Relative Transfer Function Estimation Exploiting Spatially Separated Microphones in a Diffuse Noise Field
Many multi-microphone speech enhancement algorithms require the relative transfer function (RTF) vector of the desired speech source, relating the acoustic transfer functions of all array microphones to a reference microphone. In this paper, we propo…
Authors: N. G"o{ss}ling, S. Doclo
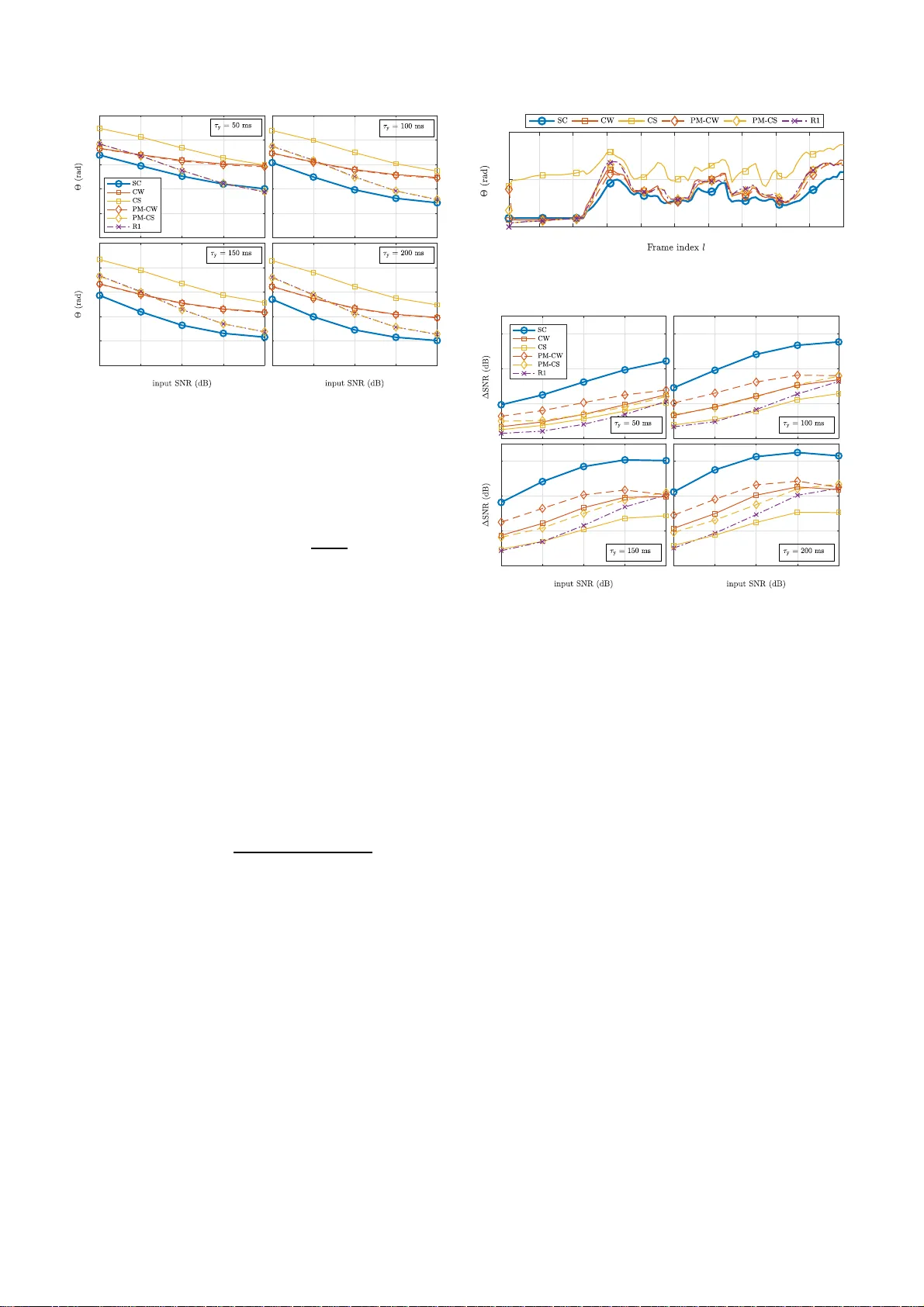
RELA TIVE TRANSFER FUNCTION EST IMA TION EXPLOITING SP A TIALL Y SEP A RA TED MICROPHONES IN A DIFFUSE NOISE F IELD Nico G ¨ oßling, Si mon Doclo Univ ersity of Oldenburg, Department of Medical Physics and Acousti cs and Cluster of Excellence Hearing4All, Oldenbur g, Germany ABSTRA CT Many multi-micropho ne speech enhance ment algorithms require the relativ e transfer function (R TF) vector of the desired speech sou rce, relating the acoustic transfer functions of all array microph ones to a reference microphone. In this paper , we propose a computationally efficien t method to estimate t he R TF vector in a diffuse noise field, which requires an additional microphone that is spatially separated from the microphon e array , such that the spatial coheren ce between the noise compon ents in the microphone array signals and the additional microphone signal is lo w . Assuming this spatial coherence to be zero, we sho w that an unbiased estimate of the R TF vector can be obtained. Based on real-world recordings experimen tal results sho w that t he proposed R TF estimator outperforms state-of-the-art estimators using only the microphone array signals in terms of estimation accuracy and noise redu ction performan ce. Index T erms — Relativ e t ransfer function , external micropho ne, acoustic sensor network, speech enhanc ement, MVDR 1. INTRODUCTION In man y hands-free speech communication systems such as hearing aids, hearables or other a ssistiv e listening de vices, t he captured speech signal is often corrupted by additiv e backgro und n oise, such t hat speech enhancement methods are required to improv e speech quality and speech intelligibillity [1]. When more than one microphone is av ailable, it is not only possible to exploit the spectro-temporal properties but also the spatial properties of the sound field to ex tract the desired speech source at a certain position from the noisy microphon e signals. By using spatially distributed microphones, e.g., one or more external microphon es in addition to the microphones on the hearing de vice, t he spatial sampling of the sound field can be increased [2–7]. A well-known multi-microphone speech enhancemen t method i s the minimum v ariance distortionless response (MVDR) be amformer [1, 8]. In a rev erberant en vironment the MVDR beamformer either requires t he acoustic transfer functions (A TFs) between the desired speech source and the microphones, which are dif ficult to accurately estimate in practice, or the relativ e transfer functions (R TF s) of the de- sired speech sou rce, which relate the A TFs to a reference microphone [1, 9]. Since R TFs can be exploited in many multi-microphone speech enhanceme nt methods [10–17], accurately estimating the R TFs of one or more sources is an important task. In the l i terature se veral methods for estimating the R TFs hav e been proposed [9–12, 18– 21], This work was supported by the Colla borati v e Research Centre 1330 Hearing Acoustics, the Cluster of Excellence 1077 Hearing4 all, funded by the German Research Foundati on (DFG), and by the joint Lower Saxony -Israeli Project A THENA. where most r ecent methods are based either on cov ariance subtrac- tion (CS) or cov arianc e whitening (CW). These methods usually require an esti mate of the microphone signal cov ariance matrix (e.g., estimated during speech-plus-no ise periods) and the noise cov ariance matrix (e.g., estimated during noise-o nly periods). Although an itera- tiv e version of the CS and C W methods has been presented in [12, 21], the computational comple xity of the CS- based and C W-based RTF estimation methods is generally high due to the in v olved matrix operations (possibly in v olving an eigen value decomposition (EVD)), which is especially relev ant for an online-implem entation. In this paper , we propose a computationally efficient method to estimate the R TF s of a local microphone array (e.g., on a hearing de vice) by exploiting the av ailability of an external microp hone that is spatiall y separated from the local micropho ne array . W e conside r a diffu se noise field and assume that the distance between the external microphone and the local microphone array is large enough such that the spatial coherence (S C) between the noise com ponents in the local microphone si gnals and the external microphone signal is lo w . When assuming this SC to be zero, we show t hat a simple R TF estimator can be deriv ed that only depends on the microphone signal cova riance matrix. Based on real-world recordings with (local) head-mounted microphones and an ( external) table microphone, we compare the performance of the proposed R TF estimator and differen t CS-based and CW -based R TF estimators (using only the local microphone signals). Simulation results show that the proposed estimator yields the best performance when used in an online implementation of the binaural MVDR beamformer . 2. SIGNAL MODEL W e con sider an acou stic scenario with one desired speech source and diffu se noise (e.g., babble noise) in a re verbera nt en vironment. The m -th microphone signa l Y m ( k ,l ) of an M -elemen t local microph one array can be writt en in the short-time Fourier transform (S TFT) domain as Y m ( k ,l ) = X m ( k ,l ) + N m ( k ,l ) , m ∈ { 1 ,...,M } , (1) where X m ( k ,l ) denotes the speec h compo nent, N m ( k ,l ) denotes the noise componen t, and k and l denote the frequenc y and frame indices, respecti vely . For the sake of bre vity , we wi ll omit these indices in the remainder of the paper whereve r possible. Al l microphone signals can be stacked in a vector , i.e., y = [ Y 1 , Y 2 , . ..,Y M ] T ∈ C M , (2) which can be w r itten as y = x + n , (3) where the speech vector x and the noise vector n are defined similarly as y i n (2). W ithout l oss of generality , we choo se the first microphone as the reference microphon e. The R T F v ector of the desired speech source i s then giv en by h = 1 , A 2 A 1 , . .., A M A 1 T , (4) where A m is the A TF between the desired speech source and the m -th microp hone. Using (4), the speech v ector can be written as x = X 1 h . (5) The speech co v ariance matrix R x ∈ C M × M and the noise cov arianc e matrix R n ∈ C M × M are given by R x = E { xx H } = Φ x 1 hh H , (6) R n = E { nn H } , (7) where ( · ) H denotes complex conjugation, E {·} denotes the expec- tation operator and Φ x 1 is the speech power spectral density (P SD) in t he fi rst microphone. Assuming statistical independenc e between the speech and the noise components, the cov ariance matrix of the microphone si gnals R y = E { yy H } is equal t o R y = R x + R n . (8) When applying a fil t er-and-sum beamformer w ∈ C M to the microphone si gnals, the output signal Z is gi ven by Z = w H y . (9) The MVDR beamformer [1, 9] aims at minimizing the output noise P SD while preserving the speech component in the reference microphone si gnal and is hence give n by w = a rg mi n w w H R n w subject to w H h = 1 , = R − 1 n h h H R − 1 n h . (10) From (10) it is clear that the MVDR beamformer only requires kno wledge abo ut the noise cov ariance matrix R n and t he R TF v ector of the desired speech source h . 3. R TF VECTOR E STIMA TION In t his section, we briefly re vie w two commonly used methods to estimate the R TF vector h , namely t he CS method [18, 19, 22] and the CW method [11, 22]. For both methods, we also discuss iterative ver- sions based on the powe r iteration method [10, 12, 21]. All methods require an esti mate of the microphone signal cov ariance matrix R y and the noise cov ariance matri x R n , where ˆ R y is estimated during speech-plus-no ise f r ames and ˆ R n is estimated during noise-only frames, assuming a voice activity detector (V AD) is available. The computational complexity of the CS-based and C W -based methods depends on the required matrix operations, where especially matri x in v ersion or EVD will result in a lar ge computational comple xity . 3.1. Covar iance subtraction (CS) By using t he rank-1 mode l in (6), the R TF ve ctor h can be calculated as any column of the speech correlation matrix R x , normalised by the entry corresponding to the reference microphon e, i.e., h CS = R x e e T R x e , (11) where e = [1 , 0 , ... , 0] T is a selection vector con sisting of zeros with one element equal to 1. Usually , the speech cov ariance matrix R x is estimated as ˆ R x = ˆ R y − ˆ R n . Although the CS method has a relativ ely low computational complex- ity , its performance is not always very goo d since due t o estimation errors t he estimated speech cov arian ce matrix ˆ R x typically does not hav e rank-1 [19, 22]. Hence, the R TF vector can also be estimated as the principal eigen v ector (correspon ding to the l argest eigen v alue) of ˆ R x normalising by the entry corresponding to the reference microphone. W e denote this estimate as h R1 . It has been shown in [ 22] that h R1 outperforms h CS when used in a multichannel W iener filter (MWF), but obviously has a larger computationa l complex ity due to the EVD. 3.2. Covar iance whitening (CW) By using a square-root decomposition (e.g., Cholesky decomposi- tion) of the no ise covarian ce matrix R n , i.e., R n = R H/ 2 n R 1 / 2 n , (12) the pre-whitened microphone signal cov ariance matrix is giv en by R w y = R − H/ 2 n R y R − 1 / 2 n . (13) The EV D of (13) is equal to R w y = VΛV H , (14) where V ∈ C M × M contains t he eigenv ectors and the diagonal matrix Λ ∈ R M × M contains the eigen v alues . Based on the principal eigen v ector v max , the R TF vector can be estimated as [ 19] h CW = R 1 / 2 n v max e T R 1 / 2 n v max . (15) 3.3. Iterative methods Iterativ e CS-based and CW -based methods for RTF estimation hav e been proposed, which aim at reducing the computational complex ity of the EVD by using the po wer i t eration method ( or von-M ises-Iteration) t o calculate the principal eigen vecto r v max . Using the power iteration method on the pre-whitened microphone signal cov ariance matrix R w y [12] or the speech cov ariance matrix R x [21] yields the power method (PM) estimators h PM − CW and h PM − CS , respective ly . As mentioned in [ 12, 21], one iteration per frame is typically suf ficient for an online implemen tation. 4. INCORPORA TION OF AN EX TERNAL MICROPHONE In addition to the l ocal microphon e array , we now assume the presence of an external microphone that is spatially separated from the local microphones. The extended microphone signal vector , containing the microp hone signals of the local microphone array and the external micropho ne signal, is gi ven by ¯ y = y Y E ∈ C M +1 , (16) where Y E denotes the external microphone signal. The extended speech and noise vectors are defined similarly as ¯ x = [ x , X E ] T and ¯ n = [ n , N E ] T , respectiv ely . Similarly to (4), t he extended R TF vecto r is given by ¯ h = h A E / A 1 ∈ C M +1 , (17) where A E denotes t he A TF between the desired speech source and the external microphone. Similarly to (6) and (7), the extended speech co- v ariance matrix and the extended noise co v ariance matrix are equal to ¯ R x = E { ¯ x ¯ x H } = Φ x 1 ¯ h ¯ h H ∈ C ( M +1) × ( M +1) , (18) ¯ R n = E { ¯ n ¯ n H } ∈ C ( M +1) × ( M +1) . (19) Similarly to (8), the extende d microphone signal correlation matrix is equal to ¯ R y = ¯ R x + ¯ R n . W e assume that the distance between the external microphone and the local microphones is large enough such that t he noise components in the local microphone si gnals are spatially uncorrelated with the noise componen t in the external microphone si gnal, i.e., E { n N ∗ E } = 0 M , (20) where 0 M is an M -element zero vector . Hence, the extended noise cov arianc e matrix ¯ R n in (19) can be written as ¯ R n = ¯ R n 0 M 0 T M Φ n E , (21) where Φ n E = E {| N E | 2 } denotes the noise PSD in the external microphone signal. For a diffuse, i.e., spherically i sotropic, noise field, the SC between the noise component in the external microphone signal and the noise component in a local microphone signal is equal to (neglecting head shado w ef fects) γ = sinc( dω /c ) , (22) with d the distance between the external microphone and t he local microphone, ω the angular frequency and c t he speed of sound. Hence, the assumption in (20) already holds well e v en for relativ ely small distances (especially at high frequencies). Based on the assumption in (20), it can be easily shown that the cov arianc e between the local microphone signals and the external microphone signal is equal to the cov ariance between the speech componen ts in these microphone signals, i.e., E { y Y ∗ E } = E { ( x + n )( X ∗ E + N ∗ E ) } = E { x X ∗ E } . (23) Using the C S method described in Section 3.1, the extend ed R TF vector ¯ h in ( 17) can be estimated as the last column of the ex- tended speech cov ariance matrix ¯ R x , normalized by the fi r st entry (corresponding to the referen ce microphone), i.e., ¯ h = ¯ R x ¯ e E ¯ e T ¯ R x ¯ e E (24) with the ( M + 1) -dimensional selection vectors ¯ e = [1 , 0 , .. . , 0 ] T and ¯ e E = [0 ,..., 0 , 1] T . Using (21), i t can easily be sho wn t hat ¯ R y ¯ e E = ¯ R x ¯ e E + ¯ R n ¯ e E = ¯ R x ¯ e E + Φ n E ¯ e E , (25) ¯ e T ¯ R y ¯ e E = ¯ e T ¯ R x ¯ e E + ¯ e T ¯ R n ¯ e E = ¯ e T ¯ R x ¯ e E , (26) such t hat, using (24), ¯ R y ¯ e E ¯ e T ¯ R y ¯ e E = ¯ R x ¯ e E + Φ n E ¯ e E ¯ e T ¯ R x ¯ e E = ¯ h + Φ n E ¯ e T ¯ R x ¯ e E ¯ e E . (27) Hence, an unb iased estimation for the R TF vector h can be obtained as the first elemen ts of the v ector in (27), i.e., h SC = [ I M , 0 M ] ¯ R y ¯ e E ¯ e T ¯ R y ¯ e E (28) where I M is the identity matrix of size M and which requires an estimate of the extended microphone cova riance matrix ¯ R y and no estimate of an y noise co v ariance matrix. The proposed estimator has a low computational complexity (similar to the CS estimator using only the l ocal microphone signals), but obvio usly requires an external microphone signal to be tr ansmitted to the local microphone array (synchronization aspects are outside the scop e of this paper). Assum- ing the av ailability of a V AD that outpu ts 1 if speech is present and 0 if speech is absent, the proposed R TF estimation algorithm i s summa- rized in Algorithm 1, where the e xtended microphone signal covari- ance matri x is recursi vely updated during speech-plus-noise frames. Algorithm 1 Proposed R TF esti mati on algorithm Input: ¯ y ( l ) , ¯ R y ( l − 1) , V AD( l ) Parameter : smoothing factor α For each frequenc y bin: Estimation of the extended micr ophone signal covariance matrix: 1: if ( V AD( l ) = = 1 ) then 2: ¯ R y ( l ) = α ¯ R y ( l − 1) + (1 − α ) ¯ y ( l ) ¯ y H ( l ) 3: else 4: ¯ R y ( l ) = ¯ R y ( l − 1) 5: end i f Estimation of the RTF vector: 6: h SC ( l ) = [ I M , 0 M ] ¯ R y ( l ) ¯ e E ¯ e T ¯ R y ( l ) ¯ e E Output: h SC ( l ) 5. EXPERIM ENT AL RESUL TS In this section we compare the performance of the proposed R TF estimator (using the local and the external microp hones) wit h al l R T F estimations discussed in Section 3 (using only the local microphon e signals). Section 5.1 describes the experimental setup and the algo- rithmic parameters. Section 5.2 and 5.3 ev aluate the R TF estimation accurac y and the noise reduction performance when using the R TF estimates in an MVDR beamformer . 5.1. Experimental setup For the simulations we used the database of r eal-world recordings (sampling frequency f s = 16 kHz ) described in [23]. The room di- mensions were about 12 . 7 × 10 × 3 . 6 m 3 with a rev erberation t i me of about 620 ms . The local microphone array consisted of M = 4 micro- phones mounted to the ears of a listener (two microphon es per ear). As reference microp hone we chose the front microphon e mounted to the l eft ear . The external microphone was located on a table in front of the desired speaker wit h about 60 cm distance to the reference micro- phone. The desired speaker was an English-speaking female talker who sat to the right of the li stener at an angle of about 45 ◦ . Both the listener and the desired speaker were seated at a circular table with a diameter of 106 cm . In addition, 56 other talkers which were also seated at tables, generated a realistic babble noise. The noise field hence contained mainly dif fuse but also directional comp onents fr om temporally dominant interfering talkers. Separate recordings of the babble noise and the desired speak er were used to mix them t ogether at differen t input signal-to-noise ratios (S NRs) {− 10 , − 5 , 0 , 5 , 10 } dB . The S NR in the external micropho ne signal was abou t 13 dB higher than in the reference microphone signal (due to distance and head shado w effect). W e calculated all SNRs using the intelligibili ty- weighted SNR [24]. The total signal length was about 23 s . W e used an STFT framew ork with a frame length L f = 512 samples and a frame-shift of L o = L f / 2 samp les and a square-root Hann win- do w . T o esti mate the cov ariance matrices ¯ R y and R y using speech- plus-noise frames and the noise cov ariance matrix R n using noise- 0.2 0.4 0.6 0.8 -10 -5 0 5 10 0.2 0.4 0.6 0.8 -5 0 5 10 Fig. 1 . Hermitian angle Θ between the reference R TF vector h REF and the estimated R TF vectors (averaged ov er frequenc y and time) for differe nt i nput S NRs and dif ferent ti me constants τ y . only frames we used a simple broadband energy-based V AD calcu- lated from the speech compo nent in the reference microphone si gnal. T o recursi vely estimate t hese cov arianc e matrices, we used the time constants τ y and τ n , respectiv ely . T he corresponding smoothing fac- tor (cf. Algorithm 1) is equal to α = exp( − L f − L o f s τ ) . Please note that a smaller t ime constant corresponds to a smaller smoothing factor and hence to a faster adaptation to possible ch anges, but may also lead to less accurate estimates of the cov arianc e matrices. Especially in a sce- nario where the microphones or the desired speaker may chang e their position, a small time constant is desireable t o be able to track changes fast enough. Because t he backgroun d noise can be assumed to be rather stationary we set the corresp onding time constant τ n = 500ms . The t ime constant used to r ecursively estimate the cov ariance matri- ces ¯ R y and R y was chosen as τ y ∈ { 50 , 100 , 150 , 200 } ms . All cov arianc e matrix estimates were initiali sed using the corresp onding long-term estimate. 5.2. RTF estimation a ccuracy As suggested in [21], to ev aluate the RTF estimation accurac y we used the Hermitian ang le between a reference R TF v ector h REF and the estimated R TF vector ˆ h , i.e., Θ( k ,l ) = arccos | h H REF ( k ,l ) ˆ h ( k ,l ) | k h REF ( k ,l ) k 2 k ˆ h ( k ,l ) k 2 . (29) The reference R TF vector h REF was calculated as the principal eigen- vector of the oracle speech cova riance matrix R x (estimated using all av ailable speech frames), normalised by its first element ( correspond- ing to the reference microphone). Figure 1 depicts the results (aver- aged ov er all frequencies and frames) for differen t ti me constants over differe nt input SNRs. As exp ected, the performance of all estimators improv es by increasing the input SNR and the time constant. It can be observ ed t hat the proposed SC-based estimator generally o utperforms the other estimators for all i nput SNRs and time constants. The CS method showed worse performance, in line wit h the literature [19]. Only for a t i me constant of τ y = 50ms and a high inpu t SNR of 10 dB the R1 and PM-CS estimators slightly outperform the proposed estimator . For an e xemplary input SNR of 0 d B and a time constan t of 50 ms Figure 2 depicts the Hermitian angles (ave raged over all frequencies) for the fi rst 100 frames. The proposed estimator starts 10 20 30 40 50 60 70 80 90 100 0 0.5 1 Fig. 2 . Hermit i an angle Θ between t he reference R TF vector h REF and the estimated R TF vectors (average d over frequency) for an input SNR of 0 dB and τ y = 50ms . 2 4 6 8 -10 -5 0 5 10 2 4 6 8 -5 0 5 10 Fig. 3 . SNR improveme nt ∆ SNR of an MVDR beamformer steered by usin g the estimated R TF v ectors for dif ferent time constants τ y . to adapt aft er about 22 frames because this is the first frame where the speaker is active. All other estimators rely on estimates of both the noisy and the noise cov ariance matrices and hence adapt during noise-only and speech-plus-noise frames. The R1 and CW estimators both seem to benefit from the l ong-term initializations in the first frames but perform worse t han the proposed estimator afterwards. 5.3. Noise r eduction W e ev aluated the noise reduction performance when using the estimated RTF s to steer an MVDR beamformer , i.e., using ˆ h ( k , l ) and the time-varying estimate of R n ( k , l ) in (10). Pl ease note, that for all estimators the MVDR beamformer is M -dimensional. Figure 3 depicts the SNR improv ement ( ∆ SN R ) calculated by app lying the beamformer to the desired speech and noise componen ts separately . As can be seen, the proposed SC estimator clearly outperforms all other estimators for all input S NRs and time constants. 6. CONCLUSION In this paper , we proposed an R TF estimation method exploiting lo w spatial coherence between the noise components in local microp hone signals and an external microphone signal. W e derived a simple and computational ef ficient R TF esti mator t hat yields an unbiased estimate of the R TF vector corresponding to the local microphone array . Evaluation results in terms of the R TF estimation error and the noise reduction performance using real-world si gnals in an online implementation showed that the proposed estimator outperforms existing estimators using only the local micropho ne signals. 7. REFERENCE S [1] S. Doclo, W . Kellermann, S. Makino, and S.E. Nordholm, “Multichannel S ignal Enhancement Algorithms for Assisted Listening Devices: Exploiting spatial di versity using multiple microphones, ” IEE E S ignal Pr ocessing Ma gazine , v ol. 32, no. 2, pp. 18–30 , Mar . 2015. [2] A. Bertrand and M. Moonen, “Robu st Distributed Noise Reduction in Hearing Aids with External Acoustic Sensor Nodes, ” EURASIP J ournal on Advanc es in Signal Pr oc essing , vol. 2009, pp. 14 pag es, Jan . 2009. [3] S. Marko vich-Golan, A. Bertrand, M. Moonen, and S. Gan- not, “Optimal distr i buted minimum-variance beamforming approaches for speech enh ancement in wir el ess acoustic sensor networks, ” Signal Pr oces sing , vol. 107 , pp . 4–20, Feb. 2015. [4] J. Szurley , A. Bertrand, B. V an Dijk, and M. Moonen, “Binaural noise cue preserv ation in a binaural noise reduction system with a remote microphone signal, ” IEEE/ACM Tr ans. on Audio, Speec h and Languag e Proc essing , v ol. 24, no. 5, pp. 952– 966, May 2016. [5] D. Y ee, H. Kamkar-Parsi, R. Martin, and H. Puder, “A Noise Re- duction Post-Fil ter for Binaurally-linked Single-Microphone Hearing Aids Utilizing a Nearby External Microphon e, ” IEEE/ACM Tr ans. on Audio Speech and Langua ge Pr ocessing , vol. 26, no . 1, pp. 5–18 , 2017. [6] N. G ¨ oßling, D. Marquardt, and S. Doclo, “Performance analysis of the extended binaural MVDR beamformer with partial noise estimation in a homogen eous noise field, ” in Pr oc. J oint W ork- shop on Hands-fr ee Speech Communication and Microph one Arrays (HSCMA) , San Francisco, USA, Mar . 2017, pp. 1–5. [7] R. Ali, T . V an W atershoot, and M. Moonen, “Generalised sidelobe can celler for noise reduction in hea ring de vices using an external microp hone, ” in Proc. IEEE International Confer - ence on Acoustics, Speech and Signal Pr ocessing (ICA SSP) , Calgary , Alberta, Kanada, Apr . 2018 , pp. 52 1–525. [8] B. D. V an V een and K. M. Buckley , “Beamforming: a versa tile approach to spatial filtering, ” IEE E ASSP Ma gazine , vol. 5, no. 2, pp. 4–24, Apr . 1988. [9] S. Gannot, D. Burshtein, and E. W einstein, “Signal En- hancement Using Beamforming and Non-Stationarity with Applications to Speech, ” IEEE T rans. on Signal Pr ocessing , vol. 49, no . 8, pp. 1614 –1626, Aug. 2001. [10] E . W arsitz and R. Haeb-Umbach, “Blind acoustic beamforming based on generalized eigen value decomposition, ” IEEE T ra ns. on Audio Speech and Languag e Pr ocessing , vo l. 15, no. 5, pp. 1529–1 539, July 2007. [11] S . Marko vich, S. Gannot, and I . Cohen, “Multichannel eigenspace beamforming in a reverb erant noisy en vironment with multiple interfering speech signals, ” IEEE T ran s. on Audio, Speech, and Langua ge Pr ocessing , vol. 17, no. 6, pp. 1071–1 086, Aug. 20 09. [12] A. Krueger , E. W arsi t z, and R. Haeb-Umbach, “Speech enhanceme nt wi th a GSC-li ke st r ucture employing eigen ve ctor- based transfer function ratios estimation, ” IE EE T rans. on Audio Speec h and Languag e Pr ocessing , vol. 19, no. 1, pp. 206–21 9, Jan. 2011. [13] D. Marquard t, E. Hadad, S. Gannot, and S. Doclo, “Theoretical Analysis of Linearly Constrained Multi-channel Wien er Filter- ing Algorithms for C ombined Noise Reduction and Binaural Cue Preservation in Binaural Hearing Aids, ” IEEE/ACM T ra ns. on Audio, Speech, and Languag e Pro cessing , vol. 23, no. 12, pp. 238 4–2397 , Dec. 201 5. [14] E . Hadad, S . Doclo, and S . Gannot, “The Binaural LCMV Beamformer and its Performance Analysis, ” IEEE /ACM T rans. on Audio, Speech, and L angua ge Proc. , vol. 24, no. 3, pp. 543–55 8, 2016. [15] A. Hassani, A. Bertrand, and M. Moonen, “LCMV beam- forming with subspa ce projection for multi-speak er speech enhanceme nt, ” in Pro c. IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , Shanghai, China, May 2016, pp. 91–95. [16] M. T ase ska and E . A. P . Habets, “Spotforming: Spatial Filtering with Distributed Arrays for Position-Selective Sound Acqui- sition, ” IEEE/ACM T r ans. on Audio Speech and Languag e Pr ocessing , vol. 24, no. 7, pp. 1291–1304 , 2016. [17] A. K outrouv elis, T . W . Sherson, R. Heusdens, and R. C. Hen- driks, “A Low-Cost Robust Distributed Linearly Constrained Beamformer for W ireless Acoustic Sensor Networks W ith Arbitrary T opology , ” IEEE /ACM T rans. on Audio Speech and Langua ge Pr ocessing , v ol. 26, no. 8, pp. 1434–144 8, 2018. [18] I. Cohen, “Relati ve transfer function identification using speech signals, ” IEEE T rans. on Speech an d Audio Proc essing , vol. 12, no. 5, pp. 45 1–459, Sep. 2004. [19] S . Markovich -Golan and S. Gannot, “Performance analysis of the cov ariance subtraction method for relative transfer func- tion estimation and comparison to the cov ariance whitening method, ” in Pr oc. IEE E International Con fer ence on Acoustics, Speec h and Signal Pro cessing (ICASSP) , Bri sbane, Australia, Apr . 2015, pp . 54 4–548. [20] R. Giri, D. Rao, B., F . Mustiere, and T . Zhang, “Dynamic relativ e impulse response estimation using structured sparse Bayesian learning, ” in Proc. IEEE International Confer ence on Acoustics, Speec h and Signal P r ocessing (ICASSP) , March 2016, pp. 514–518. [21] R. V arzand eh, M. T aseska, and E. A. P . Habets, “ An iterative multichannel subspace-based cov ariance subtraction method for relati ve t r ansfer function estimation, ” in Pr oc. J oint W ork- shop on Hands-fr ee Speech Communication and Microph one Arrays (HSCMA) , San Francisco, USA, Mar . 2017, pp. 11–15. [22] R. Serizel, M. Moonen, B. V an Dijk, and J. W outers, “Lo w-rank approximation based multichannel Wiener filter algorithms for noise reduction with application in cochlear implants, ” IEEE/ACM Tr ans. on Audio, Speech an d Languag e Pr ocessing , vol. 22, no . 4, pp. 785– 799, Apr . 2014. [23] W . S . W oods, E. Hadad, I. Merks, B. X u, S . Gannot, and T . Zhang, “ A real-world recording database for ad hoc mi- crophone arrays, ” in Proc . IE EE W orkshop on A pplications of Signal Pro cessing to Audio and Acoustics (W ASP AA) , Ne w Paltz, New Y ork, Oct 201 5, pp. 1–5. [24] J. E. Greenberg, P . M. P eterson, and P . M. Zurek, “Intelli gibility- weighted measures of speech-to-interference ratio and speech system performance, ” J ournal of the Acoustical Society of America , vol. 94, no. 5, pp. 300 9–3010, No v . 1993.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment