단어 임베딩 상위 차원 제거로 성능 향상
본 논문은 기존 워드2벡터·GloVe 등 실수형 단어 임베딩에 대해, 평균 벡터와 몇 개의 주된 주성분을 제거하는 아주 간단한 후처리 기법을 제안한다. 평균을 0으로 맞추고, 상위 D 개 주성분을 차원에서 빼내면 임베딩이 보다 등방성(isotropic)해지고, 단어 유사도·유사어 군집·유추 등 다양한 내재·외재 평가에서 일관되게 성능이 향상됨을 실험적으로 입증한다.
저자: Jiaqi Mu, Suma Bhat, Pramod Viswanath
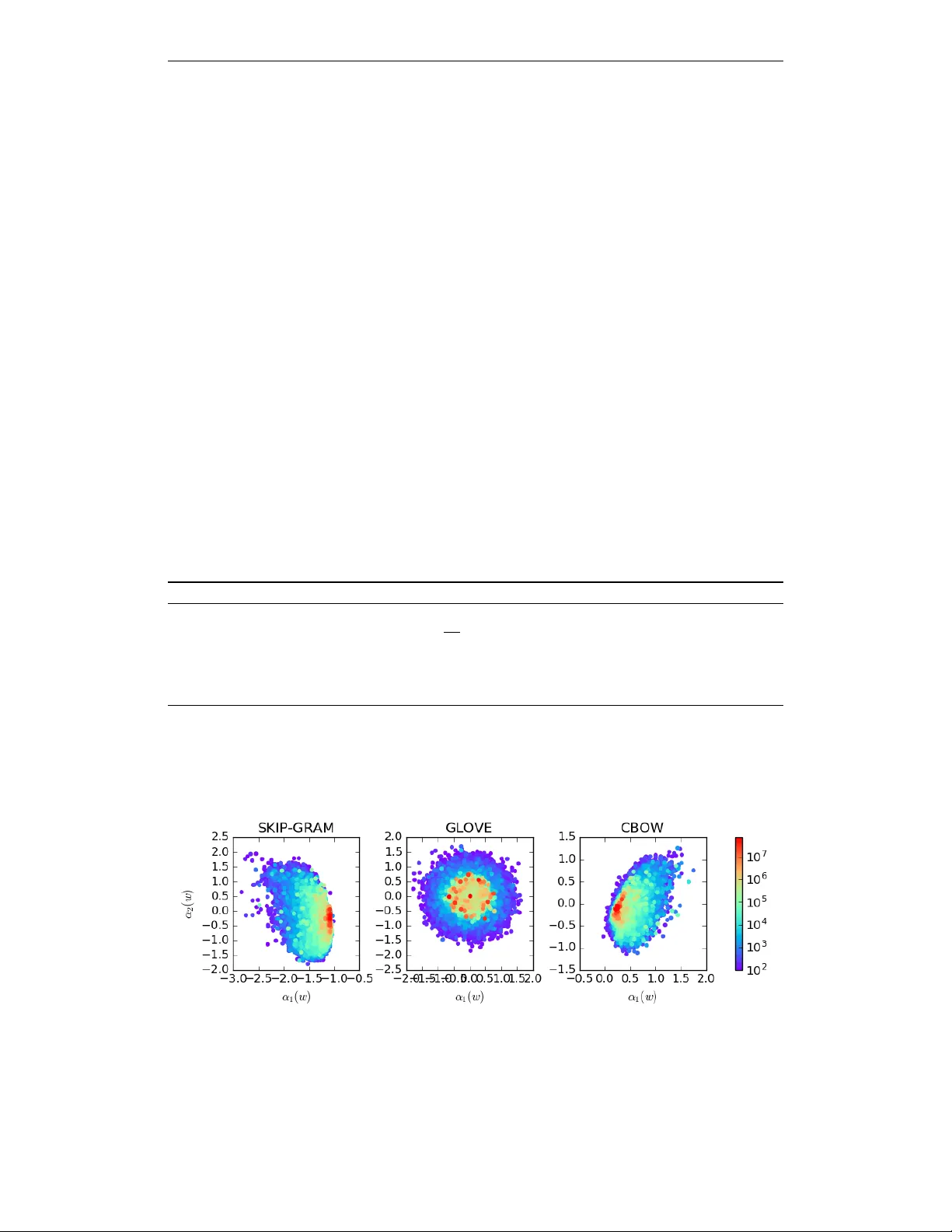
본 논문은 실수형 단어 임베딩이 현재 NLP에서 차지하는 중요성을 인정하면서도, 기존 학습 방법들(WORD2VEC, GloVe, RAND‑WALK, CBOW 등)이 만든 벡터들이 몇 가지 구조적 결함을 가지고 있음을 지적한다. 첫 번째 결함은 모든 단어 벡터가 비제로 평균을 공유한다는 점이다. 저자들은 다양한 언어와 코퍼스에서 평균 벡터의 노름이 전체 평균 노름의 1/6~1/2 수준임을 실험적으로 확인했다. 두 번째 결함은 평균을 제거한 후에도 벡터들이 등방성이 부족하고, 소수의 주성분이 전체 분산의 대부분을 차지한다는 점이다. PCA 분석 결과, 상위 D 개(대략 차원 d 의 1%) 주성분이 전체 에너지의 큰 비율을 차지하고, 나머지 차원은 거의 동일한 분산을 보인다.
이러한 관찰을 바탕으로 저자들은 두 단계의 후처리 알고리즘을 제안한다. 1) 전체 단어 벡터의 평균 µ 를 계산하고, 모든 벡터에서 이를 빼서 평균을 0으로 만든다. 2) PCA를 수행해 상위 D 개의 주성분 u₁…u_D 를 구하고, 각 벡터에서 이들 방향에 대한 투영을 다시 빼는 ‘주성분 제거’를 수행한다. 이 과정은 수학적으로는 isotropy measure I 를 1에 가깝게 만드는 두 차수 근사와 일치한다. 첫 차수에서는 평균을 0으로 만드는 것이 필요하고, 두 차수에서는 특이값을 평탄하게 만들어 스펙트럼을 균일하게 만든다.
알고리즘은 매우 간단하고, D 하나만 하이퍼파라미터로 조정하면 된다. 저자들은 D≈d/100을 경험적으로 좋은 값으로 제시했으며, d=300인 대부분의 공개 임베딩에서 이 규칙이 잘 작동한다. 실제로, WORD2VEC와 GloVe에 대해 D=2~3 정도만 제거해도 성능이 크게 개선되었다.
성능 검증은 두 축에서 이루어졌다. 첫 번째는 내재 평가(lexical‑level)로, 단어 유사도, 개념 군집, 단어 유추 세 가지 작업을 사용했다. 평균 1.7%의 유사도 향상, 2.8~4.5%의 군집 정확도 상승, 0.2~0.5%의 유추 정확도 향상이 보고되었다. 두 번째는 외재 평가(semantic textual similarity, text classification)이다. 문장을 단어 평균으로 표현한 STS 태스크에서 21개 데이터셋 평균 4%의 상관계수 상승을 기록했으며, 텍스트 분류에서는 CNN·RNN 기반 모델에 후처리된 임베딩을 적용했을 때 40개 실험 중 34개에서 평균 2.85% 정확도 향상을 보였다.
또한, 저자들은 상위 주성분이 단어 빈도와 강하게 연관된다는 사실을 시각화했다. α₁, α₂와 단어의 unigram 확률 사이에 뚜렷한 관계가 나타났으며, 이는 고빈도 단어가 특정 방향에 몰려 의미적 구분을 방해한다는 해석을 가능하게 한다. 이 점은 기존 연구(Arora et al., 2017)와 차별화된다. Arora는 데이터셋‑특정 문장 벡터에서 첫 번째 주성분을 제거했지만, 본 논문은 전체 어휘 수준에서 보편적인 지배 방향을 제거한다는 점에서 더 일반적인 접근이다.
결론적으로, 평균 및 상위 주성분 제거라는 단순한 선형 변환이 기존 고차원 단어 임베딩의 구조적 문제를 해결하고, 다양한 NLP 태스크에서 실질적인 성능 향상을 가져온다. 이 방법은 별도의 재학습 없이 기존 임베딩에 바로 적용 가능하므로, 현재 널리 사용되는 워드 임베딩을 활용하는 모든 시스템에 실용적인 개선책을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기