인공지능 조작 이미지 탐지, 학습을 통한 인간 능력 향상
본 연구는 15,000명 이상의 온라인 참여자를 대상으로, AI가 자동으로 객체를 제거한 이미지와 원본 이미지를 쌍으로 제시하고 정답 피드백을 제공함으로써 조작된 미디어를 식별하는 능력이 어떻게 향상되는지를 실험했다. 이미지 순서를 무작위화한 덕분에 노출 횟수와 정확도 사이의 인과관계를 추정할 수 있었으며, 10장의 이미지만 본 후에도 평균 정확도가 10%포인트 상승하는 등 학습 효과가 뚜렷하게 나타났다. 이미지 품질, 변형 비율, 디바이스 종…
저자: Matthew Groh, Ziv Epstein, Nick Obradovich
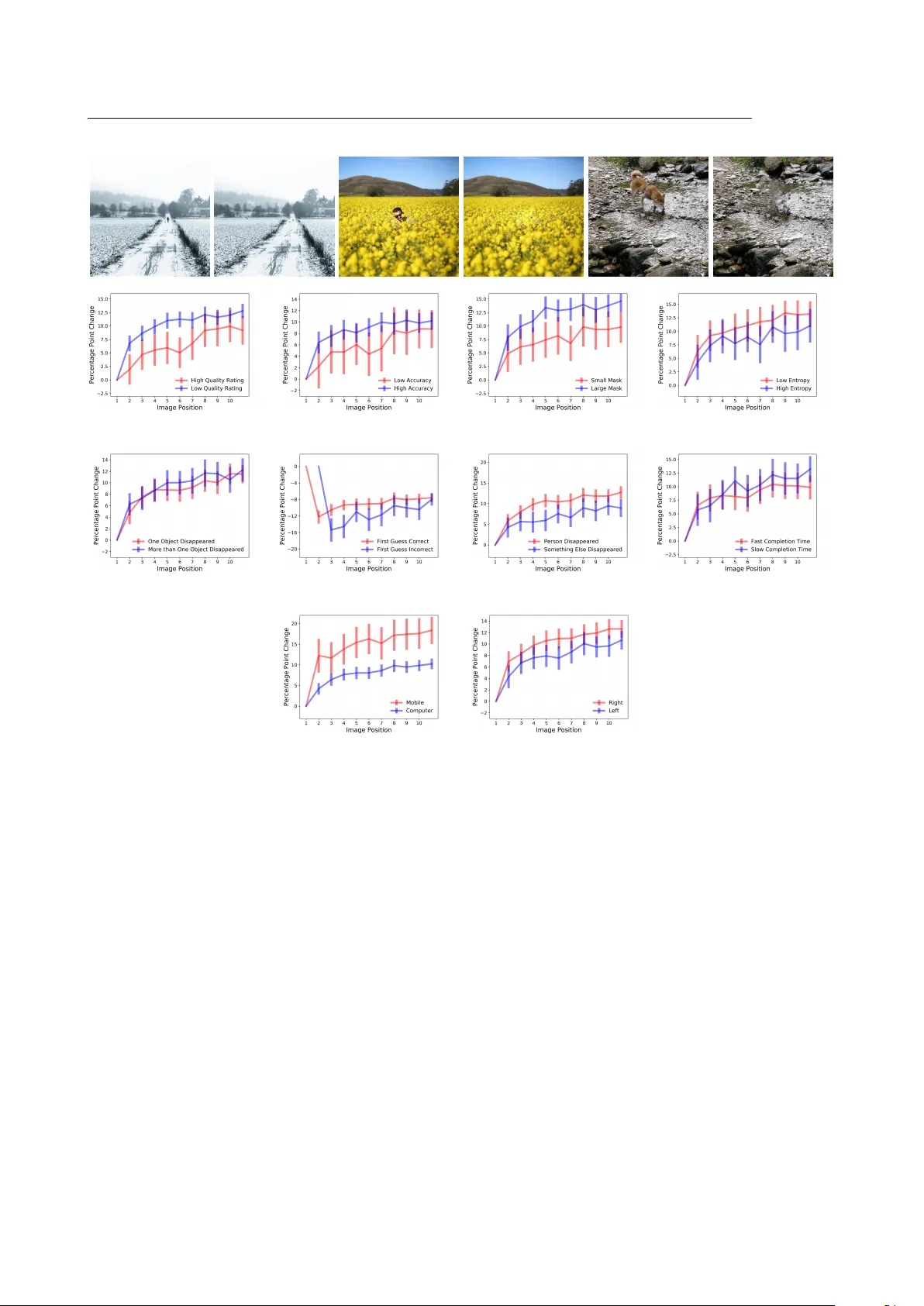
이 논문은 인공지능이 자동으로 객체를 제거해 만든 ‘machine‑manipulated’ 이미지가 대중에게 얼마나 쉽게 구별되는지를 대규모 온라인 실험을 통해 조사한다. 연구팀은 먼저 이미지에서 특정 객체를 자연스럽게 지우는 딥러닝 모델을 개발하고, 이를 ‘Deep Angel’이라는 웹 플랫폼에 배포하였다. 사용자는 웹사이트에서 두 장의 이미지를 동시에 보게 되며, 하나는 원본(2014 년 MS‑COCO 데이터셋)이고 다른 하나는 모델이 조작한 이미지이다. 참가자는 어느 이미지가 조작되었는지를 선택하고, 선택 후에는 정답이 즉시 공개되어 피드백을 받는다.
실험은 2018년 8월부터 2019년 5월까지 진행됐으며, 총 242 216번의 추측이 16 542개의 고유 IP 주소(개별 사용자)로부터 수집되었다. 평균 정확도는 86%였으며, 최소 10번 이상 추측한 7 576명의 참가자를 대상으로 하면 첫 번째 이미지에서 78%의 정확도를 보였고, 열 번째 이미지에서는 88%까지 상승했다. 이는 단순히 직관적인 판단이 아니라 반복적인 노출과 즉각적인 피드백을 통해 학습이 이루어졌음을 의미한다.
학습 곡선을 정량화하기 위해 두 가지 회귀모형을 적용했다. 첫 번째는 로그 변환된 이미지 순서(log T)를 독립변수로 하는 모델로, 순서가 한 단위 증가할 때 정확도가 3%포인트 상승한다는 결과를 도출했다(p < 0.01). 두 번째는 이미지 순서별 더미변수를 포함한 모델로, 처음 10번의 이미지마다 평균 1%포인트씩 정확도가 향상된 것으로 나타났다. 두 모델 모두 이미지 고정효과와 사용자 고정효과를 포함했으며, 오류는 이미지 수준에서 클러스터링하였다.
학습 속도에 영향을 미치는 요인으로는 이미지 품질, 변형된 영역 비율, 이미지 엔트로피, 변형된 객체 수, 그리고 사용자의 디바이스 종류가 분석되었다. 주관적 품질 평점이 낮은(눈에 띄는 아티팩트가 있는) 이미지에서는 초기 정확도가 다소 낮았지만, 학습 속도는 오히려 빨랐으며, 엔트로피가 낮고 변형 영역이 작은 ‘미세 조작’ 이미지가 가장 큰 학습 효과를 보였다. 이는 사용자가 섬세한 차이를 인식하면서 일반화 능력을 키우는 과정으로 해석될 수 있다.
디바이스별 차이도 두드러졌다. 모바일 사용자는 화면 확대·축소 기능을 활용해 이미지 세부를 자세히 관찰할 수 있기 때문에, 컴퓨터 사용자보다 일관되게 높은 학습률을 보였으며, 이는 9 ~ 10번째 이미지에서도 통계적으로 유의했다(p < 0.05). 또한 초기에 정답을 맞춘 참가자는 이후 학습 속도가 약 2%포인트 빠르게 증가했으며, 이는 메타인지적 자신감이 추가 학습을 촉진한다는 가설을 뒷받침한다.
연구는 몇 가지 제한점을 인정한다. 첫째, 실험에 사용된 조작은 특정 객체 제거 모델에 한정돼 있어, 텍스트‑투‑이미지, 딥페이크 영상 등 다른 AI 조작 유형에 대한 일반화가 어려울 수 있다. 둘째, IP 기반 사용자 식별은 동일 IP를 공유하는 경우를 구분하지 못하므로, 실제 개인별 학습 효과가 정확히 측정되지 않을 가능성이 있다. 셋째, 실험 환경이 웹 기반 게임 형태이기 때문에, 실제 뉴스 소비 상황과는 차이가 있다.
그럼에도 불구하고, 대규모 무작위화 실험과 정교한 통계 모델링을 통해 인간이 AI 조작을 인식하는 능력이 노출과 피드백을 통해 실질적으로 향상될 수 있음을 실증했다. 이는 디지털 미디어 리터러시 교육에 ‘노출‑피드백’ 루프를 도입함으로써, 대중이 AI 생성 가짜 콘텐츠에 대해 보다 비판적이고 정확한 판단을 할 수 있게 할 가능성을 제시한다. 향후 연구는 다양한 AI 조작 유형, 장기적인 학습 지속성, 그리고 실제 언론 환경에서의 적용 가능성을 탐구함으로써, 인공지능 시대의 정보 생태계 보호 전략을 구체화할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기