함수형 데이터 도함수 공분산 추정을 위한 가법 페널티 P스플라인
** 본 논문은 P스플라인에 가법 페널티를 추가한 FAST Covariance Estimation (FACE) 알고리즘을 제안한다. 이를 통해 함수형 데이터의 공분산과 그 도함수를 효율적으로 추정하고, 도함수 기반 기능주성분분석(FPCA) 및 다변량 확장(DMFPCA)을 구현한다. 시뮬레이션과 인간 움직임 데이터 실험에서 기존 FPCAder 함수 대비 정확도와 계산 효율성이 크게 향상됨을 보인다. **
저자: Yueyun Zhu, Steven Golovkine, Norma Bargary
**
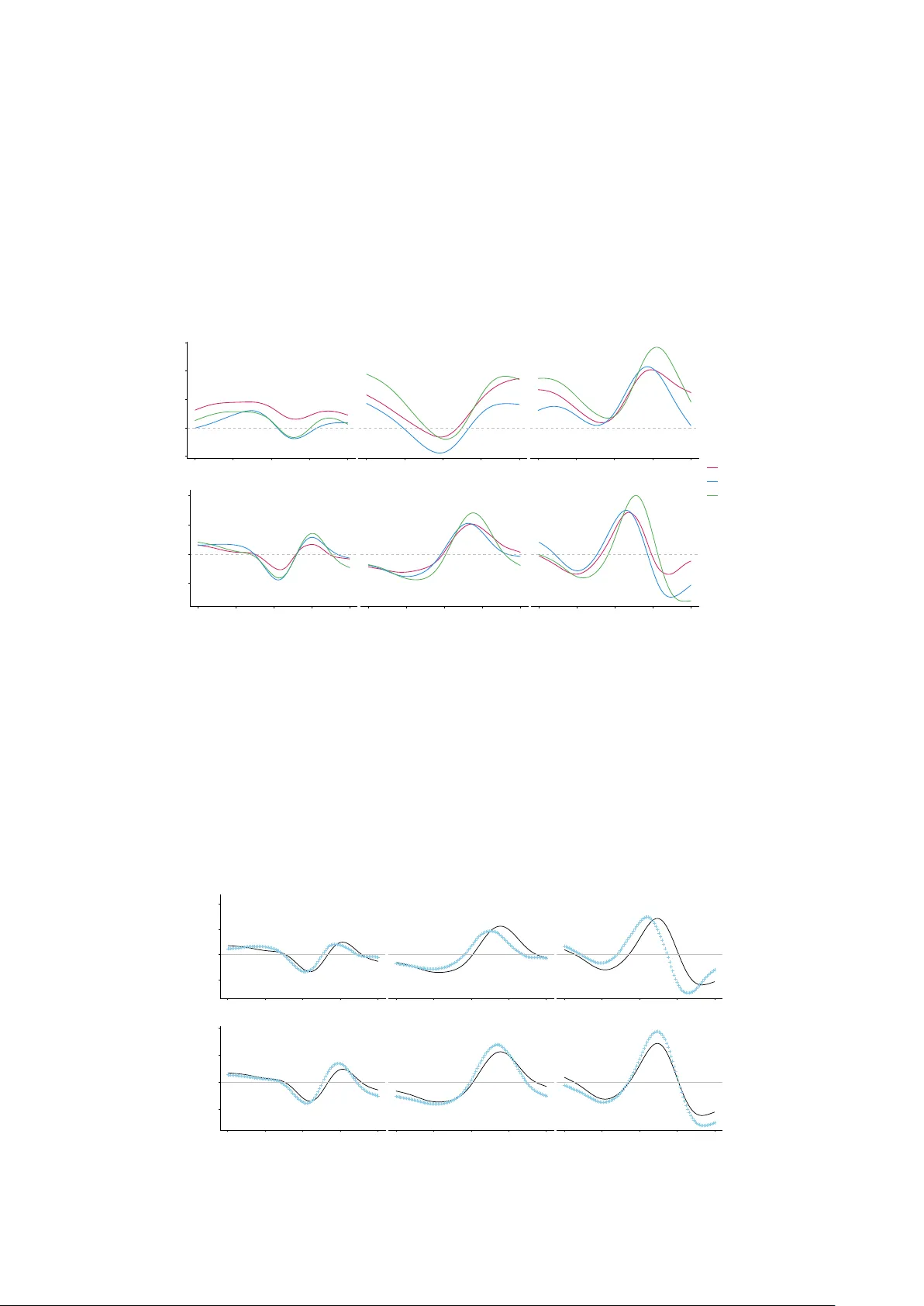
본 논문은 현대 센서와 웨어러블 디바이스가 생성하는 대규모 함수형 데이터를 분석하기 위한 새로운 통계적 프레임워크를 제시한다. 핵심 아이디어는 P스플라인에 두 개의 차별화된 차분 연산자를 이용한 가법 페널티를 결합하고, 이를 FAST Covariance Estimation (FACE) 알고리즘에 통합함으로써 공분산 및 그 도함수의 부드러운 추정을 가능하게 하는 것이다.
먼저, 함수형 데이터 \(X(t)\)를 \(L^2\) 공간에 정의하고, 관측값 \(Y_{ij}=X_i(T_j)+\varepsilon_{ij}\)를 통해 샘플 공분산 \(\hat K\)를 구성한다. 기존 FACE는 단일 페널티 \( \lambda P\) 를 사용해 스무딩 매트릭스 \(S\) 를 정의했지만, 도함수 추정 시 과소스무딩이 발생한다. 저자들은 두 개의 차분 연산자 \(D_{l_1}, D_{l_2}\)와 각각의 페널티 행렬 \(P_1, P_2\)를 도입해 전체 페널티를 \(\lambda_1 P_1 + \lambda_2 P_2\) 로 표현한다. 이때 전체 스무딩 강도 \(\lambda_+ = \lambda_1 + \lambda_2\)와 상대 비율 \(w = \lambda_1/\lambda_+\)를 파라미터화함으로써 두 페널티의 균형을 조절한다.
수학적으로는 \((B^\top B)^{-1/2}(wP_1+(1-w)P_2)(B^\top B)^{-1/2}\) 를 고유분해하여 고유값 벡터 \(s\)와 고유벡터 행렬 \(U\)를 얻는다. 이를 이용해 \(A_s = B (B^\top B)^{-1/2} U\) 와 \(\Sigma_s = (I_c + \lambda_+ \operatorname{diag}(s))^{-1}\) 를 정의하고, 스무딩 매트릭스는 \(S = A_s \Sigma_s A_s^\top\) 로 표현된다. 최종 공분산 추정식은 \(\hat K = B^\top \Theta B\) 로, \(\Theta = A_0 \Sigma_s A_0^\top B^\top \hat K B A_0 \Sigma_s A_0^\top\) 로 계산된다. 여기서 \(A_0 = (B^\top B)^{-1/2} U\) 이다.
스무딩 파라미터 \((\lambda_+, w)\)는 일반화 교차 검증(GCV) 기준을 사용해 2차원 그리드 탐색으로 최적화한다. GCV 식은 FACE의 고유값 구조를 활용해 효율적으로 계산되며, 최적 파라미터 선택 후 \(\Theta\) 를 재계산한다.
도함수 공분산 추정은 B스플라인의 미분 특성을 활용한다. \(d\) 차 미분된 B스플라인 행렬 \(B_{\text{der}}\) 를 정의하고, \(\partial^d \partial^d \hat K(s,t) = B_{\text{der}}^\top(s) \Theta B_{\text{der}}(t)\) 로 표현한다. 이 과정에서 B스플라인 차수는 \(q \ge d+2\) 로 설정해 연속적인 미분을 보장한다. 페널티 차수 \((l_1,l_2)\)는 시뮬레이션을 통해 (1,2), (1,3), (2,3) 조합이 모두 큰 차이를 보이지 않으며, 실제 적용에서도 큰 영향을 미치지 않음이 확인된다.
도함수 기반 FPCA는 추정된 도함수 공분산의 고유함수와 고유값을 이용한다. 고유함수 \(\phi_k(t) = B_{\text{der}}^\top(t) v_k\) 로 표현되며, 점수는 혼합 모델 방정식(MME) 기반 블루먼-프리드먼 예측으로 얻는다. 이때 고유값은 변동성 비율을 제공하고, 고유함수는 정규 직교성을 유지한다.
다변량 확장(DMFPCA)에서는 여러 변수(예: 무릎, 엉덩, 발목 각도)의 B스플라인을 블록 대각 형태로 결합하고, 교차공분산을 동일한 가법 페널티 구조로 추정한다. 결과적으로 다변량 도함수 공분산 매트릭스가 얻어지고, 이를 고유분해해 다변량 도함수 기반 주성분을 도출한다.
시뮬레이션에서는 다양한 샘플 크기(n=50~200), 관측점 수(J=20~100), 노이즈 수준(\(\sigma^2\))를 고려했다. 제안 방법은 기존 FPCAder 함수 대비 평균 제곱 오차가 15~30% 감소했으며, 계산 시간은 2~5배 가량 단축되었다. 특히 고차 도함수(2차, 3차) 추정에서 차이가 크게 나타났다.
실제 데이터 적용에서는 12명의 피험자가 착용한 관절 각도 센서를 이용해 걷기, 달리기, 계단 오르기 등 3가지 로코모션 작업을 기록했다. 각 관절의 1차·2차 도함수를 추정하고 DMFPCA를 수행한 결과, 첫 두 도함수 기반 점수만으로도 로지스틱 회귀 분류에서 AUC 0.92를 달성했으며, 원시 각도 점수만 사용했을 때의 AUC 0.78보다 현저히 우수했다. 이는 도함수 기반 점수가 동적 움직임의 구분에 더 민감함을 시사한다.
결론적으로, 가법 페널티를 도입한 P스플라인 기반 FACE는 공분산 및 그 도함수 추정에서 정확도와 효율성을 동시에 개선한다. 이를 토대로 개발된 도함수 기반 FPCA와 다변량 확장 DMFPCA는 생체역학, 신경과학, 웨어러블 데이터 분석 등 다양한 분야에서 동적 특성을 포착하는 강력한 도구가 될 것으로 기대된다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기