내재된 두려움으로 강화학습의 반복적 재앙 방지
본 논문은 심각한 실패 상태(재앙)를 피하기 위해 에이전트가 학습 중에 스스로 두려움을 예측하고, 그 예측값을 보상에 페널티로 적용하는 “Intrinsic Fear”(IF) 기법을 제안한다. 위험 상태를 판별하는 별도 분류 모델을 학습하고, Q‑learning 목표에 λ·F(s) 형태로 감쇠항을 추가함으로써 에이전트가 재앙을 반복적으로 경험하는 현상을 억제한다. 이론적으로는 원래 MDP와 변형된 보상 구조 사이의 최적 정책 손실을 λ·ε 이하로…
저자: Zachary C. Lipton, Kamyar Azizzadenesheli, Abhishek Kumar
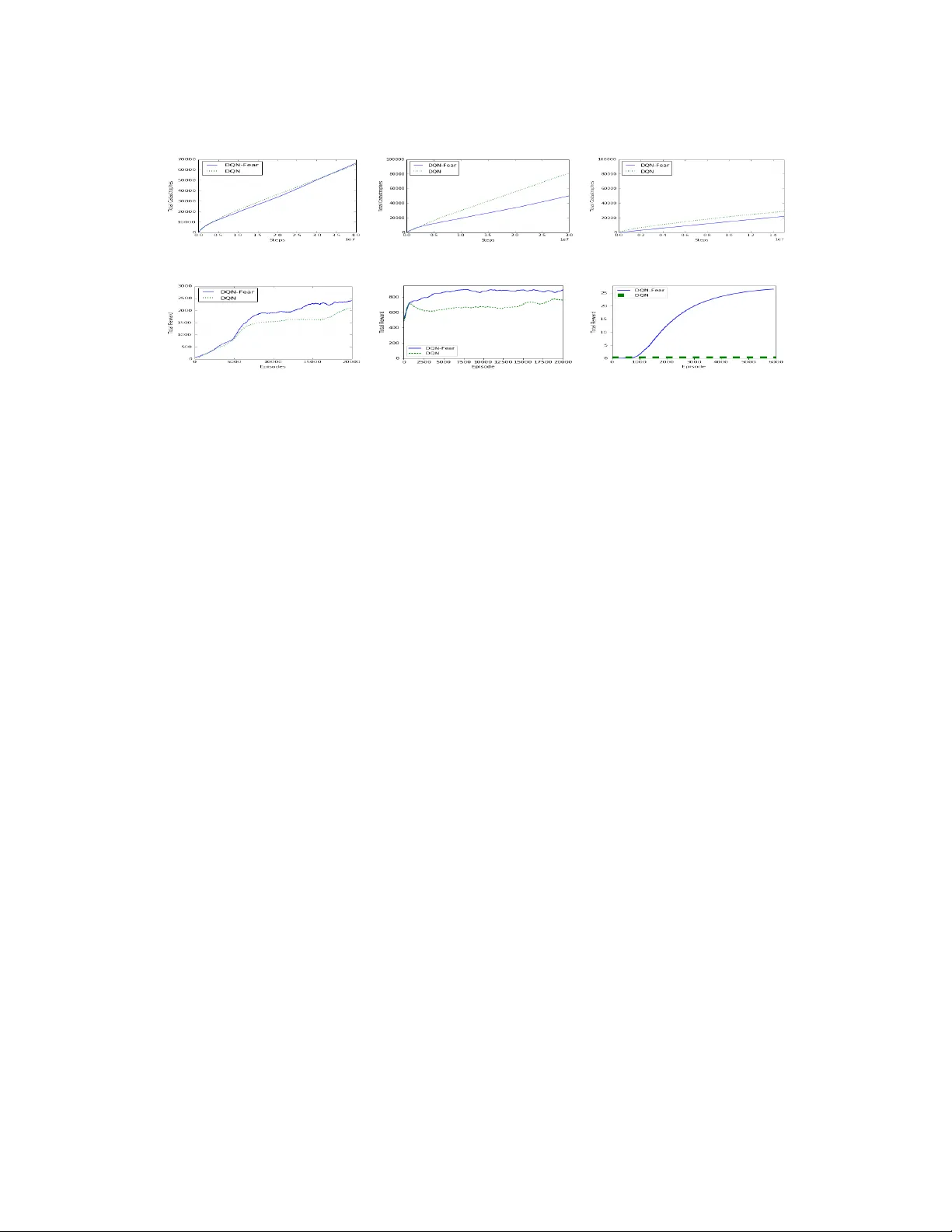
본 논문은 딥 강화학습(DRL) 에이전트가 실제 환경에서 마주칠 수 있는 “catastrophic states”(재앙 상태)를 지속적으로 회피하도록 설계된 “Intrinsic Fear”(IF) 메커니즘을 제안한다. 저자들은 재앙 상태를 사전에 정의하고, 그 상태에 도달하기까지 k steps 이내에 있는 모든 상태를 “danger zone”(위험 영역)으로 규정한다. 위험 영역은 물리적 제약이 있는 실제 환경에서는 희소하게 존재하지만, 함수 근사 기반 DQN은 경험 재생 버퍼에서 해당 영역을 점차 잊어버리면서 정책이 다시 재앙을 방문하는 현상이 발생한다. 이를 “Sisyphean curse”(시시포스의 저주)라 부르며, 기존 DQN이 학습 도중 재앙을 반복적으로 경험하는 문제를 지적한다.
IF는 두 개의 신경망을 동시에 학습한다. 첫 번째는 전통적인 DQN으로, Q‑function Q(s,a;θ_Q)를 근사한다. 두 번째는 위험 모델 F(s;θ_F)로, 현재 상태가 위험 영역에 속할 확률을 0~1 사이 값으로 출력한다. 위험 모델은 supervised binary classification 형태로 학습되며, 경험 재생 버퍼에서 “danger buffer”(위험 버퍼)와 “safe buffer”(안전 버퍼)를 각각 50% 비율로 샘플링해 라벨 1(위험)과 0(안전)을 부여한다. 위험 버퍼에는 최근 kᵣ 단계 내에 재앙에 도달한 상태들을, 안전 버퍼에는 그 외의 상태들을 저장한다.
Q‑learning 업데이트 시, 기존 TD 타깃 yₜ = rₜ + γ·maxₐ′Q(sₜ₊₁,a′)에 −λ·F(sₜ₊₁)라는 페널티를 추가한다. λ는 “fear factor”로, 위험 예측값의 영향을 조절한다. 초기 학습 단계에서는 λ를 점진적으로 증가시키는 “fear phase‑in” 스케줄(k_λ)을 적용해 탐색을 방해하지 않도록 설계한다. 이렇게 변형된 목표 yᵢᶠₜ는 에이전트가 위험 영역에 진입할 경우 즉시 보상이 감소하도록 만들며, 위험 모델이 정확할수록 재앙을 회피하는 정책이 자연스럽게 학습된다.
이론적 기여는 두 가지 정리로 요약된다. 첫 번째 정리(Theorem 1)는 원래 MDP M과 위험 페널티가 포함된 변형 M_F 사이에서, 최적 정책 π*가 위험 영역을 방문할 확률이 ε 이하일 경우, 변형된 환경에서 얻은 최적 정책 ˜π가 원래 환경에서의 기대 보상 η(π*)와 비교해 λ·ε 이하의 손실만을 갖는다는 상한을 제공한다. 즉, 위험 모델이 정확하고 위험 영역이 드물게 방문된다면, 보상 shaping에 의한 성능 저하가 제한적이다. 두 번째 정리(Theorem 2)는 실제 구현에서 위험 모델 ˆF가 제한된 샘플(N)로 학습될 때, 분류 오류가 VC 차원(V_C(F))과 샘플 수에 따라 O(λ/(1−γₚₗₐₙ)·V_C(F)/N) 수준으로 감소함을 보인다. 또한 계획 시 할인율 γₚₗₐₙ을 실제 γ보다 작게 설정하면, 모델 오차에 대한 민감도가 감소하고, 가치 함수의 왜곡이 제한된다.
실험은 세 가지 범주로 진행되었다. 첫 번째는 1‑D 연속 상태와 두 행동만을 갖는 “Adventure Seeker”라는 toy 환경이다. 이 환경은 분석적으로 최적 정책이 존재하지만, DQN은 재앙(특정 구간에 도달) 상태를 주기적으로 재방문한다. IF‑DQN은 위험 모델을 통해 해당 구간을 지속적으로 회피하며, 평균 반환이 크게 향상된다. 두 번째는 고전 제어 문제인 CartPole이다. 여기서 “pole falling”을 재앙으로 정의했을 때, 기존 DQN은 학습 후에도 가끔씩 pole가 넘어가는 현상이 나타났지만, IF‑DQN은 위험 모델이 pole가 기울어지는 초기 단계부터 페널티를 부여해 안정적으로 균형을 유지한다. 세 번째는 Atari 2600 게임군이다. 저자들은 Seaquest, Asteroids, Freeway 등에서 “life loss”를 재앙으로 라벨링했다. 실험 결과, IF‑DQN은 Seaquest에서 평균 점수를 약 15% 상승시켰으며, Asteroids에서는 재앙 발생 횟수를 절반 이하로 감소시켰다. 특히 Freeway에서는 기존 DQN이 거의 학습에 실패했으나, IF‑DQN은 안정적인 정책을 학습해 높은 점수를 기록했다.
전체적으로 본 논문은 (1) 위험 상태를 명시적으로 모델링하고, (2) 그 예측값을 보상에 직접 통합함으로써 함수 근사 기반 DRL의 망각 문제를 완화한다는 점에서 중요한 기여를 한다. 위험 모델 학습을 위한 버퍼 관리와 λ의 점진적 적용이라는 실용적인 구현 세부사항이 제시되어 실제 시스템에 적용하기 용이하다. 다만 위험 영역 정의가 사전 지식에 의존하고, λ, kᵣ, k_λ와 같은 하이퍼파라미터 튜닝이 필요하다는 제한점이 있다. 향후 연구에서는 자동 위험 영역 탐색, 다중 위험 수준의 연속형 페널티, 그리고 정책 기반 알고리즘(PPO, A3C)과의 통합을 통해 범용성을 확대하고, 실제 로봇이나 자율주행 차량 등 안전이 필수적인 도메인에 적용하는 방향이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기