Fast and Robust 3-D Sound Source Localization with DSVD-PHAT
This paper introduces a variant of the Singular Value Decomposition with Phase Transform (SVD-PHAT), named Difference SVD-PHAT (DSVD-PHAT), to achieve robust Sound Source Localization (SSL) in noisy conditions. Experiments are performed on a Baxter r…
Authors: Francois Grondin, James Glass
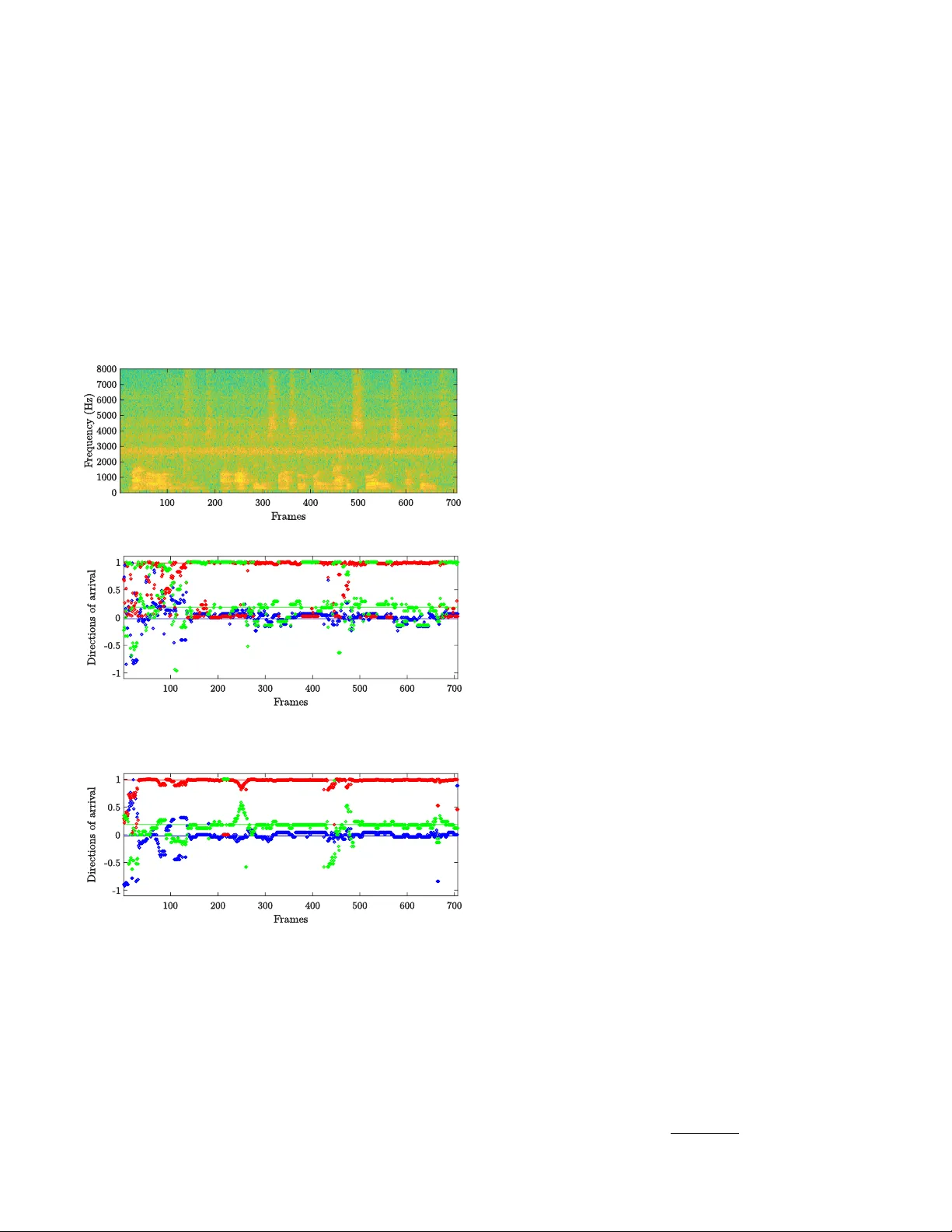
F ast and Rob ust 3-D Sound Source Localization with DSVD-PHA T Franc ¸ ois Grondin and James Glass Abstract — This paper introduces a v ariant of the Singu- lar V alue Decomposition with Phase T ransform (SVD-PHA T), named Difference SVD-PHA T (DSVD-PHA T), to achieve ro- bust Sound Sour ce Localization (SSL) in noisy conditions. Experiments are performed on a Baxter robot with a four - microphone planar array mounted on its head. Results show that this method offers similar rob ustness to noise as the state- of-the-art Multiple Signal Classification based on Generalized Singular V alue Decomposition (GSVD-MUSIC) method, and considerably reduces the computational load by a factor of 250. This performance gain thus makes DSVD-PHA T appealing for real-time application on robots with limited on-board computing power . I . I N T RO D U C T I O N Robot audition aims to provide robots with hearing ca- pabilities to interact efficiently with people in e veryday en vironments [1]. Sound source localization (SSL) is a typical task that consists of localizing the direction of arriv al (DO A) of a target source using a microphone array . This task is challenging as the robot usually generates a significant amount of noise (fans, actuators, etc.) [2] and the tar get sound source is corrupted by re verberation. SSL often relies on Multiple Signal Classification (MUSIC) and Steered- Response Po wer Phase Transform (SRP-PHA T) methods. MUSIC is a localization method based on Standard Eigen- value Decomposition (SEVD-MUSIC) that was initially used for narrowband signals [3], and then adapted to broadband signals like speech [4]. Ho wever , SEVD-MUSIC assumes the speech signal is more po werful than noise at each frequency bin in the spectrogram, which is usually not the case. T o cope with this limitation, Nakamura et al. introduced the MUSIC based on Generalized Eigen value Decomposition (GEVD-MUSIC) method [5], [6], [7]. This method solves the limitation of SEVD-MUSIC, but also introduces some localization errors because the transform provides a noise subspace with correlated bases. T o deal with this issue, a variant of GEVD-MUSIC, named MUSIC based on Gen- eralized Singular V alue Decomposition (GSVD-MUSIC), enforces orthogonality between the noise subspace bases and thus improv es the DO A estimation accuracy [8]. Ho wev er , all MUSIC-based methods rely on online eigen value or singular value decompositions that are computationally expensi ve, and make on-board real-time processing challenging [9]. SRP-PHA T is built on the Generalized Cross-Correlation with Phase Transform (GCC-PHA T) between each pair of This work was supported in part by the T oyota Research Institute and by the Fonds de recherche du Qu ´ ebec – Nature et technologies. F . Grondin and J. Glass are with the Computer Science & Artificial Intelligence Laboratory (CSAIL), Massachusetts Institute of T echnology , Cambridge, MA 02139, USA { fgrondin,glass } @mit.edu microphones [10]. GCC-PHA T is often computed with the In verse Fast Fourier T ransform (IFFT) to speed up compu- tation, at the cost of discretizing Time Dif ference of Arriv al (TDO A) values, which reduces localization accuracy . SRP- PHA T usually scans a discretized 3-D space and returns the most likely DOA [11], [12], [13], [14], [15], [16]. This scanning process often in volv es a significant amount of lookups in memory , which creates a bottleneck and increases ex ecution time. T o reduce the number of lookups, a hierar- chical search is proposed to speed up the space scan, but this method still relies on discrete TDOA [17]. W e therefore recently proposed the Singular V alue Decomposition with Phase T ransform (SVD-PHA T) method, which avoids TDO A discretization, and significantly reduces computing time [18]. Howe ver , as for SRP-PHA T , SVD-PHA T remains sensiti ve to additiv e noise. T o cope with this limitation, time-frequency (TF) masks can be generated to improve robustness to stationary noise [19], [20]. Stationary noise is often estimated with techniques like Minima Controlled Recursi ve A veraging (MCRA) [21] and Histogram-based Recursiv e Lev el Esti- mation (HRLE) [22], or recorded offline prior to test if the robot’ s environment is static. Pertil ¨ a et al. also propose a method that generates TF masks using con volutional neural networks for non-stationary noise sources [23]. Howe ver , these TF masks ignore noise spatial coherence, which carries useful insights for robust localization, and is in fact exploited by GSVD-MUSIC. In this paper , we propose a variant of the SVD-PHA T method, called Difference SVD-PHA T (DSVD-PHA T), that performs correlation matrix subtraction, which considers noise spatial coherence, while preserving the low complexity of the original SVD-PHA T . Section II revie ws the state of the art GSVD-MUSIC method, and section III introduces the proposed DSVD-PHA T method. Section IV describes the experimental setup on a Baxter robot, and then section V compares results from GSVD-MUSIC and the proposed DSVD-PHA T approach. I I . G S V D - M U S I C GSVD-MUSIC relies on the T ime Difference of Arri val (TDO A) between each microphone and a reference in space. The TDOA (in sec) stands for the propagation delay for the signal emitted by the sound source DO A s q ∈ { R 3 : k s q k 2 = 1 } (where k . . . k 2 stands for the l 2 -norm) to reach microphone r m ∈ R 3 with respect to the origin. For discrete- time signals, the TDOA is usually e xpressed in terms of samples, as shown in (1), where c ∈ R + stands for the speed of sound in air (in m/sec), and f S ∈ R + is the sample rate (in samples/sec). The operator · stands for the dot product. τ q ,m = f S c r m · s q (1) The expression X l m [ k ] ∈ C stands for the Short T ime Fourier T ransform coef ficient of microphone m ∈ { 1 , . . . , M } , at frequency bin k ∈ { 0 , . . . , N / 2 } and frame l ∈ N , where N ∈ N and ∆ N ∈ N stand for the frame and hop sizes in samples, respectiv ely . The STFT v alues are concatenated in the vector x l [ k ] ∈ C M × 1 , as sho wn in (2). x l [ k ] = X l 1 [ k ] X l 2 [ k ] · · · X l M [ k ] T (2) GSVD-MUSIC uses a steering vector A q [ k ] ∈ C M × 1 for each potential DO A s q : A q [ k ] = A q , 1 [ k ] · · · A q ,M [ k ] T (3) where A q ,m [ k ] = exp ( − 2 π √ − 1 k τ q ,m / N ) . The C M × M correlation matrix of the vector x l [ k ] at each frequency bin k can be estimated at each frame l using the following recursive approximation, where the parameter α ∈ (0 , 1) is the adaptiv e rate: R l xx [ k ] = (1 − α ) R l − 1 xx [ k ] + α x l [ k ]( x l [ k ]) H (4) where { . . . } H stands for the Hermitian operator . The GSVD-MUSIC method performs a generalized singu- lar value decomposition with respect to the noise correlation matrix R l nn [ k ] (which can be estimated as in (4) during silence periods or precomputed of fline if the test en vironment is kno wn): ( R l nn [ k ]) − 1 R l xx [ k ] = E l [ k ] Λ l [ k ]( F l [ k ]) H (5) where the diagonal matrix Λ l [ k ] ∈ ( R + ) M × M holds the singular values in descending order ( λ l 1 [ k ] > λ l 2 [ k ] > · · · > λ l M [ k ] ), and E l [ k ] ∈ C M × M and F l [ k ] ∈ C M × M are the left and right singular vectors e l 1 [ k ] , . . . , e l M [ k ] ∈ C M × 1 and f l 1 [ k ] , . . . , f l M [ k ] ∈ C M × 1 , respecti vely: Λ l [ k ] = λ l 1 [ k ] . . . 0 . . . . . . . . . 0 . . . λ l M [ k ] (6) E l [ k ] = e l 1 [ k ] , . . . , e l M [ k ] (7) F l [ k ] = f l 1 [ k ] , . . . , f l M [ k ] (8) This method projects the steering v ector A q [ k ] in the noise subspace, spanned by the singular v ectors e l m [ k ] ∀ m ∈ { 2 , 3 , . . . , M } (when there is only one tar get source). The in verse of the projections for each frequency bin k is summed ov er the full spectrum (which may also be restricted to a more specific range of frequency bins [8]): P l q = N/ 2 X k =0 M X m =2 k ( A q [ k ]) H e l m [ k ] k 2 ! − 1 (9) The sound source DO A then corresponds to s ¯ q l , where: ¯ q l = arg max q { P l q } (10) GSVD-MUSIC in volv es ( N / 2 + 1) singular value decom- positions of M × M matrices per frame, as sho wn in (5), which is challenging from a computing point of vie w for real-time applications. Moreover , it also in volves computing (9) for Q potential sources, which also implies a significant amount of computations. The proposed DSVD-PHA T aims to reduce the amount of computations, while preserving a similar robustness to noise. I I I . D S V D - P H A T DSVD-PHA T relies on the TDO A between each pair of microphones i and j (as opposed to (1), where the TDO A is between a microphone and to the origin), which leads to the following expression, for a total of P = M ( M − 1) / 2 pairs: τ q ,i,j = f S c ( r j − r i ) · s q (11) Since noise and speech sources are independent, it is reasonable to assume that the clean speech correlation matrix R l ss can be estimated from the difference between the noisy speech and the noise correlation matrices at each frame l , as proposed in [24]: R l ss [ k ] ≈ R l xx [ k ] − R l nn [ k ] (12) The normalized cross-spectra in DSVD-PHA T at each frequency bin k are thus obtained as follows, where ( . . . ) i,j refers to the element in the i th row and j th column: X l i,j [ k ] = ( R l ss [ k ]) i,j k ( R l ss [ k ]) i,j k 2 (13) Note ho w DSVD-PHA T differs from the original SVD- PHA T , as the latter uses directly the noisy correlation matrix (e.g. R l xx [ k ] replaces R l ss [ k ] in (12)). W e then define the vector X ∈ C P ( N/ 2+1) × 1 to concate- nate all normalized cross-spectra introduced in (13): X l = X l 1 , 2 [0] X l 1 , 2 [1] · · · X l M − 1 ,M [ N / 2] T (14) The matrix W ∈ C Q × P ( N/ 2+1) holds all the SRP-PHA T coefficients W q ,i,j [ k ] = exp (2 π √ − 1 k τ q ,i,j / N ) : W = W 1 , 1 , 2 [0] W 1 , 1 , 2 [1] · · · W 1 ,M − 1 ,M [ N / 2] . . . . . . . . . . . . W Q, 1 , 2 [0] W Q, 1 , 2 [1] · · · W Q,M − 1 ,M [ N / 2] (15) The vector Y l ∈ R Q × 1 stores the SRP-PHA T energy for all Q potential DOAs, where <{ . . . } e xtracts the real part of the expression: Y l = Y l 1 . . . Y l Q T = <{ WX l } (16) The sound source DO A corresponds to s ¯ q l , where: ¯ q l = arg max q { Y l q } (17) Computing Y l q for all values of q is expensi ve, and there- fore SVD-PHA T provides a more efficient way of finding ¯ q l . The Singular V alue Decomposition is first performed on the W matrix, where U ∈ C Q × K , S ∈ C K × K and V ∈ C P ( N/ 2+1) × K : W ≈ USV H (18) The parameter K ∈ { 1 , 2 , . . . , K max } (where K max = max { Q, P ( N / 2 + 1) } ) satisfies the condition in (19), which ensures accurate reconstruction of W , where δ ∈ (0 , 1) is a user-defined small v alue that stands for the tolerable reconstruction error . The operator T r { . . . } represents the trace of the matrix. T r { SS T } ≥ (1 − δ ) T r { WW H } (19) The vector Z l ∈ C K × 1 results from the projection of the observations X l in the K-dimensions subspace: Z l = V H X l (20) Similarly , the matrix D ∈ C Q × K holds a set of Q vectors D q ∈ C 1 × K : D = US = D T 1 D T 2 . . . D T Q T (21) The optimization in (17) can then be conv erted to a nearest neighbor problem: ¯ q l = arg min q {k ˆ D q − ( ˆ Z l ) H k 2 2 } (22) where ˆ D q = D q / k D k 2 and ˆ Z q = Z q / k Z k 2 . A k-d tree then solves efficiently this nearest neighbor search problem. The corresponding amplitude for the optimal DOA at index ¯ q l corresponds to: Y l ¯ q l = W ¯ q l X l (23) where W ¯ q l stands for the ¯ q l -th ro w of W . Both GSVD-MUSIC and DSVD-PHA T rely on SVD de- compositions, but DSVD-PHA T computes them offline. The online processing only inv olves the projection in (20) and the k-d tree search, which is appealing for real-time processing. I V . E X P E R I M E N T A L S E T U P The GSVD-MUSIC and DSVD-PHA T methods are ev alu- ated for a Baxter robot setup, equipped with a 4-microphone ReSpeaker 1 array mounted on its head, as shown in Fig. 1. T o compare both methods with a wide range of condi- tions, we perform simulations to ev aluate numerous room configurations and signal-to-noise ratios (SNRs). Noise from Baxter’ s fans is therefore recorded and then mixed with male and female speech utterances from the TIMIT dataset [25], con volv ed with simulated Room Impulse Responses (RIRs) and amplified with v arious gains. The room impulse response (RIR) corresponds to the impulse response obtained with the image method [26] between the microphone array and the target sound sources, both positioned randomly in a 10 m x 10 m x 3 m room. F or each pair of SNR and room rev erberation time R T60, we generate 100 RIRs and use the same number of speech sources picked randomly from the TIMIT dataset. 1 http://seeedstudio.io Fig. 1. Baxter robot equipped with a 4-microphone ReSpeaker array mounted on its head (microphones are circled in red) T ABLE I G S V D - M U S I C A N D G S V D - P H A T P A R A M E T E R S f S c M N ∆ N Q α δ 16000 343 . 0 4 256 128 1282 0 . 05 10 − 5 The parameters for the experiments are summarized in T able I. The sample rate f S captures all the frequenc y content of speech, and the speed of sound c corresponds to typical indoor conditions. The frame size N analyzes segments of 16 msecs, and the hop size ∆ N provides a 50% overlap. The potential DO As are represented by equidistant points on a unit halfsphere generated recursi vely from a tetrahedron, for a total of 1282 points, as in [17]. The smoothing parameter α provides a context of roughly 800 msecs to estimate the correlation matrices, which captures multiple phonemes. The parameter δ is set to the value found in [18], which ensures a good accuracy . For this array configuration, the dimensionality of the subspace corresponds to K = 23 with δ = 10 − 5 . T able II lists the positions of the ReSpeaker array micro- phones (in cm) w .r .t. to the center of the array . T ABLE II P O S I T I O N S ( X , Y , Z ) O F T H E M I C R O P H O N E S I N C M m x y z 1 +2 . 9 0 . 0 +2 . 9 2 +2 . 9 0 . 0 − 2 . 9 3 − 2 . 9 0 . 0 +2 . 9 4 − 2 . 9 0 . 0 − 2 . 9 In all e xperiments, the noise correlation matrix comes from the offline recording of the robot’ s fans. This ensures we compare both methods independently of the performance of the online background noise estimation method. V . R E S U L T S T o get some intuition about the SSL with GSVD-MUSIC and DSVD-PHA T , we first analyze an example of a speech utterance with a SNR of 5 dB and a re verberation level of R T60 = 400 msecs, shown in Fig. 2. The spectrogram in Fig. 2a displays the speech signal, corrupted by some stationary noise between 2500 Hz and 5000 Hz. Fig. 2b shows the DOAs obtained from GSVD-MUSIC, with the true DOA represented by straigh lines. This example demonstrates that, in this specific case, GSVD-MUSIC estimates many DOAs that differ from the theoretical DO A. Similarly , Fig. 2c displays the DO As obtained from DSVD-PHA T for the same noisy signal. Here the estimated DO As are closer to the theoretical DO A. (a) Spectrogram of the signal captured at microphone 1. (b) Circles represent the s ¯ q l found with GSVD-MUSIC, and lines stand for the theoretical DOA. The x-, y-, z-coordinates are represented by blue, red and green colors, respectively . (c) Circles represent the s ¯ q l found with DSVD-PHA T , and lines stand for the theoretical DOA. The x-, y-, z-coordinates are represented by blue, red and green colors, respectively . Fig. 2. SSL with GSVD-MUSIC and DSVD-PHA T when R T60 = 400 msecs and SNR = 5 dB. It is also con venient to define the expression θ l ∈ [0 , π / 2] to denote the angle difference between the estimated DOA s q l at frame l (obtained using GSVD-MUSIC or DSVD- PHA T), and the theoretical DOA s true extracted from the simulated room parameters: θ l = arccos { s q l · s true } (24) Let us define the margin ∆ θ ∈ [0 , π / 2] , that corresponds to the DO A error tolerance for a localized source to be considered as a valid DOA. In this section, we arbitrary define the tolerance to ∆ θ = 0 . 2 radians, which corresponds to 11 . 5 ◦ . Expression Θ l takes a value of 1 when the localized sound source is within the range, or 0 otherwise: Θ l = ( 1 θ l ≤ ∆ θ 0 θ l > ∆ θ (25) Similarly , the expression e l corresponds to the observation amplitude ( e l = P l q l for GSVD-MUSIC from (9), and e l = Y l q l from (23) for DSVD-PHA T). This metric is relev ant as it is often assumed that the confidence in the DO A s ¯ q l depends on the associated amplitude of e l [16], [17]. Therefore, a DO A is considered as a positiv e when the amplitude e l equals or exceeds the fixed threshold T min , and as a negati ve otherwise: E l = ( 1 e l ≥ T min 0 e l < T min (26) Fig. 3 illustrates the angle difference of the DO As es- timated previously with both methods, and also displays the associated amplitudes. Note that for DSVD-PHA T in particular , the amplitude goes down when the value of θ gets outside the acceptable range, which suggests that a well-tuned T min could discriminate between accurate and inaccurate estimated DO As. T o measure the performance of both methods, we vary the value of T min and compute the number of true positi ves (TP), true negati ves (TN), false positives (FP) and false negati ves (FN). A TP occurs when the amplitude is greater or equal to the threshold, and the measured DO A falls within the acceptable range of the theoretical DOA: T P = L X l =0 Θ l e l (27) Similarly , a TN happens when a DO A out of the acceptable range is rejected as its associated amplitude is belo w the fix ed threshold: T N = L X l =0 (1 − Θ l )(1 − e l ) (28) Finally , FP and FN occur when an erroneous DOA is picked and when a valid DOA is rejected, respectiv ely: F P = L X l =0 (1 − Θ l ) e l (29) F N = L X l =0 Θ l (1 − e l ) (30) The True Positiv e Rate (TPR) and False Positi ve Rate (FPR) then correspond to (31) and (32), respectiv ely , and are used to build the R OC curve. T P R = T P T P + F N (31) (a) Angle difference θ l for GSVD-MUSIC (blue) and ∆ θ threshold (red). (b) Amplitude e l = P l ¯ q l for GSVD-MUSIC. (c) Angle difference θ l for DSVD-PHA T (blue) and ∆ θ threshold (red). (d) Amplitude e l = Y l ¯ q l for DSVD-PHA T . Fig. 3. Comparisons between GSVD-MUSIC and DSVD-PHA T methods. F P R = F P F P + T N (32) Fig. 4 shows both ROC curves with GSVD-MUSIC and DSVD-PHA T for the previous example. In this case, the DSVD-PHA T surpasses the GSVD-MUSIC results as the Area Under the Curve (A UC) is clearly closer to 1 . T able III sho ws the A UC results for SNRs ∈ {− 10 , − 5 , . . . , 20 } dB and R T60 ∈ { 200 , 400 , 600 , 800 } msecs. In general, GSVD-MUSIC generates higher A UC values for cases when the SNR is belo w 0 dB. Howe ver , the DSVD-PHA T still provides A UC values close to GSVD- MUSIC, which demonstrates that the proposed method also allows accurate DOA estimation under rev erberant and noisy conditions. Moreov er , the proposed DSVD-PHA T approach Fig. 4. R OC curves for GSVD-MUSIC (blue) and DSVD-PHA T (red). provides better results for all scenarios where the SNR is greater or equal to 5 dB, at all reverberation lev els. T ABLE III AU C O F T H E R O C C U RV E S SNR (dB) R T60 (msec) GSVD-MUSIC DSVD-PHA T − 10 200 0 . 68 0 . 64 400 0 . 55 0 . 49 600 0 . 52 0 . 47 800 0 . 51 0 . 45 − 5 200 0 . 77 0 . 75 400 0 . 66 0 . 62 600 0 . 59 0 . 55 800 0 . 52 0 . 53 0 200 0 . 84 0 . 84 400 0 . 70 0 . 71 600 0 . 66 0 . 65 800 0 . 63 0 . 64 5 200 0 . 87 0 . 91 400 0 . 73 0 . 76 600 0 . 71 0 . 74 800 0 . 64 0 . 64 10 200 0 . 93 0 . 95 400 0 . 76 0 . 84 600 0 . 71 0 . 77 800 0 . 64 0 . 69 15 200 0 . 93 0 . 98 400 0 . 80 0 . 86 600 0 . 73 0 . 80 800 0 . 66 0 . 69 20 200 0 . 95 0 . 99 400 0 . 76 0 . 84 600 0 . 70 0 . 71 800 0 . 64 0 . 65 Both methods are compared in terms of the execution times per frame. These methods run in the MA TLAB en vironment, and their implementation relies mostly on vectorization to speed up processing. The hardware used consists of an Intel Xeon CPU E5-1620 clocked at 3.70GHz. T able IV shows the average execution time per frame. This demonstrates the significant efficienc y gain with DSVD- PHA T that a voids the expensi ve online SVD computations, as it runs approximately 250 times faster than GSVD-MUSIC. In this experiment, with ∆ N /f S = 8 msecs between each frame, GSVD-MUSIC requires roughly 300% of the actual computing resources to achiev e real-time, whereas DSVD- PHA T easily meets real-time requirements by using only 1% of the computing po wer . T ABLE IV E X E C U T I O N T I M E P E R F R A M E Method GSVD-MUSIC DSVD-PHA T T ime (msecs) 23.3 0.093 V I . C O N C L U S I O N This paper introduces a variant of the SVD-PHA T method to improve noise robustness. Results demonstrate that the proposed method performs similarly to the state of the art GSVD-MUSIC technique, but runs approximately 250 times faster . This makes DSVD-PHA T appealing for localization on robots with limited on-board computing power . In future work, we will inv estigate multiple sound source localization with the proposed DSVD-PHA T method. More- ov er , DSVD-PHA T could be incorporated to existing SSL framew orks such as HARK 2 [27] and OD AS 3 [17]. R E F E R E N C E S [1] H. G. Okuno, T . Ogata, K. Komatani, and K. Nakadai, “Computational auditory scene analysis and its application to robot audition, ” in Pr oceedings of the International Conference on Informatics Resear ch for Development of Knowledge Society Infrastructur e . IEEE, 2004, pp. 73–80. [2] G. Ince, K. Nakadai, T . Rodemann, H. Tsujino, and J.-I. Imura, “Robust ego noise suppression of a robot, ” in Proceedings of the International Conference on Industrial, Engineering and Other Ap- plications of Applied Intelligent Systems . Springer, 2010, pp. 62–71. [3] R. Schmidt, “Multiple emitter location and signal parameter estima- tion, ” IEEE tr ansactions on antennas and pr opagation , vol. 34, no. 3, pp. 276–280, 1986. [4] C. Ishi, O. Chatot, H. Ishiguro, and N. Hagita, “Ev aluation of a MUSIC-based real-time sound localization of multiple sound sources in real noisy en vironments, ” in Pr oceedings of the IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems , 2009, pp. 2027– 2032. [5] K. Nakamura, K. Nakadai, F . Asano, Y . Hasegawa, and H. Tsujino, “Intelligent sound source localization for dynamic environments, ” in Pr oceedings of the IEEE/RSJ international conference on Intelligent Robots and Systems . IEEE, 2009, pp. 664–669. [6] K. Nakamura, K. Nakadai, F . Asano, and G. Ince, “Intelligent sound source localization and its application to multimodal human tracking, ” in Proceedings of the IEEE/RSJ International Confer ence on Intelli- gent Robots and Systems , 2011, pp. 143–148. [7] K. Nakadai, G. Ince, K. Nakamura, and H. Nakajima, “Robot audition for dynamic en vironments, ” in Pr oceedings of the IEEE International Confer ence on Signal Processing , Communication and Computing . IEEE, 2012, pp. 125–130. [8] K. Nakamura, K. Nakadai, and G. Ince, “Real-time super-resolution sound source localization for robots, ” in Pr oceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems , 2012, pp. 694–699. 2 http://hark.jp 3 http://odas.io [9] T . Ohata, K. Nakamura, T . Mizumoto, T . T aiki, and K. Nakadai, “Improvement in outdoor sound source detection using a quadrotor- embedded microphone array , ” in Proceedings of the IEEE/RSJ Inter- national Confer ence on Intelligent Robots and Systems . IEEE, 2014, pp. 1902–1907. [10] M. Brandstein and H. Silverman, “ A robust method for speech signal time-delay estimation in re verberant rooms, ” in Pr oceedings of the International Conference on Acoustics, Speech, and Signal Pr ocessing , vol. 1. IEEE, 1997, pp. 375–378. [11] J.-M. V alin, F . Michaud, J. Rouat, and D. L ´ etourneau, “Robust sound source localization using a microphone array on a mobile robot, ” in Pr oceedings of the IEEE/RSJ International Confer ence on Intelligent Robots and Systems , vol. 2. IEEE, 2003, pp. 1228–1233. [12] J.-M. V alin, F . Michaud, B. Hadjou, and J. Rouat, “Localization of simultaneous moving sound sources for mobile robot using a frequency-domain steered beamformer approach, ” in Pr oceedings of the IEEE International Conference on Robotics and Automation , vol. 1. IEEE, 2004, pp. 1033–1038. [13] J.-M. V alin, F . Michaud, and J. Rouat, “Robust 3D localization and tracking of sound sources using beamforming and particle filtering, ” in Pr oceedings of the IEEE International Confer ence on Acoustics Speech and Signal Pr ocessing Proceedings , vol. 4. IEEE, 2006, pp. 841–844. [14] ——, “Robust localization and tracking of simultaneous moving sound sources using beamforming and particle filtering, ” Robotics and Autonomous Systems , vol. 55, no. 3, pp. 216–228, 2007. [15] A. Badali, J.-M. V alin, F . Michaud, and P . Aarabi, “Evaluating real- time audio localization algorithms for artificial audition in robotics, ” in Pr oceedings of the IEEE/RSJ International Confer ence on Intelligent Robots and Systems . IEEE, 2009, pp. 2033–2038. [16] F . Grondin, D. L ´ etourneau, F . Ferland, V . Rousseau, and F . Michaud, “The ManyEars open framework, ” Autonomous Robots , v ol. 34, no. 3, pp. 217–232, 2013. [17] F . Grondin and F . Michaud, “Lightweight and optimized sound source localization and tracking methods for open and closed microphone array configurations, ” Robotics and Autonomous Systems , vol. 113, pp. 63–80, 2019. [18] F . Grondin and J. Glass, “SVD-PHA T: A fast sound source localization method, ” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signals Processing , 2019. [19] F . Grondin and F . Michaud, “Time dif ference of arriv al estimation based on binary frequency mask for sound source localization on mo- bile robots, ” in Pr oceedings of the IEEE/RSJ International Confer ence on Intelligent Robots and Systems . IEEE, 2015, pp. 6149–6154. [20] ——, “Noise mask for tdoa sound source localization of speech on mobile robots in noisy environments, ” in Proceedings of the IEEE International Conference on Robotics and Automation . IEEE, 2016, pp. 4530–4535. [21] I. Cohen and B. Berdugo, “Noise estimation by minima controlled recursiv e averaging for robust speech enhancement, ” IEEE signal pr ocessing letters , vol. 9, no. 1, pp. 12–15, 2002. [22] H. Nakajima, G. Ince, K. Nakadai, and Y . Haseg awa, “ An easily- configurable robot audition system using histogram-based recursive lev el estimation, ” in Proceedings of the IEEE/RSJ International Con- fer ence on Intelligent Robots and Systems . IEEE, 2010, pp. 958–963. [23] P . Pertil ¨ a and E. Cakir , “Robust direction estimation with conv olutional neural networks based steered response power , ” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Pr ocessing . IEEE, 2017, pp. 6125–6129. [24] T . Higuchi, N. Ito, T . Y oshioka, and T . Nakatani, “Robust MVDR beamforming using time-frequency masks for online/offline ASR in noise, ” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing , 2016, pp. 5210–5214. [25] V . Zue, S. Seneff, and J. Glass, “Speech database development at MIT : TIMIT and beyond, ” Speech communication , vol. 9, no. 4, pp. 351– 356, 1990. [26] J. B. Allen and D. A. Berkley , “Image method for efficiently simulating small-room acoustics, ” The Journal of the Acoustical Society of America , vol. 65, no. 4, pp. 943–950, 1979. [27] K. Nakadai, T . T akahashi, H. G. Okuno, H. Nakajima, Y . Hasegawa, and H. Tsujino, “Design and implementation of robot audition sys- tem’hark’open source software for listening to three simultaneous speakers, ” Advanced Robotics , vol. 24, no. 5-6, pp. 739–761, 2010.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment