance heuristic (Original DAPS heuristic). Baseline methods are described in Appendix C and all tuning and implementation details are provided in Appendix D. 4 . 1 B E N C H M A R K I N G O N G A U S S I A N M I X T U R E P R I O R W I T H G RO U N D T R U T H E V I D E N C E T o verify DiME , we first test on a multimodal 1000-D Gaussian mixture prior and linear forward model y = Ax + ε , ε ∼ N (0 , σ 2 I ) where the model evidence has an analytic form to compare to. W e use two Gaussian components with means at ( − 0 . 75 , 0 . 75 ) and identical cov ariances of 0 . 25 I . The entries of A ∈ R 200 × 1000 are i.i.d. N (0 , 1 200 ) , and σ = 0 . 1 . W e run three experiments where the ground truth x ∗ has v arying model e vidence to test the rob ustness of our method: in-distribution x ∗ , out-of-distribution x ∗ , and x ∗ = 0 located at a saddle point. The analytic ∇ x log p ( x ) is used to sample the intermediate distributions for TI, AIS, and SMC. In contrast, for DiME the analytic ∇ x t log p ( x t ) is used to compute E [ x 0 | x t ] for σ t > 0 . 05 and the analytic score is ne ver used. All methods are tested using 100 discretization steps (equiv alently , annealing time steps for DiME ) and 20 sample paths for 50 trials. The mean and standard deviation is reported. 6 Published as a conference paper at ICLR 2026 In-distribution x ∗ Out-of-distribution x ∗ Saddle point x ∗ Estimate Rel. Error ↓ Estimate Rel. Error ↓ Estimate Rel. Error ↓ Ground truth log p ( y ) − 128 . 7 ± 0 . 0 0 . 0 − 1680 . 2 ± 0 0 . 0 − 251 . 3 ± 0 . 0 0 . 0 Naive MC (1000 samples) − 3283 ± 130 2451% − 41289 ± 577 2357% − 6029 ± 170 2299% Naive MC (10000 samples) − 3041 ± 113 2263% − 40123 ± 487 2288% − 5666 ± 144 2155% Original DAPS heuristic − 316 . 2 ± 79 . 5 146% − 1735 . 4 ± 4 . 7 3 . 3% − 269 . 6 ± 3 . 3 7 . 3% TI − 132 . 8 ± 1 . 3 3 . 2% − 1773 . 8 ± 11 . 8 5 . 6% − 254 . 2 ± 3 . 2 1 . 2% AIS − 135 . 9 ± 2 . 5 5 . 6% − 1754 . 6 ± 7 . 1 4 . 4% − 259 . 1 ± 2 . 9 3 . 1% SMC − 132 . 1 ± 1 . 0 2 . 6% − 1701 . 1 ± 5 . 8 1 . 2% − 253 . 0 ± 3 . 4 0 . 7 % DiME − 126 . 8 ± 2 . 8 1 . 5 % − 1674 . 8 ± 4 . 7 0 . 3 % − 253 . 3 ± 3 . 1 0 . 8% DiME-PnPDM * − 131 . 8 ± 2 . 0 2 . 4% − 1912 . 1 ± 6 . 5 13 . 8% − 245 . 9 ± 3 . 6 2 . 1% T able 1: Evidence estimates on Mixture of Gaussians study with analytic log p ( y ) and ground truth x ∗ in-distribution (top), out-of-distribution (middle), and at a saddle point (bottom). Mean and standard de viation of 50 trials displayed each with 20 sample paths. When the analytic prior score is av ailable, DiME performs comparably to the baselines for all cases, while DiME-PnPDM performs well when the ground truth is roughly in-distribution. *Important: as DiME-PnPDM outputs an unnormalized estimate, we normalize via the analytic constant factor for ease of comparison. Results are displayed in T able 1. DiME giv es nearly unbiased estimates of the evidence in all cases, with comparable performance to the strongest baseline (SMC), despite never using the true prior score. T o probe the effect of the covariance choice discussed in Sec. 3.1, we first consider the case where x ∗ lies within a prior mode (in-distribution). Here the original D APS heuristic consistently ov erestimates the variance of the marginals, pushing posterior samples into the wrong mode and inducing a large bias in the evidence estimate. Even when x ∗ is outside any single mode, the original heuristic continues to ov erestimate the evidence. In contrast, our improved cov ariance heuristic, incorporated in DiME , always generates samples from the correct mode and eliminates this bias, ev en when the true x ∗ lies in regions of local curv ature far from the unimodal Gaussian assumption. Unlike DiME , DiME-PnPDM only performs well for roughly in-distribution tasks. For out-of- distribution measurements y , while the PnP-DM marginals asymptotically anneal to the correct posterior , we find that in the finite-step case this annealing path results in greater bias than D APS. Because out-of-distrib ution measurements frequently arise in model selection, we conclude that PnP-DM is less well suited for this task. 4 . 2 M O D E L S E L E C T I O N U S I N G L E A R N E D S C O R E O N N O N - C O N V E X I N V E R S E P RO B L E M S W e test both DiME and the SMC baseline on two non-con vex inv erse problems, Gaussian phase retriev al and Fourier phase retriev al. In Gaussian phase retriev al, the forward model is y = | Ax | + ε , where A ∈ C m × n consists of i.i.d Gaussian N (0 , 1 m ) and ε ∼ N (0 , σ 2 I ) . In F ourier phase retriev al, the forward model is y = | F x | + ε , ε ∼ N (0 , σ 2 I ) where F is the discrete Fourier transform. In our experiments, we use m = 0 . 1 n and σ = 0 . 3 . While Fourier phase retriev al has many more measurements, the structured forward operator means that both translation and flips of x are in variances under the forward model. W e test with ten diffusion model priors, one on each MNIST (Deng, 2012) digit, and compute the evidence for each prior gi ven a measurement of each digit. For DiME , we use 50 annealing iterations and 20 generated sample-paths for each entry . For SMC, we use the learned ∇ x log p ( x t ) as a surrogate prior score at different lo w noise lev els. DiME results are shown in Figure 2, and SMC results are displayed in Appendix E. For both in verse problems, DiME always selects the correct model given a single noisy measurement y , while SMC often fails to do so, demonstrating that methods relying on a clean prior score are not suitable for diffusion-based model selection. For Gaussian phase retriev al, DiME predicts higher likelihoods of digits that look similar, such as 4 and 9 (Figure 2, bottom left, third row). For Fourier phase retriev al, DiME predicts high evidence for the MNIST 9 prior when the ground truth image is a 6 (and vice versa), but as both v ertical and horizontal flips are in variances under Fourier phase retriev al, performing these operations on a 6 results in a 9 (Figure 2, bottom right, second ro w). The normalized evidence can also provide useful insights: as the MNIST digit 1 prior has higher evidence for in-distribution y and lo wer evidence for out-of-distribution y , it must be a narrower prior . On the other hand, the MNIST 3, 5 and 8 priors hav e higher out-of-distrib ution model evidence, suggesting that they are wider priors, likely due to the v ariation in which humans write these digits. 7 Published as a conference paper at ICLR 2026 Figure 2: Model evidence confusion matrix for Gaussian phase retrieval ( left ) and Fourier phase retriev al ( right ) for each (ground truth measurement, model) pair of MNIST digits. Our method selects the correct model for all cases. Posterior samples sho wn for dotted matrix entries belo w . For Gaussian phase retrie val, DiME estimates higher model likelihood for visually similar digits, such as 4 and 9. For Fourier phase retrie val, both translations and reflections are inv ariances as seen in the posterior samples, so DiME estimates a high likelihood of model 9 giv en a measurement of a 6. 4 . 3 E V A L UA T I N G P R I O R M O D E L E V I D E N C E F O R R E A L M 8 7 * B L AC K H O L E D A T A In this section, we perform model selection and v alidation on real black hole M87* observations from April 6, 2017 (EHTC, 2019a;b). The need for such analysis was first emphasized during the release of the initial M87* images by the Event Horizon T elescope Collaboration (EHTC, 2019d), where the goal was not only to reconstruct images b ut also to test which simple parametric models best matched the data—particularly whether a ring provided the most suitable description (EHTC, 2019d; Broderick et al., 2020). In addition, the team directly compared the M87* data to a discrete set of synthetic black hole simulations (GRMHD) to assess which physical model parameters were most consistent with the observ ations (Fromm et al., 2019; EHTC, 2019d;c). Howe ver , as noted in EHTC (2019d), these conclusions are only valid to the extent that the selected simulations provide an adequate description of M87* – a question that can be answered by our proposed method. Measurements, known as visibilities , are obtained by combining signals collected by telescopes observing simultaneously at dif ferent locations around the world. The forward model for complex visibilities between two telescopes i , j is v i,j = g i g j e i ( ϕ i − ϕ j ) v ∗ i,j + ε i,j , where v ∗ i,j is the true visibilities measurements, g i is a station-dependent gain error, ϕ i is a station-dependent phase error arising from atmospheric noise and ε i,j is Gaussian thermal noise. T o become in variant to the phase error , we use the closure phase y cp = v i,j v j,k v k,i for a minimal set of 3 telescopes ( i, j, k ) and for similar in variance to the gain error , we use the closure amplitude y ca = v i,j v k,l v i,k v j,l for a minimal set of 4 telescopes ( i, j, k , l ) (Thompson et al., 2017; Blackb urn et al., 2020). W e use the In verseBench (Zheng et al., 2025) library to compute the likelihood. W e generate 20 posterior samples using 50 annealing steps and 1000 Lange vin dynamics steps per iteration. Gaussian approximation D APS takes around 4 minutes to compute, while exact D APS takes around 30 minutes to compute for the same parameters, a speedup of around 7x. 8 Published as a conference paper at ICLR 2026 Ga us si an Appr o xi ma ti on D APS Ex act D APS Figure 3: Model evidence estimates on real M87* observ ations across 5 different priors using e xact D APS ( left ) and Gaussian approximation DAPS ( right ). Our method concludes that, of these prior models, GRMHD is the most likely model. The violin plots sho w the distrib ution of evidences from 20 different posterior-sample paths from the D APS sampling process, and the mean is the ov erall evidence estimate. Gaussian approximation D APS gi ves highly accurate e vidence estimates with 7x less compute than exact D APS, but with slightly higher v ariance. RIAF M N I S T F ac es Sp ac eN et G RMHD M ean imag e P a th evid enc es (min / mean / max) M ean imag e P a th evid enc es (min / mean / max) P ri or G aussian Appr o xi ma ti on D APS Ex act D APS P ri or S ampl es Figure 4: M87* reconstructions using the 5 priors using exact DAPS ( left ) and Gaussian approxi- mation D APS ( middle ). While all posterior samples have a data fit of around reduced χ 2 ≈ 1 , they hav e v arying path evidence estimates (sho wn in the top left of each image), which are negati vely proportional to the KL div ergence between that posterior sample and the prior . Right: Example unconditional samples from each prior . 4 . 3 . 1 M O D E L S E L E C T I O N W e trained five candidate diffusion priors: (1) on 48000 General-Relativistic Magnetohydrodynamic (GRMHD) simulations (Mizuno, 2022), (2) on 9070 Radiati vely Inef ficient Accretion Flo w (RIAF) simulations (Broderick et al., 2011), (3) on 11000 general space images (SpaceNet) (Alam et al., 2024), (4) on 5923 MNIST (Deng, 2012) digit 0 images, and (5) on 48000 radially tapered CelebA Liu et al. (2015) images (Faces). Additionally , we augment our data during training to improv e generality and robustness of our priors. The GRMHD images are randomly flipped horizontally and/or vertically and zoomed in and out in the range [0 . 75 , 1 . 25] . The RIAF images were randomly flipped, zoomed in and out in the range [0 . 75 , 1 . 25] , and rotated uniformly in the range [0 , 2 π ] . The MNIST digit 0 images were zoomed in and out in the range [0 . 5 , 1] . Model selection results for the real M87* data can be seen in Figure 3. The mean reconstruction and posterior samples with the minimum, mean and maximum evidence (negati vely proportional to KL div ergence to prior) are sho wn on in Figure 4. Synthetic tests v alidating the method on this problem 9 Published as a conference paper at ICLR 2026 P ig eo n RIAF Ap p l e M o rphed Gr o u n d truth M ean imag e P a th ev id enc es (min / me an / max ) 147 212 255 4 5 74 114 OOD I ma g e 114 151 190 183 166 150 Figure 5: Left: GRMHD model validation results on M87* observations by comparing to e vidence of in-distrib ution measurements y . Our method sho ws that the evidence of M87* observations hav e a z -score of about -0.81 compared to the evidence distribution of GRMHD measurements, indicating that M87* is statistically in-distrib ution of GRMHD. The evidence of simulated measure- ments of out-of-distribution images are also shown, demonstrating that measurements from out-of- distribution (OOD) images ha ve OOD evidence. Right: Mean reconstruction and posterior samples of the OOD images with the highest and lowest distance to the GRMHD prior . The blurred ground truth image, or the maximum resolution that can be obtained from measurements, is also displayed. are shown in Appendix F. DiME determines that, for static imaging, GRMHD is the most likely prior for the M87* observ ations, follo wed by SpaceNet, Faces, MNIST , and finally RIAF . While SpaceNet contains a fe w black hole images in its training data, our method penalizes it for being too general, as demonstrated with its wide range of unconditional samples (Figure 3, right, second row). The RIAF model is a very narrow prior that enforces a strong assumption on the structure of black holes, so an y out-of-distribution images (such as M87* as determined by our method) will ha ve lo w likelihood. W e also find that Gaussian approximation D APS gives nearly identical estimates as exact D APS with 7x less compute. 4 . 3 . 2 M O D E L V A L I DA T I O N W e also diagnose the v alidity of the GRMHD model for static imaging of the M87* observations by computing the e vidence log p ( y ) . W e simulated measurements from 100 GRMHD test images using the same forward model as the EHT observations of M87*, and then computed the evidence for these measurements. Under a central limit theorem argument, we can approximate this distribution as Gaussian. W e then compared the evidence of the true M87* observation to this Gaussian as well as the e vidence of out-of-distribution measurements under the same forward model to assess if the GRMHD prior is valid for M87*. Results are shown in Figure 5. The fitted Gaussian has µ = 250 . 71 and σ = 23 . 86 . M87* has an evidence of 231.46, giving it a z-score of -0.81 and p-v alue of 0.209 with respect to the previous Gaussian fit. Therefore, M87* likely lies within the support of the GRMHD image prior , of fering credence to our current physical model of black holes through the images it produces, while still leaving open the possibility of an impro ved model. On the other hand, the morphed GRMHD image has evidence 210.37, gi ving it a z-score of -1.69 and p-value of 0.046, suggesting that it is not in the true GRMHD distribution. The apple, RIAF , and pigeon images hav e e ven lower evidences of 176.52, 150.41, and 74.68 respectiv ely and are all considered out-of-distribution. 5 C O N C L U S I O N W e introduce DiME , a method that estimates the Bayesian model evidence when solving in verse problems using diffusion model priors. DiME computes the KL div ergence between the posterior and prior by integrating along posterior time-marginals, a task made easy by using the intermediate samples of recent dif fusion posterior sampling methods. Empirically , DiME outperforms all baseline methods and we demonstrate how DiME can be used on a real-world black hole imaging problem. Altogether , DiME makes it possible to harness dif fusion priors not only for reconstruction b ut also for principled model selection and validation, laying the foundation for more reliable inference in scientific imaging. 10 Published as a conference paper at ICLR 2026 E T H I C S S TA T E M E N T Our method is a statistical estimator and can occasionally select the incorrect model, potentially leading to incorrect conclusions. Furthermore, while it could in principle be applied to sensitiv e characteristics (e.g., facial recognition), we do not support its use in this context. R E P RO D U C I B I L I T Y S TA T E M E N T All code and trained models will be made av ailable. All mathematical deri vations are detailed in the appendix. The MNIST dataset is av ailable through torchvision (Marcel & Rodriguez, 2010), the CelebA dataset is av ailable at https://mmlab .ie.cuhk.edu.hk/projects/CelebA.html, and the SpaceNet dataset is available at https://www .kaggle.com/datasets/razaimam45/spacenet-an- optimally-distributed-astronomy-data/. The RIAF and GRMHD datasets are not currently available for public use. A C K N OW L E D G M E N T S This work was supported by NSF A ward 2048237, an Amazon AI4Science Discovery A ward, Ope- nAI, and a Sloan Research Fellowship. FW is supported by a K ortschak Fellowship. The authors would like to thank Angela Gao for helpful discussions. R E F E R E N C E S Mohammed T alha Alam, Raza Imam, Mohsen Guizani, and Fakhri Karray . Flare up your data: Diffusion-based augmentation method in astronomical imaging, 2024. Lindy Blackb urn, Dominic W Pesce, Michael D Johnson, Maciek W ielgus, Andrew A Chael, Pierre Christian, and Sheperd S Doeleman. Closure statistics in interferometric data. The Astr ophysical Journal , 894(1):31, 2020. Benjamin Boys, Mark Girolami, Jakiw Pidstrigach, Sebastian Reich, Alan Mosca, and O Deniz Akyildiz. T weedie moment projected diffusions for inv erse problems. arXiv preprint arXiv:2310.06721 , 2023. A very E Broderick, V incent L Fish, Sheperd S Doeleman, and Abraham Loeb . Evidence for low black hole spin and physically motiv ated accretion models from millimeter-vlbi observations of sagittarius a. The Astrophysical J ournal , 735(2):110, 2011. A very E Broderick, Roman Gold, Mansour Karami, Jor ge A Preciado-Lopez, Paul Tiede, Hung- Y i Pu, et al. Themis: A parameter estimation framework for the ev ent horizon telescope. The Astr ophysical Journal , 897(2):139, 2020. Xiaohao Cai, Jason D McEwen, and Marcelo Pereyra. Proximal nested sampling for high- dimensional bayesian model selection. Statistics and Computing , 32(5):87, 2022. Gabriel Cardoso, Y azid Janati El Idrissi, Sylvain Le Corff, and Eric Moulines. Monte carlo guided diffusion for bayesian linear in verse problems. arXiv pr eprint arXiv:2308.07983 , 2023. Junhua Chen, Lorenz Richter , Julius Berner , Denis Blessing, Gerhard Neumann, and Anima Anand- kumar . Sequential controlled langevin dif fusions. arXiv preprint , 2024. Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky , and Jong Chul Y e. Diffusion posterior sampling for general noisy in verse problems. arXiv pr eprint arXiv:2209.14687 , 2022. Pierre Del Moral, Arnaud Doucet, and Ajay Jasra. Sequential monte carlo samplers. J ournal of the Royal Statistical Society Series B: Statistical Methodology , 68(3):411–436, 2006. Li Deng. The mnist database of handwritten digit images for machine learning research [best of the web]. IEEE signal processing ma gazine , 29(6):141–142, 2012. Arnaud Doucet, W ill Grathwohl, Alexander G Matthews, and Heiko Strathmann. Score-based dif fu- sion meets annealed importance sampling. Advances in Neural Information Pr ocessing Systems , 35:21482–21494, 2022. 11 Published as a conference paper at ICLR 2026 Bradley Efron. T weedie’ s formula and selection bias. Journal of the American Statistical Associa- tion , 106(496):1602–1614, 2011. EHTC. First m87 ev ent horizon telescope results. i. the shadow of the supermassiv e black hole. arXiv pr eprint arXiv:1906.11238 , 2019a. EHTC. First m87 e vent horizon telescope results. iv . imaging the central supermassiv e black hole. arXiv pr eprint arXiv:1906.11241 , 2019b. EHTC. First m87 event horizon telescope results. v . physical origin of the asymmetric ring. arXiv pr eprint arXiv:1906.11242 , 2019c. EHTC. First m87 ev ent horizon telescope results. vi. the shadow and mass of the central black hole. The Astr ophysical Journal Letters , 875(1):L6, 2019d. Berthy T Feng, Katherine L Bouman, and William T Freeman. Ev ent-horizon-scale imaging of m87* under dif ferent assumptions via deep generative image priors. The Astr ophysical J ournal , 975(2):201, 2024. CM Fromm, Z Y ounsi, A Baczko, Y Mizuno, O Porth, M Perucho, H Oliv ares, A Nathanail, E An- gelakis, E Ros, et al. Using ev olutionary algorithms to model relativistic jets-application to ngc 1052. Astronomy & Astr ophysics , 629:A4, 2019. W ei Guo, Molei T ao, and Y ongxin Chen. Complexity analysis of normalizing constant estima- tion: from jarzynski equality to annealed importance sampling and beyond. arXiv preprint arXiv:2502.04575 , 2025. Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information pr ocessing systems , 33:6840–6851, 2020. Xunpeng Huang, Hanze Dong, Y ifan Hao, Y i-An Ma, and T ong Zhang. Rev erse diffusion monte carlo. arXiv preprint , 2023. Ajil Jalal, Marius Arvinte, Giannis Daras, Eric Price, Ale xandros G Dimakis, and Jon T amir . Robust compressed sensing mri with deep generative priors. Advances in neural information pr ocessing systems , 34:14938–14954, 2021. Nicolas Lartillot and Herv ´ e Philippe. Computing bayes factors using thermodynamic integration. Systematic biology , 55(2):195–207, 2006. Xiang Li, Soo Min Kwon, Shijun Liang, Ismail R Alkhouri, Saiprasad Ravishankar , and Qing Qu. Decoupled data consistency with diffusion purification for image restoration. arXiv pr eprint arXiv:2403.06054 , 2024. Julia Linhart, Gabriel V ictorino Cardoso, Alexandre Gramfort, Sylvain Le Corff, and Pedro LC Rodrigues. Diffusion posterior sampling for simulation-based inference in tall data settings. arXiv pr eprint arXiv:2404.07593 , 2024. Ziwei Liu, Ping Luo, Xiaogang W ang, and Xiaoou T ang. Deep learning face attributes in the wild. In Pr oceedings of International Conference on Computer V ision (ICCV) , December 2015. S ´ ebastien Marcel and Y ann Rodriguez. T orchvision the machine-vision package of torch. In Pr o- ceedings of the 18th A CM international confer ence on Multimedia , pp. 1485–1488, 2010. Morteza Mardani, Jiaming Song, Jan Kautz, and Arash V ahdat. A v ariational perspecti ve on solving in verse problems with dif fusion models. arXiv preprint , 2023. Jason D McEwen, Christopher GR W allis, Matthew A Price, and Alessio Spurio Mancini. Machine learning assisted bayesian model comparison: learnt harmonic mean estimator . arXiv pr eprint arXiv:2111.12720 , 2021. Y osuke Mizuno. Grmhd simulations and modeling for jet formation and acceleration region in agns. Universe , 8(2):85, 2022. 12 Published as a conference paper at ICLR 2026 Badr Moufad, Y azid Janati, Lisa Bedin, Alain Durmus, Randal Douc, Eric Moulines, and Jimmy Olsson. V ariational diffusion posterior sampling with midpoint guidance. arXiv pr eprint arXiv:2410.09945 , 2024. Radford M Neal. Annealed importance sampling. Statistics and computing , 11(2):125–139, 2001. Michael A Ne wton and Adrian E Raftery . Approximate bayesian inference with the weighted lik eli- hood bootstrap. Journal of the Royal Statistical Society Series B: Statistical Methodology , 56(1): 3–26, 1994. Xinyu Peng, Ziyang Zheng, W enrui Dai, Nuoqian Xiao, Chenglin Li, Junni Zou, and Hongkai Xiong. Improving diffusion models for inv erse problems using optimal posterior covariance. arXiv pr eprint arXiv:2402.02149 , 2024. Alicja Polanska, Matthew A Price, Alessio Spurio Mancini, and Jason D McEwen. Learned har- monic mean estimation of the marginal likelihood with normalizing flo ws. In Physical sciences forum , volume 9, pp. 10. MDPI, 2023. John Skilling. Nested sampling for general bayesian computation. 2006. Marta Skreta, Lazar Atanackovic, A vishek Joe y Bose, Alexander T ong, and Kirill Neklyudov . The superposition of diffusion models using the it \ ˆ o density estimator . arXiv pr eprint arXiv:2412.17762 , 2024. Jiaming Song, Arash V ahdat, Morteza Mardani, and Jan Kautz. Pseudoin verse-guided diffusion models for in verse problems. In International Confer ence on Learning Repr esentations , 2023. Y ang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar , Stefano Ermon, and Ben Poole. Score-based generativ e modeling through stochastic dif ferential equations. arXiv pr eprint arXiv:2011.13456 , 2020. Y ang Song, Conor Durkan, Iain Murray , and Stefano Ermon. Maximum likelihood training of score-based dif fusion models. Advances in neural information pr ocessing systems , 34:1415– 1428, 2021a. Y ang Song, Liyue Shen, Lei Xing, and Stefano Ermon. Solving in verse problems in medical imaging with score-based generativ e models. arXiv preprint , 2021b. A Spurio Mancini, MM Docherty , MA Price, and JD McEwen. Bayesian model comparison for simulation-based inference. RAS T echniques and Instruments , 2(1):710–722, 2023. Andrew M Stuart. In verse problems: a bayesian perspectiv e. Acta numerica , 19:451–559, 2010. A Richard Thompson, James M Moran, and George W Swenson. Interfer ometry and synthesis in radio astr onomy . Springer Nature, 2017. Roberto Trotta. Applications of bayesian model selection to cosmological parameters. Monthly Notices of the Royal Astr onomical Society , 378(1):72–82, 2007. Maxime V ono, Nicolas Dobigeon, and Pierre Chainais. Split-and-augmented gibbs sam- pler—application to large-scale inference problems. IEEE T ransactions on Signal Processing , 67(6):1648–1661, 2019. Luhuan W u, Brian T rippe, Christian Naesseth, David Blei, and John P Cunningham. Practical and asymptotically exact conditional sampling in dif fusion models. Advances in Neural Information Pr ocessing Systems , 36:31372–31403, 2023. Zihui W u, Y u Sun, Y ifan Chen, Bingliang Zhang, Y isong Y ue, and Katherine Bouman. Princi- pled probabilistic imaging using diffusion models as plug-and-play priors. Advances in Neural Information Pr ocessing Systems , 37:118389–118427, 2024. Bingliang Zhang, W enda Chu, Julius Berner, Chenlin Meng, Anima Anandkumar, and Y ang Song. Improving diffusion in verse problem solving with decoupled noise annealing. In Pr oceedings of the Computer V ision and P attern Recognition Conference , pp. 20895–20905, 2025. 13 Published as a conference paper at ICLR 2026 Hongkai Zheng, W enda Chu, Bingliang Zhang, Zihui W u, Austin W ang, Berthy T Feng, Caifeng Zou, Y u Sun, Nikola K ovachki, Zachary E Ross, et al. In versebench: Benchmarking plug-and- play dif fusion priors for in verse problems in physical sciences. arXiv pr eprint arXiv:2503.11043 , 2025. Y uanzhi Zhu, Kai Zhang, Jingyun Liang, Jiezhang Cao, Bihan W en, Radu Timofte, and Luc V an Gool. Denoising dif fusion models for plug-and-play image restoration. In Pr oceedings of the IEEE/CVF confer ence on computer vision and pattern r ecognition , pp. 1219–1229, 2023. 14 Published as a conference paper at ICLR 2026 A P R O O F S Although the main text uses the diffusion SDE formulation, we introduce the Probability Flow ODE (PF-ODE) for the proofs and for Appendix B. This ODE has identical marginals as the SDE under ideal conditions. Giv en diffusion process x t = a t x 0 + σ t z t , z t ∼ N (0 , I ) , the PF-ODE is: d x t = h a ′ t a t x t − σ t σ ′ t − a ′ t a t σ 2 t ∇ x t log p ( x t ) i dt = v p ( x t ) dt (13) where v p ( x t ) is the unconditional flow . The conditional flo w v p ( x t | y ) can be deri ved via Bayes: v p ( x t | y ) = a ′ t a t x t − σ t σ ′ t − a ′ t a t σ 2 t ∇ x t log p ( x t | y ) (14) = v p ( x t ) − σ ′ t σ t − σ 2 t a ′ t a t ∇ x t log p ( y | x t ) . (15) For the following proof, we impose the regularity and smoothness assumptions listed in Appendix A of Song et al. (2021a) for both the prior marginals p ( x t ) and the posterior marginals π ( x t | y ) . Lemma 3. Let p ( x t ) be the unconditional diffusion marginal and π ( x t | y ) ∝ p ( x t ) π ( y | x t ) be a posterior time-marginal obtained at diffusion timestep t . Denote v p ( x t ) and v π ( x t | y ) as their corr esponding velocity vector fields. W e have the following identity: d d t D KL ( π ( x t | y ) ∥ p ( x t )) = E x t ∼ π ( x t | y ) h ( v π ( x t | y ) − v p ( x t )) T ∇ x t log π ( y | x t ) i . (16) Pr oof. Simplifying the deri vati ve giv es: d d t D KL ( π ( x t | y ) ∥ p ( x t )) = d d t Z π ( x t | y ) [log π ( x t | y ) − log p ( x t )] d x t = Z d d t π ( x t | y ) [log π ( x t | y ) − log p ( x t )] d x t + Z π ( x t | y ) d d t [log π ( x t | y ) − log p ( x t )] d x t . (Product rule) Now we expand the first term. Let v p ( x t ) , v π ( x t | y ) be the flo ws at p ( x t ) , π ( x t | y ) respectively: Z d d t π ( x t | y ) [log π ( x t | y ) − log p ( x t )] d x t = − Z ∇ · ( π ( x t | y ) v π ( x t | y )) log π ( x t | y ) − log p ( x t ) d x t (Continuity equation) = Z π ( x t | y ) v π ( x t | y ) T ∇ x t log π ( x t | y ) − log p ( x t ) d x t (Integration by parts) = Z π ( x t | y ) v π ( x t | y ) T ∇ x t log π ( y | x t ) d x t . (Bayes) 15 Published as a conference paper at ICLR 2026 For the second term: Z π ( x t | y ) d d t [log π ( x t | y ) − log p ( x t )] d x t = E x t ∼ π ( x t | y ) d d t log π ( x t | y ) − Z π ( x t | y ) d d t log p ( x t ) d x t = − Z π ( x t | y ) d d t log p ( x t ) d x t = Z π ( x t | y ) ∇ · v p ( x t ) + v p ( x t ) T ∇ x t log p ( x t ) d x t (Log-continuity equation) = Z π ( x t | y ) ∇ · v p ( x t ) + v p ( x t ) T ∇ x t log π ( x t | y ) d x t − Z π ( x t | y ) v p ( x t ) T ∇ x t log π ( y | x t ) d x t (Bayes) = − Z π ( x t | y ) v p ( x t ) T ∇ x t log π ( y | x t ) d x t . (Stein’ s identity) Adding the two terms back together gi ves us: d d t D KL ( π ( x t | y ) ∥ p ( x t )) = Z π ( x t | y ) ( v π ( x t | y ) − v p ( x t )) T ∇ x t log π ( y | x t ) d x t = E x t ∼ π ( x t | y ) h ( v π ( x t | y ) − v p ( x t )) T ∇ x t log π ( y | x t ) i . Proposition 1 ( DiME : Model e vidence estimation along the standard marginals) . Given diffusion pr ocess x t = a t x 0 + σ t z t , z t ∼ N (0 , I ) , posterior mar ginals p ( x t | y ) ∝ p ( x t ) R p ( y | x 0 ) p ( x 0 | x t ) d x 0 , and timesteps 0 = t 0 < · · · < t N = T , the model evidence can be estimated via: log p ( y ) = E x 0 ∼ p ( x 0 | y ) log p ( y | x 0 ) − D KL ( p ( x 0 | y ) || p ( x 0 )) . (8) The log-likelihood term can be estimated with posterior samples 3 , and the KL diver gence with: D KL ( p ( x 0 | y ) || p ( x 0 )) ≈ N X i =1 c t i ∆ t i E x t i ∼ p ( x t i | y ) ∥∇ x t i log p ( y | x t i ) ∥ 2 (9) wher e c t i = σ ′ t i σ t i − σ 2 t i a ′ t i a t i is dependent on the diffusion sc hedule and ∆ t i = t i − t i − 1 . Pr oof. Expanding out the KL di vergence gi ves us an expression for the model e vidence: D KL ( p ( x 0 | y ) ∥ p ( x 0 )) = E x 0 ∼ p ( x 0 | y ) log p ( x 0 | y ) − log p ( x 0 ) = E x 0 ∼ p ( x 0 | y ) log p ( y | x 0 ) − log p ( y ) = E x 0 ∼ p ( x 0 | y ) log p ( y | x 0 ) − log p ( y ) = ⇒ log p ( y ) = E x 0 ∼ p ( x 0 | y ) log p ( y | x 0 ) − D KL ( p ( x 0 | y ) || p ( x 0 )) . 3 For likelihoods with Gaussian noise, if the posterior and prior hav e enough ov erlap such that posterior samples hav e a data fit of χ 2 ≈ 1 , this term essentially becomes constant under the same likelihood function. 16 Published as a conference paper at ICLR 2026 At the final diffusion step, the forward process has destroyed all information about the measure- ments, so we hav e p ( x T | y ) = p ( x T ) , or D KL ( p ( x T | y ) ∥ p ( x T )) = 0 . Therefore, we hav e: D KL ( p ( x 0 | y ) || p ( x 0 )) = − Z T 0 d d t D KL ( p ( x t | y ) ∥ p ( x t )) dt ( i ) = − Z T 0 E x t ∼ p ( x t | y ) h v p ( x t | y ) − v p ( x t ) ⊤ ∇ x t log p ( y | x t ) i dt ( ii ) = Z T 0 σ ′ t σ t − σ 2 t a ′ t a t E x t ∼ p ( x t | y ) ∇ x t log p ( y | x t ) 2 dt. ≈ N X i =1 ∆ t i σ ′ t i σ t i − σ 2 t i a ′ t i a t i E x t i ∼ p ( x t i | y ) ∥∇ x t i log p ( y | x t i ) ∥ 2 . where (i) uses Lemma 3 b ut with π ( x t | y ) = p ( x t | y ) and (ii) uses the PF-ODE of the conditional flow (Eq. 15). 17 Published as a conference paper at ICLR 2026 A . 1 P R O O F S A N D D E R I V AT I O N S F O R T H E DA P S - B A S E D I M P L E M E N TA T I O N Lemma 1. Suppose we have dif fusion pr ocess x t = a t x 0 + σ t z t , z t ∼ N (0 , I ) . Let x t ∼ p ( x t ) and suppose p ( x 0 ) ≈ N ( µ 0 , Σ 0 ) . Then we can expr ess the posterior covariance Σ x 0 | x t as Σ x 0 | x t = Σ − 1 0 + a 2 t σ 2 t I − 1 . (10) Pr oof. Our dif fusion corruption process giv es us: Co v ( x t ) = a 2 t Σ 0 + σ 2 t I Co v ( x 0 , x t ) = Co v ( x 0 , a t x 0 + σ t z t ) = a t Co v ( x 0 ) = a t Σ 0 . Plugging these into the Gaussian posterior cov ariance formula giv es: Co v ( x 0 | x t ) = Co v ( x 0 ) − Cov( x 0 , x t )Co v ( x t ) − 1 Co v ( x 0 , x t ) = Σ 0 − a t Σ 0 a 2 t Σ 0 + σ 2 t I − 1 a t Σ 0 = Σ 0 − Σ 0 Σ 0 + σ 2 t a 2 t I − 1 Σ 0 = Σ − 1 0 + a 2 t σ 2 t I − 1 . (W oodb ury identity) . Corollary 1. Suppose the training data has λ max ( Σ 0 ) = 1 . Then ∥ Σ x 0 | x t ∥ = σ 2 t σ 2 t + a 2 t . Pr oof. Plugging in the cov ariance from Lemma 1 gi ves: ∥ Σ x 0 | x t ∥ = λ max Σ − 1 0 + a 2 t σ 2 t I − 1 = 1 λ min Σ − 1 0 + a 2 t σ 2 t I = 1 1 + a 2 t σ 2 t = σ 2 t σ 2 t + a 2 t . Lemma 2. Suppose we have diffusion pr ocess x t = a t x 0 + σ t z t , z t ∼ N (0 , I ) and sample ˜ x 0 ∼ p ( x 0 | x t , y ) . Under the assumption that p ( x 0 | x t ) ≈ N ( E [ x 0 | x t ] , Σ x 0 | x t ) , both Θ hig h ( ˜ x 0 ) and Θ low ( ˜ x 0 ) are unbiased estimator s of ∇ x t log p ( y | x t ) with Θ hig h ( ˜ x 0 ) = a t σ 2 t ( ˜ x 0 − E [ x 0 | x t ]) . (11) Θ low ( ˜ x 0 ) = a t σ 2 t Σ x 0 | x t ∇ ˜ x 0 log p ( y | ˜ x 0 ) . (12) Under low diffusion noise ( a t → 1 , σ t → 0) , V ar(Θ low ) → 0 b ut V ar(Θ hig h ) = O ( 1 σ 2 t ) . Under high noise ( a t → 0 , σ t → 1) , V ar(Θ hig h ) → 0 b ut V ar(Θ low ) = O ( σ 4 t σ 4 y V ar(Θ hig h )) . Pr oof. Using T weedie’ s rule, we can show that Θ hig h is unbiased for the likelihood score: ∇ x t log p ( y | x t ) = ∇ x t log p ( x t | y ) − ∇ x t log p ( x t ) = a t σ 2 t E [ x 0 | x t , y ] − x t a t − a t σ 2 t E [ x 0 | x t ] − x t a t = a t σ 2 t ( E [ x 0 | x t , y ] − E [ x 0 | x t ]) . ( ⋆ ) 18 Published as a conference paper at ICLR 2026 Our Gaussian approximation of p ( x 0 | x t ) gives us ∇ x 0 log p ( x 0 | x t ) = − Σ − 1 x 0 | x t ( x 0 − E [ x 0 | x t ]) . Using the fact that the expectation of the score is zero, we ha ve: E [ x 0 | x t , y ] = E [ x 0 + Σ x 0 | x t ∇ x 0 log p ( x 0 | x t , y ) | x t , y ] = E [ x 0 + Σ x 0 | x t ( ∇ x 0 log p ( x 0 | x t ) + ∇ x 0 log p ( y | x 0 )) | x t , y ] = E [ x 0 − ( x 0 − E [ x 0 | x t ]) + Σ x 0 | x t ∇ x 0 log p ( y | x 0 ) | x t , y ] = E [ x 0 | x t ] + Σ x 0 | x t E x 0 ∼ p ( x 0 | x t , y ) [ ∇ x 0 log p ( y | x 0 )] . ( ⋆⋆ ) Substituting ( ⋆⋆ ) into ( ⋆ ) sho ws that Θ low is unbiased. T o compute a v ariance bound for Θ hig h , V ar(Θ hig h ) = a 2 t σ 4 t Co v ( x 0 | x t , y ) ≤ a 2 t σ 4 t Co v ( x 0 | x t ) (Gaussian conditional cov ariance) ≤ a 2 t σ 2 t ( σ 2 t + a 2 t ) . (Corollary 1) The term σ 2 t + a 2 t is of constant order ov er the diffusion process, resulting in a variance of a 2 t /σ 2 t . T o compute a bound for Θ low , we linearize the likelihood f at a fixed ¯ x with A = ∂ f ∂ x ¯ x and get V ar(Θ low ) = a 2 t σ 4 t Σ x 0 | x t Co v ( ∇ x 0 log p ( y | x 0 ) | x t , y ) Σ T x 0 | x t = a 2 t σ 4 t Σ x 0 | x t Co v ( 1 σ 2 y A T ( y − Ax 0 ) | x t , y ) Σ T x 0 | x t = 1 σ 4 y Σ x 0 | x t A T A a 2 t σ 4 t Co v ( x 0 | x t , y ) A T A Σ T x 0 | x t ≤ ∥ A ∥ 4 σ 4 y σ 4 t ( σ 2 t + a 2 t ) 2 V ar(Θ hig h ) . (Corollary 1) ≤ ∥ A ∥ 4 σ 4 y σ 2 t a 2 t ( σ 2 t + a 2 t ) 3 . Unlike Θ hig h , the v ariance of this estimator goes to 0 as σ t → 0 , b ut for the rest of diffusion process the constant factor makes it a higher v ariance estimator than Θ hig h in practice. 19 Published as a conference paper at ICLR 2026 B G E N E R A L I Z I N G D I ME T O A R B I T R A RY P O S T E R I O R M A R G I N A L S While we only present DiME along the standard marginals in the main text, DiME can be extended to any arbitrary dif fusion posterior marginals that anneal to the true posterior as follo ws: Corollary 2 (Generalized DiME ) . Let p ( x t ) be the unconditional diffusion mar ginal and π ( x t | y ) ∝ p ( x t ) π ( y | x t ) be a path of mar ginals that anneals to the true posterior , or π ( x 0 | y ) = p ( x 0 | y ) . Denote v p ( x t ) and v π ( x t | y ) as their corresponding velocity fields. Given r everse diffusion timesteps 0 = t 0 < · · · < t N = T , we have: log p ( y ) = E x 0 ∼ p ( x 0 | y ) log p ( y | x 0 ) − D KL ( p ( x 0 | y ) || p ( x 0 )) wher e D KL ( p ( x 0 | y ) || p ( x 0 )) ≈ − N X i =1 ∆ t i E x t ∼ π ( x t | y ) h v π ( x t | y ) − v p ( x t ) ⊤ ∇ x t log π ( y | x t ) i + D KL ( π ( x T | y ) || p ( x T )) . Pr oof. Follo ws directly from the proof of Prop. 1. While v p can be directly computed using the PF-ODE (Eq. 13), computing v π can be difficult for arbitrary time-mar ginals π . By crafting a sequence of diffusion marginals with kno wn velocity , we can av oid any approximation like the one used for p ( x 0 | x t ) in the D APS implementation. The marginals π ( x t | y ) should also ideally have high ov erlap with the unconditional marginal p ( x t ) to ensure accurate computation of v p ( x t ) when the score is learned. If π ( x T | y ) = p ( x T ) , then we must use other estimation methods to compute D KL ( π ( x T | y ) || p ( x T )) or settle for an unnormalized model e vidence estimate. The following section discusses two estimators that does not require any approximation, b ut are not normalized. B . 1 E S T I M A T I N G T H E M O D E L E V I D E N C E F RO M A LT E R NA T I V E S A M P L I N G M E T H O D S Algorithm 2 One posterior sample-path of DiME-PnPDM Require: Score-based model s θ , measurement y , noise schedule σ t , ( t i ) i ∈{ 1 ,...,N } , 1: Sample ˆ x 0 ∼ p ( x 0 ) . 2: Initialize the integral sum, f = 0 . 3: for i = N , N − 1 . . . , 0 do 4: Sample x t i ∼ q ( x t i | y , ˆ x 0 ) ∝ q ( y | x t i ) p ( x t i | ˆ x 0 ) . 5: Sample ˆ x 0 ∼ p ( x 0 | x t i ) using s θ . 6: Update the integral sum f ← f − ( t i − t i − 1 ) v p ( x t i ) T ∇ x t log q ( y | x t i ) 7: end f or 8: return x (0) , f The PnP-DM marginals follow q ( x t | y ) ∝ q ( y | x t ) p ( x t ) where q ( y | x t ) is a time-independent likelihood term. As a result, the initial distribution q ( x T | y ) = p ( x T ) and the KL div ergence D KL ( q ( x T | y ) ∥ p ( x T )) is non-zero, so we can only compute the unnormalized model e vidence. Howe ver , the unknown constant is dependent on y and the forward model, so this unnormalized quantity can still be used for model selection. W e deriv e the estimator in Proposition 2 and imple- ment it with PnP-DM in Algorithm 2. Proposition 2 ( DiME-PnPDM : model evidence estimation along the PnP-DM marginals) . Given diffusion pr ocess x t = a t x 0 + σ t z t , z t ∼ N (0 , I ) , PnP-DM mar ginals q ( x t | y ) ∝ p ( x t ) q ( y | x t ) , and timesteps 0 = t 0 < · · · < t N = T , the model evidence can be estimated via: log p ( y ) ≈ C ( q , y ) − N X i =1 ∆ t i E x ∼ q ( x t i | y ) v p ( x t i ) T ∇ x t i log q ( y | x t i ) (17) wher e C ( q , y ) = log E x ∼N (0 , I ) [ q ( y | x )] is constant for fixed measurement y and forward model, and v p ( x t ) = a ′ t a t x t − ( σ ′ t σ t − σ 2 t a ′ t a t ) ∇ x log p ( x t ) is the PF-ODE velocity at x t (Eq. 13). 20 Published as a conference paper at ICLR 2026 Pr oof. While we can apply Corollary 2, we can take a shortcut to cancel some extra terms. Under the PnP-DM marginals, log q ( y | t ) is time-dependent while the likelihood q ( y | x t ) is time- independent, so we can directly compute the deriv ative of the e vidence: d dt log q ( y | t ) = E x ∼ q ( x t | y ) d dt log p ( x t ) (Fisher’ s identity) = − E x ∼ q ( x t | y ) ∇ · v p ( x t ) + v p ( x t ) T ∇ x t log p ( x t ) (Log-cont. equation) = − E x ∼ q ( x t | y ) ∇ · v p ( x t ) + v p ( x t ) T ∇ x t log q ( x t | y ) + E x ∼ q ( x t | y ) v p ( x t ) T ∇ x t log q ( y | x t ) (Bayes) = E x ∼ q ( x t | y ) v p ( x t ) T ∇ x t log q ( y | x t ) . (Stein’ s identity) Integrating o ver all t giv es us the estimator: log p ( y ) = log q ( y | t = 0) = log q ( y | t = T ) − Z T 0 d dt log q ( y | t ) dt = log q ( y | t = T ) − N X i =1 ∆ t i E x ∼ q ( x t i | y ) v p ( x t i ) T ∇ x t i log q ( y | x t i ) where log q ( y | t = T ) = log E x ∼N (0 ,σ 2 T ) [ q ( y | x )] is the model evidence under a Gaussian prior , and v p ( x t ) = a ′ t a t x t − ( σ ′ t σ t − σ 2 t a ′ t a t ) ∇ x log p ( x t ) is the PF-ODE from Equation 13. W e can also do a similar deriv ation for the marginals used for the T wisted Diffusion Sampler (W u et al., 2023), which follo w π ( x t | y ) ∝ p ( x t ) p ( y | E [ x 0 | x t ]) ; note that this e vidence gradient can be computed before resampling using SMC weights or after resampling without weights. Proposition 3 ( DiME-TDS : model e vidence estimation along the TDS marginals) . Given diffu- sion process x t = a t x 0 + σ t z t , z t ∼ N (0 , I ) , TDS marginals π ( x t | y ) ∝ p ( x t ) p ( y | µ ( x t )) , and timesteps 0 = t 0 < · · · < t N = T , the model evidence can be estimated via: log p ( y ) ≈ C ( q , y ) − N X i =1 ∆ t i E x t ∼ π ( x t i | y ) v p ( x t i ) T ∇ x t i log p ( y | µ ( x t i )) + d dt log p ( y | µ ( x t i )) (18) wher e C ( q , y ) = log E x ∼N (0 ,σ 2 T ) [ p ( y | µ ( x T ))] is constant for fixed measur ement y and forward model, and v p ( x t ) = a ′ t a t x t − ( σ ′ t σ t − σ 2 t a ′ t a t ) ∇ x log p ( x t ) is the PF-ODE velocity at x t (Eq. 13). Pr oof. d dt log π ( y | t ) = 1 π ( y | t ) d dt Z p ( x t ) p ( y | µ ( x t )) d x t = 1 π ( y | t ) Z d dt p ( x t ) p ( y | µ ( x t )) d x t + 1 π ( y | t ) Z p ( x t ) d dt p ( y | µ ( x t )) d x t = E x t ∼ π ( x t | y ) d dt log p ( x t ) + d dt log p ( y | µ ( x t )) = E x t ∼ π ( x t | y ) v p ( x t ) T ∇ x t log p ( y | µ ( x t )) + d dt log p ( y | µ ( x t )) where the last line is deri ved in a similarly to Proposition 2. Integrating ov er all t gives the estimator: log p ( y ) = log π ( y | t = T ) − Z T 0 d dt log π ( y | t ) dt ≈ log π ( y | t = T ) − N X i =1 ∆ t i E x t ∼ π ( x t i | y ) v p ( x t i ) T ∇ x t i log p ( y | µ ( x t i )) + d dt log p ( y | µ ( x t i )) 21 Published as a conference paper at ICLR 2026 where log π ( y | T ) ≈ log E x ∼N (0 ,σ 2 T ) [ p ( y | µ ( x T ))] . 22 Published as a conference paper at ICLR 2026 C B A S E L I N E M E T H O D S In Section 4.1, we compared to five baseline methods, described here. Define p β as an intermediate distribution of the power-posterior path , used in TI, AIS, and SMC: p β ( x ) ∝ p ( x ) p ( y | x ) β , β ∈ [0 , 1] . Note that this path is equiv alent to the geometric path under a different parametrization. Naive Monte Carlo (Naiv e MC) : W e generate many unconditional prior samples and compute the expectation of the likelihood as follo ws: log p ( y ) = log E x ∼ p ( x 0 ) [ p ( y | x )] . Original D APS covariance heuristic (Original heuristic) : W e perform the same steps as described in Algorithm 1 but using the originally proposed co variance heuristic Σ x 0 | x t = σ 2 t . Thermodynamic integration (TI) (Lartillot & Philippe, 2006): Originally from statistical mechan- ics, TI can also compute expectations by inte grating the evidence o ver the po wer-posterior path: d dβ log p β ( y ) = 1 p β ( y ) d dβ p β ( y ) = 1 p β ( y ) Z p ( x ) d dβ p ( y | x ) β d x = 1 p β ( y ) Z p ( x ) p ( y | x ) β log p ( y | x ) d x = E x ∼ p β [log p ( y | x )] . Using the fact that log p β =0 ( y ) = log 1 = 0 , using K integration steps we hav e the estimator: log p β =1 ( y ) ≈ K X k =1 ∆ β k E x ∼ p β k − 1 [log p ( y | x )] . Samples from each p β were generated using Sequential Monte Carlo (details below). Annealed importance sampling (AIS) (Neal, 2001): W e can compute the ratio of e vidence: p β k ( y ) p β k − 1 ( y ) = R p ( x ) p ( y | x ) β k − 1 p ( y | x ) ∆ β k d x p β k − 1 ( y ) = E x ∼ p β k − 1 [ p ( y | x ) ∆ β k ] = E p x ∼ β k − 1 [exp(∆ β k log p ( y | x ))] . Using the fact that log p β =0 ( y ) = log 1 = 0 , telescoping ov er all β k giv es: p β =1 ( y ) = K Y k =1 E p β k − 1 [exp(∆ β k log p ( y | x ))] = E x 0: k − 1 ∼ p β 0: k − 1 exp K X k =1 ∆ β k log p ( y | x k − 1 ) . Note that x 0: k − 1 ∼ p β 0: k − 1 represents the sample-path of one particle, where each transition kernel from k − 1 to k was performed using Lange vin dynamics. Sequential Monte Carlo (SMC) (Del Moral et al., 2006): An e xtension of AIS that uses the resam- pling step from Sequential Monte Carlo methods to replace particles with degenerate weights (i.e. particles stuck in the wrong mode) while sampling the next intermediate distribution, potentially reducing both bias and v ariance. These resampling steps are performed either using a fix ed schedule or adaptiv ely when the effecti ve sample size falls belo w a threshold. 23 Published as a conference paper at ICLR 2026 D I M P L E M E N TA T I O N D E TA I L S D . 1 D I ME As DiME is implemented alongside DAPS, we ha ve a similar set of hyperparameters. Number of diffusion steps f or sampling p ( x 0 | x t ) : While the original D APS method uses many diffusion steps to estimate the denoised image at each annealing iteration, we use 1 diffusion step to ensure an exact estimate of E [ x 0 | x t ] by T weedie’ s formula. Langevin dynamics : The learning rate of Langevin dynamics was tuned so that posterior samples ˜ x 0 ∼ p ( x 0 | x t , y ) have a mean reduced χ 2 data likelihood fit that con verges as low as possible (ideally around 1, which is indicativ e of a good posterior sample for likelihoods with Gaussian noise). W e also use a linear learning rate decay as is done in Zhang et al. (2025). The table belo w lists the learning rates and maximum step counts used for each experiment. In practice, sample con ver gence usually happens much sooner than the maximum step count. T ask lr Max steps Mixture of Gaussians (in-distribution) 5 × 10 − 4 2 , 000 Mixture of Gaussians (out-of-distribution) 2 × 10 − 5 10 , 000 Mixture of Gaussians (saddle point) 2 × 10 − 5 10 , 000 Fourier phase retrie val 1 × 10 − 3 1 , 000 Gaussian phase retriev al 5 × 10 − 4 1 , 000 M87* black hole imaging 1 × 10 − 5 1 , 000 Selection of σ min : This parameter can be vie wed as the minimum noise le vel that the learned score can still be trusted. For the analytic Mixture of Gaussians experiment, we use a minimum annealing noise lev el σ min = 0 . 05 , and for the diffusion model e xperiments, we use σ min = 0 . 1 as is done in Zhang et al. (2025). The remaining integral from t = 0 to t = t min in Eq. 9 is approximated by a trapezoid, using the fact that the integrand equals 0 at t = 0 . Computing the precision matrix Σ − 1 0 : for some datasets, the cov ariance of specific pixel locations is nearly 0 (such as the corner regions of MNIST), so we added a jitter of 1e-2 for stability . D . 2 B A S E L I N E S W e use TI, AIS, and SMC as baseline methods for the mixture of Gaussians experiment (Section 4.1) and SMC for the MNIST experiment (Section 4.2; Appendix E). W e used Langevin dynamics with 2000 steps and learning rate 0.0002 for our transitions between distrib utions. For SMC, we resample when the effecti ve sample size (ESS) is less than 0.6. W e test with fixed linear, exponential, sigmoidal β as well as adaptiv e β schedules that decrease the Conditional ESS at a constant rate of [0.5, 0.6, 0.7]. For the mixture of Gaussians study , an exponential schedule with λ = 6 was found to be optimal. For the MNIST experiment, the fixed schedules use 50 annealing steps, while the adaptive schedule had a minimum β step size of 0 . 002 which in practice results in 150 steps at most. 24 Published as a conference paper at ICLR 2026 E B A S E L I N E R E S U LT S O N M N I S T M O D E L S E L E C T I O N Figure 6: Model evidence confusion matrix using sequential Monte Carlo (SMC) for Gaussian phase retriev al ( left ) and Fourier phase retrie val ( right ) for each (ground truth measurement, model) pair of MNIST digits. When SMC uses the learned diffusion score ∇ x log p ( x t ) at t = 0 . 1 as the prior score, it often fails to select the correct model. Results of the MNIST experiment (Section 4.2) using SMC and the learned ∇ x log p ( x t ) with σ = 0 . 1 as a prior score are shown in Figure 6. SMC is often unable to determine the correct MNIST model. Each SMC annealing step also takes about 10 × longer than an equi valent annealing step for DiME , due to having to query the diffusion model many times for the prior score. Interestingly , narrower priors (i.e. MNIST digit 1) leads to higher model evidence estimates here; since the training data is more clumped together , the learned score becomes more accurate at lo w noise lev els. For completeness, the model evidence estimates of a few runs o ver all temperature annealing sched- ules as well as for a second noise le vel, σ = 0 . 05 , are reported in T ables 2 and 3. Mean and standard deviation o ver 5 runs is shown here. As can be seen, lowering the noise lev el only further increases ov erfitting to training data, causing the estimated evidence to drop. σ min = 0 . 1 σ min = 0 . 05 SMC schedule GT 8 Model 6 GT 8 Model 7 GT 8 Model 8 GT 8 Model 6 GT 8 Model 7 GT 8 Model 8 Linear − 182 ± 9 − 212 ± 9 − 210 ± 11 − 279 ± 26 − 352 ± 3 − 426 ± 40 Exponential − 183 ± 7 − 224 ± 5 − 239 ± 6 − 292 ± 20 − 383 ± 9 − 468 ± 12 Sigmoidal − 175 ± 5 − 219 ± 13 − 191 ± 2 − 273 ± 15 − 374 ± 9 − 480 ± 17 Adaptive 0.5 − 195 ± 31 − 202 ± 23 − 261 ± 1 − 296 ± 52 − 346 ± 16 − 489 ± 33 Adaptive 0.6 − 184 ± 6 − 189 ± 7 − 259 ± 4 − 279 ± 45 − 373 ± 17 − 485 ± 26 Adaptive 0.7 − 192 ± 14 − 192 ± 2 − 255 ± 11 − 296 ± 26 − 384 ± 18 − 522 ± 30 T able 2: SMC model e vidence estimates on Gaussian phase retriev al. σ min = 0 . 1 σ min = 0 . 05 SMC schedule GT 8 Model 6 GT 8 Model 7 GT 8 Model 8 GT 8 Model 6 GT 8 Model 7 GT 8 Model 8 Linear − 416 ± 11 − 431 ± 4 − 409 ± 1 − 485 ± 25 − 577 ± 2 − 563 ± 2 Exponential − 422 ± 20 − 427 ± 2 − 467 ± 11 − 527 ± 10 − 582 ± 12 − 585 ± 9 Sigmoidal − 415 ± 9 − 451 ± 3 − 411 ± 7 − 520 ± 13 − 580 ± 7 − 575 ± 5 Adaptive 0.5 − 409 ± 4 − 409 ± 6 − 460 ± 8 − 524 ± 33 − 563 ± 18 − 567 ± 10 Adaptive 0.6 − 431 ± 20 − 437 ± 11 − 458 ± 8 − 510 ± 9 − 566 ± 14 − 562 ± 13 Adaptive 0.7 − 442 ± 9 − 437 ± 8 − 453 ± 1 − 516 ± 6 − 584 ± 3 − 570 ± 6 T able 3: SMC model e vidence estimates on Fourier phase retrie val. 25 Published as a conference paper at ICLR 2026 F S Y N T H E T I C M O D E L S E L E C T I O N In this section, we perform model selection on the same set of fiv e priors as in Section 4.3.1, b ut on simulated closure quantities measurements of test images from each prior as verification. The correct model is chosen for all measurements. The posterior samples with the lowest, mean, and highest path evidences are also sho wn in each case. Gaussia n appr o xima tion GRMHD M ean imag e P a th ev id enc es (min / me an / max ) RIAF Spac eN et M N I S T F ac es GRMHD P ri or Figure 7: Ground truth: GRMHD. Gaussia n appr o xima tion SP A CE RIAF M N I S T F ac es GRMHD Spac eN et P ri or M ean imag e P a th ev id enc es (min / me an / max ) Figure 8: Ground truth: SpaceNet. 26 Published as a conference paper at ICLR 2026 Gaussian appr o xima tio n CELEB A M ean imag e P a th ev id enc es (min / me an / max ) RIAF M N I S T Spac eN et GRMHD F ac es P rior Figure 9: Ground truth: CelebA. Gaussia n appr o xima tion MNIS T M ean imag e P a th ev id enc es (min / me an / max ) RIAF GRMHD Spac eN et F ac es M N I S T P ri or Figure 10: Ground truth: MNIST . Gau ssia n appr o xim a tion RIAF M ean imag e P a th evid enc es (min / mean / max ) RIAF Spac eN et GRMHD F ac es RIAF P ri or Figure 11: Ground truth: RIAF . 27 Published as a conference paper at ICLR 2026 G L A R G E L A N G UA G E M O D E L U S A G E W e used ChatGPT for coding assistance, polishing text and LaT eX, and checking mathematical deriv ations. 28
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment