Human detection of machine manipulated media
Recent advances in neural networks for content generation enable artificial intelligence (AI) models to generate high-quality media manipulations. Here we report on a randomized experiment designed to study the effect of exposure to media manipulatio…
Authors: Matthew Groh, Ziv Epstein, Nick Obradovich
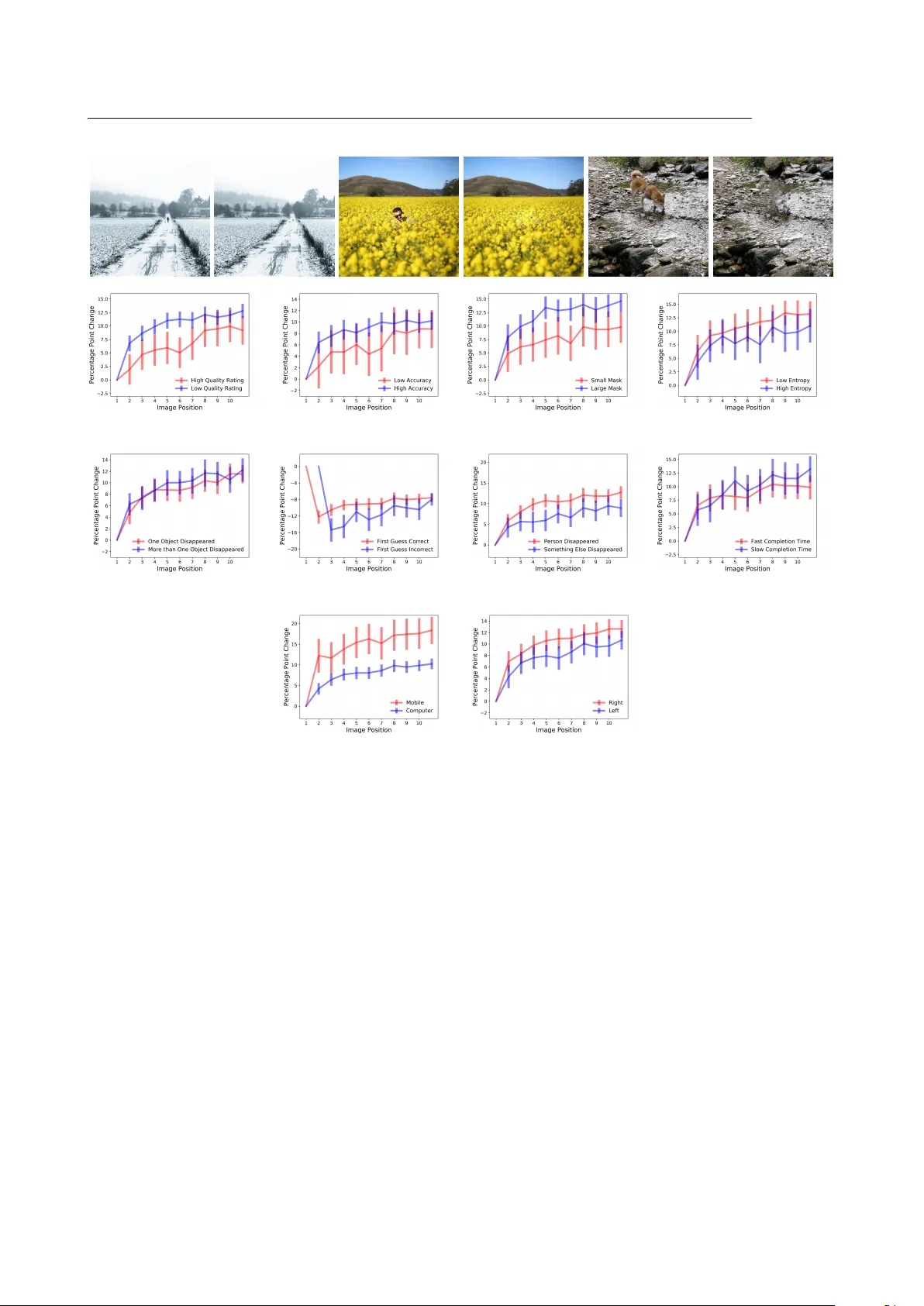
Human detection of mac hine manipulated media Matthew Groh 1 , Ziv Epstein 1 , Nic k Obradovic h 1,2 , Man uel Cebrian ∗ 1,2 , and Iy ad Rahw an ∗ 1,2 1 Media Lab oratory , Massac husetts Institute of T ec hnology , Cam bridge, Massach usetts, USA 2 Cen ter for Humans & Machines, Max Planc k Institute for Human Dev elopment, Berlin, German y Abstract Recen t adv ances in neural netw orks for conten t generation enable artificial intelligence (AI) mo dels to generate high-quality media manipulations. Here w e report on a randomized experiment designed to study the effect of exp osure to media manipulations on o ver 15,000 individuals’ abilit y to discern machine-manipulated media. W e engineer a neural netw ork to plausibly and automatically remo ve ob jects from images, and we deploy this neural netw ork online with a randomized exp erimen t where participan ts can guess whic h image out of a pair of images has b een manipulated. The system pro vides participants feedback on the accuracy of eac h guess. In the exp erimen t, we randomize the order in whic h images are presen ted, allo wing causal iden tification of the learning curve surrounding participants’ abilit y to detect fake con tent. W e find sizable and robust evidence that individuals learn to detect fake con tent through exp osure to manipulated media when provided iterativ e feedback on their detection attempts. Over a succession of only ten images, participants increase their rating accuracy by o ver ten p ercen tage p oin ts. W e then in vestigate factors that potentially mo derate rates of learning and find that image qualit y , prop ortion of image mo dified, and user device type – among other factors – may all play imp ortan t roles in learning to detect manipulated media. Our study provides initial evidence that h uman ability to detect fake, machine-generated con tent may increase alongside the prev alence of suc h media online. In tro duction The recen t emergence of artificial intelligence (AI) pow ered media manipulations has widespread so cietal implications for journalism and democracy [1], national securit y [2], and art [3]. AI models ha ve the p oten tial to scale misinformation to unprecedented levels by creating v arious forms of syn thetic media [4]. F or example, AI systems can syn thesize realistic video p ortraits of an individual with full control of facial expressions including ey e and lip mo vemen t [5 – 9], can clone a speaker’s voice with few training samples and generate new natural sounding audio of something the speaker nev er previously said [10], can synthesize visually indicated sound effects [11], can generate high quality , relev ant text based on an initial prompt [12], can produce photorealistic images of a v ariety of ob jects from text inputs [13 – 15], and can generate photorealistic videos of p eople expressing emotions from only a single image [16, 17]. The tec hnologies for pro ducing en tirely mac hine-generated, fake media online are rapidly outpacing the abilit y to man ually detect and respond to suc h media. Media manipulation and misinformation are topics of considerable in terest within the computational and so cial sciences [18 – 21], partially b ecause of their historical significance. F or a particular kind of media manipulation, ∗ T o whom correspondence should be addressed: c ebrian@mit.e du, ir ahwan@mit.e du 1 there’s a Latin term, damnatio memoriae , whic h refers to the erasure of an individual from official accounts, often in service of dominan t p olitical agendas. The earliest known instances of damnatio memoriae were discov ered in ancient Egyptian artifacts and similar patterns of remov al hav e app eared since [22, 23]. Figure SI8 presents iconic examples of damnatio memoriae throughout mo dern history . Historically , visual and audio manipulations required b oth skilled experts and a significant in vestmen t of time and resources. T o da y , an AI mo del can pro duce photorealistic manipulations nearly instan taneously , whic h magnifies the potential scale of misinformation. This gro wing capabilit y calls for understanding individuals’ abilities to differen tiate b et ween real and fake conten t. T o interrogate these questions directly , w e e ngineer an AI system for photorealistic image manipulation and host the model and its outputs online as an exp erimen t to study participants’ abilities to differentiate b et w een unmo dified and manipulated images. Our AI system consists of an end-to-end neural netw ork architecture that can plausibly disappear ob jects from images. F or example, consider an image of a b oat sailing on the ocean. The AI mo del detects the boat, remo ves the b oat, and replaces the b oat’s pixels with pixels that appro ximate what the ocean migh t ha v e looked like without the b oat present. Figure 1 presen ts four examples of participan t submitted images and their transformations. W e host this AI mo del and its image outputs on a custom-designed w ebsite called Deep Angel. Since Deep Angel launched in August 2018, o v er 110,000 individuals hav e visited the website and interacted with the mo del and its outputs. Within the Deep Angel platform, w e embedded a randomized exp erimen t to examine how rep eated exp osure to mac hine-manipulated images affects individuals’ abilit y to accurately iden tify manipulated imagery . Figure 1: Examples of original images on the top ro w and manipulated images on the b ottom row. Exp erimen tal Design User Interface In the “Detect F ak es” feature on Deep Angel, individuals are presented with t wo images and asked a single question: “Which image has something remov ed by Deep Angel?” See Figure 7 in the Supplementary Information for a screenshot of this in teraction. One image has an ob ject remov ed b y our AI model. The other image is an unaltered image from the 2014 MS-COCO data [24]. After a participant answers the question by selecting an image, the manipulated image is revealed to the participant and the participant is offered the option to try again on a new pair of images. 2 (a) (b) Figure 2: (a) Histogram of mean identification accuracies by participan ts p er image (b) Bar chart plotting n umber of individuals o ver image position. Usage Most participants interacted with “Detect F akes” multiple times; the interquartile range of the n umber of guesses p er participant is from 3 to 18 with a median of 8. Eac h interaction follo wed the same randomization with replacemen t, which ensured that the images display ed did not depend on what the individual had previously seen. F rom August 2018 to May 2019, 242,216 guesses w ere submitted from 16,542 unique IP addresses with a mean identification accuracy of 86%. Deep Angel did not require participant sign-in, so we study participant b eha vior under the assumption that eac h IP address represents a single individual. 7,576 participan ts submitted at least 10 guesses. Eac h image app ears as the first image an av erage of 35 times and the tenth image an av erage of 15 times. In the sample of participants who s a w at least ten images, the mean p ercen tage correct classification is 78% on the first image seen and 88% on the ten th image seen. The ma jority of manipulated images w ere iden tified correctly more than 90% of the time. Figure 2a shows the distribution of identification accuracy ov er images, and Figure 2b shows the distribution of image p ositions seen o v er participan ts. By plotting participant identification accuracy against the order in which participants see images, Figure 3a reveals a logarithmic relationship betw een accuracy and o verall exp osure to manipulated images. Accuracy increases fairly linearly o ver the first ten images after which accuracy plateaus around 88%. Randomization W e randomly select the “Detect F akes” images from tw o samples of images. One sample contains 440 images manipulated by Deep Angel that participants submitted to b e shared publicly . The other p o ol of images contains 5,008 images from the MS-COCO dataset [24]. Suc h randomization at the image dyad level is equiv alen t to randomization of the image p osition - the order in which images appear to the participant. Based on the randomized image p osition, w e can causally ev aluate the effect of image position on rating accuracy . W e test the causal effects with the following linear probabilit y mo dels: y i,j = αX i,j + β log( T i n ) + µ i + ν j + i,j (1) 3 and y i,j = αX i,j + β 1 T i 1 + β 2 T i 2 + β 3 T i 3 + ... + β 9 T i 9 + β 10 T i 10 + µ i + ν j + i,j (2) where y i,j is the binary accuracy (correct or incorrect guess) of participan t j on manipulated image i . X i,j represen ts a matrix of cov ariates, T i n represen ts the order n in which manipulated image i app ears to participant j , µ i represen ts th e manipulated image fixed effects, ν j represen ts the participant fixed effects, and i,j represen ts the error term. The first model fits a logarithmic transformation of T i n to y i,j . The second model estimates treatmen t effects separately for each image p osition. Both mo dels use Hub er-White (robust) standard errors, and errors are clustered at the image level. Results With 242,216 observ ations, w e run an ordinary least squares regression with user and image fixed effects on the lik eliho od of guessing the manipulated image correctly . The results of these regressions are presented in T ables 1 and 2 in the App endix. Eac h column in T able 1 and 2 adds an incremental filter to offer a series of robustness c hecks. The first column shows all observ ations. The second column drops all users who submitted fewer than 10 guesses and remov es all con trol images where nothing w as remov ed. The third column drops all observ ations where a user has already seen a particular image. The fourth column drops all images qualitativ ely judged as b elo w very high qualit y . A cross all four robustness c hecks with and without fixed-effects, our mo dels show a p ositiv e and statistically significan t relationship b et w een T n and ˆ y i,j . In the linear-log model, a one unit increase in log ( T i n ) is associated with a 3 percentage point increase in ˆ y i,j . This effect is significant at the p<.01 level. In the model that estimates Equation 2, w e find a 1 percentage p oin t av erage marginal treatmen t effect size of image position on ˆ y i,j . This effect is also significant at the p<.01 level. In other w ords, users impro ve their abilit y to guess by 1 percentage p oin t for each of the first 10 guesses. Figure 3 sho ws these results graphically . The statistically significant improv ement in accurately identifying manipulations suggests that within the con text of Deep Angel, exp osure to media manipulation and feedbac k on what has b een manipulated can successfully prepare individuals to detect fak ed media. When trained for 1 min ute and 14 seconds on a verage, across ten images, participan ts impro ved their ability to detect manipulations b y ten p ercen tage points. As participan ts are exp osed to image manipulations, they quic kly learn to spot the v ast ma jority of the manipulations. An examination of participants’ learning rate across a v ariety of image and participant characteristics provides some insight into what drives learning. W e ev aluate manipulation qualit y across five measures: (a) a sub jectiv e quality rating, (b) 1st and 4th quartile image entrop y , (c) 1st and 4th quartile prop ortion of area of the image that w as manipulated, (d) 1st and 4th quartile mean iden tification accuracy p er image, and (e) num b er of ob jects disapp eared. Retrosp ectiv ely , w e hired a third party to rate each image’s manipulation as high or lo w qualit y based on whether large and noticeable artifacts were created by the image manipulation, whic h we use as a sub jectiv e quality rating. The image en tropy is measured based on delentrop y , an extension of Shannon entrop y for images. [25] As an example, Figure 4 presents three pairs of images sub jectively rated as high quality with their corresp onding entrop y scores, prop ortion of the image transformed, mean accuracy of participants’ first guess, and mean accuracy of participan ts guesses b ey ond the first to offer an example of what study participants learned. The mean image accuracy of images sub jectively rated as high qualit y is 75% and 83% for the 1st and 10th image, resp ectiv ely , while the accuracy for the lo w qualit y images is 82% and 94%, resp ectiv ely . While, T able 3 sho ws th a t the difference in means across the sub jective quality measure is statistically significan t at the 99% confidence lev el (p<.01), w e do not find a statistically significant difference in learning rates. As sho wn in Figure 4a, there is a slight ov erlap in the confidence interv als of image p ositions 2 through 5, a statistically significan t difference in image p ositions 6 and 7, and ov erlap in the confidence in terv als for the rest of the image p ositions. There is some evidence that participants learn to iden tify lo w qualit y images faster than high qualit y 4 (a) (b) Figure 3: Participan ts’ ov erall and marginal accuracy by image order with error bars sho wing a 95% confidence in terv al for eac h image p osition – (a) o v erall accuracy for all users with no fixed effects (b) marginal accuracy (relativ e to the first image p osition) for all users who sa w at least 10 images controlling for user and image fixed effects and clustering errors at the image level. In (b), the 11th p osition includes all images p ositions b ey ond the 10th. images but the lac k of statistically significant results on 8 of the 10 image p ositions and the lack of statistically significan t results in the in teraction b et ween sub jectiv e quality and the logarithm of the image p osition in T able 3 precludes us from rejecting the null hypothesis that the learning rate is identical across high and lo w quality images. These results indicate that the main effect is not simply driven by participants b ecoming proficient at guessing low-qualit y images in our data. In addition to the sub jectiv e qualit y rating, we ev aluate the learning rate across four additional proxies for manipulation quality . P articipants learn to identify low entrop y images faster than high en tropy images and images with large masked area faster than images with small mask ed area. T able 3 shows that this difference in learning rates is statistically significan t at the 95% (p<.05) and 90% (p<.10) levels, resp ectiv ely . Smaller mask ed areas and lo wer entrop y is associated with less stark and more subtle changes b et ween an original and manipulated image. This relationship ma y indicate that participants learn more from subtle images than more ob vious manipulations. Neither the split b et ween the 1st and 4th quartile of mean accuracy p er image nor the split b et ween one ob ject and man y ob jects disapp eared has a statistically significant effect on the learning rates. W e find heterogeneous effects on the learning rate based on participan ts’ initial p erformance. In Figure 4, w e compare subsequent learning rates of participants who correctly identified a manipulation on their first attempt to participan ts who failed on their first attempt and succeeded on their second. In this comparison, the omitted p osition for eac h learning curve represents p erfect accuracy , which makes the marginal effects of subsequen t image p ositions negative relativ e to these omitted image p ositions. On the first 3 of 4 image p ositions in this comparison, which corresp ond to the 3rd through 6th image p ositions, we find that initially successful participan ts learn faster than participan ts who were initially unsuccessful. This heterogeneous effect do es not p ersist in the 7th p osition or b ey ond. Ov erall, this heterogeneous effect is statistically significant at the 99% lev el (p<.01) and can be in terpreted as initial p erformance is associated with a 2 percentage p oin t reduction in the learning rate. This suggests that p eople who are more accurate on av erage also learn faster on a verage. P articipants learn to detect images with p eople disapp eared faster than images with an y other kind of thing disapp eared. This difference is statistically significan t at the 95% confiden t interv al (p<.05) in the log-linear 5 regression as sho wn in T able 3. Figure 4 also s ho ws this difference is statistically significan t in 2 of the 10 image p ositions. W e conjecture that the photos where p eople ha ve b een disapp eared induce a feeling that something is missing whereas when material ob jects like a so ccer ball or cell phone are missing, the feeling of absence is not ev oked. W e do not find strong evidence that the sp eed with which a participant completed rating 11 images is related to the learning rate. W e do not find evidence that the image place men t is correlated with ov erall accuracy , but w e do find statistically significan t evidence at the 95% confidence in terv al (p<.05) that placement of the image on the righ t is associated with a 1 p ercen tage p oint increase in the learning rate, which ma y be related to ho w participan ts ey es scan the screen from left to righ t. There is a clear difference in the learning rate of participants based on whether they participated with mobile phones or computers. Participan ts on mobile phones learn at a consisten tly faster rate than participan ts on computers, and this difference is statistically significant as sho wn in T able 3 and displa y ed across 9 of 10 image p ositions in Figure 4. W e conjecture that the ease of the zo om feature on mobile phones relativ e to computers enables mobile participants to insp ect each image more closely . Discussion While AI mo dels can improv e clinical diagnoses [26 – 28] and bring about autonomous driving [29], they also ha ve the p oten tial to scale censorship [30], amplify polarization [31], and spread b oth fake news [18] and manipulated media. W e present results from a large scale randomized exp erimen t that sho w the com bination of exposure to manipulated media and feedback on what media has b een manipulated impro ves individuals’ abilit y to detect media manipulations. Direct in teraction with cutting edge technologies for con ten t creation might enable more discerning media consumption across so ciet y . In practice, the news media has exp osed high-profile AI manipulated media including fake videos of the Sp eak er of the House of Representativ es, Nancy P elosi, and the CEO of F aceb ook, Mark Zuck erb erg, which serves as feedback to every one on what manipulations lo ok like [32, 33]. Our results build on recent research that suggests h uman in tuition can b e a reliable source of information ab out adversarial perturbations to images [34] and recen t research that pro vides evidence that familiarising p eople with how fake news is pro duced may confer cognitive imm unity to people when they are later exp osed to misinformation [35]. In addition, our results offer suggestive evidence for what drives learning to detect fak e con tent. In this experiment, presenting participants with low en tropy images with minor manipulations on mobile devices increased learning rates at statistically significant levels. When given feedback, participants app ear to learn b est from the most subtle manipulations. The generalizability of our results is limited to the images pro duced b y our AI mo del, and a promising av en ue for future research could expand the domains and models studied. Lik ewise, future researc h could explore to what degree individuals’ ability to adaptiv ely detect manipulated media comes from learning-by-doing, direct feedbac k, and aw areness that an ything is manipulated at all. Our results suggest a need to re-examine the precautionary principle that is commonly applied to conten t generation technologies. In 2018, Go ogle published BigGAN, whic h can generate realistic app earing ob jects in images, but while they hosted the generator for any one to explore, they explicitly withheld the discriminator for their mo del [14]. Similarly , Op enAI restricted access to their GPT-2 mo del, which can generate plausible long-form stories given an initial text prompt, by only providing a pared down mo del of GPT-2 trained with few er parameters [12]. If exp osure to manipulated conten t can v accinate p eople from future manipulations, then censoring dissemination of AI research on conten t generation may prov e harmful to so ciet y by lea ving it unprepared for a future of ubiquitous AI-mediated conten t. 6 (a) Sub jective Qualit y (b) Image Accuracy (c) Mask Size (d) Entrop y (e) # of Ob jects Disapp eared (f ) First Guess (g) Has Person (h) Completion Time (i) Mobile (j) Image Lo cation Figure 4: (i) F rom left to right, images (cropp ed into squares for displa y purp oses) are increasing in entrop y (3.5, 6.0, and 8.5), v arying in percent of the image transformed (0.7%, 2.4%, and 1.9%), similar in accuracy on the first guess (70%, 71%, 70%), v arying in accuracy beyond the first guess (88%, 82%, 92%). (ii) 10 plots displa ying heterogeneous effects of image and participant characteristics on learning while controlling for user and image fixed effects (a) whether the sub jective image qualit y was judged as high by a thi r d party , (b) whether the original image was in the 1st to 25th percentile of accuracy or 75th to 99th, (c) whether the original image w as in the 1st to 25th p ercen tile of image mask prop ortion or 75th to 99th, (d) whether the original image was in the 1st to 25th p ercen tile of entrop y or 75th to 99th, (e) whether there were one or m ultiple ob jects disapp eared (f ) whether the participant’s first answ er was correct (the omitted p osition for each learning curve represen ts p erfect accuracy), (g) whether the image contained a p erson, (h) whether the original image w as in the 1st to 25th p ercen tile of time to ev aluate 10 images or 75th to 99th, (i) whether the participant viewed the images on a mobile device or computer (j) whether the image w as placed on the left or right side of the screen. The error bars represent the 95% confidence interv al for each image p osition and errors are clustered at the image lev el. 7 Metho ds W e engineered a T ar get Obje ct R emoval pip eline to remo ve ob jects in images and replace those ob jects with a plausible background. W e com bine a conv olutional neural net work (CNN) trained to detect ob jects with a generativ e adv ersarial net work (GAN) trained to inpain t missing pixels in an image [36 – 39]. Specifically , w e generate ob ject masks with a CNN based on a RoIAlign bilinear in terp olation on nearb y p oin ts in the feature map [38]. W e crop the ob ject masks from the image and apply a generative inpainting architecture to fill in the ob ject masks [40, 41]. The generativ e inpainting arc hitecture is based on dilated CNNs with an adv ersarial loss function whic h allows the generative inpainting architecture to learn semantic information from large scale datasets and generate missing conten t that makes con textual sense in the masked p ortion of the image [41]. T arget Ob ject Remo v al Pip eline Our end-to-end tar gete d obje ct r emoval pipeline consists of three in terfacing neural net w orks: • Ob ject Mask Generator (G): This netw ork creates a segmen tation mask ˆ X = G ( X, y ) given an input image X and a target class y . In our exp erimen ts, we initialize G from a seman tic segmentation netw ork trained on the 2014 MS-COCO dataset following the Mask-RCNN algorithm [38]. The netw ork generates masks for all ob ject classes present in an image, and we select only the correct masks based on input y . This netw ork was trained on 60 ob ject classes. • Generative Inpain ter (I): This netw ork creates an inpain ted version Z = I ( ˆ X , X ) of the input image X and the ob ject mask ˆ X . I is initialized following the DeepFill algorithm trained on the MIT Places 2 dataset [41, 42]. • Lo cal Discriminator (D): The final discriminator netw ork takes in the inpainted image and determines the v alidity of the image. F ollowing the training of a GAN discriminator, D is trained sim ultaneously on I where X are images from the MIT Places 2 dataset and ˆ X are the same images with randomly assigned holes following [41, 42]. F or every input image and class lab el pair, we first generate an ob ject mask using G , which is paired with the image and inputted to the inpainting netw ork I that pro duces the generated image. The inpainter is trained from the loss of the discriminator D , following the typical GAN pip eline. An illustration of our neural net work arc hitecture is provided in Figure 5. Liv e Deplo ymen t W e designed an interactiv e website called Deep Angel to make the T ar get Obje ct R emoval pip eline publicly a v ailable. 1 The API for the T ar get Obje ct R emoval pip eline is serv ed by a single Nvidia Geforce GTX Titan X. In addition to the “Detect F akes” user interaction, Deep Angel has a user in teraction “Erase with AI,” where p eople can apply the T ar get Obje ct R emoval pip eline on their own images. See Figure 6 for a screen shot of this user interface. In “Erase with AI,” p eople first select a category of ob ject that they seek to remov e and then they either upload an image or select an Instagram account from whic h to upload the three most recent images. After the user submits his or her selections, Deep Angel returns b oth the original image and a transformation of the original image with the selected ob jects remo ved. Users uploaded 18,152 unique images from mobile phones and computers. In addition, user directed the cra wling of 12,580 unique images from Instagram. The most frequently selected ob jects for remov al are display ed 1 W e retained the Cyberlaw Clinic from the Harv ard La w School and Berkman Klein Center for Internet & So ciet y to advise and support us throughout the Deep Angel experiment. 8 REFERENCES REFERENCES in T able SI4. The ov erwhelming ma jority of images uploaded and Instagram accoun ts selected were unique. 88% of the usernames en tered for targeted Instagram crawls were unique. W e can surface the most plausible ob ject remov al manipulations b y examining the images with the low est guessing accuracy . Ultimately , plausible manipulations are relativ ely rare and image dep enden t. The T ar get Obje ct R emoval mo del can produce plausible con tent but it is not perfect. F or the T ar get Obje ct R emoval mo del, plausible manipulations are confined to specific domains. Ob jects are only plausibly remo ved when they are a small p ortion of the image and the background is natural and uncluttered by other ob jects. Lik ewise, the mo del often generates model-sp ecific artifacts that h umans can learn to detect. Data A v ailabilit y : Up on publication, the data and replication co de will b e made a v ailable in a public Github rep ository . A ckno wledgmen ts : W e thank Abhiman yu Dubey , Mohit Tiw ari, and Da vid McKenzie for their helpful commen ts and feedback. Author contributions : M.G. implemented the metho ds, M.G., Z.E., N.O. analyzed data and wrote the pap er. All authors conceiv ed the original idea, designed the research, and provided critical feedback on the analysis and man uscript. References [1] R. Chesney and D. K. Citron, “Deep fakes: A lo oming challenge for priv acy , demo cracy , and national securit y ,” 2018. [2] G. Allen and T. Chan, A rtificial intel ligenc e and national se curity . Belfer Center for Science and International Affairs Cambridge, MA, 2017. [3] A. Hertzmann, “Can computers create art?,” in Arts , vol. 7, p. 18, Multidisciplinary Digital Publishing Institute, 2018. [4] D. M. Lazer, M. A. Baum, Y. Benkler, A. J. Berinsky , K. M. Greenhill, F. Menczer, M. J. Metzger, B. Nyhan, G. Penn yco ok, D. Rothschild, et al. , “The science of fak e news,” Scienc e , v ol. 359, no. 6380, pp. 1094–1096, 2018. [5] J. Thies, M. Zollhofer, M. Stamminger, C. Theobalt, and M. Nießner, “F ace2face: Real-time face capture and reenactment of rgb videos,” in Pr o c e e dings of the IEEE Confer enc e on Computer Vision and Pattern R e c o gnition , pp. 2387–2395, 2016. [6] S. Suw a janakorn, S. M. Seitz, and I. Kemelmac her-Shlizerman, “Syn thesizing obama: learning lip sync from audio,” A CM T r ansactions on Gr aphics (TOG) , v ol. 36, no. 4, p. 95, 2017. [7] H. Kim, P . Garrido, A. T ewari, W. Xu, J. Thies, M. Nießner, P . Pérez, C. Ric hardt, M . Zollhöfer, and C. Theobalt, “Deep video p ortraits,” arXiv pr eprint arXiv:1805.11714 , 2018. [8] S. Saito, L. W ei, L. Hu, K. Nagano, and H. Li, “Photorealistic facial texture inference using deep neural net works,” CoRR , v ol. abs/1612.00523, 2016. [9] P . Garrido, L. V algaerts, H. Sarmadi, I. Steiner, K. V aranasi, P . P erez, and C. Theobalt, “V dub: Mo difying face video of actors for plausible visual alignmen t to a dubb ed audio trac k,” in Computer Gr aphics F orum , v ol. 34, pp. 193–204, Wiley Online Library , 2015. [10] S. O. Arik, J. Chen, K. P eng, W. Ping, and Y. Zhou, “Neural voice cloning with a few samples,” arXiv pr eprint arXiv:1802.06006 , 2018. [11] A. Owens, P . Isola, J. H. McDermott, A. T orralba, E. H. A delson, and W. T. F reeman, “Visually indicated sounds,” CoRR , v ol. abs/1512.08512, 2015. 9 REFERENCES REFERENCES [12] A. Radford, J. W u, R. Child, D. Luan, D. Amodei, and I. Sutskev er, “Language models are unsupervised m ultitask learners,” tech. rep. [13] A. Nguyen, J. Y osinski, Y. Bengio, A. Dosovitskiy , and J. Clune, “Plug & pla y generative netw orks: Conditional iterative generation of images in laten t space,” CoRR , vol. abs/1612.00005, 2016. [14] A. Bro c k, J. Donahue, and K. Simony an, “Large scale gan training for high fidelit y natural image synthesis,” arXiv pr eprint arXiv:1809.11096 , 2018. [15] T. Karras, S. Laine, and T. Aila, “A style-based generator arc hitecture for generativ e adv ersarial netw orks,” arXiv pr eprint arXiv:1812.04948 , 2018. [16] H. A verbuc h-Elor, D. Cohen-Or, J. Kopf, and M. F. Cohen, “Bringing p ortraits to life,” A CM T r ansactions on Gr aphics (TOG) , v ol. 36, no. 6, p. 196, 2017. [17] E. Zakharov, A. Sh ysheya, E. Burk ov, and V. Lempitsky , “F ew-shot adversarial learning of realistic neural talking head mo dels,” 2019. [18] S. V osoughi, D. Roy , and S. Aral, “The spread of true and false news online,” Scienc e , vol. 359, no. 6380, pp. 1146–1151, 2018. [19] Y. Benkler, R. F aris, and H. Rob erts, Network Pr op aganda: Manipulation, Disinformation, and R adic aliza- tion in A meric an Politics . Oxford Universit y Press, 2018. [20] N. A. Co ok e, “Posttruth, truthiness, and alternativ e facts: Information behavior and critical information consumption for a new age,” The Libr ary Quarterly , v ol. 87, no. 3, pp. 211–221, 2017. [21] A. Marwick and R. Lewis, “Media manipulation and disinformation online,” New Y ork: Data & So ciety R ese ar ch Institute , 2017. [22] E. R. V arner, Monumenta Gr ae c a et R omana: Mutilation and tr ansformation: damnatio memoriae and R oman imp erial p ortr aitur e , vol. 10. Brill, 2004. [23] D. F reedb erg, The p ower of images: Studies in the history and the ory of r esp onse . Universit y of Chicago Press Chicago, 1989. [24] T.-Y. Lin, M. Maire, S. Belongie, J. Ha ys, P . P erona, D. Ramanan, P . Dollár, and C. L. Zitnic k, “Microsoft co co: Common ob jects in context,” in Eur op e an c onfer enc e on c omputer vision , pp. 740–755, Springer, 2014. [25] K. G. Larkin, “Reflections on shannon information: In search of a natural information-entrop y for images,” arXiv pr eprint arXiv:1609.01117 , 2016. [26] A. Estev a, B. Kuprel, R. A. Nov oa, J. K o, S. M. Sw etter, H. M. Blau, and S. Thrun, “Dermatologist-lev el classification of skin cancer with deep neural netw orks,” Natur e , vol. 542, no. 7639, p. 115, 2017. [27] R. Poplin, A. V. V aradara jan, K. Blumer, Y. Liu, M. V. McConnell, G. S. Corrado, L. Peng, and D. R. W ebster, “Prediction of cardiov ascular risk factors from retinal fundus photographs via deep learning,” Natur e Biome dic al Engine ering , vol. 2, no. 3, p. 158, 2018. [28] T. Kooi, G. Litjens, B. V an Ginnek en, A. Gub ern-Mérida, C. I. Sánchez, R. Mann, A. den Heeten, and N. Karssemeijer, “Large scale deep learning for computer aided detection of mammographic lesions,” Me dic al image analysis , vol. 35, pp. 303–312, 2017. [29] C. Chen, A. Seff, A. K ornhauser, and J. Xiao, “Deepdriving: Learning affordance for direct p erception in autonomous driving,” in Pr o c e e dings of the IEEE International Confer enc e on Computer Vision , pp. 2722– 2730, 2015. 10 REFERENCES REFERENCES [30] M. E. Rob erts, Censor e d: distr action and diversion inside China’s Gr e at Fir ewal l . Princeton Universit y Press, 2018. [31] E. Baksh y , S. Messing, and L. A. Adamic, “Exp osure to ideologically diverse news and opinion on faceb o ok,” Scienc e , vol. 348, no. 6239, pp. 1130–1132, 2015. [32] S. Mervosh, “Distorted videos of nancy p elosi spread on faceb ook and twitter, help ed b y trump.” https://www.nytimes.com/2019/05/24/us/politics/pelosi- doctored- video.html , May 2019. Accessed: 2019-06-20. [33] C. Metz, “Distorted videos of nancy p elosi spread on faceb o ok and twitter, help ed by trump.” https: //www.nytimes.com/2019/06/11/technology/fake- zuckerberg- video- facebook.html , June 2019. A ccessed: 2019-06-20. [34] Z. Zhou and C. Firestone, “Humans can decipher adv ersarial images,” Natur e c ommunic ations , vol. 10, no. 1, p. 1334, 2019. [35] J. Ro ozen b eek and S. v an der Linden, “F ak e news game confers psychological resistance against online misinformation,” Palgr ave Communic ations , v ol. 5, 2019. [36] I. Go odfellow, J. P ouget-Abadie, M. Mirza, B. Xu, D. W arde-F arley , S. Ozair, A. Courville, and Y. Bengio, “Generativ e adv ersarial nets,” pp. 2672–2680, 2014. [37] T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of gans for improv ed quality , stabilit y , and v ariation,” arXiv pr eprint arXiv:1710.10196 , 2017. [38] K. He, G. Gkio xari, P . Dollár, and R. B. Girshick, “Mask R-CNN,” CoRR , vol. abs/1703.06870, 2017. [39] Y. LeCun, Y. Bengio, and G. E. Hinton, “Deep learning,” Natur e , vol. 521, no. 7553, pp. 436–444, 2015. [40] S. Iizuk a, E. Simo-Serra, and H. Ishik a wa, “ Globally and Lo cally Consisten t Image Completion,” ACM T r ansactions on Gr aphics (Pr o c. of SIGGRAPH 2017) , vol. 36, no. 4, 2017. [41] J. Y u, Z. Lin, J. Y ang, X. Shen, X. Lu, and T. S. Huang, “Generative image inpain ting with contextual atten tion,” arXiv pr eprint arXiv:1801.07892 , 2018. [42] B. Zhou, A. Lapedriza, A. Khosla, A. Oliv a, and A. T orralba, “Places: A 10 million image database for scene recognition,” IEEE T r ansactions on Pattern Analysis and Machine Intel ligenc e , 2017. [43] A. M. Elgammal, B. Liu, M. Elhoseiny , and M. Mazzone, “ CAN: creativ e adversarial netw orks, generating "art" by learning about st yles and deviating from st yle norms,” CoRR , vol. abs/1706.07068, 2017. [44] S. Carter and M. Nielsen, “Using artificial intelligence to augment human in telligence,” Distil l , vol. 2, no. 12, p. e9, 2017. [45] P . Isola, J. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adv ersarial netw orks,” CoRR , vol. abs/1611.07004, 2016. [46] T.-C. W ang, M.-Y. Liu, J.-Y. Zhu, A. T ao, J. Kautz, and B. Catanzaro, “High-resolution image syn thesis and semantic manipulation with conditional gans,” in IEEE Confer enc e on Computer Vision and Pattern R e c o gnition (CVPR) , vol. 1, p. 5, 2018. [47] D. Uly anov, A. V edaldi, and V. Lempitsky , “Instance normalization: the missing ingredien t for fast stylization. cscv,” arXiv pr eprint arXiv:1607.08022 , 2017. 11 REFERENCES REFERENCES [48] P . Isola, J.-Y. Zh u, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial net works,” arXiv pr eprint , 2017. [49] J. Johnson, A. Alahi, and L. F ei-F ei, “P erceptual losses for real-time st yle transfer and super-resolution,” in Eur op e an Confer enc e on Computer Vision , pp. 694–711, Springer, 2016. [50] K. Simony an and A. Zisserman, “V ery deep conv olutional netw orks for large-scale image recognition,” arXiv pr eprint arXiv:1409.1556 , 2014. [51] D. P . Kingma and J. Ba, “Adam: A metho d for sto c hastic optimization,” arXiv pr eprint arXiv:1412.6980 , 2014. 12 REFERENCES REFERENCES App endix I: Regression T ables (1) (2) (3) (4) Log(Image Position) 0.0261*** 0.0259*** 0.0259*** 0.0255*** (0.0012) (0.0012) (0.0013) (0.0029) N 242216 192665 172434 55692 Mean Accuracy on 1 st Image 0.73 0.78 0.78 0.74 Mean Accuracy on 10 th Image 0.88 0.88 0.88 0.83 R 2 0.29 0.19 0.20 0.26 T able 1: Ordinary least squares regression with participant and image fixed effects ev aluating image p osition on users’ accuracy in identifying manipulated images. Robust s ta ndard errors clustered at the image level in paren theses. *, **, and *** indicates statistical significance at the 90, 95, and 99 p ercen t confidence interv als, resp ectiv ely . All columns include participant and image fixed effects. Column (1) includes all images (2) drops all users who submitted few er than 10 guesses and remov es all control im a ges where nothing was remo ved (3) drops all observ ations where a user has already seen a particular image (4) k eeps only the images qualitatively judged as very high quality . 13 REFERENCES REFERENCES (1) (2) (3) (4) 2nd 0.0507*** 0.0569*** 0.0571*** 0.0378*** (0.0042) (0.0059) (0.0060) (0.0131) 3rd 0.0672*** 0.0744*** 0.0746*** 0.0454*** (0.0048) (0.0060) (0.0059) (0.0123) 4th 0.0775*** 0.0888*** 0.0885*** 0.0686*** (0.0050) (0.0058) (0.0058) (0.0121) 5th 0.0859*** 0.0978*** 0.0967*** 0.0749*** (0.0052) (0.0062) (0.0064) (0.0129) 6th 0.0817*** 0.0962*** 0.0963*** 0.0613*** (0.0057) (0.0064) (0.0064) (0.0130) 7th 0.0900*** 0.1032*** 0.1039*** 0.0741*** (0.0056) (0.0064) (0.0065) (0.0134) 8th 0.1019*** 0.1120*** 0.1106*** 0.0904*** (0.0055) (0.0065) (0.0065) (0.0137) 9th 0.1028*** 0.1136*** 0.1134*** 0.0959*** (0.0055) (0.0063) (0.0063) (0.0142) 10th 0.1030*** 0.1135*** 0.1123*** 0.1014*** (0.0056) (0.0062) (0.0064) (0.0135) More than 10 0.1106*** 0.1215*** 0.1197*** 0.0985*** (0.0051) (0.0059) (0.0059) (0.0122) N 242216 192665 172434 55692 Mean Accuracy on 1 st Image 0.73 0.78 0.78 0.74 Mean Accuracy on 10 th Image 0.88 0.88 0.88 0.83 R 2 0.29 0.20 0.20 0.26 T able 2: Ordinary least squares regression with participant and image fixed effects ev aluating image p osition on users’ accuracy in identifying manipulated images. Robust s ta ndard errors clustered at the image level in paren theses. *, **, and *** indicates statistical significance at the 90, 95, and 99 p ercen t confidence interv als, resp ectiv ely . All columns include participant and image fixed effects. Column (1) includes all images (2) drops all users who submitted few er than 10 guesses and remov es all control im a ges where nothing was remo ved (3) drops all observ ations where a user has already seen a particular image (4) k eeps only the images qualitatively judged as very high quality . 14 REFERENCES REFERENCES (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) Log(Image P osition) 0.0477*** 0.0386*** 0.0565*** 0.0401*** 0.0460*** 0.0505*** 0.0367*** 0.0492*** 0.0410*** 0.0406*** (0.0029) (0.0034) (0.0044) (0.0061) (0.0043) (0.0049) (0.0050) (0.0054) (0.0028) (0.0034) High Subjective Quality In teraction -0.0076 (0.0066) High Subjective Quality -0.0879*** (0.0098) Low Accuracy Interaction -0.0044 (0.0081) Low Accuracy -0.2045*** (0.0120) Small Mask Interaction -0.0190** (0.0074) Small Mask -0.0551*** (0.0108) Low Entropy Interaction 0.0138* (0.0082) Low Entropy 0.0264** (0.0120) 1 Object Disappeared In teraction -0.0016 (0.0056) 1 Object Disappeared 0.0086 (0.0082) First Correct Interaction -0.0217*** (0.0035) First Correct -0.0017 (0.0037) Has P erson In teraction 0.0130** (0.0060) Has P erson 0.0028 (0.0088) F ast Completion Interaction -0.0108* (0.0066) F ast Completion 0.0430*** (0.0121) Mobile In teraction 0.0264*** (0.0067) Mobile -0.0753*** (0.0120) Right Placement Interaction 0.0088** (0.0043) Right Placement -0.0108 (0.0074) Constant 0.8377*** 0.8915*** 0.8249*** 0.7778*** 0.8021*** 0.8478*** 0.8051*** 0.7836*** 0.8184*** 0.8122*** (0.0043) (0.0050) (0.0065) (0.0090) (0.0064) (0.0061) (0.0073) (0.0091) (0.0043) (0.0054) N 51611 25637 25655 25868 51611 38454 51611 24963 51611 51611 R 2 0.04 0.11 0.03 0.02 0.01 0.01 0.01 0.02 0.02 0.01 T able 3: Ordinary least squares regression with image fixed effects ev aluating image position on users’ accuracy in identifying manipulated images. Robust standard errors clustered at the image lev el in parentheses. *, **, and *** indicates statistical significance at the 90, 95, and 99 p ercen t confidence in terv als, resp ectiv ely . All columns drop users who submitted fewer than 10 guesses, drop all control images where nothing w as remo ved, drop all guesses beyond each participants’ 10th guess, and include image fixed effects. 15 REFERENCES REFERENCES App endix I I: Supplemen tary Information Figure 5: End-to-end pip eline for targeted ob ject remov al following [38, 41] Figure 6: “Erase with AI” User Interfaces 16 REFERENCES REFERENCES Figure 7: “Detect F akes” User Interfaces Image Uploads Ob ject Coun t Order P erson 13450 1 Car 1229 6 Dog 1086 2 Cat 1082 3 Elephan t 185 4 Bicycle 158 7 Bird 139 22 Tie 120 31 Airplane 106 13 Stop Sign 99 8 Instagram Directed Crawls Ob ject Coun t Order P erson 6944 1 Cat 725 2 Dog 493 3 Elephan t 170 4 Car 162 6 Bicycle 71 7 Sheep 52 5 Stop Sign 31 8 Airplane 29 13 Sk ateb oard 25 10 T able 4: T op 10 T ar get Obje ct R emoval Selections for Uploaded Images and T argeted Instagram Crawls on Deep Angel. Each selection of an Instagram username initiated a targeted cra wl of Instagram for the three most recen tly uploaded images of the selected user. Figure 8: Photographic manipulation has long b een a tool of fascist go vernmen ts. On the left, Joseph Stalin is standing next to Nik olai Y ezhov who Stalin later ordered to b e executed and disapp eared from the photograph. In the middle, Mao Zedong is standing beside the “Gang of F our” who w ere arrested a month after Mao’s death and subsequently erased. On the righ t, Benito Mussolini strikes a heroic p ose on a horse while his trainer holds the horse steady . 17 REFERENCES REFERENCES Figure 9: Heat map of the world showing how many users came from eac h country . 23% of users are from the United States of America, 9% from F rance, 9% from United Kingdom, 6% from German y , 4% from Spain, 3% from China, 3% from Canada, 2% from Brazil, 2% from Australia, and 2% from Finland. 18 REFERENCES REFERENCES App endix I I Ia: Detecting Manipulation b y Image F eatures (a) Sub jective Qualit y (b) Entrop y (c) Area T ransformed (d) Device Figure 10: Histograms comparing the distribution of mean accuracy scores across images for four image features: sub jective quality , en tropy , image mask size, and user device. Figure 10 shows the distribution of mean accuracy scores across images v aries by image features. F or example, the set of images rated as high qualit y ha ve a mean accuracy score of 82% whereas the images rated as low qualit y ha ve a mean accuracy score of 92%. Lik ewise, the high qualit y images hav e a wider v ariance in accuracy scores than the low qualit y images. Another example indicating image characteristics’ role in image detection is the differential distribution in accuracy across images with high and lo w en tropy and large and small masks. The distributions in mean accuracy scores across devices is a less stark con trast than the other distribution comparisons, but here, we see that images viewed on mobile devices p erform are slightly less accurately identified. 19 REFERENCES REFERENCES App endix I I Ib: Unanc hored Ob ject Conjuring While p osing a risk to information online, these generative AI systems can also offer n ew p ossibilities for creativ e expression. F or example, the Creativ e A dv ersarial Net work learns art b y its styles and generates new art b y deviating from the st yles’ norms [43]. Likewise, interactiv e GANs (iGANS) can augment human creativity for artistic and design applications [44]. Th us, if ob jects can b e plausibly remov ed from images, then it is reasonable to imagine ob jects can b e plausibly generated in an image from which they nev er existed. As an extension to the Deep Angel pip eline, w e approac hed adding ob jects to images using image-to-image translation with conditional adversarial netw orks [45]. Since these neural netw orks learn a mapping from an input to an output image, we can train an image-to-image mo del using the manipulated images as inputs and the original submissions are outputs. While the model does not re-app ear ob jects as they w ere, the model pro duces resemblances of the missing ob jects. Images pro duced b y Deep Angel and AI Spirits (the rev ersal of Deep Angel) are on display at the online art gallery hosted b y the 2018 NeurIPS W orkshop on Mac hine Learning for Creativity and Design. As large-scale, paired datasets of creativ e conten t (such as the one presented here) b ecome increasingly common, and neural netw ork architectures for conten t generation b ecome more p o w erful, automated ob ject insertion into existing media will become a rich area for future w ork. Mo del With image-to-image translation, a latent representation of the structure an image can b e efficiently expressed in and generated for different con texts [44 – 46]. This latent structure is enco de in information like edges, shap e, size, texture, and color that are anc hored across contexts. By applying image-to-image translation to the results of the T ar get Obje ct R emoval pip eline, we force the mo del to learn b oth the structural representation for remo ved ob jects and their contextual lo cation. W e call this pro cess unanchored ob ject conjuring. F or the unanchored ob ject conjuring extension, the global comp onen t ( G 1 ) ( 7 × 7 Conv olution-InstanceNorm ReLU lay er with 32 filters and stride 1 [47]) in the top righ t of Figure 11 is first trained on do wnsampled images, then local component ( G 2 ) is concatenated to G 1 and the y are join tly trained on full resolution images. W e follo w the original pix2pixHD loss function whic h takes the form min G max D 1 ,D 2 ,D 3 X k =1 , 2 , 3 L GAN ( G, D k ) + λ V GG L V GG ( G ( x ) , y ) + λ f m X k =1 , 2 , 3 L f m ( G, D k ) where L GAN ( · ) is adversarial loss [48], L f m ( · ) is the feature matching loss pix2pixHD used to stabilize training and L V GG ( · ) is the p erceptual loss based on V GG features [49, 50]. W e train the model using the Adam solver with a learning rate η = 0 . 0002 for 200 ep ochs [51]. η is fixed for the first half of training (epo c hs 0 to 100) and then η linearly decays to 0 for the second half (ep o c hs 101 to 200). All weigh ts w ere initialized b y sampling from a Gaussian distribution with µ = 0 and σ = 0 . 02 [46]. W e used a PyT orch implementation with a batc h size of 4 on an Nvidia Geforce GTX Titan X with 8 cores. Data W e filtered all images uploaded to Deep Angel to 5,634 images where p eople were selected to be remo v ed. W e man ually filtered these images to the 1000 b est manipulations based on qualitative judgements. Then, w e resized and cropp ed images to 1024 × 1024 . W e trained these images following the pix2pixHD image-to-image translation arc hitecture, whic h yields improv ed photorealism due to its coarse-to-fine generators, multi-scale discrimination and improv ed adversarial loss [46]. Figure 11 sho ws the arc hitecture for this extended pipeline. This unanchored ob ject conjuring tec hnique can b e used to create a new class of art that com bine existing photographs with GAN-style imagery . In addition, the reconstructions provide a tec hnique for interpreting the mo del and the underlying dataset b y rev ealing where remo v ed ob jects systematically app ear. 20 REFERENCES REFERENCES Figure 11: The top ro w displa ys 4 input images and the b ottom rows displays the modeled output based on the unanc hored ob ject conjuring pipeline. The images on the left are considered reconstructions b ecause they are part of the paired training sample and the images on the right are considered creations b ecause they are not part of the training dataset. 21
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment