단일 채널 스피커 독립 음성 분리를 위한 전면형 위상 재구성 네트워크
본 논문은 STFT·iSTFT를 신경망 레이어로 구현하고, 마스크 추정 후 다중 반복 위상 재구성(MISI)을 전개하여 손실을 직접 파형 수준에서 최적화한다. 마스크 출력에 0~1을 초과하는 값을 허용하는 새로운 활성화 함수를 도입하고, wsj0‑2mix 데이터셋에서 SI‑SDR 12.6 dB, SDR 13.1 dB라는 최고 성능을 달성한다.
저자: Zhong-Qiu Wang, Jonathan Le Roux, DeLiang Wang
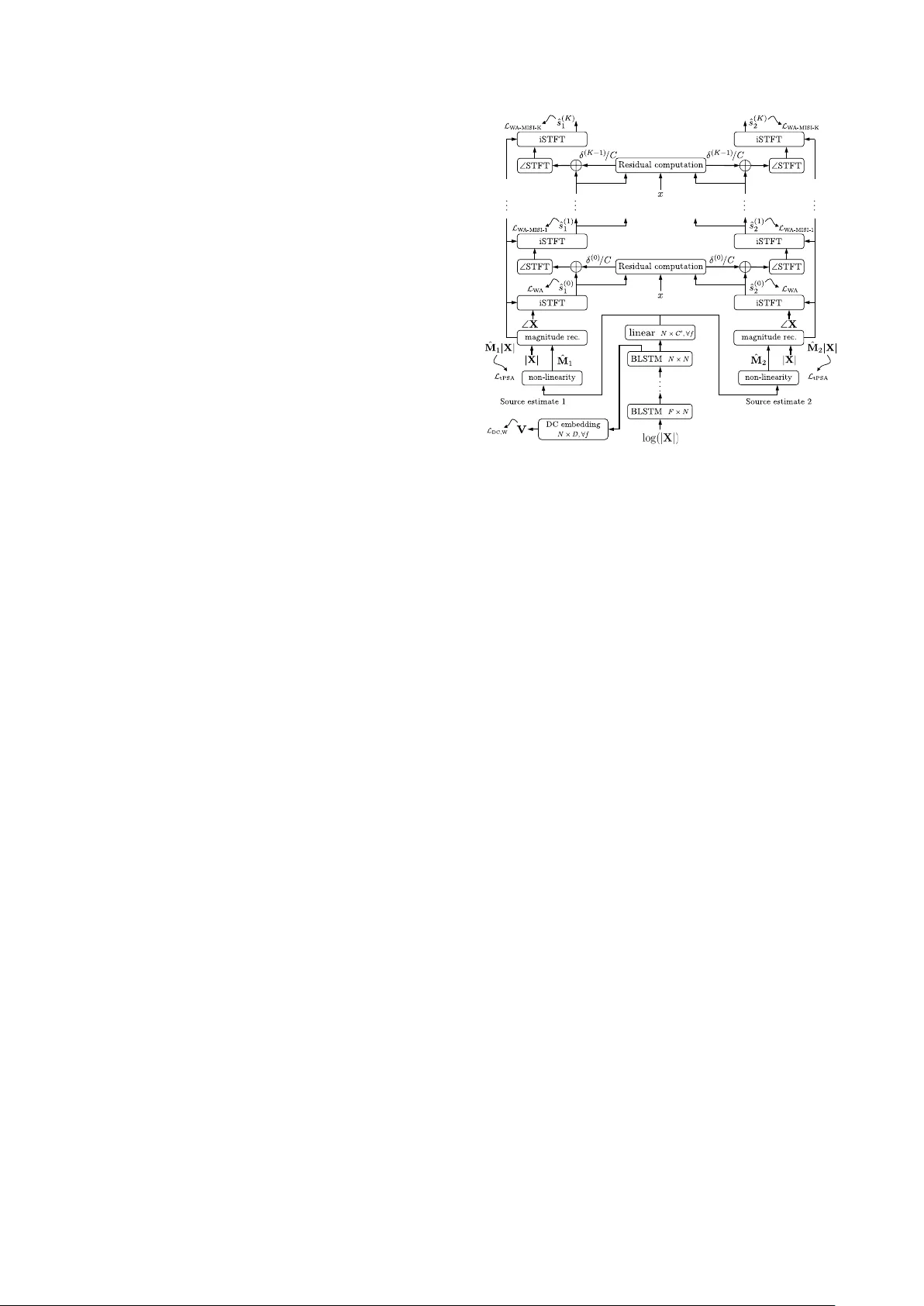
본 논문은 단일 채널, 스피커 독립적인 다중 화자 음성 분리를 목표로, 기존의 STFT 기반 마스크 추정 방식이 혼합 신호의 위상을 그대로 사용함으로써 발생하는 ‘위상 불일치’ 문제를 해결하고자 한다. 이를 위해 저자들은 STFT와 iSTFT 연산을 신경망 내부의 결정적 레이어로 구현하고, 마스크 추정 후 다중 반복 위상 재구성 알고리즘인 MISI(Multiple Input Spectrogram Inverse)를 K번 전개(unfold)하여 파형 수준의 손실을 직접 최소화하는 전면형(end‑to‑end) 학습 프레임워크를 제안한다.
1. **배경 및 기존 연구**
- Deep clustering, deep attractor network, permutation‑free training 등 최근 T‑F 마스킹 기반 방법들은 magnitude 추정에 크게 성공했지만, 위상은 여전히 혼합 위상을 그대로 사용한다. 이는 STFT가 중첩(overlap) 구조를 가짐에 따라 동일한 T‑F 셀에 대해 일관된 복소 스펙트럼을 보장하지 못한다는 점에서 문제를 일으킨다.
- 기존의 위상 재구성 시도(Griffin‑Lim, MISI, ISSIR 등)는 사후 처리(post‑processing) 형태로 적용돼, 마스크 추정 단계와 독립적으로 동작했다. 따라서 마스크가 위상 재구성을 고려하지 않은 채 학습돼, 재구성 단계에서 최적이 아닌 결과를 초래한다.
2. **Chimera++ 네트워크**
- 저자는 Chimera++라는 다중 과제 학습 구조를 사용한다. 이 구조는 deep clustering 손실 L_DC,W와 mask‑inference 손실 L_tPSA를 가중합(α)으로 결합한다.
- 네트워크는 4개의 BLSTM 레이어(양방향 각각 600 유닛)와 dropout(0.3)을 포함하며, 256‑point DFT를 통해 129‑dimensional 로그 magnitude를 입력 특징으로 사용한다.
- 기존에는 출력 마스크에 시그모이드(0~1)만을 적용했지만, 위상 재구성을 고려하면 이상적인 마스크는 1을 초과할 수 있다(예: 두 화자의 위상이 반대일 경우 혼합 진폭이 감소).
3. **새로운 활성화 함수**
- **두 배 시그모이드**: 기존 시그모이드를 2배 확대하여 0~2 범위 허용.
- **클리핑 ReLU**: ReLU를 0~2 구간으로 클리핑.
- **컨벡스 소프트맥스**: 0,1,2 세 값에 대한 3‑차원 소프트맥스를 적용해, 출력이 이 세 값의 가중합 형태가 되도록 설계.
- 이러한 함수들은 마스크가 1을 초과하도록 허용하면서도 학습 안정성을 유지한다.
4. **위상 재구성 단계**
- **Waveform Approximation (WA)**: 추정된 마스크와 혼합 위상을 사용해 iSTFT를 수행하고, 파형 L1 손실을 최소화한다. 이는 MISI 알고리즘의 초기화 단계와 동일하다.
- **Unfolded MISI (WA‑MISI‑K)**: WA 단계에서 얻은 파형을 초기값으로, MISI 알고리즘을 K번 반복한다. 각 반복은 STFT → 위상 추정 → iSTFT 순서의 레이어로 구현되며, 전체 파이프라인이 미분 가능하도록 설계돼 역전파가 가능하다.
- 손실 함수는 최종 K번째 반복 후 재구성된 파형과 정답 파형 간의 L1 혹은 SI‑SDR을 최소화한다.
5. **실험 설정**
- 데이터: wsj0‑2mix (훈련 20 k, 검증 5 k, 테스트 3 k) – 8 kHz, 32 ms 윈도우, 8 ms 홉, Hann 윈도우.
- 학습: Adam optimizer, 400‑frame 배치, α=0.975로 Chimera++ 사전 학습 후, deep clustering 브랜치를 제거하고 WA 손실로 재학습.
- 평가 지표: SI‑SDR, SDR.
6. **결과 및 분석**
- 기본 Chimera++(시그모이드) → SI‑SDR 11.1 dB (CSC) / 11.2 dB (OSC).
- WA‑MISI‑5 적용 시 SI‑SDR 12.4 dB (CSC) / 12.2 dB (OSC).
- 활성화 함수별 성능 차이: 두 배 시그모이드, 클리핑 ReLU, 컨벡스 소프트맥스 모두 WA‑MISI‑5에서 12.5~12.8 dB 수준을 달성, 특히 컨벡스 소프트맥스가 12.8 dB(폐쇄형)와 12.6 dB(열린형)로 최고 성능.
- MISI 반복 횟수를 1~5까지 변화시킨 실험에서 SI‑SDR가 점진적으로 상승했으며, 5회 반복에서 수렴에 가까운 결과를 보였다.
- 마스크 값을 0~2 범위로 허용한 것이 위상 재구성 효율을 크게 향상시켰으며, 특히 1을 초과하는 마스크가 존재하는 T‑F 셀에서 위상 일관성을 회복하는 데 기여했다.
7. **의의 및 향후 과제**
- 파형 수준 손실을 직접 최적화함으로써 위상 불일치를 최소화하고, 마스크 추정 단계와 위상 재구성 단계가 상호 보완적으로 학습되도록 만든 점이 가장 큰 혁신이다.
- 제안된 활성화 함수는 마스크가 1을 초과할 수 있음을 인정함으로써, 기존의 ‘마스크는 0~1’이라는 제한을 깨고 더 풍부한 스펙트럼 정보를 활용한다.
- 향후 연구에서는 더 깊은 네트워크 구조, 다른 위상 재구성 알고리즘(예: 복소 마스크 예측)과의 결합, 그리고 실시간 처리 가능성을 위한 경량화 등을 탐색할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기