일반 네트워크 위에서의 분산 k 평균·k 중앙값 클러스터링
본 논문은 임의의 그래프 토폴로지를 갖는 분산 환경에서 k‑median 및 k‑means 클러스터링을 수행하기 위한 새로운 코어셋 기반 알고리즘을 제시한다. 각 노드가 로컬 근사 해를 구하고, 그 비용만을 교환함으로써 전체 데이터에 대한 작은 ε‑코어셋을 구성한다. 이 코어셋은 중앙 조정자 혹은 메시지‑패싱을 통해 전체 네트워크에 전파될 수 있으며, 기존 방법에 비해 통신량을 O(kd + nk) 수준으로 크게 감소시킨다. 이론적 근사 보장과 실…
저자: Maria Florina Balcan, Steven Ehrlich, Yingyu Liang
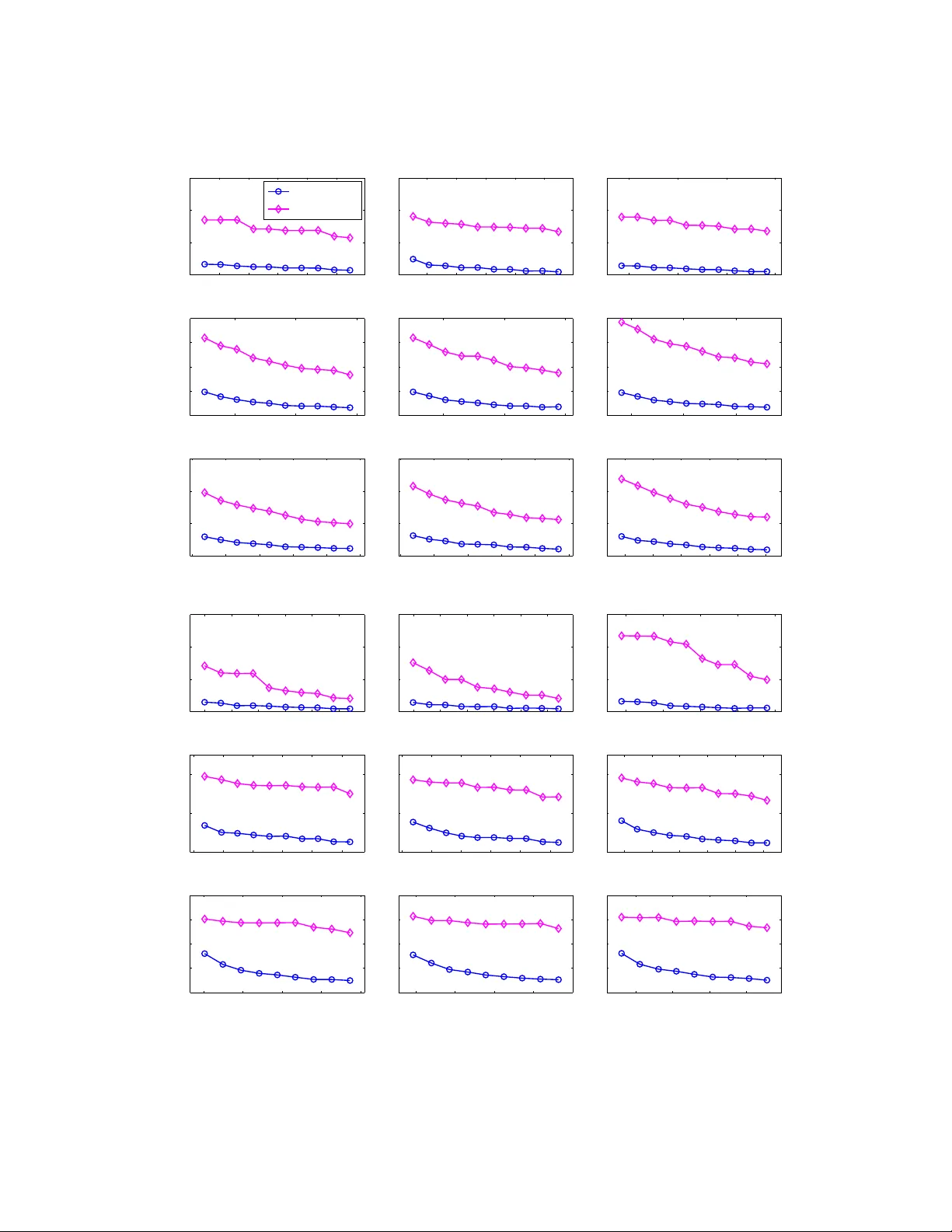
본 논문은 데이터가 여러 노드에 분산되고 노드 간 통신이 임의의 무방향 그래프 형태로 제한되는 상황에서, 두 대표적인 중심 기반 클러스터링 문제인 k‑median과 k‑means를 효율적으로 해결하기 위한 알고리즘을 제안한다. 기존의 분산 클러스터링 방법은 크게 두 갈래로 나뉜다. 하나는 중앙 조정자를 두고 각 노드가 로컬 통계(예: 평균, 분산)를 전송해 중앙에서 클러스터링을 수행하는 방식이며, 다른 하나는 각 노드가 로컬 데이터를 요약한 코어셋을 생성해 이를 중앙에 모아 전체 코어셋을 만든 뒤 클러스터링을 수행한다. 전자는 통신량이 적지만 이론적 품질 보장이 부족하고, 후자는 품질 보장은 가능하지만 코어셋 크기가 노드 수 n에 비례해 커져 통신 비용이 급증한다는 문제점이 있다.
이러한 한계를 극복하기 위해 저자들은 코어셋 개념을 “분산적으로” 구축하는 새로운 프레임워크를 설계한다. 핵심 아이디어는 전체 데이터에 대한 코어셋을 만들기 위해 각 노드가 전체 최적 해를 직접 계산할 필요 없이, 자신이 보유한 로컬 데이터에 대해 상수 근사 해(예: 2‑approximation)를 구하고 그 비용만을 네트워크 전체에 공유한다는 것이다. 이 비용은 전체 최적 비용의 상수 배이므로, 전체 데이터의 비용을 근사하는 데 충분히 정확하다.
구체적인 알고리즘은 두 라운드로 구성된다.
1️⃣ 라운드 1: 각 노드 \(v_i\)는 로컬 데이터 \(P_i\)에 대해 상수 근사 중심 집합 \(B_i\)를 구한다. 이후 \(\text{cost}(P_i, B_i)\) 를 모든 노드에 전파한다. 이 단계에서 전송되는 정보는 하나의 실수값뿐이므로 통신량이 매우 작다.
2️⃣ 라운드 2: 각 노드는 전체 비용의 합 \(\sum_{j=1}^n \text{cost}(P_j, B_j)\) 를 알고, 이를 기반으로 자신의 샘플링 비율을 결정한다. 구체적으로, 노드 \(i\)는 \(t_i = t \cdot \frac{\text{cost}(P_i, B_i)}{\sum_j \text{cost}(P_j, B_j)}\) 만큼의 샘플을 로컬 데이터에서 추출한다. 샘플링 확률은 각 포인트 \(p\)의 기여도 \(m_p = \text{cost}(p, B_i)\) 에 비례한다. 샘플링된 포인트와 로컬 중심 \(B_i\)에 적절한 가중치를 부여해 로컬 코어셋을 만든 뒤, 메시지‑패싱 방식으로 네트워크 전체에 전파한다.
이때 전체 코어셋의 크기는 \(\tilde O(kd + nk)\) 로, 기존 방법이 필요로 했던 \(\tilde O(n(kd + nk))\) 에 비해 n 배 적다. 또한 코어셋 크기가 그래프의 직경이나 높이에 의존하지 않으므로, 그리드와 같이 직경이 큰 네트워크에서도 효율적으로 동작한다.
이론적 분석에서는 코어셋 정의(ε‑코어셋)와 함수 공간 차원(dim) 개념을 활용한다. 함수 집합 \(F = \{f_x : f_x(p) = \text{cost}(p, x) - \text{cost}(b_p, x) + \text{cost}(p, b_p)\}\) 를 정의하고, 각 포인트에 대한 상한 \(m_p = 2\cdot \text{cost}(p, b_p)\) 를 사용해 샘플링한다. Lemma 1에 따라 충분히 큰 샘플 크기 \(t = O\big(\frac{1}{\epsilon^2}( \text{dim}(F,P)\log \text{dim}(F,P) + \log(1/\delta))\big)\) 를 선택하면, 모든 중심 집합 \(x\) 에 대해 코어셋 비용과 원본 비용의 차이가 \(\epsilon\) 이하가 된다. 여기서 \(\text{dim}(F,P) = O(kd)\) 로, 최종 코어셋 크기가 \(\tilde O(kd/\epsilon^2)\) 로 도출된다.
k‑median와 k‑means 각각에 대해 차원 분석과 샘플링 파라미터를 조정함으로써, Theorem 1은 두 문제 모두에 대해 확률 \(1-\delta\) 로 ε‑코어셋을 얻을 수 있음을 보인다. 통신 비용은 첫 라운드에서 O(n) (각 노드당 하나의 실수), 두 번째 라운드에서 O(mn) (각 에지당 코어셋 포인트 전송) 로, 전체 복잡도는 O(mn) 이다.
실험 섹션에서는 합성 데이터와 실제 대규모 데이터(예: 이미지 피처, 센서 로그)를 사용해 제안 알고리즘과 기존 코어셋 기반 방법(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기