Non-Autoregressive Neural Text-to-Speech
In this work, we propose ParaNet, a non-autoregressive seq2seq model that converts text to spectrogram. It is fully convolutional and brings 46.7 times speed-up over the lightweight Deep Voice 3 at synthesis, while obtaining reasonably good speech qu…
Authors: Kainan Peng, Wei Ping, Zhao Song
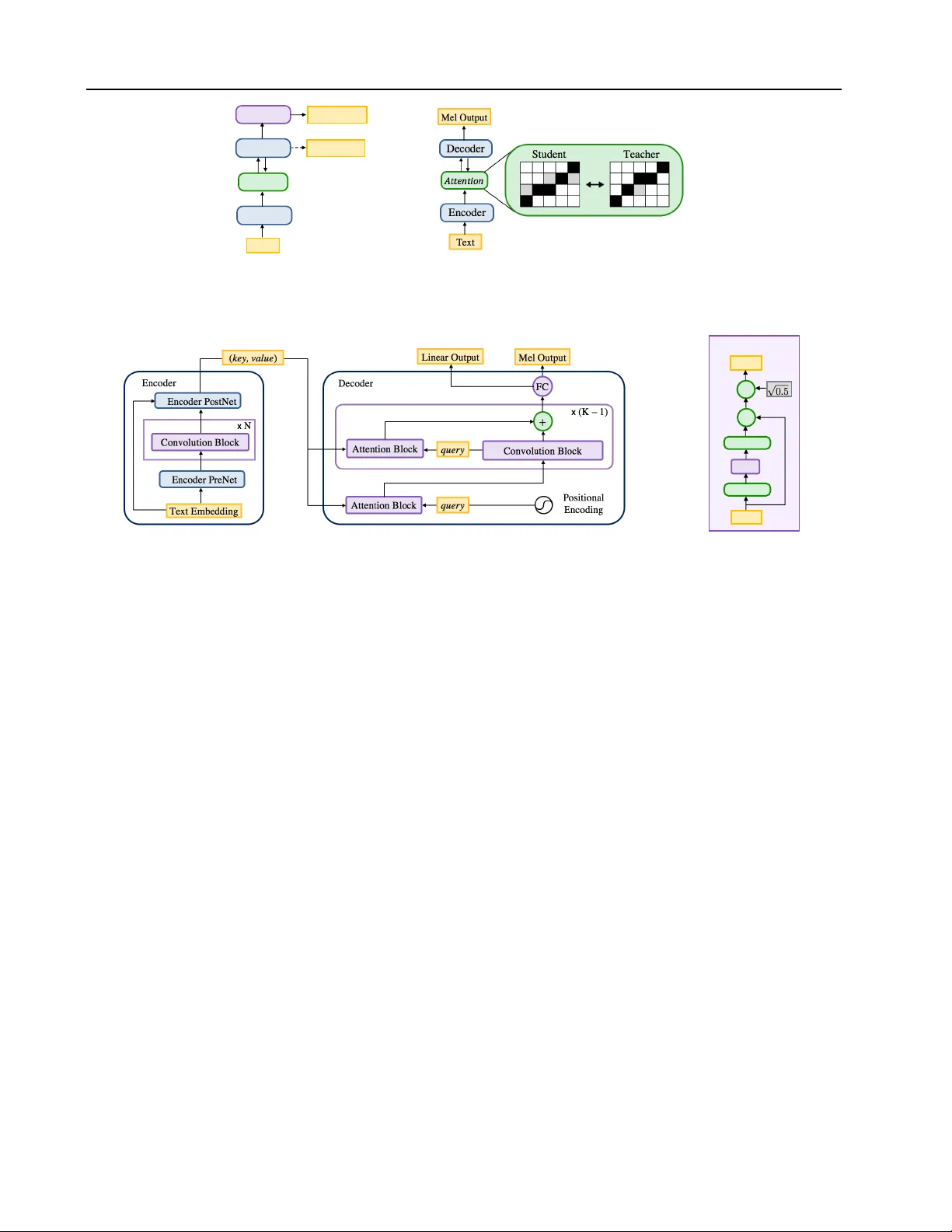
Non-A utor egr essiv e Neural T ext-to-Speech Kainan Peng ∗ 1 W ei Ping ∗ 1 Zhao Song ∗ 1 Kexin Zhao ∗ 1 Abstract In this work, we propose ParaNet, a non- autoregressi v e seq2seq model that con verts text to spectrogram. It is fully con v olutional and brings 46 . 7 times speed-up over the lightweight Deep V oice 3 at synthesis, while obtaining rea- sonably good speech quality . ParaNet also pro- duces stable alignment between text and speech on the challenging test sentences by iterati v ely im- proving the attention in a layer-by-layer manner . Furthermore, we build the parallel text-to-speech system and test v arious parallel neural v ocoders, which can synthesize speech from text through a single feed-forward pass. W e also explore a nov el V AE-based approach to train the in verse autor e gressive flow (IAF) based parallel v ocoder from scratch, which av oids the need for distilla- tion from a separately trained W a v eNet as pre vi- ous work. 1. Introduction T ext-to-speech (TTS), also called speech synthesis, has long been a vital tool in a variety of applications, such as human- computer interactions, virtual assistant, and content cre- ation. T raditional TTS systems are based on multi-stage hand-engineered pipelines ( T aylor , 2009 ). In recent years, deep neural networks based autore gressi ve models ha v e at- tained state-of-the-art results, including high-fidelity audio synthesis ( van den Oord et al. , 2016 ), and much simpler seq2seq pipelines ( Sotelo et al. , 2017 ; W ang et al. , 2017 ; Ping et al. , 2018b ). In particular, one of the most popular neural TTS pipeline (a.k.a. “end-to-end") consists of two components ( Ping et al. , 2018b ; Shen et al. , 2018 ): ( i ) an au- toregressi v e seq2seq model that generates mel spectrogram from text, and ( ii ) an autoregressi v e neural vocoder (e.g., W a veNet) that synthesizes raw wa v eform from mel spectro- * Equal contrib ution . 1 Baidu Research, 1195 Bordeaux Dr , Sunnyv ale, CA. Speech samples can be found in: https:// parallel- neural- tts- demo.github.io/ . Correspon- dence to: W ei Ping . Pr oceedings of the 37 th International Conference on Machine Learning , V ienna, Austria, PMLR 119, 2020. Copyright 2020 by the author(s). gram. This pipeline requires much less expert knowledge and only needs pairs of audio and transcript as training data. Howe ver , the autore gressi ve nature of these models makes them quite slo w at synthesis, because the y operate sequen- tially at a high temporal resolution of w av eform samples and spectrogram. Most recently , several models are proposed for parallel wa veform generation (e.g., van den Oord et al. , 2018 ; Ping et al. , 2018a ; Prenger et al. , 2019 ; Kumar et al. , 2019 ; Bi ´ nko wski et al. , 2020 ; Ping et al. , 2020 ). In the end- to-end pipeline, the models (e.g., ClariNet, W av eFlo w) still rely on autoregressi ve component to predict spectrogram fea- tures (e.g., 100 frames per second). In the linguistic feature- based pipeline, the models (e.g., Parallel W av eNet, GAN- TTS) are conditioned on aligned linguistic features from phoneme duration model and F0 from frequency model, which are recurrent or autoregressi ve models. Both of these TTS pipelines can be slow at synthesis on modern hardware optimized for parallel ex ecution. In this work, we present a fully parallel neural TTS sys- tem by proposing a non-autoregressi ve te xt-to-spectrogram model. Our major contributions are as follo ws: 1. W e propose ParaNet, a non-autore gressi ve attention- based architecture for text-to-speech, which is fully con- volutional and con verts text to mel spectrogram. It runs 254.6 times faster than real-time at synthesis on a 1080 T i GPU, and brings 46 . 7 times speed-up ov er its autore- gressi ve counterpart ( Ping et al. , 2018b ), while obtaining reasonably good speech quality using neural vocoders. 2. ParaNet distills the attention from the autoregressi ve text-to-spectrogram model, and iterati vely refines the alignment between te xt and spectrogram in a layer-by- layer manner . It can produce more stable attentions than autoregressi ve Deep V oice 3 ( Ping et al. , 2018b ) on the challenging test sentences, because it does not have the discrepancy between the teacher-forced training and autoregressi v e inference. 3. W e b uild the fully parallel neural TTS system by com- bining ParaNet with parallel neural vocoder , thus it can generate speech from text through a single feed-forw ard pass. W e in v estigate se veral parallel vocoders, including the distilled IAF vocoder ( Ping et al. , 2018a ) and W av e- Glow ( Prenger et al. , 2019 ). T o explore the possibility of training IAF vocoder without distillation , we also Non-A utor egr essive Neural T ext-to-Speech propose an alternati ve approach, W a v eV AE, which can be trained from scratch within the variational autoen- coder (V AE) frame work ( Kingma & W elling , 2014 ). W e or ganize the rest of paper as follows. Section 2 dis- cusses related work. W e introduce the non-autoregressi ve ParaNet architecture in Section 3 . W e discuss parallel neural vocoders in Section 4 , and report experimental settings and results in Section 5 . W e conclude the paper in Section 6 . 2. Related work Neural speech synthesis has obtained the state-of-the-art results and gained a lot of attention. Sev eral neural TTS systems were proposed, including W a v eNet ( v an den Oord et al. , 2016 ), Deep V oice ( Arık et al. , 2017a ), Deep V oice 2 ( Arık et al. , 2017b ), Deep V oice 3 ( Ping et al. , 2018b ), T acotron ( W ang et al. , 2017 ), T acotron 2 ( Shen et al. , 2018 ), Char2W av ( Sotelo et al. , 2017 ), V oiceLoop ( T aig- man et al. , 2018 ), W aveRNN ( Kalchbrenner et al. , 2018 ), ClariNet ( Ping et al. , 2018a ), and T ransformer TTS ( Li et al. , 2019 ). In particular , Deep V oice 3, T acotron and Char2W av employ seq2seq framework with the attention mechanism ( Bahdanau et al. , 2015 ), yielding much simpler pipeline compared to traditional multi-stage pipeline. Their excellent extensibility leads to promising results for sev- eral challenging tasks, such as voice cloning ( Arik et al. , 2018 ; Nachmani et al. , 2018 ; Jia et al. , 2018 ; Chen et al. , 2019 ). All of these state-of-the-art systems are based on autoregressi v e models. RNN-based autoregressiv e models, such as T acotron and W aveRNN ( Kalchbrenner et al. , 2018 ), lack parallelism at both training and synthesis. CNN-based autoregressi ve models, such as Deep V oice 3 and W aveNet, enable parallel processing at training, b ut they still operate sequentially at synthesis since each output element must be generated before it can be passed in as input at the next time-step. Re- cently , there are some non-autoregressiv e models proposed for neural machine translation. Gu et al. ( 2018 ) trains a feed-forward neural network conditioned on fertility val- ues, which are obtained from an external alignment system. Kaiser et al. ( 2018 ) proposes a latent variable model for fast decoding, while it remains autoregressi v eness between latent variables. Lee et al. ( 2018 ) iterati v ely refines the output sequence through a denoising autoencoder frame- work. Arguably , non-autoregressi ve model plays a more important role in text-to-speech, where the output speech spectrogram usually consists of hundreds of time-steps for a short text input with a few words. Our work is one of the first non-autoregressi ve seq2seq model for TTS and pro- vides as much as 46 . 7 times speed-up at synthesis o ver its autoregressi v e counterpart ( Ping et al. , 2018b ). There is a concurrent work ( Ren et al. , 2019 ), which is based on the autoregressiv e transformer TTS ( Li et al. , 2019 ) and can generate mel spectrogram in parallel. Our ParaNet is fully con v olutional and lightweight. In contrast to Fast- Speech, it has half of model parameters, requires smaller batch size (16 vs. 64) for training and provides faster speed at synthesis (see T able 2 for detailed comparison). Flow-ba sed generative models ( Rezende & Mohamed , 2015 ; Kingma et al. , 2016 ; Dinh et al. , 2017 ; Kingma & Dhariwal , 2018 ) transform a simple initial distribution into a more com- plex one by applying a series of in vertible transformations. In previous work, flow-based models have obtained state- of-the-art results for parallel w av eform synthesis ( v an den Oord et al. , 2018 ; Ping et al. , 2018a ; Prenger et al. , 2019 ; Kim et al. , 2019 ; Y amamoto et al. , 2019 ; Ping et al. , 2020 ). V ariational autoencoder (V AE) ( Kingma & W elling , 2014 ; Rezende et al. , 2014 ) has been applied for representation learning of natural speech for years. It models either the generativ e process of raw wav eform ( Chung et al. , 2015 ; van den Oord et al. , 2017 ), or spectrograms ( Hsu et al. , 2019 ). In pre vious work, autoregressi ve or recurrent neural networks are employed as the decoder of V AE ( Chung et al. , 2015 ; van den Oord et al. , 2017 ), but the y can be quite slow at synthesis. In this work, we employ a feed-forward IAF as the decoder , which enables parallel wa v eform synthesis. 3. T ext-to-spectrogram model Our parallel TTS system has two components: 1) a feed- forward text-to-spectrogram model, and 2) a parallel w av e- form synthesizer conditioned on mel spectrogram. In this section, we first present an autoregressiv e model deri v ed from Deep V oice 3 (D V3) ( Ping et al. , 2018b ). W e then in- troduce ParaNet, a non-autore gressi ve te xt-to-spectrogram model (see Figure 1 ). 3.1. A utoregressiv e ar chitecture Our autoregressi v e model is based on D V3, a con v olutional text-to-spectrogram architecture, which consists of three components: • Encoder : A con volutional encoder , which takes text in- puts and encodes them into internal hidden representation. • Decoder : A causal conv olutional decoder , which de- codes the encoder representation with an attention mech- anism to log-mel spectragrams in an autore gressive man- ner with an ` 1 loss. It starts with a 1 × 1 con v olution to preprocess the input log-mel spectrograms. • Con verter : A non-causal con v olutional post processing network, which processes the hidden representation from the decoder using both past and future context informa- tion and predicts the log-linear spectrograms with an ` 1 loss. It enables bidirectional processing. All these components use the same 1-D con volution bloc k Non-A utor egr essive Neural T ext-to-Speech Text Encoder Decoder Converter Linear output Attention Mel output (a) (b) Figure 1. (a) Autoregressi v e seq2seq model. The dashed line depicts the autoregressi v e decoding of mel spectrogram at inference. (b) Non-autoregressi ve P araNet model, which distills the attention from a pretrained autoregressi ve model. Convolution Block Input Conv. + ⨉ Output Dropout GLU (a) (b) Figure 2. (a) Architecture of ParaNet. Its encoder provides ke y and value as the textual representation. The first attention block in decoder gets positional encoding as the query and is followed by non-causal con v olution blocks and attention blocks. (b) Conv olution block appears in both encoder and decoder . It consists of a 1-D conv olution with a gated linear unit (GLU) and a residual connection. with a gated linear unit as in D V3 (see Figure 2 (b) for more details). The major difference between our model and D V3 is the decoder architecture. The decoder of DV3 has mul- tiple attention-based layers, where each layer consists of a causal con v olution block follo wed by an attention block. T o simplify the attention distillation described in Section 3.3.1 , our autoregressi v e decoder has only one attention block at its first layer . W e find that reducing the number of attention blocks does not hurt the generated speech quality in general. 3.2. Non-autoregr essiv e architectur e The proposed ParaNet (see Figure 2 ) uses the same encoder architecture as the autoregressiv e model. The decoder of ParaNet, conditioned solely on the hidden representation from the encoder, predicts the entire sequence of log-mel spectrograms in a feed-forward manner . As a result, both its training and synthesis can be done in parallel. Specially , we make the follo wing major architecture modifications from the autoregressi v e text-to-spectrogram model to the non-autoregressi v e model: 1. Non-autoregr essive decoder : W ithout the autoregres- siv e generativ e constraint, the decoder can use non- causal con v olution blocks to take adv antage of fu- ture conte xt information and to impro ve model per- formance. In addition to log-mel spectrograms, it also predicts log-linear spectrograms with an ` 1 loss for slightly better performance. W e also remov e the 1 × 1 con v olution at the be ginning, because the decoder does not take log-mel spectrograms as input. 2. No con verter : Non-autoregressi v e model removes the non-causal conv erter since it already employs a non- causal decoder . Note that, the major motiv ation of introducing non-causal converter in DV3 is to refine the decoder predictions based on bidirectional context information provided by non-causal con volutions. 3.3. Parallel attention mechanism It is challenging for the feed-forward model to learn the ac- curate alignment between the input text and output spectro- gram. In particular , we need the full parallelism within the attention mechanism. For e xample, the location-sensiti v e at- tention ( Chorowski et al. , 2015 ; Shen et al. , 2018 ) improv es attention stability , but it performs sequentially at both train- ing and synthesis, because it uses the cumulati v e attention weights from pre vious decoder time steps as an additional feature for the next time step. Previous non-autoregressi ve decoders rely on an external alignment system ( Gu et al. , 2018 ), or an autoregressi ve latent variable model ( Kaiser Non-A utor egr essive Neural T ext-to-Speech Figure 3. Our ParaNet iterativ ely refines the attention alignment in a layer-by-layer way . One can see the 1st layer attention is mostly dominated by the positional encoding prior . It becomes more and more confident about the alignment in the subsequent layers. et al. , 2018 ). In this work, we present se veral simple & ef fecti ve tech- niques, which could obtain accurate and stable attention alignment. In particular , our non-autoregressiv e decoder can iterativ ely refine the attention alignment between text and mel spectrogram in a layer -by-layer manner as illus- trated in Figure 3 . Specially , the decoder adopts a dot- product attention mechanism and consists of K attention blocks (see Figure 2 (a)), where each attention block uses the per-time-step query v ectors from con v olution block and per-time-step ke y vectors from encoder to compute the at- tention weights ( Ping et al. , 2018b ). The attention block computes context vectors as the weighted av erage of the value vectors from the encoder . The non-autoregressiv e decoder starts with an attention block, in which the query vectors are solely positional encoding (see Section 3.3.2 for details). The first attention block then provides the input for the con v olution block at the next attention-based layer . 3 . 3 . 1 . A T T E N T I O N D I S T I L L A T I O N W e use the attention alignments from a pretrained autore- gressiv e model to guide the training of non-autoregressi v e model. Specifically , we minimize the cross entropy between the attention distributions from the non-autoregressi ve ParaNet and a pretrained autoregressi ve teacher . W e denote the attention weights from the non-autore gressi v e ParaNet as W ( k ) i,j , where i and j index the time-step of encoder and decoder respecti vely , and k refers to the k -th attention block within the decoder . Note that, the attention weights { W ( k ) i,j } M i =1 form a v alid distribution. W e compute the atten- tion loss as the av erage cross entropy between the P araNet and teacher’ s attention distributions: l atten = − 1 K N K X k =1 N X j =1 M X i =1 W t i,j log W ( k ) i,j , (1) where W t i,j are the attention weights from the autoregressi v e teacher , M and N are the lengths of encoder and decoder , respectiv ely . Our final loss function is a linear combination of l atten and ` 1 losses from spectrogram predictions. W e set the coefficient of l atten as 4 , and other coefficients as 1 in all experiments. 3 . 3 . 2 . P O S I T I O N A L E N C O D I N G W e use a similar positional encoding as in D V3 at ev ery attention block ( Ping et al. , 2018b ). The positional encod- ing is added to both ke y and query v ectors in the attention block, which forms an inducti ve bias for monotonic atten- tion. Note that, the non-autore gressi ve model solely relies on its attention mechanism to decode mel spectrograms from the encoded te xtual features, without an y autore gres- siv e input. This makes the positional encoding ev en more crucial in guiding the attention to follow a monotonic pro- gression ov er time at the beginning of training. The posi- tional encodings h p ( i, k ) = sin ( ω s i / 10000 k / d ) (for ev en i ), and cos ( ω s i / 10000 k / d ) (for odd i ), where i is the time-step index, k is the channel index, d is the total number of chan- nels in the positional encoding, and ω s is the position r ate which indicates the average slope of the line in the attention distribution and roughly corresponds to the speed of speech. W e set ω s in the following w ays: • For the autoregressi v e teacher, ω s is set to one for the positional encoding of query . For the ke y , it is set to the av eraged ratio of the time-steps of spectrograms to the time-steps of textual features, which is around 6 . 3 across our training dataset. T aking into account that a reduction factor of 4 is used to simplify the learning of attention mechanism ( W ang et al. , 2017 ) , ω s is simply set as 6 . 3 / 4 for the key at both training and synthesis. • For ParaNet, ω s is also set to one for the query , while ω s for the ke y is calculated differently . At training, ω s is set to the ratio of the lengths of spectrograms and text for each indi vidual training instance, which is also divided by a reduction factor of 4 . At synthesis, we need to specify the length of output spectrogram and the corresponding ω s , which actually controls the speech rate of the generated audios (see Section II on demo website). In all of our experiments, we simply set ω s to be 6 . 3 / 4 as in autoregressi ve model, and the length of output spectrogram as 6 . 3 / 4 times the length of input te xt. Non-A utor egr essive Neural T ext-to-Speech Such a setup yields an initial attention in the form of a diagonal line and guides the non-autoregressi ve decoder to refine its attention layer by layer (see Figure 3 ). 3 . 3 . 3 . A T T E N T I O N M A S K I N G Inspired by the attention masking in Deep V oice 3, we pro- pose an attention masking scheme for the non-autoregressiv e ParaNet at synthesis: • For each query from decoder , instead of computing the softmax over the entire set of encoder ke y vectors, we compute the softmax only over a fix ed windo w centered around the tar get position and going forw ard and back- ward se v eral time-steps (e.g., 3). The targ et position is calculated as b i query × 4 / 6 . 3 e , where i query is the time- step index of the query vector , and be is the rounding operator . W e observe that this strategy reduces serious attention er- rors such as repeating or skipping words, and also yields clearer pronunciations, thanks to its more condensed atten- tion distribution. Note that, this attention masking is shared across all attention blocks once it is generated, and does not prev ent the parallel synthesis of the non-autoregressi ve model. 4. Parallel wa vef orm model As an indispensable component in our parallel neural TTS system, the parallel wav eform model con verts the mel spec- trogram predicted from ParaNet into the ra w wa v eform. In this section, we discuss se veral e xisting parallel wa v eform models, and explore a ne w alternati v e in the system. 4.1. Flow-based wavef orm models In v erse autoregressi ve flow (IAF) ( Kingma et al. , 2016 ) is a special type of normalizing flow where each in v ertible transformation is based on an autoregressi ve neural net- work. IAF performs synthesis in parallel and can easily reuse the expressi v e autoregressi v e architecture, such as W aveNet ( van den Oord et al. , 2016 ), which leads to the state-of-the-art results for speech synthesis ( van den Oord et al. , 2018 ; Ping et al. , 2018a ). Howe v er , the likelihood ev aluation in IAF is autoregressiv e and slo w , thus previous training methods rely on probability density distillation from a pretrained autoregressi v e W av eNet. This two-stage dis- tillation process complicates the training pipeline and may introduce pathological optimization ( Huang et al. , 2019 ). RealNVP ( Dinh et al. , 2017 ) and Glow ( Kingma & Dhari- wal , 2018 ) are dif ferent types of normalizing flows, where both synthesis and likelihood e v aluation can be performed in parallel by enforcing bipartite architecture constraints. Most recently , both of them were applied as parallel neu- ral vocoders and can be trained from scratch ( Prenger et al. , 2019 ; Kim et al. , 2019 ). Howe ver , these models are less expressi v e than their autoregressi v e and IAF coun- terparts. One can find a detailed analysis in W aveFlo w paper ( Ping et al. , 2020 ). In general, these bipartite flows require lar ger number of layers and hidden units, which lead to huge number of parameters. For example, a W aveG- low vocoder ( Prenger et al. , 2019 ) has 87.88M parameters, whereas IAF vocoder has much smaller footprint with only 2.17M parameters ( Ping et al. , 2018a ), making it more pre- ferred in production deployment. 4.2. W av eV AE Giv en the adv antage of IAF vocoder , it is interesting to in v estigate whether it can be trained without the density distillation. One related w ork trains IAF within an auto- encoder ( Huang et al. , 2019 ). Our method uses the V AE framew ork, thus it is termed as W av eV AE. In contrast to van den Oord et al. ( 2018 ) and Ping et al. ( 2018a ), W ave- V AE can be trained from scratch by jointly optimizing the encoder q φ ( z | x , c ) and decoder p θ ( x | z , c ) , where z is la- tent variables and c is the mel spectrogram conditioner . W e omit c for concise notation hereafter . 4 . 2 . 1 . E N C O D E R The encoder of W aveV AE q φ ( z | x ) is parameterized by a Gaussian autoregressi v e W aveNet ( Ping et al. , 2018a ) that maps the ground truth audio x into the same length la- tent representation z . Specifically , the Gaussian W av eNet models x t giv en the previous samples x 0 to decouple the global v ariation, which will make optimization process easier . Given the observed x , the q φ ( z | x ) admits parallel sampling of latents z . One can build the connection between the encoder of W aveV AE and the teacher model of ClariNet, as both of them use a Gaussian W aveNet to guide the training of IAF for parallel wa ve generation. 4 . 2 . 2 . D E C O D E R Our decoder p θ ( x | z ) is parameterized by the one-step- ahead predictions from an IAF ( Ping et al. , 2018a ). W e let z (0) = z and apply a stack of IAF transformations Non-A utor egr essive Neural T ext-to-Speech from z (0) → . . . z ( i ) → . . . z ( n ) , and each transformation z ( i ) = f ( z ( i − 1) ; θ ) is defined as, z ( i ) = z ( i − 1) · σ ( i ) + µ ( i ) , (2) where µ ( i ) t = µ ( z ( i − 1) i σ ( j ) . (3) Lastly , we set x = · σ tot + µ tot , where ∼ N (0 , I ) . Thus, p θ ( x | z ) = N ( µ tot , σ tot ) . For the generative process, we use the standard Gaussian prior p ( z ) = N (0 , I ) . 4 . 2 . 3 . T R A I N I N G O B J E C T I V E W e maximize the evidence lower bound (ELBO) for ob- served x in V AE, max φ,θ E q φ ( z | x ) log p θ ( x | z ) − KL q φ ( z | x ) || p ( z ) , (4) where the KL di ver gence can be calculated in closed-form as both q φ ( z | x ) and p ( z ) are Gaussians, KL q φ ( z | x ) || p ( z ) = X t log 1 ε + 1 2 ε 2 − 1 + x t − µ ( x
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment