Distributed k-Means and k-Median Clustering on General Topologies
This paper provides new algorithms for distributed clustering for two popular center-based objectives, k-median and k-means. These algorithms have provable guarantees and improve communication complexity over existing approaches. Following a classic …
Authors: Maria Florina Balcan, Steven Ehrlich, Yingyu Liang
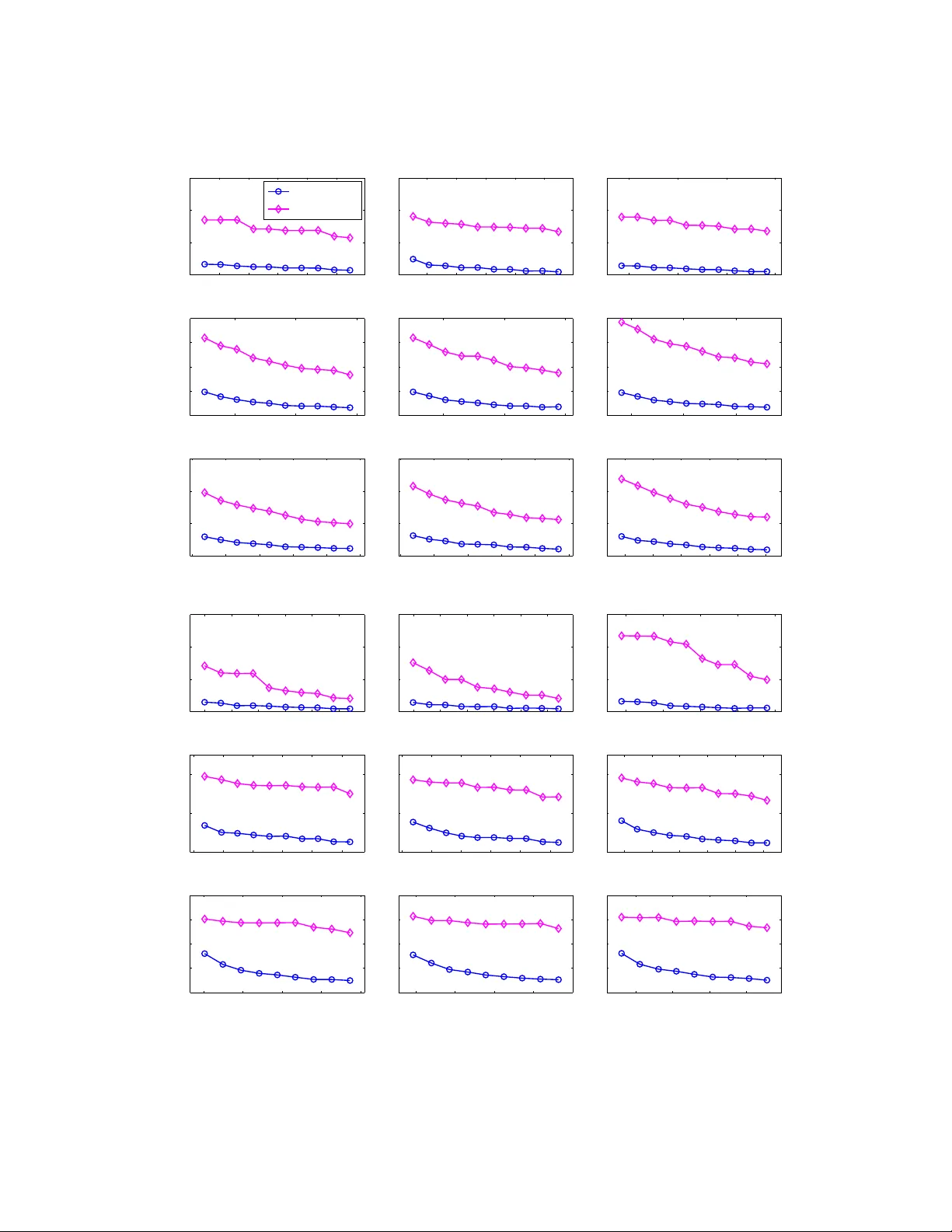
Distrib uted k -Means and k -Median Clustering on General T opologies Maria Florina Balcan ∗ Ste ven Ehrlich † Y ingyu Liang ‡ Abstract This paper provides new algorithms for distributed clustering for two popular center-based objec- tiv es, k -median and k -means. These algorithms have pro v able guarantees and improv e communication complexity over existing approaches. Follo wing a classic approach in clustering by [ 20 ], we reduce the problem of finding a clustering with low cost to the problem of finding a coreset of small size. W e provide a distrib uted method for constructing a global coreset which improv es over the pre vious methods by reducing the communication comple xity , and which works o ver general communication topologies. Experimental results on large scale data sets show that this approach outperforms other coreset-based distributed clustering algorithms. 1 Intr oduction Most classic clustering algorithms are designed for the centralized setting, but in recent years data has become distrib uted ov er dif ferent locations, such as distrib uted databases [ 29 , 10 ], images and videos o ver networks [ 28 ], surveillance [ 16 ] and sensor networks [ 9 , 17 ]. In many of these applications the data is inherently distributed because, as in sensor networks, it is collected at different sites. As a consequence it has become crucial to de velop clustering algorithms which are ef fecti ve in the distrib uted setting. Se veral algorithms for distrib uted clustering hav e been proposed and empirically tested. Some of these algorithms [15, 30, 11] are direct adaptations of centralized algorithms which rely on statistics that are easy to compute in a distributed manner . Other algorithms [ 21 , 24 ] generate summaries of local data and transmit them to a central coordinator which then performs the clustering algorithm. No theoretical guarantees are provided for the clustering quality in these algorithms, and the y do not try to minimize the communication cost. Additionally , most of these algorithms assume that the distributed nodes can communicate with all other sites or that there is a central coordinator that communicates with all other sites. In this paper , we study the problem of distrib uted clustering where the data is distributed across nodes whose communication is restricted to the edges of an arbitrary graph. W e provide algorithms with small communication cost and prov able guarantees on the clustering quality . Our technique for reducing communi- cation in general graphs is based on the construction of a small set of points which act as a proxy for the entire data set. An -cor eset is a weighted set of points whose cost on any set of centers is approximately the cost of the original data on those same centers up to accuracy . Thus an approximate solution for the coreset is also an approximate solution for the original data. Coresets ha ve previously been studied in the centralized setting ∗ Georgia Institute of T echnology , ninamf@cc.gatech.edu † Georgia Institute of T echnology , sehrlich@cc.gatech.edu ‡ Georgia Institute of T echnology , yliang39@gatech.edu 1 ([ 20 , 13 ]) but ha ve also recently been used for distributed clustering as in [ 31 ] and as implied by [ 14 ]. In this work, we propose a distrib uted algorithm for k -means and k -median, by which each node constructs a local portion of a global coreset. Communicating the approximate cost of a global solution to each node is enough for the local construction, leading to lo w communication cost ov erall. The nodes then share the local portions of the coreset, which can be done ef ficiently in general graphs using a message passing approach. More precisely , in Section 3, we propose a distributed coreset construction algorithm based on local approximate solutions. Each node computes an approximate solution for its local data, and then constructs the local portion of a coreset using only its local data and the total cost of each node’ s approximation. F or constant, this builds a coreset of size ˜ O ( k d + nk ) for k -median and k -means when the data lies in d dimensions and is distrib uted o ver n sites 1 . If there is a central coordinator among the n sites, then clustering can be performed on the coordinator by collecting the local portions of the coreset with a communication cost equal to the coreset size ˜ O ( k d + nk ) . For distrib uted clustering over general connected topologies, we propose an algorithm based on the distributed coreset construction and a message-passing approach, whose communication cost improv es o ver pre vious coreset-based algorithms. W e provide a detailed comparison belo w . Experimental results on large scale data sets show that our algorithm performs well in practice. For a fixed amount of communication, our algorithm outperforms other coreset construction algorithms. Comparison to Other Coreset Algorithms: Since coresets summarize local information they are a natural tool to use when trying to reduce communication complexity . If each node constructs an -coreset on its local data, then the union of these coresets is clearly an -coreset for the entire data set. Unfortunately the size of the coreset in this approach increases greatly with the number of nodes. Another approach is the one presented in [ 31 ]. Its main idea is to approximate the union of local coresets with another coreset. They assume nodes communicate over a rooted tree, with each node passing its coreset to its parent. Because the approximation factor of the constructed coreset depends on the quality of its component coresets, the accurac y a coreset needs (and thus the ov erall communication complexity) scales with the height of this tree. Although it is possible to find a spanning tree in any communication network, when the graph has lar ge diameter e very tree has lar ge height. In particular many natural netw orks such as grid networks hav e a large diameter ( Ω( √ n ) for grids) which greatly increases the size of coresets which must be communicated across the lo wer levels of the tree. W e show that it is possible to construct a global coreset with lo w communication ov erhead. This is done by distrib uting the coreset construction procedure rather than combining local coresets. The communication needed to construct this coreset is negligible – just a single v alue from each data set representing the approximate cost of their local optimal clustering. Since the sampled global -coreset is the same size as any local -coreset, this leads to an improvement of the communication cost ov er the other approaches. See Figure 1 for an illustration. The constructed coreset is smaller by a factor of n in general graphs, and is independent of the communication topology . This method excels in sparse networks with large diameters, where the previous approach in [ 31 ] requires coresets that are quadratic in the size of the diameter for k -median and quartic for k -means; see Section 4 for details. [ 14 ] also merge coresets using coreset construction, b ut they do so in a model of parallel computation and ignore communication costs. Balcan et al. [ 6 ] and Daume et al. [ 12 ] consider communication complexity questions arising when doing classification in distrib uted settings. In concurrent and independent work, Kannan and V empala [ 22 ] study sev eral optimization problems in distributed settings, including k -means clustering under an interesting 1 For k -median and k -means in general metric spaces, the bound on the size of the coreset can be obtained by replacing d with the logarithm of the total number of points. The analysis for general metric spaces is largely the same as that for d dimensional Euclidean space, so we will focus on Euclidean space and point out the difference when needed. 