End-to-End Speech Separation with Unfolded Iterative Phase Reconstruction
This paper proposes an end-to-end approach for single-channel speaker-independent multi-speaker speech separation, where time-frequency (T-F) masking, the short-time Fourier transform (STFT), and its inverse are represented as layers within a deep ne…
Authors: Zhong-Qiu Wang, Jonathan Le Roux, DeLiang Wang
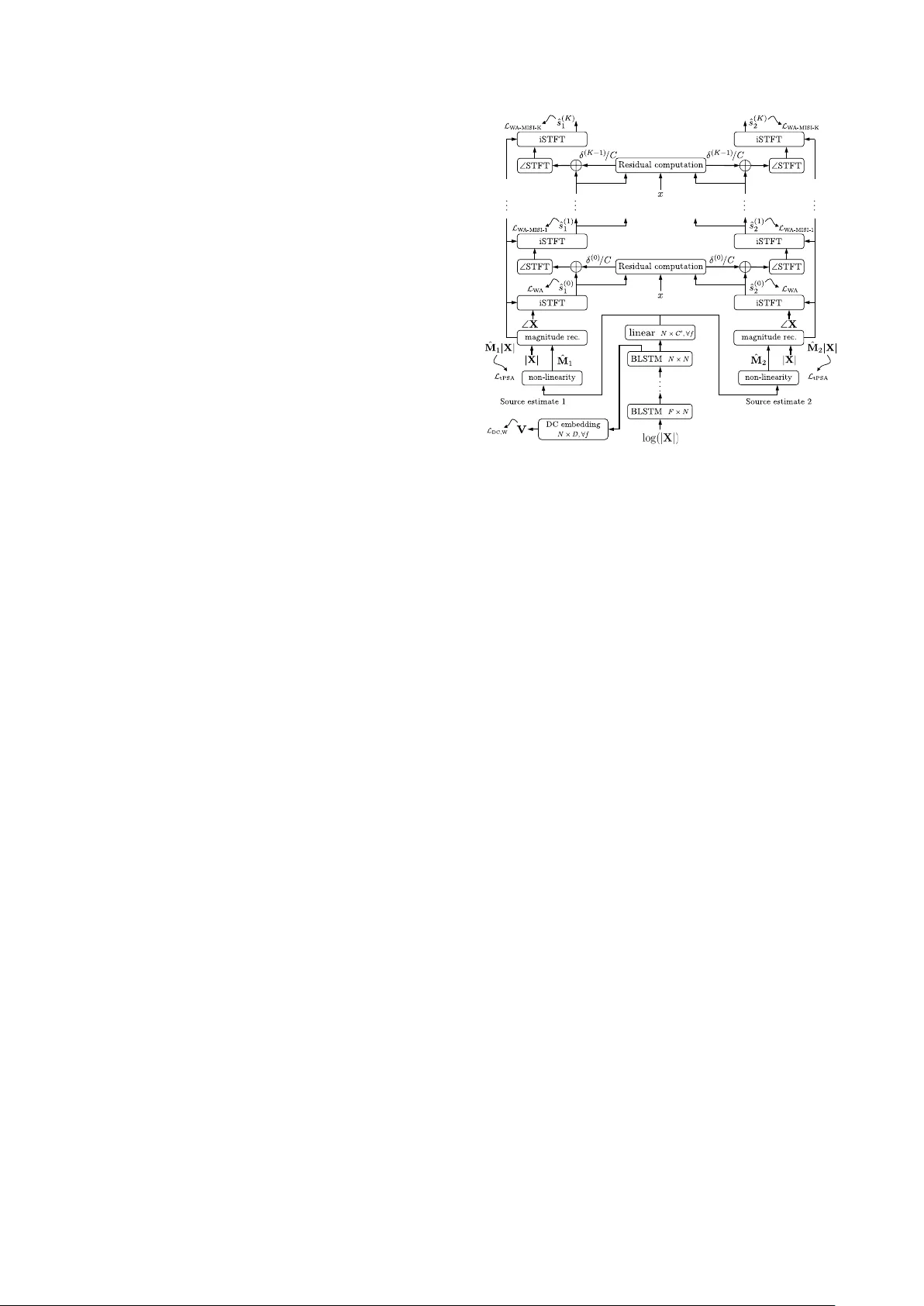
End-to-End Speech Separation with Unf olded Iterativ e Phase Reconstruction Zhong-Qiu W ang 1 , 2 , J onathan Le Roux 1 , DeLiang W ang 2 , 3 , J ohn R. Hershe y 1 1 Mitsubishi Electric Research Laboratories (MERL), USA 2 Department of Computer Science and Engineering, The Ohio State Uni versity , USA 3 Center for Cogniti ve and Brain Sciences, The Ohio State Uni versity , USA { wangzhon,dwang } @cse.ohio-state.edu, leroux@merl.com Abstract This paper proposes an end-to-end approach for single-channel speaker -independent multi-speaker speech separation, where time-frequency (T -F) masking, the short-time F ourier transform (STFT), and its in verse are represented as layers within a deep network. Previous approaches, rather than computing a loss on the reconstructed signal, used a surrogate loss based on the tar- get STFT magnitudes. This ignores reconstruction error intro- duced by phase inconsistency . In our approach, the loss func- tion is directly defined on the reconstructed signals, which are optimized for best separation. In addition, we train through unfolded iterations of a phase reconstruction algorithm, repre- sented as a series of STFT and in v erse STFT layers. While mask values are typically limited to lie between zero and one for approaches using the mixture phase for reconstruction, this limitation is less relev ant if the estimated magnitudes are to be used together with phase reconstruction. W e thus propose sev- eral novel activ ation functions for the output layer of the T -F masking, to allow mask values beyond one. On the publicly- av ailable wsj0-2mix dataset, our approach achie ves state-of- the-art 12.6 dB scale-inv ariant signal-to-distortion ratio (SI- SDR) and 13.1 dB SDR, rev ealing new possibilities for deep learning based phase reconstruction and representing a funda- mental progress towards solving the notoriously-hard cocktail party problem. Index T erms : deep clustering, chimera++ network, iterative phase reconstruction, cocktail party problem. 1. Intr oduction Recent years have witnessed exciting advances towards solv- ing the cocktail party problem. The in ventions of deep clus- tering [1, 2, 3], deep attractor networks [4, 5] and permu- tation free training [1, 2, 6, 7] have dramatically improved the performance of single-channel speaker -independent multi- speaker speech separation, demonstrating ov erwhelming advan- tages over previous methods including graphical modeling ap- proaches [8], spectral clustering approaches [9], and CASA methods [10]. Howe ver , all of these conduct separation on the magnitude in the time-frequency (T -F) domain and directly use the mix- ture phase for time-domain re-synthesis, largely because phase is difficult to estimate. It is well-known that this incurs a phase inconsistency problem [11, 12, 13], especially for speech pro- cessing, where there is typically at least half overlap between consecutiv e frames. This overlap makes the STFT representa- tion of a speech signal highly redundant. As a result, the en- hanced STFT representation obtained using the estimated mag- nitude and mixture phase would not be in the consistent STFT Part of this work was done while Z.-Q. W ang was an intern at MERL. domain, meaning that it is not guaranteed that there exists a time-domain signal having that STFT representation. T o improve the consistency , one stream of research is fo- cused on iterative methods such as the classic Griffin-Lim al- gorithm [14], multiple input spectrogram inv erse (MISI) [15], ISSIR [16], and consistent Wiener filtering [17], which can re- cov er the clean phase to some extent starting from the mixture phase and a good estimated magnitude by iteratively perform- ing STFT and iSTFT [13]. There are some pre vious attempts at naiv ely applying such iterative algorithms as a post-processing step on the magnitudes produced by deep learning based speech enhancement and separation [18, 19, 20, 3]. Ho wev er , this usu- ally only leads to small improvements, ev en though the magni- tude estimates from DNNs are reasonably good. W e think that this is possibly because the T -F masking is performed without being aware of the later phase reconstruction steps and hence may not produce spectral structures that are appropriate for it- erativ e phase reconstruction. This study hence proposes a novel end-to-end speech sep- aration algorithm that trains through iterative phase reconstruc- tion via T -F masking for signal-level approximation. On the publicly-av ailable wsj0-2mix corpus, our algorithm reaches 12.6 dB scale-inv ariant SDR, which surpasses the previous best by a large mar gin and is comparable to the oracle 12.7 dB re- sult obtained using the so-called ideal ratio mask (IRM). Our study shows, for the first time and based on a large open dataset, that deep learning based phase reconstruction leads to tangible and large improv ements when combined with state-of-the-art magnitude-domain separation. 2. Chimera++ Network T o elicit a good phase via phase reconstruction, it is necessary to first obtain a good enough magnitude estimate. Our recent study [3] proposed a novel multi-task learning approach combining the regularization capability of deep clustering with the ease of end-to-end training of mask inference, yielding significant improv ements over the indi vidual models. The ke y idea of deep clustering [1] is to learn a high- dimensional embedding vector for each T -F unit using a pow- erful deep neural network (DNN) such that the embeddings of the T -F units dominated by the same speak er are close to each other in the embedding space while farther otherwise. This way , simple clustering methods like k-means can be applied to the learned embeddings to perform separation at run time. More specifically , the network computes a unit-length embed- ding vector v i ∈ R 1 × D corresponding to the i th T -F element. Similarly , y i ∈ R 1 × C is a one-hot label vector representing which source in a mixture dominates the i th T -F unit. V ertically stacking these, we form the embedding matrix V ∈ R T F × D and the label matrix Y ∈ R T F × C . The embeddings are learned by approximating the affinity matrix from the embeddings: L DC , classic = k V V T − Y Y T k 2 F (1) Our recent study [3] suggests that an alternati ve loss func- tion, which whitens the embedding in a k-means objectiv e, leads to better separation performance. L DC , W = k V ( V T V ) − 1 2 − Y ( Y T Y ) − 1 Y T V ( V T V ) − 1 2 k 2 F = D − tr ( V T V ) − 1 V T Y ( Y T Y ) − 1 Y T V (2) T o learn the embeddings, bi-directional LSTM (BLSTM) is usually used to model the context information from past and future frames. The network architecture is shown at the bottom of Fig. 1, where the DC embedding layer is a fully-connected layer with a non-linearity such as a logistic sigmoid, followed by unit-length normalization for each frequency . Another permutation-free training scheme was proposed for mask-inference networks first in [1], and was later found to be working v ery well in [2] and [6]. The idea is to train a mask- inference network to minimize the minimum loss over all per - mutations. Follo wing [7], the phase-sensitive mask (PSM) [21] is used as the training target. It is common in phase-sensiti ve spectrum approximation (PSA) to truncate the unbounded mask values. Using T b a ( x ) = min(max( x, a ) , b ) , the truncated PSA (tPSA) objectiv e is L tPSA = min π ∈P X c ˆ M π ( c ) | X | − T γ | X | 0 ( | S c | cos( ∠ S c − ∠ X )) 1 , (3) where ∠ X is the mixture phase, ∠ S c the phase of the c -th source, P the set of permutations on { 1 , . . . , C } , | X | the mix- ture magnitude, ˆ M c the c -th estimated mask, | S c | the magni- tude of the c -th reference source, denotes element-wise ma- trix multiplication, and γ is a mask truncation factor . Sigmoidal activ ation together with γ = 1 is commonly used in the output layer of T -F masking. T o endow the network with more capa- bility , multiple acti vation functions that can work with γ > 1 will be discussed in Section 3.4. Follo wing [22], our recent study [3] proposed a chimera++ network combining the tw o approaches via multi-task learning, as illustrated in the bottom of Fig. 1. The loss function is a weighted sum of the deep clustering loss and the mask inference loss. L chi ++ α = α L DC,W + (1 − α ) L tPSA (4) Only the MI output is needed to make predictions at run time. 3. Pr oposed Algorithms 3.1. Iterative Phase Reconstruction There are multiple target sources to be separated in each mixture in our study . The Grif fin-Lim algorithm [14] only performs it- erativ e reconstruction for each source independently . In [3], we therefore proposed to utilize the MISI algorithm [15] (see Algo- rithm 1) to reconstruct the clean phase of each source starting from the estimated magnitude of each source and the mixture phase, where the sum of the reconstructed time-domain signals after each iteration is constrained to be the same as the mix- ture signal. Note that the estimated magnitudes remain fixed during iterations, while the phase of each source are iterativ ely reconstructed. In [3], the phase reconstruction was only added as a post-processing, and it was not part of the objectiv e func- tion during training, which remained computed on the time- Input : Mixture time-domain signal x , mixture complex spectrogram X , mixture phase ∠ X , enhanced magnitudes ˆ A c = ˆ M c ◦ | X | for c = 1 , . . . , C , and iteration number K Output : Reconstructed phase ˆ θ ( K ) c and signal ˆ s ( K ) c for c = 1 , . . . , C ˆ s (0) c = iSTFT ( ˆ A c , ∠ X ) , for c = 1 , . . . , C ; for i = 1 , . . . , K do δ ( i − 1) = x − P C c =1 ˆ s ( i − 1) c ; ˆ θ ( i ) c = ∠ STFT ˆ s ( i − 1) c + δ ( i − 1) C , for c = 1 , . . . , C ; ˆ s ( i ) c = iSTFT ( ˆ A c , ˆ θ ( i ) c ) , for c = 1 , . . . , C ; end Algorithm 1: Iterati ve phase reconstruction based on MISI. STFT( · ) extracts the STFT magnitude and phase of a signal, and iSTFT( · , · ) reconstructs a time-domain signal from a mag- nitude and a phase. frequency representation of the estimated signal, prior to resyn- thesis. In this paper , we go se veral steps further . 3.2. W avef orm Approximation The first step in phase reconstruction algorithms such as MISI is to reconstruct a wav eform from a time-frequency domain rep- resentation using the in verse STFT . W e thus consider a first ob- jectiv e function computed on the wav eform reconstructed by iSTFT , denoted as wa veform approximation (W A), and repre- sent iSTFT as v arious layers on top of the mask inference layer , so that end-to-end optimization can be performed. The label permutation problem is resolved by minimizing the minimum L 1 loss of all the permutations at the wav eform le vel. W e de- note the model trained this way as W A. The objectiv e function to train this model is L W A = min π ∈P X c ˆ s (0) π ( c ) − s c 1 , (5) where s c denotes the time-domain signal of source c , and ˆ s (0) c denotes the c -th time-domain signal obtained by inv erse STFT from the combination of the c -th estimated magnitude and the mixture phase. Note that mixture phase is still used here and no phase reconstruction is yet performed. This corresponds to the initialization step in Algorithm 1. In [23], a time-domain reconstruction approach is proposed for speech enhancement. Howe ver , their approach only trains a feed-forward mask-inference DNN through iDFT separately for each frame using squared error in the time domain. By Par- sev al’ s theorem, this is equiv alent to optimizing the mask for minimum squared error in the comple x spectrum domain, when using the noisy phases, as in [21], proposed in the same con- ference. A follo w-up work [19] of [23] supplies clean phase during training. Howe ver , this makes their approach equiv alent to conv entional magnitude spectrum approximation [24], which does not perform as well as the phase-sensitiv e mask [25]. Clos- est to the abov e W A objectiv e, an adaptiv e front-end framew ork was recently proposed [26] in which the STFT and its inv erse are subsumed by the network, along with the noisy phase, so that training is effecti vely end-to-end in the time-domain. The proposed method then replaces the STFT and its in verse by trainable linear con volutional layers. Unfortunately the paper does not compare training through the STFT to the con ventional method so the results are uninformativ e about this direction. 3.3. Unfolded Iterative Phase Reconstruction W e further unfold the iterations in the MISI algorithm as various deterministic layers in a neural network. This can be achie ved by further gro wing sev eral layers representing STFT and iSTFT operations on top of the mask inference layer . By perform- ing end-to-end optimization that trains through MISI, the net- work can become a ware of the later iterativ e phase reconstruc- tion steps and learn to produce estimated magnitudes that are well-suited to that subsequent processing, hence producing bet- ter phase estimates for separation. The model trained this way is denoted as W A-MISI-K, where K ≥ 1 is the number of un- folded MISI iterations. The objecti ve function is L W A-MISI-K = min π ∈P X c ˆ s ( K ) π ( c ) − s c 1 , (6) where ˆ s ( K ) c denotes the c -th time-domain signal obtained after K MISI iterations as described in Algorithm 1. The whole sep- aration network, including unfolded phase reconstruction steps at the output of the mask inference head of the Chimera++ net- work, is illustrated in Fig. 1. The STFT and iSTFT can be easily implemented using modern deep learning toolkits as determin- istic layers efficiently computed on a GPU and through which backpropagation can be performed. A recent study by W illiamson et al. [27, 28] proposed a complex ratio masking approach for phase reconstruction and speech enhancement, where a feed-forward DNN is trained to predict the real and imaginary components of the ideal complex filter in the STFT domain, i.e., M c = S c /X = | S c | e j ( ∠ S c − ∠ X ) / | X | for source c for example. The real com- ponent is equivalent to the earlier proposed phase-sensitive mask [21], which contains patterns clearly predictable from energy-based features [21, 25]. Howe ver , recent studies along this line suggest that the patterns in the imaginary component are too random to predict [29], possibly because it is difficult for a learning machine to determine the sign of sin( ∠ S c − ∠ X ) only from energy-based features. In contrast, the cos( ∠ S c − ∠ X ) in the real component is typically much smaller than one for T -F units dominated by other sources and close to one other - wise, making itself predictable from energy-based features. The proposed method thus only focuses on estimating a mask in the magnitude domain and uses the estimated magnitude to elicit better phase through iterativ e phase reconstruction. Another recent trend is to avoid the phase inconsistency problem altogether by operating in the time domain, using con- volutional neural networks [30, 31], W aveNet [32], genera- tiv e adversarial networks [33], or encoder-decoder architectures [34]. Although they are promising approaches, the current state- of-the-art approach for supervised speech separation is via T -F masking [35, 3]. The proposed approach is e xpected to produce ev en better separation if the phase can be reconstructed. 3.4. Activation Functions with V alues Beyond One Sigmoidal units are dominantly used in the output layer of deep learning based T -F masking [36, 35], partly because they can model well data with bi-modal distribution [37], such as the IRM [38] and its variants [36]. Restricting the possible v al- ues of the T -F mask to lie in [0 , 1] is also reasonable when using the mixture phase for reconstruction: indeed, T -F mask values larger than one would in theory be needed in regions where interferences between sources result in a mixture magni- tude smaller than that of a source; but the mixture phase is also likely to be dif ferent from the phase of that source in such re- gions, in which case it is more rewarding in terms of objecti ve measure to oversuppress than to go even further in a wrong di- rection. This is no longer v alid if we consider phase reconstruc- tion in the optimization. Moreover , capping the mask values to Figure 1: T raining thr ough K MISI iterations. be between zero and one is more likely to take the enhanced magnitude further away from the consistent STFT domain, pos- ing potential difficulties for later phase reconstruction. T o obtain clean magnitudes, the oracle mask should be | S c | / | X | (also known as the FFT mask in [38] or the ideal am- plitude mask in [21]). Clearly , this mask can go beyond one, because the underlying sources, although statistically indepen- dent, may hav e opposite phase at a particular T -F unit, therefore cancelling with each other and producing a mixture magnitude that is smaller than the magnitude of a given source. It is likely much harder to predict the mask v alues of such T -F units, but we believ e that it is still possible based on contextual information. In our study , we truncate the values in PSM to the range [0 , 2] (i.e., γ = 2 in Eq. (3)), as only a small percentage of mask values goes beyond this range. Multiple activ ation functions can be utilized in the output layer . W e here consider: • doubled sigmoid: sigmoid non-linearity multiplied by 2; • clipped ReLU: ReLU non-linearity clipped to [0 , 2] ; • con ve x softmax: the output non-linearity is a three- dimensional softmax for each source at each T -F unit. It is used to compute a con vex sum between the values 0, 1, and 2: y = [ x 0 , x 1 , x 2 ][0 , 1 , 2] T where [ x 0 , x 1 , x 2 ] is the output of the softmax. This activ ation function is designed to model the three modes concentrated at 0, 1 and 2 in the histogram of the PSM. 4. Experimental Setup W e validate the proposed algorithms on the publicly-a vailable wsj0-2mix corpus [1], which is widely used in many speaker- independent speech separation tasks. It contains 20,000, 5,000 and 3,000 tw o-speaker mixtures in its 30 h training, 10 h valida- tion, and 5 h test sets, respectively . The speakers in the valida- tion set (closed speaker condition, CSC) are seen during train- ing, while the speak ers in the test set (open speaker condition, OSC) are completely unseen. The sampling rate is 8 kHz. Our neural netw ork contains four BLSTM layers, each with 600 units in each direction. A dropout of 0 . 3 is applied on the output of each BLSTM layer except the last one. The network is trained on 400-frame segments using the Adam algorithm. The T able 1: SI-SDR (dB) performance on wsj0-2mix. Approaches CSC OSC L DC,W 10.4 10.4 L tPSA 10.1 10.0 L chi ++ α (sigmoid) 11.1 11.2 + Griffin-Lim-5 11.2 11.3 + MISI-5 11.4 11.5 + L W A 11.6 11.6 +MISI-5 11.6 11.6 + L W A-MISI-5 12.4 12.2 L chi ++ α (doubled sigmoid) 10.0 10.0 + L W A 11.5 11.4 + L W A-MISI-5 12.5 12.3 L chi ++ α (clipped RelU) 10.4 10.4 + L W A 11.7 11.7 + L W A-MISI-5 12.6 12.4 L chi ++ α (con vex softmax) 11.0 11.1 + L W A 11.8 11.8 + L W A-MISI-5 12.8 12.6 0 1 2 3 4 5 Num b er of MISI iterations at test time 11 . 00 11 . 25 11 . 50 11 . 75 12 . 00 12 . 25 12 . 50 12 . 75 SI-SDR [dB] L c hi ++ α L W A L W A − MISI − 1 L W A − MISI − 2 L W A − MISI − 3 L W A − MISI − 4 L W A − MISI − 5 Figure 2: SI-SDR vs number of MISI iterations at test time window length is 32 ms and the hop size is 8 ms. The square root Hann window is employed as the analysis window and the synthesis windo w is designed accordingly to achiev e perfect re- construction after o verlap-add. A 256-point DFT is performed to extract 129-dimensional log magnitude input features. W e first train the chimera++ network with α set to 0.975. Next, we discard the deep clustering branch (i.e., we set α to 0) and train the network with L W A . Subsequently , the network is trained us- ing L W A-MISI-1 , then L W A-MISI-2 , and all the way to L W A-MISI-K , where here K = 5 , as performance saturated after five itera- tions in our experiments. W e found this curriculum learning strategy to be helpful. At run time, for the models trained us- ing L W A-MISI-5 , we run MISI with 5 iterations, while results for other models are obtained without phase reconstruction unless specified. W e report the performance using scale-invariant SDR (SI- SDR) [1, 2, 5, 39], as well as the SDR metric computed using the bss ev al sources software [40] because it is used by other groups. W e believ e SI-SDR is a more proper measure for single- channel instantaneous mixtures [39]. 5. Evaluation Results T able 1 reports the SI-SDR results on the wsj0-2mix dataset. W e first present the results using sigmoidal activ ation. The chimera++ network obtains significantly better results than the individual models (11.2 dB vs. 10.4 dB and 10.0 dB SI-SDR). W ith the mixture phase and estimated magnitudes, performing fiv e iterations of MISI pushes the performance to 11.5 dB, while 11.3 dB is obtained when applying fiv e iterations of Grif fin-Lim T able 2: Comparison with other systems on wsj0-2mix. SI-SDR (dB) SDR (dB) Approaches CSC OSC CSC OSC Deep Clustering [1, 2] - 10.8 - - Deep Attractor Networks [4, 5] - 10.4 - 10.8 PIT [6, 7] - - 10.0 10.0 T asNet [34] - 10.2 - 10.5 Chimera++ Networks [3] 11.1 11.2 11.6 11.7 + MISI-5 [3] 11.4 11.5 12.0 12.0 W A (proposed) 11.8 11.8 12.3 12.3 W A-MISI-5 (proposed) 12.8 12.6 13.2 13.1 Oracle Masks: Magnitude Ratio Mask 12.5 12.7 13.0 13.2 + MISI-5 13.5 13.7 14.1 14.3 Ideal Binary Mask 13.2 13.5 13.7 14.0 + MISI-5 13.1 13.4 13.6 13.8 PSM 16.2 16.4 16.7 16.9 + MISI-5 18.1 18.3 18.5 18.8 Ideal Amplitude Mask 12.6 12.8 12.9 13.2 + MISI-5 26.3 26.6 26.8 27.1 on each source independently , as is reported in [3]. Performing end-to-end optimization using L W A improv es the results to 11.6 dB from 11.2 dB, without requiring phase reconstruction post- processing. Further applying MISI post-processing for fi ve it- erations (MISI-5) on this model ho wev er does not lead to any improv ements, likely because the mixture phase is used during training and the model compensates for it without expecting fur- ther processing. In contrast, training the network through MISI using L W A-MISI-5 pushes the performance to 12.2 dB. Among the three proposed activ ation functions, the conv ex softmax performs the best, reaching 12.6 dB SI-SDR. It thus seems ef fectiv e to model the multiple peaks in the histogram of the truncated PSM, and important to produce estimated mag- nitudes that are closer to the consistent STFT domain. As expected, activ ations going beyond 1 only become beneficial when training through phase reconstruction. In Fig. 2, we show the evolution of the SI-SDR performance of the con vex softmax models trained with different objecti ve functions ag ainst the number of MISI iterations at test time ( 0 to 5 ). T raining with L W A leads to a magnitude that is very well suited to iSTFT , but not to further MISI iterations. As we train for more MISI iterations, performance starts lower , but reaches higher values with more test-time iterations. T able 2 lists the performance of competitiv e approaches on the same corpus, along with the performance of v arious oracle masks with or without applying MISI for five iterations. The first three algorithms use mixture phase directly for separation. The fourth one, time-domain audio separation network (T as- Net), operates directly in the time domain. Our result is 1.1 dB better than the previous state-of-the-art by [3] in terms of both SI-SDR and SDR. 6. Concluding Remarks W e hav e proposed a novel end-to-end approach for single- channel speech separation. Significant improvements are ob- tained by training the T -F masking network through an iterati ve phase reconstruction procedure. Future w ork includes applying the proposed methods to speech enhancement, considering the joint estimation of magnitude and an initial phase that improv es upon the mixture phase, and improving the estimation of the ideal amplitude mask. W e shall also consider alternati ves to the wa veform-le vel loss, such as errors computed on the magnitude spectrograms of the reconstructed signals. 7. Refer ences [1] J. R. Hershey , Z. Chen, and J. Le Roux, “Deep Clustering: Discriminativ e Embeddings for Segmentation and Separation, ” in Pr oc. IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , 2016. [2] Y . Isik, J. Le Roux, Z. Chen, S. W atanabe, and J. R. Hershey , “Single-Channel Multi-Speaker Separation using Deep Cluster- ing, ” in Pr oc. Interspeech , 2016. [3] Z.-Q. W ang, J. Le Roux, and J. R. Hershey , “ Alternati ve Objectiv e Functions for Deep Clustering, ” in Pr oc. IEEE International Con- fer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2018. [4] Z. Chen, Y . Luo, and N. Mesgarani, “Deep Attractor Network for Single-Microphone Speaker Separation, ” in Pr oc. IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2017. [5] Y . Luo, Z. Chen, and N. Mesgarani, “Speaker-Independent Speech Separation with Deep Attractor Network, ” IEEE/ACM T ransactions on Audio, Speech, and Language Processing , 2018. [6] D. Y u, M. Kolbæk, Z.-H. T an, and J. Jensen, “Permutation In variant Training of Deep Models for Speaker-Independent Multi-talker Speech Separation, ” in Proc. IEEE International Confer ence on Acoustics, Speec h and Signal Processing (ICASSP) , 2017. [7] M. Kolbæk, D. Y u, Z.-H. T an, and J. Jensen, “Multi-T alker Speech Separation with Utterance-Lev el Permutation In variant T raining of Deep Recurrent Neural Networks, ” IEEE/A CM T ransactions on Audio, Speech and Language Pr ocessing , 2017. [8] J. R. Hershey , S. Rennie, P . A. Olsen, and T . T . Kristjansson, “Super-Human Multi-T alker Speech Recognition: A Graphical Modeling Approach, ” Computer Speech & Language , vol. 24, no. 1, 2010. [9] F . Bach and M. Jordan, “Learning Spectral Clustering, with Application to Speech Separation, ” The Journal of Machine Learning Researc h , vol. 7, 2006. [10] D. W ang and G. J. Brown, Eds., Computational A uditory Scene Analysis: Principles, Algorithms, and Applications . Hoboken, NJ: W iley-IEEE Press, Sep. 2006. [11] J. Le Roux, N. Ono, and S. Sagayama, “Explicit consistency con- straints for STFT spectrograms and their application to phase re- construction, ” in Pr oc. ISCA W orkshop on Statistical and P ercep- tual Audition (SAP A) , Sep. 2008. [12] N. Sturmel and L. Daudet, “Signal Reconstruction from STFT Magnitude: A State of the Art, ” in International Confer ence on Digital Audio Effects , 2011. [13] T . Gerkmann, M. Krawczyk-Becker , and J. Le Roux, “Phase Pro- cessing for Single-Channel Speech Enhancement: History and Recent Advances, ” IEEE Signal Processing Magazine , vol. 32, no. 2, 2015. [14] D. W . Grif fin and J. S. Lim, “Signal Estimation from Modified Short-T ime Fourier T ransform, ” IEEE T ransactions on Acoustics, Speech, and Signal Pr ocessing , vol. 32, no. 2, 1984. [15] D. Gunawan and D. Sen, “Iterative Phase Estimation for the Synthesis of Separated Sources from Single-Channel Mixtures, ” in IEEE Signal Pr ocessing Letters , 2010. [16] N. Sturmel and L. Daudet, “Informed Source Separation using Iterativ e Reconstruction, ” IEEE T ransactions on Audio, Speech, and Language Processing , v ol. 21, no. 1, Jan. 2013. [17] J. Le Roux and E. V incent, “Consistent Wiener Filtering for Au- dio Source Separation, ” IEEE Signal Pr ocessing Letters , vol. 20, no. 3, Mar . 2013. [18] K. Han, Y . W ang, D. W ang, W . S. W oods, and I. Merks, “Learning Spectral Mapping for Speech Dereverberation and Denoising, ” IEEE/A CM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 23, no. 6, 2015. [19] Y . Zhao, Z.-Q. W ang, and D. W ang, “A T wo-stage Algorithm for Noisy and Re verberant Speech Enhancement, ” in Proc. IEEE In- ternational Conference on Acoustics, Speech and Signal Process- ing (ICASSP) , 2017. [20] K. Li, B. Wu, and C.-H. Lee, “An Iterative Phase Recov ery Framew ork with Phase Mask for Spectral Mapping with an Ap- plication to Speech Enhancement, ” in Pr oc. Interspeech , 2016. [21] H. Erdogan, J. R. Hershey, S. W atanabe, and J. Le Roux, “Phase-Sensitiv e and Recognition-Boosted Speech Separation using Deep Recurrent Neural Networks, ” in Proc. IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2015. [22] Y . Luo, Z. Chen, J. R. Hershe y , J. Le Roux, and N. Mesgarani, “Deep Clustering and Con ventional Networks for Music Separa- tion: Stronger T ogether, ” in Proc. IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2017. [23] Y . W ang and D. W ang, “A Deep Neural Network for Time- Domain Signal Reconstruction, ” in Pr oc. IEEE International Confer ence on Acoustics, Speec h and Signal Processing (ICASSP) , 2015. [24] F . W eninger, J. R. Hershey , J. Le Roux, and B. Schuller, “Discriminativ ely T rained Recurrent Neural Netw orks for Single- channel Speech Separation, ” in Proc. IEEE Global Conference on Signal and Information Pr ocessing (GlobalSIP) , 2014. [25] F . W eninger , H. Erdogan, S. W atanabe, E. V incent, J. Le Roux, J. R. Hershey, and B. Schuller, “Speech Enhancement with LSTM Recurrent Neural Networks and its Application to Noise-Robust ASR, ” in Proc. International Conference on Latent V ariable Analysis and Signal Separation (L V A/ICA) , 2015. [26] S. V enkataramani and P . Smaragdis, “End-to-end source separation with adaptiv e front-ends, ” in arXiv pr eprint arXiv:1705.02514 , 2017. [27] D. S. Williamson, Y . W ang, and D. W ang, “Complex Ratio Masking for Monaural Speech Separation, ” IEEE/ACM T ransactions on Audio, Speech, and Language Processing , 2016. [28] D. S. Williamson and D. W ang, “Time-Frequenc y Masking in the Complex Domain for Speech Dereverberation and Denoising, ” IEEE/ACM T ransactions on Audio Speech and Language Process- ing , vol. 25, no. 7, 2017. [29] D. S. Williamson and D. W ang, “Speech Derev erberation and Denoising using Complex Ratio Masks, ” in Proc. IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2017. [30] S.-W . Fu, Y . Tsao, X. Lu, and H. Kawai, “End-to-End W aveform Utterance Enhancement for Direct Evaluation Metrics Optimization by Fully Con volutional Neural Networks, ” arXiv pr eprint arXiv:1709.03658 , 2017. [31] ——, “Ra w W a veform-Based Speech Enhancement by Fully Con volutional Networks, ” in arXiv preprint arXiv:1703.02205 , 2017. [32] K. Qian, Y . Zhang, S. Chang, X. Y ang, M. Hasega wa-Johnson, D. Florencio, and M. Hasegaw a-Johnson, “Speech Enhancement using Bayesian W aveNet, ” in Proc. Interspeech , 2017. [33] S. Pascual, A. Bonafonte, and J. Serra, “SEGAN: Speech En- hancement Generative Adversarial Network, ” in Proc. Inter- speech , 2017. [34] Y . Luo and N. Mesgarani, “T asNet: T ime-Domain Audio Separation Network for Real-Time, Single-Channel Speech Separation, ” in arXiv preprint , 2017. [35] D. W ang and J. Chen, “Supervised Speech Separation Based on Deep Learning: An Overvie w, ” in arXiv preprint arXiv:1708.07524 , 2017. [36] Z.-Q. W ang and D. W ang, “Recurrent Deep Stacking Net- works for Supervised Speech Separation, ” in Proc. IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2017. [37] C. M. Bishop, P attern Recognition and Machine Learning . Springer , 2006. [38] Y . W ang, A. Narayanan, and D. W ang, “On T raining T ar gets for Supervised Speech Separation, ” IEEE/A CM T ransactions on Audio, Speech, and Language Processing , v ol. 22, no. 12, 2014. [39] J. Le Roux, J. R. Hershey , S. T . Wisdom, and H. Erdogan, “SDR – half-baked or well done?” Mitsubishi Electric Research Labo- ratories (MERL), Cambridge, MA, USA, T ech. Rep., 2018. [40] E. V incent, R. Gribon v al, and C. F ´ evotte, “Performance measure- ment in blind audio source separation, ” IEEE T ransactions on Au- dio, Speech and Language Pr ocessing , vol. 14, no. 4, Jul. 2006.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment