확산 사전 기반 모델 선택을 위한 샘플 효율적 증거 추정
본 논문은 확산 모델을 사전으로 사용하는 베이지안 역문제에서 모델 증거를 효율적으로 추정하는 새로운 방법인 DiME를 제안한다. 시간‑마진을 이용해 역확산 샘플링 과정에서 얻어지는 중간 샘플을 활용함으로써 수십 개의 후방 샘플만으로도 정확한 증거 값을 계산한다. 실험을 통해 분석 가능한 경우와 실제 블랙홀 영상 복원 문제에서 기존 방법을 능가함을 보였다.
저자: Frederic Wang, Katherine L. Bouman
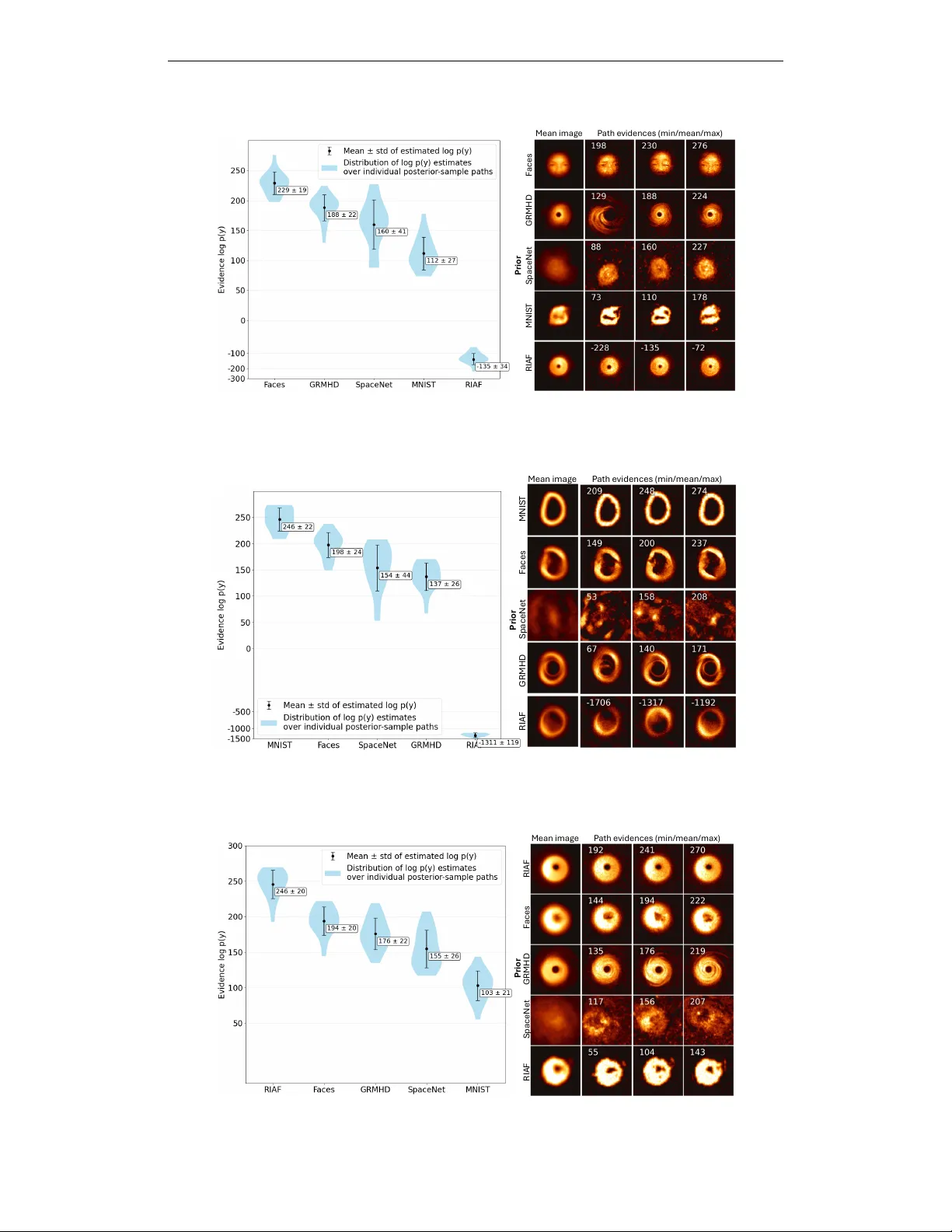
베이지안 이미지 역문제에서 사전 선택은 재구성 편향을 최소화하는 핵심 요소이다. 전통적인 방법은 사전의 로그 증거 p(y|M)를 계산해 가장 높은 값을 갖는 모델을 선택하지만, 확산 모델과 같이 복잡한 데이터‑구동 사전에서는 증거 계산이 직접적으로 불가능하다. 기존 증거 추정기들은 사전의 비정규화 밀도나 정확한 스코어 ∇_x log p(x)를 필요로 하는데, 이는 고차원 이미지에 대해 수천 번의 평가가 요구돼 실용적이지 않다.
본 논문은 이러한 한계를 극복하기 위해 DiME(Diffusion Model Evidence)라는 새로운 추정기를 제안한다. 확산 과정은 시간 t에 따라 x_t = a_t x_0 + σ_t z_t 로 정의되며, 역확산 샘플링은 p(x_t|y) 라는 일련의 시간‑마진을 따라 진행된다. DiME는 이 마진들을 이용해 로그 증거를 두 부분으로 분해한다. 첫 번째는 후방 분포 p(x_0|y) 에서 직접 샘플링한 하나의 이미지에 대한 로그 우도 log p(y|x_0) 로 근사한다. 두 번째는 사전과 후방 사이의 KL 발산을 시간에 걸친 스코어 제곱의 적분으로 표현한다. 구체적으로
log p(y) ≈ E_{x_0∼p(x_0|y)}
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기