Conditioning Deep Generative Raw Audio Models for Structured Automatic Music
Existing automatic music generation approaches that feature deep learning can be broadly classified into two types: raw audio models and symbolic models. Symbolic models, which train and generate at the note level, are currently the more prevalent ap…
Authors: Rachel Manzelli, Vijay Thakkar, Ali Siahkamari
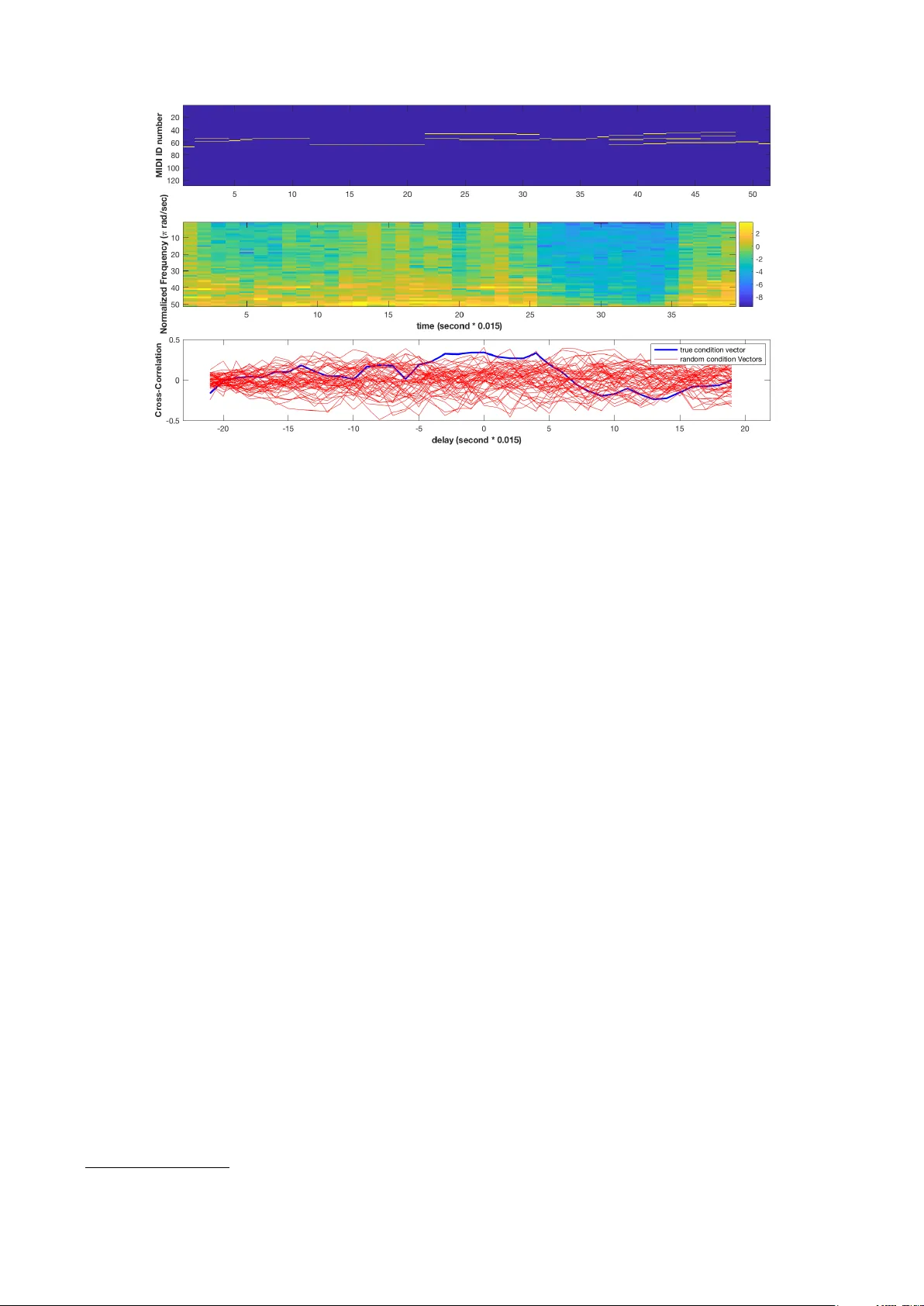
CONDITIONING DEEP GENERA TIVE RA W A UDIO MODELS FOR STR UCTURED A UT OMA TIC MUSIC Rachel Manzelli ∗ V ijay Thakkar ∗ Ali Siahkamari Brian Kulis ∗ Equal contributions ECE Department, Boston Uni versity { manzelli, thakkarv, siaa, bkulis } @bu.edu ABSTRA CT Existing automatic music generation approaches that fea- ture deep learning can be broadly classified into two types: raw audio models and symbolic models. Symbolic mod- els, which train and generate at the note le vel, are cur- rently the more prev alent approach; these models can cap- ture long-range dependencies of melodic structure, b ut fail to grasp the nuances and richness of raw audio genera- tions. Raw audio models, such as DeepMind’ s W av eNet, train directly on sampled audio wav eforms, allowing them to produce realistic-sounding, albeit unstructured music. In this paper , we propose an automatic music generation methodology combining both of these approaches to cre- ate structured, realistic-sounding compositions. W e con- sider a Long Short T erm Memory network to learn the melodic structure of dif ferent styles of music, and then use the unique symbolic generations from this model as a con- ditioning input to a W av eNet-based raw audio generator , creating a model for automatic, no vel music. W e then e val- uate this approach by showcasing results of this w ork. 1. INTRODUCTION The ability of deep neural networks to generate nov el mu- sical content has recently become a popular area of re- search. Many v ariations of deep neural architectures have generated pop ballads, 1 helped artists write melodies, 2 and e ven have been inte grated into commercial music gen- eration tools. 3 Current music generation methods are largely focused on generating music at the note le vel, resulting in outputs consisting of symbolic representations of music such as se- quences of note numbers or MIDI-like streams of events. These methods, such as those based on Long Short T erm Memory networks (LSTMs) and recurrent neural networks (RNNs), are effecti ve at capturing medium-scale effects in music, can produce melodies with constraints such as mood and tempo, and feature fast generation times [14, 22]. 1 http://www .flow-machines.com/ 2 https://www .ampermusic.com/ 3 https://www .jukedeck.com/ c Rachel Manzelli, V ijay Thakkar , Ali Siahkamari, Brian Kulis. Licensed under a Creative Commons Attribution 4.0 International License (CC BY 4.0). Attrib ution: Rachel Manzelli, V ijay Thakkar , Ali Siahkamari, Brian Kulis. “Conditioning Deep Generativ e Raw Audio Models for Structured Automatic Music”, 19th International Society for Music Information Retriev al Conference, Paris, France, 2018. In order to create sound, these methods often require an in- termediate step of interpretation of the output by humans, where the symbolic representation transitions to an audio output in some way . An alternati ve is to train on and produce raw audio wa veforms directly by adapting speech synthesis models, resulting in a richer palette of potential musical outputs, albeit at a higher computational cost. W a veNet, a model dev eloped at DeepMind primarily targeted towards speech applications, has been applied directly to music; the model is trained to predict the next sample of 8-bit audio (typi- cally sampled at 16 kHz) giv en the previous samples [25]. Initially , this was sho wn to produce rich, unique piano music when trained on raw piano samples. Follo w-up work has de veloped faster generation times [16], generated synthetic vocals for music using W a veNet-based architec- tures [3], and has been used to generate novel sounds and instruments [8]. This approach to music generation, while very new , shows tremendous potential for music genera- tion tools. Ho wever , while W aveNet produces more real- istic sounds, the model does not handle medium or long- range dependencies such as melody or global structure in music. The music is expressi ve and novel, yet sounds un- practiced in its lack of musical structure. Nonetheless, ra w audio models show great potential for the future of automatic music. Despite the expressi ve na- ture of some adv anced symbolic models, those methods re- quire constraints such as mood and tempo to generate cor- responding symbolic output [22]. While these constraints can be desirable in some cases, we express interest in gen- erating structured raw audio directly due to the flexibility and versatility that raw audio provides; with no specifica- tion, these models are able to learn to generate expression and mood directly from the wa veforms they are trained on. W e believ e that raw audio models are a step towards less guided, unsupervised music generation, since they are un- constrained in this way . W ith such tools for generating raw audio, one can imagine a number of new applications, such as the ability to edit existing ra w audio in various ways. Thus, we explore the combination of ra w audio and symbolic approaches, opening the door to a host of new possibilities for music generation tools. In particular , we train a biaxial Long Short T erm Memory netw ork to create novel symbolic melodies, and then treat these melodies as an extra conditioning input to a W av eNet- based model. Consequently , the LSTM model allows us to represent long-range melodic structure in the music, while the W aveNet-based component interprets and ex- pands upon the generated melodic structure in raw audio form. This serves to both eliminate the intermediate inter- pretation step of the symbolic representations and provide structure to the output of the raw audio model, while main- taining the aforementioned desirable properties of both models. W e first discuss the tuning of the original unconditioned W a veNet model to produce music of different instruments, styles, and genres. Once we have tuned this model appro- priately , we then discuss our extension to the conditioned case, where we add a local conditioning technique to the raw audio model. This method is comparable to using a text-to-speech method within a speech synthesis model. W e first generate audio from the conditioned raw audio model using well-known melodies (e.g., a C major scale and the Happy Birthday melody) after training on the Mu- sicNet dataset [24]. W e also discuss an application of our technique to editing existing raw audio music by changing some of the underlying notes and re-generating selections of audio. Then, we incorporate the LSTM generations as a unique symbolic component. W e demonstrate results of training both the LSTM and our conditioned W a veNet- based model on corresponding training data, as well as showcase and evaluate generations of realistic raw audio melodies by using the output of the LSTM as a unique lo- cal conditioning time series to the W a veNet model. This paper is an extension of an earlier work originally published as a workshop paper [19]. W e augment that work-in-progress model in many aspects, including more concrete results, stronger ev aluation, and new applications. 2. BA CKGROUND W e elaborate on two prev alent deep learning models for music generation, namely raw audio models and symbolic models. 2.1 Raw A udio Models Initial efforts to generate raw audio in volv ed models used primarily for text generation, such as char-rnn [15] and LSTMs. Raw audio generations from these networks are often noisy and unstructured; they are limited in their ca- pacity to abstract higher lev el representations of raw audio, mainly due to problems with ov erfitting [21]. In 2016, DeepMind introduced W av eNet [25], a gen- erativ e model for general raw audio, designed mainly for speech applications. At a high level, W a veNet is a deep learning architecture that operates directly on a raw audio wa veform. In particular , for a wav eform modeled by a v ec- tor x = { x 1 , ..., x T } (representing speech, music, etc.), the joint probability of the entire wav eform is factorized as a product of conditional probabilities, namely p ( x ) = p ( x 1 ) T Y t =2 p ( x t | x 1 , ..., x t − 1 ) . (1) The wav eforms in W aveNet are typically represented as 8-bit audio, meaning that each x i can take on one of Figure 1 : A stack of dilated causal conv olutions as used by W a veNet, reproduced from [25]. 256 possible values. The W a veNet model uses a deep neural network to model the conditional probabilities p ( x t | x 1 , ..., x t − 1 ) . The model is trained by predicting val- ues of the wa veform at step t and comparing them to the true value x t , using cross-entropy as a loss function; thus, the problem simply becomes a multi-class classification problem (with 256 classes) for each timestep in the wave- form. The modeling of conditional probabilities in W av eNet utilizes causal con volutions, similar to masked con volu- tions used in PixelRNN and similar image generation net- works [7]. Causal con volutions ensure that the prediction for time step t only depends on the predictions for previ- ous timesteps. Furthermore, the causal conv olutions are dilated; these are conv olutions where the filter is applied ov er an area larger than its length by skipping particular input values, as sho wn in Figure 1. In addition to dilated causal con volutions, each layer features gated activ ation units and residual connections, as well as skip connections to the final output layers. 2.2 Symbolic A udio Models Most deep learning approaches for automatic music gen- eration are based on symbolic representations of the mu- sic. MIDI (Musical Instrument Digital Interface), 4 for e x- ample, is a ubiquitous standard for file format and proto- col specification for symbolic representation and transmis- sion. Other representations that have been utilized include the piano roll representation [13]—inspired by player pi- ano music rolls—text representations (e.g., ABC nota- tion 5 ), chord representations (e.g., Chord2V ec [18]), and lead sheet representations. A typical scenario for produc- ing music in such models is to train and generate on the same type of representation; for instance, one may train on a set of MIDI files that encode melodies, and then generate new MIDI melodies from the learned model. These mod- els attempt to capture the aspect of long-range dependenc y in music. A traditional approach to learning temporal dependen- cies in data is to use recurrent neural networks (RNNs). A recurrent neural network receives a timestep of a series x t along with a hidden state h t as input. It outputs y t , the model output at that timestep, and computes h t +1 , the hid- den state at the next timestep. RNNs take advantage of 4 https://www .midi.org/specifications 5 http://abcnotation.com Figure 2 : A representation of a biaxial LSTM network. Note that the first two layers have connections across timesteps, while the last tw o layers hav e recurrent connec- tions across notes [14]. this hidden state to store some information from the pre- vious timesteps. In practice, vanilla RNNs do not perform well when training sequences hav e long temporal depen- dencies due to issues of v anishing/exploding gradients [2]. This is especially true for music, as properties such as key signature and time signature may be constant throughout a composition. Long Short T erm Memory networks are a v ariant of RNNs that have proven useful in symbolic music gener- ation systems. LSTM networks modify the way memory information is stored in RNNs by introducing another unit to the original RNN network: the cell state, c t , where the flow of information is controlled by v arious gates. LSTMs are designed such that the interaction between the cell state and the hidden state pre vents the issue of vanish- ing/exploding gradients [10, 12]. There are numerous existing deep learning symbolic music generation approaches [5], including models that are based on RNNs, many of which use an LSTM as a key component of the model. Some notable examples include DeepBach [11], the CONCER T system [20], the Celtic Melody Generation system [23] and the Biaxial LSTM model [14]. Additionally , some approaches com- bine RNNs with restricted Boltzmann machines [4, 6, 9, 17]. 3. ARCHITECTURE W e first discuss our symbolic method for generating unique melodies, then detail the modifications to the raw audio model for compatibility with these generations. Modifying the architecture in volves working with both symbolic and raw audio data in harmon y . 3.1 Unique Symbolic Melody Generation with LSTM Networks Recently , applications of LSTMs specific to music genera- tion, such as the biaxial LSTM, have been implemented and explored. This model utilizes a pair of tied, paral- lel networks to impose LSTMs both in the temporal di- mension and the pitch dimension at each timestep. Each note has its own network instance at each timestep, and Figure 3 : An ov erview of the model architecture, showing the local conditioning time series as an extra input. receiv es input of the MIDI note number , pitchclass, beat, and information on surrounding notes and notes at previous timesteps. This information first passes through two lay- ers with connections across timesteps, and then two layers with connections across notes, detailed in Figure 2. This combination of note dependency and temporal dependency allow the model to not only learn the overall instrumen- tal and temporal structure of the music, but also capture the interdependence of the notes being played at any gi ven timestep [14]. W e explore the sequential combination of the symbolic and raw audio models to produce structured raw audio out- put. W e train a biaxial LSTM model on the MIDI files of a particular genre of music as training data, and then feed the MIDI generations from this trained model into the raw audio generator model. 3.2 Local Conditioning with Raw A udio Models Once a learned symbolic melody is obtained, we treat it as a second time series within our raw audio model (anal- ogous to using a second time series with a desired text to be spoken in the speech domain). In particular, in the W a veNet model, each layer features a gated activ ation unit. If x is the raw audio input vector , then at each layer k , it passes through the following g ated activ ation unit: z = tanh ( W f ,k ∗ x ) σ ( W g ,k ∗ x ) , (2) where ∗ is a conv olution operator , is an elementwise multiplication operator , σ ( · ) is the sigmoid function, and the W f ,k and W g ,k are learnable con volution filters. Fol- lowing W aveNet’ s use of local conditioning, we can intro- duce a second time series y (in this case from the LSTM model, to capture the long-term melody), and instead uti- lize the follo wing acti vation, ef fectiv ely incorporating y as an extra input: z = tanh ( W f ,k ∗ x + V f ,k ∗ y ) σ ( W g ,k ∗ x + V g ,k ∗ y ) , (3) where V are learnable linear projections. By condition- ing on an extra time series input, we effecti vely guide the raw audio generations to require certain characteristics; y influences the output at all timestamps. Instrument Minutes Labels Piano 1,346 794,532 V iolin 874 230,484 Cello 621 99,407 Solo Piano 917 576,471 Solo V iolin 30 8,837 Solo Cello 49 10,876 T able 1 : Statistics of the MusicNet dataset. [24] In our modified W av eNet model, the second time series y is the upsampled MIDI embedding of the local condition- ing time series. In particular, local conditioning (LC) em- beddings are 128-dimensional binary vectors, where ones correspond to note indices that are being played at the cur - rent timestep. As with the audio time series, the LC em- beddings first go through a layer of causal con volutions to reduce the number of dimensions from 128 to 16, which are then used in the dilation layers as the conditioning sam- ples. This reduces the computational requirement for the dilation layers without reducing the note state information, as most of the embeddings are zero for most timestamps. This process along with the surrounding architecture is shown in Figure 3. 3.3 Hyperparameter T uning T able 2 enumerates the hyperparameters used in the W a veNet-based conditioned model to obtain our results. W e note that the conditioned model needs only 30 dila- tion layers as compared to the 50 we had used in the un- conditioned network. T raining with these parameters gav e us comparable results as compared to the unconditioned model in terms of the timbre of instruments and other nu- ances in generations. This indicates that the decrease in parameters is offset by the extra information provided by the conditioning time series. 4. EMPIRICAL EV ALU A TION Example results of generations from our models are posted on our web page. 6 One of the most challenging tasks in automated music generation is ev aluating the resulting music. Any gener- ated piece of music can generally only be subjectiv ely ev al- uated by human listeners. Here, we qualitativ ely ev aluate our results to the best of our ability , but leave the results on our web page for the reader to subjectively ev aluate. W e additionally quantify our results by comparing the re- sulting loss functions of the unconditioned and conditioned raw audio models. Then, we ev aluate the structural compo- nent by computing the cross-correlation between the spec- trogram of the generated ra w audio and conditioning input. 4.1 T raining Datasets and Loss Analysis At training time, in addition to raw training audio, we must also incorporate its underlying symbolic melody , perfectly 6 http://people.bu.edu/bkulis/projects/music/inde x.html Hyperparameter V alue Initial Filter W idth 32 Dilation Filter W idth 2 Dilation Layers 30 Residual Channels 32 Dilation Channels 32 Skip Channels 512 Initial LC Channels 128 Dilation LC Channels 16 Quantization Channels 128 T able 2 : W a veNet hyperparameters used for training of the conditioned network. aligned with the raw audio at each timestep. The problem of melody extraction in raw audio is still an activ e area of research; due to a general lack of such annotated music, we hav e experimented with multiple datasets. Primarily , we have been exploring use of the recently- released MusicNet database for training [24], as this data features both raw audio as well as melodic annotations. Other metadata is also included, such as the composer of the piece, the instrument with which the composition is played, and each note’ s position in the metrical structure of the composition. The music is separated by genre; there are over 900 minutes of solo piano alone, which has prov en to be very useful in training on only one instrument. The different genres provide many different options for train- ing. T able 1 shows some other statistics of the MusicNet dataset. After training with these datasets, we have found that the loss for the unconditioned and conditioned W av eNet models follows our expectation of the conditioned model exhibiting a lower cross-entropy training loss than the un- conditioned model. This is due to the additional embed- ding information provided along with the audio in the con- ditioned case. Figure 5 shows the loss for two W av eNet models trained on the MusicNet cello dataset over 100,000 iterations, illustrating this decreased loss for the condi- tioned model. 4.2 Unconditioned Music Generation with W aveNet W e preface the ev aluation of our musical results by ac- knowledging the fact that we first tuned W av eNet for unstructured music generation, as most applications of W a veNet hav e explored speech applications. Here we worked in the unconditioned case, i.e., no second time se- ries was input to the network. W e tuned the model to gener- ate music trained on solo piano inputs (about 50 minutes of the Chopin nocturnes, from the Y ouT ube-8M dataset [1]), as well as 350 songs of various genres of electronic dance music, obtained from No Copyright Sounds 7 . W e found that W aveNet models are capable of produc- ing lengthy , complex musical generations without losing instrumental quality for solo instrumental training data. The network is able to learn short-range dependencies, in- 7 https://www .youtube.com/user/NoCopyrightSounds Figure 4 : Example MIDI generation from the biaxial LSTM trained on cello music, visualized as sheet music. Figure 5 : Cross entropy loss for the conditioned (solid green) and unconditioned (dotted orange) W av eNet mod- els o ver the first 100,000 training iterations, illustrating the lower training loss of the conditioned model. cluding hammer action and simple chords. Although gen- erations may hav e a consistent energy , they are unstruc- tured and do not contain any long-range temporal depen- dencies. Results that showcase these techniques and at- tributes are a vailable on our webpage. 4.3 Structure in Raw A udio Generations W e ev aluate the structuring ability of our conditioned raw audio model for a generation based on how closely it fol- lows the conditioning signal it was giv en, first using pop- ular existing melodies, then the unique LSTM genera- tions. W e use cross-correlation as a quantitativ e ev alua- tion method. W e also acknowledge the applications of our model to edit existing ra w audio. 4.3.1 Raw Audio fr om Existing Melodies W e ev aluate our approach first by generating raw audio from popular existing melodies, by giving our conditioned model a second time series input of the Happy Birthday melody and a C major scale. Since we are familiar with these melodies, they are easier to e valuate by ear . Initial versions of the model e valuated in this way were trained on the MusicNet cello dataset. The generated raw audio follo ws the conditioning input, the recognizable Happy Birthday melody and C major scale, in a cello tim- bre. The results of these generations are uploaded on our webpage. 4.3.2 Raw Audio F rom Unique LSTM Gener ations After generating nov el melodies from the LSTM, we pro- duced corresponding output from our conditioned model. Since it is difficult to qualitativ ely e valuate such melodies (a) Unedited training sample from the MusicNet dataset. (b) Slightly modified training sample. Figure 6 : MIDI representations of a sample from the Mu- sicNet solo cello dataset, visualized as sheet music; (b) is a slightly modified version of (a), the original training sam- ple. W e use these samples to showcase the ability of our model to “edit” raw audio. by ear due to unfamiliarity with the melody , we are inter- ested in ev aluating how accurately the conditioned model follows a novel melody quantitati vely . W e ev aluate our re- sults by computing the cross-correlation between the MIDI sequence and the spectrogram of the generated raw au- dio as shown in Figure 7. Due to the sparsity of both the spectrogram and the MIDI file in the frequency dimension, we decided to calculate the cross-correlation between one- dimensional representations of the two time series. W e chose the frequency of the highest note in the MIDI at each timestep as its one-dimensional representation. In the case of the raw audio, we chose the most active frequency in its spectrogram at each timestep. W e acknowledge some weakness in this approach, since some information is lost by reducing the dimensionality of both time series. Cross-correlation is the “sliding dot product” of two time series — a measure of linear similarity as a function of the displacement of one series relativ e to the other . In this instance, the cross-correlation between the MIDI se- quence and the corresponding raw audio peaks at delay 0 and is equal to 0.3. In order to assure that this correlation is not due to chance, we have additionally calculated the cross-correlation between the generated raw audio and 50 different MIDI sequences in the same dataset. In Figure 7, we can see that the cross-correlation curve stays above the other random correlation curves in the the area around de- lay 0. This shows that the correlation found is not by chance, and the raw audio output follows the conditioning vector appropriately . This analysis generalizes to any piece generated with our model; we have successfully been able to transform an unstructured model with little long-range dependency to one with generations that exhibit certain characteristics. 4.3.3 Editing Existing Raw Audio In addition, we explored the possibility of using our ap- proach as a tool similar to a MIDI synthesizer , where we first generate from an e xisting piece of a symbolic melody , Figure 7 : Comparison of the nov el LSTM-generated melody (top) and the corresponding raw audio output of the condi- tioned model represented as a spectrogram (middle). The bottom plot shows the cross-correlation between the frequenc y of the highest note of the MIDI and the most acti ve frequency of raw audio from the W a veNet-based model, showing strong conditioning from the MIDI on the generated audio. in this case, from the training data. Then, we generate ne w audio by making small changes to the MIDI, and e valuate how the edits reflect in the generated audio. W e experi- ment with this with the goal of achieving a higher level of fidelity to the audio itself rather using a synthesizer to re- play the MIDI as audio, as that often forgoes the nuances associated with raw audio. Figure 6(a) and 6(b) respectively show a snippet of the training data taken from the MusicNet cello dataset and the small perturbations made to it, which were used to ev alu- ate this approach. The results posted on our webpage show that the generated raw audio retains similar characteristics between the original and the edited melody , while also in- corporating the changes to the MIDI in an expressiv e way . 5. CONCLUSIONS AND FUTURE WORK In conclusion, we focus on combining raw and symbolic audio models for the improvement of automatic music gen- eration. Combining two prev alent models allows us to take advantage of both of their features; in the case of raw audio models, this is the realistic sound and feel of the music, and in the case of symbolic models, it is the complexity , struc- ture, and long-range dependency of the generations. Before continuing to improv e our work, we first plan to more thoroughly ev aluate our current model using rat- ings of human listeners. W e will use cro wdsourced ev alua- tion techniques (specifically , Amazon Mechanical T urk 8 ) to compare our outputs with other systems. A future modification of our approach is to merge the LSTM and W av eNet models to a coupled architecture. 8 https://www .mturk.com/mturk/ This joint model would eliminate the need to synthesize MIDI files, as well as the need for MIDI labels aligned with raw audio data. In essence, this adjustment would create a true end-to-end automatic music generation model. Additionally , DeepMind recently updated the W aveNet model to improve generation speed by 1000 times over the previous model, at 16 bits per sample and a sampling rate of 24kHz [26]. W e hope to in vestigate this ne w model to dev elop real-time generation of novel, structured music, which has many significant implications. The potential results of our work could augment and inspire many future applications. The combination of our model with multiple audio domains could be implemented; this could inv olve the inte gration of speech audio with mu- sic to produce lyrics sung in tune with our realistic melody . Even without the additional improvements considered abov e, the architecture proposed in this paper allows for a modular approach to automated music generation. Mul- tiple different instances of our conditioned model can be trained on different genres of music, and generate based on a single local conditioning series in parallel. As a re- sult, the same melody can be reproduced in different genres or instruments, strung together to create effects such as a quartet or a band. The ke y application here is that this type of synchronized effect can be achieved without awareness of the other networks, a voiding model interdependence. 6. A CKNO WLEDGEMENT W e would like to acknowledge that this research was sup- ported in part by NSF CAREER A ward 1559558. 7. REFERENCES [1] S. Abu-El-Haija, N. K othari, J. Lee, P . Natsev , G. T oderici, B. V aradarajan, and S. V ijayanarasimhan. Y ouTube-8M: A large-scale video classification bench- mark. CoRR , abs/1609.08675, 2016. [2] Y . Bengio, P . Simard, and P . Frasconi. Learning long- term dependencies with gradient descent is difficult. IEEE transactions on neural networks , 5(2):157–166, 1994. [3] M. Blaauw and J. Bonada. A neural parametric singing synthesizer . ArXiv pr eprint 1704.03809 , 2017. [4] N. Boulanger-Le wando wski, Y . Bengio, and P . V in- cent. Modeling temporal dependencies in high- dimensional sequences: Application to polyphonic music generation and transcription. In Pr oceedings of the 29th International Conference on Machine Learn- ing , Edinbur gh, Scotland, UK, 26 Jun–1 Jul 2012. [5] J. Briot, G. Hadjeres, and F . Pachet. Deep learn- ing techniques for music generation—a survey . ArXiv pr eprint 1709.01620 , 2017. [6] J. Chung, C. Gulcehre, K. Cho, and Y . Bengio. Empir- ical e valuation of gated recurrent neural networks on sequence modeling. ArXiv pr eprint 1412:3555 , 2014. [7] A. V an den Oord, N. Kalchbrenner , and K. Ka vukcuoglu. Pixel recurrent neural networks. In Pr oceedings of The 33rd International Conference on Machine Learning , volume 48 of Proceedings of Machine Learning Researc h , pages 1747–1756, New Y ork, Ne w Y ork, USA, 20–22 Jun 2016. [8] J. Engel, C. Resnick, A. Roberts, S. Dieleman, M. Norouzi, D. Eck, and K. Simonyan. Neural au- dio synthesis of musical notes with Wav eNet autoen- coders. In Pr oceedings of the 34th International Con- fer ence on Machine Learning , volume 70 of Proceed- ings of Machine Learning Resear ch , pages 1068–1077, International Con vention Centre, Sydney , Australia, 06–11 Aug 2017. [9] K. Goel, R. V ohra, and JK Sahoo. Polyphonic music generation by modeling temporal dependencies using a rnn-dbn. In International Confer ence on Artificial Neu- ral Networks , pages 217–224. Springer , 2014. [10] I. Goodfellow , Y . Bengio, and A. Courville. Deep Learning . MIT Press, 2016. http://www .deeplearningbook.org. [11] G. Hadjeres, F . Pachet, and F . Nielsen. DeepBach: a steerable model for Bach chorales generation. In Pr o- ceedings of the 34th International Conference on Ma- chine Learning , volume 70 of Proceedings of Ma- chine Learning Resear ch , pages 1362–1371, Interna- tional Con vention Centre, Sydney , Australia, 06–11 Aug 2017. [12] S. Hochreiter and J. Schmidhuber . Long short-term memory . Neural computation , 9(8):1735–1780, 1997. [13] A. Huang and R. W u. Deep learning for music. ArXiv pr eprint 1606:04930 , 2016. [14] D. D. Johnson. Generating polyphonic music using tied parallel networks. In International Confer ence on Evolutionary and Biologically Inspired Music and Art , pages 128–143. Springer , 2017. [15] A. Karpathy , J. Johnson, and L. Fei-Fei. V isual- izing and understanding recurrent networks. CoRR , abs/1506.02078, 2015. [16] T . Le Paine, P . Khorrami, S. Chang, Y . Zhang, P . Ra- machandran, M. A. Hasegaw a-Johnson, and T . S. Huang. F ast wav eNet generation algorithm. ArXiv pr eprint 1611.09482 , 2016. [17] Q. L yu, J. Zhu Z. W u, and H. Meng. Modelling high- dimensional sequences with LSTM-R TRBM: Applica- tion to polyphonic music generation. In Pr oc. Interna- tional Artificial Intelligence Confer ence (AAAI) , 2015. [18] S. Madjiheurem, L. Qu, and C. W alder . Chord2Vec: Learning musical chord embeddings. In Proceedings of the Constructive Machine Learning W orkshop at 30th Confer ence on Neural Information Pr ocessing Systems , Barcelona, Spain, 2016. [19] R. Manzelli, V . Thakkar , A. Siahkamari, and B. Kulis. An end to end model for automatic music generation: Combining deep raw and symbolic audio networks. In Pr oceedings of the Musical Metacreation W orkshop at 9th International Conference on Computational Cre- ativity , Salamanca, Spain, 2018. [20] M. C. Mozer . Neural network composition by predic- tion: Exploring the benefits of psychophysical con- straints and multiscale processing. Connection Sci- ence , 6(2–3):247–280, 1994. [21] A. Nayebi and M. V itelli. Gruv: Algorithmic mu- sic generation using recurrent neural netw orks. Course CS224D: Deep Learning for Natural Language Pro- cessing (Stanfor d) , 2015. [22] I. Simon and S. Oore. Performance RNN: Generat- ing music with expressi ve timing and dynamics, 2017. https://magenta.tensorflow .org/performance-rnn. [23] B. L. Sturm, J. F . Santos, O. Ben-T al, and I. Kor - shunov a. Music transcription modelling and composi- tion using deep learning. ArXiv preprint 1604:08723 , 2016. [24] J. Thickstun, Z. Harchaoui, and S. M Kakade. Learning features of music from scratch. In International Con- fer ence on Learning Repr esentations (ICLR) , 2017. [25] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. V inyals, A. Grav es, N. Kalchbrenner , A. Senior , and K. Kavukcuoglu. W av eNet: A generativ e model for raw audio. ArXiv pr eprint 1609.03499 , 2016. [26] A. van den Oord, Y . Li, I. Babuschkin, K. Simonyan, O. V inyals, K. Kavukcuoglu, G. van den Driessche, E. Lockhart, L. C. Cobo, F . Stimberg, N. Casagrande, D. Grewe, S. Noury , S. Dieleman, E. Elsen, N. Kalch- brenner , H. Zen, A. Graves, H. King, T . W alters, D. Belov , and D. Hassabis. Parallel wavenet: Fast high-fidelity speech synthesis. CoRR , abs/1711.10433, 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment