Distributed Filtering for Uncertain Systems Under Switching Sensor Networks and Quantized Communications
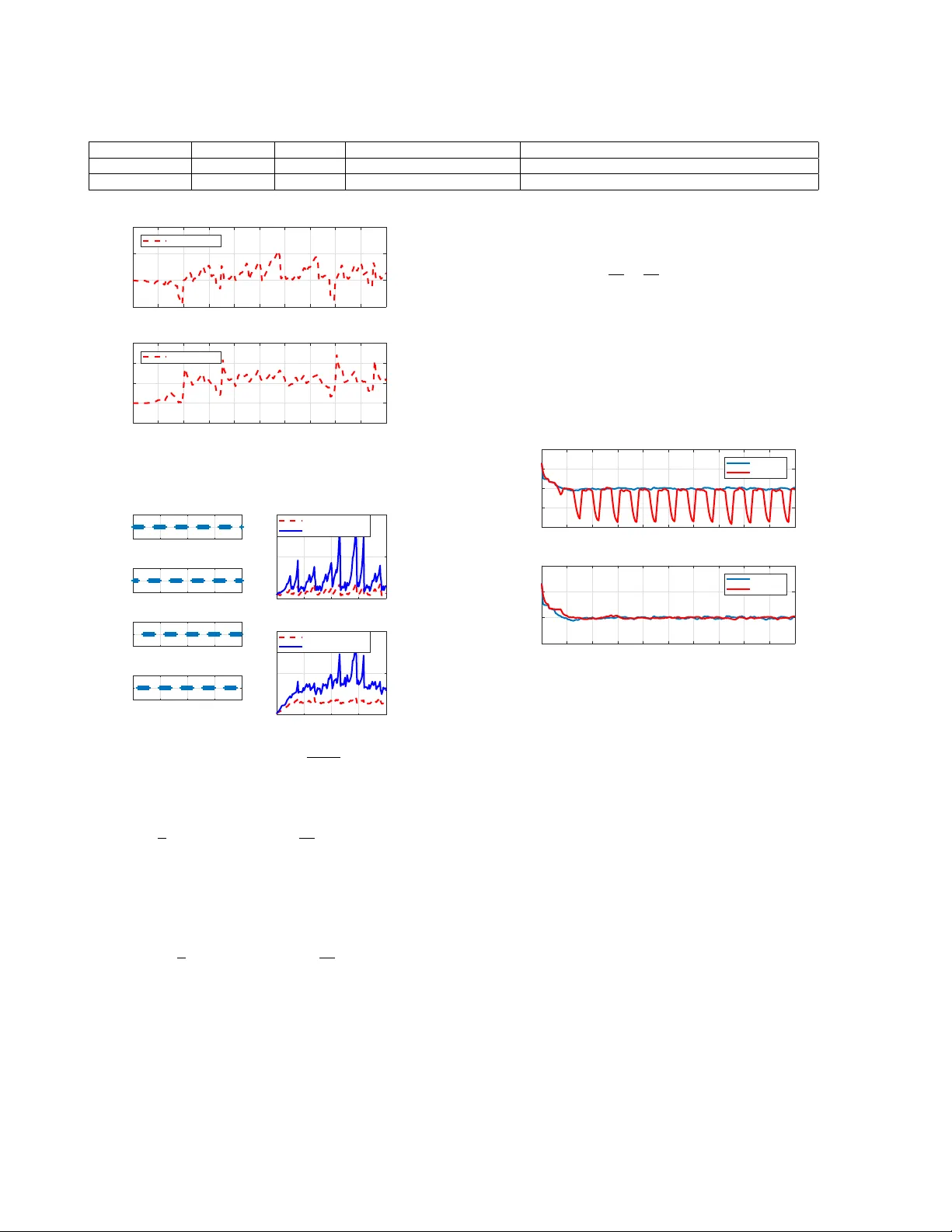
This paper considers the distributed filtering problem for a class of stochastic uncertain systems under quantized data flowing over switching sensor networks. Employing the biased noisy observations of the local sensor and interval-quantized message…
Authors: Xingkang He, Wenchao Xue, Xiaocheng Zhang
Distrib uted Filtering f or Uncertain Systems Under Switching Sensor Networks and Quantized Communications 1 Xingkang He a , b , W enchao Xue a , ∗ , Xiaocheng Zhang a , Haitao Fang a a LSC, NCMIS, Academy of Mathematics and Systems Science, Chinese Academy of Sciences, Beijing 100190, China b Division of Decision and Contr ol Systems, KTH Royal Institute of T echnology , SE-100 44 Stoc kholm, Sweden Abstract This paper considers the distributed filtering problem for a class of stochastic uncertain systems under quantized data flo wing ov er switching sensor networks. Employing the biased noisy observations of the local sensor and interv al-quantized messages from neighboring sensors successiv ely , an extended state based distrib uted Kalman filter (DKF) is proposed for simultaneously estimating both system state and uncertain dynamics. T o alle viate the effect of observ ation biases, an event-triggered update based DKF is presented with a tighter mean square error bound than that of the time-dri ven one by designing a proper threshold. Both the two DKFs are sho wn to provide the upper bounds of mean square errors online for each sensor . Under mild conditions on systems and networks, the mean square error boundedness and asymptotic unbiasedness for the proposed two DKFs are pro ved. Finally , the numerical simulations demonstrate the effecti veness of the dev eloped filters. K ey wor ds: Sensor network; Uncertain system; Distributed Kalman filtering; Biased observation; Quantized communications 1 Introduction In recent years, sensor networks are broadly studied and applied to en vironment sensing, target tracking, smart grid, etc. As is well kno wn, state estimation problems o ver sensor networks are usually modeled as distributed filtering studies. Thus more and more researchers and engineers around the world are paying their attention to the methods and theories of distributed filtering. In the existing literature on distrib uted filtering ov er sen- sor networks, many effecti ve approaches and analysis tools hav e been provided. For linear time-in variant systems, dis- tributed filters with constant parameter gains were inv esti- gated in [1, 2], which yet confined the scope of the sys- tem dynamics to be considered. As is known, the optimal centralized Kalman filter for linear stochastic systems can provide the estimation error co variances online. Howe ver , in distributed Kalman filters (DKFs) [3–9], the covariances can not be obtained by each sensor due to the unkno wn ? The material in this paper was not presented at any conference. ∗ Corresponding author . Email addr esses: xingkang@kth.se (Xingkang He), wenchaoxue@amss.ac.cn ( W enchao Xue ), zhangxiaocheng16@mails.ucas.ac.cn (Xiaocheng Zhang), htfang@iss.ac.cn (Haitao Fang). correlation between state estimates of sensors, which essen- tially hinders the optimality of distributed filters. Then the distributed Kalman filters based on consensus or diffusion strategies were studied in [4, 5], where the state estimates were fused by scalar weights. As a result, the neighboring information can not be well utilized. Owing to the important role of filtering consistency 1 in real-time precision ev alua- tion, the consistent algorithms in [6 – 8, 10] enabled their ap- plications to design co variance weight based fusion schemes, though the system models were limited to be linear and the communications were required to be perfect. In this paper , we will propose consistent filters for general system models, communication schemes and network topologies. Stability is one of fundamental properties for filtering al- gorithms. In the existing results on stability analysis, local observability conditions of linear systems were assumed in [5, 11], which confined the application scope of distributed filters. On the other hand, the sensor observation bias, which prev alently e xists o wing to factors like calibration error , sen- sor drift, and registration error , can directly influence the consistency as well as the stability of filters. This is attributed to the dif ficulty in dealing with biased observations of the lo- cal sensor and fusing the biased estimates from neighboring 1 The filtering consistency means that an upper bound of estima- tion error cov ariance can be calculated online. Preprint submitted to Automatica 8 October 2019 sensors. The state estimation problems in the presence of ob- servation bias were in vestigated in [12, 13] by assuming the independence between the system state and the random bias, which yet is hard to be satisfied for feedback control systems with colored random bias processes. More importantly , ow- ing to the existence of outer disturbances or unmodeled dy- namics, man y practical systems contain uncertain dynamics, which may be nonlinear . T o deal with the unknown dynam- ics, some rob ust estimation methods, such as H ∞ filters and set valued filters, were studied by researchers [14, 15]. An extended state based Kalman filter was proposed in [16] for a class of nonlinear uncertain systems. Howe ver , the relation between the original system and the formulated system still needs further inv estigation. Compared with the centralized filter [16], more general system models and noise conditions will be studied in this work under a distributed framework. Communication scheme between sensors is one of the essen- tial features for decentralized algorithms. In the past years, a considerable number of results hav e analyzed topology conditions in terms of network connecti vity and graph types [3 – 9, 11]. Most of these results assumed that the network is fixed over time. Howe ver , due to the network vulnerability (e.g., link failure [10]), the topologies of sensor netw orks may be changing with time. Another significant aspect is on the message transmission between neighboring sensors. A majority of the existing literature on distributed filters re- quired the accurate transmission. Nevertheless, due to lim- itations of energy and channels in practical networks, such as wireless sensor network, it is difficult to ensure perfect sensor communications. Thus, the filter design under quan- tized sensor communications seems to be an important issue of practice. The main contributions of this paper are summarized in the following. (1) By utilizing the techniques of interv al quantization and state extension, we propose a quantized communication based distributed Kalman filter for a class of stochastic systems suf fering uncertain dynamics and observation biases. The filter enables the upper bounds of mean square estimation errors to be avaiable online. (2) Under some mild conditions including uniformly col- lectiv e observability of the system and jointly strong connectivity of the switching networks, we prov e that the mean square estimation errors are uniformly upper bounded. Furthermore, it is shown that the estimation biases tend to zero under certain decaying conditions of uncertain dynamics and observation biases. (3) An e vent-triggered observ ation update based DKF is presented with a tighter mean square error bound than that of the time-driven one. Also, the mean square boundedness of the estimation error for the ev ent- triggered filter is proved. More importantly , we rev eal that the estimation biases of the ev ent-triggered filter can tend to zero ev en if the observation biases of some sensors are not decaying over time. Compared with the e xisting literature [1 – 9], the studied sys- tems are more general by considering uncertain dynam- ics and observation biases. Furthermore, although there are some results on quantized distributed consensus [17, 18], the distributed filtering problems with quantized sensor com- munications hav e not been well inv estigated in the existing literature, especially for the scenario that the system is un- stable and collectiv ely observable. Moreo ver , the conditions of noise in [8], the initial estimation error in [3, 19], and the non-singularity of time-varying system matrices in [3, 8] are all relaxed in this paper . The remainder of the paper is or ganized as follo ws. Sec- tion 2 is on the model description and preliminaries. Section 3 studies the system reconstruction and filtering structure. Section 4 analyzes the distrib uted filter with time-dri ven up- date scheme. Section 5 studies the distributed filter with ev ent-triggered update scheme. Section 6 shows the numer- ical simulations. The conclusion of this paper is gi ven in Section 7. Some proofs are given in Appendix. Notations . The superscript “T” represents the transpose. I n stands for the identity matrix with n rows and n columns. E { x } denotes the mathematical expectation of the stochastic variable x , and blockdiag {·} means that the block elements are arranged in diagonals. diag {·} represents the diagonal- ization of scalar elements. tr( P ) is the trace of the matrix P . N + denotes the set of positive natural numbers. R n stands for the set of n -dimensional real vectors. [ a : b ) stands for the set of integers a, a + 1 , · · · , b − 1 . W e denote [ a : b ] = [ a : b ) ∪ b . And, sat( f , b ) means max { min { f , b } , − b } . W e assume that λ min ( A ) and λ max ( A ) are the minimal eigenv alue and max- imal eigen value of a real-v alued square matrix A , respec- tiv ely . sup k ∈ N A k A T k < ∞ means sup k ∈ N λ max A k A T k < ∞ . Let k · k 2 be the standard Euclidean norm. 2 Model Description and Preliminaries 2.1 Network topology and definitions W e model the communication topologies of sensor netw orks by switching weighted digraphs {G s = ( V , E s , A s ) } , where V , E s and A s stand for the node set, the edge set and the weighted adjacency matrix, respectiv ely . W e assume that A s is row stochastic with nonnegativ e off-diagonal el- ements and positive diagonal elements, i.e., a G s i,i > 0 , a G s i,j ≥ 0 , P j ∈V a G s i,j = 1 . As node i can receive information from its neighboring sensors, the neighbor set of node i is denoted by N G s i , { j ∈ V | a G s i,j > 0 } , which includes node i . W e de- note a G s i,j = a i,j ( k ) and N G s i = N i ( k ) , if the graph is G s at time k . G s is called strongly connected if for any pair nodes ( i 1 , i l ) , there exists a direct path from i 1 to i l consisting of edges ( i 1 , i 2 ) , ( i 2 , i 3 ) , · · · , ( i l − 1 , i l ) . W e say that {G s } K s =1 is jointly strongly connected if the union graph S K s =1 G s is strongly connected, where K ∈ N + . The follo wing definitions are needed in this paper . 2 Definition 2.1 ([20]) Suppose that x k is a r andom vector and ˆ x k is the estimate of x k . Then the pair ( ˆ x k , Π k ) is said to be consistent if E { ( ˆ x k − x k )( ˆ x k − x k ) T } ≤ Π k . An algorithm is of consistency if it pro vides consistent pairs ( ˆ x k , Π k ) for all k ∈ N . Definition 2.2 Let e k,i be the state estimation err or of sensor i at time k , then the sequence of estimation err or covariances E { e k,i e T k,i } , k ∈ N , is said to be stable if sup k ∈ N E { e k,i e T k,i } < ∞ . And, the sequence of estimates is said to be asymptotically unbiased if lim k →∞ E { e k,i } = 0 . Let (Ω , F , P ) be the basic probability space. F k stands for a filtration of σ -algebra F , i.e., for F k ⊂ F , F i ⊂ F j if i < j . Here, the σ -algebra is a collection of subsets of Ω and satisfies certain algebraic structure. A discrete-time sequence { ξ k , F k } is said to be adapted if ξ k is measurable to F k . In principle, ξ k is a function of past ev ents within F k . W e refer the readers to the formal definitions of ‘filtration’, ‘ σ -algebra’ and ‘measurable’ in [21]. Definition 2.3 A discrete-time adapted sequence { ξ k , F k } is called a martingale dif ference sequence (MDS) , if E {k ξ k k 2 } < ∞ and E { ξ k |F k − 1 } = 0 , almost sur ely . Definition 2.4 A time sequence { T l , l ∈ N } is called an L -step supporting sequence (L-SS) of a matrix sequence { M k , k ∈ N } , if ther e exists a scalar β > 0 , such that the sequence { T l , l ∈ N } is well defined in the following manner T 0 = inf k ≥ 0 λ min ( M k + s M T k + s ) ≥ β , ∀ s ∈ [0 : L ) T l +1 = inf k ≥ T l + L λ min ( M k + s M T k + s ) ≥ β , ∀ s ∈ [0 : L ) sup l ∈ N { T l +1 − T l } < ∞ . (1) Remark 2.1 The definition of L-SS is intr oduced to study the nonsingularity of the time-varying transition matrices { ¯ A k,i } given in the sequel. In many existing r esults [3, 8], ¯ A k,i is assumed to be nonsingular for any k ∈ N , which is r emoved in this paper . 2.2 Model description and assumptions Consider the following model for a class of stochastic sys- tems with uncertain dynamics and biased observations x k +1 = ¯ A k x k + ¯ G k f ( x k , k ) + ¯ ω k , y k,i = ¯ H k,i x k + b k,i + v k,i , i ∈ V , (2) where x k ∈ R n is the unknown system state, ¯ A k ∈ R n × n is the known state transition matrix and ¯ ω k ∈ R n is the un- known zero-mean white process noise. f ( x k , k ) ∈ R p is the uncertain dynamics (e.g., some unknown disturbance). ¯ G k ∈ R n × p is the kno wn matrix subject to sup k ∈ N { ¯ G k ¯ G T k } < ∞ . Here, y k,i ∈ R m i is the observation v ector obtained via sensor i , ¯ H k,i ∈ R m i × n is the kno wn observ ation matrix, subject to sup k ∈ N { ¯ H T k,i ¯ H k,i } < ∞ , b k,i ∈ R m i is the un- known state-correlated stochastic observation bias of sen- sor i , and v k,i ∈ R m i is the stochastic zero-mean obser- vation noise. N is the number of sensors over the system, thus V = { 1 , 2 , . . . , N } . Note that ¯ A k , ¯ G k are known to all the local sensors, while ¯ H k,i and y k,i are only kno wn to the local sensor i . Suppose that σ { x } stands for the minimal sigma algebra generated by the random vector x . Let F k , σ { x 0 , b 0 ,i , ¯ ω j , v j,i , i ∈ V , 0 ≤ j ≤ k } and f k , f ( x k , k ) for simplicity . In the following, we will pro- vide several assumptions on the system structure and com- munication scheme. Assumption 2.1 The following conditions hold: • 1) The sequence { ¯ ω k } ∞ k =0 is independent of x 0 and { v k,i } ∞ k =0 , i ∈ V , with E { ¯ ω k ¯ ω T k } ≤ Q k , where inf k Q k > 0 and sup Q k < ∞ , ∀ k ∈ N . • 2) The sequences { b k,i } ∞ k =0 , i ∈ V , ar e measurable to F k − 1 , k ≥ 1 , and E { b k,i b T k,i } ≤ B k,i . • 3) The sequence { v k,i , F k } ∞ k =0 is MDS and E { v k,i v T k,i } ≤ R k,i as well as sup k ∈ N R k,i > 0 holds ∀ i ∈ V . • 4) It holds that E { ( X 0 − ˆ X 0 ,i )( X 0 − ˆ X 0 ,i ) T } ≤ P 0 ,i , wher e ˆ X 0 ,i is the estimate of X 0 , [ x T 0 , f T 0 ] T , i ∈ V . Compared with [8] where the observation noises of sensors are independent, the MDS assumption on v k,i is milder . The condition 4) of Assumption 2.1 is more general than that in [3, 19] which the initial estimation error is required to be sufficiently small. Assumption 2.2 Ther e is an L ∈ N + , such that the se- quence { ¯ A k , k ∈ N } has an L-SS and sup k ∈ N { ¯ A k ¯ A T k } < ∞ . Assumption 2.2 poses no requirement on the stability of the original system (2). Besides, within the scope of distributed filtering for time-v arying systems, Assumption 2.2 is milder than that in [3, 8], where the non-singularity of the system state transition matrix is needed for each time. Assumption 2.3 The following conditions hold. • 1) f k is measurable to ¯ F k , wher e ¯ F k = σ { x 0 , b 0 ,i , ¯ ω j − 1 , v j,i , i ∈ V , 1 ≤ j ≤ k } for k ≥ 1 , and ¯ F 0 = σ { x 0 , b 0 ,i , v 0 ,i , i ∈ V } . • 2) E { u k u T k } ≤ ˆ Q k , where u k , f k +1 − f k , subject to inf k ∈ N λ min ( ˆ Q k ) > 0 and sup k ∈ N λ max ( ˆ Q k ) < ∞ . 3 The first condition of Assumption 2.3 permits f k to be im- plicitly related with { x j , y j,i } k j =0 , i ∈ V . Under this setting, the model built in (2) also considers the distributed output feedback control systems, such as the system of coupled tanks [22]. The condition in 2) of Assumption 2.3 relies on the boundedness of the dynamic increment, which is milder than the boundedness of uncertain dynamics required by [23]. Definition 2.5 The system (2) is said to be uniformly col- lectively observable if there exist two positive integ ers ¯ N , ¯ M , and a constant α > 0 such that for any k ≥ ¯ M , ther e is P N i =1 h P k + ¯ N j = k ¯ Φ T j,k ¯ H T j,i ( R j,i + B j,i ) − 1 ¯ H j,i ¯ Φ j,k i ≥ αI n , wher e ¯ Φ k,k = I n , ¯ Φ k +1 ,k = ¯ A k , ¯ Φ j,k = ¯ Φ j,j − 1 × · · · × ¯ Φ k +1 ,k , if j > k . Assumption 2.4 The system (2) is uniformly collectively observable. Assumption 2.4 is a mild collectiv e observability condition for time-varying stochastic systems. If the system is time- in variant, then Assumption 2.4 degenerates to ( ¯ A, ¯ H ) being observable [6, 24], where ¯ H = [ ¯ H T 1 , . . . , ¯ H T N ] T . Besides, if the local observability conditions are satisfied [5, 11], then Assumption 2.4 holds, but not vice versa. The topologies of the networks are assumed to be switching digraphs {G σ k , k ∈ N } . σ k is the switching signal defined by σ k : N → Ω , where Ω is the set of the underlying network topology numbers. For con venience, the weighted adjacency matrix of the digraph G σ k is denoted by A σ k = [ a i,j ( k )] ∈ R N × N . T o analyze the switching topologies, we consider the infinite interval sequence consisting of non-ov erlapping and contiguous time intervals [ k l , k l +1 ) , l = 0 , 1 , . . . , with k 0 = 0 . It is assumed that there exists an integer k 0 , such that k l +1 − k l ≤ k 0 . On the switching topologies, the following assumption is needed. Assumption 2.5 The union graph S k l +1 k = k l G σ k is str ongly connected, and the elements of G σ k , i.e., a i,j ( k ) , belong to a set consisting of finite nonnegative r eal numbers. Since the joint connecti vity of the switching digraphs admits that the network is unconnected at each moment, Assump- tion 2.5 is milder for the networks confronting link failures. If the network remains connected at each moment or fixed [6, 7], then Assumption 2.5 holds as well. 2.3 Quantized communications In sensor networks, such as wireless sensor networks, the signal transmission between two sensors may confront the problems of channel limitation and energy restriction. Thus, without losing too much accuracy , some quantization oper- ators can be considered to reduce the package size in the en- coding process with respect to the transmitted messages. In this paper , we study the case that the messages to be trans- mitted are quantized element by element through a gi ven quantizer before transmission. Let z k,i be a scalar element remaining to be sent out by sensor i , then we consider the following interv al quantizer with quantizing step ∆ i > 0 and quantizing function g ( · ) : R − → Q i g ( z k,i ) = m ∆ i , if ( m − 1 2 )∆ i ≤ z k,i < ( m + 1 2 )∆ i (3) where Q i = { m ∆ i | m ∈ Z } is the quantization alphabet with countably infinite elements. Then we write g ( z k,i ) = z k,i + ϑ ( z k,i ) , where ϑ ( z k,i ) is the quantization error , which is deterministic conditioned on the input z k,i . In addition, we have ϑ ( z k,i ) ∈ [ − ∆ i 2 , ∆ i 2 ) . A technique to deal with the correlation between ϑ ( z k,i ) and z k,i is to consider a dither operator by adding a random sequence { ξ k,i } , which can randomize the quantization error and make it independent of the input data. Write ϑ ( k , i ) = g ( z k,i + ξ k,i ) − ( z k,i + ξ k,i ) , (4) then the quantization error sequence { ϑ ( k , i ) } is indepen- dent and identically distributed (i.i.d.), uniformly distrib uted on [ − ∆ i 2 , ∆ i 2 ) and independent of z k,i , if the following as- sumption holds. Assumption 2.6 The sequence { ξ k } k ≥ 0 satisfies Schuch- man conditions [17] and it is independent of ¯ F k defined in Assumption 2.3. A sufficient condition such that { ξ k } k ≥ 0 satisfies Schuch- man conditions is that { ξ k,i } k ≥ 0 is an i.i.d. sequence uni- formly distributed on [ − ∆ i 2 , ∆ i 2 ) and independent of input sequence { z k,i } . 3 System Reconstruction and Filtering Structure 3.1 System r econstruction By constructing a ne w state vector , consisting of the original state x k and the uncertain dynamics f k , a modified system model is given as follows. X k +1 = A k X k + D u k + ω k y k,i = H k,i X k + b k,i + v k,i (5) where X k , x k f k ! ∈ R n + p , A k , ¯ A k ¯ G k 0 I p ! ∈ R ( n + p ) × ( n + p ) , ω k , ¯ ω k 0 ! ∈ R n + p , D , 0 I p ! ∈ R ( n + p ) × p , u k , f k +1 − f k ∈ R p , H k,i , ¯ H k,i 0 ∈ R m i × ( n + p ) . 4 Considering the system (2) and the reformulated system (5), Propositions 3.1 and 3.2, which are proved in Appendices A-B, show the equiv alence between the properties of the two systems. Proposition 3.1 On the relation between ¯ A k in (2) and A k in (5), the following conclusions hold. • 1) sup k ∈ N { A k A T k } < ∞ if and only if sup k ∈ N { ¯ A k ¯ A T k } < ∞ . • 2) { A k | A k ∈ R ( n + p ) × ( n + p ) , k ∈ N } has an L-SS if and only if { ¯ A k | ¯ A k ∈ R n × n , k ∈ N } has an L-SS. Proposition 3.2 The r eformulated system (5) is uniformly collectively observable if and only if ther e exist M , ¯ N ∈ N + and α > 0 , such that for any k ≥ M , ¯ Θ 1 , 1 k, ¯ N > αI n ¯ Θ 2 , 2 k, ¯ N − ( ¯ Θ 1 , 2 k, ¯ N ) T ( ¯ Θ 1 , 1 k, ¯ N − αI n ) − 1 ¯ Θ 1 , 2 k, ¯ N > αI p (6) wher e ¯ Θ 1 , 1 k, ¯ N , ¯ Θ 1 , 2 k, ¯ N , and ¯ Θ 2 , 2 k, ¯ N ar e given in (B.1) . According to the proof of Proposition 3.2 and Definition 2.5, we can obtain the following lemma. Lemma 3.1 Let Assumption 2.4 holds, then there exist M , ¯ N ∈ N + and α > 0 , such that for any k ≥ M , ¯ Θ 1 , 1 k, ¯ N > αI n , wher e ¯ Θ 1 , 1 k, ¯ N is given in (B.1) . Remark 3.1 By Proposition 3.2 and Lemma 3.1, the ob- servability gap between the reformulated system (5) and the system (2) is the second equation in (6) , which will reduce to rank I n − ¯ A − ¯ G ¯ H 0 = n + p if the system is time-invariant and observable, where ¯ H = [ ¯ H T 1 , . . . , ¯ H T N ] T , ¯ H i ∈ R m i × n , ¯ A ∈ R n × n and ¯ G ∈ R n × p . Example T o show the feasibility of (6), we consider a con- nected network with three sensors. Suppose that b k,i = sat sin x 2 k (1) + x 2 k (2) , 1 . For the system (2), we let ¯ A = ( 1 1 0 2 ) , ¯ G = [1 , 1] T , ¯ H 1 = [1 , 0] , ¯ H 2 = [0 , 1] , ¯ H 3 = [1 , 1] , R i = 1 , B i = 1 , i = 1 , 2 , 3 . On one hand, according to (6) and the notations in the proof of Proposition 3.2, by choosing α = 2 and ¯ N = 10 , we hav e λ min ( ¯ Θ 1 , 1 k, ¯ N − αI n ) > 5 . 77 , and λ min ¯ Θ 2 , 2 k, ¯ N − ( ¯ Θ 1 , 2 k, ¯ N ) T ( ¯ Θ 1 , 1 k, ¯ N − αI n ) − 1 ¯ Θ 1 , 2 k, ¯ N − αI p > 1 . 2 × 10 6 . On the other hand, by Remark 3.1, we have rank I n − A − G ¯ H 0 = 3 . Then due to rank ¯ H ¯ H ¯ A = 2 , the condition (6) holds. In the sequel, we require the following assumption. Assumption 3.1 Ther e exist M , ¯ N ∈ N + and α > 0 , such that for any k ≥ M , the second inequality in (6) holds. It is straightforward to prove that if Assumptions 2.4 and 3.1 are both satisfied, there is a common α > 0 , such that the two inequalities in (6) holds simultaneously . By Proposition 3.1, Assumptions 2.4 and 3.1 can lead to the uniformly collecti ve observability of the reformulated system (5). 3.2 F iltering structure In this paper , we consider two observation update schemes, namely , time-driv en update and ev ent-triggered update, whose difference lies in whether the biased noisy observa- tion y k,i is utilized at the update stage or not. W e propose the following distrib uted filter structure of the system (5) for sensor i , ∀ i ∈ V , ¯ X k,i = A k − 1 ˆ X k − 1 ,i if y k,i is utilized: ˜ X k,i = ¯ X k,i + K k,i ( y k,i − H k,i ¯ X k,i ) if y k,i is discarded: ˜ X k,i = ¯ X k,i ˆ X k,i = P j ∈N i ( k ) W k,i,j ˜ X k,j (7) where ˜ X k,j = ˜ X k,i , if i = j , otherwise ˜ X k,j = G 1 ( ˜ X k,j ) , j ∈ N i , and G 1 ( ˜ X k,j ) =: [ g ( ˜ X k,j (1)) , . . . , g ( ˜ X k,j ( n ))] T is the quantized message sent out by sensor j with element-wise quantization by (3). Also, ¯ X k,i , ˜ X k,i , and ˆ X k,i are the extended state’ s prediction, update, and es- timate by sensor i at the k th moment, respectively . K k,i and W k,i,j , j ∈ N i ( k ) , are the filtering gain matrix and the local fusion matrices, respectively . They remain to be designed. Remark 3.2 W e utilize the dither quantization of state es- timates in (7) to relax the conservativeness in handling corr elation between the quantization err or and state esti- mates. F or example, if random variables x and y are cor- r elated, a common technique is to use E { ( x + y ) 2 } ≤ (1 + 1 α ) E { x 2 } + (1 + α ) E { y 2 } for α > 0 . However , this operator is usually conservative. Thus, we use the dither ed quantization to remove the corr elation. In the sequel, we will study the consistency , stability and asymptotic unbiasedness of the proposed distributed filters under Assumptions 2.1-3.1. T able 1 is to provide the con- nection between the main results and assumptions. T able 1 Connection between results and assumptions Assumptions Results Assumptions 2.1, 2.3, 2.6 Lemma 4.1/5.2 (Consistency) Assumptions 2.1-2.3 Lemma 4.3 Assumptions 2.1-2.6, 3.1 Theorem 4.1/5.1(Stability) Assumptions 2.1-2.6, 3.1 Theorem 4.2/5.2(Unbiasedness) 5 4 Distributed filter: time-driven update In this section, for the filtering structure (7) with y k,i em- ployed at each time, we will study the design methods of K k,i and W k,i,j . Then we will find the conditions to guar- antee the stability of the estimation error cov ariances for the proposed filter with the designed K k,i and W k,i,j . 4.1 F ilter design The next lemma, proved in Appendix C, provides a design method of fusion matrices { W k,i,j } j ∈N i , which can lead to the consistent estimate of each sensor . Lemma 4.1 Consider the filtering structur e (7) with a non- stochastic filtering gain K k,i . Under Assumptions 2.1, 2.3 and 2.6, for any i ∈ V , positive scalar s θ k,i and µ k,i , the pairs ( ¯ X k,i , ¯ P k,i ),( ˜ X k,i , ˜ P k,i ), ( ˜ X k,i , ˜ P k,i ) and ( ˆ X k,i , P k,i ) ar e all consistent, pr ovided by W k,i,j = a i,j ( k ) P k,i ˜ P − 1 k,j , wher e ˜ P k,j = ( ˜ P k,j , if i = j , j ∈ N i ( k ) ˇ P k,j + ¯ n ∆ j (2∆ j +1) 2 I ¯ n , if i 6 = j , j ∈ N i ( k ) , and ¯ P k,i , ˜ P k,i , ˇ P k,i and P k,i ar e r ecursively calculated thr ough ¯ P k,i = (1 + θ k,i ) A k − 1 P k − 1 ,i A T k − 1 + 1+ θ k,i θ k,i ¯ Q k − 1 + ˜ Q k − 1 , ˜ P k,i = (1 + µ k,i )( I − K k,i H k,i ) ¯ P k,i ( I − K k,i H k,i ) T + K k,i R k,i + 1+ µ k,i µ k,i B k,i K T k,i , ˇ P k,i = G 2 ( ˜ P k,i ) , P k,i = P j ∈N i ( k ) a i,j ( k ) ˜ P − 1 k,j − 1 , with ¯ n = n + p , ˜ Q k − 1 = blo c kdiag { Q k − 1 , 0 p × p } , ¯ Q k − 1 = D ˆ Q k − 1 D T . Her e, G 2 ( ˜ P k,i ) is the element-wise quantiza- tion operator by (3) without dither . Remark 4.1 In some distrib uted filtering algorithms [6, 7], besides state estimates, parameter matrices are also trans- mitted between neighboring sensors. In this work, the quan- tized messages { ˇ X k,j , ˇ P k,j } , will be r eceived by sensor i fr om its neighbor sensor j , j 6 = i . T o keep the consistency in Definition 2.1, the quantization err or of the parameter matrix is compensated by ˜ P k,j = ˇ P k,j + ¯ n ∆ j (2∆ j +1) 2 I ¯ n . The next lemma, proved in Appendix D, considers the design of the filtering gain matrix K k,i . Lemma 4.2 Solving the optimization pr oblem K ∗ k,i = arg min K k,i tr( ˜ P k,i ) yields K ∗ k,i = ¯ P k,i H T k,i H k,i ¯ P k,i H T k,i + R k,i 1 + µ k,i + B k,i µ k,i − 1 . Summing up the results of Lemmas 4.1 and 4.2, the ex- tended state based distributed Kalman filter (ESDKF) with quantized communications is provided in Algorithm 1. Algorithm 1 Extended State Based Distributed Kalman Fil- ter (ESDKF): Prediction: Each sensor carries out a prediction operation ¯ X k,i = A k − 1 ˆ X k − 1 ,i , ¯ P k,i = (1 + θ k,i ) A k − 1 P k − 1 ,i A T k − 1 + 1+ θ k,i θ k,i ¯ Q k − 1 + ˜ Q k − 1 , ∀ θ k,i > 0 . where ¯ Q k − 1 and ˜ Q k − 1 are gi ven in Lemma 4.1. Update: Each sensor uses its o wn observations to update the estimation ˜ X k,i = ¯ X k,i + K k,i ( y k,i − H k,i ¯ X k,i ) K k,i = ¯ P k,i H T k,i H k,i ¯ P k,i H T k,i + R k,i 1+ µ k,i + B k,i µ k,i − 1 ˜ P k,i = (1 + µ k,i )( I − K k,i H k,i ) ¯ P k,i . Quantization: Each sensor uses element-wise dither quan- tization to ˜ X k,i and interval quantization to ˜ P k,i , i.e., ˇ X k,i = G 1 ( ˜ X k,i ) , ˇ P k,i = G 2 ( ˜ P k,i ) , where G 1 ( · ) and G 2 ( · ) are the element-wise quantization operators with and without dither , respectively . Local Fusion: Each sensor receives ( ˇ X k,i , ˇ P k,i , ∆ j ) from its neighbors, denoting ¯ n = n + p, for j ∈ N i ( k ) , ( ˜ X k,j , ˜ P k,j ) = ( ( ˜ X k,j , ˜ P k,j ) , if i = j , ( ˇ X k,i , ˇ P k,j + ¯ n ∆ j (2∆ j +1) 2 I ¯ n ) , otherwise ˆ X k,i = P k,i P j ∈N i ( k ) a i,j ( k ) ˜ P − 1 k,j ˜ X k,j , P k,i = P j ∈N i ( k ) a i,j ( k ) ˜ P − 1 k,j − 1 . 4.2 Stability The next lemma, prov ed in Appendix E, is useful for further analysis. Lemma 4.3 Under Assumptions 2.1-2.3, if there ar e posi- tive constants { θ 1 , θ 2 , µ 1 , µ 2 } such that θ k,i ∈ ( θ 1 , θ 2 ) and µ k,i ∈ ( µ 1 , µ 2 ) , the following two conclusions hold. • 1) It holds that ˜ P − 1 k,i = ¯ P − 1 k,i 1+ µ k,i + H T k,i ∆ R − 1 k,i H k,i , k ∈ N , i ∈ V , where ∆ R k,i = R k,i + 1+ µ k,i µ k,i B k,i . • 2) There exists a positive scalar η such that ¯ P − 1 T l + s +1 ,i ≥ η A − T T l + s P − 1 T l + s,i A − 1 T l + s , s ∈ [0 : L ) , where { T l , l ∈ N } is an L-SS of { A k , k ∈ N } . Theorem 4.1 Consider the system (5) with Algorithm 1. Under Assumptions 2.1-2.6 and 3.1, if the param- eter L given in (1) satisfies L > max { k 0 , N } + ¯ N and there ar e positive constants { θ 1 , θ 2 , µ 1 , µ 2 } such 6 that θ k,i ∈ ( θ 1 , θ 2 ) and µ k,i ∈ ( µ 1 , µ 2 ) , then the se- quence of estimation err or covariances is stable, i.e., sup k ∈ N n E { ( ˆ X k,i − X k )( ˆ X k,i − X k ) T } o < + ∞ , ∀ i ∈ V . PR OOF . Due to the consistency in Lemma 4.1, we turn to prov e sup k ∈ N P k,i < ∞ . Under Assumption 2.2, { A k | A k ∈ R ( n + p ) × ( n + p ) , k ∈ N } has an L-SS, which is supposed to be { T l , l ∈ N } subject to L ≤ T l +1 − T l ≤ T < ∞ , ∀ l ≥ 0 , where L > max { k 0 , N } + ¯ N . W ithout loss of generality , we assume T 0 ≥ ¯ M , where ¯ M is giv en in Assumption 2.4. Otherwise, a subsequence of { T l , l ∈ N } can always be obtained to satisfy the requirement. W e divide the sequence set { T l , l ≥ 0 } into two non-ov erlapping time set: { T l + L, l ≥ 0 } and S l ≥ 0 [ T l + L + 1 : T l +1 + L − 1] . 1) First, we consider the case of k = T l + L , l ≥ 1 . For con venience, let ¯ k , T l + L . It can be easily sho wn that ˇ P k,i + ¯ n ∆ i (2∆ i +1) 2 I ¯ n − 1 ≥ % ˜ P − 1 ¯ k,i , where % ∈ (0 , 1] and ¯ n = n + p . According to Lemma 4.3, we obtain P − 1 ¯ k,i ≥ % X j ∈N i ( ¯ k ) a i,j ( ¯ k ) ˜ P − 1 ¯ k,j ≥ %η (1 + µ 2 ) X j ∈N i ( ¯ k ) a i,j ( ¯ k ) A − T ¯ k − 1 P − 1 ¯ k − 1 ,j A − 1 ¯ k − 1 + X j ∈N i ( ¯ k ) a i,j ( ¯ k ) H T ¯ k,j ∆ R − 1 ¯ k,j H ¯ k,j . (8) By recursiv ely applying (8) for L times, denoting δ = %η (1+ µ 2 ) , one has P − 1 ¯ k,i ≥ a min δ L − 1 µ 1 µ 1 + 1 L − 1 X s = k 0 " Φ − T ¯ k, ¯ k − s (9) · X j ∈V H T ¯ k − s,j ( R ¯ k − s,j + B ¯ k − s,j ) − 1 H ¯ k − s,j # Φ − 1 ¯ k, ¯ k − s , where a min = min i,j ∈V a ¯ k, ¯ k − s i,j > 0 , s ∈ [max { k 0 , N } : L ) , and a ¯ k, ¯ k − s i,j is the ( i, j ) th element of Π ¯ k l = ¯ k − s A σ l . Note that a min can be obtained under Assumption 2.5, since the elements of A σ k belong to a finite set and the jointly strongly connected network can lead to a ¯ k, ¯ k − s i,j > 0 , s ≥ max { k 0 , N } . Under Assumptions 2.2 and 2.4, there exists a constant positi ve definite matrix ˘ P , such that P k,i ≤ ˘ P , k = T l + L. 2) Second, we consider the time set S l ≥ 0 [ T l + L + 1 : T l +1 + L − 1] . Considering (9), we have P T l + L,i ≤ ˘ P , k ≥ L. Since the length of the interval k ∈ [ T l + L + 1 : T l +1 + L − 1] is bounded by T < ∞ , we can just consider the prediction stage to study the boundedness of P k,i , for k ∈ [ T l + L + 1 : T l +1 + L − 1] . Under Assumption 2.2 and Proposition 3.1, there is a scalar β 1 > 0 such that A k A T k ≤ β 1 I n . Due to sup k ( ¯ Q k + ˜ Q k ) < ∞ , it is safe to conclude that there exists an constant matrix P mid , such that P k,i ≤ P mid , k ∈ [ T l + L + 1 : T l +1 + L − 1] (10) 3) Finally , for the time interval [0 : T 0 + L ] , there exists a constant matrix ˆ P , such that P k,i ≤ ˆ P , k ∈ [0 : T 0 + L ] . (11) According to (10) and (11), we have sup k ∈ N P k,i < ∞ . An upper bound of error cov ariance can be derived by the proof of Theorem 4.1, from which the influence of quantiza- tion interval size ∆ i can be seen through the scalar % . W ith the increase of ∆ i , the upper bound will become larger . 4.3 Design of parameters In this subsection, the design methods for the parameters θ k,i and µ k,i are considered by solving two optimization problems. a) Design of θ k,i At the prediction stage, the design of the parameter θ k,i is aimed to minimize the trace of ¯ P k,i , which is an upper bound of mean square error by Lemma 4.1. Mathematically , the optimization problem on θ k,i is gi ven as θ ∗ k,i = arg min θ k,i tr( ¯ P k,i ) , (12) where ¯ P k,i = (1 + θ k,i ) A k − 1 P k − 1 ,i A T k − 1 + 1+ θ k,i θ k,i ¯ Q k − 1 + ˜ Q k − 1 . Since (12) is con vex, which can be numerically solved by many existing con vex optimization methods. The next proposition 4.1, prov ed in Appendix F , provides the closed- form solution of (12). Proposition 4.1 Solving (12) yields the closed-form solu- tion θ ∗ k,i = s tr( ¯ Q k − 1 ) tr( A k − 1 P k − 1 ,i A T k − 1 ) , i ∈ V . Furthermor e, it holds that θ ∗ k,i > 0 . 7 b) Design of µ k,i Considering the consistency , we cast the design of µ k,i into the follo wing optimization problem: µ ∗ k,i = arg min µ k,i tr( ˜ P k,i ) , s.t. µ k,i > 0 . (13) Remark 4.2 Although the optimization in (13) is not con- vex, it can be solved by some existing methods, such as the quasi-Newton methods or the nonlinear least squar e [25]. 4.4 Asymptotically unbiased W e write f k = O ( g k ) (or f k = o ( g k ) ) if and only if f k ≤ M g k for all k ≥ 0 (or lim k →∞ f k g k = 0 ). The follo wing two lemmas, prov ed in [26] and Appendix G respecti vely , are to find conditions ensuring the asymptotic unbiasedness of Algorithm 1. Lemma 4.4 Suppose that Π 0 and Π 1 satisfy 0 ≤ Π 0 ≤ Π 1 and Π 1 > 0 , then Π 0 Π − 1 1 Π 0 ≤ Π 0 . Lemma 4.5 Let { d k } ∈ R be generated by d k +1 = ρd k + m k with ρ ∈ (0 , 1) and d 0 < ∞ , then (1) if m k = o (1) , then d k = o (1) , i.e., d k → 0 as k → ∞ ; (2) if m k = o ( δ k ) and ρ < δ < 1 , then d k = o ( δ k ) ; (3) if m k = o ( 1 k M ) with M ∈ N + , then d k = o ( 1 k M − 1 ) . Theorem 4.2 Consider the system (5) satisfying the same conditions as Theorem 4.1 and λ min { A k A T k } ≥ β 0 > 0 . Denoting M k := max j ∈V k E { b k,j }k 2 2 + k E { u k }k 2 2 , • if M k = o (1) , then k E { e k,i }k 2 = o (1) ; • if M k = o ( k − M ) with M ∈ N + , then k E { e k,i }k 2 = o ( k 1 − M 2 ) ; • if M k = o ( δ k ) and ˜ % < δ < 1 , then k E { e k,i }k 2 = o ( δ k 2 ) , wher e ˜ % ∈ (0 , 1) is defined in (16) . PR OOF . Since ¯ P k,i is positiv e definite, we define the fol- lowing function V k,i ( E { ¯ e k,i } ) = E { ¯ e k,i } T ¯ P − 1 k,i E { ¯ e k,i } . From the fact (iii) of Lemma 1 in [6] and the non- singularity of A k , we hav e V k +1 ,i ( E { ¯ e k +1 ,i } ) ≤ % E { ¯ e k +1 ,i } T A − T k P − 1 k,i A − 1 k E { ¯ e k +1 ,i } , where 0 < % < 1 . Since w k is zero-mean, E { ¯ e k +1 ,i } = A k E { e k,i } − D E { u k } . Then, there exists a scalar α 0 > 0 , such that ¯ % 1 = % (1 + α 0 ) ∈ (0 , 1) , and V k +1 ,i ( E { ¯ e k +1 ,i } ) ≤ ¯ % 1 E { e k,i } T P − 1 k,i E { e k,i } + O ( k E { u k }k 2 2 ) . (14) As the quantization error is uniformly distributed in [ − ∆ i 2 , ∆ i 2 ] , the quantization error is zero-mean. By (14) and Lemma 2 in [6], there exists a scalar ¯ % 2 ∈ (0 , 1) such that V k +1 ,i ( E { ¯ e k +1 ,i } ) ≤ ¯ % 2 X j ∈N i ( k ) a i,j ( k ) E { ˜ e k,j } T ˜ P − 1 k,j E { ˜ e k,j } + O ( k E { u k }k 2 2 ) . (15) Notice that ˜ P k,j = (1 + µ k,j )( I − K k,j H k,j ) ¯ P k,j and E { e k,j } = ( I − K k,j H k,j ) E { ¯ e k,j } + K k,j E { b k,j } , then we hav e ¯ P − 1 k,j 1+ µ k,j = ˜ P − 1 k,j ( I − K k,j H k,j ) and ˜ P − 1 k,j ≤ ˜ P − 1 k,j . There exists a suf ficiently small scalar α 1 > 0 such that ¯ % 2 (1 + α 1 ) < 1 . Denote ˜ % = ¯ % 2 (1 + α 1 ) , (16) For this α 1 , we have E { ˜ e k,j } T ˜ P − 1 k,j E { ˜ e k,j } ≤ (1 + α 1 ) E { ¯ e k,j } T ( I − K k,j H k,j ) T × ˜ P − 1 k,j ( I − K k,j H k,j ) E { ¯ e k,j } + O ( k E { b k,j }k 2 2 ) ≤ (1 + α 1 ) E { ¯ e k,j } T ¯ P − 1 k,j 1 + µ k,j ˜ P k,j ¯ P − 1 k,j 1 + µ k,j E { ¯ e k,j } + O ( k E { b k,j k 2 2 ) ≤ (1 + α 1 ) E { ¯ e k,j } T ¯ P − 1 k,j E { ¯ e k,j } + O ( k E { b k,j k 2 2 ) where the last inequality is obtained by Lemma 4.4 and 1) of Lemma 4.3. By (15) and (16), we have V k +1 ,i ( E { ¯ e k +1 ,i } ) ≤ ˜ % X j ∈N i ( k ) a i,j ( k ) V k,j ( E { ¯ e k,j } ) + O (max j ∈V k b k,j k 2 2 ) + O ( k u k k 2 2 ) (17) Due to A k = [ a i,j ( k )] , i, j = 1 , 2 , · · · , N , summing up (17) for i = 1 , 2 , · · · , N , then V k +1 ( E { ¯ e k +1 } ) (18) ≤ ˜ % A k V k ( E { ¯ e k } ) + 1 N ⊗ ( O (max j ∈V k b k,j k 2 2 ) + O ( k u k k 2 2 )) , where V k ( E { ¯ e k } ) = [ V T k, 1 ( E { ¯ e k, 1 } ) , . . . , V T k,N ( E { ¯ e k,N } )] T . T aking 2-norm operator on both sides of (18) and con- sidering kA k k 2 = 1 yields k V k +1 ( E { ¯ e k +1 } ) k 2 ≤ ˜ % k V k ( E { ¯ e k } ) k 2 + O max j ∈V k b k,j k 2 2 + k u k k 2 2 . Due to M k = max j ∈V k b k,j k 2 2 + k u k k 2 2 = o (1) and (1) of Lemma 4.5, the estimate sequence of each sensor by Algorithm 1 is asymptotically unbiased. Furthermore, if M k satis- fies certain conv ergence rates (i.e., M k = o ( k − M ) or M k = o ( δ k ) ), by (2) and (3) of Lemma 4.5, the estimation bias is con ver gent to zero with certain rates (i.e., o ( k 1 − M 2 ) or o ( δ k 2 ) ), respecti vely . 8 Remark 4.3 Theor em 4.2 shows the polynomial and expo- nential con ver gence rates of estimation bias by Algorithm 1 in presence of decaying observation biases and uncertain dynamics. In pr actical applications, if the observation bi- ases of sensors do not conver ge to zero or the uncertainty does not con ver ge to a constant vector , one can analyze an upper bound (i.e., b 1 ) of estimation bias with the similar pr ocedure as the pr oof of Theor em 4.2. Additionally , due to E { ˆ X k,i − X k } E { ˆ X k,i − X k } T + C ov { ˆ X k,i − X k } = E { ( ˆ X k,i − X k )( ˆ X k,i − X k ) T } ≤ P k,i , it holds that b 2 := k E { ( ˆ X k,i − X k ) }k 2 ≤ p k P k,i k 2 . Then one can utilize the value min { b 1 , b 2 } to evaluate the estimation bias in r eal time. 5 Distributed filter: event-trigger ed update In this section, we will study an e ven-triggered update based DKF and analyze the conditions to ensure the mean square boundedness and asymptotic unbiasedness. 5.1 Event-trigger ed update scheme Due to the influence of random noise and observation bias ov er the system (2), some corrupted observations may lead to the performance degradation of filters. Thus, we aim to provide a scheme to decide when the observation is utilized or discarded. W e introduce the information metric S k,i , de- fined as S k,i , H T k,i R k,i + (1+ µ k,i ) µ k,i B k,i − 1 H k,i . In the following, we define the update ev ent and the ev ent-triggered scheme. Definition 5.1 W e say that an update event E of sensor i is trigger ed at time k , if sensor i utilizes the observation y k,i to update the estimate as Algorithm 1. The e vent E is triggered at time k (i.e., y k,i is utilized) if λ max S k,i − µ k,i 1 + µ k,i ¯ P − 1 k,i > τ , (19) where τ ≥ 0 is the preset triggering threshold of the obser- vation update. Otherwise, y k,i will be discarded. Remark 5.1 The triggering scheme in (19) shows that if the curr ent information is more sufficient in at least one channel than the pr ediction information, then it is worth using the available observation in the update stag e. The triggering thr eshold τ is used as a measure of information incr ement. The following lemma, proved in Appendix H, provides an equiv alent form of the triggering scheme. Lemma 5.1 The event-trigg er ed scheme (19) is satisfied if and only if λ max ( ˜ P − 1 k,i − ¯ P − 1 k,i ) > τ , (20) wher e ˜ P k,i = (1 + µ k,i )( I − K k,i H k,i ) ¯ P k,i and τ ≥ 0 . Since Algorithm 1 is consistent, ˜ P − 1 k,i and ¯ P − 1 k,i stand for the lower bounds of information matrices at the update stage and the prediction stage, respectiv ely . Then ˜ P − 1 k,i − ¯ P − 1 k,i reflects the variation of statistical information resulted from a new observation. In light of Lemma 5.1, the ev ent E is triggered if sufficiently new information is accumulated at the update stage. 5.2 ESKDF with event-trigger ed update Based on the event-triggered scheme (19) and Algorithm 1, we can obtain the extended state based DKF with ev ent- triggered update scheme in Algorithm 2. According to Al- Algorithm 2 ESDKF based on event-triggered update: Prediction: the same as the one of Algorithm 1 Event-trigger ed update: If (19) is satisfied, then K k,i = ¯ P k,i H T k,i H k,i ¯ P k,i H T k,i + R k,i 1+ µ k,i + B k,i µ k,i − 1 ˜ P k,i = (1 + µ k,i )( I − K k,i H k,i ) ¯ P k,i . ˜ X k,i = ¯ X k,i + K k,i ( y k,i − H k,i ¯ X k,i ) Otherwise, ˜ X k,i = ¯ X k,i , ˜ P k,i = ¯ P k,i . Quantization: the same as the one of Algorithm 1 Local Fusion: the same as the one of Algorithm 1 gorithms 1 and 2, we can easily obtain Lemma 5.2. Lemma 5.2 Consider the system (5) with Algorithm 2. Un- der Assumptions 2.1, 2.3 and 2.6, the pairs ( ¯ X k,i , ¯ P k,i ), ( ˜ X k,i , ˜ P k,i ), ( ˜ X k,i , ˜ P k,i ) and ( ˆ X k,i , P k,i ) ar e all consistent. The next lemma, proved in Appendix H, is on Algorithm 2. Lemma 5.3 Under the event-trigger ed update scheme, for Algorithm 2, it holds that ˜ P − 1 k,i ≥ ¯ P − 1 k,i 1+ µ k,i + H T k,i ∆ R − 1 k,i H k,i − τ I n + p , wher e ∆ R k,i = R k,i + 1+ µ k,i µ k,i B k,i . The next proposition, proved in Appendix H, studies the relation between Algorithm 1 and Algorithm 2, which shows that the ev ent-triggered observation update scheme can lead to a tighter bound of error covariance than the typical time- driv en observation update. Proposition 5.1 Let P As k,i , s = 1 , 2 , be the P k,i matrix of Algorithm 1 and Algorithm 2, r espectively . If the two al- gorithms shar e the same initial setting and τ = 0 , then P A 2 k,i ≤ P A 1 k,i . Remark 5.2 Compar ed with Algorithm 1, Algorithm 2 is able to obtain better estimation performance since it dis- car ds corrupted observations that may deteriorate the esti- mation performance. Meanwhile, in the scenarios as [27, 28] 9 wher e the estimator and sensor ar e distributed at differ ent geogr aphical locations with ener gy-constrained communi- cation channels, it is suggested to judge which observations contain novel information and to decide when the observa- tions are transmitted fr om the sensor to the r emote estimator . These tasks can be achie ved by the pr oposed event-trig ger ed update scheme . 5.3 Stability and asymptotic unbiasedness Theorem 5.1 Consider the system (5) and Algorithm 2 un- der Assumptions 2.1-2.6 and 3.1. If the parameter L given in (1) satisfies L > max { k 0 , N } + ¯ N and θ k,i ∈ ( θ 1 , θ 2 ) , µ k,i ∈ ( µ 1 , µ 2 ) for positive constants { θ 1 , θ 2 , µ 1 , µ 2 } , then ther e exists a scalar ϑ > 0 , such that for 0 ≤ τ < ϑ , sup k ∈ N E { e k,i e T k,i } < + ∞ , ∀ i ∈ V . Furthermor e, if inf k λ min A k A T k > 0 , then max i ∈V sup k ≥ L λ max E { e k,i e T k,i } ≤ 1 a 0 − τ a 1 , wher e e k,i = ˆ X k,i − X k , a 0 and a 1 ar e given in (22) . PR OOF . According to Lemma 5.2, we turn to prove sup k ∈ N P k,i < ∞ . Similar to the proof of Theorem 4.1, with the same notations, we consider the time set S l ≥ 0 [ T l + L + 1 : T l +1 + L − 1] . The rest part can be similarly prov ed by taking the method as the proof of Theorem 4.1. W e ha ve P − 1 ¯ k,i ≥ δ L Φ − T ¯ k, ¯ k − L h P j ∈V a ¯ k, ¯ k − L i,j P − 1 ¯ k − L,j i Φ − 1 ¯ k, ¯ k − L + ˘ P − 1 ¯ k,i , where δ = %η (1+ µ 2 ) and ˘ P − 1 ¯ k,i = % L − 1 X s =0 δ s " Φ − T ¯ k, ¯ k − s X j ∈V a ¯ k, ¯ k − s i,j (21) · H T ¯ k − s,j ∆ R − 1 ¯ k − s,j H ¯ k − s,j − τ I n + p Φ − 1 ¯ k, ¯ k − s # . W e hav e P − 1 ¯ k,i ≥ ˘ P − 1 ¯ k,i . T o prove the conclusion, we turn to prov e there is a constant matrix S > 0 , such that ˘ P − 1 ¯ k,i ≥ S . Under the conditions of this theorem, it follows from the proof of Theorem 4.1 that there is a scalar π > 0 , such that P L − 1 s =0 δ s Φ − T ¯ k, ¯ k − s h P j ∈V a ¯ k, ¯ k − s i,j H T ¯ k,j ∆ R − 1 ¯ k,j H ¯ k,j i Φ − 1 ¯ k, ¯ k − s ≥ π I n + p . Denote Ξ ¯ k = P L − 1 s =0 δ s Φ − T ¯ k, ¯ k − s Φ − 1 ¯ k, ¯ k − s . T o guaran- tee inf ¯ k ˘ P − 1 ¯ k,i > 0 , it is sufficient to prove that there exists a constant matrix S , such that π I n + p − τ Ξ ¯ k ≥ S > 0 . Under Assumption 2.2, there exists a constant scalar ¯ µ > 0 , such that sup ¯ k Ξ ¯ k ≤ ¯ µI n + p . Let S = ( π − τ ¯ µ ) I n + p , then a suf ficient condition is 0 ≤ τ < π ¯ µ . Choosing ϑ = π ¯ µ > 0 , then the boundedness is obtained. Furthermore, if inf k λ min { A k A T k } > 0 , then the above analysis holds for any k ≥ L with no prediction step in the proof of Theo- rem 4.1. Thus, for any k ≥ 0 , it holds that P − 1 k,i ≥ ˘ P − 1 ¯ k,i ≥ % ( π − τ ¯ µ ) I n + p . Let a 0 = %π , a 1 = % ¯ µ, (22) then we have max i ∈V sup k ≥ L λ max ( P k,i ) ≤ 1 a 0 − τ a 1 . In light of the consistency in Lemma 4.1, the conclusion holds. Remark 5.3 If better performance of Algorithm 2 is pur- sued, one could let τ be zer o or sufficiently small, which can ensur e a smaller bound of mean square err or by Proposition 5.1. If one aims to r educe the update frequency with stable estimation err or , a relatively lar ge τ can be set by satisfy- ing the r equir ement in Theor em 5.1. Note that if a too larg e τ is given such that the triggering condition (19) is hardly satisfied, then most of observation information will be dis- car ded. As a result, the collective observability condition in Assumption 2.4 may not hold, which means that the bound- edness of estimation error covariances is not guaranteed. T o analyze the asymptotic unbiasedness of Algorithm 2, for con venience, we denote I k,i = H T k,i R k,i + 1 + µ 2 µ 2 B k,i − 1 H k,i ¯ a = sup k ∈ N { λ max ( A k A T k ) } , b w = sup { λ max ( ¯ Q k ) } r 0 = (1 + θ 2 )( a 0 − τ a 1 )¯ a + 1 + θ 1 θ 1 b w + b q r 1 = µ 1 ( µ 1 + 1) r 0 + τ , b q = sup { λ max ( ˜ Q k ) } , (23) where a 0 and a 1 are gi ven in (22), { θ 1 , θ 2 , µ 1 , µ 2 } are giv en in Theorem 5.1. Theorem 5.2 Consider the system (5) with Algorithm 2 under the same conditions as Theorem 5.1. If ther e is an inte ger ˜ M > L such that the set S = { i ∈ V | sup k ≥ ˜ M λ max ( I k +1 ,i ) ≤ r 1 } is non-empty , and • if ¯ M k = o (1) , then k E { e k,i }k 2 = o (1) ; • if ¯ M k = o ( k − M ) with M ∈ N + , then k E { e k,i }k 2 = o ( k 1 − M 2 ) ; • if ¯ M k = o ( δ k ) and ˜ % < δ < 1 , then k E { e k,i }k 2 = o ( δ k 2 ) , wher e ˜ % ∈ (0 , 1) is defined in (16) , wher e ¯ M k := max j ∈V −S k E { b k,j }k 2 2 + k E { u k }k 2 2 . Remark 5.4 Theor em 5.2 shows that the estimation biases of Algorithm 2 tend to zer o even if the observation biases of some sensors do not decay . The pr oof of Theorem 5.2 is similar to that of Theorem 4.2, by noting that ˜ P k,i = ¯ P k,i , for i ∈ V − S . 10 In the follo wing, we show the feasibility of the condition that there is a positi ve integer ˜ M > L such that the set S = { i ∈ V | sup k ≥ ˜ M λ max ( I k +1 ,i ) ≤ r 1 } is non-empty . Feasibility for a non-empty S T o find the condition under which the set S is non-empty , we prove that the condition sup k ≥ ˜ M λ max ( I k +1 ,i ) ≤ r 1 can be satisfied for some sensors. Note that under the condi- tions of Theorem 5.2, then the conclusions of Theorem 5.1 holds as well. Thus, recalling the notations in (23), we hav e a 0 − τ a 1 > 0 , which leads to r 0 > 0 and then r 1 > τ > 0 . Meanwhile, whatev er ho w τ is small, r 1 has a uniformly lower bound by noting 0 < r 0 ≤ (1 + θ 2 ) a 0 ¯ a + 1+ θ 1 θ 1 b w + b q . If there is M ≥ L , such that sup k ≥ ˜ M λ max ( I k +1 ,i ) ≤ r 1 , then S is non-empty . Simple examples ensuring this condi- tion include that for k ≥ ˜ M ≥ L , k H k,i k 2 being v ery small, λ max R k,i + 1+ µ 2 µ 2 B k,i being very large, and so on. The ev ent-triggered scheme and the time-driv en scheme hav e some similar properties in estimation consistency , boundedness of error co variances, and asymptotic unbiased- ness of estimates. The differences between the two schemes are explicitly shown in T able 2. 6 Numerical Simulations In this section, numerical simulations are carried out to demonstrate the aforementioned theoretical results and show the ef fectiv eness of the proposed algorithms. 6.1 P erformance Evaluation In this and next subsections, let us consider an object whose motion is described by the kinematic model [29] with un- certain dynamics: x k +1 = 1 0 T 0 0 1 0 T 0 0 1 0 0 0 0 1 x k + 0 0 0 0 T 0 0 T f ( x k , k ) + ω k , (24) where T = 0 . 1 is the sampling step, x k is the unkno wn state vector consisting of four -dimensional components along the coordinate axes and f ( x k , k ) is the uncertain dynamics. The cov ariance of process noise ω k is Q k = diag ([4 , 4 , 1 , 1]) . The kinematic state of the object is observed by means of four sensors modeled as y k,i = ¯ H k,i x k + b k,i + v k,i , i = 1 , 2 , 3 , 4 . The observ ation noise [ v k, 1 , . . . , v k,N ] T is i.i.d. Gaussian with cov ariance R k = 4 × I 4 . Additionally , the sensor network’ s communication topology is assumed to be di- rected and switching, whose adjacency matrix is selected from A 1 = 1 0 0 0 0 . 5 0 . 5 0 0 0 0 . 5 0 . 5 0 0 0 0 . 5 0 . 5 , A 2 = 0 . 5 0 . 5 0 0 0 1 0 0 0 0 . 3 0 . 4 0 . 3 0 0 . 5 0 0 . 5 and A 3 = 0 . 5 0 . 5 0 0 0 0 . 5 0 . 5 0 0 0 1 0 0 . 25 0 . 25 0 . 25 0 . 25 . And the topology switch- ing signal σ k = mo d b k 5 c , 3 + 1 , where mod ( a, b ) stands for the modulo operation of a by b . In the fol- lowing, we conduct the numerical simulations through Monte Carlo experiment, in which 500 runs for the con- sidered algorithms are implemented, respectively . The Root Mean Square Error (RMSE) av eraged ov er all the sensors is defined as RM S E k = q 1 4 P 4 i =1 M S E k,i , where M S E k,i = 1 500 P 500 j =1 x j k,i − ˆ x j k,i T x j k,i − ˆ x j k,i , and ˆ x j k,i is the state (position or velocity) estimate of the j th run of sensor i at the k th time instant. Be- sides, we denote P k = 1 4 P 4 i =1 P k,i . The mean estima- tion error (ME) averaged over all sensors is defined by M E k = 1 4 P 4 i =1 1 500 P 500 j =1 1 4 P 4 l =1 x j k,i ( l ) − ˆ x j k,i ( l ) . It is assumed that the initial state is a zero-mean random vector with cov ariance matrix P 0 = diag ([10 , 10 , 1 , 1]) . The uncertain dynamics and the state-correlated bias are assumed to be f ( x k , k ) = 1 3 sin( x k (3))+ k sin( x k (4))+ k and b k,i = sat 2 sin x 2 k (1) + x 2 k (2) + b 0 ,i , 2 , respec- tiv ely , where the initial bias b 0 ,i is generated uni- formly within [-2,2]. W e assume B k,i = 4 . The ob- servation matrices are supposed to be switching with time, follo wing ¯ H k,i = ¯ H mod ( i + b k 10 c , 4 ) +1 , and ¯ H 1 = ( 1 0 0 0 ) , ¯ H 2 = ( 0 1 0 0 ) , ¯ H 3 = ¯ H 4 = ( 0 0 0 0 ) . And the parameters of Algorithm 1 and Algorithm 2 are set X i, 0 = 0 6 × 1 , P i, 0 = P 0 0 4 × 2 0 2 × 4 I 2 , ˆ Q k = 10 − 3 × I 2 , µ k,i = 0 . 3 , τ i = 0 . 001 , ∀ i = 1 , 2 , 3 , 4 . First, we carry out numerical simulations for Algorithm 1 (i.e., ESDKF) and Algorithm 2 with results giv en in Fig. 1 and Fig. 2. Fig. 1 shows Algorithm 2 generally hav e better performance than Algorithm 1. Meanwhile, Fig. 2 sho ws the triggering time instants of observation update for each sensor . Be- cause of the periodic switching of observation matrices, the triggering time instants of all sensors are also periodic. Thus, compared with Algorithm 1, Algorithm 2 can reduce the frequency of observation update with competitive esti- mation performance. Fig. 2 also gi ves the behavior of the RMSE and p tr ( P k ) of Algorithm 2, from which one can see the estimation error covariances of the proposed ES- DKF keep stable in the given period and the consistency of each sensor remains. 6.2 Asymptotically unbiasedness of Algorithms 1 and 2 Next, we gi ve a numerical simulation to verify Theorem 4.2 and Theorem 5.2. In this subsection, the uncertain dynamics is assumed to be f ( x k , k ) = 1 2 k sin( x k (3)) sin( x k (4)) + ( 1 1 ) , and the state-correlated bias b k,i has two situations: 11 T able 2 Differences of time-driv en and ev ent-triggered update schemes update scheme observation threshold stability condition asymptotic unbiasedness time-driv en always no system+topology decaying observation biases of all sensors ev ent-triggered selective yes system+topology+threshold non-decaying observation biases of some sensors 0 20 40 60 80 100 120 140 160 180 200 Time step -5 0 5 10 Position(m) RMSE1-RMSE2 0 20 40 60 80 100 120 140 160 180 200 Time step -5 0 5 10 15 Velocity(m/s) RMSE1-RMSE2 Fig. 1. RMSE difference between Algorithm 1 and Algorithm 2 0 50 100 150 200 Time step -1 0 1 Sensor1 0 50 100 150 200 Time step -1 0 1 Sensor2 0 50 100 150 200 Time step -1 0 1 Sensor3 0 50 100 150 200 Time step -1 0 1 Sensor4 0 50 100 150 200 Time step 0 50 100 Position(m) RMSE of ESDKF sqrt(tr(P)) of ESDKF 0 50 100 150 200 Time step 0 50 100 Velocity(m/s) RMSE of ESDKF sqrt(tr(P)) of ESDKF Fig. 2. T riggering times, RMSE and p tr( P ) of Algorithm 2 • Situation 1: b k,i = 1 k sat ( s k,i , 2) , B k,i = 4 k 2 i = 1 , 2 , 3 , 4 where s k,i = 2 sin x 2 k (1) + x 2 k (2) + b 0 ,i , and b 0 ,i is generated uniformly within [-2,2]. • Situation 2: b k,i = 1 k sat ( s k,i , 2) , B k,i = 4 k 2 , i = 1 , 2 , sat ( ˜ s k,i , 40) , B k,i = 1600 , i = 3 , 4 , where ˜ s k,i = 40 sin x 2 k (1) + x 2 k (2) + b 0 ,i , b 0 , 1 and b 0 , 2 are generated uniformly within [-2,2], b 0 , 3 and b 0 , 4 are generated uniformly within [-40,40]. In Situation 2, the biases of sensor 3 and sensor 4 are big and do not tend to zero. The observation ma- trices are supposed to be ¯ H k, 1 = ( 1 0 0 0 ) , ¯ H k, 2 = ( 0 1 0 0 ) , ¯ H k, 3 = ( 1 0 0 0 ) , ¯ H k, 4 = ( 0 1 0 0 ) . And the parameters of Algorithm 1 and Algorithm 2 are set X i, 0 = − 10 10 √ 10 √ 10 0 0 T , P i, 0 = 11 P 0 0 4 × 2 0 2 × 4 I 2 , ˆ Q k = 10 − 3 × I 2 , µ k,i = 0 . 3 , τ i = 0 . 001 , ∀ i = 1 , 2 , 3 , 4 . Fig. 3 giv es the mean estimation error of Algorithm 1 and Algorithm 2 under Situation 1 and Situation 2. From this figure, one can see, under Situation 1, both Algorithm 1 and Algorithm 2 are asymptotically unbiased; howe ver , under Situation 2, only Algorithm 2 is asymptotically unbiased. Thus Thereom 4.2 and Theorem 5.2 are verified. 0 20 40 60 80 100 120 140 160 180 200 Time step -10 -5 0 5 10 Mean estimation error of Algorithm 1 Situation 1 Situation 2 0 20 40 60 80 100 120 140 160 180 200 Time step -5 0 5 10 Mean estimation error of Algorithm 2 Situation 1 Situation 2 Fig. 3. Mean estimation error of Algorithm 1 and Algorithm 2 6.3 Comparisons with other algorithms T o verify that the proposed algorithm can handle singu- lar system matrices, as stated in Theorems 4.1 and 5.1, in this subsection, let us leave out the physical meaning of system (24) and assume that the system matrix satisfies ¯ A k = 1 0 T 0 0 1 0 T 0 0 1 0 0 0 0 1 if mo d ( k , 10) < 8 . Otherwise, ¯ A k = 1 0 T 0 0 1 0 T 0 0 1 0 0 0 1 0 . Besides, we consider a network with 20 nodes, where 3 kinds of nodes in this network: sensor A, sensor B and non-sensing node. A non-sensing node has no observa- tion but it is capable to run algorithms and communicate with other nodes. The observation matrices of sensor A and sen- sor B are supposed to be ¯ H A = ( 1 0 0 0 ) , ¯ H B = ( 0 1 0 0 ) . The distribution of these 3 kinds of nodes is given in Fig. 4, which is undirected and switching between tw o graphs. Note that a non-sensing node i can implement algorithms by assuming ¯ H k,i = 0 and y k,i = 0 . In the figure, the dot- ted red lines and blue lines will exist successively for every fiv e time instants. The elements of the adjacency matrix are 12 set to be a G s i,j = 1 | N G s i | . The setting of uncertain dynamics and bias is the same as Subsection 6.1. sensor A sensor B non-sensing node Fig. 4. Communication topology of the sensor network For above system, we carry out numerical simulations to compare Algorithm 2 with other three algorithms, namely , distributed state estimation with consensus on the posteri- ors (DSEA-CP) [6], centralized Kalman filter (CKF) and centralized extended state based Kalman filter (CESKF) [16]. For DSEA-CP , the initial estimate is assume to be ˆ x 0 ,i = 0 4 × 1 , P 0 ,i = P 0 , ∀ i = 1 , 2 , 3 , 4 . As for CKF , in a data center, the CKF is utilized with the form of standard Kalman filter by employing the collected observations from all sensors. Here, the initial estimate of CKF are ˆ x 0 = 0 4 × 1 , P CKF 0 = P 0 . Similar to CKF , CESKF is utilized with the form of ESKF [16] by employing the collected observations from all sensors. As for the parameter of CESKF are set to be ˆ X 0 = 0 6 × 1 , P CESKF 0 = P 0 0 4 × 2 0 2 × 4 I 2 , ˆ Q k = I 2 . The performance comparison result of the above algorithms is shown in Fig. 5. From this figure, one can see that the RMSE of x 3 and x 4 for DSEA-CP and CKF become un- stable, but the estimation errors of CESKF and Algorithm 2 still keep stable. The stability of CESKF and Algorithm 2 lies in its capability in handling with uncertain nonlinear dynamics. Since CESKF is a centralized filter without be- ing affected by the quantized channels and the switching of communication topologies, its estimation error is smaller than ESDKF . For the DSEA-CP , due to the existence of un- bounded uncertain dynamics and the switching topologies, both the position estimation error and the velocity estima- tion error are div ergent. As for CKF , since observ ations (po- sition information) of all sensors are av ailable, the position estimation error is stable. Howe ver , the velocity estimation error is diver gent since the existence of unbounded uncer - tain dynamics. Based on the above results, we can see the proposed Algo- rithm 1 and Algorithm 2 are effecti ve distributed filtering algorithms for the considered scenarios. 7 Conclusion In this paper , we studied a distributed filtering problem for a class of general uncertain stochastic systems. By treating the nonlinear uncertain dynamics as an extended state, we 0 20 40 60 80 100 120 140 160 180 200 Time step 0 10 20 30 RMSE of (x 1 ,x 2 ) RMSE of ESDKF RMSE of DSEA-CP RMSE of CKF RMSE of CESKF 0 20 40 60 80 100 120 140 160 180 200 Time step 0 50 100 150 RMSE of (x 3 ,x 4 ) RMSE of ESDKF RMSE of DSEA-CP RMSE of CKF RMSE of CESKF Fig. 5. Estimation performance of different algorithms proposed a nov el consistent distributed Kalman filter based on quantized sensor communications. T o alleviate the effect of biased observations, the event-triggered observ ation up- date based distrib uted Kalman filter was presented with a tighter bound of error co variance than that of the time-driven one by designing a proper threshold. Based on mild condi- tions, the boundedness of the estimation error covariances and the asymptotic unbiasedness of state estimate for both the proposed two distributed filters were proved. Acknowledgements The authors would like to thank the editors and anony- mous re viewers for their v ery constructi ve comments, which greatly improv ed the quality of this work. A Proof of Proposition 3.1 Recall A k = ¯ A k ¯ G k 0 I p ! , and sup k ∈ N { ¯ G k ¯ G T k } < ∞ , then we hav e A k A T k = ¯ A k ¯ A T k + ¯ G k ¯ G T k ¯ G k ¯ G T k I p ! . (A.1) First, we consider the proof of 1). W e start with the suf- ficiency of 1). According to (A.1), we hav e A k A T k ≤ 2 ¯ A k ¯ A T k + ¯ G k ¯ G T k 0 0 I p . Thus, sup k { ¯ A k ¯ A T k } < ∞ and sup k { ¯ G k ¯ G T k } < ∞ lead to sup k { A k A T k } < ∞ . W e then consider the necessity of 1). If sup k { A k A T k } < ∞ , it fol- lows from (A.1) that sup k { ¯ A k ¯ A T k + ¯ G k ¯ G T k } < ∞ . Due to ¯ G k ¯ G T k ≥ 0 , then sup k { ¯ A k ¯ A T k } < ∞ . Next, we consider the proof of 2). According to (A.1), it holds that A k A T k = I n ¯ G k 0 I p ¯ A k ¯ A T k 0 0 I p I n 0 ¯ G T k I p . Thus, λ min ( ¯ A k ¯ A T k ) = min { λ min ( ¯ A k ¯ A T k ) , 1 } . W e study the sufficiency of 2). If { ¯ A k | ¯ A k ∈ R n × n , k ∈ N } has an L-SS { T l , l ∈ N } 13 which satisfies λ min ( ¯ A T l + s ¯ A T T l + s ) > β , s ∈ [0 : L ) . Then for the same time sequence { T l , l ∈ N } , it holds that λ min ( A T l + s A T T l + s ) > β ∗ = min { β , 1 } , s ∈ [0 : L ) . Thus, the time sequence { T l , l ∈ N } is also an L-SS of { A k | A k ∈ R ( n + p ) × ( n + p ) , k ∈ N } . W e then consider the ne- cessity of 2). If { A k | A k ∈ R ( n + p ) × ( n + p ) , , k ∈ N } has an L- SS { ¯ T l , l ∈ N } , then λ min ( A ¯ T l + s A T ¯ T l + s ) > ¯ β , s ∈ [0 : L ) . Recall λ min ( ¯ A k ¯ A T k ) = min { λ min ( ¯ A k ¯ A T k ) , 1 } . , then we hav e λ min ( ¯ A ¯ T l + s ¯ A T ¯ T l + s ) > ¯ β , s ∈ [0 : L ) . As a re- sult, the time sequence { ¯ T l , l ∈ N } is also an L-SS of { ¯ A k | ¯ A k ∈ R n × n , , k ∈ N } . B Proof of Proposition 3.2 Denote Φ j,k = Φ j,j − 1 · · · Φ k +1 ,k ( j > k ) , Φ k,k = I n + p , and Φ k +1 ,k = A k , then it holds that Φ j,k = ¯ A j − 1 ¯ G j − 1 0 I p ! × · · · × ¯ A k ¯ G k 0 I p ! = ¯ Φ j,k ˜ Φ j,k +1 0 I p ! , where ˜ Φ j,k +1 = P j i = k +1 ¯ Φ j,i ¯ G i − 1 . Thus, we obtain Φ T j,k H T j,i ( R j,i + B j,i ) − 1 H j,i Φ j,k = Θ 1 , 1 i,j,k Θ 1 , 2 i,j,k (Θ 1 , 2 i,j,k ) T Θ 2 , 2 i,j,k ! , where Θ 1 , 1 i,j,k = ¯ Φ T j,k ¯ H T j,i ( R j,i + B j,i ) − 1 ¯ H j,i ¯ Φ j,k , Θ 1 , 2 i,j,k = ¯ Φ T j,k ¯ H T j,i ( R j,i + B j,i ) − 1 ¯ H j,i ˜ Φ j,k +1 and Θ 2 , 2 i,j,k = ( ¯ H j,i ˜ Φ j,k +1 ) T ( R j,i + B j,i ) − 1 ( ¯ H j,i ˜ Φ j,k +1 ) . For ¯ N ∈ N + , we denote N X i =1 k + ¯ N X j = k Θ 1 , 1 i,j,k Θ 1 , 2 i,j,k (Θ 1 , 2 i,j,k ) T Θ 2 , 2 i,j,k ! := ¯ Θ 1 , 1 k, ¯ N ¯ Θ 1 , 2 k, ¯ N ( ¯ Θ 1 , 2 k, ¯ N ) T ¯ Θ 2 , 2 k, ¯ N . where ¯ Θ 1 , 1 k, ¯ N = N X i =1 k + ¯ N X j = k Θ 1 , 1 i,j,k ¯ Θ 1 , 2 k, ¯ N = N X i =1 k + ¯ N X j = k Θ 1 , 2 i,j,k ¯ Θ 2 , 2 k, ¯ N = N X i =1 k + ¯ N X j = k Θ 2 , 2 i,j,k (B.1) 1) Necessity . If the reformulated system (5) is uniformly col- lectiv ely observ able, then there exist M , ¯ N ∈ N + and α > 0 such that ¯ Θ 1 , 1 k, ¯ N ¯ Θ 1 , 2 k, ¯ N ( ¯ Θ 1 , 2 k, ¯ N ) T ¯ Θ 2 , 2 k, ¯ N − αI p − αI n + p > 0 , ∀ k ≥ M . Thus, ¯ Θ 1 , 1 k, ¯ N > 0 , then in light of Schur Complement [30], for k ≥ ¯ M , ( ¯ Θ 2 , 2 k, ¯ N − αI p ) − ( ¯ Θ 1 , 2 k, ¯ N ) T ( ¯ Θ 1 , 1 k, ¯ N − αI n ) − 1 ¯ Θ 1 , 2 k, ¯ N > 0 . 2) Sufficiency . If there exist ¯ N , M ∈ N + and α > 0 , such that ¯ Θ 1 , 1 k, ¯ N − αI n > 0 , for k ≥ ¯ M . For k ≥ ¯ M , by ( ¯ Θ 2 , 2 k, ¯ N − αI p ) − ( ¯ Θ 1 , 2 k, ¯ N ) T ( ¯ Θ 1 , 1 k, ¯ N − αI n ) − 1 ¯ Θ 1 , 2 k, ¯ N > 0 and Schur Complement [30], for k ≥ ¯ M , ¯ Θ 1 , 1 k, ¯ N ¯ Θ 1 , 2 k, ¯ N ( ¯ Θ 1 , 2 k, ¯ N ) T ¯ Θ 2 , 2 k, ¯ N > αI n + p holds. Thus, the reformulated system (5) is uniformly collectiv ely observable. C Proof of Lemma 4.1 Here we utilize an inducti ve method for the proof. At the ini- tial moment, under Assumption 2.1, E { ( ˆ X 0 ,i − X 0 )( ˆ X 0 ,i − X 0 ) T } ≤ P 0 ,i . Suppose E { ( ˆ X k − 1 ,i − X k − 1 )( ˆ X k − 1 ,i − X k − 1 ) T } ≤ P k − 1 ,i . Recall ¯ e k,i = ¯ X k,i − X k = A k − 1 e k − 1 ,i − D u k − 1 − ω k − 1 . Since the estimation er- ror e k − 1 ,i is measurable to σ {F k − 2 , v k − 1 ,i , i ∈ V } , and ω k − 1 is independent from F k − 2 and v k − 1 ,i , i ∈ V , we ha ve E { e k − 1 ,i ω T k − 1 } = 0 . Similarly , it holds that E { u k − 1 ω T k − 1 } = 0 . Then, due to E { ( p θ k,i x + y √ θ k,i )( p θ k,i x + y √ θ k,i ) T } ≥ 0 , we ha ve the inequality E { xy T + y x T } ≤ E { θ k,i xx T + 1 θ k,i y y T } , ∀ θ k,i > 0 . Then, we ha ve E { ¯ e k,i ¯ e T k,i } ≤ (1 + θ k,i ) A k − 1 P k − 1 ,i A T k − 1 + (1 + 1 θ k,i ) ¯ Q k − 1 + ˜ Q k − 1 . According to the definition of ¯ P k,i , E { ¯ e k,i ¯ e T k,i } ≤ ¯ P k,i hold. At the update stage, there is ˜ e k,i = ˜ X k,i − X k = ( I − K k,i H k,i ) ¯ e k,i + K k,i b k,i + K k,i v k,i . Under Assumption 2.1 and the fact that ¯ e k,i is measurable to F k − 1 , it follows that E { ¯ e k,i v T k,i } = E { E { ¯ e k,i v T k,i |F k − 1 }} = E { A k − 1 e k − 1 ,i E { v T k,i |F k − 1 }} + E { E { w k − 1 v T k,i |F k − 1 }} = E { w k − 1 v T k,i } = 0 . Similarly , it holds that E { b k,i v T k,i } = 0 by noting that b k,i is mea- surable to F k − 1 . Then, ∀ µ k,i > 0 , we hav e E { ˜ e k,i ˜ e T k,i } ≤ (1 + µ k,i )( I − K k,i H k,i ) E { ¯ e k,i ¯ e T k,i } ( I − K k,i H k,i ) T + K k,i E { v k,i v T k,i } K T k,i + 1+ µ k,i µ k,i K k,i E { b k,i b T k,i } K T k,i ≤ ˜ P k,i . Recall the existence of quantization operation with respect to ˜ X k,i + ξ k,i , where ξ k,i stands for the dithering noise vector . W e denote the estimation error ˇ e k,i := ˇ X k,i − X k = ˜ e k,i + ξ k,i + ϑ k,i , where ϑ k,i is the quantization error vector of ˜ X k,i + ξ k,i . By Assumption 2.6, ξ k,i + ϑ k,i is indepen- dent of ˜ e k,i . Then E { ˇ e k,i ˇ e T k,i } ≤ E { ˜ e k,i ˜ e T k,i } + E { ( ξ k,i + ϑ k,i )( ξ k,i + ϑ k,i ) T } ≤ ˜ P k,i + ∆ 2 i ¯ nI ¯ n = ˇ P k,i + P ∗ k,i + ∆ 2 i ¯ nI ¯ n , where P ∗ k,i ∈ R ¯ n × ¯ n is the symmetric quantization er- ror matrix of ˇ P k,i . It holds that P ∗ k,i ≤ λ max ( P ∗ k,i ) I ¯ n ≤ k P ∗ k,i k F I ¯ n := s P ¯ n s =1 P ¯ n l =1 P ∗ k,i ( s, l ) 2 I ¯ n ≤ ∆ i ¯ n 2 I ¯ n , where k · k F is the Frobenius norm, and P ∗ k,i ( s, l ) is the ( s, l ) th element of P k,i . Thus, we hav e E { ˇ e k,i ˇ e T k,i } ≤ ˇ P k,i + ¯ n ∆ i (2∆ i +1) 2 I ¯ n . Notice that e k,i = ˆ X k,i − X k = 14 P k,i ( P j ∈N i ( k ) ,j 6 = i a i,j ( k ) ˜ P − 1 k,j ˇ e k,j + a i,i ( k ) ˜ P − 1 k,i ˜ e k,i ) , where ˜ P k,j = ˇ P k,j + ¯ n ∆ i (2∆ i +1) 2 I ¯ n , if i 6 = j , and j ∈ N i . According to the consistent estimate of Cov ariance Inter- section [31], there is E { e k,i e T k,i } ≤ P k,i . Therefore, the proof is finished. D Proof of Lemma 4.2 By Lemma 4.1, it holds that ˜ P k,i = (1 + µ k,i )∆ ˜ P k,i , with ∆ ˜ P k,i , ( I − K k,i H k,i ) ¯ P k,i ( I − K k,i H k,i ) T + K k,i ˜ R k,i K T k,i , =( K k,i − K ∗ k,i )( H k,i ¯ P k,i H T k,i + ˜ R k,i )( K k,i − K ∗ k,i ) T + ( I − K ∗ k,i H k,i ) ¯ P k,i , (D.1) where ˜ R k,i = R k,i 1+ µ k,i + B k,i µ k,i , K ∗ k,i = ¯ P k,i H T k,i ( H k,i ¯ P k,i H T k,i + ˜ R k,i ) − 1 . Thus, it is seen from (D.1) that ˜ P k,i is mini- mized in the sense of positive definiteness (i.e., tr( ˜ P k,i ) is minimized) when K k,i = K ∗ k,i . E Proof of Lemma 4.3 For the proof of 1), exploiting the matrix in verse formula on ˜ P k,i directly yields the conclusion. Next, we consider the proof of 2). First, we prove there exists a constant positiv e definite matrix ¯ P , such that P k,i ≥ ¯ P . Consider ¯ P k,i ≥ 1+ θ k,i θ k,i ¯ Q k − 1 + ˜ Q k − 1 ≥ 1+ θ 2 θ 2 ¯ Q k − 1 + ˜ Q k − 1 ≥ Q ∗ > 0 , where Q ∗ can be obtained by noting inf k Q k ≥ Q > 0 and Assumption 2.3. According to 1) of Lemma 4.3, then we have ˜ P − 1 k,i ≤ Q ∗ 1+ µ k,i + H T k,i ∆ R − 1 k,i H k,i ≤ Q ∗ , where Q ∗ > 0 is obtained by emplo ying the condition 3) of As- sumption 2.1. Recall P k,i = P j ∈N i ( k ) a i,j ( k ) ˜ P − 1 k,j − 1 , then P − 1 k,i ≤ Q ∗ , which means P k,i ≥ Q − 1 ∗ > 0 . Consider the time sequence { T l , l ∈ N } , which is the L-SS of { A k , k ∈ N } . Under Assumption 2.2, there exists a scalar β , such that A T l + s P T l + s,i A T T l + s ≥ β Q − 1 ∗ > 0 . Due to sup k Q k ≤ ¯ Q < ∞ , there is a scalar $ > 0 , such that Q T l + s ≤ $ A T l + s P T l + s,i A T T l + s . Then ¯ P T l + s +1 ,i = A T l + s P T l + s,i A T T l + s + Q T l + s ≤ (1 + $ ) A T l + s P T l + s,i A T T l + s . Let η = 1 1+ $ , then the con- clusion 2) of this lemma holds. F Proof of Proposition 4.1 Consider tr( ¯ P k,i ) , then we have tr( ¯ P k,i ) = (1 + θ k,i ) tr( A k − 1 P k − 1 ,i A T k − 1 ) + 1+ θ k,i θ k,i tr( ¯ Q k − 1 ) + tr ( ˜ Q k − 1 ) . Hence θ ∗ k,i = arg min θ k,i tr( ¯ P k,i ) = arg min θ k,i f k ( θ k,i ) , where f k ( θ k,i ) = θ k,i tr( A k − 1 P k − 1 ,i A T k − 1 ) + tr( ¯ Q k − 1 ) θ k,i , which is minimized if θ ∗ k,i tr( A k − 1 P k − 1 ,i A T k − 1 ) = tr( ¯ Q k − 1 ) θ ∗ k,i . As a result, θ ∗ k,i = r tr( ¯ Q k − 1 ) tr( A k − 1 P k − 1 ,i A T k − 1 ) . Since P k − 1 ,i > 0 , ¯ Q k − 1 > 0 and A k − 1 6 = 0 , we have θ ∗ k,i > 0 . G Proof of Lemma 4.5 By Theorem 1 of [5], (1) can be proved. For (2), we ha ve x k δ k = ρ δ k x 0 + P k i =0 ρ δ k − i m i δ i . Due to ρ < δ < 1 , ρ δ k x 0 → 0 . Denote ¯ ρ = ρ δ ∈ (0 , 1) and ¯ m i = m i δ i = o (1) , then construct a sequence { ¯ x k } sat- isfying ¯ x k +1 = ¯ ρ ¯ x k + ¯ m k with ¯ x 0 = 0 . By (1), we hav e ¯ x k = o (1) . In light of ¯ x k = P k i =0 ( ¯ ρ ) k − i ¯ m i , P k i =0 ρ δ k − i m i δ i = P k i =0 ( ¯ ρ ) k − i ¯ m i → 0 as k → ∞ . Hence, x k = o ( δ k ) . For (3), consider x k k M − 1 = ρ k k M − 1 x 0 + k M − 1 P k i =0 ρ k − i m i . Notice ρ k k M − 1 = o (1) , then consider the con vergence of the second term, namely , k M − 1 P k i =0 ρ k − i m i . Due to m k = o ( 1 k M ) , we hav e k M − 1 P k i =0 ρ k − i m i = P k i =0 o ( ρ k − i k M − 1 i M ) = P k i =0 o ( k M − 1 i M ( k − i ) M ) = P k i =0 o ( 1 k ) = o (1) , where the sec- ond equality is obtained by ρ k − i = o ( 1 ( k − i ) M ) and the third equality is obtained by i ( k − i ) ≤ k 2 . Thus, x k k M − 1 = o (1) , which means x k = o ( 1 k M − 1 ) . H Proofs of Lemmas 5.1, 5.3 and Proposition 5.1 Proof of Lemma 5.1. Employing the matrix in verse for- mula on ˜ P k,i yields ˜ P − 1 k,i = ¯ P − 1 k,i 1+ µ k,i + H T k,i ∆ R − 1 k,i H k,i . where ∆ R k,i = R k,i + 1+ µ k,i µ k,i B k,i . Substituting ˜ P − 1 k,i into (20), the conclusion of this lemma holds. Proof of Lemma 5.3 . If (20) is satisfied, we hav e ˜ P − 1 k,i = ¯ P − 1 k,i 1+ µ k,i + H T k,i ∆ R − 1 k,i H k,i . Thus, conclusion of Lemma 5.3 holds in this case. If the update e vent in (20) is not trig- gered, then ˜ P k,i = ¯ P k,i . Besides, according to the scheme, it follo ws that ˜ P − 1 k,i ≥ ¯ P − 1 k,i 1+ µ k,i + H T k,i ∆ R − 1 k,i H k,i − τ I n . Proof of Pr oposition 5.1. In light of Lemma 5.3, for τ = 0 , ˜ P − 1 k,i ≥ ¯ P − 1 k,i 1+ µ k,i + H T k,i ∆ R − 1 k,i H k,i = ˇ P − 1 k,i , which means ˜ P k,i ≤ ˇ P k,i , where ˇ P k,i corresponds to the observation up- date of Algorithm 1. By using the mathematical induction method, the proof of this proposition can be finished. References [1] U. A. Khan and A. Jadbabaie, “Collaborative scalar-gain es- timators for potentially unstable social dynamics with limited communication, ” Automatica , vol. 50, no. 7, pp. 1909–1914, 2014. 15 [2] U. A. Khan, S. Kar , A. Jadbabaie, and J. M. F . Moura, “On connecti vity , observ ability , and stability in distributed estimation, ” in IEEE Conference on Decision and Contr ol , pp. 6639–6644, 2010. [3] G. Battistelli and L. Chisci, “Stability of consensus extended Kalman filter for distributed state estimation, ” A utomatica , vol. 68, pp. 169–178, 2016. [4] R. Olfati-Saber , “Distributed Kalman filtering for sensor net- works, ” in Pr oceedings of the IEEE Conference on Decision and Contr ol , pp. 5492 – 5498, 2007. [5] F . S. Cattiv elli and A. H. Sayed, “Dif fusion strategies for distributed Kalman filtering and smoothing, ” IEEE T ransac- tions on Automatic Contr ol , vol. 55, no. 9, pp. 2069–2084, 2010. [6] G. Battistelli and L. Chisci, “Kullback-Leibler av erage, con- sensus on probability densities, and distributed state estima- tion with guaranteed stability , ” A utomatica , v ol. 50, no. 3, pp. 707–718, 2014. [7] X. He, W . Xue, and H. Fang, “Consistent distrib uted state estimation with global observ ability over sensor network, ” Automatica , vol. 92, pp. 162 – 172, 2018. [8] S. W ang and W . Ren, “On the con vergence conditions of distributed dynamic state estimation using sensor networks: A unified frame work, ” IEEE T ransactions on Control Systems T echnology , vol. 26, no. 4, pp. 1300–1316, 2018. [9] P . Liu, Y . Tian, and Y . Zhang, “Distributed Kalman filter- ing with finite-time max-consensus protocol, ” IEEE Access , vol. 6, pp. 10795–10802, 2018. [10] Q. Liu, Z. W ang, X. He, and D. Zhou, “On Kalman-consensus filtering with random link failures ov er sensor networks, ” IEEE T ransactions on Automatic Contr ol , vol. 63, no. 8, pp. 2701–2708, 2017. [11] W . Y ang, G. Chen, X. W ang, and L. Shi, “Stochastic sen- sor activ ation for distrib uted state estimation over a sensor network, ” Automatica , vol. 50, no. 8, pp. 2070–2076, 2014. [12] A. K. Caglayan and R. E. Lancraft, “ A separated bias iden- tification and state estimation algorithm for nonlinear sys- tems, ” Automatica , vol. 19, no. 5, pp. 561–570, 1983. [13] J. Y . Keller and M. Darouach, “Optimal two-stage Kalman filter in the presence of random bias, ” Automatica , vol. 33, no. 9, pp. 1745–1748, 1997. [14] G. Y ang and W . Che, “Non-fragile H ∞ filter design for linear continuous-time systems, ” Automatica , vol. 44, no. 11, pp. 2849–2856, 2008. [15] D. Ding, Z. W ang, H. Dong, and H. Shu, “Distributed H ∞ state estimation with stochastic parameters and nonlinearities through sensor networks: the finite-horizon case, ” Automat- ica , vol. 48, no. 8, pp. 1575–1585, 2012. [16] W . Bai, W . Xue, Y . Huang, and H. Fang, “On extended state based Kalman filter design for a class of nonlinear time-varying uncertain systems, ” Science China Information Sciences , vol. 61, no. 4, p. 042201, 2018. [17] S. Kar and J. M. Moura, “Distrib uted consensus algorithms in sensor networks: Quantized data and random link failures, ” IEEE Tr ansactions on Signal Processing , vol. 58, no. 3, pp. 1383–1400, 2010. [18] M. Zhu and S. Mart ´ ınez, “On the con vergence time of asyn- chronous distributed quantized av eraging algorithms, ” IEEE T ransactions on Automatic Control , vol. 56, no. 2, pp. 386– 390, 2011. [19] K. Reif, S. Gunther , E. Y az, and R. Unbehauen, “Stochastic stability of the discrete-time extended Kalman filter, ” IEEE T ransactions on Automatic contr ol , vol. 44, no. 4, pp. 714– 728, 1999. [20] S. J. Julier and J. K. Uhlmann, “ A non-di vergent estima- tion algorithm in the presence of unknown correlations, ” in American Contr ol Conference , pp. 2369–2373, 1997. [21] Y . S. Chow and H. T eicher , Pr obability theory: independence, inter changeability , martingales . Springer Science & Business Media, 2012. [22] L. Orihuela, P . Mill ´ an, C. V iv as, and F . R. Rubio, “Subopti- mal distributed control and estimation: application to a four coupled tanks system, ” International Journal of Systems Sci- ence , vol. 47, no. 8, pp. 1755–1771, 2016. [23] Z. Cai, M. S. D. Queiroz, and D. M. Dawson, “Robust adaptiv e asymptotic tracking of nonlinear systems with addi- tiv e disturbance, ” IEEE T ransactions on Automatic Control , vol. 51, no. 3, pp. 524–529, 2006. [24] X. He, C. Hu, W . Xue, and H. Fang, “On ev ent-based dis- tributed Kalman filter with information matrix triggers, ” in IF AC W orld Congress , pp. 14873–14878, 2017. [25] M. Bartholome w-Biggs, Nonlinear optimization with engi- neering applications . Springer Science & Business Media, 2008. [26] X. He, C. Hu, Y . Hong, L. Shi, and H. F ang, “Distributed Kalman filters with state equality constraints: time-based and ev ent-triggered communications, ” IEEE T ransactions on Au- tomatic Contr ol , 2019. [27] D. Han, K. Y ou, L. Xie, J. W u, and L. Shi, “Optimal param- eter estimation under controlled communication over sensor networks., ” IEEE T ransaction on Signal Processing , vol. 63, no. 24, pp. 6473–6485, 2015. [28] S. W eerakkody , Y . Mo, B. Sinopoli, D. Han, and L. Shi, “Multi-sensor scheduling for state estimation with event- based, stochastic triggers, ” IEEE T ransactions on Automatic Contr ol , vol. 61, no. 9, pp. 2695–2701, 2016. [29] D. Simon, “Kalman filtering with state constraints: a survey of linear and nonlinear algorithms, ” IET Contr ol Theory & Applications , vol. 4, no. 8, pp. 1303–1318, 2010. [30] G. A. F . Seber, A Matrix Handbook for Statisticians . Wiley- Interscience, 2007. [31] W . Niehsen, “Information fusion based on fast cov ariance intersection filtering, ” in International Conference on Infor- mation Fusion , pp. 901–904, 2002. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment