심층 생성 모델로 구조화된 원시 오디오 음악 만들기
본 논문은 LSTM 기반 심볼릭 멜로디 생성기를 WaveNet에 로컬 컨디션으로 연결해, 구조적이며 현실감 있는 원시 오디오 음악을 자동으로 생성하는 방법을 제안한다. 심볼릭 모델이 장기 멜로디 구조를 담당하고, WaveNet이 실제 음색과 표현을 담당한다. MusicNet 데이터셋을 활용해 학습했으며, 조건부 모델이 비조건부 모델보다 낮은 교차 엔트로피 손실과 높은 스펙트로그램 상관성을 보였다.
저자: Rachel Manzelli, Vijay Thakkar, Ali Siahkamari
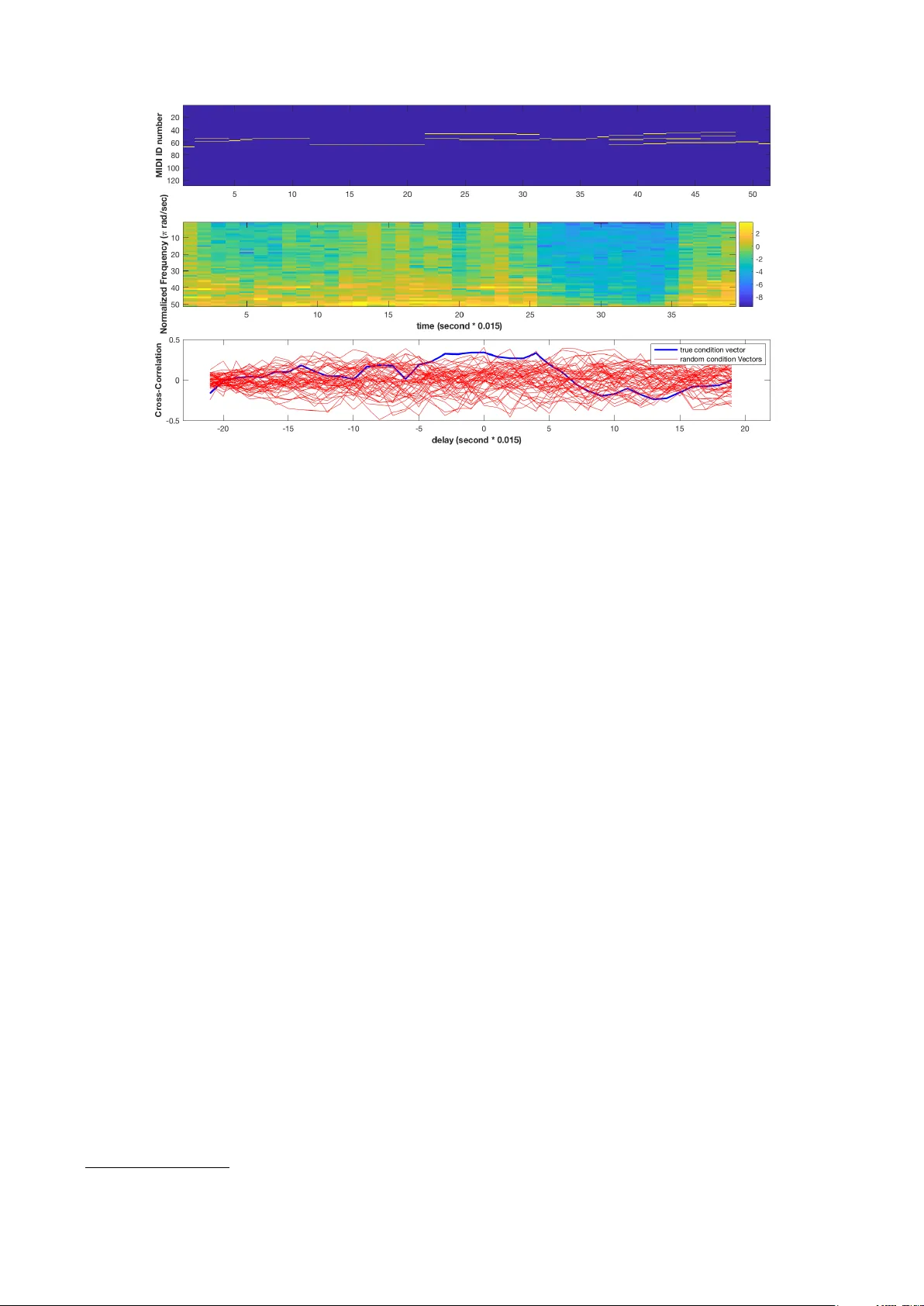
본 논문은 자동 음악 생성 분야에서 심볼릭 모델과 원시 오디오 모델이 각각 가지고 있는 장점과 단점을 보완하기 위해, 두 모델을 순차적으로 결합한 새로운 프레임워크를 제시한다. 먼저, 바이액셜 LSTM 네트워크를 이용해 MIDI 형식의 심볼릭 멜로디를 학습·생성한다. 이 모델은 시간 축과 피치 축 모두에 LSTM 레이어를 배치함으로써, 각 음표가 주변 음표와 시간적 맥락을 동시에 고려하도록 설계되었다. 학습 데이터는 MusicNet 데이터셋에서 추출한 다양한 장르와 악기의 MIDI 파일이며, 이를 통해 모델은 장기적인 멜로디 구조와 리듬 패턴을 효과적으로 학습한다.
다음 단계에서는 학습된 LSTM이 생성한 심볼릭 시퀀스를 WaveNet에 로컬 컨디션 입력으로 제공한다. WaveNet은 원래 음성 합성에 최적화된 인과적(시간 순서만 고려) dilated convolution 구조를 갖고 있으며, 8‑bit 양자화된 오디오 샘플을 다음 샘플의 확률 분포로 예측한다. 논문에서는 WaveNet의 각 디레이트 레이어에 존재하는 게이트 연산에 추가적인 선형 투영 V_f, V_g 를 도입해, LSTM에서 나온 MIDI 임베딩 y를 합산한다. 이때 y는 128‑차원 바이너리 벡터(각 음표가 현재 시점에 연주되는지를 표시)이며, 1‑D causal convolution을 거쳐 16‑차원으로 차원 축소된 뒤 컨디션으로 사용된다. 이렇게 함으로써, WaveNet은 단순히 무작위적인 음색을 생성하는 것이 아니라, LSTM이 제공하는 멜로디 흐름에 맞춰 음색과 표현을 조절한다.
학습은 MusicNet의 원시 오디오와 정렬된 MIDI 어노테이션을 동시에 사용한다. 데이터는 16 kHz, 8‑bit 양자화된 오디오와 각 음표의 시작·끝 시점, 피치, 악기 정보를 포함한다. 피아노, 바이올린, 첼로 등 각 악기별로 별도 모델을 학습했으며, 악기별 데이터 양은 표 1에 제시된 바와 같다(예: 피아노 794 532분, 바이올린 230 484분 등). 하이퍼파라미터는 원본 WaveNet 대비 디레이트 레이어를 50→30으로 감소시켰으며, 이는 컨디션 정보가 추가됨에 따라 모델 용량을 줄여도 성능 저하가 없음을 보여준다. 주요 파라미터는 초기 필터 폭 32, 디레이트 필터 폭 2, 잔차·스킵 채널 각각 32·512, 로컬 컨디션 채널 128→16, 양자화 채널 128 등이다.
평가에서는 두 가지 관점을 제시한다. 첫째, 학습 손실 측면에서 조건부 모델이 비조건부 모델보다 교차 엔트로피가 현저히 낮았다(그림 5). 이는 멜로디 정보를 제공함으로써 모델이 더 정확한 확률 분포를 학습함을 의미한다. 둘째, 구조적 일관성을 정량화하기 위해 생성된 오디오 스펙트로그램과 원본 MIDI 컨디션 시퀀스 간의 교차‑상관을 계산했으며, 조건부 모델이 높은 상관값을 보였다. 정성적 평가로는 C 메이저 스케일, Happy Birthday 등 알려진 멜로디를 재현하고, 기존 오디오의 일부 음표를 수정해 재생성하는 편집 실험을 수행했다. 또한, 웹 페이지에 전체 생성 결과를 공개해 청취자들이 직접 주관적인 평가를 할 수 있도록 하였다.
본 연구의 주요 기여는 다음과 같다. (1) 심볼릭 LSTM이 제공하는 장기 멜로디 구조와 WaveNet이 제공하는 고품질 음색을 결합해, 구조적이면서도 현실감 있는 원시 오디오 음악을 자동 생성한다. (2) 로컬 컨디션 방식을 도입해 심볼릭-오디오 변환 과정을 자동화함으로써 인간의 중간 개입을 최소화한다. (3) MusicNet과 같은 멀티모달 데이터셋을 활용해 원시 오디오와 심볼릭 라벨을 동시에 학습함으로써, 두 도메인 간 정렬 문제를 효과적으로 해결한다. (4) 조건부 모델이 비조건부 모델 대비 낮은 손실과 높은 스펙트로그램 상관성을 보이며, 구조적 일관성을 정량적으로 입증한다.
한계점으로는 (a) MIDI‑오디오 정렬이 가능한 데이터에 의존한다는 점, (b) 현재 컨디션 입력이 128‑차원 바이너리 임베딩에 국한되어 다중 음성(폴리포니)이나 악기 변형 등 복합적인 음악적 요소를 충분히 전달하지 못할 가능성이 있다. 또한, 8‑bit 양자화와 16 kHz 샘플링 레이트는 고음역대와 섬세한 다이내믹을 충분히 재현하지 못한다는 점도 있다. 향후 연구에서는 (i) 비지도 멜로디 추출 기법을 도입해 정렬되지 않은 오디오에서도 컨디션을 생성하고, (ii) 고해상도 양자화와 다중 트랙 컨디션을 적용해 복합적인 음악 구조를 다룰 수 있도록 확장할 필요가 있다.
결론적으로, 이 논문은 심볼릭과 원시 오디오 모델을 효과적으로 결합함으로써, 기존의 각각의 접근법이 가지고 있던 단점을 보완하고, 구조적이면서도 풍부한 음색을 가진 자동 음악 생성 시스템을 구현한다는 점에서 의미가 크다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기