Enabling Low-Latency Machine learning on Radiation-Hard FPGAs with hls4ml
This paper presents the first demonstration of a viable, ultra-fast, radiation-hard machine learning (ML) application on FPGAs, which could be used in future high-energy physics experiments. We present a three-fold contribution, with the PicoCal calo…
Authors: Katya Govorkova, Julian Garcia Pardinas, Vladimir Loncar
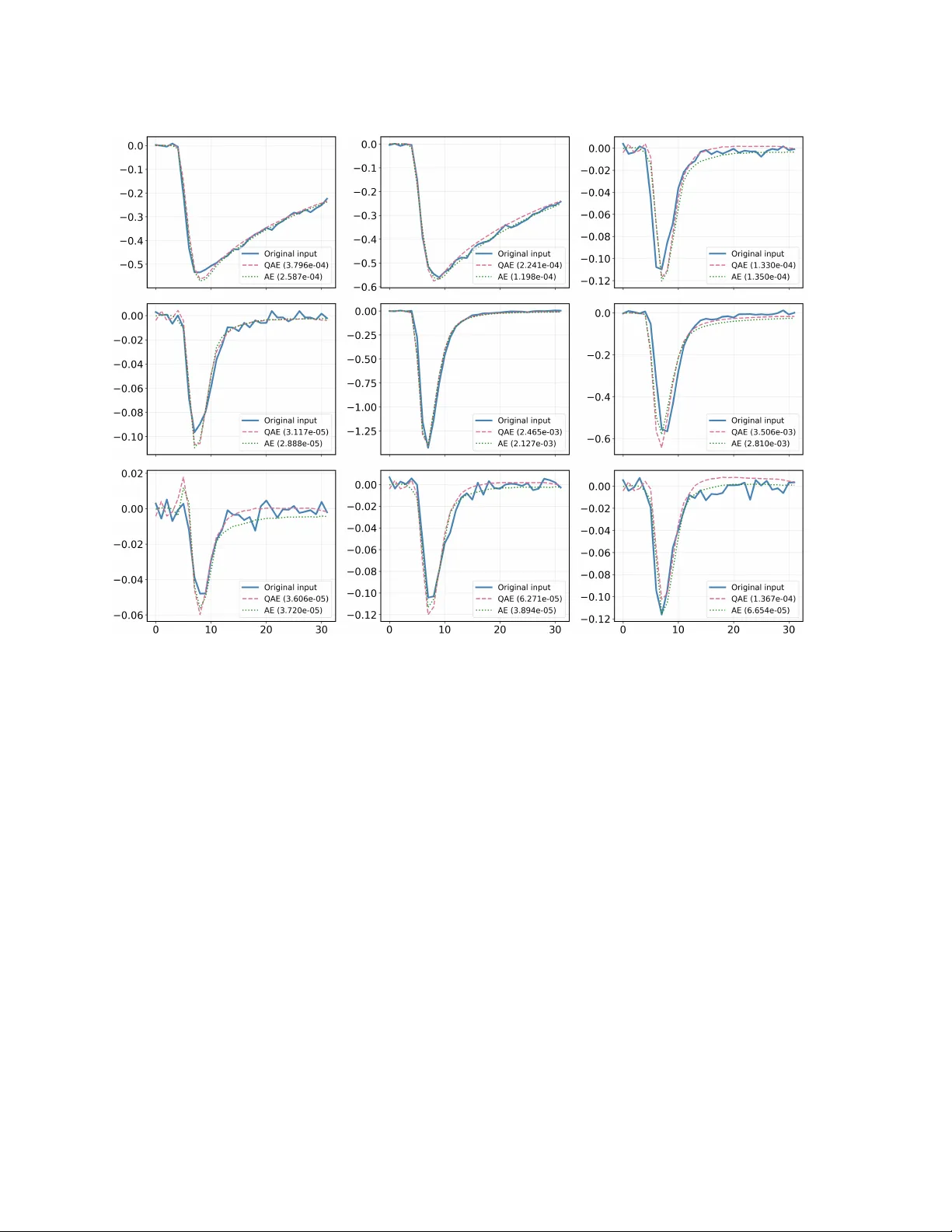
Enabling Lo w-Latency Mac hine learning on Radiation-Hard FPGAs with hls4ml Kat ya Go vork o v a Massac h usetts Institute of T ec hnology (MIT), 77 Massac h usetts Av e, Cam bridge, MA 02139, USA E-mail: ekaterina.govorkova@cern.ch Juli´ an Garc ´ ıa Pardi˜ nas Massac h usetts Institute of T ec hnology (MIT), 77 Massac h usetts Av e, Cam bridge, MA 02139, USA E-mail: julian.garcia.pardinas@cern.ch Vladimir Lonˇ car Departmen t of Exp erimen tal Physics, European Organization for Nuclear Research (CERN), 1211 Genev a 23, Switzerland E-mail: vladimir.loncar@cern.ch Victoria Nguyen Massac h usetts Institute of T ec hnology (MIT), 77 Massac h usetts Av e, Cam bridge, MA 02139, USA E-mail: vkn@mit.edu Sebastian Schmitt Massac h usetts Institute of T ec hnology (MIT), 77 Massac h usetts Av e, Cam bridge, MA 02139, USA E-mail: s.schmitt@cern.ch Marco Pizzichemi Univ ersit y of Milano-Bico cca (Italy), and Departmen t of Exp erimen tal Physics, European Organization for Nuclear Research (CERN), 1211 Genev a 23, Switzerland Loris Martinazzoli Departmen t of Exp erimen tal Physics, European Organization for Nuclear Research (CERN), 1211 Genev a 23, Switzerland E-mail: loris.martinazzoli@cern.ch R adiation-Har d L ow-L atency ML on FPGAs 2 Eluned Anne Smith Massac h usetts Institute of T ec hnology (MIT), 77 Massac h usetts Av e, Cam bridge, MA 02139, USA E-mail: eluned@mit.edu Abstract. This pap er presen ts the first demonstration of a viable, ultra-fast, radiation-hard mac hine learning (ML) application on FPGAs, whic h could b e used in future high- energy physics exp eriments. W e presen t a three-fold contribution, with the PicoCal calorimeter, planned for the LHCb Upgrade I I exp erimen t, used as a test case. First, we dev elop a light weigh t auto enco der to compress a 32-sample timing readout, represen tativ e of that of the PicoCal, into a tw o-dimensional latent space. Second, w e in tro duce a systematic, hardware-a ware quan tization strategy and sho w that the mo del can b e reduced to 10-bit w eigh ts with minimal p erformance loss. Third, as a barrier to the adoption of on-detector ML is the lack of supp ort for radiation-hard FPGAs in the High-Energy Physics communit y’s standard ML synthesis to ol, hls4ml , w e develop a new back end for this library . This new back-end enables the automatic translation of ML mo dels in to High-Level Syn thesis (HLS) pro jects for the Micro c hip P olarFire family of FPGAs, one of the few commercially av ailable and radiation hard FPGAs. W e present the synthesis of the autoenco der on a target PolarFire FPGA, whic h indicates that a latency of 25 ns can b e achiev ed. W e show that the resources utilized are lo w enough that the mo del can b e placed within the inherently protected logic of the FPGA. Our extension to hls4ml is a significant con tribution, paving the w a y for broader adoption of ML on FPGAs in high-radiation environmen ts. Keyw ords: Mac hine Learning, FPGA, Radiation Hardness, High-Energy Physics, hls4ml, LHCb, P olarFire, SmartHLS, Autoenco der, Data Compression 1. In tro duction The pursuit of new ph ysics at the fron tiers of energy and intensit y requires constant inno v ation in detector tec hnology and real-time data pro cessing. The up coming High- Luminosit y Large Hadron Collider (HL-LHC) era is set to deliver an unpreceden ted v olume of data [ 1 ]. This increase in discov ery p otential is accompanied by formidable c hallenges, most notably a massiv e increase in data rates and a higher n umber of sim ultaneous proton-proton collisions (pile-up). T o handle this growing volume of data, exp erimen ts are increasingly forced to deplo y p o werful computational solutions as close to the detectors as p ossible. This ”edge computing” strategy minimizes data transmission latency and bandwidth but necessitates that compression b e p erformed on electronics in harsh radiation environmen ts [ 2 ]. Consequen tly , there is a pressing need for ultra-fast, lo w-latency , and radiation-hard mac hine learning (ML) applications that can in telligently filter and compress data at the extreme edge of the readout c hain. The Large Hadron Collider b eaut y (LHCb) experiment’s Upgrade I I, planned to tak e place during the fourth Long Shutdo wn of the LHC, pro vides a comp elling and concrete example of this challenge [ 3 ]. This upgrade is designed to op erate at a R adiation-Har d L ow-L atency ML on FPGAs 3 significan tly higher instantaneous luminosit y than b efore of up to 1 . 5 × 10 34 cm − 2 s − 1 , whic h will increase the av erage pile-up to approximately 40. This higher collision rate, com bined with the inheren tly large pro duction cross-sections for the b eauty and c harm hadrons that LHCb targets, will generate an unpreceden ted data rate of 200 Tb/s, a v olume that necessitates significant detector enhancements. An example of such a detector enhancemen t is the planned, high-granularit y electromagnetic calorimeter with excellen t timing capabilities, kno wn as the PicoCal [ 4 ]. T o achiev e its target time resolution of 10 − 20 ps, the SPIDER [ 5 ], a w av eform digitizer ASIC, will digitize the pulse shap e from eac h calorimeter read-out c hannel. This pulse shap e represen ts the time ev olution of the voltage induced b y the cascade of electrons pro duced within a photom ultiplier tub e (PMTs) [ 4 ] in resp onse to scintillation photons generated b y an electromagnetic sho wer in the calorimeter. While the final num b er of samples is yet to b e determined, with current estimates ranging from 8 to 32, this study assumes the pulse shap e is represen ted b y 32 16-bit n umbers. The sampling in terv al is chosen suc h that the pulse rise time, defined as the time b etw een the p oin ts where the pulse reaches 10% and 90% of its maxim um amplitude, is captured b y approximately four to fiv e sampling p oints. This granularit y is assumed to very roughly represent that exp ected of the LHCb PicoCal readout. How ev er, it should b e stressed that the p erformance of the mac hine-learning–based compression algorithms, which is the focus of this paper, should not depend critically on the precise granularit y of the readout. It is estimated that in order to ha ve tenable data-rates b et ween the on-detector fron t-end electronics and the back end electronics, the initial sample of 32 inputs m ust be compressed in to a maximum of t wo n umbers of a similar bit size on the detector. This work aims to ac hieve this compression ratio whilst still main taining as m uc h information ab out the pulse as p ossible. The hardware platform c hosen for this design study is the Microchip P olarFire FPGA, a device selected for its inherent radiation tolerance. The tec hnical motiv ations for this c hoice, which relate to its flash-based architecture as a sup erior alternativ e to traditional SRAM-based FPGAs requiring T riple Mo dular Redundancy (TMR), are detailed in Section 2.3. In high-energy ph ysics, a common alternative to FPGAs is a custom Application- Sp ecific In tegrated Circuit (ASIC). How ever, the inflexible, m ulti-y ear dev elopment cycle and high non-recurring engineering costs mean ASICs are typically only used when extreme p erformance or p ow er constraints cannot b e met b y programmable hardware. This work also serv es to demonstrate that FPGAs can represent a viable alternative to ASICs for ML algorithms that m ust satisfy b oth demanding real-time requirements and run on-detector, in high-radiation environmen ts. A t the outset of this w ork, t wo key comp onen ts for tac kling the PicoCal data compression challenge were missing. First, no specific ML algorithm had b een dev elop ed and v alidated for compression of the full pulse shap e. Second, the high-lev el syn thesis for mac hine learning ( hls4ml ) to olc hain, a comm unity standard for deploying ML mo dels on FPGAs, lack ed supp ort for radiation-hard Micro c hip devices [ 6 ]. This pap er addresses these gaps with a three-fold con tribution: R adiation-Har d L ow-L atency ML on FPGAs 4 (i) An ML Algorithm for Pulse Compression: W e develop and v alidate a ligh tw eight auto enco der model designed sp ecifically for the LHCb PicoCal use case. W e demonstrate through simulation that this mo del can effectiv ely compress the 32-sample pulse shap es in to a compact t w o-dimensional laten t space, preserving the information required for downstream physics reconstruction. (ii) Hardw are-Aware Mo del Compression: W e conduct a systematic study of mo del quantization, demonstrating a metho dology to drastically reduce the mo del’s computational complexit y while preserving ph ysics reconstruction performance. (iii) A New Bac k end for hls4ml : W e develop a new softw are bac kend for the hls4ml library to supp ort the Micro c hip SmartHLS compiler ‡ [ 7 ]. This critical infrastructure w ork enables, for the first time, the automated deploymen t of ML mo dels on to radiation-hard Polar Fire FPGAs, opening the door for the wider high- energy physics comm unity to lev erage these devices for on-detector ML applications. The result is the first end-to-end demonstration of a viable, ultra-fast ML application on a radiation-hard FPGA for a future high-energy physics exp erimen t, a milestone enabled b y the new automated design flow also dev elop ed as part of this w ork. F or this design study , k ey performance and arc hitectural parameters were established based on preliminary discussions with exp erts inv olv ed in the LHCb Upgrade I I electronics design. A baseline scenario assumes that each fron t-end FPGA will need to pro cess data from 8 indep enden t calorimeter channels in parallel. F urthermore, while the LHC bunc h crossing rate is 40 MHz, a target for the FPGA’s in ternal pro cessing clo c k of 160 MHz is considered a realistic b enc hmark. This c hoice allo ws for exactly four in ternal clo c k cycles to process eac h new input, setting a strict latency and throughput requiremen t for the compression algorithm. This pap er is structured as follo ws. W e first review related w ork in ML-based data compression and FPGA deploymen t to olchains in Section 2. In Section 3, we describ e the architecture of our auto enco der model and demonstrate its abilit y to compress and faithfully reconstruct pulse shap es while preserving k ey physics information. Section 4 details the hardware-a w are quantization study p erformed to optimize the mo del for hardw are implementation. In Section 5, w e presen t the dev elopmen t of the new hls4ml bac kend and the final synthesis results on the target P olarFire FPGA, sho wing that the design meets the application’s strict p erformance requiremen ts. Finally , w e discuss the broader implications of these results in Section 6 and presen t our conclusions in Section 7. 2. Related W ork This w ork builds up on established techniques in tw o distinct domains: the use of auto enco ders for data pro cessing in high-energy ph ysics and the deploymen t of mac hine ‡ Micro c hip SmartHLS T o ol Suite, V ersion 2021.2, Micro c hip T echnology Inc., Chandler, AZ, USA. R adiation-Har d L ow-L atency ML on FPGAs 5 learning mo dels on FPGAs using high-lev el synthesis to ols. This section reviews the state-of-the-art in both areas to con textualize our con tributions. 2.1. Data Compr ession and Anomaly Dete ction with Auto enc o ders The immense data volume at the LHC has driv en the widespread exploration of mac hine learning for real-time data reduction and analysis [ 8 ]. Auto enco ders, as a class of unsup ervised neural net works, ha ve pro v en to be particularly effectiv e. They are trained to learn a compressed, lo w-dimensional represen tation (laten t space) of high-dimensional data by reconstructing their own input, forcing the mo del to capture the most salien t features of the data distribution. In high-energy ph ysics, this technique has b een successfully applied to a range of problems. These include the compression of jet substructure information for trigger systems and offline storage, as w ell as mo del-agnostic anomaly detection, where even ts that are p o orly reconstructed from the latent space are flagged as p otential new physics [ 9 ]. Other studies ha ve explored the ph ysical meaning of the laten t space itself, demonstrating that its learned v ariables can b e correlated with underlying physical pro cesses, forming a p ow erful feature space for analysis [ 10 ]. Our w ork applies this paradigm to a no vel and challenging use case: the on-detector, ultra-low-latency compression of full calorimeter pulse shapes, where preserving timing information is critical and preserving other pulse-shap e information, suc h as the rise-time, is desirable. 2.2. ML-to-FPGA T o olchains and R adiation-Har d Har dwar e F or ML mo dels to b e deploy ed at the detector fron t-end, they m ust meet stringen t real-time processing constraints, with latencies typically ranging from nanoseconds to a few microseconds [ 6 ]. FPGAs are an ideal hardw are platform for this task, enabling massiv ely parallel and deeply pip elined implemen tations that eliminate external memory b ottlenec ks. The high-energy physics comm unity has largely standardized on the hls4ml library for translating ML mo dels from framew orks lik e T ensorFlo w/Keras into FPGA firm ware. It has b een successfully used to deplo y a v ariety of mo dels, from dense neural net works to recurrent net works, with latencies on the order of h undreds of nanoseconds. While commercial to olc hains lik e Xilinx Vitis AI and In tel Op enVINO offer p ow erful solutions for deploying ML mo dels on FPGAs, they are often tailored to sp ecific vendor arc hitectures and target a more general pro cessing st yle with data and mo del residing in off-c hip memory . In con trast, hls4ml real-time pro cessing with mo dels deplo y ed fully on-c hip is particularly well-suited to the needs of the scien tific comm unity , enabling fine-grained control ov er the hardw are implemen tation and facilitating the integration of new bac kends, as demonstrated in this w ork. F urthermore, such automated w orkflo ws are crucial for enabling rapid design space exploration, suc h as systematically v arying mo del quantization, which would b e significantly time-consuming with a purely manual HLS implemen tation. R adiation-Har d L ow-L atency ML on FPGAs 6 Ho wev er, hls4ml has historically supported HLS compilers exclusively for commercial FPGAs from Xilinx (now AMD) and Intel, which are t ypically SRAM- based . At the outset of this pro ject, the lack of a streamlined, high-level to olchain for deplo ying ML mo dels onto the radiation-hard, flash-based Micro c hip devices considered for this w ork w as a primary barrier to their adoption . This w ork closes that gap by dev eloping and v alidating the first hls4ml back end for this class of FPGAs, providing an automated and open-source path from a high-level ML mo del to a hardw are implemen tation on a radiation-hard platform. 2.3. R adiation Har dness Par adigms in FPGAs Deplo ying electronics in the LHC’s radiation en vironment necessitates robust mitigation against Single Even t Effects (SEEs), whic h can disrupt circuit op eration. F or FPGAs, the mitigation strategy is in trinsically link ed to the underlying technology of the configuration memory . SRAM-based FPGAs, the most common commercial option, store their logic configuration in static RAM cells susceptible to SEUs, where a c harged particle can corrupt the device’s logic function. The standard mitigation technique is T riple Modular Redundancy (TMR), where logic is triplicated and a v oter system corrects an y single fault [ 11 ]. While effectiv e, TMR imp oses a significan t o verhead of at least 3x in logic resources, increased pow er consumption, and considerable design complexit y . In con trast, flash-based FPGAs, suc h as the Micro c hip PolarFire family used in this work, offer an alternative paradigm. Their configuration is stored in non- v olatile flash memory cells, whic h are inherently imm une to these configuration SEUs. This “radiation-hardened-b y-design” approac h a voids the need for configuration TMR, offering a path to reliable systems with significantly low er complexit y and resource utilization. This fundamen tal difference was a k ey motiv ator for the hardware c hoice in this design study . The in terpla y b etw een algorithm design, mitigation techniques, and the inheren t robustness of the hardware is explored further in Section 6. 3. Auto enco der Arc hitecture and Co-Design Rationale W e aim to dev elop a ligh t w eight auto enco der that ac hiev es a high compression ratio while preserving the full pulse-shap e information. Although extracting a single timestamp from the pulse shap e is the most critical piece of information, retaining the full shap e is highly desirable, as it provides additional insight in to sho wer formation in the calorimeter and can help further mitigate pile-up effects. The follo wing subsections detail the auto enco der’s sp ecific arc hitecture, its training, and its p erformance against k ey ph ysics metrics. The algorithm p erformance presented in this section corresponds to results obtained after quan tization-aw are training, which motiv ated the choice to represen t the laten t space using t w o 10-bit v alues. The pro cedure used to implement and optimize this quantization-a w are training is describ ed in Section 4. R adiation-Har d L ow-L atency ML on FPGAs 7 3.1. Mo del A r chite ctur e and Co-Design R ationale The auto enco der’s arc hitecture w as co-designed with its hardw are implemen tation in mind, prioritizing a minimal fo otprint and the low est p ossible latency . The hardw are- implemen ted p ortion is the enco der, whic h p erforms the on-detector data compression. It consists of tw o sequen tial lay ers: • A fully-connected dense lay er that maps the 32 input data p oints directly to the t wo-dimensional latent space. • A Rectified Linear Unit (ReLU) activ ation function is applied to the t w o laten t space v ariables. This inv olv ed directing the HLS compiler to create a highly parallel, pip elined arc hitecture, relying on partially or fully unrolled lo ops, av oiding an y resource sharing that w ould increase the processing time. This ensures that an inference can be completed in the minimum num b er of clo ck cycles, a critical requiremen t for the front- end application. F or completeness, the deco der half of the auto encoder, used during training to reconstruct the pulse shap e from the latent space, is constructed as a mirror of the enco der. It consists of a single fully-connected dense la yer that maps the t w o latent space v ariables back to the 32-dimensional space of the output pulse shap e. A linear activ ation function is used for this final lay er to allow the output v alues to span the full, unconstrained range of the digitized pulse samples. 3.2. Simulation Dataset The dataset used for training and ev aluation consists of pulse shap es generated from a dedicated Mon te Carlo sim ulation of the LHCb PicoCal electromagnetic calorimeter protot yp e [ 12 ], implemen ted using the Gean t4 toolkit [ 13 ]. The simulation accurately mo dels the detector geometry , material prop erties, and readout electronics to repro duce realistic signal responses under exp ected Run 5 conditions. Tw o t yp es of samples were prepared and then merged to mimic realistic detector conditions. Signal pulses corresp ond to the resp onses of SpaCal mo dules with a Pb absorb er [ 12 ] to a single photon generated with energies uniformly distributed b et ween 0 . 5 < E T < 5 GeV , close to the proton-proton interaction p oin t. Those are merged with background pulses, which w ere generated separately to represen t pile-up and underlying even t conditions. These were sim ulated assuming a fixed luminosit y of 1 . 5 × 10 34 cm − 2 s − 1 [ 12 ]. After generation, signal and background pulses were combined to em ulate the complex conditions exp ected in LHCb Run 5 data-taking. Eac h pulse was simulated with 1024 consecutive data p oin ts, reflecting the output of the DRS4-based V1742 CAEN digitizer (5 Gs/s, 500 MHz bandwidth) [ 14 ] used in the test b eam setup. In the actual calorimeter, how ev er, a different digitizer will b e emplo y ed, providing only 32 samples p er pulse. T o matc h this configuration, we do wnsample the simulated wa v eforms from 1024 to 32 data p oints, with the rise-time R adiation-Har d L ow-L atency ML on FPGAs 8 of a t ypical pulse shape represented by around 1-3 sampling in terv als. This is ac hieved b y taking ev ery 9 samples starting at the 380th to 668 out of 1024. 3.3. T r aining W e implemented fully connected auto enco ders to reconstruct calorimeter pulse shap es represen ted as 32-sample vectors. The implemen tation w as carried out using T ensorFlo w [ 15 ] with the Keras high-lev el API [ 16 ]. W e train a full precision mo del as well as a qunatized mo del for the FPGA implemen tation. The details ab out the quan tization are co vered in Section 4. T raining w as p erformed using the Adam optimizer with a learning rate of 10 − 3 and the Mean Squared Error (MSE) loss function. Mo dels were trained for up to 20 ep o c hs with an early stopping criterion (patience of 5 ep o c hs) based on v alidation loss to prev ent o v erfitting. A batc h size of 32 was applied during all experiments. The dataset of 353513 calorimeter pulses was split in to 70% training, 15% v alidation, and 15% test sets using a fixed random seed to ensure repro ducibilit y . W e used the ”k eras tuner” [ 16 ] random searc h to select the b est learning rate and b est mo del architecture by minimizing the MSE loss together with the n um b er of FLOPS (num b er of floating p oin t op erations p er second). Since our input size was 32, w e searched ov er the space of 15 combinations of keeping/dropping lay ers corresp onding to sizes of 16, 8, 4, and 2 while maintaining that w e alw a ys had at least one lay er in the middle. W e con v erged on a 32-2 structure, as the MSE loss w as approximately the same, and this w as the smallest mo del with the smallest n umber of flops. Before tuning the architecture, we tested using different activ ation functions (relu, elu, tanh), from whic h the relu activ ation function was found to b e most p erformant. W e additionally tested using different loss functions (Mean Squared Error, Mean Absolute Error, Hub er, and Logcosh), but found no difference in p erformance. The training pro cess w as monitored using b oth training and v alidation loss, as sho wn in Figure 1. The fact that the v alidation loss falls b elow the training loss is purely a statistical fluctuation, determined b y the random seed used in partitioning the training and v alidation datasets. The best-p erforming weigh ts, determined by the minim um v alidation loss, w ere restored at the end of training. After training, mo dels w ere ev aluated on the held-out test set using the MSE metric. 3.4. Pulse Shap e R e c onstruction Performanc e The p erformance of the trained auto enco der was initially assessed b y visually comparing original input pulse shap es with their reconstructed counterparts and by ev aluating the MSE on the test set. Figure 2 presen ts several represen tative examples where the original w av eforms (solid lines) are o v erlaid with reconstructions (dashed lines) obtained after compression into the 2-dimensional laten t space. The green line shows the reconstruction using 32-bit precision for the laten t space v ariables, and the pink line using 10-bit precision, as discussed in Sec. 4. R adiation-Har d L ow-L atency ML on FPGAs 9 Figure 1. T raining and v alidation loss curv es for the full-precision auto enco der (in green) and the quantized auto enco der (in pink), discussed fully in Sec. 4. The y-axis uses a logarithmic scale to emphasize con v ergence b eha vior. The close visual alignment b et w een the original and reconstructed signals across a wide range of amplitudes confirms that the autoenco der effectiv ely preserv es both global and fine-grained features of the calorimeter resp onse. This observ ation is consistent with the lo w av erage MSE v alues measured on the v alidation and test sets, demonstrating that the model ac hieves high-fidelity reconstruction even for challenging cases such as pulses with significan t noise or extended tails. 3.5. L atent Sp ac e Analysis T o assess the in terpretability of the learned laten t space, w e analyzed its correlation with k ey ph ysical properties of the pulse shapes: true timestamp (time of arriv al of the sim ulated particle to the PicoCal), p e ak amplitude and rising time , where the latter pro vides a shap e-sensitiv e indicator of the signal developmen t. Figure 3 summarizes the Pearson and Sp earman correlation co efficien ts b et ween the t wo latent v ariables ( z 0 , z 1 ) and these physical quantities. The results rev eal a clear structure in the latent space. The second dimension ( z 1 ) sho ws an almost perfect p ositiv e correlation with the p e ak amplitude (Pearson = 0 . 979, Sp earman = 0 . 977), indicating that this axis primarily encodes amplitude-related information. The first latent v ariable ( z 0 ) also correlates with amplitude (Pearson = 0 . 925), suggesting it captures secondary shap e-dep enden t features. Both laten t v ariables exhibit mo dest negativ e correlations with the true timestamp (P earson ≈ − 0 . 11 to − 0 . 16) and the rising time (Pearson up to − 0 . 17), with stronger monotonic relationships indicated by the Sp earman co efficien ts for z 0 ( − 0 . 703) and z 1 ( − 0 . 012). This suggests that timing and shape information are partially disen tangled in the laten t represen tation, although less strongly than amplitude. Ov erall, these findings indicate that the autoenco der do es not op erate as a “blac k b o x” but rather organizes the tw o-dimensional latent space with one dimension dominated b y amplitude information, and another influenced b y shap e and timing R adiation-Har d L ow-L atency ML on FPGAs 10 Figure 2. Examples of autoenco der reconstruction p erformance on calorimeter pulse shap es from the test set. Original wa veforms (solid blue lines) are compared with their corresp onding reconstructions (dashed lines). In green is the full precision model, and in pink is the quantized mo del, discussed in Sec. 4. Visual agreement is supp orted b y lo w MSE v alues across div erse pulse amplitudes, highligh ting the robustness of the reconstruction. v ariations. This in terpretable structure increases confidence that the compression preserv es the essen tial ph ysics characteristics necessary for downstream tasks suc h as time reconstruction. 3.6. V alidation of Timestamp and R ise-time R e c onstruction Time reconstruction, expressed as a timestamp, refers to determining the precise arriv al time of a signal from the pulse shape it generates in the PMT. This is typically done using algorithms suc h as the Constan t F raction Discrimination (CFD) [ 17 ]. Preserving this information after compression is crucial, as it underpins the abilit y to correctly group cells originating from the same incoming particle in the high pile-up en vironment of LHCb Upgrade I I, and to asso ciate the particle with the correct proton–proton in teraction [ 12 ]. As further v alidation of our auto enco der, w e therefore wish to apply the standard CFD timing algorithm to b oth the original and the auto enco der-reconstructed pulses R adiation-Har d L ow-L atency ML on FPGAs 11 Figure 3. Correlation betw een laten t space v ariables of the full-precision autoenco der and three pulse-lev el features on the test set: rise time (10%–90% interv al), pulse true timestamp, and p eak amplitude. Each row corresp onds to one laten t dimension ( z [0] , z [1]), and each column to one feature. Scatter plots include Pearson’s r and Sp earman’s ρ coefficients in the titles. The latent representation is strongly correlated with p eak amplitude, while correlations with timing features (rise time and cell time) are weak er. from the held-out test set, and compare b oth with the true timestamp. While injecting the underlying ev ent into the baseline simulation produces a more realistic readout scenario, it obscures the true arriv al time of a pulse, b ecause it is no longer p ossible to determine whether a giv en pulse shap e originates from an injected signal photon (for which the true time is kno wn) or from other photons in the even t (for whic h it is not). As a result, the timestamp reconstruction is tested on pulses from so- called seed cells only . T o iden tify these, w e p erform a simple clustering of cells, selecting the one with the highest lo cal energy (the seed cell). W e then matc h clusters to the true sim ulated photons. T aking the seed cell from the matc hed cluster ensures that the arriv al time corresponds to the sim ulated photon and not to the underlying even t; therefore, w e can use it to p erform the time-extraction study detailed b elow. Additionally , t wo distinct types of pulses are observ ed due to the geometry of the spaghetti calorimeter (SpaCal), whic h is the detector type in the central region of the PicoCal [ 12 ], comp osed of longitudinal scin tillators in tersected by a mirror along the longitudinal plane. Photons can either b e reflected b y this mirror and read out at the front of the SpaCal (front pulses) or they can originate b ey ond the mirror and b e read out at the bac k of the SpaCal (back pulses). These tw o pulse-types ha ve differen t offsets from the true arriv al time, due to differing distances b etw een the active material and the read-out, and so for the purpose of v alidation, w e restrict the data-set to just one pulse-t yp e (fron t pulses). It should b e stressed, how ev er, that it is still the baseline auto enco der used in the R adiation-Har d L ow-L atency ML on FPGAs 12 v alidation, i.e. trained on b oth pulse-t yp es and quan tized to 10 bits. The CFD algorithm estimates the signal timestamp by finding the p oin t at whic h the pulse crosses a fixed fraction (20%) of its maxim um amplitude after baseline subtraction. The same CFD configuration was adopted for b oth original and autoenco der-reconstructed pulses to ensure a fair comparison. The reconstructed timestamps were then compared against the ground-truth timing, corresponding to the sim ulated time of arriv al of the particle in the calorimeter. T o accoun t for a constant bias in the CFD estimator arising from the difference b et ween the front pulse time of arriv al and the true time, the mean residual obtained on the training sample was subtracted from all test results. This correction serv es purely to remo ve a fixed offset, whic h w ould also b e calibrated for in a real detector implemen tation. The constan t offset w as calculated on the training data for b oth the original and reconstructed pulses. Figure 4 shows the distributions of CFD timing residuals b et ween reconstructed and sim ulated arriv al times. The left panel compares the residuals obtained from the original 32-sample pulses and from the auto enco der-reconstructed pulses using iden tical CFD parameters. After applying the constan t-bias calibration (mean subtraction estimated on the training set), b oth distributions are centred roughly around zero, as exp ected. The key comparison of in terest is the width of the distributions. The reconstructed pulses exhibit a substantially narro w er residual distribution than the original 32-sample pulses, indicating an improv emen t in timing precision of about a factor of tw o. Additionally , the right panel presents the ratio of absolute residuals for the reconstructed pulses ov er the absolute residuals of the original pulse. This quan tifies the even t-b y-even t p erformance gain, which is b etter than t wo (i.e. a ratio less than 0.5) for approximately half of the ev ents. The units for the standard deviation shown in Figure 4 (left) are expressed in sampling in terv als. Assuming the upp er end of the exp ected sampling p erio d for the readout—approximately 200 ps § —this corresp onds to a standard deviation of ab out 30 ps for the reconstructed pulses and 62 ps for the original pulses. How ever, it should be emphasized that the sim ulation used in this study do es not incorp orate the final v ersion of the digitizer, and therefore, the approximate “do wnsampling” p erformed man ually may not fully represent the characteristics of the final digitized output and, therefore, the final exp ected timing-resolution. Ov erall, ho wev er, the results confirm that the autoenco der effectiv ely denoises and restores the temp oral structure of the pulses, and that is smo othing effect actually leads to a far more accurate and stable CFD-based timestamp reconstruction. The histogram in Fig. 5 quan tifies how accurately the reconstructed pulses repro duce the temp oral characteristics of the original wa v eforms by comparing the deviation of their 10–90 % rise times from the ”true” rise-time, whic h is tak en as that found on the original 1024-sample pulses. Similarly to the CFD residuals, the mean bias in the rise-time difference due to downsampling from 1024 to 32 samples § https://indico.cern.ch/event/1502285/contributions/6554431/attachments/3081316/ 5592641/SPIDER_oral_TWEPP2025.pdf R adiation-Har d L ow-L atency ML on FPGAs 13 Figure 4. Residual distributions b etw een CFD-reconstructed timestamps and true sim ulation times for original and auto encoder-reconstructed pulses (left), and the ratio of their absolute v alues (right). Reconstruction systematically reduces the timing residual for approximately half of the ev ents. Figure 5. Histogram of the ratio of absolute differences in 10–90 % rise time: (reconstructed vs. 32-sample original) relative to (32-sample original vs. 1024-sample original). w as subtracted separately for the original and reconstructed pulses using the training dataset before ratio ev aluation. This ensures that the comparison focuses on the relativ e reconstruction precision rather than on the systematic offset in tro duced b y coarser sampling. The auto enco der successfully restores fine temp oral features lost during the 32-sample discretisation, ac hieving rise-time consistency with the full-resolution (1024-sample) reference within a few p ercent and again sho wing a modest increase in p erformance compared to the original 32-sample pulses. 3.7. Timestamp R e gr ession T o v alidate our approach, we inv estigated whether a mo del with the same n umber of la y ers but trained to directly regress the timestamp from the 32-sample pulse (i.e. 32 → 1) could outp erform the autoenco der-based reconstruction follow ed by the CFD ev aluation. In this setup, the net work con tained no activ ation function in the output, R adiation-Har d L ow-L atency ML on FPGAs 14 Figure 6. Timestamp–residual distributions for the timestamps predicted using linear regression. The panel sho ws the histogram of ∆ t = ˆ t − t true ; the legend rep orts the mean µ and standard deviation σ . All v alues are in units of samples. making it equiv alen t to a linear regressor. The model was trained join tly on b oth fron t and bac k pulses, in the same wa y as the baseline auto enco der in this pap er, to ensure a fair comparison. Ho wev er, b etter p erformance is ac hiev able if the model is trained separately . The residuals ( t pred − t true ), sho wn in Fig. 6, were then analyzed. These results indicate that the direct timestamp regression ac hieves a mo dest impro vemen t o v er the default mo del ( σ = 0 . 13 vs σ = 0 . 15). Ho wev er the 32–2 auto enco der also pro vides a compact, denoised pulse representation that can supp ort other reconstruction tasks and aid in iden tifying anomalous signals suc h as pile- up–induced double p eaks. In either case, since this study demonstrates that a 32–2 mo del can be implemented within the av ailable pro cessing logic, reducing it to a 32–1 mo del w ould b e straigh tforward. F uture w ork should determine the lev el of compression that ultimately pro vides the optimal balance b et w een p erformance and efficiency . 4. Hardw are-Aw are Quan tization for Efficient FPGA Inference 4.1. Quantization and Imp act Analysis T o prepare the auto enco der for an efficient hardware implemen tation, the mo del’s inputs, activ ations, and w eights were con verted to fixed-p oint data types. A mixed- precision sc heme w as adopted to optimize hardware resource usage while preserving ph ysics p erformance. The final configuration uses a 16-bit fixed-p oint representation with 6 in teger bits, denoted as < 16 , 6 > , for the mo del’s inputs and lay er activ ations. F or the computational core of the mo del, the dense la y er’s w eights and biases w ere quan tized more aggressiv ely to a 10-bit fixed-p oin t represen tation with 4 integer bits, < 10 , 4 > . This c hoice is supp orted by the quan tization scan sho wn in Figure 7. The reconstruction error (MSE) impro ves significan tly as precision increases from 2 to 8 bits and begins to plateau around 10 bits. Additionally , Figure 7 sho ws the R adiation-Har d L ow-L atency ML on FPGAs 15 histograms of MSE v alues on the test sample for the full-precision and for the quantized mo dels. This confirms that using a 10-bit precision for the w eights provides a reconstruction p erformance nearly identical to that of a full-precision mo del, justifying the aggressive quantization. This hardware-a w are compression drastically reduces the mo del’s complexity with a negligible impact on its abilit y to reconstruct the original pulse shapes. Figure 7. The impact of quan tization on the auto enco der’s reconstruction p erformance (left). The a verage Mean Squared Error (MSE) is ev aluated on the test dataset for differen t fixed-point bit widths. The green dashed line shows the MSE for non-quantized mo del. On the righ t is he distribution of the test MSE for the full precision mo del vs quantized to 10 bits. 5. Enabling ML on Radiation-Hard FPGAs: A New hls4ml Bac kend and Syn thesis Results With an optimized mo del, the final step is to translate it into firmw are for the target FPGA. This required developing new comm unity infrastructure and syn thesizing the design to v erify its p erformance against the strict op erational constraints of the front- end electronics. 5.1. A New Backend for hls4ml : T ar geting Micr o chip SmartHLS The core of our engineering con tribution is the developmen t of a new bac k end for hls4ml that targets the Micro chip SmartHLS compiler. This effort effectively bridges the gap b et ween the HEP ML ecosystem and the target hardware platform. The dev elopment pro cess inv olv ed a systematic translation of the entire compilation flow. T o ensure correctness, the developmen t b egan with a manual C++ implemen tation to establish a functional baseline for the SmartHLS compiler. While this man ual implemen tation w as sufficient for the auto enco der in this study , the primary goal was to create a reusable, automated path for the communit y . The dev elopmen t of the back end required significan t mo difications to b oth the C++ templates and the Python co de-generation R adiation-Har d L ow-L atency ML on FPGAs 16 framew ork. Key steps included: adapting and optimizing the baseline C++ algorithms to use SmartHLS-native libraries and pragmas; expanding the hls4ml Python data t yp e system to map quantized tensors to the new data types used by SmartHLS (e.g., hls::ap fixpt ); writing a new co de-generation engine tailored to SmartHLS in tricacies; and creating the build scripts to integrate the new compiler in to the hls4ml w orkflow. A rigorous v alidation pro cess w as critical to the developmen t, using C- sim ulations to confirm that the output of the new back end was bit-for-bit iden tical to that from established hls4ml flows. T o ensure a robust hardware v erification path, and in co ordination with the vendor’s tec hnical team, a streaming in terface using FIFO buffers w as implemen ted for the top-level mo dule. This design pattern w as adopted on their advice to ensure maximum compatibilit y and to streamline the Softw are/Hardw are co-sim ulation flow with the curren t v ersion of the SmartHLS to olc hain. The culmination of this effort w as the in tegration of these c hanges in to a new, fully- fledged hls4ml back end that smo othly integrates in to the existing Python API. This new back end, which will b e made publicly av ailable, demo cratizes access to this class of radiation-hard FPGAs for the scientific communit y . 5.2. Synthesis and Performanc e on PolarFir e FPGA The quantized mo del w as then pro cessed b y our new hls4ml-SmartHLS bac kend to generate HDL co de. An imp ortan t asp ect of the hardware implemen tation relates to ho w the quantized op erations are mapp ed to the FPGA fabric. The aggressiv e quan tization of the mo del’s weigh ts to a 10-bit fixed-p oin t representation means that the resulting m ultiplications are implemen ted efficiently using the general-purp ose 4- input LUTs (Lo ok-Up T ables) rather than the dedicated 18x18 Math Blo cks. This b eha vior, whic h is consistent with other HLS to ols, mak es the design highly resource- efficien t and underscores the imp ortance of the hardw are-aw are quantization detailed in Section 4. By tailoring the arithmetic precision, the mo del av oids relying on sp ecialized DSP resources, whic h are a limited resource on the FPGA. This co de was subsequen tly syn thesized, placed, and routed considering a target Micro c hip PolarFire MPF100T-F CVG484I device using the Micro c hip Lib ero softw are to obtain the final implementation results. The post-synthesis timing analysis confirms that the design significantly exceeds the requirements, ac hieving a maxim um frequency (Fmax) of 234 MHz, well ab o v e the target of 160 MHz. The p ost-synthesis resource utilization and p erformance metrics are summarized in T able 1. The implementation is remark ably efficient, achieving an inference latency of just 25 ns (4 clo c k cycles at 160 MHz). With an initiation in terv al (I I) of 4 clo c k cycles, the accelerator can pro cess new data ev ery 25 ns, comfortably meeting the 40 MHz data rate requirement of the LHCb fron t-end. The resource fo otprin t is minimal, consuming just 3.1% of the FPGA’s logic (LUTs) and 0.3% of its dedicated math blo c ks. This confirms the solution is not only fast enough for real-time pro cessing but also light w eight enough to b e easily integrated alongside other critical logic on the front-end electronics. R adiation-Har d L ow-L atency ML on FPGAs 17 T able 1. P ost-synthesis resource utilization p er channel and p erformance for the auto encoder mo del on a Micro c hip PolarFire MPF100T-F CVG484I FPGA. P arameter V alue T arget Clo ck F requency 160 MHz (6.25 ns p erio d) Latency 4 clock cycles (25 ns) Initiation In terv al (II) 4 clock cycles Resource Used / Av ailable (Utilization %) 4-input Look-Up T ables 3,385 / 108,600 (3.12%) D-Flip-Flop 1,545 / 108,600 (1.42%) Math Blocks (18x18) 1 / 336 (0.30%) LSRAM 0 / 352 (0%) uSRAM 0 / 1,008 (0%) 6. Discussion The results presen ted in the previous sections demonstrate a complete, end-to-end solution for ML-based on-detector data compression using FPGAs, from algorithm conception to successful hardware implementation, although it should b e stressed the syn thesis results are based on Soft ware/Hardw are co-simulation. Here, w e discuss the implications of these findings, b oth for the immediate LHCb Upgrade I I use case and for the wider communit y seeking to deploy machine learning in harsh en vironments. 6.1. F e asibility for the LHCb Up gr ade II Use Case A primary goal of this work was to in v estigate viable solutions for the PicoCal data bandwidth challenge. It w as demonstrated that compressing the signal to t wo 10-bit n umbers preserves the full pulse shap e. The rising time and peak amplitude could still b e extracted from the compressed pulse, and applying a traditional CFD algorithm to the compressed w a veform even yielded improv ed timestamp resolution compared to the original pulse, due to the smo othing of noise effects. Note that ML-alternatives to the CFD algorithm should b e the sub ject of future w ork. The hardware implemen tation results confirm that our approach is not only viable but highly effectiv e. The auto enco der mo del is extremely ligh t weigh t, consuming a negligible fraction of the PolarFire FPGA’s resources, as shown in T able 1. This is a critical success factor, as it ensures that the data compression blo c k can b e easily in tegrated on to the front-end electronics without in terfering with other necessary functionalities. F urthermore, the ac hieved latency of 25 ns and throughput equiv alen t to the 40 MHz bunc h crossing rate meet the demanding real-time requiremen ts of the LHCb trigger and data acquisition system. The successful syn thesis prov es that a sophisticated ML mo del can p erform a complex task like pulse shap e compression well within the allotted time budget. This pro vides a strong pro of-of-principle for the consideration of this R adiation-Har d L ow-L atency ML on FPGAs 18 implemen tation by the LHCb collab oration for its future upgrade [ 4 ]. A crucial asp ect of this feasibility study is the scalability of the solution to meet the system’s architectural requiremen ts. The resource utilization rep orted in T able 1 corresp onds to a single auto enco der instance for one calorimeter channel. As noted, the baseline design for the PicoCal front-end b oard assumes that each FPGA will pro cess 8 c hannels. Assuming a parallel implementation where eac h c hannel requires a dedicated enco der, the total resource fo otprint w ould scale linearly . This w ould pro ject a total utilization of approximately 25% of the FPGA’s 4-input LUTs (8 × 3 . 10%) and 2.4% of its Math Blo c ks (8 × 0 . 30%). This pro jected usage remains modest and falls comfortably within preliminary resource budgets discussed for this pro cessing task. It leav es a substan tial fraction of the FPGA’s resources a v ailable for other critical functionalities, suc h as data aggregation and control logic. This analysis confirms that the prop osed solution is not only p erforman t for a single channel but also highly scalable to the m ulti-channel requirements of the final system. 6.2. The Br o ader Imp act of the hls4ml-SmartHLS Backend P erhaps the most significant and lasting contribution of this work is the developmen t of the new hls4ml bac kend for Micro c hip’s SmartHLS compiler. By creating this piece of op en-source infrastructure, we hav e remov ed the primary barrier to entry for using radiation-hard PolarFire FPGAs for mac hine learning inference. This to ol makes a new class of radiation-hard devices accessible to the entire high-energy ph ysics comm unity and beyond. This automated approac h provides a significant adv antage o ver a one-off, man ual implemen tation. While the sp ecific auto enco der in this study could hav e b een realized with a man ual HLS design, such a solution w ould lack scalabilit y and reusability . The hls4ml back end, in contrast, emp o wers the communit y to rapidly prototype and deploy a wide v ariet y of mo dels without requiring b esp ok e HLS dev elopment for eac h. This automation w as also k ey to our o wn design pro cess, enabling the systematic hardw are- a ware quan tization scan presented in Section 4, a crucial optimization step that w ould ha ve b een impractical within a man ual design flo w. Exp erimen ts at the HL-LHC, future colliders, or in space-based applications can no w follo w a standard, streamlined w orkflow to deplo y ML mo dels on these robust FPGAs. This accelerates the developmen t cycle and emp o wers domain exp erts who are not necessarily FPGA design sp ecialists to implement p ow erful, on-detector ML solutions. It is imp ortant to note that the bac k end, in its curren t state, supports the sp ecific la yers required for this w ork, namely dense lay ers and ReLU activ ations. The immediate plan is to maintain this functionalit y , providing a robust and stable to ol for similar applications. F uture developmen t will be driven by comm unit y needs, with plans to expand the library of supp orted la yers as new use cases and requirements emerge. The bac kend is publicly a v ailable and is scheduled for in tegration into the main R adiation-Har d L ow-L atency ML on FPGAs 19 library as part of the hls4ml v1.3.0 release. 6.3. R adiation Har dness: A Holistic View A key consideration for any electronics deploy ed in the LHC tunnel is tolerance to radiation-induced errors [ 2 ]. Our hardware implementation rev eals a p ow erful synergy b et ween our ligh t w eight algorithm and the inheren t robustness of the target hardware. The auto enco der mo del is so resource-efficien t (see T able 1) that its core logic can b e ph ysically placed in a radiation-protected region of the FPGA. This lev erages the SEU- imm une nature of the flash-based configuration memory in the P olarFire ® FPGA family and b enefits from the reduced radiation exp osure of this region. Flash-based FPGAs, suc h as the Microchip PolarFire family used in this work, store their configuration in non volatile memory that is inheren tly immune to configuration SEUs, remo ving the need for configuration scrubbing or configuration-level TMR required in SRAM-based FPGAs. Ho wev er, unlike radiation-hardened or space-qualified comp onen ts, the user logic fabric is not nativ ely protected against SEUs affecting the data path. Registers, state machines, logic elemen ts, and embedded memories remain susceptible to radiation- induced upsets. Therefore, mitigation techniques lik e TMR or correction tec hniques may still be required to protect critical functional paths and main tain reliable op eration. In applications where a mo del is to o large for such physical protection, algorithmic mitigation b ecomes essential. A common approach is a full TMR of the mo del, which algorithmically strengthens the design against SEUs at the cost of increased resource consumption. In cases where the resource o verhead of full TMR is prohibitiv e, more gran ular techniques can be applied. F or instance, selectiv e p ersistence approaches, like those enabled by the FKeras framework [ 18 ], can iden tify the most critical fraction of a mo del’s parameters that require triplication, offering a balance betw een robustness and resource usage. Alternativ ely , one could follo w fault-aw are, quan tization-a ware training metho dologies. These adv anced techniques create mo dels that are, by construction, b oth p erforman t and inheren tly resilient to faults, making them radiation-hard with minimal redundancy [ 19 ]. These algorithmic mitigation strategies can further expand the radiation protection offered by the approac h describ ed in this paper should a model’s resource utilization exceed the capacity of the FPGA’s inheren tly protected logic. 6.4. F utur e Dir e ctions: Quantifying Physics Performanc e Gains The results presented in this pap er pro vide a strong pro of-of-principle for the on- detector compression of calorimeter signals. The ultimate v alidation, ho wev er, will b e to quan titatively measure the p erformance gain ac hieved b y using the compressed information in do wnstream ph ysics tasks. A key future study will b e to integrate the tw o-dimensional latent space v ariables in to the clustering algorithms used for reconstructing neutral particles. It is exp ected that the rich pulse shap e information preserved in the laten t space—whic h goes far b ey ond a single timestamp v ariable—will b e crucial for correctly asso ciating energy R adiation-Har d L ow-L atency ML on FPGAs 20 dep ositions with their paren t particle clusters. This is particularly important for mitigating the effects of increased pile-up, where the ability to disen tangle o verlapping signals directly impacts the final energy resolution of the measuremen t. Suc h a quantitativ e analysis was b ey ond the scop e of this design study , primarily b ecause the official clustering algorithms for the LHCb Upgrade I I, which include timing information, are not y et finalized. The developmen t of these future reconstruction algorithms, whic h will b e designed sp ecifically to exploit precision timing information, is a prerequisite for measuring the full physics impact of the compression strategy demonstrated in this work. 7. Conclusion The increasing data rates and harsh radiation environmen ts of future high-energy ph ysics exp eriments necessitate the dev elopment of nov el, on-detector mac hine learning solutions using FPGAs. This pap er presen ts the first end-to-end demonstration of such a system, using the specific data compression c hallenge of the LHCb Upgrade I I PicoCal calorimeter as a testing-ground. W e hav e successfully deliv ered on a three-fold con tribution. First, w e developed a ligh tw eigh t auto enco der that effectively compresses the 32-sample detector pulse shap es in to a compact, t w o-dimensional latent space while preserving the critical information needed for physics reconstruction. Second, w e p erformed a hardw are- a ware optimization of the mo del, using quan tization to create a highly efficien t fixed- p oin t represen tation with a negligible loss in ph ysics p erformance. Third, and most significan tly , we dev elop ed a new back end for the hls4ml library , enabling for the first time the automatic deploymen t of ML mo dels on radiation-hard Micro chip P olarFire FPGAs via the SmartHLS compiler. Our synthesis results for the target P olarFire FPGA confirm that the implemen tation is highly efficient. It ac hieves an inference latency of just 25 ns and a throughput of 40 MHz, meeting the stringent requirements of the LHCb fron t-end system. The design utilizes a minimal fraction of the device’s resources ( ≈ 25–30% of logic and less than 10% of DSPs for 8 channels). This efficiency allo ws the model to reside entirely within the FPGA’s inherently radiation-hard logic fabric, providing a robust solution for this use case without the need for complex mitigation schemes. This work transforms a c hallenging data compression problem in to a demonstrated realit y . The dev elopmen t of the op en-source hls4ml -SmartHLS bac kend, in particular, pro vides a lasting con tribution to the scien tific comm unity , pa ving the w ay for a new w av e of in telligent, radiation-hard detector systems at the fron tiers of science. F uture w ork will fo cus on expanding the bac k end’s la yer supp ort to broaden its applicabilit y for the comm unit y . REFERENCES 21 Ac knowledgemen ts The authors w ould lik e to thank the LHCb collab oration for pro viding the con text and resources for this design study . W e esp ecially thank the Upgrade I I team and the Syracuse LHCb group for providing the sim ulated samples used to train and ev aluate the p erformance of the auto encoder. W e are also grateful for the fruitful discussions with our colleagues within the LHCb data pro cessing team that help ed improv e this work, including F elipe Souza de Almeida, Nuria V alls Can udas, Christophe Beigb eder, Zulal Kiraz, Christina Agap op oulou, Marina Artuso, Matthew Rudolph, Lauren Mac key , P atrick Robbe and Philipp Roloff. W e wish to express our gratitude to the developmen t and supp ort team of Micro chip’s SmartHLS for their v aluable assistance in enhancing the compatibilit y of the hls4ml library with their framew ork. Co de Av ailabilit y The hls4ml bac k end dev elop ed for this w ork is publicly av ailable on GitHub at https: //github.com/fastmachinelearning/hls4ml/pull/1240 . References [1] I. Zurbano F ernandez et al. High-Luminosit y Large Hadron Collider (HL-LHC): T ec hnical design report. 10/2020, 12 2020. [2] Ian Dawson, F F accio, M Moll, and A W eidb erg. Radiation effects in the lhc exp erimen ts: Impact on detector performance and operation. CERN Y el low R ep orts: Mono gr aphs, Geneva: CERN , pages 87–122, 2021. [3] Ro el Aaij et al. Ph ysics case for an LHCb Upgrade I I - Opp ortunities in fla vour ph ysics, and b ey ond, in the HL-LHC era. 8 2018. [4] F ramew ork TDR for the LHCb Upgrade I I: Opp ortunities in flav our ph ysics, and b ey ond, in the HL-LHC era. 2021. [5] Ludo vic Alv ado, Nicolas Arveuf, Edouard Bec hetoille, Guillaume Blanchard, Dominique Breton, Baptiste Joly , Laurent Leterrier, Jihane Maalmi, Sam uel Manen, Herv ´ e Mathez, Christophe Sylvia, Philipp e V allerand, and Richard V andaele. Spider, a wa v eform digitizer asic for picosecond timing in lhcb pico cal, 2025. [6] Ja vier Duarte et al. F ast inference of deep neural netw orks in FPGAs for particle ph ysics. JINST , 13(07):P07027, 2018. [7] F arah F ahim, Benjamin Ha wks, Christian Herwig, James Hirschauer, Sergo Jindariani, Nhan T ran, Luca P Carloni, Giusepp e Di Guglielmo, Philip Harris, Jeffrey Krupa, et al. hls4ml: An op en-source co design w orkflow to emp ow er scien tific lo w-p ow er machine learning devices. arXiv pr eprint arXiv:2103.05579 , 2021. REFERENCES 22 [8] Alexander Radovic, Mik e Williams, David Rousseau, Mic hael Kagan, Daniele Bonacorsi, Alexander Himmel, Adam Aurisano, Kazuhiro T erao, and T aritree W ongjirad. Machine learning at the energy and intensit y frontiers of particle ph ysics. Natur e , 560(7716):41–48, 2018. [9] Marco F arina, Y uic hiro Nak ai, and Da vid Shih. Searc hing for new ph ysics with deep autoenco ders. Phys. R ev. D , 101:075021, Apr 2020. [10] Buhmann, Erik, Diefen bacher, Sascha, Eren, Engin, Gaede, F rank, Kasieczk a, Gregor, Korol, Anatolii, and Kr ¨ uger, Katja. Deco ding photons: Ph ysics in the laten t space of a bib-ae generative netw ork. EPJ Web Conf. , 251:03003, 2021. [11] F Lima Kastensmidt, Luca Sterpone, Luigi Carro, and M Sonza Reorda. On the optimal design of triple mo dular redundancy logic for sram-based fpgas. In Design, A utomation and T est in Eur op e , pages 1290–1295. IEEE, 2005. [12] F ramew ork TDR for the LHCb Upgrade II. T echnical rep ort, CERN, Genev a, 2021. [13] S. Agostinelli et al. Geant4 simulation to olkit. Nucle ar Instruments and Metho ds in Physics R ese ar ch Se ction A: A c c eler ators, Sp e ctr ometers, Dete ctors and Asso ciate d Equipment , 506(3):250–303, 2003. [14] Aleksandar Bordelius. The lhcb pico cal. Nucle ar Instruments and Metho ds in Physics R ese ar ch Se ction A: A c c eler ators, Sp e ctr ometers, Dete ctors and Asso ciate d Equipment , 1079:170608, 2025. [15] Mart ´ ın Abadi et al. T ensorFlo w: Large-scale machine learning on heterogeneous systems, 2015. Soft ware av ailable from tensorflo w.org. [16] F ran¸ cois Chollet et al. Keras. https://keras.io , 2015. [17] D.A. Gedc k e and W.J. McDonald. A constant fraction of pulse height trigger for optim um time resolution. Nucle ar Instruments and Metho ds , 55:377–380, 1967. [18] Olivia W eng, Andres Meza, Quinlan Bo c k, Benjamin Ha wks, Ja vier Camp os, Nhan T ran, Ja vier Mauricio Duarte, and Ry an Kastner. Fk eras: A sensitivit y analysis to ol for edge neural net works. A CM J. Auton. T r ansp ort. Syst. , 1(3), July 2024. [19] Muhammad Abdullah Hanif and Muhammad Shafique. F aq: Mitigating the impact of faults in the w eight memory of dnn accelerators through fault-aw are quantization. arXiv e-prints , pages arXiv–2305, 2023.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment