Combating Reinforcement Learnings Sisyphean Curse with Intrinsic Fear
Many practical environments contain catastrophic states that an optimal agent would visit infrequently or never. Even on toy problems, Deep Reinforcement Learning (DRL) agents tend to periodically revisit these states upon forgetting their existence …
Authors: Zachary C. Lipton, Kamyar Azizzadenesheli, Abhishek Kumar
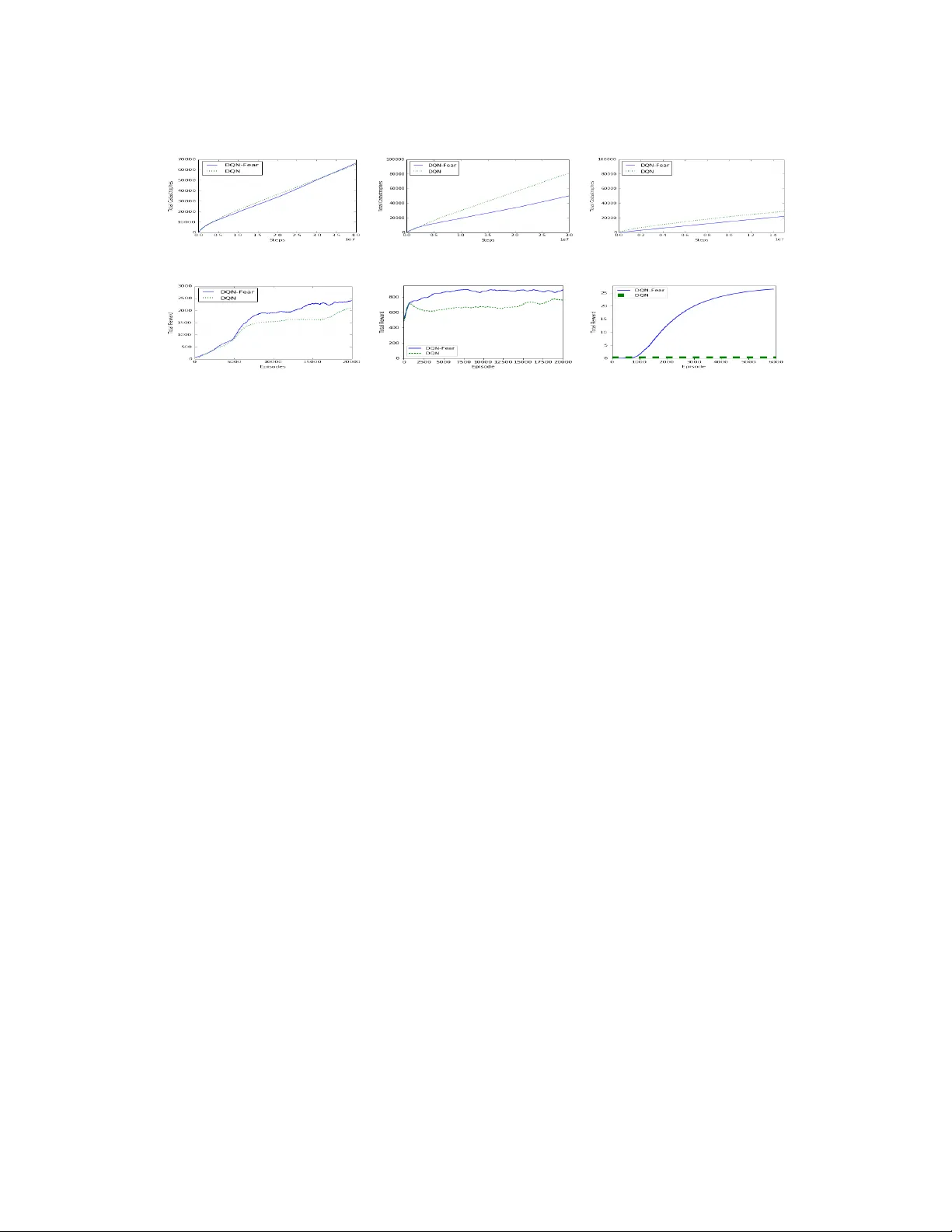
Combating Reinforcement Learning’s Sisyphean Curse with Intrinsic Fear Zachary C. Lipton 1 , 2 , 3 , Kamyar Azizzadenesheli 4 , Abhishek Kumar 3 , Lihong Li 5 , Jianfeng Gao 6 , Li Deng 7 Carnegie Mellon University 1 , Amazon AI 2 , University of California, San Diego 3 , Univerisity of California, Irvine 4 , Google 5 , Microsoft Research 6 , Citadel 7 zlipton@cmu.edu , kazizzad@uci.edu , abkumar@ucsd.edu { lihongli , jfgao , deng } @microsoft.com March 15, 2018 Abstract Many practical environments contain catastrophic states that an optimal agent would visit infr equently or never . Even on toy pr oblems, Deep Reinforcement Learning (DRL) agents tend to periodically revisit these states upon forgetting their existence under a new policy . W e introduce intrinsic fear (IF), a learned reward shaping that guards DRL agents against p eriodic catastrophes. IF agents possess a fear model trained to predict the probability of imminent catastrophe. This score is then used to p enalize the Q- learning objective. Our the oretical analysis bounds the reduction in av erage return due to learning on the perturbed obje ctive. W e also prove robustness to classication errors. As a bonus, IF mo dels tend to learn faster , owing to reward shaping. Experiments demonstrate that intrinsic-fear DQNs solve other wise pathological environments and improv e on several Atari games. 1 Introduction Following the success of deep reinforcement learning (DRL) on Atari games [ 22 ] and the board game of Go [ 29 ], researchers are incr easingly exploring practical applications. Some investigated applications include robotics [ 17 ], dialogue systems [ 9 , 19 ], energy management [ 25 ], and self-driving cars [ 27 ]. Amid this push to apply DRL, we might ask, can we trust these agents in the wild? Agents acting society may cause harm. A self-driving car might hit pedestrians and a domestic robot might injure a child. Agents might also cause self-injury , and while Atari lives lost are inconsequential, robots are expensive. Unfortunately , it may not b e feasible to pre vent all catastrophes without requiring extensive prior knowledge [ 10 ]. Moreover , for typical DQNs, providing large negativ e rewards does not solve the problem: as soon as the catastrophic trajectories are ushed from the r eplay buer , the updated Q-function ceases to discourage revisiting these states. In this paper , we dene avoidable catastrophes as states that prior knowledge dictates an optimal policy should visit rarely or ne ver . Additionally , we dene danger states —those from which a catastrophic state can 1 be reached in a small number of steps, and assume that the optimal policy does visit the danger states rarely or ne ver . The notion of a danger state might seem odd absent any assumptions about the transition function. With a fully-connected transition matrix, all states are danger states. Howe ver , physical environments are not fully connected. A car cannot be parked this se cond, underwater one second later . This work primarily addresses how w e might pre vent DRL agents from perpetually making the same mistakes. As a bonus, w e show that the prior knowledge knowledge that catastrophic states should be avoided accelerates learning. Our experiments show that even on simple toy problems, the classic deep Q-network (DQN) algorithm fails badly , repeatedly visiting catastrophic states so long as they continue to learn. This p oses a formidable obstacle to using DQNs in the real world. How can we trust a DRL-based agent that was doomed to periodically experience catastr ophes, just to remember that they e xist? Imagine a self-driving car that had to periodically hit a few pedestrians to remember that it is undesirable. In the tabular setting, an RL agent never forgets the learned dynamics of its environment, even as its policy evolves. Moreover , when the Markovian assumption holds, convergence to a globally optimal policy is guaranteed. Howe ver , the tabular approach becomes infeasible in high-dimensional, continuous state spaces. The trouble for DQNs owes to the use of function approximation [ 24 ]. When training a DQN, w e successively update a neural network based on experiences. These experiences might b e sampled in an online fashion, from a trailing windo w ( experience replay buer ), or uniformly from all past e xperiences. Regardless of which mo de w e use to train the network, e ventually , states that a learned policy never encounters will come to form an innitesimally small region of the training distribution. At such times, our networks suer the well-known pr oblem of catastrophic forgetting [ 21 , 20 ]. Nothing prev ents the DQN’s policy from drifting back towards one that re visits forgotten catastrophic mistakes. W e illustrate the brittleness of modern DRL algorithms with a simple pathological problem called Adventur e Seeker . This problem consists of a one-dimensional continuous state, two actions, simple dynamics, and admits an analytic solution. Nevertheless, the DQN fails. W e then show that similar dynamics exist in the classic RL environment Cart-Pole. T o combat these problems, we propose the intrinsic fear (IF) algorithm. In this approach, we train a supervise d fear model that predicts which states are likely to lead to a catastrophe within k r steps. The output of the fear model (a probability), scaled by a fear factor penalizes the Q -learning target. Crucially , the fear model maintains buers of b oth safe and danger states. This model never forgets danger states, which is possible due to the infrequency of catastrophes. W e validate the approach both empirically and theoretically . Our experiments address Adventur e Seeker , Cartpole, and several Atari games. In these environments, we label every lost life as a catastrophe. On the toy environments, IF agents learns to avoid catastrophe indenitely . In Seaquest experiments, the IF agent achieves higher re ward and in Aster oids, the IF agent achieves both higher reward and few er catastrophes. The improvement on Fr eeway is most dramatic. W e also make the following theoretical contributions: First, we prove that when the reward is bounde d and the optimal policy rarely visits the danger states, an optimal policy learned on the perturbe d reward function has approximately the same return as the optimal policy learned on the original value function. Second, we prove that our method is robust to noise in the danger model. 2 2 Intrinsic fear An agent interacts with its environment via a Marko v decision process, or MDP, (S , A , T , R , γ ) . At each step t , the agent observes a state s ∈ S and then chooses an action a ∈ A according to its policy π . The environment then transitions to state s t + 1 ∈ S according to transition dynamics T ( s t + 1 | s t , a t ) and generates a reward r t with expectation R ( s , a ) . This cycle continues until each episode terminates. An agent seeks to maximize the cumulative discounted return T t = 0 γ t r t . T emporal-dierences methods [ 31 ] like Q-learning [ 33 ] model the Q-function, which giv es the optimal discounted total reward of a state-action pair . Problems of practical interest tend to have large state spaces, thus the Q-function is typically approximated by parametric models such as neural networks. In Q-learning with function approximation, an agent collects experiences by acting greedily with respect to Q ( s , a ; θ Q ) and updates its parameters θ Q . Up dates proceed as follo ws. For a given experience ( s t , a t , r t , s t + 1 ) , we minimize the squared Bellman error: L = ( Q ( s t , a t ; θ Q ) − y t ) 2 (1) for y t = r t + γ · max a 0 Q ( s t + 1 , a 0 ; θ Q ) . Traditionally , the parameterised Q ( s , a ; θ ) is traine d by stochastic approximation, estimating the loss on each experience as it is encountered, yielding the update: θ t + 1 ← θ t + α ( y t − Q ( s t , a t ; θ t ))∇ Q ( s t , a t ; θ t ) . (2) Q-learning methods also require an exploration strategy for action selection. For simplicity , we consider only the ϵ -greedy heuristic. A few tricks help to stabilize Q-learning with function approximation. Notably , with experience replay [ 18 ], the RL agent maintains a buer of experiences, of experience to update the Q-function. W e propose a new formulation: Suppose there exists a subset C ⊂ S of known catastrophe states / And assume that for a given environment, the optimal policy rarely enters from which catastrophe states are reachable in a short number of steps. W e dene the distance d ( s i , s j ) to be length N of the smallest sequence of transitions { ( s t , a t , r t , s t + 1 )} N t = 1 that traverses state space from s i to s j . 1 Denition 2.1. Suppose a priori knowledge that acting according to the optimal p olicy π ∗ , an agent rarely encounters states s ∈ S that lie within distance d ( s , c ) < k τ for any catastrophe state c ∈ C . Then each state s for which ∃ c ∈ C s.t. d ( s , c ) < k τ is a danger state . In Algorithm 1 , the agent maintains both a DQN and a separate , supervised fear model F : S 7→ [ 0 , 1 ] . F provides an auxiliary source of r eward, p enalizing the Q-learner for entering likely danger states. In our case, we use a neural network of the same architecture as the DQN (but for the output layer ). While one could sharing weights between the two networks, such tricks are not relevant to this paper’s contribution. W e train the fear model to predict the probability that any state will lead to catastrophe within k moves. Over the course of training, our agent adds each experience ( s , a , r , s 0 ) to its experience replay buer . Whenever a catastrophe is reached at, say , the n t h turn of an episode, we add the preceding k r ( fear radius ) states to a danger buer . W e add the rst n − k r states of that episode to a safe buer . When n < k r , all states for that episode are added to the list of danger states. Then after each turn, in addition to up dating the Q-network, we update the fear model, sampling 50% of states from the danger buer , assigning them label 1 , and the remaining 50% from the safe buer , assigning them label 0 . 1 In the stochastic dynamics setting, the distance is the minimum mean passing time between the states. 3 Algorithm 1 Training DQN with Intrinsic Fear 1: Input: Q (DQN), F (fear model), fear factor λ , fear phase-in length k λ , fear radius k r 2: Output: Learned parameters θ Q and θ F 3: Initialize parameters θ Q and θ F randomly 4: Initialize replay buer D , danger state buer D D , and safe state buer D S 5: Start per-episo de turn counter n e 6: for t in 1: T do 7: With probability ϵ sele ct random action a t 8: Otherwise, select a greedy action a t = arg max a Q ( s t , a ; θ Q ) 9: Execute action a t in environment, observing reward r t and successor state s t + 1 10: Store transition ( s t , a t , r t , s t + 1 ) in D 11: if s t + 1 is a catastrophe state then 12: Add states s t − k r through s t to D D 13: else 14: Add states s t − n e through s t − k r − 1 to D S 15: Sample a random mini-batch of transitions ( s τ , a τ , r τ , s τ + 1 ) from D 16: λ τ ← min ( λ , λ · t k λ ) 17: y τ ← for terminal s τ + 1 : r τ − λ τ for non-terminal s τ + 1 : r τ + max a 0 Q ( s τ + 1 , a 0 ; θ Q )− λ · F ( s τ + 1 ; θ F ) 18: θ Q ← θ Q − η · ∇ θ Q ( y τ − Q ( s τ , a τ ; θ Q )) 2 19: Sample random mini-batch s j with 50% of examples fr om D D and 50% from D S 20: y j ← 1 , for s j ∈ D D 0 , for s j ∈ D S 21: θ F ← θ F − η · ∇ θ F loss F ( y j , F ( s j ; θ F )) For each update to the DQN, we perturb the TD target y t . Instead of updating Q ( s t , a t ; θ Q ) towards r t + max a 0 Q ( s t + 1 , a 0 ; θ Q ) , we modify the target by subtracting the intrinsic fear : y I F t = r t + max a 0 Q ( s t + 1 , a 0 ; θ Q ) − λ · F ( s t + 1 ; θ F ) (3) where F ( s ; θ F ) is the fear model and λ is a fear factor determining the scale of the impact of intrinsic fear on the Q-function update. 3 Analysis Note that IF perturbs the objective function. Thus, one might be concerned that the perturbed reward might lead to a sub-optimal policy . Fortunately , as we will show formally , if the labeled catastrophe states and danger zone do not violate our assumptions, and if the fear model reaches arbitrarily high accuracy , then this will not happen. For an MDP, M = hS , A , T , R , γ i , with 0 ≤ γ ≤ 1 , the average reward return is as follows: 4 η M ( π ) : = lim T →∞ 1 T E M T t r t | π if γ = 1 ( 1 − γ ) E M ∞ t γ t r t | π if 0 ≤ γ < 1 The optimal policy π ∗ of the model M is the policy which maximizes the average rewar d return, π ∗ = max π ∈ P η ( π ) where P is a set of stationary polices. Theorem 1. For a given MDP , M , with γ ∈ [ 0 , 1 ] and a catastrophe detector f , let π ∗ denote any optimal policy of M , and ˜ π denote an optimal policy of M equipped with fear mo del F , and λ , environment ( M , F ) . If the probability π ∗ visits the states in the danger zone is at most ϵ , and 0 ≤ R ( s , a ) ≤ 1 , then η M ( π ∗ ) ≥ η M ( ˜ π ) ≥ η M , F ( ˜ π ) ≥ η M ( π ∗ ) − λϵ . (4) In other words, ˜ π is λϵ -optimal in the original MDP . Proof. The policy π ∗ visits the fear zone with probability at most ϵ . Therefor e, applying π ∗ on the envi- ronment with intrinsic fear ( M , F ) , provides a expected return of at least η M ( π ∗ ) − ϵ λ . Since there exists a policy with this expected r eturn on ( M , F ) , ther efore, the optimal policy of ( M , F ) , must result in an expected return of at least η M ( π ∗ ) − ϵ λ on ( M , F ) , i.e. η M , F ( ˜ π ) ≥ η M ( π ∗ ) − ϵ λ . The expected return η M , F ( ˜ π ) decomposes into two parts: ( i ) the expected return from original environment M , η M ( ˜ π ) , ( ii ) the expected return from the fear model. If ˜ π visits the fear zone with probability at most ˜ ϵ , then η M , F ( ˜ π ) ≥ η M ( ˜ π ) − λ ˜ ϵ . Therefore , applying ˜ π on M promises an expected return of at least η M ( π ∗ ) − ϵ λ + ˜ ϵ λ , lower bounded by η M ( π ∗ ) − ϵ λ . It is worth noting that the theorem holds for any optimal p olicy of M . If one of them does not visit the fear zone at all (i.e., ϵ = 0 ), then η M ( π ∗ ) = η M , F ( ˜ π ) and the fear signal can boost up the process of learning the optimal policy . Since we empirically learn the fear model F using collected data of some nite sample size N , our RL agent has access to an imperfect fear model ˆ F , and therefor e, computes the optimal policy based on ˆ F . In this case , the RL agent trains with intrinsic fear generate d by ˆ F , learning a dierent value function than the RL agent with perfect F . T o show the robustness against errors in ˆ F , we are interested in the average de viation in the value functions of the two agents. Our second main theoretical result, given in Theorem 2 , allows the RL agent to use a smaller discount factor , denoted γ p l a n , than the actual one ( γ p l a n ≤ γ ), to reduce the planning horizon and computation cost. Moreover , when an estimated model of the environment is used, Jiang et al. [ 2015 ] shows that using a smaller discount factor for planning may prevent over-tting to the estimated model. Our result demonstrates that using a smaller discount factor for planning can reduce reduction of expected return when an estimated fear model is used. Specically , for a given environment, with fear model F 1 and discount factor γ 1 , let V π ∗ F 2 , γ 2 F 1 , γ 1 ( s ) , s ∈ S , denote the state value function under the optimal policy of an envir onment with fear model F 2 and the discount factor γ 2 . In the same environment, let ω π ( s ) denote the visitation distribution over states under policy π . W e are interested in the average reduction on expe cted return cause d by an imperfe ct classier; this 5 reduction, denoted L ( F , F , γ , γ p l a n ) , is dened as ( 1 − γ ) s ∈ S ω π ∗ F , γ p l a n ( s ) V π ∗ F , γ F , γ ( s ) − V π ∗ F , γ p l a n F , γ ( s ) d s . Theorem 2. Suppose γ p l a n ≤ γ , and δ ∈ ( 0 , 1 ) . Let ˆ F be the fear model in F with minimum empirical risk on N samples. For a given MDP model, the average reduction on expected return, L ( F , F , γ , γ p l a n ) , vanishes as N increase: with probability at least 1 − δ , L = O λ 1 − γ 1 − γ p l a n V C (F ) + log 1 δ N + ( γ − γ p l a n ) 1 − γ p l a n , (5) where V C (F ) is the V C dimension of the hypothesis class F . Proof. In order to analyze V π ∗ F , γ F , γ ( s ) − V π ∗ F , γ p l a n F , γ ( s ) , which is always non-negative, we decomp ose it as follows: V π ∗ F , γ F , γ ( s ) − V π ∗ F , γ F , γ p l a n ( s ) + V π ∗ F , γ F , γ p l a n ( s ) − V π ∗ F , γ p l a n F , γ ( s ) (6) The rst term is the dierence in the expe cted returns of π ∗ F , γ under two dierent discount factors, starting from s : E ∞ t = 0 ( γ t − γ t p l a n ) r t | s 0 = s , π ∗ F , γ , F , M . (7) Since r t ≤ 1 , ∀ t , using the geometric series, Eq. 7 is upper b ounded by 1 1 − γ − 1 1 − γ p l a n = γ − γ p l a n ( 1 − γ p l a n )( 1 − γ ) . The second term is upper b ounded by V π ∗ F , γ p l a n F , γ p l a n ( s ) − V π ∗ F , γ p l a n F , γ ( s ) since π ∗ F , γ p l a n is an optimal policy of an environment equipp ed with ( F , γ p l a n ) . Furthermore, as γ p l a n ≤ γ and r t ≥ 0 , we have V π ∗ F , γ p l a n F , γ ( s ) ≥ V π ∗ F , γ p l a n F , γ p l a n ( s ) . Therefor e, the second term of Eq. 6 is upper bounded by V π ∗ F , γ p l a n F , γ p l a n ( s ) − V π ∗ F , γ p l a n F , γ p l a n ( s ) , which is the deviation of the value function under two dierent close policies. Since F and F are close, w e expect that this deviation to be small. With one more decomposition step V π ∗ F , γ p l a n F , γ p l a n ( s ) − V π ∗ F , γ p l a n F , γ p l a n ( s ) = V π ∗ F , γ p l a n F , γ p l a n ( s ) − V π ∗ F , γ p l a n F , γ p l a n ( s ) + V π ∗ F , γ p l a n F , γ p l a n ( s ) − V π ∗ F , γ p l a n F , γ p l a n ( s ) + V π ∗ F , γ p l a n F , γ p l a n ( s ) − V π ∗ F , γ p l a n F , γ p l a n ( s ) . Since the middle term in this equation is non-p ositive, we can ignor e it for the purpose of upp er-bounding the left-hand side. The upp er bound is sum of the remaining two terms which is also upper bounded by 2 6 times of the maximum of them; 2 max π ∈ { π ∗ F , γ p l a n , π ∗ F , γ p l a n } V π F , γ p l a n ( s ) − V π F , γ p l a n ( s ) , which is the deviation in values of dierent domains. The value functions satisfy the Bellman equation for any π : V π F , γ p l a n ( s ) = R ( s , π ( s )) + λ F ( s ) + γ p l a n s 0 ∈ S T ( s 0 | s , π ( s )) V π F , γ p l a n ( s 0 ) d s V π F , γ p l a n ( s ) = R ( s , π ( s )) + λ F ( s ) (8) + γ p l a n s 0 ∈ S T ( s 0 | s , π ( s )) V π F , γ p l a n ( s 0 ) d s (9) which can be solved using iterative updates of dynamic programing. Let V π i ( s ) and V π i ( s ) respectably denote the i ’th iteration of the dynamic pr ogrammings corresponding to the rst and second equalities in Eq. 8 . Therefore , for any state V π i ( s )− V π i ( s ) = λ 0 F ( s ) − λ 0 F ( s ) + γ p l a n s 0 ∈ S T ( s 0 | s , π ( s )) V i − 1 ( s 0 ) − V i − 1 ( s 0 ) d s ≤ λ i i 0 = 0 γ p l a n T π i 0 F − F ( s ) , (10) where (T π ) i is a kernel and denotes the transition operator applied i times to itself. The classication error F ( s ) − F ( s ) is the zero-one loss of binar y classier , therefore, its expectation s ∈ S ω π ∗ F , γ p l a n ( s ) F ( s ) − F ( s ) d s is bounded by 3200 V C ( F ) + log 1 δ N with probability at least 1 − δ [ 32 , 12 ]. As long as the operator (T π ) i is a linear operator , s ∈ S ω π ∗ F , γ p l a n ( s ) V π i ( s ) − V π i ( s ) d s ≤ λ 3200 1 − γ p l a n V C (F ) + log 1 δ N . (11) Therefore, L ( F , F , γ , γ p l a n ) is b ounded by ( 1 − γ ) times of sum of Eq. 11 and 1 − γ 1 − γ p l a n , with probability at least 1 − δ . Theorem 2 holds for both nite and continuous state-action MDPs. O ver the course of our e xperiments, we discovered the following pattern: Intrinsic fear models are more eective when the fear radius k r is large enough that the model can experience danger states at a safe distance and correct the policy , without experiencing many catastrophes. When the fear radius is too small, the danger probability is only nonzero at states from which catastrophes are ine vitable anyway and intrinsic fear seems not to help . W e also found that wider fear factors train more stably when phase d in over the course of many episodes. So, in all of our experiments we gradually phase in the fear factor from 0 to λ reaching full strength at predetermined time step k λ . 7 4 Environments W e demonstrate our algorithms on the following environments: (i) Adventure Se eker , a toy pathological environment that we designed to demonstrate catastrophic forgetting; (ii) Cartpole , a classic RL environment; and (ii) the Atari games Seaquest , Asteroids , and Fr eeway [ 3 ]. Adventure Seeker W e imagine a play er placed on a hill, sloping upward to the right (Figure 1( a) ). At each turn, the player can move to the right (up the hill) or left (do wn the hill). The environment adjusts the player’s position accordingly , adding some random noise. Between the left and right edges of the hill, the player gets more reward for spending time higher on the hill. But if the player go es too far to the right, she will fall o, terminating the episode (catastrophe). Formally , the state is single continuous variable s ∈ [ 0 , 1 . 0 ] , denoting the player’s position. The starting position for each episode is chosen uniformly at random in the interval [ . 25 , . 75 ] . The available actions consist only of {− 1 , + 1 } ( left and right ). Given an action a t in state s t , T ( s t + 1 | s t , a t ) the successor state is produce d s t + 1 ← s t + . 01 · a t + η where η ∼ N ( 0 , . 01 2 ) . The reward at each turn is s t (proportional to height). The player falls o the hill, entering the catastrophic terminating state, whenever s t + 1 > 1 . 0 or s t + 1 < 0 . 0 . This game should be easy to solve. There exists a threshold above which the agent should always choose to go left and below which it should always go right. And yet a DQN agent will p eriodically die. Initially , the DQN quickly learns a good policy and avoids the catastrophe, but over the course of continued training, the agent, owing to the shape of the reward function, collapses to a policy which always moves right, r egardless of the state. W e might critically ask in what real-world scenario, we could depend upon a system that cannot solve Adv enture Se eker . Cart-Pole In this classic RL environment, an agent balances a p ole atop a cart (Figure 1(b) ). Qualitatively , the game exhibits four distinct catastrophe modes. The pole could fall down to the right or fall down to the left. Additionally , the cart could run o the right boundar y of the screen or run o the left. Formally , at each time, the agent observes a four-dimensional state vector ( x , v , θ , ω ) consisting respectively of the cart position, cart velocity , pole angle, and the p ole’s angular v elocity . At each time step, the agent chooses an action, applying a force of either − 1 or + 1 . For e very time step that the pole remains upright and the cart remains on the scr een, the agent receives a r eward of 1 . If the pole falls, the episode terminates, giving a return of 0 from the penultimate state. In experiments, we use the implementation CartPole-v0 contained in the openAI gym [ 6 ]. Like Adventure Se eker , this problem admits an analytic solution. A perfect policy should never drop the pole. But, as with Adventure Seeker , a DQN converges to a constant rate of catastrophes per turn. Atari games In addition to these pathological cases, we address Freeway , Asteroids, and Seaquest, games from the Atari Learning Environment. In Freeway , the agent controls a chicken with a goal of crossing the road while dodging trac. The chicken loses a life and starts from the original location if hit by a car . Points are only rewar ded for successfully crossing the road. In Aster oids, the agent pilots a ship and gains points from shooting the asteroids. She must avoid colliding with asteroids which cost it lives. In Seaquest, a player swims under water . Periodically , as the o xygen gets low , she must rise to the surface for o xygen. Additionally , shes swim across the screen. The player gains points each time she shoots a sh. Colliding 8 (a) Adventure Seeker (b) Cart-Pole (c) Seaquest (d) Asteroids (e) Freeway Figure 1: In experiments, we consider two toy envir onments (a,b) and the Atari games Seaquest (c), A steroids (d), and Freeway (e) with a sh or running out of oxygen result in death. In all three games, the agent has 3 lives, and the nal death is a terminal state. W e label each loss of a life as a catastrophe state. 5 Experiments First, on the toy examples, W e evaluate standard DQNs and intrinsic fear DQNs using multilayer perceptrons (MLPs) with a single hidden layer and 128 hidden nodes. W e train all MLPs by stochastic gradient descent using the Adam optimizer [ 16 ]. In Adventur e Se eker , an agent can escape from danger with only a few time steps of notice, so w e set the fear radius k r to 5 . W e phase in the fear factor quickly , reaching full strength in just 1000 steps. On this 9 (a) Seaquest (b) Asteroids (c) Freeway (d) Seaquest (e) Asteroids (f ) Freeway Figure 2: Catastrophes (rst ro w) and re ward/episode (second row ) for DQNs and Intrinsic Fear . On Adventure Seeker , all Intrinsic Fear models cease to “die ” within 14 runs, giving unbounde d (unplottable) reward ther eafter . On Seaquest, the IF model achiev es a similar catastrophe rate but signicantly higher total reward. On Asteroids, the IF model outperforms DQN. For Freeway , a randomly exploring DQN (under our time limit) never gets reward but IF mo del learns successfully . problem we set the fear factor λ to 40 . For Cart-Pole , we set a wider fear radius of k r = 20 . W e initially tried training this model with a short fear radius but made the following observation: One some runs, IF-DQN would surviving for millions of experiences, while on other runs, it might experience many catastrophes. Manually examining fear model output on successful vs unsuccessful runs, we noticed that on the bad runs, the fear model outputs non-zero pr obability of danger for pr ecisely the 5 moves before a catastrophe . In Cart-Pole, by that time , it is too to correct course . On the more successful runs, the fear model often outputs predictions in the range . 1 − . 5 . W e suspe ct that the gradation between mildly dangerous states and those with certain danger provides a richer re ward signal to the DQN. On b oth the Adventure Seeker and Cart-Pole environments, DQNs augmented by intrinsic fear far out- perform their otherwise identical counterparts. W e also compared IF to some traditional approaches for mitigating catastrophic forgetting. For example , we tried a memory-based method in which we prefer entially sample the catastrophic states for updating the model, but they did not improve o ver the DQN. It seems that the notion of a danger zone is necessary here. For Seaquest, Asteroids, and Fr eeway , we use a fear radius of 5 and a fear factor of . 5 . For all Atari games, the IF models outperform their DQN counterparts. Interestingly while for all games, the IF mo dels achieve higher reward, on Seaquest, IF-DQNs have similar catastrophe rates (Figur e 2 ). Perhaps the IF-DQN enters a region of policy space with a str ong incentives to e xchange catastrophes for higher r eward. This result suggests an interplay between the various reward signals that warrants further exploration. For Asteroids and Freeway , the impr ovements are more dramatic. Over just a few thousand episodes of Freeway , a randomly exploring DQN achieves zero rewar d. However , the rewar d shaping of intrinsic fear leads to rapid improvement. 10 6 Related work The paper studies safety in RL, intrinsically motivate d RL, and the stability of Q-learning with function approximation under distributional shift. Our work also has some connection to reward shaping. W e attempt to highlight the most r elevant papers her e. Several papers address safety in RL. Garcıa and Fernández [ 2015 ] provide a thor ough re view on the topic, identifying two main classes of methods: those that perturb the objective function and those that use external knowledge to improv e the safety of exploration. While a typical reinforcement learner optimizes e xpected return, some papers suggest that a safely acting agent should also minimize risk. Hans et al. [ 2008 ] denes a fatality as any return below some threshold τ . They propose a solution comprised of a safety function , which identies unsafe states, and a backup model , which navigates away fr om those states. Their work, which only addresses the tabular setting, suggests that an agent should minimize the probability of fatality instead of maximizing the expecte d return. Heger [ 1994 ] suggests an alternative Q-learning objective concerned with the minimum (vs. expected) return. Other papers suggest modifying the objective to p enalize policies with high-variance returns [ 10 , 8 ]. Maximizing expected returns while minimizing their variance is a classic problem in nance, where a common objective is the ratio of expected return to its standard deviation [ 28 ]. Moreover , Azizzadenesheli et al. [ 2018 ] suggests to learn the variance over the returns in order to make safe decisions at each decision step. Moldovan and Abbeel [ 2012 ] give a denition of safety base d on ergodicity . They consider a fatality to b e a state from which one cannot return to the start state. Shalev-Shwartz et al. [ 2016 ] theoretically analyzes how strong a penalty should be to discourage accidents. They also consider hard constraints to ensur e safety . None of the above works address the case wher e distributional shift dooms an agent to perpetually revisit known catastrophic failure modes. Other pap ers incorporate external knowledge into the exploration process. T ypically , this requires access to an oracle or e xtensive prior knowledge of the environment. In the extreme case, some papers suggest conning the policy sear ch to a known subset of safe policies. For reasonably complex environments or classes of policies, this seems infeasible. The potential oscillator y or divergent behavior of Q-learners with function approximation has been previ- ously identied [ 5 , 2 , 11 ]. Outside of RL, the pr oblem of covariate shift has been extensively studied [ 30 ]. Murata and Ozawa [ 2005 ] addresses the problem of catastrophic forgetting owing to distributional shift in RL with function appr oximation, proposing a memory-based solution. Many papers address intrinsic rewards, which ar e internally assigned, vs the standard ( extrinsic) rewar d. T ypically , intrinsic rewards are used to encourage exploration [ 26 , 4 ] and to acquire a modular set of skills [ 7 ]. Some papers refer to the intrinsic reward for disco very as curiosity . Like classic work on intrinsic motivation, our methods perturb the re ward function. But instead of assigning bonuses to encourage discovery of novel transitions, we assign penalties to discourage catastrophic transitions. Ke y dierences In this paper , we undertake a novel treatment of safe reinforcement learning, While the literature oers several notions of safety in reinforcement learning, we see the following problem: Existing safety research that perturbs the reward function requires little forekno wledge, but fundamentally changes the objective globally . On the other hand, processes relying on expert knowledge may presume an unreasonable level of foreknowledge. Mor eover , little of the prior work on safe reinforcement learning, to the b est of our knowledge, specically addresses the problem of catastrophic forgetting. This paper proposes a new class of algorithms for avoiding catastrophic states and a the oretical analysis supporting its robustness. 11 7 Conclusions Our experiments demonstrate that DQNs are susceptible to periodically repeating mistakes, howev er bad, raising questions about their real-world utility when harm can come of actions. While it is easy to visualize these problems on toy examples, similar dynamics ar e embedded in more complex domains. Consider a domestic robot acting as a barb er . The robot might receive p ositive feedback for giving a closer shave. This reward encourages closer contact at a steeper angle. Of course, the shape of this reward function belies the catastrophe lurking just past the optimal shav e. Similar dynamics might be imagines in a vehicle that is rewarded for traveling faster but could risk an accident with excessive spee d. Our results with the intrinsic fear model suggest that with only a small amount of prior knowledge (the ability to recognize catastrophe states after the fact), we can simultaneously accelerate learning and avoid catastrophic states. This work is a step towards combating DRL’s tendency to revisit catastrophic states due to catastrophic forgetting. References [1] Kamyar Azizzadenesheli, Emma Brunskill, and Animashree Anandkumar . Ecient e xploration through bayesian deep q-networks. arXiv preprint , 2018. [2] Leemon Baird. Residual algorithms: Reinforcement learning with function approximation. 1995. [3] Marc G Bellemare, Y avar Naddaf, Joel V eness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents. J. A rtif. Intell. Res.( JAIR) , 2013. [4] Marc G Bellemare , Sriram Srinivasan, Georg Ostrovski, T om Schaul, David Saxton, and Remi Munos. Unifying count-based exploration and intrinsic motivation. In NIPS , 2016. [5] Justin Boyan and Andre w W Moore. Generalization in reinfor cement learning: Safely approximating the value function. In NIPS , 1995. [6] Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider , John Schulman, Jie T ang, and W ojcie ch Zaremba. OpenAI gym, 2016. ar xiv .org/abs/1606.01540. [7] Nuttapong Chentanez, Andrew G Barto , and Satinder P Singh. Intrinsically motivated reinforcement learning. In NIPS , 2004. [8] Yinlam Chow , A viv T amar , Shie Mannor , and Marco Pavone. Risk-sensitive and robust decision-making: A CV aR optimization approach. In NIPS , 2015. [9] Mehdi Fatemi, Layla El Asri, Hannes Schulz, Jing He, and Kaheer Suleman. Policy networks with two-stage training for dialogue systems. In SIGDIAL , 2016. [10] Javier Garcıa and Fernando Fernández. A comprehensive survey on safe reinforcement learning. JMLR , 2015. [11] Georey J Gordon. Chattering in SARSA( λ ). T echnical report, CMU, 1996. [12] Steve Hanneke. The optimal sample complexity of P A C learning. JMLR , 2016. [13] Alexander Hans, Daniel Schneegaß, Anton Maximilian Schäfer , and Steen Udluft. Safe exploration for reinforcement learning. In ESANN , 2008. 12 [14] Matthias Heger . Consideration of risk in reinforcement learning. In Machine Learning , 1994. [15] Nan Jiang, Alex Kulesza, Satinder Singh, and Richard Lewis. The dependence of eective planning horizon on model accuracy . In International Conference on A utonomous Agents and Multiagent Systems , 2015. [16] Diederik Kingma and Jimmy Ba. Adam: A metho d for stochastic optimization. In ICLR , 2015. [17] Sergey Levine, Chelsea Finn, Tr evor Darrell, and Pieter Abbeel. End-to-end training of deep visuomotor policies. JMLR , 2016. [18] Long-Ji Lin. Self-improving reactiv e agents based on reinforcement learning, planning and teaching. Machine learning , 1992. [19] Zachary C Lipton, Jianfeng Gao, Lihong Li, Xiujun Li, Faisal Ahmed, and Li Deng. Ecient exploration for dialogue policy learning with bbq networks & replay buer spiking. In AAAI , 2018. [20] James L McClelland, Bruce L McNaughton, and Randall C O’Reilly . Why there ar e complemen- tary learning systems in the hipp ocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memor y . Psychological Review , 1995. [21] Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. Psychology of learning and motivation , 1989. [22] V olodymyr Mnih et al. Human-level control through deep reinforcement learning. Nature , 2015. [23] T eodor Mihai Moldovan and Pieter Abbe el. Safe exploration in Markov decision processes. In ICML , 2012. [24] Makoto Murata and Seiichi Ozawa. A memory-base d reinforcement learning model utilizing macro- actions. In Adaptive and Natural Computing Algorithms . 2005. [25] Will Night. The AI that cut go ogle’s energy bill could soon help y ou. MI T T ech Review , 2016. [26] Jurgen Schmidhuber . A possibility for implementing curiosity and boredom in model-building neural controllers. In From animals to animats: SAB90 , 1991. [27] Shai Shalev-Shwartz, Shaked Shammah, and Amnon Shashua. Safe, multi-agent, reinforcement learning for autonomous driving. 2016. [28] William F Sharpe. Mutual fund p erformance. The Journal of Business , 1966. [29] David Silver et al. Mastering the game of go with deep neural networks and tree search. Nature , 2016. [30] Masashi Sugiyama and Motoaki K awanabe. Machine learning in non-stationary environments: Intro- duction to covariate shift adaptation . MI T Press, 2012. [31] Richard S. Sutton. Learning to predict by the methods of temporal dierences. Machine Learning , 1988. [32] Vladimir V apnik. The nature of statistical learning theor y . Springer science & business me dia, 2013. [33] Christopher J.C.H. W atkins and Peter Dayan. Q -learning. Machine Learning , 1992. 13 An extension to the Theorem 2 In practice, we gradually learn and improv e F where the dierence b etween learned F after two consecrative updates, F t and F t + 1 , consequently , ω π ∗ F t , γ p l a n and ω π ∗ F t + 1 , γ p l a n decrease. While F t + 1 is learned through using the samples drawn from ω π ∗ F t , γ p l a n , with high probability s ∈ S ω π ∗ F t , γ p l a n ( s ) F ( s ) − F t + 1 ( s ) d s ≤ 3200 V C (F ) + log 1 δ N But in the nal b ound in The orem 2 , w e interested in s ∈ S ω π ∗ F t + 1 , γ p l a n ( s ) F ( s ) − F t + 1 ( s ) d s . Via decomposing in into two terms s ∈ S ω π ∗ F t , γ p l a n ( s ) F ( s ) − F t + 1 ( s ) d s + s ∈ S | ω π ∗ F t + 1 , γ p l a n ( s ) − ω π ∗ F t , γ p l a n ( s ) | ds Therefore, an extra term of λ 1 1 − γ p l a n s ∈ S | ω π ∗ F t + 1 , γ p l a n ( s ) − ω π ∗ F t , γ p l a n ( s ) | ds appears in the nal bound of Theorem 2 . Regarding the choice of γ p l a n , if λ V C ( F ) + log 1 δ N is less than one , then the best choice of γ p l a n is γ . Other wise, if V C ( F ) + log 1 δ N is equal to exact error in the model estimation, and is greater than 1 , then the b est γ p l a n is 0. Since, V C ( F ) + log 1 δ N is an upper bound, not an exact error , on the model estimation, the choice of zero for γ p l a n is not recommended, and a choice of γ p l a n ≤ γ is pr eferred. 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment