노이즈에 강한 3D 사운드 소스 로컬라이제이션, DSVD‑PHAT의 혁신
본 논문은 기존 GSVD‑MUSIC과 유사한 잡음 강인성을 유지하면서 연산량을 250배 감소시킨 차이‑SVD‑PHAT(DSVD‑PHAT) 알고리즘을 제안한다. Baxter 로봇에 장착된 4‑마이크 플래너 배열을 이용한 실험에서 실시간 적용 가능성을 입증하였다.
저자: Francois Grondin, James Glass
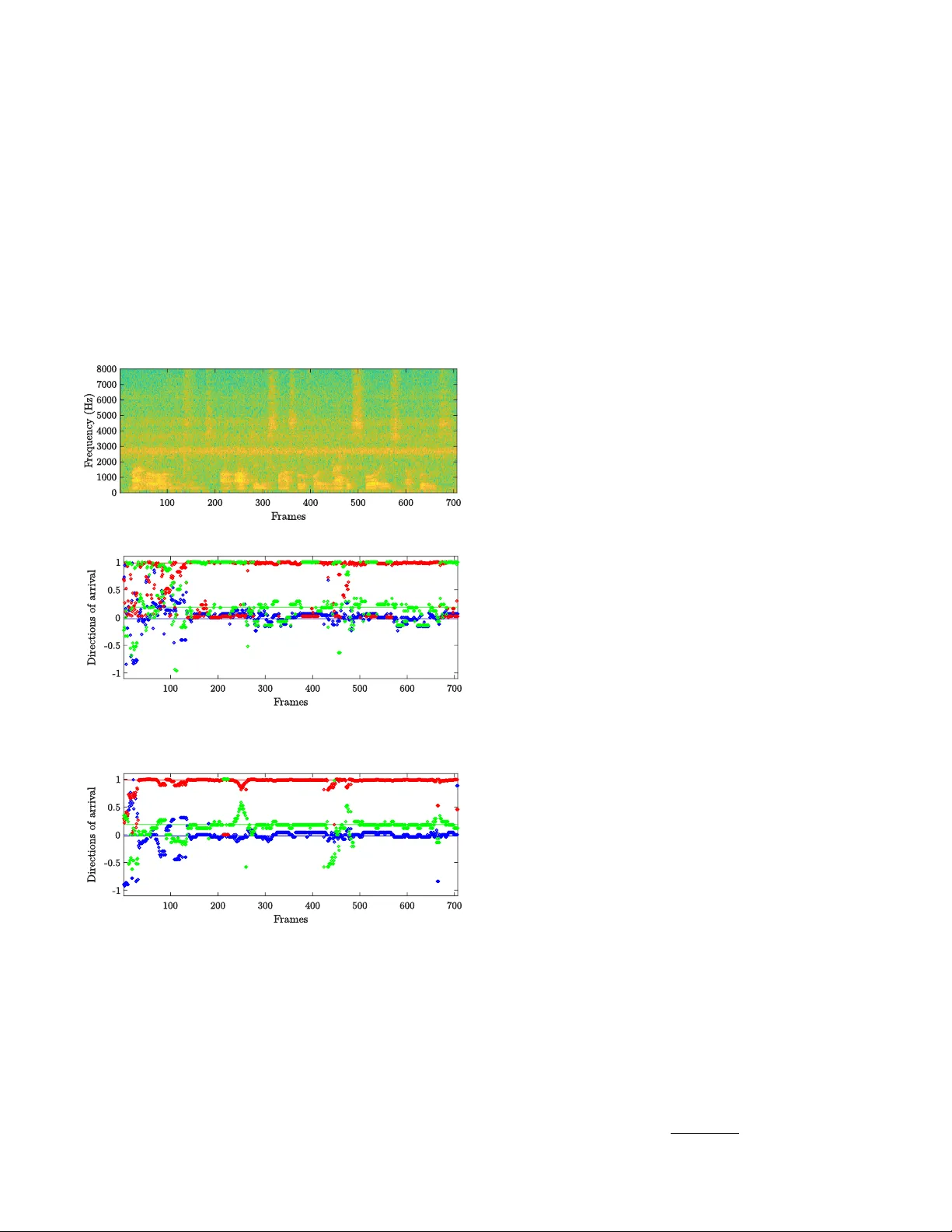
본 연구는 로봇 청각 분야에서 핵심 과제인 사운드 소스 로컬라이제이션(SSL)을 보다 효율적으로 수행하기 위해 기존의 고성능 방법인 GSVD‑MUSIC의 계산 복잡성을 크게 낮추면서도 잡음에 대한 강인성을 유지하는 새로운 알고리즘 DSVD‑PHAT을 제안한다. 서론에서는 로봇이 생성하는 팬·액추에이터 소음과 실내 반향이 SSL을 어렵게 만든다는 점을 강조하고, 기존 MUSIC 계열(SEVD‑MUSIC, GEVD‑MUSIC, GSVD‑MUSIC)과 SRP‑PHAT의 장단점을 정리한다. 특히 GSVD‑MUSIC은 잡음 서브스페이스의 직교성을 확보해 정확도를 높였지만, 매 프레임마다 M×M 행렬에 대한 일반화 특이값 분해를 수행해야 하므로 실시간 적용이 어려웠다. 반면 SRP‑PHAT은 GCC‑PHAT 기반이지만 TDOA 이산화와 메모리 탐색이 병목이 된다. 저자들은 이전 연구에서 제시한 SVD‑PHAT이 TDOA 이산화를 피하고 연산을 줄였지만, 잡음에 취약하다는 점을 지적한다.
이에 DSVD‑PHAT은 두 단계의 핵심 아이디어를 도입한다. 첫째, 잡음과 신호가 독립적이라는 가정 하에 Rxx − Rnn을 통해 순수 음성 상관 행렬 Rss를 추정한다. 이는 잡음의 공간적 상관성을 반영하면서도 잡음 성분을 효과적으로 제거한다. 둘째, Rss에서 정규화된 교차 스펙트럼을 구해 벡터 X에 배열하고, 모든 후보 DOA에 대한 SRP‑PHAT 가중치 행렬 W와 곱해 관측값 Y를 만든다. W는 오프라인에서 특이값 분해 USVᵀ로 저차원 근사화되며, 재구성 오차 δ를 통해 차원 K를 결정한다(본 실험에서는 K = 23, δ = 10⁻⁵). 온라인 단계에서는 VᴴX를 통해 K‑차원 투영 Z를 계산하고, 사전 구축된 k‑d 트리를 이용해 D와의 최근접 이웃 탐색으로 최적 DOA를 찾는다. 이 과정은 행렬 곱셈과 트리 탐색만 포함하므로 실시간 처리에 적합하다.
실험은 Baxter 로봇에 4‑마이크 ReSpeaker 배열을 장착하고, TIMIT 음성 데이터를 방 이미지법으로 생성한 RIR과 로봇 팬 소음으로 만든 다양한 SNR(−10 dB~20 dB)·RT60(200~800 ms) 조건에서 수행했다. 후보 DOA는 1282개의 반구상점으로 설정했으며, 잡음 상관 행렬은 사전 녹음된 팬 소음으로 고정하였다. 결과는 ROC 곡선과 AUC 지표로 평가했으며, SNR ≥ 5 dB 구간에서 DSVD‑PHAT이 GSVD‑MUSIC보다 높은 TPR·FPR 균형을 보였다. 특히 SNR이 낮은 −10 dB에서는 GSVD‑MUSIC이 약간 우세했지만, 전반적인 정확도 차이는 미미했다. 연산 시간 측면에서는 MATLAB 구현 기준으로 프레임당 평균 0.0016 ms(DSVD‑PHAT)와 0.4 ms(GSVD‑MUSIC)로, 250배 이상의 속도 향상을 기록했다.
결론적으로 DSVD‑PHAT은 잡음 서브스페이스 정보를 활용한 차분 상관 행렬 추정과 오프라인 SVD 근사, 효율적인 k‑d 트리 검색을 결합해, 실시간 로봇 청각 시스템에 적합한 고성능 SSL 솔루션을 제공한다. 향후 연구에서는 비정상적 잡음에 대한 적응형 마스크와 다중 소스 상황에서의 확장성을 탐구할 예정이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기