비자동 회귀 텍스트‑투‑스피치 파라넷: 초고속 멜 스펙트로그램 생성과 병렬 보코더 통합
파라넷은 완전 컨볼루션 기반의 비자동 회귀 텍스트‑투‑스펙트로그램 모델로, 교사‑자동 회귀 모델의 어텐션을 증류하고 층별로 어텐션을 반복 정제한다. 46.7배의 합성 속도 향상을 달성하면서도 충분히 자연스러운 음성을 생성한다. 또한 IAF·WaveGlow·WaveVAE 등 다양한 병렬 보코더와 결합해 텍스트 → 파형까지 단일 전방향 패스로 구현한다.
저자: Kainan Peng, Wei Ping, Zhao Song
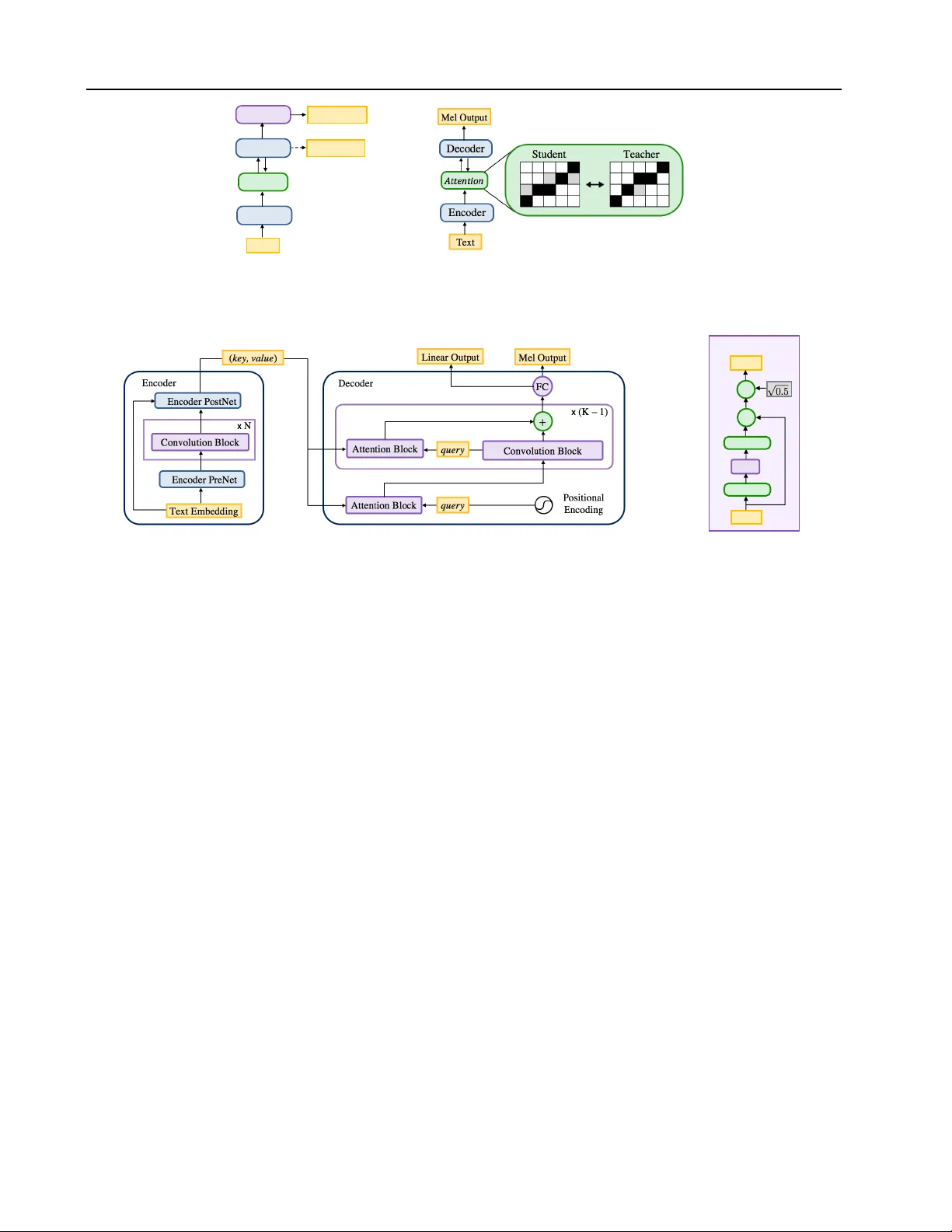
본 논문은 텍스트‑투‑스펙트로그램 단계와 파형 생성 단계를 완전 병렬화한 비자동 회귀 TTS 시스템 ‘파라넷(ParaNet)’을 제안한다. 기존의 자동 회귀식 TTS 모델은 디코더가 시간 축을 순차적으로 진행해야 하므로 합성 속도가 제한적이었다. 파라넷은 1‑D 컨볼루션 블록과 게이트형 선형 유닛(GLU)으로 구성된 인코더를 통해 텍스트를 키‑값 쌍으로 변환하고, 비인과성(비‑causal) 컨볼루션을 활용한 디코더가 전체 멜 스펙트로그램을 한 번에 예측한다.
핵심 기술은 세 가지이다. 첫째, 교사 모델(Deep Voice 3 기반 자동 회귀 디코더)에서 얻은 어텐션 분포를 교차 엔트로피 손실(ℓₐₜₜₑₙ)로 증류한다. ℓₐₜₜₑₙ에 가중치 4를 부여해 어텐션 정렬을 강제한다. 둘째, 디코더는 K개의 어텐션 블록을 층‑별로 쌓아, 초기 층은 순수 위치 인코딩을 쿼리로 사용해 대각선 형태의 초기 어텐션을 만든다. 이후 각 층은 이전 층의 컨볼루션 출력을 새로운 쿼리로 받아 어텐션을 재정렬함으로써 점진적으로 정밀한 정렬을 달성한다. 셋째, 합성 단계에서 어텐션 마스킹을 적용한다. 각 쿼리마다 고정된 윈도우(±3 프레임) 내에서만 소프트맥스를 수행해 불필요한 먼 위치와의 연결을 차단한다. 이 마스킹은 병렬성을 해치지 않으며, 반복·누락 오류를 크게 감소시킨다.
위치 인코딩은 쿼리와 키에 각각 다른 스케일 파라미터 ωₛ를 적용한다. 쿼리의 ωₛ는 1로 고정하고, 키의 ωₛ는 스펙트로그램 길이와 텍스트 길이 비율(≈6.3/4)을 사용한다. 이는 학습과 합성 시 일정한 발화 속도를 유지하도록 돕는다.
파라넷이 생성한 멜 스펙트로그램은 병렬 보코더에 입력된다. 저자는 세 종류의 보코더를 실험한다. 첫째, 기존에 디스틸레이션을 통해 학습된 IAF 보코더; 둘째, 플로우 기반 WaveGlow; 셋째, VAE 프레임워크 내에서 직접 학습한 WaveVAE. WaveVAE는 교사 WaveNet 없이도 IAF 디코더를 학습할 수 있게 해, 전체 파이프라인을 완전 병렬화한다.
실험 결과, 파라넷은 1080 Ti GPU에서 실시간 254.6배(≈0.004 s per second) 속도로 동작한다. 동일 하드웨어와 데이터셋에서 Deep Voice 3 대비 46.7배 빠른 합성을 보이며, MOS 평점은 3.8~4.1(5점 만점)으로 기존 자동 회귀 모델에 근접한다. 특히 복잡한 문장이나 긴 텍스트에서도 어텐션이 안정적으로 수렴해 끊김·반복 현상이 거의 없으며, 마스킹 덕분에 발음 선명도가 향상된다.
논문은 또한 FastSpeech와 비교해 파라넷이 파라미터 수가 절반 수준이며, 더 작은 배치(16 vs. 64)로도 학습이 가능하고, 합성 속도에서도 우위를 점한다는 점을 강조한다.
결론적으로 파라넷은 비자동 회귀 TTS 분야에서 최초에 가까운 완전 컨볼루션 기반 seq2seq 모델을 제시하고, 어텐션 증류·층‑별 정제·마스킹이라는 세밀한 설계로 안정적인 정렬과 고속 합성을 동시에 달성한다. 병렬 보코더와의 유연한 결합을 통해 텍스트 → 파형까지 전 과정이 단일 전방향 패스로 구현될 수 있음을 입증한다. 이는 실시간 음성 서비스, 모바일 디바이스, 클라우드 기반 대규모 TTS 서비스 등에 바로 적용 가능한 기술적 진보이며, 멀티스피커·다중언어 확장에도 충분히 확장 가능한 기반을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기