2 5 6 3 1 2 4 C 2 C 4 C 5 C 6 C 3 5 6 (a) Zhang et al.[31] 5 6 3 1 2 4 5 2 3 4 6 1 (b) Our Construction Figure 1: (a) Each node computes a coreset on the weighted pointset for its o wn data and its subtrees’ coresets. (b) Local constant approximation solutions are computed, and the costs of these solutions are used to coordinate the construction of a local portion on each node. separability assumption. Section 6 provides a re view of additional related work. 2 Pr eliminaries Let d ( p, q ) denote the Euclidean distance between any two points p, q ∈ R d . The goal of k -means clustering is to find a set of k centers x = { x 1 , x 2 , . . . , x k } which minimize the k -means cost of data set P ⊆ R d . Here the k -means cost is defined as cost( P , x ) = P p ∈ P d ( p, x ) 2 where d ( p, x ) = min x ∈ x d ( p, x ) . If P is a weighted data set with a weighting function w , then the k -means cost is defined as P p ∈ P w ( p ) d ( p, x ) 2 . Similarly , the k -median cost is defined as P p ∈ P d ( p, x ) . Both k -means and k -median cost functions are kno wn to be NP -hard to minimize (see for example [ 2 ]). For both objectiv es, there exist se veral readily av ailable polynomial-time algorithms that achie ve constant approximation solutions (see for e xample [23, 26]). In the distributed clustering task, we consider a set of n nodes V = { v i , 1 ≤ i ≤ n } which communicate on an undirected connected graph G = ( V , E ) with m = | E | edges. More precisely , an edge ( v i , v j ) ∈ E indicates that v i and v j can communicate with each other . Here we measure the communication cost in number of points transmitted, and assume for simplicity that there is no latency in the communication. On each node v i , there is a local set of data points P i , and the global data set is P = S n i =1 P i . The goal is to find a set of k centers x which optimize cost( P , x ) while keeping the computation efficient and the communication cost as lo w as possible. Our focus is to reduce the total communication cost while preserving theoretical guarantees for approximating clustering cost. 2.1 Coresets For the distributed clustering task, a natural approach to a void broadcasting raw data is to generate a local summary of the relev ant information. If each site computes a summary for their o wn data set and then communicates this to a central coordinator, a solution can be computed from a much smaller amount of data, drastically reducing the communication. 3 In the centralized setting, the idea of summarization with respect to the clustering task is captured by the concept of coresets [ 20 , 13 ]. A coreset is a set of points, together with a weight for each point, such that the cost of this weighted set approximates the cost of the original data for any set of k centers. The formal definition of coresets is: Definition 1 ( coreset ) . An -cor eset for a set of points P with r espect to a center-based cost function is a set of points S and a set of weights w : S → R such that for any set of centers x , (1 − )cost( P , x ) ≤ X p ∈ S w ( p )cost( p, x ) ≤ (1 + )cost( P, x ) . In the centralized setting, man y coreset construction algorithms ha ve been proposed for k -median, k - means and some other cost functions. F or example, for points in R d , algorithms in [ 13 ] construct coresets of size t = ˜ O ( k d/ 4 ) for k -means and coresets of size t = ˜ O ( k d/ 2 ) for k -median. In the distributed setting, it is natural to ask whether there exists an algorithm that constructs a small coreset for the entire point set but still has low communication cost. Note that the union of coresets for multiple data sets is a coreset for the union of the data sets. The immediate construction of combining the local coresets from each node would produce a global coreset whose size was lar ger by a factor of n , greatly increasing the communication complexity . W e present a distributed algorithm which constructs a global coreset the same size as the centralized construction and only needs a single v alue 2 communicated to each node. This serves as the basis for our distributed clustering algorithm. 3 Distrib uted Coreset Construction In this section, we design a distributed coreset construction algorithm for k -means and k -median. Note that the underlying technique can be extended to other additi ve clustering objectiv es such as k -line median. T o gain some intuition on the distributed coreset construction algorithm, we briefly re view the coreset construction algorithm in [ 13 ] in the centralized setting. The coreset is constructed by computing a constant approximation solution for the entire data set, and then sampling points proportional to their contributions to the cost of this solution. Intuitiv ely , the points close to the nearest centers can be approximately represented by the nearest centers while points far away cannot be well represented. Thus, points should be sampled with probability proportional to their contributions to the cost. Directly adapting the algorithm to the distributed setting would require computing a constant approxima- tion solution for the entire data set. W e show that a global coreset can be constructed in a distributed fashion by estimating the weight of the entire data set with the sum of local approximations. W e first compute a local approximation solution for each local data set, and communicate the total costs of these local solutions. Then we sample points proportional to their contributions to the cost of their local solutions. At the end of the algorithm, the coreset consists of the sampled points and the centers in the local solutions. The coreset points are distributed o ver the nodes, so we call it distrib uted coreset. See Algorithm 1 for details. Theorem 1. F or distributed k -means and k -median clustering on a gr aph, ther e e xists an algorithm suc h that with pr obability at least 1 − δ , the union of its output on all nodes is an -cor eset for P = S n i =1 P i . The size of the cor eset is O ( 1 4 ( k d log ( k d ) + log 1 δ ) + nk log nk δ ) for k -means, and O ( 1 2 ( k d log ( k d ) + log 1 δ ) + nk ) for k -median. The total communication cost is O ( mn ) . 2 The value that is communicated is the sum of the costs of approximations to the local optimal clustering. This is guaranteed to be no more than a constant factor times lar ger than the optimal cost. 4 Algorithm 1 Communication aw are distributed coreset construction Input: Local datasets { P i , 1 ≤ i ≤ n } , parameter t (number of points to be sampled). Round 1: on each node v i ∈ V • Compute a constant approximation B i for P i . Communicate cost( P i , B i ) to all other nodes. Round 2: on each node v i ∈ V • Set t i = t cost( P i ,B i ) P n j =1 cost( P j ,B j ) and m p = cost( p, B i ) , ∀ p ∈ P i . • Pick a non-uniform random sample S i of t i points from P i , where for e very q ∈ S i and p ∈ P i , we hav e q = p with probability m p / P z ∈ P i m z . Let w q = P i P z ∈ P i m z tm q for each q ∈ S i . • F or ∀ b ∈ B i , let P b = { p ∈ P i : d ( p, b ) = d ( p, B i ) } , w b = | P b | − P q ∈ P b ∩ S w q . Output: Distributed coreset: points S i ∪ B i with weights { w q : q ∈ S i ∪ B i } , 1 ≤ i ≤ n . As described belo w , the distributed coreset construction can be achie ved by using Algorithm 1 with appropriate t , namely O ( 1 4 ( k d log ( k d ) + log 1 δ ) + nk log nk δ ) for k -means and O ( 1 2 ( k d log ( k d ) + log 1 δ )) for k -median. The formal proofs are described in the following subsections. 3.1 Proof of Theor em 1: k -median The analysis relies on the definition of the dimension of a function space and a sampling lemma. Definition 2 ([ 13 ]) . Let F be a finite set of functions from a set P to R ≥ 0 . F or f ∈ F , let B ( f , r ) = { p : f ( p ) ≤ r } . The dimension of the function space dim( F , P ) is the smallest inte ger d such that for any G ⊆ P , { G ∩ B ( f , r ) : f ∈ F, r ≥ 0 } ≤ | G | d . Suppose we draw a sample S according to { m p : p ∈ P } , namely for e very q ∈ S and e very p ∈ P , we hav e q = p with probability m p P z ∈ P m z . Set the weights of the points as w p = P z ∈ P m z m p | S | for p ∈ P . Then for any f ∈ F , the expectation of the weighted cost of S equals the cost of the original data P : E X q ∈ S w q f ( q ) = X q ∈ S E [ w q f ( q )] = X q ∈ S X p ∈ P Pr[ q = p ] w p f ( p ) = X q ∈ S X p ∈ P m p P z ∈ P m z P z ∈ P m z m p | S | f ( p ) = X q ∈ S X p ∈ P 1 | S | f ( p ) = X p ∈ P f ( p ) . The follo wing lemma shows that if the sample size is lar ge enough, then we also hav e concentration for any f ∈ F . The lemma is implicit in [13] and we include the proof in the appendix for completeness. Lemma 1. F ix a set F of functions f : P → R ≥ 0 . Let S be a sample drawn i.i.d. fr om P accor ding to { m p : p ∈ P } , namely , for every q ∈ S and every p ∈ P , we have q = p with pr obability m p P z ∈ P m z . Let w p = P z ∈ P m z m p | S | for p ∈ P . F or a suf ficiently larg e c , if | S | ≥ c 2 dim( F , P ) log dim( F , P ) + log 1 δ then with pr obability at least 1 − δ, ∀ f ∈ F : P p ∈ P f ( p ) − P q ∈ S w q f ( q ) ≤ P p ∈ P m p max p ∈ P f ( p ) m p . 5 T o get a small bound on the dif ference between P p ∈ P f ( p ) and P q ∈ S w q f ( q ) , we need to choose m p such that max p ∈ P f ( p ) m p is bounded. More precisely , if we choose m p = max f ∈ F f ( p ) , then the difference is bounded by P p ∈ P m p . W e first consider the centralized setting and revie w ho w [ 13 ] applied the lemma to construct a coreset for k -median as in Definition 1. A natural approach is to apply this lemma directly to the cost, namely , to choose f x ( p ) := cost( p, x ) . The problem is that a suitable upper bound m p is not av ailable for cost( p, x ) . Howe ver , we can still apply the lemma to a different set of functions defined as follo ws. Let b p denote the closest center to p in the approximation solution. Aiming to approximate the error P p [cost( p, x ) − cost( b p , x )] rather than to approximate P p cost( p, x ) directly , we define f x ( p ) := cost( p, x ) − cost( b p , x ) + cost( p, b p ) , where cost( p, b p ) is added so that f x ( p ) ≥ 0 . Since 0 ≤ f x ( p ) ≤ 2cost( p, b p ) , we can apply the lemma to f x ( p ) and m p = 2cost( p, b p ) . The lemma then bounds the difference | P p ∈ P f x ( p ) − P q ∈ S w q f x ( q ) | by 2 P p ∈ P cost( p, b p ) , so we hav e an O ( ) -approximation. Note that P p ∈ P f x ( p ) − P q ∈ S w q f x ( q ) does not equal P p ∈ P cost( p, x ) − P q ∈ S w q cost( q , x ) . Ho we ver , it equals the dif ference between P p ∈ P cost( p, x ) and a weighted cost of the sampled points and the centers in the approximation solution. T o get a coreset as in Definition 1, we need to add the centers of the approximation solution with specific weights to the coreset. Then when the sample is sufficiently large, the union of the sampled points and the centers is an -coreset. Our ke y contribution in this paper is to sho w that in the distributed setting, it suf fices to choose b p from the local approximation solution for the local dataset containing p , rather than from an approximation solution for the global dataset. Furthermore, the sampling and the weighting of the coreset points can be done in a local manner . In the following, we provide a formal verification of our discussion abov e. W e have the follo wing lemma for k -median with F = { f x : f x ( p ) = d ( p, x ) − d ( b p , x ) + d ( p, b p ) , x ∈ ( R d ) k } . Lemma 2. F or k -median, the output of Algorithm 1 is an -cor eset with pr obability at least 1 − δ , if t ≥ c 2 dim( F , P ) log dim( F , P ) + log 1 δ for a sufficiently lar ge constant c . Pr oof. W e w ant to sho w that for any set of centers x the true cost for using these centers is well approximated by the cost on the weighted coreset. Note that our coreset has two types of points: sampled points p ∈ S = ∪ n i =1 S i with weight w p := P z ∈ P m z m p | S | and local solution centers b ∈ B = ∪ n i =1 B i with weight w b := | P b | − P p ∈ S ∩ P b w p . W e use b p to represent the nearest center to p in the local approximation solution. W e use P b to represent the set of points having b as their closest center in the local approximation solution. As mentioned abo ve, we construct f x to be the dif ference between the cost of p and the cost of b p on x so that Lemma 1 can be applied to f x . Note that 0 ≤ f x ( p ) ≤ 2 d ( p, b p ) by triangle inequality , and S is suf ficiently large and chosen according to weights m p = d ( p, b p ) , so the conditions of Lemma 1 are met. Then we hav e D = X p ∈ P f x ( p ) − X q ∈ S w q f x ( q ) ≤ 2 X p ∈ P m p = 2 X p ∈ P d ( p, b p ) = 2 n X i =1 d ( P i , B i ) ≤ O ( ) X p ∈ P d ( p, x ) where the last inequality follo ws from the fact that B i is a constant approximation solution for P i . Next, we sho w that the coreset is constructed such that D is exactly the dif ference between the true cost and the weighted cost of the coreset, which then leads to the lemma. Note that the centers are weighted such that X b ∈ B w b d ( b, x ) = X b ∈ B | P b | d ( b, x ) − X b ∈ B X q ∈ S ∩ P b w q d ( b, x ) = X p ∈ P d ( b p , x ) − X q ∈ S w q d ( b q , x ) . (1) 6 Also note that P p ∈ P m p = P q ∈ S w q m q , so D = X p ∈ P [ d ( p, x ) − d ( b p , x ) + m p ] − X q ∈ S w q [ d ( q , x ) − d ( b q , x ) + m q ] = X p ∈ P d ( p, x ) − X q ∈ S w q d ( q , x ) − X p ∈ P d ( b p , x ) − X q ∈ S w q d ( b q , x ) . (2) By plugging (1) into (2), we hav e D = X p ∈ P d ( p, x ) − X q ∈ S w q d ( q , x ) − X b ∈ B w b d ( b, x ) = X p ∈ P d ( p, x ) − X q ∈ S ∪ B w q d ( q , x ) which implies the lemma. In [ 13 ] it is sho wn that 3 dim( F , P ) = O ( k d ) . So by Lemma 2, when | S | ≥ O 1 2 ( k d log ( k d ) + log 1 δ ) , the weighted cost of S ∪ B approximates the k -median cost of P for any set of centers, then ( S ∪ B , w ) is an -coreset for P . The total communication cost is bounded by O ( mn ) , since e ven in the most general case when e very node only kno ws its neighbors, we can broadcast the local costs with O ( mn ) communication (see Algorithm 3). 3.2 Proof of Theor em 1: k -means W e hav e for k -means a similar lemma that when t = O ( 1 4 ( k d log ( k d ) + log 1 δ ) + nk log nk δ )) , the algorithm constructs an -coreset with probability at least 1 − δ . The key idea is the same as that for k -median: we use centers b p from the local approximation solutions as an approximation to the original data points p , and show that the error between the total cost and the weighted sample cost is approximately the error between the cost of p and its sampled cost (compensated by the weighted centers), which is sho wn to be small by Lemma 1. The ke y dif ference between k -means and k -median is that triangle inequality applies directly to the k - median cost. In particular , for the k -median problem note that cost( b p , p ) = d ( b p , p ) is an upper bound for the error of b p on any set of centers, i.e. ∀ x ∈ ( R d ) k , d ( b p , p ) ≥ | d ( p, x ) − d ( b p , x ) | = | cost( p, x ) − cost( b p , x ) | by triangle inequality . Then we can construct f x ( p ) := cost( p, x ) − cost( b p , x ) + d ( b p , p ) such that h p ( x ) is bounded. In contrast, for k -means, the error | cost( p, x ) − cost( b p , x ) | = | d ( p, x ) 2 − d ( b p , x ) 2 | does not hav e such an upper bound. The main change to the analysis is that we di vide the points into two categories: good points whose costs approximately satisfy the triangle inequality (up to a factor of 1 / ) and bad points. The good points for a fixed set of centers x are defined as G ( x ) = { p ∈ P : | cost( p, x ) − cost( b p , x ) | ≤ ∆ p } where the upper bound is ∆ p = cost( p,b p ) . Good points we can bound as before. For bad points we can sho w that while the difference in cost may be larger than cost( p, b p ) / , it must still be small, namely O ( min { cost( p, x ) , cost( b p , x ) } ) . 3 For both k -median and k -means in general metric spaces, dim( F , P ) = O ( k log | P | ) , so the bound for general metric spaces (including Euclidean space we focus on) can be obtained by replacing d with log | P | . 7 Formally , the functions f x ( p ) are restricted to be defined only o ver good points: f x ( p ) = ( cost( p, x ) − cost( b p , x ) + ∆ p if p ∈ G ( x ) , 0 otherwise. Then P p ∈ P cost( p, x ) − P q ∈ S ∪ B w q cost( q , x ) is decomposed into three terms: X p ∈ P f x ( p ) − X q ∈ S w q f x ( q ) (3) + X p ∈ P \ G ( x ) [cost( p, x ) − cost( b p , x ) + ∆ p ] (4) − X q ∈ S \ G ( x ) w q [cost( q , x ) − cost( b q , x ) + ∆ q ] (5) Lemma 1 bounds (3) by O ( )cost( P , x ) , but we need an accuracy of 2 to compensate for the 1 / factor in the upper bound, resulting in a O (1 / 4 ) factor in the sample comple xity . W e begin by bounding (4). Note that for each term in (4), | cost( p, x ) − cost( b p , x ) | > ∆ p since p 6∈ G ( x ) . Furthermore, p 6∈ G ( x ) only when p and b p are close to each other and far away from x . In Lemma 3 we use this to sho w that | cost( p, x ) − cost( b p , x ) | ≤ O ( ) min { cost( p, x ) , cost( b p , x ) } . The details are presented in the appendix. Using Lemma 3, (4) can be bounded by O ( ) P p ∈ P \ G ( x ) cost( p, x ) ≤ O ( )cost( P , x ) . Similarly , by the definition of ∆ q and Lemma 3, (5) is bounded by (5) ≤ X q ∈ S \ G ( x ) 2 w q | cost( q , x ) − cost( b q , x ) | ≤ O ( ) X q ∈ S \ G ( x ) w q cost( b q , x ) ≤ O ( ) X b ∈ B X q ∈ P b ∩ S w q cost( b, x ) . Note that the expectation of P q ∈ P b ∩ S w q is | P b | . By a sampling argument (Lemma 4), if t ≥ O ( nk log nk δ ) , then P q ∈ P b ∩ S w q ≤ 2 | P b | . Then (5) is bounded by O ( ) P b ∈ B cost( b, x ) | P b | = O ( ) P p ∈ P cost( b p , x ) where P p ∈ P cost( b p , x ) is at most a constant factor more than the optimum cost. Since each of (3),(4), and (5) is O ( )cost( P , x ) , we know that their sum is the same magnitude. Combin- ing the abov e bounds, we ha ve cost( P , x ) − P q ∈ S ∪ B w q cost( q , x ) ≤ O ( )cost( P , x ) . The proof is then completed by choosing a suitable , and bounding dim( F , P ) = O ( k d ) as in [13]. 4 Effect of Network T opology on Communication Cost In the pre vious section, we presented a distrib uted coreset construction algorithm. The coreset constructed can then be used as a proxy for the original data, and we can run any distributed clustering algorithm on it. In this paper , we discuss the approach of simply collecting all local portions of the distributed coreset and run non-distributed clustering algorithm on it. If there is a central coordinator in the communication graph, then we can simply send the local portions of the coreset to the coordinator which can perform the clustering task. The total communication cost is just the size of the coreset. 8 In this section, we consider the distrib uted clustering tasks where the nodes are arranged in some arbitrary connected topology , and can only communicate with their neighbors. W e propose a message passing approach for globally sharing information, and use it for collecting information for coreset construction and sharing the local portions of the coreset. W e also consider the special case when the graph is a rooted tree. Algorithm 2 Distributed clustering on a graph Input: { P i , 1 ≤ i ≤ n } : local datasets; { N i , 1 ≤ i ≤ n } : the neighbors of v i ; A α : an α -approximation algorithm for weighted clustering instances. Round 1: on each node v i • Construct its local portion D i of an / 2 -coreset by Algorithm 1, using Message-Passing for communicating the local costs. Round 2: on each node v i • Call Message-P assing( D i , N i ). • x = A α ( S j D j ) . Output: x Algorithm 3 Message-Passing( I i , N i ) Input: I i is the message, N i are the neighbors. • Let R i denote the information recei ved. Initialize R i = { I i } , and send I i to all the neighbors. • While R i 6 = { I j , 1 ≤ j ≤ n } : If recei ve message I j 6∈ R i , R i = R i ∪ { I j } and send I j to all the neighbors. 4.1 General Graphs W e now present the main result for distrib uted clustering on graphs. Theorem 2. Given an α -appr oximation algorithm for weighted k -means ( k -median r espectively) as a sub- r outine, ther e exists an algorithm that with pr obability at least 1 − δ outputs a (1 + ) α -appr oximation solution for distributed k -means ( k -median r espectively) clustering. The total communication cost is O ( m ( 1 4 ( k d log ( k d ) + log 1 δ ) + nk log nk δ )) for k -means, and O ( m ( 1 2 ( k d log ( k d ) + log 1 δ ) + nk )) for k -median. Pr oof. The details are presented in Algorithm 2. By Theorem 1, the output of Algorithm 1 is a coreset. Observe that in Algorithm 3, for an y j , I j propagates on the graph in a breadth-first-search style, so at the end e very node recei ves I j . This holds for all 1 ≤ j ≤ n , so all nodes has a copy of the coreset at the end, and thus the output is a (1 + ) α -approximation solution. 9 Also observ e that in Algorithm 3, for any node v i and j ∈ [ n ] , v i sends out I j once, so the communication of v i is | N i | × P n j =1 | I j | . The communication cost of Algorithm 3 is O ( m P n j =1 | I j | ) . Then the total communication cost of Algorithm 2 follo ws from the size of the coreset constructed. In contrast, an approach where each node constructs an -coreset for k -means and sends it to the other nodes incurs communication cost of ˜ O ( mnkd 4 ) . Our algorithm significantly reduces this. 4.2 Rooted T rees Our algorithm can also be applied on a rooted tree, and compares f av orably to other approaches in volving coresets [ 31 ]. W e can restrict message passing to operating along this tree, leading to the following theorem. Theorem 3. Given an α -appr oximation algorithm for weighted k -means ( k -median r espectively) as a subr outine, ther e e xists an algorithm that with pr obability at least 1 − δ outputs a (1 + ) α -appr oximation solution for distrib uted k -means ( k -median r espectively) clustering on a r ooted tr ee of height h . The total communication cost is O ( h ( 1 4 ( k d log ( k d ) + log 1 δ ) + nk log nk δ )) for k -means, and O ( h ( 1 2 ( k d log ( k d ) + log 1 δ ) + nk )) for k -median. Pr oof. W e can construct the distributed coreset using Algorithm 1. In the construction, the costs of the local approximation solutions are sent from e very node to the root, and the sum is sent to e very node by the root. After the construction, the local portions of the coreset are sent from e very node to the root. A local portion D i leads to a communication cost of O ( | D i | h ) , so the total communication cost is O ( h P n i =1 | D i | ) . Once the coreset is constructed at the root, the α -approximation algorithm can be applied centrally , and the results can be sent back to all nodes. Our approach impro ves the cost of ˜ O ( nh 4 kd 4 ) for k -means and the cost of ˜ O ( nh 2 kd 2 ) for k -median in [ 31 ] 4 . The algorithm in [ 31 ] b uilds on each node a coreset for the union of coresets from its children, and thus needs O ( /h ) accuracy to prevent the accumulation of errors. Since the coreset construction subroutine has quadratic dependence on 1 / for k -median (quartic for k -means), the algorithm then has quadratic dependence on h (quartic for k -means). Our algorithm does not build coreset on top of coresets, resulting in a better dependence on the height of the tree h . In a general graph, any rooted tree will have its height h at least as large as half the diameter . For sensors in a grid network, this implies h = Ω( √ n ) . In this case, our algorithm gains a significant improvement o ver existing algorithms. 5 Experiments In our experiments we seek to determine whether our algorithm is ef fectiv e for the clustering tasks and ho w it compares to the other distributed coreset algorithms 5 . W e present the k -means cost of the solution produced by our algorithm with varying communication cost, and compare to those of other algorithms when they use the same amount of communication. 4 Their algorithm used coreset construction as a subroutine. The construction algorithm they used builds coreset of size ˜ O ( nkh d log | P | ) . Throughout this paper , when we compare to [ 31 ] we assume they use the coreset construction technique of [ 13 ] to reduce their coreset size and communication cost. 5 Our theoretical analysis shows that our algorithm has better bounds on the communication cost. Since the bounds are from worst-case analysis, it is meaningful to verify that our algorithm also empirically outperforms other distrib uted coreset algorithms. 10 Data sets: Follo wing the setup of [ 31 , 5 ], for the synthetic data we randomly choose k = 5 centers from the standard Gaussian distribution in R 10 , and sample equal number of 20 , 000 points from the Gaussian distribution around each center . Note that, as in [ 31 , 5 ], we use the cost of the centers as a baseline for comparing the clustering quality . W e choose the follo wing r eal w orld data sets from [ 3 ]: Spam (4601 points in R 58 ), Pendigits (10992 points in R 16 ), Letter (20000 points in R 16 ), and ColorHistogram of the Corel Image data set (68040 points in R 32 ). W e use k = 10 for these data sets. W e further choose Y earPredictionMSD (515345 points in R 90 ) for larger scale e xperiments, and use k = 50 for this data set. Experimental Methodology: T o transform the centralized clustering data sets into distributed data sets we first generate a communication graph connecting local sites, and then partition the data into local data sets. T o ev aluate our algorithm, we consider several netw ork topologies and partition methods. The algorithms are e valuated on three types of communication graphs: random, grid, and preferential. The random graphs are Erd ¨ os-Renyi graphs G ( n, p ) with p = 0 . 3 , i.e. they are generated by including each potential edge independently with probability 0 . 3 . The preferential graphs are generated according to the preferential attachment mechanism in the Barab ´ asi-Albert model [ 1 ]. F or data sets Spam, Pendigits, and Letter , we use random/preferential graphs with 10 sites and 3 × 3 grid graphs. F or synthetic data set and ColorHistogram, we use random/preferential graphs with 25 sites and 5 × 5 grid graphs. For lar ge data set Y earPredictionMSD, we use random/preferential graphs with 100 sites and 10 × 10 grid graphs. The data is then distributed ov er the local sites. When the communication network is a random graph, we consider three partition methods: uniform, similarity-based, and weighted. In the uniform partition, each data point in the global data set is assigned to the local sites with equal probability . In the similarity-based partition, each site has an associated data point randomly selected from the global data. Each data point in the global data is then assigned to the site with probability proportional to its similarity to the associated point of the site, where the similarities are computed by Gaussian kernel function. In the weighted partition, each local site is assigned a weight chosen by | N (0 , 1) | and then each data point is distributed to the local sites with probability proportional to the site’ s weight. When the network is a grid graph, we consider the similarity-based and weighted partitions. When the network is a preferential graph, we consider the degree-based partition, where each point is assigned with probability proportional to the site’ s degree. T o measure the quality of the coreset generated, we run Lloyd’ s algorithm on the coreset and the global data respecti vely to get two solutions, and compute the ratio between the costs of the two solutions o ver the global data. The average ratio ov er 30 runs is then reported. W e compare our algorithm with COMBINE, the method of combining a coreset from each local data set, and with the algorithm of [ 31 ] (Zhang et al.). When running the algorithm of Zhang et al., we restrict the general communication network to a spanning tree by picking a root uniformly at random and performing a breadth first search. Results: Here we focus on the results of the lar gest data set Y earPredictionMSD, and in Appendix B we present the experimental results for all the data sets. Figure 2 shows the results o ver different network topologies and partition methods. W e observe that the algorithms perform well with much smaller coreset sizes than predicted by the theoretical bounds. F or example, to get 1 . 1 cost ratio, the coreset size and thus the communication needed is only 0 . 1% − 1% of the theoretical bound. In the uniform partition, our algorithm performs nearly the same as COMBINE. This is not surprising since our algorithm reduces to the COMBINE algorithm when each local site has the same cost and the two algorithms use the same amount of communication. In this case, since in our algorithm the sizes of the local samples are proportional to the costs of the local solutions, it samples the same number of points from each 11 COMBINE Our Algo k-means cost ratio × 10 7 1 . 6 1 . 8 2 2 . 2 1 . 05 1 . 1 1 . 15 (a) random graph, uniform × 10 7 1 . 7 1 . 8 1 . 9 2 2 . 1 2 . 2 2 . 3 1 . 04 1 . 06 1 . 08 1 . 1 1 . 12 1 . 14 1 . 16 1 . 18 1 . 2 (b) random graph, similarity-based × 10 7 1 . 6 1 . 7 1 . 8 1 . 9 2 2 . 1 2 . 2 1 . 04 1 . 06 1 . 08 1 . 1 1 . 12 1 . 14 1 . 16 1 . 18 1 . 2 (c) random graph, weighted k-means cost ratio communication cost × 10 6 2 2 . 2 2 . 4 2 . 6 2 . 8 1 . 05 1 . 1 1 . 15 (d) grid graph, similarity-based communication cost × 10 6 2 2 . 2 2 . 4 2 . 6 2 . 8 1 . 05 1 . 1 1 . 15 (e) grid graph, weighted communication cost × 10 6 2 . 2 2 . 4 2 . 6 2 . 8 1 . 05 1 . 1 1 . 15 (f) preferential graph, degree-based Figure 2: k -means cost (normalized by baseline) v .s. communication cost ov er graphs. The titles indicate the network topology and partition method. local data set. This is equi valent to the COMBINE algorithm with the same amount of communication. In the similarity-based partition, similar results are observ ed as it also leads to balanced local costs. Ho we ver , when the local sites ha ve significantly dif ferent costs (as in the weighted and degree-based partitions), our algorithm outperforms COMBINE. As observed in Figure 2, the costs of our solutions consistently improv e ov er those of COMBINE by 2% − 5% . Our algorithm then sa ves 10% − 20% communication cost to achie ve the same approximation ratio. Figure 3 shows the results ov er the spanning trees of the graphs. Our algorithm performs much better than the algorithm of Zhang et al., achieving about 20% improv ement in cost. This is due to the f act that their algorithm needs larger coresets to pre vent the accumulation of errors when constructing coresets from component coresets, and thus needs higher communication cost to achie ve the same approximation ratio. Similar results are observed on the other datasets, which are presented in Appendix B. 6 Additional Related W ork Many empirical algorithms adapt the centralized algorithms to the distributed setting. They generally provide no bound for the clustering quality or the communication cost. For instance, a technique is proposed in [ 15 ] to adapt sev eral iterati ve center -based data clustering algorithms including Lloyd’ s algorithm for k -means to the distributed setting, where suf ficient statistics instead of the raw data are sent to a central coordinator . This 12 Zhang et al. Our Algo k-means cost ratio × 10 7 1 . 6 1 . 8 2 2 . 2 1 1 . 1 1 . 2 1 . 3 1 . 4 1 . 5 (a) random graph, uniform × 10 7 1 . 7 1 . 8 1 . 9 2 2 . 1 2 . 2 2 . 3 1 1 . 05 1 . 1 1 . 15 1 . 2 1 . 25 1 . 3 1 . 35 1 . 4 (b) random graph, similarity-based × 10 7 1 . 6 1 . 7 1 . 8 1 . 9 2 2 . 1 2 . 2 1 1 . 05 1 . 1 1 . 15 1 . 2 1 . 25 1 . 3 1 . 35 1 . 4 (c) random graph, weighted k-means cost ratio communication cost × 10 6 2 2 . 2 2 . 4 2 . 6 2 . 8 1 1 . 1 1 . 2 1 . 3 1 . 4 (d) grid graph, similarity-based communication cost × 10 6 2 2 . 2 2 . 4 2 . 6 2 . 8 1 1 . 1 1 . 2 1 . 3 1 . 4 (e) grid graph, weighted communication cost × 10 6 2 . 2 2 . 4 2 . 6 2 . 8 1 1 . 1 1 . 2 1 . 3 1 . 4 (f) preferential graph, degree-based Figure 3: k -means cost (normalized by baseline) v .s. communication cost over the spanning trees of the graphs. The titles indicate the network topology and partition method. approach in volv es transferring data back and forth in each iteration, and thus the communication cost depends on the number of iterations. Similarly , the communication costs of the distrib uted clustering algorithms proposed in [ 11 ] and [ 30 ] depend on the number of iterations. Some other algorithms gather local summaries and then perform global clustering on the summaries. The distributed density-based clustering algorithm in [ 21 ] clusters and computes summaries for the local data at each node, and sends the local summaries to a central node where the global clustering is carried out. This algorithm only considers the flat tw o-tier topology . Some in-network aggregation schemes for computing statistics o ver distributed data are useful for such distributed clustering algorithms. For example, an algorithm is provided in [ 9 ] for approximate duplicate-sensiti ve aggre gates across distributed data sets, such as SUM. An algorithm is proposed in [ 17 ] for po wer-preserving computation of order statistics such as quantile. Se veral coreset construction algorithms ha ve been proposed for k -median, k -means and k -line median clustering [ 20 , 8 , 19 , 25 , 13 ]. For e xample, the algorithm in [ 13 ] constructs a coreset of size ˜ O ( k d/ 2 ) whose cost approximates that of the original data up to accurac y with respect to k -median in R d . All of these algorithms consider coreset construction in the centralized setting, while our construction algorithm is for the distributed setting. There has also been work attempting to parallelize clustering algorithms. [ 14 ] showed that coresets could be constructed in parallel and then merged together . Bahmani et al. [ 5 ] adapted k-means++ to the parallel setting. Their algorithm, k-means || , essentially builds O (1) -coreset of size O ( k log | P | ) . Howe ver , it cannot build -coreset for = o (1) , and thus can only guarantee constant approximation solutions. 13 There is also related w ork pro viding approximation solutions for k -median based on random sampling [ 7 ]. Particularly , they showed that giv en a sample of size ˜ O ( k 2 ) drawn i.i.d. from the data, there e xists an algorithm that outputs a solution with an average cost bounded by twice the optimal a verage cost plus an error bound . If we con vert it to a multiplicativ e approximation factor , the factor depends on the optimal av erage cost. When there are outlier points far away from all other points, the optimal av erage cost can be very small after normalization, then the multiplicati ve approximation factor is large. The coreset approach provides better guarantees. Additionally , their approach is not applicable to k -means. Balcan et al. [ 6 ] and Daume et al. [ 12 ] consider fundamental communication complexity questions arising when doing classification in distrib uted settings. In concurrent and independent w ork, V empala et al. [ 22 ] study sev eral optimization problems in distributed settings, including k -means clustering under an interesting separability assumption. Acknowledgements This work was supported by ONR grant N00014-09-1-0751, AFOSR grant F A9550- 09-1-0538, and by a Google Research A ward. W e thank Le Song for generously allowing us to use his computer cluster . Refer ences [1] R. Albert and A.-L. Barab ´ asi. Statistical mechanics of complex netw orks. Revie ws of Modern Physics , 2002. [2] P . A wasthi and M. Balcan. Center based clustering: A foundational perspecti ve. Surve y Chapter in Handbook of Cluster Analysis (Manuscript), 2013. [3] K. Bache and M. Lichman. UCI machine learning repository , 2013. [4] O. Bachem, M. Lucic, and A. Krause. Scalable and distributed clustering via lightweight coresets. In A CM SIGKDD International Confer ence on Knowledge Disco very and Data Mining (KDD) , 2018. [5] B. Bahmani, B. Moseley , A. V attani, R. Kumar , and S. V assilvitskii. Scalable k-means++. In Pr oceedings of the International Confer ence on V ery Lar ge Data Bases , 2012. [6] M.-F . Balcan, A. Blum, S. Fine, and Y . Mansour . Distrib uted learning, communication complexity and pri vac y . In Pr oceedings of the Confer ence on Learning Thoery , 2012. [7] S. Ben-David. A framework for statistical clustering with a constant time approximation algorithms for k-median clustering. Pr oceedings of Annual Confer ence on Learning Theory , 2004. [8] K. Chen. On k-median clustering in high dimensions. In Pr oceedings of the Annual ACM-SIAM Symposium on Discr ete Algorithms , 2006. [9] J. Considine, F . Li, G. Kollios, and J. Byers. Approximate aggregation techniques for sensor databases. In Pr oceedings of the International Conference on Data Engineering , 2004. [10] J. C. Corbett, J. Dean, M. Epstein, A. Fikes, C. Frost, J. Furman, S. Ghemaw at, A. Gubarev , C. Heiser , P . Hochschild, et al. Spanner: Googles globally-distributed database. In Pr oceedings of the USENIX Symposium on Operating Systems Design and Implementation , 2012. 14 [11] S. Datta, C. Giannella, H. Kargupta, et al. K-means clustering over peer -to-peer networks. In Pr oceed- ings of the International W orkshop on High P erformance and Distributed Mining , 2005. [12] H. Daum ´ e III, J. M. Phillips, A. Saha, and S. V enkatasubramanian. Efficient protocols for distrib uted classification and optimization. In Algorithmic Learning Theory , pages 154–168. Springer , 2012. [13] D. Feldman and M. Langber g. A unified frame work for approximating and clustering data. In Pr oceedings of the Annual ACM Symposium on Theory of Computing , 2011. [14] D. Feldman, A. Sugaya, and D. Rus. An effecti ve coreset compression algorithm for large scale sensor networks. In Pr oceedings of the International Confer ence on Information Pr ocessing in Sensor Networks , 2012. [15] G. Forman and B. Zhang. Distributed data clustering can be efficient and exact. A CM SIGKDD Explorations Ne wsletter , 2000. [16] S. Greenhill and S. V enkatesh. Distributed query processing for mobile surveillance. In Pr oceedings of the International Confer ence on Multimedia , 2007. [17] M. Greenwald and S. Khanna. Po wer-conserving computation of order -statistics ov er sensor networks. In Pr oceedings of the ACM SIGMOD-SIGA CT -SIGART Symposium on Principles of Database Systems , 2004. [18] S. Har -Peled. Geometric appr oximation algorithms . Number V ol. 173. American Mathematical Society , 2011. [19] S. Har-Peled and A. Kushal. Smaller coresets for k-median and k-means clustering. Discr ete & Computational Geometry , 2007. [20] S. Har-Peled and S. Mazumdar . On coresets for k-means and k-median clustering. In Pr oceedings of the Annual A CM Symposium on Theory of Computing , 2004. [21] E. Januzaj, H. Kriegel, and M. Pfeifle. T ow ards effecti ve and ef ficient distributed clustering. In W orkshop on Clustering Lar ge Data Sets in the IEEE International Confer ence on Data Mining , 2003. [22] R. Kannan and S. V empala. Nimble algorithms for cloud computing. arXiv preprint , 2013. [23] T . Kanungo, D. M. Mount, N. S. Netanyahu, C. D. Piatko, R. Silverman, and A. Y . W u. A local search approximation algorithm for k-means clustering. In Pr oceedings of the Annual Symposium on Computational Geometry , 2002. [24] H. Kargupta, W . Huang, K. Siv akumar , and E. Johnson. Distributed clustering using collecti ve principal component analysis. Knowledge and Information Systems , 2001. [25] M. Langberg and L. Schulman. Univ ersal ε -approximators for integrals. In Pr oceedings of the Annual A CM-SIAM Symposium on Discr ete Algorithms , 2010. [26] S. Li and O. Sv ensson. Approximating k-median via pseudo-approximation. In Pr oceedings of the Annual A CM Symposium on Theory of Computing , 2013. 15 [27] Y . Li, P . M. Long, and A. Srini vasan. Impro ved bounds on the sample complexity of learning. In Pr oceedings of the eleventh annual A CM-SIAM Symposium on Discr ete Algorithms , 2000. [28] S. Mitra, M. Agrawal, A. Y adav , N. Carlsson, D. Eager, and A. Mahanti. Characterizing web-based video sharing workloads. ACM T ransactions on the W eb , 2011. [29] C. Olston, J. Jiang, and J. Widom. Adaptiv e filters for continuous queries over distrib uted data streams. In Pr oceedings of the ACM SIGMOD International Confer ence on Management of Data , 2003. [30] D. T asoulis and M. Vrahatis. Unsupervised distrib uted clustering. In Pr oceedings of the International Confer ence on P arallel and Distrib uted Computing and Networks , 2004. [31] Q. Zhang, J. Liu, and W . W ang. Approximate clustering on distributed data streams. In Pr oceedings of the IEEE International Confer ence on Data Engineering , 2008. A Pr oofs f or Section 3 The proof of Lemma 1 follows from the analysis in [ 13 ], although not explicitly stated there. W e begin with the following theorem for uniform sampling on a function space. The theorem is from [ 13 ] but rephrased for con venience (and corrected). 6 Theorem 4 (Theorem 6.9 in [ 13 ]) . Let F be a set of functions fr om P to R ≥ 0 , and let ∈ (0 , 1) . Let S be a sample of | S | = c 2 (dim( F , P ) log dim( F , P ) + log 1 δ ) i.i.d items fr om P , wher e c is a sufficiently lar ge constant. Then, with pr obability at least 1 − δ , for any f ∈ F and any r ≥ 0 , P p ∈ P,f ( p ) ≤ r f ( p ) | P | − P q ∈ S,f ( q ) ≤ r f ( q ) | S | ≤ r. Lemma 1 (Restated) . F ix a set F of functions f : P → R ≥ 0 . Let S be a sample drawn i.i.d. fr om P accor d- ing to { m p : p ∈ P } , namely , for every q ∈ S and every p ∈ P , we have q = p with pr obability m p P z ∈ P m z . Let w p = P z ∈ P m z m p | S | for p ∈ P . F or a suf ficiently larg e c , if | S | ≥ c 2 dim( F , P ) log dim( F , P ) + log 1 δ then with pr obability at least 1 − δ, ∀ f ∈ F : P p ∈ P f ( p ) − P q ∈ S w q f ( q ) ≤ P p ∈ P m p max p ∈ P f ( p ) m p . Pr oof of Lemma 1. W ithout loss of generality , assume m p ∈ N + . Define G as follo ws: for each p ∈ P , include m p copies { p i } m p i =1 of p in G and define f ( p i ) = f ( p ) /m p . Then S is equi valent to a sample draw i.i.d. and uniformly at random from G . W e no w apply Theorem 4 on G and r = max f ∈ F,p 0 ∈ G f ( p 0 ) . By Theorem 4, we kno w that for any f ∈ F , P p 0 ∈ G f ( p 0 ) | G | − P q 0 ∈ S f ( q 0 ) | S | ≤ max p 0 ∈ G f ( p 0 ) . (6) 6 As pointed out in [ 4 ], the proof in [ 13 ] used a theorem from [ 27 ] which used the notion of pseudo-dimension d of a function space. Howe ver , the definition of the dimension d 0 of a function space in [ 13 ] is dif ferent from d . Fortunately , by [ 18 ], d = O ( d 0 log d 0 ) . Therefore, the theorem is corrected by replacing dim( F , P ) with dim( F , P ) log dim( F, P ) . 16 The lemma then follo ws from multiplying both sides of (6) by | G | = P p ∈ P m p . Also note that the dimension dim( F , G ) is the same as that of dim( F, P ) as pointed out by [13]. Lemma 3. If d ( p, b p ) 2 / ≤ | d ( p, x ) 2 − d ( b p , x ) 2 | , then | d ( p, x ) 2 − d ( b p , x ) 2 | ≤ 8 min { d ( p, x ) 2 , d ( b p , x ) 2 } . Pr oof. W e first have by triangle inequality | d ( p, x ) 2 − d ( b p , x ) 2 | ≤ d ( p, b p )[ d ( p, x ) + d ( b p , x )] . Then by d ( p, b p ) 2 / ≤ | d ( p, x ) 2 − d ( b p , x ) 2 | , d ( p, b p ) ≤ [ d ( p, x ) + d ( b p , x )] . Therefore, we hav e | d ( p, x ) 2 − d ( b p , x ) 2 | ≤ d ( p, b p )[ d ( p, x ) + d ( b p , x )] ≤ [ d ( p, x ) + d ( b p , x )] 2 ≤ 2 [ d ( p, x ) 2 + d ( b p , x ) 2 ] ≤ 2 [ d ( p, x ) 2 + ( d ( p, x ) + d ( p, b p )) 2 ] ≤ 2 [ d ( p, x ) 2 + 2 d ( p, x ) 2 + 2 d ( p, b p ) 2 ] ≤ 6 d ( p, x ) 2 + 4 d ( p, b p ) 2 ≤ 6 d ( p, x ) 2 + 4 2 | d ( p, x ) 2 − d ( b p , x ) 2 | for suf ficiently small . Then | d ( p, x ) 2 − d ( b p , x ) 2 | ≤ 6 1 − 4 2 d ( p, x ) 2 ≤ 8 d ( p, x ) 2 . Similarly , | d ( p, x ) 2 − d ( b p , x ) 2 | ≤ 8 d ( b p , x ) 2 . The lemma follows from the last tw o inequalities. Lemma 4 (Corollary 15.4 in [ 13 ]) . Let 0 < δ < 1 / 2 , and t ≥ c | B | log | B | δ for a sufficiently larg e c . Then with pr obability at least 1 − δ , ∀ b ∈ B i , P q ∈ P b ∩ S w q ≤ 2 | P b | . B Complete Experimental Results Here we present the results of all the data sets ov er dif ferent network topologies and data partition methods. Figure 4 shows the results of all the data sets on random graphs. The first column of Figure 4 shows that our algorithm and COMBINE perform nearly the same in the uniform data partition. This is not surprising since our algorithm reduces to the COMBINE algorithm when each local site has the same cost and the two algorithms use the same amount of communication. In this case, since in our algorithm the sizes of the local samples are proportional to the costs of the local solutions, it samples the same number of points from each local data set. This is equi v alent to the COMBINE algorithm with the same amount of communication. In the similarity-based partition, similar results are observ ed as this partition method also leads to balanced local costs. Ho wev er , in the weighted partition where local sites ha ve significantly dif ferent contributions to the total cost, our algorithm outperforms COMBINE. It improves the k -means cost by 2% − 5% , and thus sav es 10% − 30% communication cost to achieve the same approximation ratio. Figure 5 shows the results of all the data sets on grid and preferential graphs. Similar to the results on random graphs, our algorithm performs nearly the same as COMBINE in the similarity-based partition and outperforms COMBINE in the weighted partition and de gree-based partition. Furthermore, Figure 4 17 and 5 also show that the performance of our algorithm merely changes ov er different network topologies and partition methods. Figure 6 sho ws the results of all the data sets on the spanning trees of the random graphs and Figure 7 sho ws those on the spanning trees of the grid and preferential graphs. Compared to the algorithm of Zhang et al., our algorithm consistently shows much better performance on all the data sets in different settings. It improves the k -means cost by 10% − 30% , and thus can achiev e e ven better approximation ratio with only 10% communication cost. This is because the algorithm of Zhang et al. constructs coresets from component coresets and needs larger coresets to prev ent the accumulation of errors. Figure 6 also shows that although their costs decrease with the increase of the communication, the decrease is slower on larger graphs (e.g., as in the experiments for Y earPredictionMSD). This is due to the fact that the spanning tree of a larger graph has larger height, leading to more accumulation of errors. In this case, more communication is needed to pre vent the accumulation. 18 random graph random graph random graph uniform partition similarity-based partition weighted partition COMBINE Our Algo k-means cost ratio k-means cost ratio k-means cost ratio × 10 4 × 10 4 × 10 4 × 10 4 × 10 4 × 10 4 2 3 4 1 . 5 2 2 . 5 3 3 . 5 4 1 . 5 2 2 . 5 3 3 . 5 4 1 1 . 5 2 2 . 5 1 1 . 5 2 2 . 5 1 1 . 5 2 2 . 5 6000 8000 10000 12000 6000 8000 10000 12000 6000 8000 10000 1 1 . 05 1 . 1 1 1 . 05 1 . 1 1 1 . 05 1 . 1 1 1 . 05 1 . 1 1 . 15 1 1 . 05 1 . 1 1 . 15 1 1 . 05 1 . 1 1 . 15 1 1 . 05 1 . 1 1 . 15 1 1 . 05 1 . 1 1 . 15 1 1 . 05 1 . 1 1 . 15 comm unication cost comm unication cost k-means cost ratio comm unication cost k-means cost ratio k-means cost ratio × 10 7 × 10 7 × 10 7 × 10 5 × 10 4 × 10 4 × 10 5 × 10 5 × 10 5 1 . 6 1 . 8 2 2 . 2 1 . 8 2 2 . 2 1 . 6 1 . 8 2 2 . 2 0 . 8 1 1 . 2 8 10 12 8 10 12 0 . 6 0 . 8 1 1 . 2 1 . 4 0 . 6 0 . 8 1 1 . 2 1 . 4 0 . 6 0 . 8 1 1 . 2 1 . 4 1 . 05 1 . 1 1 . 15 1 . 05 1 . 1 1 . 15 1 . 05 1 . 1 1 . 15 1 . 05 1 . 1 1 . 15 1 . 05 1 . 1 1 . 15 1 . 05 1 . 1 1 . 15 1 1 . 02 1 . 04 1 . 06 1 1 . 02 1 . 04 1 . 06 1 1 . 02 1 . 04 1 . 06 Figure 4: k -means cost on random graphs. Columns: random graph with uniform partition, random graph with similarity-based partition, and random graph with weighted partition. Ro ws: Spam, Pendigits, Letter , synthetic, ColorHistogram, and Y earPredictionMSD. 19 grid graph grid graph preferential graph similarity-based partition weighted partition degree-based partition COMBINE Our Algo k-means cost ratio k-means cost ratio k-means cost ratio × 10 4 × 10 4 × 10 4 × 10 4 × 10 4 × 10 4 1 . 5 2 2 . 5 3 3 . 5 4 1 1 . 5 2 2 . 5 3 3 . 5 1 1 . 5 2 2 . 5 3 3 . 5 1 1 . 5 2 1 1 . 5 2 1 1 . 5 2 6000 8000 10000 12000 5000 6000 7000 8000 9000 5000 6000 7000 8000 9000 1 1 . 05 1 . 1 1 1 . 05 1 . 1 1 1 . 05 1 . 1 1 1 . 05 1 . 1 1 . 15 1 1 . 05 1 . 1 1 . 15 1 1 . 05 1 . 1 1 . 15 1 1 . 05 1 . 1 1 . 15 1 1 . 05 1 . 1 1 . 15 1 1 . 05 1 . 1 1 . 15 comm unication cost comm unication cost k-means cost ratio comm unication cost k-means cost ratio k-me ans cost ratio × 10 6 × 10 6 × 10 6 × 10 4 × 10 4 × 10 4 × 10 4 × 10 4 × 10 4 2 . 2 2 . 4 2 . 6 2 . 8 2 2 . 2 2 . 4 2 . 6 2 . 8 2 2 . 2 2 . 4 2 . 6 2 . 8 3 . 5 4 4 . 5 5 5 . 5 6 3 3 . 5 4 4 . 5 5 5 . 5 3 3 . 5 4 4 . 5 5 5 . 5 3 4 5 6 7 0 . 6 0 . 8 1 1 . 2 1 . 4 1 . 6 0 . 6 0 . 8 1 1 . 2 1 . 4 1 . 6 1 . 05 1 . 1 1 . 15 1 . 05 1 . 1 1 . 15 1 . 05 1 . 1 1 . 15 1 . 05 1 . 1 1 . 15 1 . 05 1 . 1 1 . 15 1 . 05 1 . 1 1 . 15 1 1 . 02 1 . 04 1 . 06 1 1 . 02 1 . 04 1 . 06 1 1 . 02 1 . 04 1 . 06 Figure 5: k -means cost on grid and preferential graphs. Columns: grid graph with similarity-based partition, grid graph with weighted partition, and preferential graph with degree-based partition. Rows: Spam, Pendigits, Letter , synthetic, ColorHistogram, and Y earPredictionMSD. 20 spanning tree of random graph spanning tree of random graph spanning tree of random graph uniform partition similarity-based partition weighted partition Zhang et al. Our Algo k-means cost ratio k-means cost ratio k-means cost ratio × 10 4 × 10 4 × 10 4 × 10 4 × 10 4 × 10 4 2 3 4 1 . 5 2 2 . 5 3 3 . 5 4 1 . 5 2 2 . 5 3 3 . 5 4 1 1 . 5 2 2 . 5 1 1 . 5 2 2 . 5 1 1 . 5 2 2 . 5 6000 8000 10000 12000 6000 8000 10000 12000 6000 8000 10000 1 1 . 1 1 . 2 1 . 3 1 1 . 1 1 . 2 1 . 3 1 1 . 1 1 . 2 1 . 3 1 1 . 1 1 . 2 1 . 3 1 . 4 1 1 . 1 1 . 2 1 . 3 1 . 4 1 1 . 1 1 . 2 1 . 3 1 . 4 1 1 . 2 1 . 4 1 . 6 1 1 . 2 1 . 4 1 . 6 1 1 . 2 1 . 4 1 . 6 comm unication cost comm unication cost k-means cost ratio comm unication cost k-means cost ratio k-means cost ratio × 10 7 × 10 7 × 10 7 × 10 5 × 10 4 × 10 4 × 10 5 × 10 5 × 10 5 1 . 6 1 . 8 2 2 . 2 1 . 8 2 2 . 2 1 . 6 1 . 8 2 2 . 2 0 . 8 1 1 . 2 8 10 12 8 10 12 0 . 6 0 . 8 1 1 . 2 1 . 4 0 . 6 0 . 8 1 1 . 2 1 . 4 0 . 6 0 . 8 1 1 . 2 1 . 4 1 1 . 1 1 . 2 1 . 3 1 . 4 1 1 . 1 1 . 2 1 . 3 1 . 4 1 1 . 1 1 . 2 1 . 3 1 . 4 1 1 . 2 1 . 4 1 1 . 2 1 . 4 1 1 . 2 1 . 4 1 1 . 1 1 . 2 1 . 3 1 1 . 1 1 . 2 1 . 3 1 1 . 1 1 . 2 1 . 3 Figure 6: k -means cost on the spanning trees of the random graphs. Columns: random graph with uniform partition, random graph with similarity-based partition, and random graph with weighted partition. Ro ws: Spam, Pendigits, Letter , synthetic, ColorHistogram, and Y earPredictionMSD. 21 spanning tree of grid graph spanning tree of grid graph spanning tree of preferential graph similarity-based partition weighted partition degree-based partition Zhang et al. Our Algo k-means cost ratio k-means cost ratio k-means cost ratio × 10 4 × 10 4 × 10 4 × 10 4 × 10 4 × 10 4 1 . 5 2 2 . 5 3 3 . 5 4 1 1 . 5 2 2 . 5 3 3 . 5 1 1 . 5 2 2 . 5 3 3 . 5 1 1 . 5 2 1 1 . 5 2 1 1 . 5 2 6000 8000 10000 12000 5000 6000 7000 8000 9000 5000 6000 7000 8000 9000 1 1 . 1 1 . 2 1 . 3 1 1 . 1 1 . 2 1 . 3 1 1 . 1 1 . 2 1 . 3 1 1 . 1 1 . 2 1 . 3 1 . 4 1 1 . 1 1 . 2 1 . 3 1 . 4 1 1 . 1 1 . 2 1 . 3 1 . 4 1 1 . 2 1 . 4 1 . 6 1 1 . 2 1 . 4 1 . 6 1 1 . 2 1 . 4 1 . 6 comm unication cost comm unication cost k-means cost ratio comm unication cost k-means cost ratio k-me ans cost ratio × 10 6 × 10 6 × 10 6 × 10 4 × 10 4 × 10 4 × 10 4 × 10 4 × 10 4 2 . 2 2 . 4 2 . 6 2 . 8 2 2 . 2 2 . 4 2 . 6 2 . 8 2 2 . 2 2 . 4 2 . 6 2 . 8 3 . 5 4 4 . 5 5 5 . 5 6 3 3 . 5 4 4 . 5 5 5 . 5 3 3 . 5 4 4 . 5 5 5 . 5 3 4 5 6 7 0 . 6 0 . 8 1 1 . 2 1 . 4 1 . 6 0 . 6 0 . 8 1 1 . 2 1 . 4 1 . 6 1 1 . 1 1 . 2 1 . 3 1 . 4 1 1 . 1 1 . 2 1 . 3 1 . 4 1 1 . 1 1 . 2 1 . 3 1 . 4 1 1 . 2 1 . 4 1 1 . 2 1 . 4 1 1 . 2 1 . 4 1 1 . 1 1 . 2 1 . 3 1 1 . 1 1 . 2 1 . 3 1 1 . 1 1 . 2 1 . 3 Figure 7: k -means cost on the spanning trees of the grid and preferential graphs. Columns: grid graph with similarity-based partition, grid graph with weighted partition, and preferential graph with degree-based partition. Rows: Spam, Pendigits, Letter , synthetic, ColorHistogram, and Y earPredictionMSD. 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment