All-but-the-Top: Simple and Effective Postprocessing for Word Representations
Real-valued word representations have transformed NLP applications; popular examples are word2vec and GloVe, recognized for their ability to capture linguistic regularities. In this paper, we demonstrate a {\em very simple}, and yet counter-intuitive…
Authors: Jiaqi Mu, Suma Bhat, Pramod Viswanath
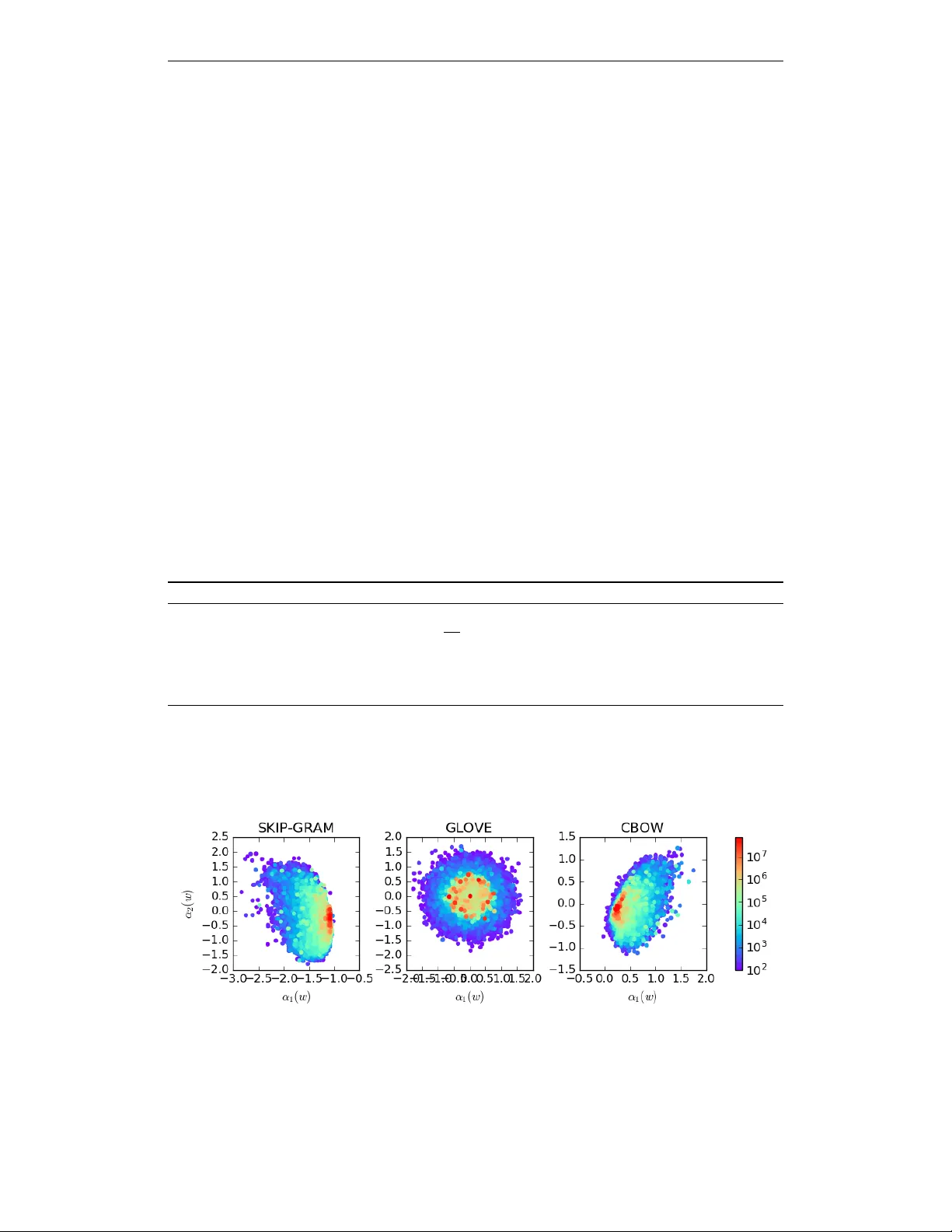
Published as a conference paper at ICLR 2018 A L L - B U T - T H E - T O P : S I M P L E A N D E FF E C T I V E P O S T - P R O C E S S I N G F O R W O R D R E P R E S E N T A T I O N S Jiaqi Mu, Pramod V iswanath Univ ersity of Illinois at Urbana Champaign {jiaqimu2, pramodv}@illinois.edu A B S T R A C T Real-valued word representations hav e transformed NLP applications; popular examples are word2v ec and GloV e, recognized for their ability to capture linguistic regularities. In this paper , we demonstrate a very simple , and yet counter-intuiti ve, postprocessing technique – eliminate the common mean vector and a few top dominating directions from the word v ectors – that renders off-the-shelf represen- tations even str onger . The postprocessing is empirically v alidated on a v ariety of lexical-le vel intrinsic tasks (word similarity , concept categorization, word analogy) and sentence-lev el tasks (semantic textural similarity and text classification) on multiple datasets and with a variety of representation methods and hyperparameter choices in multiple languages; in each case, the processed representations are consistently better than the original ones. 1 I N T R O D U C T I O N W ords and their interactions (as sentences) are the basic units of natural language. Although words are readily modeled as discrete atomic units, this is unable to capture the relation between the words. Recent distributional real-v alued representations of words (examples: word2vec, GloV e) hav e transformed the landscape of NLP applications – for instance, text classification (Socher et al., 2013b; Maas et al., 2011; Kim, 2014), machine translation (Sutsk ev er et al., 2014; Bahdanau et al., 2014) and knowledge base completion (Bordes et al., 2013; Socher et al., 2013a). The success comes from the geometry of the representations that ef ficiently captures linguistic regularities: the semantic similarity of words is well captured by the similarity of the corresponding vector representations. A variety of approaches have been proposed in recent years to learn the w ord representations: Collobert et al. (2011); T urian et al. (2010) learn the representations via semi-supervised learning by jointly training the language model and do wnstream applications; Bengio et al. (2003); Mikolo v et al. (2010); Huang et al. (2012) do so by fitting the data into a neural network language model; Mikolo v et al. (2013); Mnih & Hinton (2007) by log-linear models; and Dhillon et al. (2012); Pennington et al. (2014); Levy & Goldber g (2014); Stratos et al. (2015); Arora et al. (2016) by producing a low- dimensional representation of the cooccurrence statistics. Despite the wide disparity of algorithms to induce word representations, the performance of se veral of the recent methods is roughly similar on a variety of intrinsic and e xtrinsic e valuation testbeds. In this paper , we find that a simple processing renders the off-the-shelf existing representations e ven str onger . The proposed algorithm is moti vated by the follo wing observ ation. Observation Every representation we tested, in many languages, has the following properties: • The word representations hav e non-zer o mean – indeed, word vectors share a large common vector (with norm up to a half of the a verage norm of word v ector). • After remo ving the common mean v ector , the representations are far fr om isotropic – indeed, much of the ener gy of most word v ectors is contained in a very lo w dimensional subspace (say , 8 dimensions out of 300). Implication Since all words share the same common vector and ha ve the same dominating direc- tions, and such vector and directions strongly influence the word representations in the same w ay , we 1 Published as a conference paper at ICLR 2018 propose to eliminate them by: (a) remo ving the nonzero mean vector from all word v ectors, ef fec- ti vely reducing the energy; (b) projecting the representations away from the dominating D directions, effecti v ely reducing the dimension. Experiments suggest that D depends on the representations (for example, the dimension of the representation, the training methods and their specific h yperparameters, the training corpus) and also depends on the downstream applications. Nev ertheless, a rule of thumb of choosing D around d/ 100 , where d is the dimension of the word representations, works uniformly well across multiple languages and multiple representations and multiple test scenarios. W e emphasize that the proposed postprocessing is counter intuitive – typically denoising by dimen- sionality reduction is done by eliminating the weakest directions (in a singular value decomposition of the stacked word v ectors), and not the dominating ones. Y et, such postprocessing yields a “purified” and more “isotropic” word representation as seen in our elaborate experiments. Experiments By postprocessing the word representation by eliminating the common parts, we find the processed word representations to capture stronger linguistic re gularities. W e demonstrate this quantitati vely , by comparing the performance of both the original word representations and the processed ones on three canonical lexical-le vel tasks: • wor d similarity task tests the extent to which the representations capture the similarity between two words – the processed representations are consistently better on se ven dif ferent datasets, on av erage by 1.7%; • concept cate gorization task tests the extent to which the clusters of word representations capture the word semantics – the processed representations are consistently better on three different datasets, by 2.8%, 4.5% and 4.3%; • wor d analogy task tests the extent to which the dif ference of two representations captures a latent linguistic relation – again, the performance is consistently improv ed (by 0.5% on semantic analogies, 0.2% on syntactic analogies and 0.4% in total). Since part of the dominant components are inherently canceled due to the subtraction operation while solving the analogy , we posit that the performance improvement is not as pronounced as earlier . Extrinsic e valuations pro vide a way to test the goodness of representations in specific do wnstream tasks. W e ev aluate the effect of postprocessing on a standardized and important e xtrinsic ev aluation task on sentence modeling: semantic te xtual similarity task – where we represent a sentence by its av eraged word v ectors and score the similarity between a pair of sentences by the cosine similarity between the corresponding sentence representation. Postprocessing improves the performance consistently and significantly ov er 21 different datasets (a verage impro vement of 4%). W ord representations have been particularly successful in NLP applications in volving supervised- learning, especially in conjunction with neural network architecture. Indeed, we see the power of postprocessing in an experiment on a standard te xt classification task using a well established con voluntional neural netw ork (CNN) classifier (Kim, 2014) and three RNN classifiers (with v anilla RNN, GR U (Chung et al., 2015) and LSTM Gref f et al. (2016) as recurrent units). Across two dif ferent pre-trained word vectors, fi ve datasets and four dif ferent architectures, the performance with processing improv es on a majority of instances (34 out of 40) by a good mar gin (2.85% on average), and the two performances with and without processing are comparable in the remaining ones. Related W ork. Our work is directly related to word representation algorithms, most of which have been elaborately cited. Aspects similar to our postprocessing algorithm hav e appeared in specific NLP contexts very recently in (Sahlgren et al., 2016) (centering the mean) and (Arora et al., 2017) (nulling aw ay only the first principal component). Although there is a superficial similarity between our w ork and (Arora et al. 2017), the nulling directions we take and the one they take are fundamentally dif ferent. Specifically , in Arora et al. (2017), the first dominating v ector is *dataset-specific*, i.e., they first compute the sentence representation for the entire semantic textual similarity dataset, then e xtract the top direction from those sentence representations and finally project the sentence representation away from it. By doing so, the top direction will inherently encode the common information across the entire dataset, the top direction for the "headlines" dataset may encode common information about ne ws articles while the top direction for "T witter’15" may encode the common information about tweets. In contrast, our dominating vectors are o ver the entire v ocabulary of the language. 2 Published as a conference paper at ICLR 2018 More generally , the idea of remo ving the top principal components has been studied in the context of positive-valued, high-dimensional data matrix analysis (Bullinaria & Levy, 2012; Price et al., 2006). Bullinaria & Levy (2012) posits that the highest variance components of the cooccurrence matrix are corrupted by information other than lexical semantics, thus heuristically justifying the remov al of the top principal components. A similar idea appears in the context of population matrix analysis (Price et al., 2006), where the entries are also all positiv e. Our postprocessing operation is on dense low-dimensional representations (with both positi v e and negati ve entries). W e posit that the postprocessing operation makes the representations more “isotropic” with stronger self-normalization properties – discussed in detail in Section 2 and Appendix A. Our main point is that this isotropy condition can be e xplicitly enforced to come up with ne w embedding algorithms (of which our proposed post-processing is a simple and practical version). 2 P O S T P R O C E S S I N G W e test our observ ations on various word representations: four publicly av ailable word representations (WORD2VEC 1 (Mikolov et al., 2013) trained using Google News, GLO VE 2 (Pennington et al., 2014) trained using Common Crawl, RAND-W ALK (Arora et al., 2016) trained using Wikipedia and TSCCA 3 trained using English Giga word) and two self-trained word representations using CBO W and Skip-gram (Mikolov et al., 2013) on the 2010 W ikipedia corpus from (Al-Rfou et al., 2013). The detailed statistics for all representations are listed in T able 1. For completeness, we also consider the representations on other languages: a detailed study is provided in Appendix C.2. Language Corpus dim vocab size a vg. k v ( w ) k 2 k µ k 2 WORD2VEC English Google News 300 3,000,000 2.04 0.69 GLO VE English Common Crawl 300 2,196,017 8.30 3.15 RAND-W ALK English W ikipedia 300 68, 430 2.27 0.70 CBO W English W ikipedia 300 1,028,961 1.14 0.29 Skip-Gram English W ikipedia 300 1,028,961 2.32 1.25 T able 1: A detailed description for the embeddings in this paper . 1 0 0 1 0 1 1 0 2 1 0 3 index 0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 0.040 0.045 variance ratio GLOVE RAND_WALK WORD2VEC CBOW SKIP-GRAM Figure 1: The decay of the normalized singular v alues of word representation. Let v ( w ) ∈ R d be a word representation for a gi ven w ord w in the vocab ulary V . W e observe the following tw o phenomena in each of the word representations listed abov e: • { v ( w ) : w ∈ V } are not of zero-mean: i.e., all v ( w ) share a non-zero common vector , v ( w ) = ˜ v ( w ) + µ, where µ is the av erage of all v ( w ) ’ s, i.e., µ = 1 / |V | P w ∈V v ( w ) . The norm of µ is approximately 1/6 to 1/2 of the av erage norm of all v ( w ) (cf. T able 1). • { ˜ v ( w ) : w ∈ V } are not isotropic: Let u 1 , ..., u d be the first to the last components recov ered by the principal component analysis (PCA) of { ˜ v ( w ) : w ∈ V } , and σ 1 , ..., σ d be the corresponding normalized variance ratio. Each ˜ v ( w ) can be written as a linear combinations of u : ˜ v ( w ) = P d i =1 α i ( w ) u i . As shown in Figure 1, we observe that σ i decays near exponentially for small values of i and remains roughly constant over the later ones. This suggests there exists D such that α i α j for all i ≤ D and j D ; from Figure 1 one observes that D is roughly 10 with dimension d = 300 . Angular Asymmetry of Representations A modern understanding of word representations in- volv es either PMI-based (including w ord2vec (Mikolo v et al., 2010; Le vy & Goldber g, 2014) and GloV e (Pennington et al., 2014)) or CCA-based spectral factorization approaches. While CCA-based 1 https://code.google.com/archive/p/word2vec/ 2 https://github.com/stanfordnlp/GloVe 3 http://www.pdhillon.com/code.html 3 Published as a conference paper at ICLR 2018 spectral factorization methods ha ve long been understood from a probabilistic (i.e., generati ve model) view point (Bro wne, 1979; Hotelling, 1936) and recently in the NLP context (Stratos et al., 2015), a corresponding ef fort for the PMI-based methods has only recently been conducted in an inspired work (Arora et al., 2016). Arora et al. (2016) propose a generativ e model (named RAND-W ALK) of sentences, where e very word is parameterized by a d -dimensional vector . With a key postulate that the word vectors are angularly uniform (“isotropic"), the family of PMI-based word representations can be explained under the RAND-W ALK model in terms of the maximum likelihood rule. Our observ ation that word vectors learnt through PMI-based approaches are not of zero-mean and are not isotropic (c.f. Section 2) contradicts with this postulate. The isotropy conditions are relaxed in Section 2.2 of (Arora et al., 2016), but the match with the spectral properties observ ed in Figure 1 is not immediate. This contradiction is explicitly reslov ed by relaxing the constraints on the word vectors to directly fit the observed spectral properties. The relaxed conditions are: the word vectors should be isotropic around a point (whose distance to the origin is a small fraction of the average norm of w ord vectors) lying on a lo w dimensional subspace. Our main result is to show that e ven with this enlarged parameter-space, the maximum likelihood rule continues to be close to the PMI-based spectral factorization methods. A brief summary of RAND-W ALK, and the mathematical connection between our work and theirs, are explored in detail in Appendix A. 2 . 1 A L G O R I T H M Since all word representations share the same common vector µ and ha ve the same dominating directions and such v ector and directions strongly influence the w ord representations in the same w ay , we propose to eliminate them, as formally achiev ed as Algorithm 1. Algorithm 1: Postprocessing algorithm on word representations. Input : W ord representations { v ( w ) , w ∈ V } , a threshold parameter D , 1 Compute the mean of { v ( w ) , w ∈ V } , µ ← 1 |V | P w ∈V v ( w ) , ˜ v ( w ) ← v ( w ) − µ 2 Compute the PCA components: u 1 , ..., u d ← PCA( { ˜ v ( w ) , w ∈ V } ) . 3 Preprocess the representations: v 0 ( w ) ← ˜ v ( w ) − P D i =1 u > i v ( w ) u i Output : Processed representations v 0 ( w ) . Significance of Nulled V ectors Consider the representation of the words as viewed in terms of the top D PCA coefficients α ` ( w ) , for 1 ≤ ` ≤ D . W e find that these fe w coef ficients encode the fr equency of the word to a significant de gree; Figure 2 illustrates the relation between the ( α 1 ( w ) , α 2 ( w )) and the unigram probabilty p ( w ) , where the correlation is geometrically visible. Figure 2: The top two PCA directions (i.e, α 1 ( w ) and α 2 ( w ) ) encode frequency . Discussion In our proposed processing algorithm, the number of components to be nulled, D , is the only hyperparameter that needs to be tuned. W e find that a good rule of thumb is to choose D approximately to be d/ 100 , where d is the dimension of a w ord representation. This is empirically justified in the e xperiments of the follo wing section where d = 300 is standard for published word representations. W e trained word representations for higher values of d using the WORD2VEC and 4 Published as a conference paper at ICLR 2018 GLO VE algorithms and repeated these experiments; we see corresponding consistent improv ements due to postprocessing in Appendix C. 2 . 2 P O S T P R O C E S S I N G A S A “ R O U N D I N G ” T O W A R D S I S O T RO P Y The idea of isotropy comes from the partition function defined in (Arora et al., 2016), Z ( c ) = X w ∈V exp c > v ( w ) , where Z ( c ) should approximately be a constant with any unit vector c (c.f. Lemma 2.1 in (Arora et al., 2016)). Hence, we mathematically define a measure of isotropy as follows, I ( { v ( w ) } ) = min k c k =1 Z ( c ) max k c k =1 Z ( c ) , (1) where I ( { v ( w ) } ) ranges from 0 to 1, and I ( { v ( w ) } ) closer to 1 indicates that { v ( w ) } is more isotropic. The intuition behind our postprocessing algorithm can also be motiv ated by letting I ( { v ( w ) } ) → 1 . Let V be the matrix stacked by all word vectors, where the rows correspond to word vectors, and 1 |V | be the |V | -dimensional vectors with all entries equal to one, Z ( c ) can be equiv alently defined as follows, Z ( c ) = |V | + 1 | V | > V c + 1 2 c > V > V c + ∞ X k =3 1 k ! X w ∈V ( c > v ( w )) k . I ( { v ( w ) } ) is, therefore, can be very coar sely approximated by , • A first order approximation : I ( { v ( w ) } ) ≈ |V | + min k c k =1 1 > |V | V c |V | + max k c k =1 1 > |V | V c = |V | − k 1 > |V | V k |V | + k 1 > |V | V k . Letting I ( { v ( w ) } ) = 1 yields k 1 > |V | V k = 0 , which is equi v alent to P w ∈V v ( w ) = 0 . The intuition behind the first order approximation matches with the first step of the proposed algorithm, where we enforce v ( w ) to ha ve a zero mean. • A second order approximation : I ( { v ( w ) } ) ≈ |V | + min k c k =1 1 > |V | V c + min k c k =1 1 2 c > V > V c |V | + max k c k =1 1 > |V | V c + max k c k =1 1 2 c > V > V c = |V | − k 1 > |V | V k + 1 2 σ 2 min |V | + k 1 > |V | V k + 1 2 σ 2 max , where σ min and σ max are the smallest and largest singular v alue of V , respectiv ely . Letting I ( { v ( w ) } ) = 1 yields k 1 > |V | V k = 0 and σ min = σ max . The fact that σ min = σ max suggests the spectrum of v ( w ) ’ s should be flat. The second step of the proposed algorithm remov es the highest singular values, and therefore e xplicitly flatten the spectrum of V . Empirical V erification Indeed, we empirically validate the effect of postprocessing of on I ( { v ( w ) } ) . Since there is no closed-form solution for arg max k c k =1 Z ( c ) or arg min k c k =1 Z ( c ) , and it is impossible to enumerate all c ’ s, we estimate the measure by , I ( { v ( w ) } ) ≈ min c ∈ C Z ( c ) max c ∈ C Z ( c ) , where C is the set of eigen vectors of V > V . The value of I ( { v ( w ) } ) for the original vectors and processed ones are reported in T able 2, where we can observe that the degree of isotropy vastly increases in terms of this measure. 5 Published as a conference paper at ICLR 2018 before after WORD2VEC 0.7 0.95 GLO VE 0.065 0.6 T able 2: Before-After on the measure of isotropy . A formal way to verify the isotropy property is to directly check if the “self-normalization" property (i.e., Z ( c ) is a constant, independent of c (Andreas & Klein, 2015)) holds more strongly . Such a v ali- dation is seen diagrammatically in Figure 3 where we randomly sampled 1,000 c ’ s as (Arora et al., 2016). 0.80 0.85 0.90 0.95 1.00 1.05 1.10 1.15 1.20 p a r t i t i o n f u n c t i o n Z ( c ) 0 200 400 600 800 1000 frequency before after (a) word2v ec 0.7 0.8 0.9 1.0 1.1 1.2 1.3 p a r t i t i o n f u n c t i o n Z ( c ) 0 200 400 600 800 1000 frequency before after (b) GloV e Figure 3: The histogram of Z ( c ) for 1,000 randomly sampled vectors c of unit norm, where x -axis is normalized by the mean of all values and D = 2 for GLO VE and D = 3 for WORD2VEC. 3 E X P E R I M E N T S Giv en the popularity and widespread use of WORD2VEC (Mikolov et al., 2013) and GLO VE (Pennington et al., 2014), we use their publicly av ailable pre-trained reprepsentations in the follo wing experiments. W e choose D = 3 for WORD2VEC and D = 2 for GLO VE. The key underlying principle behind word representations is that similar words should hav e similar representations. Follo wing the tradition of ev aluating word representations (Schnabel et al., 2015; Baroni et al., 2014), we perform three canonical lexical-level tasks: (a) word similarity; (b) concept categorization; (c) word analogy; and one sentence-lev el task: (d) semantic textual similarity . The processed representations consistently improve performance on all three of them, and especially strongly on the first two. WORD2VEC GLO VE orig. proc. orig. proc. RG65 76.08 78.34 76.96 74.36 WS 68.29 69.05 73.79 76.79 R W 53.74 54.33 46.41 52.04 MEN 78.20 79.08 80.49 81.78 MT urk 68.23 69.35 69.29 70.85 SimLex 44.20 45.10 40 83 44.97 SimV erb 36.35 36.50 28.33 32.23 T able 3: Before-After results (x100) on word similarity task on sev en datasets. W ord Similarity The word similarity task is as follows: gi ven a pair of words, the algorithm as- signs a “similarity" score – if the pair of words are highly related then the score should also be high and vice versa. The algorithm is ev aluated in terms of Spearman’ s rank correlation compared to (a gold set of) human judgements. For this experiment, we use seven standard datasets: the first published RG65 dataset (Ruben- stein & Goodenough, 1965); the widely used W ordSim-353 (WS) dataset (Finkelstein et al., 2001) which contains 353 pairs of commonly used verbs and nouns; the rare-words (R W) dataset (Lu- ong et al., 2013) composed of rarely used words; the MEN dataset (Bruni et al., 2014) where the 3000 pairs of words are rated by crowdsourced participants; the MT urk dataset (Radinsky et al., 2011) where the 287 pairs of words are rated in terms of relatedness; the SimLex-999 (SimLex) dataset (Hill et al., 2016) where the score measures “genuine" similarity; and lastly the SimV erb-3500 (SimV erb) dataset (Gerz et al., 2016), a newly released lar ge dataset focusing on similarity of verbs. In our experiment, the algorithm scores the similarity between two words by the cosine similarity between the two corresponding word vectors ( CosSim( v 1 , v 2 ) = v > 1 v 2 / k v 1 kk v 2 k ). The detailed performance on the se ven datasets is reported in T able 3, where we see a consistent and signifi- cant performance improvement due to postprocessing, across all seven datasets. These statistics 6 Published as a conference paper at ICLR 2018 (av erage improvement of 2.3 %) suggest that by removing the common parts, the remaining word representations are able to capture stronger semantic relatedness/similarity between words. WORD2VEC GLO VE orig. proc. orig. proc. ap 54.43 57.72 64 .18 65.42 esslli 75.00 84.09 81.82 81.82 battig 71.97 81.71 86.59 86.59 T able 4: Before-After results (x100) on the categorization task. Concept Categorization This task is an indirect ev aluation of the similarity principle: gi ven a set of concepts, the algorithm needs to group them into different categories (for example, “bear” and “cat” are both animals and “city” and “country” are both related to districts). The clustering performance is then ev aluated in terms of purity (Manning et al., 2008) – the fraction of the total number of the objects that were classified correctly . W e conduct this task on three different datasets: the Almuhareb-Poesio (ap) dataset (Almuhareb, 2006) contains 402 concepts which fall into 21 categories; the ESSLLI 2008 Distributional Semantic W orkshop shared-task dataset (Baroni et al., 2008) that contains 44 concepts in 6 categories; and the Battig test set (Baroni & Lenci, 2010) that contains 83 words in 10 categories. Here we follow the setting and the proposed algorithm in (Baroni et al., 2014; Schnabel et al., 2015) – we cluster words (via their representations) using the classical k -Means algorithm (with fixed k ). Again, the processed vectors perform consistently better on all three datasets (with a verage improv ement of 2.5%); the full details are in T able 4. WORD2VEC GLO VE orig. proc. orig. proc. syntax 73.46 73.50 74.95 75.40 semantics 72.28 73.36 79.22 79.25 all 72.93 73.44 76.89 77.15 T able 5: Before-After results (x100) on the word analogy task. W ord Analogy The analogy task tests to what extent the w ord representations can encode latent linguistic relations between a pair of words. Gi ven three words w 1 , w 2 , and w 3 , the analogy task re- quires the algorithm to find the word w 4 such that w 4 is to w 3 as w 2 is to w 1 . W e use the analogy dataset introduced in (Mikolov et al., 2013). The dataset can be di vided into two parts: (a) the semantic part containing around 9k questions, focusing on the latent semantic relation between pairs of words (for example, what is to Chicago as T exas is to Houston); and (b) the syntatic one containing roughly 10.5k questions, focusing on the latent syntatic relation between pairs of words (for example, what is to “amazing” as “apprently” is to “apparent”). In our setting, we use the original algorithm introduced in (Mikolo v et al., 2013) to solve this problem, i.e., w 4 is the word that maximize the cosine similarity between v ( w 4 ) and v ( w 2 ) − v ( w 1 ) + v ( w 3 ) . The av erage performance on the analogy task is provided in T able 5 (with a detailed performance provided in T able 19 in Appendix D). It can be noticed that while postprocessing continues to improv e the performance, the impro vement is not as pronounced as earlier . W e hypothesize that this is because the mean and some dominant components get canceled during the subtraction of v ( w 2 ) from v ( w 1 ) , and therefore the effect of postprocessing is less rele v ant. WORD2VEC GLO VE orig. proc. orig. proc. 2012 57.22 57.67 48.27 54.06 2013 56.81 57.98 44.83 57.71 2014 62.89 63.30 51.11 59.23 2015 62.74 63.35 47.23 57.29 SICK 70.10 70 20 65.14 67.85 all 60.88 61.45 49.19 56.76 T able 6: Before-After results (x100) on the semantic textual similarity tasks. Semantic T extual Similarity Extrinsic e v alua- tions measure the contrib ution of a word representa- tion to specific downstream tasks; below , we study the effect of postprocessing on a standard sentence modeling task – semantic textual similarity (STS) which aims at testing the degree to which the algo- rithm can capture the semantic equi v alence between two sentences. For each pair of sentences, the algo- rithm needs to measure ho w similar the tw o sentences are. The degree to which the measure matches with human judgment (in terms of Pearson correlation) is an index of the algorithm’ s performance. W e test the word representations on 20 textual similarity datasets 7 Published as a conference paper at ICLR 2018 from the 2012-2015 SemEval STS tasks (Agirre et al., 2012; 2013; 2014; 2015), and the 2012 SemEval Semantic Related task (SICK) (Marelli et al., 2014). Representing sentences by the av erage of their constituent word representations is surprisingly effecti v e in encoding the semantic information of sentences (W ieting et al., 2015; Adi et al., 2016) and close to the state-of-the-art in these datasets. W e follow this rubric and represent a sentence s based on its av eraged word representation, i.e., v ( s ) = 1 | s | P w ∈ s v ( w ) , and then compute the similarity between two sentences via the cosine similarity between the two representations. The av erage performance of the original and processed representations is itemized in T able 6 (with a detailed performance in T able 20 in Appendix E) – we see a consistent and significant improv ement in performance because of postprocessing (on av erage 4 % improv ement). 4 P O S T P R O C E S S I N G A N D S U P E RV I S E D C L A S S I FI C A T I O N Supervised downstream NLP applications ha ve greatly impro ved their performances in recent years by combining the discriminati ve learning powers of neural networks in conjunction with the word representations. W e e valuate the performance of a v ariety of neural network architectures on a standard and important NLP application: text classification , with sentiment analysis being a particularly important and popular example. The task is defined as follows: giv en a sentence, the algorithm needs to decide which category it falls into. The categories can be either binary (e.g., positi ve/ne gativ e) or can be more fine-grained (e.g. very positi ve, positi ve, neutral, neg ativ e, and very ne gativ e). W e e valuate the word representations (with and without postprocessing) using four different neural network architectures (CNN, v anilla-RNN, GR U-RNN and LSTM-RNN) on fi ve benchmarks: (a) the movie re view (MR) dataset (Pang & Lee, 2005); (b) the subjectivity (SUBJ) dataset (Pang & Lee, 2004); (c) the TREC question dataset (Li & Roth, 2002); (d) the IMDb dataset (Maas et al., 2011); (e) the stanford sentiment treebank (SST) dataset (Socher et al., 2013a). A detailed description of these standard datasets, their training/test parameters and the cross validation methods adopted is in Appendix F. Specifically , we allow the parameter D (i.e., the number of nulled components) to vary between 0 and 4, and the best performance of the four neural network architectures with the now-standard CNN-based te xt classification algorithm (Kim, 2014) (implemented using tensorflow 4 ) is itemized in T able 7. The ke y observ ation is that the performance of postprocessing is better in a majority (34 out of 40) of the instances by 2.32% on a verage, and in the rest the instances the two performances (with and without postprocessing) are comparable. CNN vanilla-RNN GR U-RNN LSTM-RNN WORD2VEC GLO VE WORD2VEC GLOVE WORD2VEC GLO VE WORD2VEC GLO VE orig. proc. orig. proc. orig. proc. orig. proc. orig. proc. orig. proc. orig. proc. orig. proc. MR 70.80 71.27 71.01 71.11 74.95 74.01 71.14 72.56 77.86 78.26 74.98 75.13 75.69 77.34 72.02 71.84 SUBJ 87.14 87.33 86.98 87.25 82.85 87.60 81.45 87.37 90.96 91.10 91.16 91.85 90.23 90.54 90.74 90.82 TREC 87.80 89.00 87.60 89.00 80.60 89.20 85.20 89.00 91.60 92.40 91.60 93.00 88.00 91.20 85.80 91.20 SST 38.46 38.33 38.82 37.83 42.08 39.91 41.45 41.90 41.86 45.02 36.52 37.69 43.08 42.08 37.51 38.05 IMDb 86.68 87.12 87.27 87.10 50.15 53.14 52.76 76.07 82.96 83.47 81.50 82.44 81.29 82.60 79.10 81.33 T able 7: Before-After results (x100) on the text classification task using CNN (Kim, 2014) and v anilla RNN, GR U-RNN and LSTM-RNN. A further validation of the postprocessing operation in a variety of do wnstream applications (eg: named entity recognition, syntactic parsers, machine translation) and classification methods (e g: random forests, neural network architectures) is of acti ve research interest. Of particular interest is the impact of the postprocessing on the rate of conv ergence and generalization capabilities of the classifiers. Such a systematic study would entail a concerted and large-scale effort by the research community and is left to future research. Discussion All neural network architectures, ranging from feedforward to recurrent (either v anilla or GR U or LSTM), implement at least linear processing of hidden/input state vectors at each of their nodes; thus the postprocessing operation suggested in this paper can in principle be automatically “learnt” by the neural network, if such internal learning is in-line with the end-to-end training examples. Y et, in practice this is complicated due to limitations of optimization procedures (SGD) and sample 4 https://github.com/dennybritz/cnn- text- classification- tf 8 Published as a conference paper at ICLR 2018 noise. W e conduct a preliminary experiment in Appendix B and show that subtracting the mean (i.e., the first step of postprocessing) is “effecti v ely learnt" by neural networks within their nodes. 5 C O N C L U S I O N W e present a simple postprocessing operation that renders word representations e ven stronger , by eliminating the top principal components of all words. Such an simple operation could be used for word embeddings in do wnstream tasks or as intializations for training task-specific embeddings. Due to their popularity , we hav e used the published representations of WORD2VEC and GLO VE in En- glish in the main te xt of this paper; postprocessing continues to be successful for other representations and in multilingual settings – the detailed empirical results are tabulated in Appendix C. R E F E R E N C E S Y ossi Adi, Einat Kerman y , Y onatan Belinkov , Ofer Lavi, and Y oa v Goldberg. Fine-grained analysis of sentence embeddings using auxiliary prediction tasks. arXiv preprint , 2016. Eneko Agirre, Mona Diab, Daniel Cer, and Aitor Gonzalez-Agirre. Semev al-2012 task 6: A pilot on semantic textual similarity . In Pr oceedings of the F irst Joint Confer ence on Lexical and Computational Semantics-V olume 1: Pr oceedings of the main conference and the shar ed task, and V olume 2: Pr oceedings of the Sixth International W orkshop on Semantic Evaluation , pp. 385–393. Association for Computational Linguistics, 2012. Eneko Agirre, Daniel Cer , Mona Diab, Aitor Gonzalez-Agirre, and W eiwei Guo. sem 2013 shared task: Semantic textual similarity , including a pilot on typed-similarity . In In* SEM 2013: The Second Joint Confer ence on Lexical and Computational Semantics. Association for Computational Linguistics . Citeseer , 2013. Eneko Agirre, Carmen Banea, Claire Cardie, Daniel Cer , Mona Diab, Aitor Gonzalez-Agirre, W eiwei Guo, Rada Mihalcea, German Rigau, and Jan yce W iebe. Seme val-2014 task 10: Multilingual se- mantic textual similarity . In Pr oceedings of the 8th international workshop on semantic evaluation (SemEval 2014) , pp. 81–91, 2014. Eneko Agirre, Carmen Baneab, Claire Cardiec, Daniel Cerd, Mona Diabe, Aitor Gonzalez-Agirrea, W eiwei Guof, Inigo Lopez-Gazpioa, Montse Maritxalara, Rada Mihalceab, et al. Semev al-2015 task 2: Semantic textual similarity , english, spanish and pilot on interpretability . In Proceedings of the 9th international workshop on semantic evaluation (SemEval 2015) , pp. 252–263, 2015. Rami Al-Rfou, Bryan Perozzi, and Steven Skiena. Polyglot: Distributed word representations for multilingual nlp. arXiv preprint , 2013. Abdulrahman Almuhareb . Attributes in lexical acquisition . PhD thesis, Univ ersity of Essex, 2006. Jacob Andreas and Dan Klein. When and why are log-linear models self-normalizing? In HLT - N AACL , pp. 244–249, 2015. Sanjeev Arora, Y uanzhi Li, Y ingyu Liang, T engyu Ma, and Andrej Risteski. A latent variable model approach to pmi-based word embeddings. T ransactions of the Association for Computational Linguistics , 4:385–399, 2016. ISSN 2307-387X. URL https://transacl.org/ojs/ index.php/tacl/article/view/742 . Sanjeev Arora, Y ingyu Liang, and T engyu Ma. A simple b ut tough-to-beat baseline for sentence embeddings. In International Conference on Learning Repr esentations. , 2017. Dzmitry Bahdanau, Kyunghyun Cho, and Y oshua Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint , 2014. M Baroni, S Evert, and A Lenci. Bridging the gap between semantic theory and computational simulations: Proceedings of the esslli workshop on distrib utional lexical semantics. Hambur g, Germany: FOLLI , 2008. 9 Published as a conference paper at ICLR 2018 Marco Baroni and Alessandro Lenci. Distributional memory: A general framework for corpus-based semantics. Computational Linguistics , 36(4):673–721, 2010. Marco Baroni, Geor giana Dinu, and Germán Krusze wski. Don’t count, predict! a systematic comparison of context-counting vs. context-predicting semantic v ectors. In ACL (1) , pp. 238–247, 2014. Y oshua Bengio, Réjean Ducharme, Pascal V incent, and Christian Jauvin. A neural probabilistic language model. journal of machine learning r esear ch , 3(Feb):1137–1155, 2003. Antoine Bordes, Nicolas Usunier , Alberto Garcia-Duran, Jason W eston, and Oksana Y akhnenko. T ranslating embeddings for modeling multi-relational data. In Advances in Neural Information Pr ocessing Systems , pp. 2787–2795, 2013. Michael W Bro wne. The maximum-likelihood solution in inter-battery factor analysis. British Journal of Mathematical and Statistical Psyc hology , 32(1):75–86, 1979. Elia Bruni, Nam-Khanh T ran, and Marco Baroni. Multimodal distributional semantics. J. Artif . Intell. Res.(J AIR) , 49(1-47), 2014. John A Bullinaria and Joseph P Levy . Extracting semantic representations from word co-occurrence statistics: stop-lists, stemming, and svd. Behavior r esear ch methods , 44(3):890–907, 2012. José Camacho-Collados, Mohammad T aher Pilehvar , and Roberto Navigli. A framew ork for the construction of monolingual and cross-lingual word similarity datasets. In ACL (2) , pp. 1–7, 2015. Junyoung Chung, Caglar Gülçehre, K yunghyun Cho, and Y oshua Bengio. Gated feedback recurrent neural networks. In ICML , pp. 2067–2075, 2015. Ronan Collobert, Jason W eston, Léon Bottou, Michael Karlen, K oray Kavukcuoglu, and Pa vel Kuksa. Natural language processing (almost) from scratch. J ournal of Machine Learning Resear ch , 12 (Aug):2493–2537, 2011. Paramv eer Dhillon, Jordan Rodu, Dean Foster , and L yle Ungar . T wo step cca: A ne w spectral method for estimating vector models of words. arXiv pr eprint arXiv:1206.6403 , 2012. Lev Finkelstein, Evgeniy Gabrilo vich, Y ossi Matias, Ehud Ri vlin, Zach Solan, Gadi W olfman, and Eytan Ruppin. Placing search in context: The concept revisited. In Pr oceedings of the 10th international confer ence on W orld W ide W eb , pp. 406–414. A CM, 2001. Daniela Gerz, Iv an V uli ´ c, Felix Hill, Roi Reichart, and Anna K orhonen. Simverb-3500: A large-scale ev aluation set of v erb similarity . arXiv preprint , 2016. Klaus Greff, Rupesh K Sri v astav a, Jan K outník, Bas R Steunebrink, and Jürgen Schmidhuber . Lstm: A search space odyssey . IEEE transactions on neural networks and learning systems , 2016. Felix Hill, Roi Reichart, and Anna Korhonen. Simlex-999: Evaluating semantic models with (genuine) similarity estimation. Computational Linguistics , 2016. Harold Hotelling. Relations between two sets of variates. Biometrika , 28(3/4):321–377, 1936. Eric H Huang, Richard Socher, Christopher D Manning, and Andrew Y Ng. Improving word representations via global context and multiple word prototypes. In Pr oceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long P apers-V olume 1 , pp. 873–882. Association for Computational Linguistics, 2012. Y oon Kim. Conv olutional neural networks for sentence classification. arXiv pr eprint arXiv:1408.5882 , 2014. Beatrice Laurent and Pascal Massart. Adaptive estimation of a quadratic functional by model selection. Annals of Statistics , pp. 1302–1338, 2000. Omer Levy and Y oa v Goldberg. Neural word embedding as implicit matrix factorization. In Advances in neural information pr ocessing systems , pp. 2177–2185, 2014. 10 Published as a conference paper at ICLR 2018 Xin Li and Dan Roth. Learning question classifiers. In Pr oceedings of the 19th international confer- ence on Computational linguistics-V olume 1 , pp. 1–7. Association for Computational Linguistics, 2002. Thang Luong, Richard Socher , and Christopher D Manning. Better word representations with recursiv e neural networks for morphology . In CoNLL , pp. 104–113, 2013. Andrew L Maas, Raymond E Daly , Peter T Pham, Dan Huang, Andrew Y Ng, and Christopher Potts. Learning word vectors for sentiment analysis. In Pr oceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Languag e T echnologies-V olume 1 , pp. 142–150. Association for Computational Linguistics, 2011. Christopher D Manning, Prabhakar Ragha van, Hinrich Schütze, et al. Intr oduction to information r etrieval , v olume 1. Cambridge university press Cambridge, 2008. Marco Marelli, Stefano Menini, Marco Baroni, Luisa Benti vogli, Raf faella Bernardi, and Roberto Zamparelli. A sick cure for the ev aluation of compositional distributional semantic models. In LREC , pp. 216–223, 2014. T omas Mikolo v , Martin Karafiát, Lukas Burget, Jan Cernock ` y, and Sanjee v Khudanpur . Recurrent neural network based language model. In Interspeech , v olume 2, pp. 3, 2010. T omas Mikolo v , Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representa- tions in vector space. arXiv pr eprint arXiv:1301.3781 , 2013. Andriy Mnih and Geof frey Hinton. Three new graphical models for statistical language modelling. In Pr oceedings of the 24th international confer ence on Machine learning , pp. 641–648. A CM, 2007. Bo Pang and Lillian Lee. A sentimental education: Sentiment analysis using subjectivity summa- rization based on minimum cuts. In Pr oceedings of the 42nd annual meeting on Association for Computational Linguistics , pp. 271. Association for Computational Linguistics, 2004. Bo Pang and Lillian Lee. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. In Pr oceedings of the 43rd annual meeting on association for computational linguistics , pp. 115–124. Association for Computational Linguistics, 2005. Jeffre y Pennington, Richard Socher , and Christopher D Manning. Glove: Global v ectors for word representation. In EMNLP , volume 14, pp. 1532–43, 2014. Alkes L Price, Nick J P atterson, Robert M Plenge, Michael E W einblatt, Nancy A Shadick, and David Reich. Principal components analysis corrects for stratification in genome-wide association studies. Natur e genetics , 38(8):904–909, 2006. Kira Radinsky , Eugene Agichtein, Evgeniy Gabrilovich, and Shaul Markovitch. A word at a time: computing word relatedness using temporal semantic analysis. In Pr oceedings of the 20th international confer ence on W orld wide web , pp. 337–346. ACM, 2011. Herbert Rubenstein and John B Goodenough. Contextual correlates of synon ymy . Communications of the A CM , 8(10):627–633, 1965. Magnus Sahlgren, Amaru Cuba Gyllensten, Fredrik Espinoza, Ola Hamfors, Jussi Karlgren, Fredrik Olsson, Per Persson, Akshay V iswanathan, and Anders Holst. The gav agai li ving lexicon. In Nicoletta Calzolari (Conference Chair), Khalid Choukri, Thierry Declerck, Sara Goggi, Marko Grobelnik, Bente Maegaard, Joseph Mariani, Helene Mazo, Asuncion Moreno, Jan Odijk, and Stelios Piperidis (eds.), Pr oceedings of the T enth International Confer ence on Langua ge Resour ces and Evaluation (LREC 2016) , Paris, France, may 2016. European Language Resources Association (ELRA). ISBN 978-2-9517408-9-1. T obias Schnabel, Igor Labuto v , David Mimno, and Thorsten Joachims. Evaluation methods for unsupervised word embeddings. In Pr oc. of EMNLP , 2015. Richard Socher , Danqi Chen, Christopher D Manning, and Andre w Ng. Reasoning with neural tensor networks for kno wledge base completion. In Advances in Neural Information Pr ocessing Systems , pp. 926–934, 2013a. 11 Published as a conference paper at ICLR 2018 Richard Socher , Alex Perelygin, Jean Y W u, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. Recursiv e deep models for semantic compositionality ov er a sentiment treebank. In Pr oceedings of the confer ence on empirical methods in natural languag e pr ocessing (EMNLP) , volume 1631, pp. 1642. Citeseer , 2013b. Karl Stratos, Michael Collins, and Daniel Hsu. Model-based w ord embeddings from decompositions of count matrices. In Proceedings of A CL , pp. 1282–1291, 2015. Ilya Sutske ver , Oriol V inyals, and Quoc V Le. Sequence to sequence learning with neural networks. In Advances in neural information pr ocessing systems , pp. 3104–3112, 2014. Joseph T urian, Lev Ratino v , and Y oshua Bengio. W ord representations: a simple and general method for semi-supervised learning. In Proceedings of the 48th annual meeting of the association for computational linguistics , pp. 384–394. Association for Computational Linguistics, 2010. John W ieting, Mohit Bansal, K evin Gimpel, Karen Li vescu, and Dan Roth. From paraphrase database to compositional paraphrase model and back. arXiv preprint , 2015. T orsten Zesch and Iryna Gurevych. Automatically creating datasets for measures of semantic relatedness. In Pr oceedings of the W orkshop on Linguistic Distances , pp. 16–24. Association for Computational Linguistics, 2006. 12 Published as a conference paper at ICLR 2018 Appendix: All-b ut-the-T op: Simple and Effecti ve postprocessing for W ord Representations A A N G U L A R A S Y M M E T RY O F R E P R E S E N TA T I O N S A modern understanding of word representations inv olves either PMI-based (including word2vec (Mikolov et al., 2010; Le vy & Goldberg, 2014) and GloV e (Pennington et al., 2014)) or CCA-based spectral factorization approaches. While CCA-based spectral factorization methods ha ve long been understood from a probabilistic (i.e., generativ e model) vie w point (Browne, 1979; Hotelling, 1936) and recently in the NLP context (Stratos et al., 2015), a corresponding effort for the PMI-based methods has only recently been conducted in an inspired work (Arora et al., 2016). (Arora et al., 2016) propose a generati ve model (named RAND-W ALK) of sentences, where e very word is parameterized by a d -dimensional vector . With a key postulate that the word vectors are angularly uniform (“isotropic"), the family of PMI-based word representations can be explained under the RAND-W ALK model in terms of the maximum likelihood rule. Our observ ation that word vectors learnt through PMI-based approaches are not of zero-mean and are not isotropic (c.f. Section 2) contradicts with this postulate. The isotropy conditions are relaxed in Section 2.2 of (Arora et al., 2016), but the match with the spectral properties observ ed in Figure 1 is not immediate. In this section, we resolve this by explicitly relaxing the constraints on the word vectors to directly fit the observed spectral properties. The relaxed conditions are: the word vectors should be isotropic around a point (whose distance to the origin is a small fraction of the average norm of w ord vectors) lying on a lo w dimensional subspace. Our main result is to show that ev en with this enlarged parameter-space, the maximum likelihood rule continues to be close to the PMI-based spectral factorization methods. Formally , the model, the original constraints of (Arora et al., 2016) and the enlarged constraints on the w ord vectors are listed belo w: • A generative model of sentences : the word at time t , denoted by w t , is generated via a log-linear model with a latent discourse variable c t (Arora et al., 2016), i.e., p ( w t | c t ) = 1 Z ( c t ) exp c > t v ( w t ) , (2) where v ( w ) ∈ R d is the vector representation for a word w in the vocab ulary V , c t is the latent v ariable which forms a “slowly mo ving" random walk, and the partition function: Z ( c ) = P w ∈V exp c > v ( w ) . • Constraints on the word vectors : (Arora et al., 2016) suppose that there is a Bayesian priori on the word vectors: The ensemble of word vectors consists of i.i.d. draws generated by v = s · ˆ v , where ˆ v is from the spherical Gaussian distrib ution, and s is a scalar random variable. A deterministic version of this prior is discussed in Section 2.2 of (Arora et al., 2016), but part of these (relaxed) conditions on the w ord vectors are specifically meant for Theorem 4.1 and not the main theorem (Theorem 2.2). The geometry of the word representations is only ev aluated via the ratio of the quadratic mean of the singular values to the smallest one being small enough. This meets the relaxed conditions, but not sufficient to validate the proof approach of the main result (Theorem 2.2); what would be needed is that the ratio of the lar gest singular v alue to the smallest one be small. • Revised conditions : W e revise the Bayesian prior postulate (and in a deterministic fashion) formally as follo ws: there is a mean vector µ , D orthonormal vectors u 1 , . . . , u D (that are orthogonal and of unit norm), such that ev ery word v ector v ( w ) can be represented by , v ( w ) = µ + D X i =1 α i ( w ) u i + ˜ v ( w ) , (3) where µ is bounded, α i is bounded by A , D is bounded by D A 2 = o ( d ) , ˜ v ( w ) are statistically isotropic. By statistical isotropy , we mean: for high-dimensional rectangles R , 13 Published as a conference paper at ICLR 2018 1 |V | P w ∈V 1 ( ˜ v ( w ) ∈ R ) → R R f ( ˜ v ) d ˜ v , as |V | → ∞ , where f is an angle-independent pdf, i.e., f ( ˜ v ) is a function of k ˜ v k . The revised postulate dif fers from the original one in two ways: (a) it imposes a formal deterministic constraint on the word vectors; (b) the revised postulate allo ws the word vectors to be angularly asymmetric: as long as the energy in the direction of u 1 ,. . . , u D is bounded, there is no constraint on the coefficients. Indeed, note that there is no constraint on ˜ v ( w ) to be orthogonal to u 1 , . . . u D . Empirical V alidation W e can verify that the enlarged conditions are met by the existing word representations. Specifically , the natural choice for µ is the mean of the word representations and u 1 . . . u D are the singular vectors associated with the top D singular values of the matrix of word vectors. W e pick D = 20 for WORD2VEC and D = 10 for GLO VE, and the corresponding value of D A 2 for WORD2VEC and GLO VE vectors are both roughly 40, respectively; both v alues are small compared to d = 300 . 1 0 1 1 0 2 index 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 variance ratio GLOVE WORD2VEC random Figure 4: Spectrum of the published WORD2VEC and GLO VE and random Gaussian matrices, ignoring the top D components; D = 10 for GLO VE and D = 20 for W ORD2VEC. This leav es us to check the statistical isotropy of the “remaining" vectors ˜ v ( w ) for words w in the vocab ulary . W e do this by plotting the remaining spectrum (i.e. the ( D + 1) -th, ..., 300th singular values) for the published WORD2VEC and GLO VE vectors in Figure 4. As a comparison, the empirical spectrum of a random Gaussian matrix is also plotted in Figure 4. W e see that both spectra are flat (since the vocab ulary size is much larger than the dimension d = 300 ). Thus the postprocessing operation can also be viewed as a w ay of making the vectors “more isotropic”. Mathematical Contribution Under the revised postulate, we sho w that the main theorem in (Arora et al., 2016) (c.f. Theorem 2.2) still holds. Formally: Theorem A.1 Suppose the wor d vectors satisfy the constr aints. Then PMI( w 1 , w 2 ) def = log p ( w 1 , w 2 ) p ( w 1 ) p ( w 2 ) → v ( w 1 ) > v ( w 2 ) d , as |V | → ∞ , (4) wher e p ( w ) is the unigram distribution induced fr om the model (2) , and p ( w 1 , w 2 ) is the pr obability that two wor ds w 1 and w 2 occur with each other within distance q . The proof is in Appendix G. Theorem A.1 suggests that the RAND-W ALK generativ e model and its properties proposed by (Arora et al., 2016) can be generalized to a broader setting (with a relaxed restriction on the geometry of word representations) – rele v antly , this relaxation on the geometry of word representations is empirically satisfied by the vectors learnt as part of the maximum lik elihood rule. B N E U R A L N E T W O R K S L E A R N T O P O S T P R O C E S S Every neural network f amily posseses the ability to conduct linear processing inside their nodes; this includes feedforward and recurrent and conv olutional neural network models. Thus, in principle, the postprocessing operation can be “learnt and implemented" within the parameters of the neural network. On the other hand, due to the large number of parameters within the neural network, it 14 Published as a conference paper at ICLR 2018 is unclear how to verify such a process, ev en if it were learnt (only one of the layers might be implementing the postprocessing operation or via a combination of multiple effects). T o address this issue, we have adopted a comparative approach in the rest of this section. The comparativ e approach inv olves adding an extra layer interposed in between the inputs (which are word vectors) and the rest of the neural network. This extra layer inv olves only linear processing. Next we compare the results of the final parameters of the extra layer (trained jointly with the rest of tne neural network parameters, using the end-to-end training examples) with and without preprocessing of the word v ectors. Such a comparativ e approach allo ws us to separate the ef fect of the postprocessing operation on the word vectors from the complicated “semantics” of the neural network parameters. softmax n onlinear - unit n onlinear - unit n onlinear - unit l inear- bias v ( w 1 ) v ( w 2 ) v ( w T ) … … v ( w 1 ) b v ( w 2 ) b v ( w T ) b h 1 h 2 h T Figure 5: T ime-expanded RNN architecture with an appended layer in volving linear bias. vanilla GR U LSTM W . G. W . G. W . G. MR 82.07 49.23 81.35 47.63 77.95 44.92 SUBJ 84.02 49.94 83.15 50.60 83.39 48.95 TREC 81.68 52.99 82.68 50.42 80.80 46.77 SST 79.64 46.59 78.06 43.21 77.72 42.82 IMDb 93.48 66.37 94.49 55.24 87.27 46.74 Figure 6: The cosine similarity (x100) between b proc . + µ and b orig . , where W . and G. stand for WORD2VEC and GLO VE respectively . Experiment W e construct a modified neural network by e xplicitly adding a “postprocessing unit" as the first layer of the RNN architecture (as in Figure 5, where the appended layer is used to test the first step (i.e., remov e the mean vector)) of the postprocessing algorithm. In the modified neural network, the input word vectors are now v ( w ) − b instead of v ( w ) . Here b is a bias vector trained jointly with the rest of the neural network parameters. Note that this is only a relabeling of the parameters from the perspectiv e of the RNN architecture: the nonlinear activ ation function of the node is no w operated on A ( v ( w ) − b ) + b 0 = Av ( w ) + ( b 0 − Ab ) instead of the previous Av ( w ) + b 0 . Let b proc . and b orig . be the inferred biases when using the processed and original word representations, respecti vely . W e itemize the cosine similarity between b proc . + µ and b orig . in T able 6 for the 5 dif ferent datasets and 3 dif ferent neural network architectures. In each case, the cosine similarity is remarkably lar ge (on av erage 0.66, in 300 dimensions) – in other words, trained neural networks implicitly postprocess the word vectors nearly exactly as we proposed. This agenda is successfully implemented in the context of v erifying the remov al of the mean vector . The second step of our postprocessing algorithm (i.e., nulling away from the top principal components) is equi valent to applying a projection matrix P = I − P D i =1 u i u > i on the word v ectors, where u i is the i -th principal component and D is the number of the removed directions. A comparativ e analysis effort for the second step (nulling the dominant PCA directions) is the following. Instead of applying a bias term b , we multiply by a matrix Q to simulate the projection operation. The input word vectors are no w Q orig . v ( w ) instead of v ( w ) for the original word vectors, and Q proc . P v ( w ) instead of P v ( w ) for the processed vectors. T esting the similarity between Q orig . P and Q proc . , allows us to verify if the neural network learns to conduct the projection operation as proposed. In our experiment, we found that such a result cannot be inferred. One possibility is that there are too many parameters in both Q proc . and Q orig . , which adds randomness to the experiment. Alternatively , the neural network weights may not be able to learn the second step of the postprocessing operation (indeed, in our experiments postprocessing significantly boosted end-performance of neural network architectures). A more careful experimental setup to test whether the second step of the postprocessing operation is learnt is left as a future research direction. 15 Published as a conference paper at ICLR 2018 C E X P E R I M E N T S O N V A R I O U S R E P R E S E N TA T I O N S In the main text, we have reported empirical results for two published word representations: WORD2VEC and GLO VE, each in 300 dimensions. In this section, we report the results of the same experiments in a v ariety of other settings to sho w the generalization capability of the postprocessing operation: representations trained via WORD2VEC and GLO VE algorithms in dimensions other than 300, other representations algorithms (specifically TSCCA and RAND-W ALK) and in multiple languages. C . 1 S TA T I S T I C S O F M U LT I L I N G U A L W O R D R E P R E S E N TA T I O N S W e use the publicly av ailable TSCCA representations (Dhillon et al., 2012) on German, French, Spanish, Italian, Dutch and Chinese. The detailed statistics can be found in T able 8 and the decay of their singular values are plotted in Figure 7. Language Corpus dim vocab size a vg. k v ( w ) k 2 k µ k 2 TSCCA-En English Gigaw ords 200 300,000 4.38 0.78 TSCCA-De German Newswire 200 300,000 4.52 0.79 TSCCA-Fr French Giga word 200 300,000 4.34 0.81 TSCCA-Es Spanish Gigaword 200 300,000 4.17 0.79 TSCCA-It Italian Newswire+W iki 200 300,000 4.34 0.79 TSCCA-Nl Dutch Newswire+W iki 200 300,000 4.46 0.72 TSCCA-Zh Chinese Giga word 200 300,000 4.51 0.89 T able 8: A detailed description for the TSCCA embeddings in this paper . 1 0 0 1 0 1 1 0 2 1 0 3 index 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 variance ratio TSCCA-De TSCCA-En TSCCA-Es TSCCA-Fr TSCCA-It TSCCA-Nl TSCCA-Zh Figure 7: The decay of the normalized singular values of multilingual word representation. C . 2 M U LT I L I N G U A L G E N E R A L I Z A T I O N In this section, we perform the word similarity task with the original and the processed TSCCA word representations in German and Spanish on three German similarity datasets (GUR65 – a German version of the RG65 dataset, GUR350, and ZG222 in terms of relatedness) (Zesch & Gure vych, 2006) and the Spanish version of RG65 dataset (Camacho-Collados et al., 2015). The choice of D is 2 for both German and Spanish. The experiment setup and the similarity scoring algorithm are the same as those in Section 3. The detailed experiment results are provided in T able 9, from which we observe that the processed repre- sentations are consistently better than the original ones. This provides e vidence to the generalization capabilities of the postprocessing operation to multiple languages (similarity datasets in Spanish and German were the only ones we could locate). C . 3 G E N E R A L I Z A T I O N T O D I FF E R E N T R E P R E S E N TA T I O N A L G O R I T H M S Giv en the popularity and widespread use of WORD2VEC (Mikolov et al., 2013) and GLO VE (Pennington et al., 2014), the main text has solely focused on their published publicly avalable 16 Published as a conference paper at ICLR 2018 language TSCCA orig. proc. RG65 Spanish 60.33 60.37 GUR65 German 61.75 64.39 GUR350 German 44.91 46.59 ZG222 German 30.37 32.92 T able 9: Before-After results (x100) on the word similarity task in multiple languages. 300-dimension representations. In this section, we show that the proposed postprocessing algorithm generalizes to other representation methods. Specifically , we demonstrate this on RAND-W ALK (obtained via personal communication) and TSCCA (publicly av ailable) on all the e xperiments of Section 3. The choice of D is 2 for both RAND-W ALK and TSCCA. In summary , the performance improv ements on the similarity task, the concept categorization task, the analogy task, and the semantic textual similarity dataset are on av erage 2.23%, 2.39%, 0.11% and 0.61%, respectiv ely . The detailed statistics are provided in T able 10, T able 11, T able 12 and T able 13, respectiv ely . These results are a testament to the generalization capabilities of the postprocessing algorithm to other representation algorithms. RAND-W ALK TSCCA orig. proc. orig. proc. RG65 80.66 82.96 47.53 47.67 WS 65.89 74.37 54.21 54.35 R W 45.11 51.23 43.96 43.72 MEN 73.56 77.22 65.48 65.62 MT urk 64.35 66.11 59.65 60.03 SimLex 34.05 36.55 34.86 34.91 SimV erb 16.05 21.84 23.79 23.83 T able 10: Before-After results (x100) on the word similarity task on se ven datasets. RAND-W ALK TSCCA orig. proc. orig. proc. ap 59.83 62.36 60.00 63.42 esslli 72.73 72.73 68.18 70.45 battig 75.73 81.82 70.73 70.73 T able 11: Before-After results (x100) on the categorization task. RAND-W ALK TSCCA orig. proc. orig. proc. syn. 60.39 60.48 37.72 37.80 sem. 83.55 83.82 14.54 14.55 all 70.50 70.67 27.30 27.35 T able 12: Before-After results (x100) on the word analogy task. C . 4 R O L E O F D I M E N S I O N S The main text has focused on the dimension choice of d = 300 , due to its popularity . In this section we explore the role of the dimension in terms of both choice of D and the performance of the postprocessing operation – we do this by using skip-gram model on the 2010 snapshot of Wikipedia corpus (Al-Rfou et al., 2013) to train word representations. W e first observe that the two phenomena of Section 2 continue to hold: • From T able 14 we observe that the ratio between the norm of µ and the norm av erage of all v ( w ) spans from 1/3 to 1/4; 17 Published as a conference paper at ICLR 2018 RAND-W ALK TSCCA orig. proc. orig. proc. 2012 38.03 37.66 44.51 44.63 2013 37.47 36.85 43.21 42.74 2014 46.06 48.32 52.85 52.87 2015 47.82 51.76 56.22 56.14 SICK 51.58 51.76 56.15 56.11 all 43.48 44.67 50.01 50.23 T able 13: Before-After results (x100) on the semantic textual similarity tasks. dim 300 400 500 600 700 800 900 1000 avg. k v ( w ) k 2 4.51 5.17 5.91 6.22 6.49 6.73 6.95 7.15 k µ k 2 1.74 1.76 1.77 1.78 1.79 1.80 1.81 1.83 T able 14: Statistics on word representation of dimensions 300, 400, ..., and 1000 using the skip-gram model. • From Figure 8 we observe that the decay of the variance ratios σ i is near exponential for small values of i and remains roughly constant ov er the later ones. 1 0 0 1 0 1 1 0 2 1 0 3 index 0.000 0.005 0.010 0.015 0.020 0.025 variance ratio 300 400 500 600 700 800 900 1000 Figure 8: The decay of the normalized singular values of word representations. A rule of thumb choice of D is around d/ 100 . W e validate this claim empirically by performing the tasks in Section 3 on w ord representations of higher dimensions, ranging from 300 to 1000, where we set the parameter D = d/ 100 . In summary , the performance improvement on the four itemized tasks of Section 3 are 2.27%, 3.37%, 0.01 and 1.92% respecti vely; the detailed results can be found in T able 15, T able 16, T able 17, and T able 18. Again, note that the improvement for analogy tasks is marginal. These e xperimental results justify the rule-of-thumb setting of D = d/ 100 , although we emphasize that the improvements can be further accentuated by tuning the choice of D based on the specific setting. D E X P E R I M E N T S O N W O R D A N A L O G Y T A S K The detailed performance on the analogy task is provided in T able 19. E E X P E R I M E N T S O N S E M A N T I C T E X T U A L S I M I L A R I T Y T A S K The detailed performance on the semantic textual similarity is pro vided in T able 20. 18 Published as a conference paper at ICLR 2018 Dim 300 400 500 600 orig. proc. orig. proc. orig. proc. orig. proc. RG65 73.57 74.72 75.64 79.87 77.72 81.97 77.59 80.7 WS 70.25 71.95 70.8 72.88 70.39 72.73 71.64 74.04 R W 46.25 49.11 45.97 47.63 46.6 48.59 45.7 47.81 MEN 75.66 77.59 76.07 77.89 75.9 78.15 75.88 78.15 Mturk 75.66 77.59 67.68 68.11 66.89 68.25 67.6 67.87 SimLex 34.02 36.19 35.17 37.1 35.73 37.65 35.76 38.04 SimV erb 22.22 24.98 22.91 25.32 23.03 25.82 23.35 25.97 Dim 700 800 900 1000 orig. proc. orig. proc. orig. proc. orig. proc. RG65 77.3 81.07 77.52 81.07 79.75 82.34 78.18 79.07 WS 70.31 73.02 71.52 74.65 71.19 73.06 71.5 74.78 R W 45.86 48.4 44.96 49 44.44 49.22 44.5 49.03 MEN 75.84 78.21 75.84 77.96 76.16 78.35 76.72 78.1 Mturk 67.47 67.79 67.67 68 67.98 68.87 68.34 69.44 SimLex 35.3 37.59 36.54 37.85 36.62 38.44 36.67 38.58 SimV erb 22.81 25.6 23.48 25.57 23.68 25.76 23.24 26.58 T able 15: Before-After results (x100) on word similarity task on se ven datasets. Dim 300 400 500 600 orig. proc. orig. proc. orig. proc. orig. proc. ap 46.1 48.61 42.57 45.34 46.85 50.88 40.3 45.84 esslli 68.18 72.73 64.2 82.72 64.2 65.43 65.91 72.73 battig 71.6 77.78 68.18 75 68.18 70.45 46.91 66.67 Dim 700 800 900 1000 orig. proc. orig. proc. orig. proc. orig. proc. ap 38.04 41.31 34.76 39.8 34.76 27.46 27.96 28.21 esslli 54.55 54.55 68.18 56.82 72.73 72.73 52.27 52.27 battig 62.96 66.67 67.9 69.14 49.38 59.26 51.85 46.91 T able 16: Before-After results (x100) on the categorization task. Dim 300 400 500 600 orig. proc. orig. proc. orig. proc. orig. proc. syn. 60.48 60.52 61.61 61.45 60.93 60.84 61.66 61.57 sem. 74.51 74.54 77.11 77.36 76.39 76.89 77.28 77.61 all. 66.86 66.87 68.66 68.69 67.88 68.11 68.77 68.81 Dim 700 800 900 1000 orig. proc. orig. proc. orig. proc. orig. proc. syn. 60.94 61.02 68.38 68.34 60.47 60.30 67.56 67.30 sem. 77.24 77.26 77.24 77.35 76.76 76.90 76.71 76.51 all. 68.36 68.41 68.38 68.50 67.91 67.67 67.56 67.30 T able 17: Before-After results (x100) on the word analogy task. F S TA T I S T I C S O F T E X T C L A S S I FI C A T I O N D A T A S E T S W e e valuate the word representations (with and without postprocessing) using four different neural network architectures (CNN, v anilla-RNN, GR U-RNN and LSTM-RNN) on fi ve benchmarks: • the movie re view (MR) dataset (P ang & Lee, 2005) where each revie w is composed by only one sentence; • the subjectivity (SUBJ) dataset (Pang & Lee, 2004) where the algorithm needs to decide whether a sentence is subjectiv e or objecti ve; 19 Published as a conference paper at ICLR 2018 Dim 300 400 500 600 orig. proc. orig. proc. orig. proc. orig. proc. 2012 54.51 54.95 54.31 54.57 55.13 56.23 55.35 56.03 2013 56.58 57.89 56.35 57.35 57.55 59.38 57.43 59.00 2014 59.6 61.92 59.57 61.62 61.19 64.38 61.10 63.86 2015 59.65 61.48 59.69 61.19 61.63 64.77 61.42 64.04 SICK 68.89 70.79 60.6 70.27 68.63 71.00 68.58 70.57 all 58.32 59.91 58.25 59.55 59.61 62.02 59.57 61.55 Dim 700 800 900 1000 orig. proc. orig. proc. orig. proc. orig. proc. 2012 55.52 56.49 54.47 54.85 54.69 55.18 54.34 54.78 2013 57.61 59.31 56.75 57.62 56.98 58.26 56.78 57.73 2014 61.57 64.77 60.51 62.83 60.89 63.34 60.78 63.03 2015 62.05 65.45 60.74 62.84 61.09 63.48 60.92 63.03 SICK 68.38 70.63 67.94 69.59 67.86 69.5 67.58 69.16 all 59.96 62.34 58.87 60.39 59.16 60.88 58.94 60.48 T able 18: Before-After results (x100) on the semantic textual similarity tasks. WORD2VEC GLO VE orig. proc. orig. proc. capital-common-countries 82.01 83.60 95.06 95.96 capital-world 78.38 80.08 91.89 92.31 city-in-state 69.56 69.88 69.56 70.45 currency 32.43 32.92 21.59 21.36 family 84.98 84.59 95.84 95.65 gram1-adjectiv e-to-adverb 28.02 27.72 40.42 39.21 gram2-opposite 40.14 40.51 31.65 30.91 gram3-comparativ e 89.19 89.26 86.93 87.09 gram4-superlativ e 82.71 83.33 90.46 90.59 gram5-present-participle 79.36 79.64 82.95 82.76 gram6-nationality-adjectiv e 90.24 90.36 90.24 90.24 gram7-past-tense 66.03 66.53 63.91 64.87 gram8-plural 91.07 90.61 95.27 95.36 gram9-plural-verbs 68.74 67.58 67.24 68.05 T able 19: Before-After results (x100) on the word analogy task. • the TREC question dataset (Li & Roth, 2002) where all the questions in this dataset has to be partitioned into six categories; • the IMDb dataset (Maas et al., 2011) – each revie w consists of sev eral sentences; • the Stanford sentiment treebank (SST) dataset (Socher et al., 2013a), where we only use the full sentences as the training data. In TREC, SST and IMDb, the datasets hav e already been split into train/test sets. Otherwise we use 10-fold cross validation in the remaining datasets (i.e., MR and SUBJ). Detailed statistics of v arious features of each of the datasets are provided in T able 21. G P R O O F O F T H E O R E M A . 1 Giv en the similarity between the setup in Theorem 2.2 in (Arora et al., 2016) and Theorem A.1, many parts of the original proof can be reused except one key aspect – the concentration of Z ( c ) . W e summarize this part in the following lemma: 20 Published as a conference paper at ICLR 2018 WORD2VEC GLO VE orig. proc. orig. proc. 2012.MSRpar 42.12 43.85 44.54 44.09 2012.MSRvid 72.07 72.16 64.47 68.05 2012.OnWN 69.38 69.48 53.07 65.67 2012.SMT europarl 53.15 54.32 41.74 45.28 2012.SMTnews 49.37 48.53 37.54 47.22 2013.FNWN 40.70 41.96 37.54 39.34 2013.OnWN 67.87 68.17 47.22 58.60 2013.headlines 61.88 63.81 49.73 57.20 2014.OnWN 74.61 74.78 57.41 67.56 2014.deft-forum 32.19 33.26 21.55 29.39 2014.deft-news 66.83 65.96 65.14 71.45 2014.headlines 58.01 59.58 47.05 52.60 2014.images 73.75 74.17 57.22 68.28 2014.tweet-news 71.92 72.07 58.32 66.13 2015.answers-forum 46.35 46.80 30.02 39.86 2015.answers-students 68.07 67.99 49.20 62.38 2015.belief 59.72 60.42 44.05 57.68 2015.headlines 61.47 63.45 46.22 53.31 2015.images 78.09 78.08 66.63 73.20 SICK 70.10 70.20 65.14 67.85 T able 20: Before-After results (x100) on the semantic textual similarity tasks. c l T rain T est MR 2 20 10,662 10-fold cross validation SUBJ 2 23 10,000 10-fold cross validation TREC 6 10 5,952 500 SST 5 18 11,855 2,210 IMDb 2 100 25,000 25,000 T able 21: Statistics for the five datasets after tokenization: c represents the number of classes; l represents the a verage sentence length; T rain represents the size of the training set; and T est represent the size of the test set. Lemma G.1 Let c be a random variable uniformly distrib uted over the unit spher e, we pr ove that with high pr obability , Z ( c ) / |V | con ver ges to a constant Z : p ((1 − z ) Z ≤ Z ( c ) ≤ (1 + z ) Z ) ≥ 1 − δ, wher e z = Ω(( D + 1) / |V | ) and δ = Ω(( D A 2 + k µ k 2 ) /d ) . Our proof differs from the one in (Arora et al., 2016) in two ways: (a) we treat v ( w ) as deterministic parameters instead of random variables and pro ve the Lemma by sho wing a certain concentration of measure; (b) the asymmetric parts µ and u 1 ,..., u D , (which did not exist in the original proof), need to be carefully addressed to complete the proof. 21 Published as a conference paper at ICLR 2018 G . 1 P R O O F O F L E M M A G . 1 Giv en the constraints on the word v ectors (3), the partition function Z ( c ) can be re written as, Z ( c ) = X v ∈V exp( c > v ( w )) = X v ∈V exp c > µ + D X i =1 α i ( w ) u i + ˜ v ( w ) !! = X v ∈V exp( c > µ ) " D Y i =1 exp( α i ( w ) c > u i ) # exp c > ˜ v ( w ) . The equation abov e suggests that we can divide the proof into fi ve parts. Step 1: for every unit v ector c , one has, 1 |V | X w ∈V exp c > ˜ v ( w ) → E f exp c > ˜ v , as |V | → ∞ . (5) Proof Let M , N be a positive inte ger , and let A M ⊂ R d such that, A M ,N = ˜ v ∈ R d : M − 1 N < exp( c > ˜ v ) ≤ M N . Since A M ,N can be represented by a union of countable disjoint rectangles, we kno w that for e very M , N ∈ N + , 1 |V | X w ∈V 1 ( ˜ v ( w ) ∈ A M ,N ) = Z A M,N f ( ˜ v ) d ˜ v . Further , since A M ,N are disjoint for different M ’ s and R d = ∪ ∞ M =1 A M ,N , one has, 1 |V | X w ∈V exp c > ˜ v ( w ) = ∞ X M =1 1 |V | X w ∈V 1 ( ˜ v ( w ) ∈ A M ,N ) exp( c > ˜ v ( w )) ≤ ∞ X M =1 1 |V | X w ∈V 1 ( ˜ v ( w ) ∈ A M ,N ) M N → ∞ X M =1 M N Z A M,N f ( ˜ v ) d ˜ v . The abov e statement holds for ev ery N . Let N → ∞ , by definition of integration, one has, lim N →∞ ∞ X M =1 M N Z A M,N f ( ˜ v ) d ˜ v = E f exp c > ˜ v , which yields, 1 |V | X w ∈V exp c > ˜ v ( w ) ≤ E f exp c > ˜ v , as |V | → ∞ . (6) Similarly , one has, 1 |V | X w ∈V exp c > ˜ v ( w ) ≥ lim N →∞ ∞ X M =1 M − 1 N Z A M,N f ( ˜ v ) d ˜ v = E f exp c > ˜ v , as |V | → ∞ . (7) Putting (6) and (7) prov es (5). 22 Published as a conference paper at ICLR 2018 Step 2: the expected value, E f exp c > ˜ v is a constant independent of c : E f exp c > ˜ v = Z 0 . (8) Proof Let Q ∈ R d × d be a orthonormal matrix such that Q > c 0 = c where c 0 = (1 , 0 , ..., 0) > and det( Q ) = 1 , then we hav e f ( ˜ v ) = f ( Q ˜ v ) , and, E f exp c > 0 ˜ v = Z ˜ v f ( ˜ v ) exp c > 0 ˜ v d ˜ v = Z ˜ v f ( Q ˜ v ) exp c > Q ˜ v det( Q ) d ˜ v = Z ˜ v 0 f ( ˜ v 0 ) exp c > ˜ v 0 d ˜ v 0 = E f exp c > ˜ v , which prov es (8). Step 3: for any vector µ , one has the follo wing concentration property , p | exp c > µ − 1 | > k ≤ 2 exp − 1 4 + k µ k 2 d − 1 1 log 2 (1 − k ) (9) Proof Let c 1 ,..., c d be i.i.d. N (0 , 1) , and let C = P d i =1 c 2 i , then c = ( c 1 , ..., c d ) / √ C is uniform o ver unit sphere. Since c is uniform, then without loss of generality we can consider µ = ( k µ k , 0 , ..., 0) . Thus it suffices to bound exp k µ k c 1 / √ C . W e divide the proof into the follo wing steps: • C follows chi-square distribution with the degree of freedom of d , thus C can be bounded by (Laurent & Massart, 2000), p ( C ≥ d + 2 √ dx + 2 x ) ≤ exp( − x ) , ∀ x > 0 . (10) p ( C ≤ d − 2 √ dx ) ≤ exp( − x ) , ∀ x > 0 . (11) • Therefore for any x > 0 , one has, p | C − d | ≥ 2 √ dx ≤ exp( − x ) Let x = 1 / 4 d , one has, p ( C > d + 1) ≤ exp − 1 4 d , p ( C < d − 1) ≤ exp − 1 4 d . • Since c 1 is a Gaussian random variable with variance 1 , by Chebyshev’ s inequality , one has, p ( y c i ≥ k ) ≤ y 2 k 2 , p ( y c i ≤ − k ) ≤ y 2 k 2 , ∀ k > 0 and therefore thus, p (exp( y c i ) − 1 > k ) ≤ y 2 log 2 (1 + k ) , p (exp( y c i ) − 1 < − k ) ≤ y 2 log(1 − k ) 2 , ∀ k > 0 . 23 Published as a conference paper at ICLR 2018 • Therefore we can bound exp k µ k c 1 / √ C by , p exp k µ k c 1 √ C − 1 > k ≤ p ( C > d + 1) + p exp k µ k c 1 √ C − 1 > k C < d + 1 p ( C < d + 1) ≤ exp − 1 4 d + p exp k µ k c 1 √ d + 1 − 1 > k = exp − 1 4 d + k µ k 2 d + 1 1 log(1 − k ) 2 . p exp k µ k c 1 √ C − 1 < − k ≤ exp − 1 4 d + k µ k 2 d − 1 1 log 2 (1 + k ) . Combining the two inequalities abov e, one has (9) prov ed. Step 4: W e are now ready to pro ve con v ergence of Z ( c ) . With (9), let C ⊂ R d such that, C = c : exp( c > µ ) − 1 < k , exp( Ac > u i ) − 1 < k , exp( − Ac > u i ) − 1 < k ∀ i = 1 , ..., D Then we can bound the probability on C by , p ( C ) ≥ p exp( c > µ ) − 1 < k + D X i =1 p ( exp( Ac > u i ) − 1 < k ) − 2 D ≥ 1 − (2 D + 1) exp − 1 4 d − 2 D A 2 d − 1 1 log 2 (1 − k ) − k µ k 2 d − 1 1 log 2 (1 − k ) . Next, we need to sho w that for e very w , the corresponding C ( w ) , i.e., C ( w ) = c : exp( c > µ ) − 1 < k , exp( α i ( w ) c > u i ) − 1 < k , ∀ i = 1 , ..., D W e observe that α i ( w ) is bounded by A , therefore for an y c that, min(exp( − Ac > u i ) , exp( Ac > u i )) ≤ exp( α i c > u i ) ≤ max(exp( − Ac > u i ) , exp( Ac > u i )) , and thus, min(exp( − Ac > u i ) , exp( Ac > u i )) − 1 ≤ exp( α i c > u i ) − 1 ≤ max(exp( − Ac > u i ) , exp( Ac > u i )) − 1 , which yields, | exp( α i c > u i ) − 1 | ≤ max( | exp( − Ac > u i ) − 1 | , | exp( Ac > u i ) − 1 | ) < k . Therefore we prov e C ( w ) ⊃ C . Assembling e verything together , one has, p exp( c > µ ) D Y i =1 exp( α i ( w ) c > u i ) − 1 > ( D + 1) k , ∀ i = 1 , ..., D, ∀ w ∈ V ! ≤ p ( ¯ C ) ≤ (2 D + 1) exp( − 1 4 d ) + 2 D A 2 d − 1 1 log 2 (1 − k ) + k µ k 2 d − 1 1 log 2 (1 − k ) For e very c ∈ C , one has, 1 |V | | Z ( c ) − Z 0 | ≤ ( D + 1) k |V | Z 0 . Let Z = |V | Z 0 , one can conclude that, p ((1 − z ) Z ≤ Z ( c ) ≤ (1 + z ) Z ) ≥ 1 − δ, where z = Ω(( D + 1) / |V | ) and δ = Ω( D A 2 /d ) . 24 Published as a conference paper at ICLR 2018 G . 2 P R O O F O F T H E O R E M A . 1 Having Lemma G.1 ready , we can follo w the same proof as in (Arora et al., 2016) that both p ( w ) and p ( w , w 0 ) are correlated with k v ( w ) k , formally log p ( w ) → k v ( w ) k 2 2 d − log Z, as |V | → ∞ , (12) log p ( w, w 0 ) → k v ( w ) + v ( w 0 ) k 2 2 d − log Z, as |V | → ∞ . (13) Therefore, the inference presented in (Arora et al., 2016) (i.e., (4) ) is obvious by assembling (12) and (13) together: PMI( w , w 0 ) → v ( w ) > v ( w 0 ) d , as |V | → ∞ . 25
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment