Covariance estimation for derivatives of functional data using an additive penalty in P-splines
P-splines provide a flexible and computationally efficient smoothing framework and are commonly used for derivative estimation in functional data. Including an additive penalty term in P-splines has been shown to improve estimates of derivatives. We …
Authors: Yueyun Zhu, Steven Golovkine, Norma Bargary
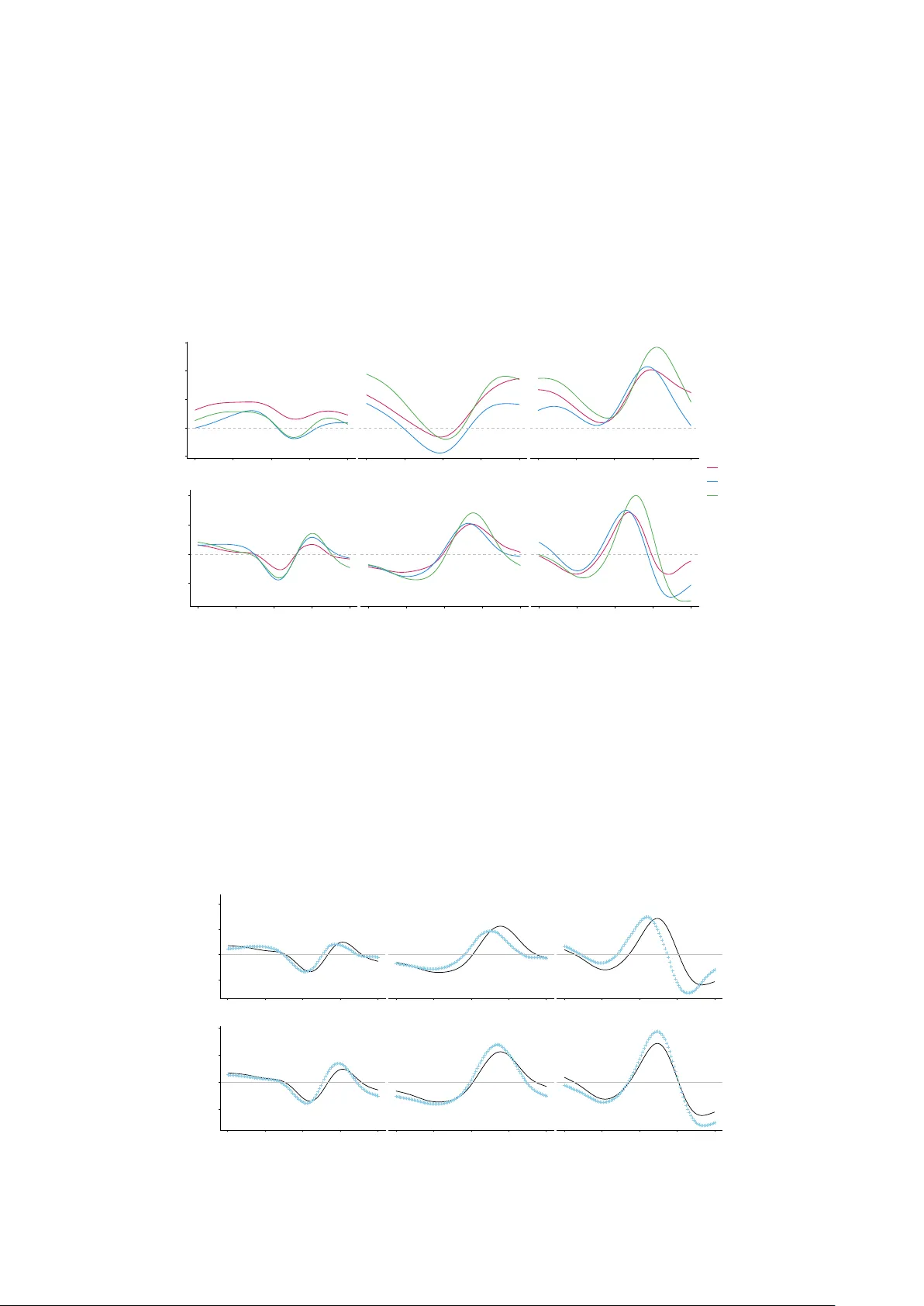
Co v ariance estimation for deriv ativ es of functional data using an additiv e p enalt y in P-splines Y ueyun Zh u ∗ Stev en Golovkine † Norma Bargary ‡ Andrew J. Simpkin § F ebruary 24, 2026 Abstract P-splines provide a flexible and computationally efficien t smoothing framew ork and are commonly used for deriv ativ e estimation in functional data. Including an additive p enalt y term in P-splines has b een sho wn to improv e estimates of deriv ativ es. W e prop ose a method whic h incorporates the fast cov ariance estimation (F A CE) algorithm with an additive p enalty in P-splines. The prop osed metho d is used to estimate deriv atives of co v ariance for functional data, whic h pla y an imp ortan t role in deriv ativ e-based functional principal component analysis (FPCA). F ollowing this, we provide an algorithm for estimating the eigenfunctions and their corresp onding scores in deriv ative-based FPCA. F or comparison, we ev aluate our algorithm against an existing function FPCAder() in simulation. In addition, w e extend the algorithm to multiv ariate cases, referred to as deriv ative multiv ariate functional principal comp onen t analysis (DMFPCA). DMFPCA is applied to join t angles in human mov emen t data, where the deriv ative-based scores demonstrate strong p erformance in distinguishing lo comotion tasks. Keywor ds— P-splines; Deriv ative estimation; F unctional principal component analysis; F unc- tional data analysis 1 In tro duction With the dev elopment of w earable monitoring devices, sensors, and neuroimaging tec hnologies, increasingly large and complex datasets are b eing recorded. F unctional data analysis (FD A) has b ecome important in this con text, with early foundational w ork developed b y Rao ( 1958 ); Ramsay ( 1982 ) and Ramsay and Dalzell ( 1991 ). F unctional principal component analysis (FPCA) is a pow erful to ol in FDA. V arious FPCA metho ds hav e b een prop osed and applied to analyze sensor and neuroimaging data for feature extraction, dimension reduction, regression and classification. F or instance, Di et al. ( 2009 ) intro- duced m ultilevel FPCA which was applied to the electro encephalographic (EEG) signals from the Sleep Heart Health Study to extract core intra- and in ter-sub ject geometric comp onen ts. Happ and Greven ( 2018 ) introduced multiv ariate FPCA which was applied to images from Alzheimer’s Disease Neuroimaging Initiative study to capture imp ortant sources of v ariation in the neuroimag- ing data. More applications of FPCA to biomechanics and human mov ement data can b e found in Coffey et al. ( 2011 ); Gunning et al. ( 2024 , 2025 ). Co v ariance estimation plays an important role in FPCA ( Ramsay and Silverman , 2002 , 2005 ; Y ao et al. , 2005 ; W ang et al. , 2016 ; Gertheiss et al. , 2024 ). The orthonormal eigenfunctions ob- tained by decomp osing the cov ariance of functional tra jectories constitute the functional principal comp onen ts (FPCs), whic h capture the dominan t mo des of v ariation of the underlying function. Note that FPCA is often enhanced b y the use of smo othing ( Silv erman , 1996 ). Co v ariance smooth- ing is essen tial in FPCA b ecause it reduces the measuremen t error and enables accurate estimation of the true FPCs and their eigenv alues. There are three main approaches to estimating the smooth co v ariance, namely “smo oth then estimate”,“estimate then smo oth” and “low-rank smo othing”. The “smo oth then estimate” first pre-smo oths each tra jectory indep enden tly and then estimates the cov ariance from the smo othed data, which can lead to substan tial bias as the pre-smo othing pro cedure fails to capture the o verall dep endence structure. The “low-rank smoothing” estimates ∗ School of Mathematical and Statistical Sciences, Univ ersity of Galwa y , Ireland yueyun.zhu@univ ersity ofgalwa y .ie † Department of Mathematics and Statistics, Univ ersit´ e La v al, Canada steven.golo vkine@mat.ula v al.ca ‡ MACSI, Department of Mathematics and Statistics, Universit y of Limerick, Ireland norma.bargary@ul.ie § School of Mathematical and Statistical Sciences, Universit y of Galw ay , Ireland an- drew.simpkin@universit y ofgalwa y .ie 1 the co v ariance by representing it as a low-dimensional outer product of smo oth basis-expanded laten t functions, see Mbak a et al. ( 2025 ). The “estimate then smooth” first estimates the raw sample cov ariance and then smooths the resulting sample co v ariance using lo cal linear smo others ( F an et al. , 1995 ) or P-splines ( Eilers and Marx , 2021 ). The “estimate then smo oth” is applied in most of the literature, see Staniswalis and Lee ( 1998 ); Y ao et al. ( 2003 , 2005 ); Y ao and Lee ( 2006 ) for example. Recently , a fast P-spline metho d for biv ariate smo othing is introduced by Xiao et al. ( 2013 ), where they proposed a “sandwich smo other” that improv es computational efficiency to estimate the smo oth cov ariance function. The sandwic h smoother w as shown to b e m uch faster than lo cal linear smo others. F ollo wing this, Xiao et al. ( 2016 ) introduced a fast co v ariance estima- tion (F A CE) algorithm which has significant computational adv antages ov er biv ariate P-splines. Li et al. ( 2020 ) extended the F A CE algorithm to multiv ariate sparse functional data, where they estimated the auto-cov ariance functions for within-function correlations and cross-cov ariance func- tions for b et ween-function correlations. Cui et al. ( 2023 ) prop osed a fast m ultilevel FPCA based on the F A CE algorithm, whic h demonstrates higher computational efficiency than Di et al. ( 2009 ). In many applications, the deriv atives of functional tra jectories are not directly observ ed but they are useful in c apturing the underlying dynamics, suc h as velocity and acceleration. Deriv ative- based FPCA is therefore imp ortan t, whic h captures the mo des of v ariation of the unobserved deriv ativ es (i.e., deriv ative-based FPCs) and pro vides a low-dimensional represen tation of these deriv ativ es (i.e., deriv ative-based scores). Subsequently , the deriv ativ es can b e recov ered b y the Karh unen-Lo` ev e expansion. Previous work on deriv ativ e-based FPCA can b e found in Liu and M ¨ uller ( 2009 ); Dai et al. ( 2018 ); Grith et al. ( 2018 ). In Liu and M¨ uller ( 2009 ), the deriv ative- based FPCs were estimated by taking the deriv ative from both sides of the eigenequation of the con ven tional FPCA. In other words, the estimation of deriv ativ e-based FPCs w as linked to the task of estimating a partial deriv ative of the sample cov ariance function, which was achiev ed by the lo cal linear smo other. Dai et al. ( 2018 ) illustrated that the deriv ativ e-based FPCs estimated b y Liu and M ¨ uller ( 2009 ) were not orthogonal. T o obtain the orthogonal deriv ative-based FPCs, they presen ted a new approach b y estimating the deriv ativ e of the co v ariance function with respect to tw o dimensions (i.e., the mixed partial deriv ative). In this case, the deriv ativ e-based FPCs were obtained via the eigendecomposition of the mixed partial deriv ativ e of the cov ariance and therefore w ere orthogonal. Their method has b een implemented in the FPCAder() function of the fdap ac e pac k age ( Zhou et al. , 2024 ). Grith et al. ( 2018 ) extended the deriv ativ e-based FPCA to a multi- dimensional domain, where they applied the eigendecomp osition to a dual co v ariance matrix of the deriv ativ es to obtain the deriv ativ e-based FPCs. How ever, all these metho ds rely on lo cal linear smo others to estimate the deriv ativ e of co v ariance function. In deriv ative-based FPCA, estimating the deriv ative of cov ariance function is a fundamental step. In this pap er, w e are in terested in using P-splines to estimate the deriv ative of co v ariance. P-splines are computationally efficien t and provide enough flexibility to capture non-linearities in functional data. More importantly , in one-dimensional cases, incorp orating an extra p enalt y term in a P-spline allo ws for increased smo othing and impro ves the accuracy of deriv ative es- timation for functional curves ( Simpkin and New ell , 2013 ). T o estimate the deriv ative of the co v ariance function, w e aim to extend F A CE algorithm by incorp orating an additive p enalty term in P-splines. Analogous to one-dimensional cases, the additive p enalt y enables a stronger smo oth whic h is particularly useful for deriv ative estimation of the co v ariance surface. It is further found that the deriv ativ e-based FPCs can be estimated without requiring the eigendecomp osition of the deriv ativ e of cov ariance function. T o estimate the deriv ativ e-based scores, w e prop ose a metho d based on mixed model equations (MME) ( Henderson , 1973 ). F ollowing this framework, we extend the deriv ative-based FPCA to multiv ariate cases, referred to as deriv ativ e multiv ariate functional principal comp onen t analysis (DMFPCA). The pap er is organized as follows. In Section 2 , w e introduce a new approac h whic h incorporates an additiv e penalty in P-splines with the F A CE algorithm. Section 3 shows the estimation of deriv ativ e-based FPCA, including the deriv ativ e-based FPCs, eigenv alues and scores; and the extension to DMFPCA. A simulation study to ev aluate the proposed deriv ativ e-based FPCA and DMFPCA is provided in Section 4 , where the FPCAder() function is used for comparison with our approac h for univ ariate cases. Section 5 shows an application of DMFPCA to human mov ement data (e.g., the joint angles of the knee, hip and ankle) collected by wearable sensors, where the scores demonstrate strong classification p erformance in distinguishing participants across differen t lo comotion tasks. The paper concludes with a discussion in Section 6 . 2 2 F ast co v ariance estimation with an additiv e p enalt y in P-splines Let X : T → R b e a random pro cess defined in the Hilb ert space H , suc h that X ∈ L 2 ( T ) where T ⊂ R denotes the observ ation domain. Assume X ( t ) is d -times differentiable, with mean E ( X ( t )) = 0 and co v ariance K ( s, t ) = Cov( X ( s ) , X ( t )). Supp ose that { X i , i = 1 , . . . , n } is a collection of indep enden t realizations of X . Let Y ij b e the j th observ ation ( j = 1 , . . . , J ) of the pro cess X i at a random time T j ∈ T , Y ij = X i ( T j ) + ϵ ij , where ϵ ij are normally distributed measuremen t errors with E ( ϵ ij )=0 and V ar( ϵ ij ) = σ 2 . The cov ariance of the sample can b e calculated b y ˆ K ( T j , T l ) = n − 1 P n i =1 Y ij Y il at eac h pair of sampling points ( T j , T l ). Let Y i = ( Y i 1 , . . . , Y iJ ) T and Y = [ Y 1 , . . . , Y n ]. W e denote the cov ariance of the sample by b K = n − 1 YY T . 2.1 Co v ariance estimation F ollowing Xiao et al. ( 2016 ), the F A CE estimator of the co v ariance matrix can b e represented as e K = S b KS , (1) where S ∈ R J × J is a smo other symmetric matrix constructed using P-splines ( Eilers and Marx , 1996 ), S = B ( B T B + λ P ) − 1 B T . Here, we denote B ∈ R J × c as the matrix of the B-spline basis, suc h that B = [ B 1 , . . . , B c ], where B k = ( B k ( t 1 ) , . . . , B k ( t J )) T are the B-spline basis functions for k = 1 , . . . , c . The matrix P ∈ R c × c is a symmetric penalty matrix, such that P = D T l D l , where D l is a difference op erator of dimension ( c − l ) × c and l is the p enalty order. The scalar λ ≥ 0 is the smo othing parameter, with larger v alues resulting in smo other estimates. Simpkin and New ell ( 2013 ) and Hern´ andez et al. ( 2023 ) introduced metho ds to include an additiv e p enalt y structure to P-splines to allo w for extra smo othing, whic h should help prev ent undersmo othing in deriv ativ e estimation. By incorporating an additive p enalt y term in P-splines, the smo other matrix is reconstructed by S = B ( B T B + λ 1 P 1 + λ 2 P 2 ) − 1 B T , where P 1 = D T l 1 D l 1 and P 2 = D T l 2 D l 2 are p enalt y matrices p enalized by smo othing parameters λ 1 and λ 2 , resp ectiv ely . When there is a single penalty in P-splines, Xiao et al. ( 2016 ) show ed that F ACE starts with the decomposition ( B T B ) − 1 / 2 P ( B T B ) − 1 / 2 = U diag( s ) U T where U is the matrix of eigenv ectors and s is the v ector of eigenv alues. When including an additive p enalt y in P-splines, we define λ + = λ 1 + λ 2 to be an ov erall smo othing level and w = λ 1 /λ + ∈ [0 , 1] to b e a relative weigh t of λ 1 . Then, the ov erall p enalt y matrix λ 1 P 1 + λ 2 P 2 can b e represented by λ + ( w P 1 + (1 − w ) P 2 ). F or a given w , let U diag( s ) U T b e the decomp osition of ( B T B ) − 1 / 2 ( w P 1 + (1 − w ) P 2 )( B T B ) − 1 / 2 , such that ( B T B ) − 1 / 2 ( w P 1 + (1 − w ) P 2 ) ( B T B ) − 1 / 2 = U diag( s ) U T , (2) where U ∈ R c × c is the matrix of eigenv ectors and s is the vector of eigenv alues. By using the decomp osition in ( 2 ), the smo other matrix can b e simplified in Lemma 1 , with the pro of pro vided in App endix A.1 . Lemma 1. Define A 0 = ( B T B ) − 1 / 2 U ∈ R c × c , A s = BA 0 ∈ R J × c , Σ s = { I c + λ + diag ( s ) } − 1 ∈ R c × c . A s has orthonormal c olumns, A T s A s = I c . The smo other matrix is r ewritten as S = A s Σ s A T s . Based on Lemma 1 , replacing S with A s Σ s A T s in to expression ( 1 ) gives e K = BΘB T , where Θ = A 0 Σ s A T 0 B T b KBA 0 Σ s A T 0 (3) is a c × c symmetric and p ositiv e-definite matrix. More specifically , the ( s, t )th entry of the co v ariance estimator is e K ( s, t ) = B T ( s ) ΘB ( t ) . (4) The cov ariance estimator is in ‘sandwich form’. The B-spline bases are uniquely determined once the knot, degree and the num b er of basis functions are given. Therefore, to obtain the co v ariance estimator, we only need to estimate Θ . W e start with the selection of smo othing 3 parameters. According to Xiao et al. ( 2016 , Prop.2), the smo othing parameters are estimated by minimizing a generalized cross-v alidation (GCV): P n i =1 ∥ Y i − SY i ∥ 2 (1 − tr( S ) /J ) 2 = P c k =1 C kk ( λ + s k ) 2 / (1 + λ + s k ) 2 − ∥ Y s ∥ 2 F + ∥ Y ∥ 2 F { 1 − J − 1 P c k =1 (1 + λ + s k ) − 1 } 2 , (5) where s k is the k th element of s , Y s = A T s Y ∈ R c × n , C kk is the k th diagonal element of Y s Y T s , and ∥ · ∥ F is the F robenius norm. In practice, w e p erform a tw o-dimensional grid search of ( λ + , w ), building on a similar idea shown in Li et al. ( 2020 ). F or a given pair ( λ + , w ), we calculate U and s based on the decomposition equation in ( 2 ), then apply Lemma 1 to construct A s and finally calculate the GCV in ( 5 ). The optimal pair ( λ + , w ) is chosen by minimizing GCV ov er the tw o- dimensional grid, which is equiv alen t to re-parametrizing λ 1 = w λ + and λ 2 = λ + (1 − w ). After finding the optimal pair ( λ + , w ), w e re-calculate U , s , A 0 and Σ s and replace them in ( 3 ) to obtain Θ . The metho d of F A CE with additiv e p enalty is summarized in Algorithm 1 . Algorithm 1: F A CE with an additive penalty in P-splines Input: Sample { Y ij } 1 ≤ i ≤ n, 1 ≤ j ≤ J , p enalt y orders l 1 and l 2 , num b er of B-spline basis functions c , B-spline degree q . Construction: The B-spline matrix B , the p enalt y matrices P 1 and P 2 , the observ ation matrix Y , the sample cov ariance matrix b K . Selection of smo othing parameters: F or a given pair of ( λ + , w ), Step 1: Obtain U and s by solving ( 2 ) Step 2: Compute A 0 , A s , Σ s b y Lemma 1 and Y s = A T s Y Step 3: Ev aluate the GCV in ( 5 ) and identify the optimal pair ( λ + , w ) that minimizes GCV Step 4: Update U , s , A 0 , A s , Σ s b y using the selected ( λ + , w ) Estimation of Θ : Calculate Θ = A 0 Σ s A T 0 B T b KBA 0 Σ s A T 0 in ( 3 ). Output: The matrices A 0 , A s , Σ s , Θ . 2.2 The deriv ativ e of cov ariance estimation Giv en that X ( t ) is d -times differen tiable, K ( s, t ) is d -times differen tiable in each argument. F or simplicit y , we denote ∂ d X ( t ) : = ∂ d ∂ t d X ( t ) , ∂ d ∂ d K ( s, t ) : = ∂ d ∂ s d ∂ d ∂ t d K ( s, t ) , d ∈ N where when d = 0 in particular, w e ha ve X ( t ) = ∂ 0 X ( t ) and K ( s, t ) = ∂ 0 ∂ 0 K ( s, t ). Note that under the assumptions that X ( t ) is mean cen tered, square integrable and d -times differentiable; ∂ d ∂ d K ( s, t ) exists and is contin uous; the deriv ativ e of cov ariance is equiv alen t to the cov ariance of deriv ativ es, which is: ∂ d ∂ d K ( s, t ) = ∂ d ∂ s d ∂ d ∂ t d Co v ( X ( s ) , X ( t )) = E ∂ d X ( s ) ∂ d X ( t ) . Based on de Bo or ( 1978 ) and Eilers and Marx ( 2021 , Sec.2.5), B-splines hav e sp ecial deriv ative prop erties. F or instance, assume f ( t ) ∈ H can be represented b y a linear com bination of c B- spline basis functions of degree q defined ov er a sequence of ev enly spaced knots. That is, f ( t ) = P c k =1 B k ( t ; q ) θ k , or equiv alen tly in the matrix form, f ( t ) = B T ( t ) θ , where θ = ( θ 1 , . . . , θ c ) T is a v ector of co efficien ts and B ( t ) = { B k ( t ; q ) } c k =1 is a vector of B-spline basis. The d th order deriv ativ e of f can b e obtained b y ∂ d f ( t ) = h − d { B ( t ; q − d ) } T D d θ , where h is the distance b et ween adjacent knots, D d ∈ R ( c − d ) × c is a difference operator, B ( t ; q − d ) = { B k ( t ; q − d ) } c k = d +1 ∈ R ( c − d ) × 1 is a v ector of B-spline basis of degree q − d . This is a linear com bination of the new B-spline basis functions of degree q − d and the new co efficien ts after taking d th order difference of the original co efficien t vector θ , divided by the constant h d . On the other hand, the deriv ative of f can be rewritten as ∂ d f ( t ) = B T der ( t ) θ , where B der ( t ) = h − d D T d B ( t ; q − d ). This shows the deriv ativ e is represen ted by a linear combination of the new basis B der and the original v ector of co efficients θ . F ollowing this, the d th order deriv ativ e of the cov ariance estimator in ( 4 ) can b e expressed as ∂ d ∂ d e K ( s, t ) = B T der ( s ) ΘB der ( t ) . (6) 4 The deriv ativ e of cov ariance retains the sandwic h form, where B der ( t ) is computed from B ( t ) and Θ is the original coefficient matrix defined in ( 3 ). Algorithm 1 can therefore be directly applied to estimate the deriv ative of cov ariance. F rom the input, a deriv ativ e order d will b e needed. In the construction pro cess, it is straigh tforward to ha ve B der once B is defined. The selection of smo othing parameters and the estimation of Θ remain the same. By replacing B der and Θ in ( 6 ), the deriv ativ e of cov ariance is estimated. T o ensure the deriv ative of B-splines are contin uous, w e restrict the degree to satisfy q ≥ d + 2. In terms of the selection of p enalt y orders l 1 and l 2 , Simpkin and Newell ( 2013 ) and Hern´ andez et al. ( 2023 ) compared sev eral pairs of p enalty order and found that the selections of penalty orders had little effect on the p erformance of deriv ative estimation (i.e., one-dimensional cases). In our study , we reac h the same conclusion that the selection of p enalty orders has minimal impact on the estimation of the deriv ative of cov ariance. W e conduct a simulation with three pairs of p enalt y order ( l 1 , l 2 ) = { (1 , 2) , (1 , 3) , (2 , 3) } and the results are pro vided in Section 4.1 . 3 Deriv ativ e-based functional principal comp onen t analysis Co v ariance estimation is a fundamental step in FPCA ( Ramsay and Silverman , 2002 , 2005 ; Y ao et al. , 2005 ). With the approach introduced in Section 2 , w e can estimate the deriv ativ e of co- v ariance, which allows conv en tional FPCA to b e extended to deriv ativ e-based FPCA. While con- v entional FPCA fo cuses on v ariation in the functions themselves, deriv ative-based FPCA captures v ariation in their deriv ativ es (e.g., velocities and accelerations), whic h is useful for analyzing un- derlying dynamics. 3.1 Deriv ative-based eigenfunctions and eigenv alues The co v ariance op erator Γ : H → H of ∂ d X is defined as an integral op erator with kernel K d , where K d ( s, t ) = Cov( ∂ d X ( s ) , ∂ d X ( t )) is the cov ariance of deriv ativ es. Assuming that Γ is a compact p ositiv e op erator on H , there exists an orthonormal basis { ϕ k } k ≥ 1 and a set of real num b ers { ν k } k ≥ 1 suc h that ν 1 ≥ ν 2 ≥ · · · ≥ 0, satisfying Γ ϕ k ( · ) = ν k ϕ k ( · ) , ν k − → 0 as k − → ∞ . According to Mercer’s theorem ( Mercer , 1909 ), the eigendecomp osition of K d ( s, t ) can b e expressed as K d ( s, t ) = P ∞ k =1 ν k ϕ k ( s ) ϕ k ( t ). As shown in Section 2.2 , the co v ariance of deriv ativ es is equal to the deriv ativ e of co v ariance, i.e., K d ( s, t ) = ∂ d ∂ d K ( s, t ). Consequently , we can rewrite Mercer’s expansion as Z ∂ d ∂ d K ( s, t ) ϕ k ( t ) dt = ν k ϕ k ( s ) . (7) The smooth estimator of the deriv ativ e of the cov ariance, ∂ d ∂ d e K ( s, t ), is con tin uous, symmetric and p ositive semi-definite, see ( 6 ). As ∂ d ∂ d e K is expanded in B der , its eigenfunctions ˆ ϕ k should lie in the same functional space, which can b e represen ted by ˆ ϕ k ( t ) = B T der ( t ) ˆ α k , where ˆ α k ∈ R c × 1 is a co efficien t v ector asso ciated to the k th deriv ative-based eigenfunction. Moreo ver, by replacing ∂ d ∂ d K ( s, t ) with its smo oth estimator, ( 7 ) b ecomes B T der ( s ) Θ Z B der ( t ) B T der ( t ) dt ˆ α k = ˆ ν k B T der ( s ) ˆ α k . Define G = R B der ( t ) B T der ( t ) dt , which is a c × c p ositiv e definite matrix. The ab ov e equa- tion is further simplified to ΘG ˆ α k = ˆ ν k ˆ α k . By multiplying b oth sides b y G 1 / 2 , we obtain G 1 / 2 ΘG 1 / 2 G 1 / 2 ˆ α k = ˆ ν k G 1 / 2 ˆ α k , where ˆ ν k are the eigen v alues of G 1 / 2 ΘG 1 / 2 and G 1 / 2 ˆ α k are the corresp onding eigen vectors. Let Q = [ Q 1 , . . . , Q c ] b e an orthonormal matrix of eigenv ec- tors, suc h that G 1 / 2 ΘG 1 / 2 = Q ˆ VQ , where ˆ V = diag( ˆ ν 1 , . . . , ˆ ν c ) is a diagonal matrix with the first c eigenv alues of ∂ d ∂ d e K . It is straightforw ard to obtain ˆ α k = G − 1 / 2 Q k . Therefore, we finally ha ve ˆ ϕ k ( t ) = B T der ( t ) G − 1 / 2 Q k , k = 1 , . . . , c. (8) Note that ( 8 ) pro vides a metho d to estimate the deriv ative-based eigenfunctions ϕ k without requiring eigendecomp osition of the deriv ativ e of co v ariance ∂ d ∂ d e K . The pro cedure for estimating the deriv ativ e-based eigencomp onen ts is provided in Algorithm 2 . 5 3.2 Deriv ative-based scores The b est linear un biased prediction (BLUP) is commonly used to estimate functional principal comp onen t scores ( Y ao et al. , 2005 ; Dai et al. , 2018 ), and this requires the inv ersion of matrices that are of dimension equal to the num b er of observ ations p er curve. Cui et al. ( 2023 ) prop osed a new metho d for multilev el FPCA based on a mixed mo del equation (MME), which reduces the computational complexity . W e aim to extend the MME metho d to estimate the deriv ativ e-based scores. Giv en that ∂ d X ( t ) exists and has a finite second moment in the Hilbert space H , it can be represen ted b y a Karhunen-Lo ` eve expansion ∂ d X ( t ) = ∞ X k =1 ξ k ϕ k ( t ) , t ∈ T , where ϕ k ( t ) are the deriv ativ e-based eigenfunctions, ξ k are the deriv ativ e-based scores with ξ k ∼ N (0 , ν k ) and ν k are the deriv ativ e-based eigen v alues. In practice, we use a truncated form of the Karh unen-Lo` ev e represen tation ∂ d X ( t ) = P K k =1 ξ k ϕ k ( t ), where only the first K eigenfunctions are selected. Let ∂ d X i , i = 1 , . . . , n b e a collection of indep endent realizations of ∂ d X . Let Y d ij b e the j th observ ation of the pro cess ∂ d X i at a random time T j ∈ T , Y d ij = K X k =1 ξ ik ϕ k ( t ) + ϵ ij , ϵ ij ∼ N (0 , σ 2 ) . (9) Define Y d i = ( Y d i 1 , . . . , Y d iJ ) T , Φ = [ ϕ 1 , . . . , ϕ K ], ξ i = ( ξ i 1 , . . . , ξ iK ) T and ϵ i = ( ϵ i 1 , . . . , ϵ iJ ) T . The mo del in ( 9 ) is rewritten in a matrix form Y d i = Φ ξ i + ϵ i . Note that ξ i can b e treated as a random effect. By using the MME ( Henderson , 1973 ), the deriv ativ e-based scores are represented as ξ i = ( Φ T Φ + σ 2 V − 1 ) − 1 Φ T Y d i , (10) where V = diag( ν 1 , . . . , ν K ) is a diagonal matrix with the first K deriv ativ e-based eigenv alues. T o estimate Y d i , we use the smo other matrix based on F ACE with an additive p enalt y in P- splines. Let e Y i b e the smo oth estimator of Y i , which is represented as e Y i = SY i . By replacing S with A s Σ s A T s based on Lemma 1 , e Y i can b e further expressed as e Y i = B θ , where θ = A 0 Σ s A T 0 B T Y i . According to the sp ecial deriv ativ e prop erties of B-splines, the deriv ativ e of e Y i can then b e estimated by Y d i = B der θ . F or the estimation of σ 2 , we ha ve ˆ σ 2 = R ( ∂ d ∂ d ˆ K ( s, s ) − ∂ d ∂ d e K ( s, s )) ds , where ∂ d ∂ d ˆ K ( s, s ) and ∂ d ∂ d e K ( s, s ) are the main diagonal elements of sample and smo othed cov ariance of the deriv ativ es. The pro cedure of estimating the deriv ative-based scores is summarised in Algorithm 2 . Algorithm 2: Deriv ative-based eigencomp onen ts and scores Input: Sample { Y ij } 1 ≤ i ≤ n, 1 ≤ j ≤ J , p enalt y orders l 1 and l 2 , deriv ativ e order d , num b er of B-spline basis functions c , B-spline degree q Construction: The B-spline matrix B , the deriv ativ e B-spline matrix B der , the p enalty matrices P 1 and P 2 , the sample cov ariance matrix b K Estimation of Θ : Use F A CE with an additive p enalt y in P-splines (Algorithm 1 ) to obtain Θ Estimation of deriv ativ e-based eigencomponents : Step 1: Calculate G = R B der ( t ) B T der ( t ) dt Step 2: Obtain Q and V b y solving G 1 / 2 ΘG 1 / 2 = QV Q Step 3: Determine the smallest K such that P K k =1 ν k / P c k =1 ν k ≥ 0 . 95 Step 4: Calculate the deriv ative-based eigenfunctions ϕ k ( t ), k = 1 , . . . , K based on ( 8 ) and select the asso ciated deriv ative-based eigenv alues { ν 1 , . . . , ν K } Estimation of deriv ativ e-based scores : Step 1: Calculate θ = A 0 Σ s A T 0 B T Y i , where A 0 and Σ s are obtained from Algorithm 1 Step 2: Calculate Y d i = B der θ and construct Y d = [ Y d 1 , . . . , Y d n ] Step 3: Calculate ∂ d ∂ d ˆ K = n − 1 Y d Y d T and ∂ d ∂ d e K = B T der ΘB der Step 4: Calculate ˆ σ 2 = R ( ∂ d ∂ d ˆ K ( s, s ) − ∂ d ∂ d e K ( s, s )) ds Step 5: Calculate the deriv ative-based scores ξ i based on ( 10 ) Output: ϕ k ( t ), { ν 1 , . . . , ν K } and { ξ i 1 , . . . , ξ iK } 6 3.3 Deriv ative m ultiv ariate functional principal comp onent analysis Happ and Grev en ( 2018 ) introduced an estimation strategy to calculate eigencomp onents and scores of MFPCA based on their univ ariate counterparts. W e extend the strategy to deriv ative m ultiv ariate functional principal comp onen t analysis (DMFPCA). W e consider indep enden t realizations of X = ( X [1] , . . . , X [ P ] ) T , P ≥ 1, a cen tered vector- v alued sto c hastic process which consists of P tra jectories. Eac h X [ p ] : T p → R is assumed to b elong to L 2 ( T p ), with T p ⊂ R . Let T : = T 1 × · · · × T P b e the domain of X and denote by t : = ( t 1 , . . . , t P ) an elemen t of T . The pro cess X ( t ) = ( X [1] ( t 1 ) , . . . , X [ P ] ( t P )) T is then defined on H : = L 2 ( T 1 ) × · · · × L 2 ( T P ). Given that each ∂ d X ( t ) exists and has a finite second momen t, it can b e represented by a multiv ariate Karhunen-Lo ` eve expansion ∂ d X ( t ) = ∞ X k =1 ρ k ψ k ( t ) , t ∈ T , (11) where ρ k are the deriv ativ e multiv ariate functional principal comp onent scores (DMFPC-scores) and ψ k ( t ) = ( ψ [1] k ( t 1 ) , . . . , ψ [ P ] k ( t P )) T are the deriv ativ e multiv ariate functional principal compo- nen ts (DMFPCs). In particular, a truncated form of ( 11 ) for the realizations of ∂ d X can be written as ∂ d X i ( t ) = P M k =1 ρ ik ψ k ( t ) where M is the truncation n umber of DMFPCs and DMFPC-scores. W e denote b y K p the truncation num b er used for the d th deriv ativ e of p th univ ariate comp onen t, such that ∂ d X [ p ] i ( t ) = P K p k =1 ξ [ p ] ik ϕ [ p ] k ( t ). Note that the DMFPCA metho d requires only M ≪ K + = P P p =1 K p scores, which achiev es substantial dimension reduction and retains the essential v ariability of the deriv ativ es. T o estimate ρ k and ψ k , we first construct a score matrix Ξ ∈ R n × K + , where the i th ro w collects the K + deriv ativ e-based scores for all univ ariate comp onents p = 1 , . . . , P , i.e., ξ [1] i 1 , . . . , ξ [1] iK 1 , . . . , ξ [ P ] i 1 , . . . , ξ [ P ] iK P . Define Z = ( n − 1) − 1 Ξ T Ξ . Let v k and c k b e the eigen v alues and eigen vectors of Z . W e define c k = ( c [1] k , . . . , c [ P ] k ) T ∈ R K + × 1 , with c [ p ] k ∈ R K p × 1 represen ting the p th block of c k . W e select the first M eigen vectors and eigenv alues of Z , where M is the smallest n umber such that P M k =1 v k / P K + k =1 v k ≥ 0 . 95. F ollo wing Happ and Greven ( 2018 , Prop.5), the elements of c [ p ] k can b e used as the co efficien ts to link DMFPCs and DMFPC-scores to their univ ariate counterparts, ψ [ p ] k ( t p ) = K p X l =1 c [ p ] k l ϕ [ p ] l ( t p ) , ρ ik = P X p =1 K p X l =1 c [ p ] k l ξ [ p ] ik , k = 1 , . . . , M , (12) where ϕ [ p ] l and ξ [ p ] ik are the deriv ativ e-based eigenfunctions and scores for univ ariate data X [ p ] for p = 1 , . . . , P , and ρ ik ∼ N (0 , v k ). The pro cedure of estimating the DMFPCA is pro vided in Algorithm 3 . Algorithm 3: DMFPCA Input: Sample n Y [ p ] ij o 1 ≤ i ≤ n, 1 ≤ j ≤ J, 1 ≤ p ≤ P , p enalt y orders l 1 and l 2 , deriv ativ e order d , num b er of B-spline basis functions c , B-spline degree q F or eac h p ∈ [1 , P ] : Estimate deriv ativ e-based eigenfunctions ϕ [ p ] k ( t p ) and scores ξ [ p ] ik using Algorithm 2 Construction : A score matrix Ξ where ( Ξ ) i · = ( ξ [1] i 1 , . . . , ξ [1] iK 1 , . . . , ξ [ P ] i 1 , . . . , ξ [ P ] iK P ) and its co v ariance Z = ( n − 1) − 1 Ξ T Ξ Eigendecomp osition : Obtain c k and v k b y solving Zc k = v k c k Selection of M : Determine the smallest M suc h that P M k =1 v k / P K + k =1 v k ≥ 0 . 95 Estimation of DMFPCs and DMFPC-scores: Calculate ψ k and ρ ik based on ( 12 ) Output: ψ k ( t ), { v 1 , . . . , v M } and { ρ i 1 , . . . , ρ iM } 7 4 Sim ulation W e simulate m ultiv ariate functional data with the following tw o univ ariate comp onents: X [1] ( t ) = a + 5 ct + 10 b exp( − 16 t 2 ) , X [2] ( t ) = a − cos ct 4 (2 t − π ) + 2 exp( − 16 bt 2 ) , where a ∼ N (0 , 1), b ∼ N (0 . 5 , 0 . 0196), c ∼ N (3 . 75 , 0 . 49) and ρ ab = ρ ac = ρ bc = 0 . 2. W e consider the most common case of the first deriv ative d = 1 and use the notation ∂ X for simplicity . The deriv ativ es of the tw o functions are: ∂ X [1] ( t ) = 64 bt exp( − 16 t 2 ) − c/ 5 ( ct/ 5 + 2 b exp( − 16 t 2 )) 2 , ∂ X [2] ( t ) = ct − cπ 4 sin ct 4 (2 t − π ) − 64 bt exp( − 16 bt 2 ) . As an illustration, Figure 1 shows a sample of the data simulated from the tw o functions and their corresp onding deriv atives, when setting t ∈ [0 , 1] with 101 equidistant observ ations. This indicates the tra jectories of X [1] and X [2] are correlated and hav e some joint v ariation. F or instance, the blue tra jectory in X [1] ( t ) shows an increase o ver the first half of the domain, whereas the corresp onding tra jectory in X [2] exhibits a decrease ov er the same interv al. Note that the data are non-cen tered. In the case of non-centered data, w e use P-splines to estimate the mean and cen ter the data at the initial step. In practice, the deriv ativ es are usually unobserved. In this sim ulation, the deriv atives are calculated straightforw ardly since w e ha ve the functional forms of the data, which are treated as ground truth to ev aluate the estimation metho ds. 0 1 2 3 0.00 0.25 0.50 0.75 1.00 X [1] ( t ) −1 0 1 2 0.00 0.25 0.50 0.75 1.00 X [2] ( t ) −5 0 5 10 0.00 0.25 0.50 0.75 1.00 ∂ X [1] ( t ) −5 −4 −3 −2 −1 0 0.00 0.25 0.50 0.75 1.00 ∂ X [2] ( t ) Figure 1: A sample of data sim ulated from the t wo functions (upper panel) and their corresponding true deriv ativ es (lo wer panel). W e consider three settings: (1) densely observed data without measurement error; (2) densely observ ed data with measurement error σ = 0 . 5; (3) sparsely observed data with measuremen t error σ = 0 . 5. F or each setting, we generate n = 100 random tra jectories for p = 1 , 2, resp ectively , and run the simulation 500 times. F or dense cases, data are observed on the same time grid t p ∈ [0 , 1] consisting of 101 equidistan t observ ations. F or the sparse case, data are observed on t p ∈ [0 , 1] while 40%-50% of the observ ations for eac h tra jectory are missing completely at random. T o handle sparse data, we reconstruct individual tra jectories ov er the entire observ ation domain using the P ACE approach of Y ao et al. ( 2005 ). 4.1 Univ ariate functional data W e start with estimating the deriv ativ e-based eigencomponents and scores for univ ariate functional data. W e apply Algorithm 2 to both X [1] and X [2] and refer to this metho d as ‘DFPCA’. F or 8 comparison, w e use an existing R function FPCAder() ( Dai et al. , 2018 ) in fdap ac e pac k age. In Dai et al. ( 2018 ), a tw o-dimensional lo cal p olynomial smo othing metho d is employ ed to obtain the first-order deriv ativ e of the cov ariance function, and a BLUP metho d is used to estimate the deriv ativ e-based scores. W e ev aluate accuracy using relativ e errors (RE) for eigenv alues, integrated square errors (ISE) for eigenfunctions, normalised mean squared errors (MSE) for scores and relative mean integrated square errors (RMISE) for deriv atives. They are defined b y: RE( ν [ p ] k , b ν [ p ] k ) = | ν [ p ] k − b ν [ p ] k | /ν [ p ] k , ISE( ϕ [ p ] k , b ϕ [ p ] k ) = Z ϕ [ p ] k ( t p ) − b ϕ [ p ] k ( t p ) 2 dt p , MSE( ξ [ p ] k , b ξ [ p ] k ) = P n i =1 ( ξ [ p ] ik − b ξ [ p ] ik ) 2 /n V ar( ξ [ p ] k ) , RMISE( ∂ X [ p ] , \ ∂ X [ p ] ) = 1 n n X i =1 R ( ∂ X [ p ] i ( t p ) − \ ∂ X [ p ] i ( t p )) 2 dt p R ( ∂ X [ p ] i ( t p )) 2 dt p . Note that in simulation, ν [ p ] k , ϕ [ p ] k and ξ [ p ] k are obtained by applying R function FPCA() ( Y ao et al. , 2005 ) to the true deriv atives ∂ X [ p ] ; b ν [ p ] k , b ϕ [ p ] k and b ξ [ p ] k are estimated by applying DFPCA and FPCAder metho ds. After estimating the deriv ative-based eigenfunctions and scores, the Karhunen- Lo ` ev e represen tation is used to construct the deriv atives, i.e., \ ∂ X [ p ] ( t p ) = P K p k =1 b ξ [ p ] k b ϕ [ p ] k ( t p ), in comparison with the ground truth ∂ X [ p ] . W e apply b oth DFPCA and FPCAder to X [1] . W e calculate the logarithm of ISE for the first t wo deriv ative-based eigenfunctions, b ϕ [1] 1 and b ϕ [1] 2 , which together explain approximately 95% of the total v ariance in most simulations. Similarly , the RE and logarithm of MSE are computed for the first tw o deriv ativ e-based eigen v alues (i.e., b ν [1] 1 and b ν [1] 2 ) and scores (i.e., b ξ [1] 1 and b ξ [1] 2 ), resp ectiv ely . Figure 2 presents the corresp onding sim ulation results, whic h illustrates DFPCA p erforms b etter than FPCAder in all three settings. In particular, the errors are extremely small under the no noise setting for b oth methods, whereas the DFPCA still outperforms FPCAder, with the mean of RMISE 0.4% vs 0.9%. When data are noisy but dense, the mean of RMISE of DFPCA and FPCAder increase to 3% and 5%, resp ectively . When data are sparse and noisy , the DFPCA still p erforms b etter than FPCAder, with the mean of RMISE 12% vs 14%. W e pro vide the simulation results for X [2] in App endix A.2 , which also illustrates the DFPCA outp erforms FPCAder. Moreov er, an example of the estimation of the deriv ativ e of cov ariance is pro vided in App endix A.2 to illustrate DFPCA is b etter than FPCAder. 9 0.025 0.050 0.075 0.100 0.125 k=1 k=2 RE −15.0 −12.5 −10.0 −7.5 −5.0 k=1 k=2 log(ISE) −16 −12 −8 −4 k=1 k=2 log(MSE) 0.005 0.010 0.015 0.020 DFPCA FPCAder RMISE Method DFPCA FPCAder No noise 0.0 0.1 0.2 0.3 0.4 k=1 k=2 RE −5 −4 −3 −2 k=1 k=2 log(ISE) −4 −3 −2 −1 k=1 k=2 log(MSE) 0.02 0.03 0.04 0.05 0.06 DFPCA FPCAder RMISE Method DFPCA FPCAder Noisy 0.00 0.25 0.50 0.75 1.00 k=1 k=2 RE −3 −2 −1 0 k=1 k=2 log(ISE) −4 −3 −2 −1 0 1 k=1 k=2 log(MSE) 0.08 0.12 0.16 0.20 DFPCA FPCAder RMISE Method DFPCA FPCAder Sparse Figure 2: Simulation results for X [1] . (1) the dense case without noise (upp er); (2) the dense case with noise (middle); (3) the sparse case with noise (low er). It is noted that DFPCA relies on the F ACE algorithm with an additive penalty in P-splines. W e find that the pre-defined parameters in Algorithm 1 hav e little impact on the DFPCA results. Firstly , the c hoice of the num ber of B-spline basis functions is not critical, as smoothness is primarily con trolled b y the p enalt y terms. W e set c = 38 in simulation to provide enough flexibility to capture the underlying trend. Secondly , the B-spline degree should satisfy q ≥ d + 2. W e use cubic B-splines (i.e., q = 3) whic h is a common c hoice in practice. At last, for the penalty orders, w e consider three pairs ( l 1 , l 2 ) = { (1 , 2) , (1 , 3) , (2 , 3) } . F or each pair, we apply the DFPCA metho d to X [1] under the dense and noisy setting. T able 1 shows the corresp onding DFPCA results for each pair, presented as mean (standard deviation). This suggests that the selection of p enalt y orders has little effect on the DFPCA p erformance, although the pair ( l 1 , l 2 ) = (2 , 3) provides b etter o verall results. T able 1: DFPCA p erformance under different p enalt y orders ( l 1 , l 2 ) = { (1 , 2) , (1 , 3) , (2 , 3) } . P enalty order RE ISE MSE RMISE ( l 1 , l 2 ) k = 1 k = 2 k = 1 k = 2 k = 1 k = 2 (1 , 2) 0.13 (0.03) 0.11 (0.06) 0.04 (0.01) 0.06 (0.03) 0.02 (0.00) 0.10 (0.04) 0.04 (0.01) (1 , 3) 0.13 (0.03) 0.11 (0.06) 0.04 (0.01) 0.06 (0.03) 0.02 (0.00) 0.10 (0.04) 0.04 (0.01) (2 , 3) 0.11 (0.03) 0.08 (0.05) 0.03 (0.01) 0.05 (0.02) 0.02 (0.01) 0.10 (0.03) 0.03 (0.01) 4.2 Multiv ariate functional data W e consider the m ultiv ariate functional data X ( t ) = ( X [1] ( t ) , X [2] ( t )) and apply DMFPCA based on Algorithm 3 under the three settings. T o the b est of our knowledge, there is no existing method for estimating deriv ative-based FPCA for multiv ariate functional data. Although it is p ossible to extend FPCAder to m ultiv ariate cases, it is unlikely to pro vide better estimation results than the DMFPCA, as we hav e shown that FPCAder is outperformed by DFPCA. 10 F or multiv ariate functional data, w e ev aluate the accuracy based on: RE( v k , b v k ) = | v k − b v k | /v k , ISE( ψ k , b ψ k ) = P X p =1 Z ψ [ p ] k ( t p ) − b ψ [ p ] k ( t p ) 2 dt p , MSE( ρ k , b ρ k ) = P n i =1 ( ρ ik − b ρ ik ) 2 /n V ar( ρ k ) , RMISE( ∂ X , d ∂ X ) = 1 P P X p =1 P n i =1 R ( ∂ X [ p ] i ( t p ) − \ ∂ X [ p ] i ( t p )) 2 dt p P n i =1 R ( ∂ X [ p ] i ( t p )) 2 dt p , where v k , ψ k and ρ k are obtained by applying R function MFPCA() ( Happ and Greven , 2018 ) to the true deriv ativ es ∂ X ; b v k , b ψ k and b ρ k are estimated by applying DMFPCA based on Algorithm 3 . After estimating the DMFPCs b ψ k and DMFPC-scores b ρ k , the multiv ariate Karhunen-Lo ` eve rep- resen tation is used to construct the deriv atives, i.e., d ∂ X ( t ) = P M k =1 b ρ k b ψ k ( t ). Figure 3 sho ws the RE, ISE, MSE and RMISE for the m ultiv ariate functional data under three settings (i.e., no noise, noisy , sparse and noisy). The RE of the first tw o eigenv alues are b elo w 1% under the no noise setting, and increase to appro ximately 10% when data are noisy , and increase further when data are sparse. The ISE of DMFPCs are extremely small for the no noise case, with mean v alues around 0.002 for the first tw o DMFPCs. They increase to 0.036 for k = 1 and 0.049 for k = 2 when data are noisy , and 0.117 and 0.171 when data are sparse. The mean MSE of DMFPC-scores are less than 1% for b oth k = 1 and k = 2 when data are without noise, and increase to 2% for k = 1 and 6% for k = 2 when data are noisy , to 3% for k = 1 and 12% for k = 2 when data are sparse. The mean RMISE of fitted deriv atives are 1% for the no noise case, 6% for the noisy case and 13% for the sparse case. 0.0 0.1 0.2 0.3 k=1 k=2 RE 0.0 0.1 0.2 0.3 k=1 k=2 ISE 0.0 0.1 0.2 k=1 k=2 MSE 0.00 0.05 0.10 0.15 No noise Noisy Sparse RMISE Cases No noise Noisy Sparse Figure 3: Sim ulation results for multiv ariate functional data under three settings. 5 Application W earable sensors suc h as inertial measurement units (IMU) and electromy ography (EMG) are widely used to capture human mov ement data. These data offer v aluable information on gait patterns and mov ement abnormalities. Through quantifying v ariables such as angle, velocity and acceleration, joint kinematics analysis can improv e sp orts performance, reduce injury risk and facilitate early detection of abnormal mo vemen t patterns. Bo o et al. ( 2025 ) presen ted a dataset of h uman locomotion during daily activities collected from 120 male participants. P articipants p erformed three lo comotion tasks: lev el walking, incline w alking and stair ascent. Reflectiv e markers and surface EMG sensors were attached to the low er lim b, such as right knee (RNKE), right ankle (RANK) and righ t hip (RASI), to measure joint kinematics and m uscle activit y , see Fig.2 of Bo o et al. ( 2025 ). W e randomly selected 40 participan ts 11 from the lev el, incline and stair walking groups, resp ectiv ely . F or each participant, w e used data collected from the RANK, RASI and RNKE p ositions. The top panel of Figure 4 shows an example of ankle dorsiflexion, hip flexion and knee flexion for three participan ts ov er a normalized gait cycle. Positiv e v alues represent dorsiflexion (ankle) or flexion (hip and knee), whereas negative v alues indicate plan tarflexion or extension. The tra jectories suggest a join t kinematic pattern. F or instance, during a gait cycle in lev el walking, the transition to ankle plan tarflexion around the mid-gait coincided with maximum hip extension and the onset of rapid knee flexion. On the other hand, join t angular v elo cit y (i.e., the first deriv ativ e of joint angles) can measure the rate of c hange of joint angles ov er the gait cycle and characterize b oth the speed and timing of joint motion; how ever, it w as not observed in the dataset. By applying DMFPCA to the join t angle tra jectories, we aim to construct the join t angular velocities and to obtain their corresp onding eigenfunctions and scores. Ankle Hip Knee 0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00 −30 0 30 60 90 Gait cycle (%) Angle (Deg) Ankle Hip Knee 0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00 −200 0 200 400 Gait cycle (%) Angular velocity (Deg/s) Locomotion Incline walking Level walking Stair walking Figure 4: An example of ankle dorsiflexion, hip flexion and knee flexion for three participan ts (top panel) and their fitted angular v elo cities by DMFPCA (b ottom panel). Applying DMFPCA to joint angles retained the first six DMFPCs which together explained 96% of the total v ariation. Figure 5 presents the first tw o DMFPCs, which accounted for 60% and 18% of the total v ariance, resp ectiv ely . Note that DMFPCs of joint angles corresp ond to m ultiv ariate eigenfunctions of join t angular v elocities, and zero crossings for angular v elo cit y reflect c hanges in mov ement direction. F rom Figure 5 , participan ts with a higher first DMFPC-score exp erienced earlier zero crossings and smaller velocity magnitudes, and participants with a higher second DMFPC-score had earlier zero crossings and larger v elo cit y magnitudes. This suggests the DMFPC-scores c haracterize key features of joint motion for each participant, suc h as the range of v elo cit y and timing of directional change. _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ Ankle Hip Knee 0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00 −200 0 200 400 Gait cycle (%) ψ 1 _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ __ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ Ankle Hip Knee 0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00 −200 0 200 400 Gait cycle (%) ψ 2 Figure 5: The mean functions (black) plus and minus the first tw o m ultiv ariate eigenfunctions of join t angular velocities (i.e., the first tw o DMFPCs of joint angle tra jectories). 12 W e applied K-means clustering to the scaled DMFPC-scores and fixed the n umber of clusters to three based on the kno wn lo comotion tasks. Figure 6 presen ts the results for K-means clustering using DMFPC-scores. The left panel shows the three clusters against the first tw o scaled DMFPC- scores, whic h indicates that the first t wo DMFPC-scores clearly discriminate the three motions. More sp ecifically , participan ts in the level walking group generally had higher first DMFPC-scores than those in the incline and stair walking groups, whereas participan ts in the stair walking group generally had higher second DMFPC-scores than those the incline walking group. Based on Fig- ure 5 , it further suggests that participants in the level w alking group exp erienced an earlier time of directional c hange and a smaller v elo cit y range compared to those in the incline and stair w alking groups. It is eviden t that the level w alking t ypically has a shorter stance phase and a smaller range of joint motion compared with incline and stair w alking. Moreov er, the righ t panel of Figure 6 illustrates the first DMFPC (represented in black) primarily determined the cluster of level walk- ing, as it captured the ov erall pattern of the fitted deriv ativ e curv es within this group (shown in green). −2 −1 0 1 2 3 −1 0 1 2 ρ 1 (scaled) ρ 2 (scaled) Cluster Incline walking Level walking Stair walking K−Means on DMFPC−scores Ankle Hip Knee 0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00 −200 −100 0 100 200 Gait cycle (%) Centred angular velocity (Deg/s) Cluster Incline walking Level walking Stair walking Figure 6: Results for K-means clustering using scaled DMFPC-scores. Left panel: the three clusters against the first t wo scaled DMFPC-scores. Right panel: fitted deriv atives (after cen tering) together with the first DMFPC represen ted by the black line. Next, we ev aluated classification p erformance using the agreemen t b etw een the ground-truth cluster lab els and labels obtained after K-means clustering. Note that the ground-truth labels w ere defined a priori when 40 participan ts were selected from each lo comotion task. Based on K-means clustering of the DMFPC-scores, the cluster sizes for level, stair and incline w alking w ere 40, 39, and 41, resp ectiv ely . More specifically , all participants in the lev el w alking task w ere correctly iden tified, 3 participants in the stair walking task were misclassified as incline w alking and 2 participants in the incline walking task were misclassified as stair walking. Overall, the classification achiev ed a high accuracy of 0.96 (95% CI: 0.91-0.99). This demonstrates that the DMFPC-scores pro vided a compact and p o werful summary of key features of joint motion, whic h enabled accurate classification of different lo comotion tasks. Additionally , we conducted a sensitivit y analysis by v arying the num b er of participants assigned to eac h lo comotion task. W e applied DMFPCA to the new samples and performed K-means clustering of the DMFPC-scores. It w as found that the classification accuracy remained high. F or instance, when ground-truth lab els c hanged to 30, 50 and 40 (or to 30, 40 and 50) for level, incline and stair w alking tasks, respectively , the classification accuracy was 0.94 with 95% CI: 0.88-0.98 (or 0.93 with 95% CI: 0.87-0.97). Finally , angular velocities were constructed after estimating DMFPCs and DMFPC-scores of join t angle tra jectories. The b ottom panel of Figure 4 shows the fitted angular v elo cities of three participan ts, where the stair walking tended to exhibit larger velocities at the ankle, hip and knee than the level and incline walking. In general, understanding joint angular velocity across differen t lo comotion tasks ma y help clinicians ev aluate how individual joint mov ement tra jectories deviate from tasks. More imp ortan tly , DMFPC-scores provided a pow erful and compact summary of join t motion and could b e used to predict future outcomes such as risk of falls or injuries, which may assist clinicians in early risk iden tification. 6 Discussion FPCA and deriv ativ e-based FPCA pro vide a comprehensive view of functional v ariability , where FPCA captures v ariation in observed functional data and deriv ative-based FPCA characterises underlying dynamic b eha viour. The cov ariance estimation plays a fundamental role in both FPCA and deriv ative-based FPCA. The F A CE algorithm offers higher estimation accuracy and compu- 13 tationally efficiency in co v ariance estimation than lo cal linear smo others and biv ariate P-splines ( Xiao et al. , 2016 ; Cui et al. , 2023 ), where the smooth estimator is represented in a sandwich form. This motiv ates extending F A CE to estimate the deriv ative of the cov ariance function. The curren t literature relies on lo cal linear smo others to estimate the deriv ativ e of the cov ariance ( Liu and M¨ uller , 2009 ; Dai et al. , 2018 ; Grith et al. , 2018 ). In this pap er, w e prop ose a new approach b y incorp orating the F A CE algorithm with an additive p enalt y in P-splines. Including an extra p enalt y term in P-splines has been sho wn to improv e estimates of deriv ativ es in one-dimensional cases ( Simpkin and Newell , 2013 ; Hern´ andez et al. , 2023 ). When estimating the deriv atives of the cov ariance, the additional penalty enforces smoothness in b oth dimensions of the cov ariance surface, which preven ts undersmo othing and leads to improv ed estimation accuracy . Moreo ver, the smo oth estimator of the deriv ativ e of the cov ariance retains a sandwich form, therefore ensuring that the estimator is symmetric and p ositiv e semi-definite. F ollowing the F ACE algorithm with an additiv e p enalt y , we proceed to deriv ativ e-based FPCA. W e prop ose a new metho d to estimate the deriv ativ e-based FPCs without directly requiring the eigendecomp osition of the deriv ativ e of the cov ariance. W e use a mixed mo del equation to estimate the deriv ativ e-based scores, which av oids calculating the inv erse of the deriv ativ e of the cov ariance in BLUP . Based on this framework, we dev elop a DMFPCA method, whic h is the first metho d to the b est of our kno wledge to consider the deriv ativ e-based FPCA in multiv ariate cases. There are sev eral limitations of our study . Firstly , we note that the F A CE with an additive p enalt y in P-splines is primarily designed for densely observed data, as sho wn in Xiao et al. ( 2016 ) and Cui et al. ( 2023 ) where the original F A CE algorithm was prop osed and applied under dense settings. Secondly , even if an additive p enalt y term is included, the b oundary effects in P-splines ma y still lead to reduced accuracy for estimating the deriv ative-based FPCA. Thirdly , w e hav e fo cused on the scenario where the first-order deriv ative is considered but our metho d could b e used for higher-order cases. In conclusion, this pap er prop oses the F ACE algorithm with an additive penalty in P-splines and applies it to deriv ative-based FPCA. The deriv ative-based FPCA and its extension to multiv ariate cases help identify v ariations in dynamic changes and provide a low-dimensional summary of these v ariations for functional tra jectories. A App endix A.1 Pro of of Lemma 1 T o prov e Lemma 1 , we start from ( 2 ) ( B T B ) − 1 / 2 ( w P 1 + (1 − w ) P 2 ) ( B T B ) − 1 / 2 = U diag( s ) U T . Giv en that λ + = λ 1 + λ 2 and w = λ 1 /λ + , w e hav e λ + ( w P 1 + (1 − w ) P 2 ) = λ 1 P 1 + λ 2 P 2 . Multiplying b oth sides of ( 2 ) by λ + leads to ( B T B ) − 1 / 2 ( λ 1 P 1 + λ 2 P 2 )( B T B ) − 1 / 2 = U λ + diag( s ) U T . Multiplying b oth sides of the ab o ve equation on the left by U T and on the right by U gives U T ( B T B ) − 1 / 2 ( λ 1 P 1 + λ 2 P 2 )( B T B ) − 1 / 2 U = λ + diag( s ) , whic h can b e further constructed in to U T ( B T B ) − 1 / 2 ( B T B + λ 1 P 1 + λ 2 P 2 )( B T B ) − 1 / 2 U = I c + λ + diag( s ) . (A.1) T aking the in verse of b oth sides of ( A.1 ) gives U T ( B T B ) 1 / 2 ( B T B + λ 1 P 1 + λ 2 P 2 ) − 1 ( B T B ) 1 / 2 U = { I c + λ + diag( s ) } − 1 . (A.2) Define A 0 = ( B T B ) − 1 / 2 U , A s = BA 0 , Σ s = { I c + λ + diag( s ) } − 1 . By multiplying b oth sides of ( A.2 ) on the left by A s and on the right by A T s , we ha ve B ( B T B + λ 1 P 1 + λ 2 P 2 ) − 1 B T = A s Σ s A T s , where the left-hand side is exactly the smo other matrix S . Therefore, w e complete the proof of Lemma 1 . 14 A.2 Sim ulation Section 4.1 pro vides the sim ulation results of X [1] in terms of the RE for eigen v alues, ISE for eigen- functions, MSE for scores and RMISE for deriv ativ es under three different settings. In particular, Figure A.1 presents the estimation result of the deriv ativ e of co v ariance surface for X [1] under the dense and noisy setting. The ground truth surface is computed from the giv en true deriv ative func- tions of X [1] . The DFPCA and FPCAder metho ds estimate the surface based on dense but noisy observ ations of X [1] . Although the DFPCA metho d loses accuracy near the b oundaries due to the b oundary effect of P-splines, it outp erforms the FPCAder metho d which leads to undersmo othing and wiggly eigenfunctions. s t ∂ ∂ K ( s , t ) G r o u n d t r u t h 0 2 4 6 8 1 0 1 2 s t ∂ ∂ K ( s , t ) D F P C A 0 2 4 6 8 s t ∂ ∂ K ( s , t ) F P C A d e r 0 1 2 3 4 5 6 Figure A.1: The deriv ativ e of cov ariance surface of ∂ X [1] under the dense and noisy setting. The first tw o eigenfunctions of the deriv ative of co v ariance surfaces (see Figure A.1 ) are provided in Figure A.2 . W e note that even if an additive p enalty is included, the b oundary effects in P- splines ma y still lead to reduced accuracy for deriv ative estimation, as illustrated b y the differences b et w een the blue (i.e., the ground truth) and red (i.e., DFPCA) lines. Nevertheless, the deriv ativ e- based eigenfunctions estimated by DFPCA still outp erforms those estimated b y FPCAder. 0.0 0.5 1.0 1.5 2.0 2.5 0.00 0.25 0.50 0.75 1.00 k=1 −1 0 1 0.00 0.25 0.50 0.75 1.00 k=2 Method DFPCA FPCAder Ground truth Figure A.2: The deriv ativ e-based eigenfunctions of ∂ X [1] under the dense and noisy setting. In the following, w e present the sim ulation result of X [2] . W e apply b oth DFPCA and FPCAder to X [2] . W e calculate the logarithm of ISE for the first t wo deriv ativ e-based eigenfunctions, b ϕ [2] 1 and b ϕ [2] 2 , whic h together explain appro ximately 95% of the total v ariance in most sim ulations. Similarly , the RE and logarithm of MSE are computed for the first t wo deriv ativ e-based eigenv alues (i.e., b ν [2] 1 and b ν [2] 2 ) and scores (i.e., b ξ [2] 1 and b ξ [2] 2 ), respectively . Figure A.3 presents the corresponding sim ulation results, which illustrates DFPCA p erforms b etter than FPCAder in all three settings. 15 0.02 0.04 0.06 k=1 k=2 RE −16 −14 −12 −10 −8 −6 k=1 k=2 log(ISE) −20 −15 −10 −5 k=1 k=2 log(MSE) 0.004 0.006 0.008 DFPCA FPCAder RMISE Method DFPCA FPCAder No noise 0.0 0.1 0.2 0.3 0.4 k=1 k=2 RE −4 −2 0 k=1 k=2 log(ISE) −3 −2 −1 0 k=1 k=2 log(MSE) 0.050 0.075 0.100 0.125 DFPCA FPCAder RMISE Method DFPCA FPCAder Noisy 0.025 0.050 0.075 0.100 0.125 k=1 k=2 RE −15.0 −12.5 −10.0 −7.5 −5.0 k=1 k=2 log(ISE) −16 −12 −8 −4 k=1 k=2 log(MSE) 0.005 0.010 0.015 0.020 DFPCA FPCAder RMISE Method DFPCA FPCAder Sparse Figure A.3: Sim ulation results for X [2] , (1) the dense case without noise (upper); (2) the dense case with noise (middle); (3) the sparse case with noise (low er). Ac kno wledgmen t This work w as supp orted b y the F unctional data Analysis for Sensor T ec hnologies (F AST) pro ject, funded by Researc h Ireland grant 19/FFP/7002. References Bo o, J., Seo, D., Kim, M., and Ko o, S. (2025). Comprehensive h uman lo comotion and electromy o- graph y dataset: Gait120. Scientific Data , 12(1):1023. Coffey , N., Harrison, A. J., Donogh ue, O. A., and Hay es, K. (2011). Common functional principal comp onen ts analysis: A new approach to analyzing human mov emen t data. Human movement scienc e , 30(6):1144–1166. Cui, E., Li, R., Crainicean u, C. M., and Xiao, L. (2023). F ast multilev el functional principal comp onen t analysis. Journal of Computational and Gr aphic al Statistics , 32(2):366–377. Dai, X., M ¨ uller, H.-G., and T ao, W. (2018). Deriv ativ e principal comp onen t analysis for represent- ing the time dynamics of longitudinal and functional data. Statistic a Sinic a , 28(3):1583–1609. de Bo or, C. (1978). A pr actic al guide to splines , volume 27. springer New Y ork. Di, C.-Z., Crainiceanu, C. M., Caffo, B. S., and Punjabi, N. M. (2009). Multilev el functional principal comp onen t analysis. The annals of applie d statistics , 3(1):458. Eilers, P . H. and Marx, B. D. (1996). Flexible smo othing with b-splines and p enalties. Statistic al scienc e , 11(2):89–121. Eilers, P . H. and Marx, B. D. (2021). Pr actic al smo othing: The joys of P-splines . Cam bridge Univ ersity Press. 16 F an, J., Heckman, N. E., and W and, M. P . (1995). Lo cal p olynomial kernel regression for gener- alized linear mo dels and quasi-likelihoo d functions. Journal of the Americ an Statistic al Asso ci- ation , 90(429):141–150. Gertheiss, J., R ¨ ugamer, D., Liew, B. X., and Greven, S. (2024). F unctional data analysis: An in tro duction and recent developmen ts. Biometric al Journal , 66(7):e202300363. Grith, M., W agner, H., H¨ ardle, W. K., and Kneip, A. (2018). F unctional Principal Comp onen t Analysis for Deriv atives of Multiv ariate Curves. Statistic a Sinic a , 28(4):2469–2496. Gunning, E., Golovkine, S., Simpkin, A. J., Burke, A., Dillon, S., Gore, S., Moran, K., O’Connor, S., White, E., and Bargary , N. (2025). Analysing kinematic data from recreational runners using functional data analysis. Computational Statistics , 40(4):1825–1847. Gunning, E., W armenho v en, J., Harrison, A. J., and Bargary , N. (2024). F unctional Data Analysis in Biome chanics: A Concise R eview of Cor e T e chniques, Applic ations and Emer ging A r e as . Springer. Happ, C. and Greven, S. (2018). Multiv ariate functional principal component analysis for data observ ed on different (dimensional) domains. Journal of the A meric an Statistic al Asso ciation , 113(522):649–659. Henderson, C. R. (1973). Sire ev aluation and genetic trends. Journal of A nimal Scienc e , 1973(Symp osium):10–41. Hern´ andez, M. A., Lee, D.-J., Ro driguez-Alv arez, M. X., and Durb´ an, M. (2023). Deriv ativ e curve estimation in longitudinal studies using p-splines. Statistic al Mo del ling , 23(5-6):424–440. Li, C., Xiao, L., and Luo, S. (2020). F ast co v ariance estimation for multiv ariate sparse functional data. Stat , 9(1):e245. Liu, B. and M¨ uller, H.-G. (2009). Estimating d eriv atives for samples of sparsely observed functions, with application to online auction dynamics. Journal of the Americ an Statistic al Asso ciation , 104(486):704–717. Mbak a, U., Ramsay , J. O., and Carey , M. (2025). Estimating a smo oth cov ariance for functional data. Computational Statistics & Data Analysis , page 108255. Mercer, J. (1909). F unctions of p ositiv e and negativet ypeand their connection with theory ofintegral equations. Philosophic al T rinso ctions of R oyal So ciety , pages 4–415. Ramsa y , J. O. (1982). When the data are functions. Psychometrika , 47:379–396. Ramsa y , J. O. and Dalzell, C. J. (1991). Some to ols for functional data analysis. Journal of the R oyal Statistic al So ciety Series B: Statistic al Metho dolo gy , 53(3):539–561. Ramsa y , J. O. and Silverman, B. W. (2002). Applie d functional data analysis: metho ds and c ase studies . Springer. Ramsa y , J. O. and Silv erman, B. W. (2005). F unctional data analysis . Springer, New Y ork, 2nd edition. Rao, C. R. (1958). Some statistical metho ds for comparison of gro wth curves. Biometrics , 14(1):1– 17. Silv erman, B. W. (1996). Smo othed functional principal comp onen ts analysis by c hoice of norm. The Annals of Statistics , 24(1):1–24. Simpkin, A. and Newell, J. (2013). An additive p enalt y p-spline approach to deriv ative estimation. Computational Statistics & Data Analysis , 68:30–43. Stanisw alis, J. G. and Lee, J. J. (1998). Nonparametric regression analysis of longitudinal data. Journal of the Americ an Statistic al Asso ciation , 93(444):1403–1418. W ang, J.-L., Chiou, J.-M., and M ¨ uller, H.-G. (2016). F unctional data analysis. A nnual R eview of Statistics and its applic ation , 3(1):257–295. Xiao, L., Li, Y., and Rupp ert, D. (2013). F ast biv ariate p-splines: the sandwich smoother. Journal of the R oyal Statistic al So ciety Series B: Statistic al Metho dolo gy , 75(3):577–599. 17 Xiao, L., Zipunniko v, V., Rupp ert, D., and Crainiceanu, C. (2016). F ast co v ariance estimation for high-dimensional functional data. Statistics and c omputing , 26(1):409–421. Y ao, F. and Lee, T. C. (2006). Penalized spline mo dels for functional principal component analysis. Journal of the R oyal Statistic al So ciety Series B: Statistic al Metho dolo gy , 68(1):3–25. Y ao, F., M ¨ uller, H.-G., Clifford, A. J., Dueker, S. R., F ollett, J., Lin, Y., Buc hholz, B. A., and V ogel, J. S. (2003). Shrink age estimation for functional principal comp onen t score s with application to the p opulation kinetics of plasma folate. Biometrics , 59(3):676–685. Y ao, F., M ¨ uller, H.-G., and W ang, J.-L. (2005). F unctional data analysis for sparse longitudinal data. Journal of the Americ an Statistic al Asso ciation , 100(470):577–590. Zhou, Y., Chen, H., Iao, S. I., Kundu, P ., Zhou, H., Bhattac harjee, S., Carroll, C., Chen, Y., Dai, X., F an, J., Ga jardo, A., Hadjipantelis, P . Z., Han, K., Ji, H., Zhu, C., M ¨ uller, H.-G., and W ang, J.-L. (2024). fdap ac e: F unctional Data A nalysis and Empiric al Dynamics . R pac k age version 0.6.0. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment