Distilling Information Reliability and Source Trustworthiness from Digital Traces
Online knowledge repositories typically rely on their users or dedicated editors to evaluate the reliability of their content. These evaluations can be viewed as noisy measurements of both information reliability and information source trustworthines…
Authors: Behzad Tabibian, Isabel Valera, Mehrdad Farajtabar
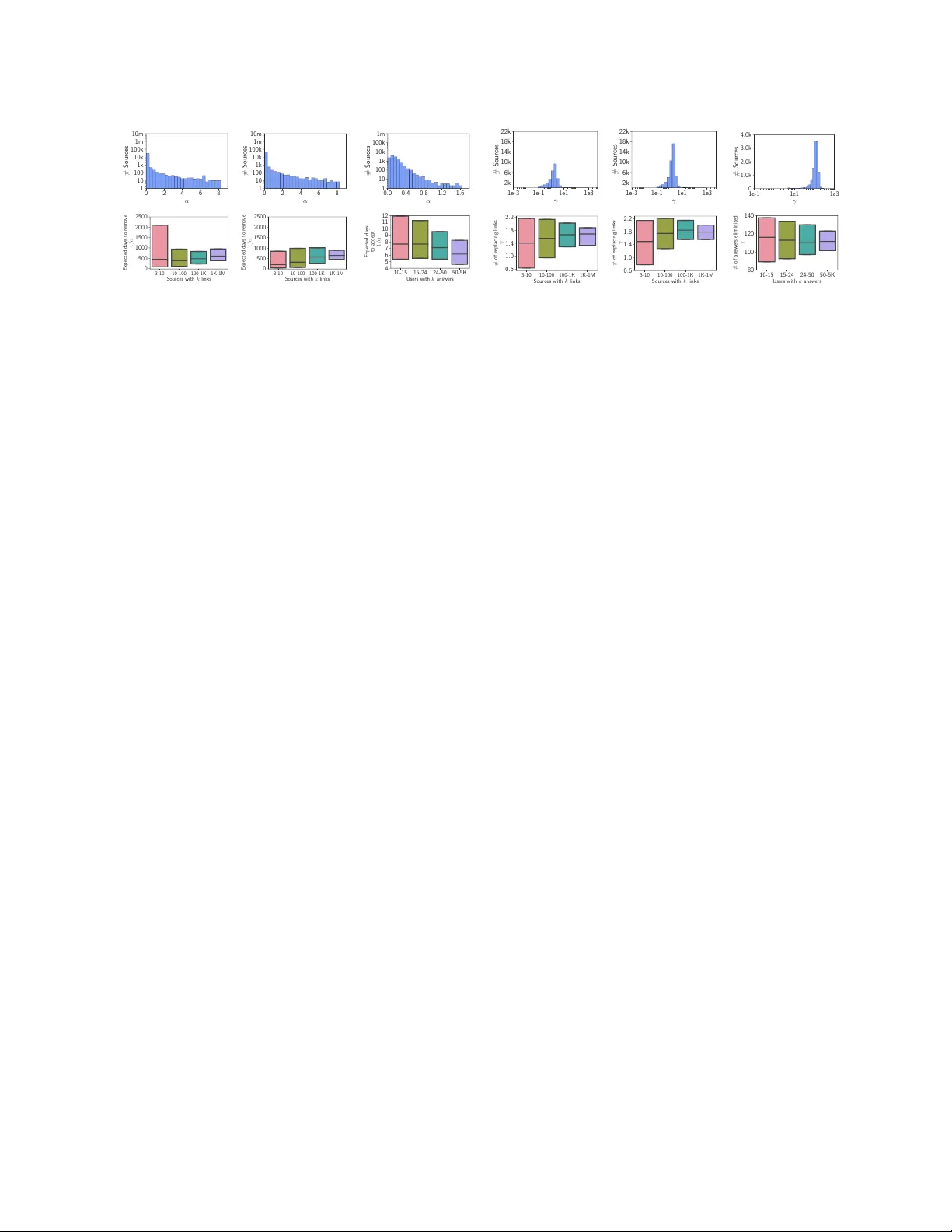
Distilling Information Reliabilit y and Source T rust w orthiness from Digital T races Behzdad T abibian 1 , Isab el V alera 2 , Mehrdad F ara jtabar 3 , Le Song 3 , Bernhard Sc hölkopf 1 , and Man uel Gomez-Ro driguez 2 1 Max Planc k Institute for Intelligen t Systems, me@btabibian.com, bs@tue.mpg.de 2 Max Planc k Institute for Softw are Systems, iv alera@mpi-sws.org, man uelgr@mpi-sws.org 3 Georgia Institute of T ec hnology , mehrdad@gatech.edu, lsong@cc.gatec h.edu Abstract Online kno wledge rep ositories typically rely on their users or dedicated editors to ev aluate the reliability of their con tent. These ev aluations can b e view ed as noisy measurements of both information reliability and information source trustw orthiness. Can we lev erage these noisy ev aluations, often biased, to distill a robust, un biased and interpretable measure of both notions? In this pap er, we argue that the temp or al tr ac es left by these noisy ev aluations give cues on the reliabilit y of the information and the trustw orthiness of the sources. Then, we prop ose a temp oral p oin t pro cess mo deling framework that links these temporal traces to robust, unbiased and interpretable notions of information reliabilit y and source trustw orthiness. F urthermore, we develop an efficien t con vex optimization pro cedure to learn the parameters of the mo del from historical traces. Experiments on real-w orld data gathered from Wikip e dia and Stack Overflow show that our mo deling framework accurately predicts ev aluation even ts, provides an interpretable measure of information reliability and source trust worthiness, and yields interesting insigh ts ab out real-world even ts. 1 In tro duction Ov er the years, the W eb has b ecome a v ast rep ository of information and knowledge ab out a ric h v ariety of topics and real-world even ts – one muc h larger than an ything we could hop e to accumulate in conv entional textb ooks and traditional news media outlets. Unfortunately , due to its immediate nature, it also contains an ev er-growing num b er of opinionated, inaccurate or false facts, urban legends and unv erified stories of unknown or questionable origin, which are often refuted ov er time. 1 , 2 T o ov ercome this problem, online knowledge rep ositories, such as Wikip e dia , Stack Overflow and Quor a , put in place different ev aluation mechanisms to increase the reliability of their conten t. These mechanisms can b e typically classified as: I. Refutation: A user refutes, challenges or questions a statement contributed by another user or a piece of conten t originated from an external web source. F or example, in Wikip e dia , an editor can refute a questionable, false or incomplete statement in an article by removing it. I I. V erification: A user verifies, accepts or supp orts a statement contributed by another user or a piece of conten t originated from an external w eb source. F or example, in Stack Overflow , a user can accept or up-v ote the answers provided by other users. Ho wev er, these ev aluation mechanisms only provide noisy measuremen ts of the reliabilit y of information and the trustw orthiness of the information sources. Can we leverage these noisy measurements, often biased, to distill a robust, unbiased and interpretable measure of b oth notions? 1 http://www.snopes.com 2 http://www.factcheck.org 1 In this pap er, we argue that the temp or al tr ac es left by these noisy ev aluations giv e cues on the reliabilit y of the information and the trustw orthiness of the sources. F or example, while statemen ts provided by an un trustw orthy user will b e often sp otted by other users as unreliable and refuted quickly , statements provided b y trustw orthy users will b e refuted less often. Ho wev er, at a particular p oint in time, a statement ab out a complex, contro versial or time evolving topic, story , or more generally , know le dge item , may b e refuted by other users indep enden tly of the source. In this case, quick refutations will not reflect the trustw orthiness of the source but the intrinsic unreliability of the knowledge item the statement refers to. T o explore this h yp othesis, we prop ose a temp oral p oin t pro cess mo deling framework of refutation and v erification in online knowledge rep ositories, which leverages the ab o ve mentioned temp oral traces to obtain a meaningful measure of b oth information reliability and source trustw orthiness. The k ey idea is to disentangle to what extent the temp oral information in a statement ev aluation (verification or refutation) is due to the in trinsic unreliability of the in volv ed knowledge item, or to the trustw orthiness of the source providing the statemen t. T o this aim, we mo del the times at which statements are added to a knowledge item as a counting pro cess, whose intensit y captures the temp oral evolution of the reliability of the item—as a knowledge item b ecomes more reliable, it is less likely to b e mo dified. Moreov er, each adde d statement is supp orted by an information source and ev aluated by the users in the knowledge rep ository at some p oint after its addition time. Here, w e mo del the ev aluation time of each statement as a surviv al pro cess, whic h starts at the addition time of the statement and whose intensit y captures both the trust worthiness of the asso ciated source and the unreliabilit y of the inv olv ed knowledge item. F or the prop osed mo del, we develop an efficient metho d to find the optimal mo del parameters that jointly maximize the lik eliho o d of an observed set of statement addition and ev aluation times. This efficient algorithm allo ws us to apply our framew ork to ∼ 19 million addition and refutation even ts in ∼ 100 thousand Wikip e dia articles and ∼ 1 million addition and verification even ts in ∼ 378 thousand questions in Stack Overflow . Our exp erimen ts show that our mo del accurately predicts whether a statement in a Wikip e dia article (an answ er in Stack Overflow ) will b e refuted (verified), it provides interpretable measures of source trustw orthiness and information reliabilit y , and yields in teresting insights: 3 I. Most active sources are generally more trustw orthy , how ever, trustw orth y sources can b e also found among less active ones. I I. Changes on the reliability of a Wikip e dia article ov er time, as inferred by our framework, match external notew orthy even ts. I II. Questions and answ ers in Stack Overflow cluster into groups with similar lev els of difficulty and p opularit y . Related work. The research area most closely related to ours is on truth discov ery and source trust- w orthiness. The former aims at resolving conflicts among noisy information published by different sources and the latter assesses the quality of a source by means of its ability to pro vide correct factual information. Most previous works hav e studied b oth problems together and measure the trust worthiness of a source using link-based measures [ 4 , 17 ], information retriev al based measures [ 28 ], accuracy-based measures [ 8 , 9 , 29 ], con tent-based measures [ 2 ], and graphical mo del analysis [ 23 , 30 , 31 , 32 ]. A recent line of work [ 20 , 21 , 22 , 27 ] also considers scenarios in which the truth may change o ver time. Ho wev er, previous work typically shares one or more of the follo wing limitations, which we address in this work: (i) they only supp ort kno wledge triplets (sub ject, predicate, ob ject) or structured knowledge; (ii) they assume there is a truth , how ever, a statemen t may b e under discussion wh en a source writes ab out it; and, (iii) they do not distinguish betw een the unreliabilit y of the knowledge item to which the statement refers and the trustw orthiness of the source. T emp oral p oint pro cesses hav e b een previously used to mo del information cas cades [ 15 , 11 , 5 ], so cial activit y [ 14 , 19 , 12 ], badges [ 10 ], netw ork evolution [ 18 , 13 ], opinion dynamics [ 6 ], or pro duct comp etition [ 26 ]. Ho wev er, to the b est of our knowledge, the present work is the first that leverages temp oral p oin t pro cesses in the context of information reliability and source trustw orthiness. 3 W e will release code for our inference method, datasets and a w eb interface for exploring results at http://btabibian.com/projects/reliabilit y . 2 2 Bac kground on T emp oral P oin t Pro cesses A temp oral p oin t pro cess is a sto chastic pro cess whose realization consists of a list of discrete ev ents lo calized in time, { t i } with t i ∈ R + and i ∈ Z + . Many different types of data pro duced in so cial media and the W eb can b e represen ted as temp oral p oin t pro cesses [ 6 , 13 , 26 ]. A temp oral p oint pro cess can b e equiv alently represented as a counting pro cess, N ( t ) , which records the num b er of even ts up to time t , and can b e c haracterized via its conditional in tensity function — a sto c hastic mo del for the time of the next even t giv en all the times of previous even ts. More formally , the conditional intensit y function λ ∗ ( t ) (in tensity , for short) is giv en by λ ∗ ( t ) dt := P { ev ent in [ t, t + dt ) |H ( t ) } = E [ dN ( t ) |H ( t )] , where dN ( t ) ∈ { 0 , 1 } denotes the increment of the process, H ( t ) denotes the history of ev ent times { t 1 , t 2 , . . . , t n } up to but not including time t , and the sign ∗ indicates that the intensit y may dep end on the his- tory . Then, given a time t i > t i − 1 , we can also c haracterize the conditional probability that no even t happ ens during [ t i − 1 , t i ) and the conditional density that an even t o ccurs at time t i as S ∗ ( t i ) = exp ( − R t i t i − 1 λ ∗ ( τ ) dτ ) and f ∗ ( t i ) = λ ∗ ( t i ) S ∗ ( t i ) , resp ectiv ely . F urthermore, we can express the log-likelihoo d of a list of ev ents { t 1 , t 2 , . . . , t n } in an observ ation window [0 , T ) as [1] L = n X i =1 log λ ∗ ( t i ) − Z T 0 λ ∗ ( τ ) dτ . (1) This simple log-likelihoo d will later enable us to learn the parameters of our mo del from observed data. Finally , the functional form of the intensit y λ ∗ ( t ) is often designed to capture the phenomena of interests. Some useful functional forms we will use later are [1]: I. P oisson pro cess. The intensit y is assumed to b e indep endent of the history H ( t ) , but it can be a time-v arying function, i.e. , λ ∗ ( t ) = g ( t ) > 0 ; I I. Ha wkes Pro cess. The intensit y mo dels a m utual excitation b etw een even ts, i.e. , λ ∗ ( t ) = µ + α X t i ∈H ( t ) κ ω ( t − t i ) , (2) where κ ω ( t ) is the triggering k ernel, µ > 0 is a baseline in tensity indep endent of history . Here, the o ccurrence of each historical even t increases the intensit y by a certain amount determined by the kernel and the weigh t α > 0 , making the intensit y history dep endent and a sto chastic pro cess by itself; and, I II. Surviv al pro cess. There is only one even t for an instan tiation of the pro cess, i.e. , λ ∗ ( t ) = g ( t )(1 − N ( t )) , (3) where λ ∗ ( t ) b ecomes 0 if an even t already happ ened b efore t and g ( t ) > 0 . 3 Prop osed Mo del In this section, we formulate our mo deling framework of v erification and refutation in kno wledge rep ositories, starting with the data representation it uses. Data representation. The digital traces generated during the construction of a knowledge rep ository can b e represented using the following three entities: the statements , whic h are asso ciated to particular know le dge items , and the information sour c es , whic h supp ort each of the statements. More sp ecifically: — A n information sour c e is an entit y that supp orts a statement in a knowledge rep ository , i.e. , the web source an editor uses to supp ort a paragraph in Wikip e dia , the user who p osts an answer on a Q&A site, or 3 the softw are developer who con tributes a piece of co de in Github . W e denote the set of information sources in a kno wledge rep ository as S . — A statement is a piece of information contributed to a knowledge rep ository , which is characterized b y its addition time t , its ev aluation time τ , and the information source s ∈ S that supp orts it. Here, we represen t each statement as the triplet e = ( source ↓ s, t ↑ addition time , ev aluation time ↓ τ ) , (4) where an ev aluation may corresp ond either to a v erification or refutation. 4 Moreo ver, if a statement is never refuted or verified, then we set τ = ∞ . — A know le dge item is a collection of statements. F or example, a knowledge item corresp onds to an article in Wikip edia ; to a question and its answer(s) in a Q&A site; or to a softw are pro ject on Github . Here, w e gather the history of the d -th knowledge item, H d ( t ) , as the set of statements added to the knowledge item d up to but not including time t , i.e. , H d ( t ) = { e i | t i < t } . (5) In most knowledge rep ositories, one can recov er the source, addition time, and ev aluation time of each statemen t added to a kno wledge item. F or example, in Wikip e dia , there is an edit history for each Wikip e dia article; on Q&A sites, all answ ers to a question are recorded; and, in Github , there is a version control mec hanism to keep track of all changes. Generativ e pro cess for kno wledge ev olution. Our hypothesis is that the temp oral information related to statemen t additions and ev aluations reflects b oth the reliability of knowledge items and the trust worthiness of information sources. More sp ecifically , our intuition is as follows: I. A reliable knowledge item should b e stable in the sense that new statement addition will b e rare, and it is less likely to b e changed compared to unreliable items. Suc h notion of reliabilit y should b e reflected in the statemen t addition pro cess—as a knowledge item b ecomes more reliable, the num b er of statement addition ev ents within a unit of time should b e smaller. I I. A trustw orthy information source should result in statements which are verified quickly and refuted rarely . Suc h notion of trustw orthiness should b e therefore reflected in its statement ev aluation time—the more trustw orthy an information source is, the shorter (longer) the time it will take to verify (refute) its statemen ts. In our temp oral p oint pro cess mo deling framework, we build on the ab o ve intuition to accoun t for b oth information reliability and source trustw orthiness. In particular, for each knowledge item, we mo del the statemen t addition times { t i } as a counting pro cess whose in tensity directly relates to the reliabilit y of the item—as a knowledge item b ecomes more reliable, it is less likely to b e changed. Moreo ver, each addition time t i is marked by its information source s i and its ev aluation time τ i , which in turn dep ends on the source trust worthiness and also hav e an impact on the o verall reliability of the knowledge item—the v erification (refutation) of statemen ts supp orted by trustw orth y sources result in an increase (dec rease) of the reliability of the knowledge item. More in detail, for each knowledge item d , w e represent the statement addition times { t i } as a counting pro cess N d ( t ) , whic h counts the num b er of statements that hav e been added up to but not including time t . Th us, we characterize the statement addition pro cess using its corresp onding intensit y λ ∗ d ( t ) as E [ dN d ( t ) |H d ( t )] = λ ∗ d ( t ) dt, (6) whic h captures the ev olution of the reliability of the knowledge item ov er time. Here, the smaller the intensit y λ ∗ ( t ) , the more reliable the knowledge item at time t . Moreov er, since a knowledge item consists of a collection 4 F or clarity , w e assume that a knowledge repository either uses refutation or v erification. How ever, our mo del can be readily extended to knowledge rep ositories using b oth. 4 of statements, the ov erall reliability of the knowledge item will also dep end on the individual reliability of its added statements through their ev aluations—the verification (refutation) of statemen ts may result in an increase (decrease) of the reliability of the knowledge item, leading to an inhibition (increase) in the intensit y of the statement additions to the knowledge item. A dditionally , every time a statemen t i is added to the knowledge item d , the corresp onding information source s i ∈ S is sampled from a distribution p ( s | d ) and the ev aluation time τ i is sampled from a surviv al pro cess, which we represen t as a binary counting pro cess N i ( t ) ∈ { 0 , 1 } , in which t = 0 corresp onds to the time in whic h the statement is added and b ecomes one when t = τ i − t i . Here, w e characterize this surviv al pro cess using its corresp onding intensit y µ ∗ i ( t ) as E [ N i ( t ) |H d ( t )] = µ ∗ i ( t ) dt, (7) whic h captures the temp oral evolution of the reliability of the i -th statement added to the kno wledge item. Here, the smaller the intensit y µ ∗ i ( t ) , the shorter (longer) time it will tak e to v erify (refute) it. This intensit y will dep end, on the one hand, on the current in trinsic reliability of the corresp onding knowledge item and, on the other hand, on the trustw orthiness of the source supp orting the statement. Next, we formally define the functional form of the intensities λ ∗ d ( t ) and µ ∗ i ( t ) , and the source distribution p ( s | d ) . Kno wledge item reliability . F or each knowledge item d , we consider the following form for its reliability function, or equiv alently , its statement addition intensit y: λ d ( t ) = X j φ d,j k ( t − t j ) | {z } item intrinsic reliabilit y + X e i ∈H d ( t ) w > d γ s i g ( t − τ i ) | {z } effect of past ev aluations . (8) In the ab ov e expression, the first term is a mixture of kernels k ( t ) accounting for the temp oral evolution of the in trinsic reliability of a knowledge item ov er time, and the second term accounts for the effect that previous statemen t ev aluations hav e on the o verall reliability of the knowledge item. Here, w d and γ s i are L -length v ectors whose elements indicate, resp ectively , the w eight (presence) of each topic in the knowledge item and the p er-topic influence of past ev aluations of statements back ed by source s i . Finally , the function g ( t ) is a nonnegativ e triggering kernel, which mo dels the deca y of the influence of past ev aluations ov er time. If the ev aluation is a refutation then we assume γ s i ≥ 0 , since a refuted statement typically decreases the reliability of the knowledge item and thus triggers the arriv al of new statements to replace it. If the ev aluation is a v erification, we assume γ s i ≤ 0 , since a verified statement typically increases the reliabilit y of the knowledge item and th us inhibits the arriv al of new statemen ts to the knowledge item. As a consequence, the ab o ve design results in an “ev aluation aw are" pro cess, whic h captures the effect that previous statement ev aluations exert on the reliability of a knowledge item. Statemen t reliability . As discussed ab ov e, every statement addition even t e i is marke d with an ev aluation time τ i , which we mo del using a surviv al pro cess. The pro cess is “statement driven" since it starts at the time when the statement addition ev ent o ccurs and, within the pro cess, t = 0 corresp onds to the addition time of the statemen t. F or each statement i , we adopt the following form for the statement reliability or, equiv alently , for the intensit y asso ciated with its surviv al pro cess: µ i ( t ) = (1 − N i ( t )) h X j β d,j k ( t + t i − t j ) | {z } item intrinsic reliabilit y + w > d α s i | {z } source trustw orthiness i . (9) In the ab ov e expression, the first term is a mixture of kernels k ( t ) accounting for the temp oral evolution of the in trinsic reliability of the corresp onding knowledge item d and the second term captures the trustw orthiness of the source that supp orts the statement. Here, w d and α s i are L-length nonnegative vectors whose elements indicate, resp ectiv ely , the weigh t (presence) of each topic in the knowledge item d and the trustw orthiness of source s i in each topic. Since the elemen ts w d sum up to one, the pro duct w d α s i can b e seen as the av erage 5 trust worthiness of the source s i in the kno wledge item d . With this mo deling choice, the higher the parameter α s i , the quic ker the ev aluation of the statement. Then, if the ev aluation is a refutation, a high v alue of α s i implies low trustw orthiness of the source s i . In contrast, if it is a verification, a high v alue of α s i implies high trust worthiness. Finally , note that the reliability of a statement, as defined in Eq. 9, reflects how quickly (slo wly) it will b e refuted or verified, and the reliability of a knowledge item, as defined in Eq. 8, reflects how quickly (slo wly) new statemen ts are added to the knowledge item. Selection of source. The source p opularity p ( s | d ) t ypically dep ends on the topics contained in the kno wledge item d . Therefore, we consider the following form for the source distribution: p ( s | d ) = L X ` =1 w d,` p ( s | ` ) , (10) where w d,` denotes the w eight of topic ` in kno wledge item d and p ( s | ` ) ∝ M ultinomial ( π ` ) is the distribution of the sources for topic ` , i.e. , the vector π ` con tains the probability of each source to b e assigned to a topic ` . 4 Efficien t P arameter Estimation In this section, w e show how to efficiently learn the parameters of our mo del, as defined b y Eqs. 8 and 9, from a set of statemen t addition and ev aluation even ts. Here, we assume that the topic weigh t vectors w d are given 5 . More sp ecifically , given a set of sources S and a set of knowledge items D with histories {H 1 ( T ) , . . . , H |D| ( T ) } , spanning a time perio d [0 , T ) , w e find the model parameters { π ` } L ` =1 , { β d } |D| d =1 , { φ d } |D| d =1 , { α s } |S | s =1 and { γ s } |S | s =1 , b y solving the following maximum likelihoo d estimation (MLE) problem maximize L ( { π ` } , { β d } , { φ d } , { α s } , { γ s } ) sub ject to π ` > 0 , β d > 0 , φ d > 0 , α s > 0 , 1 T π ` = 1 where the log-likelihoo d is given by L = |D| X d =1 X i : e i ∈H d ( T ) log p ( t i |H d ( t i ) , φ d , { γ s } , w d ) | {z } statements additions + |D| X d =1 X i : e i ∈H d ( T ) log p (∆ i | t i , β d , { α s } , w d ) | {z } statements ev aluations + |D| X d =1 X i : e i ∈H d ( T ) log p ( s i |{ π ` } , w d ) | {z } sources p opularity . (11) In the ab ov e likelihoo d, the first term accoun ts for the times at which statements are added to the knowledge item, the second term accoun ts for the times at which statements are ev aluated, and the third term accounts for the probability that source s i is assigned to the statement addition even t e i . Since the first tw o terms corresp ond to likelihoo ds of temp oral p oin t pro cesses, they can b e computed using Eq. 1. The third term is simply giv en by p ( s i |{ π ` } L ` =1 , w d ) = P L ` =1 w d,` π ` ( s i ) , where π ` ( s i ) denotes the s i -th elemen t of π ` . Remark ably , the ab ov e terms can b e expressed as linear combinations of logarithms and linear functions or comp ositions of linear functions with logarithms and thus easily follow that the ab ov e optimization problem is jointly conv ex in all the parameters. Moreov er, the problem can b e decomp osed into three indep enden t problems, which can b e solved in parallel obtaining lo cal solutions that are in turn globally optimal. F or kno wledge rep ositories using refutation, i.e. , γ s > 0 , we solve b oth the first and second problem by adapting the algorithm by Zhou et al. [ 33 ]. F or knowledge rep ositories using verification, i.e. , γ s 6 0 , w e solve the first 5 There are many topic mo deling to ols to learn the topic weight vectors w d . 6 800 1600 2800 3600 Do cuments 0.04 0.06 0.08 RMSE (a) α 800 1600 2800 3600 Do cuments 0.24 0.32 0.40 0.48 0.56 RMSE (b) γ 800 1600 2800 3600 Do cuments 1.09 1.11 1.12 1.14 1.16 RMSE (c) β 800 1600 2800 3600 Do cuments 4.00 4.05 4.10 4.15 RMSE (d) φ Figure 1: Performance of our mo del parameter estimation metho d on synthetic data in terms of ro ot mean squared error (RMSE). The estimation b ecomes more accurate as we feed more knowledge items into our estimation pro cedure. Ho wev er, since each new knowledge item increases the num b er of β and φ parameters, once the source parameter estimation b ecomes accurate enough, the estimation error for β and φ flattens. problem using cvxpy [ 7 ] and the second problem b y adapting the algorithm by Zhou et al. [ 33 ]. In b oth cases, the third problem can b e computed analytically as π ` ( s ) = P |D| d =1 w d ( ` ) ˆ π d ( s ) P |D| d =1 P |S | s 0 =1 w d ( ` ) ˆ π d ( s 0 ) , (12) where w d ( ` ) denotes the ` -th elemen t of w d , and ˆ π d ( s ) is the probability that source s is assigned to a statemen t in knowledge item d . In particular, ˆ π d ( s ) can b e computed as ˆ π d ( s ) = n d,s P |S | s 0 =1 n d,s 0 , (13) where n d,s is the n umber of statement addition even ts in the history of the knowledge item that are back ed b y source s , i.e. , |{ e i ∈ H d ( T ) | s i = s }| . In practice, we found that adding a ` -1 p enalt y term on the parameters { β d } , i.e. , η P d || β d || 1 , which we set b y cross-v alidation, a voids ov erfitting and impro ves the predictiv e p erformance of our mo del. 5 Exp erimen ts on Syn thetic Data Our goal in this section is to inv estigate if our parameter estimation metho d can accurately recov er the true mo del parameters from statement addition and ev aluation even ts. W e examine this question using a syn thetically generated dataset from our probabilistic mo del. Exp erimen tal setup. W e set the n umber of sources to |S | = 400 , the total num b er of knowledge items to |D | = 3 , 600 , and assume the ev aluation mechanism is refutation. W e assume there is only one topic and then, for each source, we sample its trust worthiness α s from the Beta distribution B eta (2 . 0 , 5 . 0) and its parameter γ s from the uniform distribution U (0 , b ) , where b = 0 . 03 × max ( { α s } s ∈S ) . F or the temporal evolution of the in trinsic reliability in the addition and ev aluation pro cesses, we consider a mixture of three radial basis (RBF) kernels lo cated at times t j = 0 , 6 , 12 , with standard deviations of 2 and 0 . 5 , resp ectively . Then, for eac h knowledge item, we first pick one of the kernel lo cations j uniformly at random, whic h determines the only active k ernel for b oth the addition and the ev aluation pro cesses in the knowledge item, and sample their asso ciated parameters, φ d,j and β d,j , from the log-normal distribution ln N (3 . 5 , 0 . 1) and the uniform distribution U (0 , 0 . 2 φ d ) , resp ectiv ely . Moreo v er, we assume that only up to five (different) sources are active in each knowledge item, which w e pick at random, and then draw a source probabilit y vector for these five activ e sources in the knowledge item from a Diric hlet distribution with parameter 0 . 5 . The choice of prior distributions for the mo del parameters ensures enough v ariability across knowledge items and sources, so 7 1.0 3.0 5.0 7.0 9.0 11.0 T (Months) 0.0 0.2 0.4 0.6 0.8 1.0 A UC Our Mo del Intrinsic Logistic Regression Source Random 10 30 50 70 90 % T raining data 0.2 0.3 0.4 0.5 0.6 Accuracy Our Mo del Random Co rrect Answ ers Source (a) Wikip e dia (b) Stack Overflow Figure 2: Prediction p erformance. Panel (a) shows the AUC achiev ed by our mo del and three baselines (In trinsic, Source and Logistic Regression) for predicting whether a statement will b e remov ed (refuted) from a Wikip e dia article within a time p eriod of T after it is p osted; for different v alues of T . P anel (b) shows the success probabilit y achiev ed by our mo del and tw o baseline (Source and Correct Answer) at predicting which answ er to a question, among several answers, will b e even tually verified in Stack Overflow . that the mo del parameters can b e recov ered. Finally , we generate addition and refutation samples from the resulting addition and ev aluation pro cesses during the time in terv al (0 , 15] . Results. W e ev aluate the accuracy of our mo del estimation pro cedure by means of the ro ot mean square error (RMSE) b etw een the true ( x ) and the estimated ( ˆ x ) parameters, i.e. , RMSE ( x ) = p E [( x − ˆ x ) 2 ] . Figure 1 shows the parameter estimation error with resp ect to the n umber of knowledge items used to estimate the mo del parameters. Since the source parameters α and γ are shared across knowledge items, the estimation b ecomes more accurate as w e feed more kno wledge items in to our estimation pro cedure. Ho wev er, ev ery time we observ e a new kno wledge item, the num b er of parameters increases with an additional β d and φ d . Therefore, the kno wledge item parameter estimation only b ecomes more accurate as a consequence of a better estimation of the source parameters. As so on as the source parameter estimation becomes go o d enough , the estimation do es not improv e further and the estimation error flattens. 6 Exp erimen ts on Real Data In this section, we apply our mo del estimation metho d to large-scale data gathered from tw o knowledge rep ositories: Wikip e dia , which uses refutation as ev aluation mechanism ( i.e. , deleted statements), and Stack Overflow , which uses verification ( i.e. , accepted answers). First, we show that our mo del can accurately predict whether a particular statement in a Wikip e dia article will b e refuted after a certain p erio d of time, as w ell as which of the answers to a question in Stack Overflow will b e accepted. Then, we show that it pro vides meaningful measures of web source trustw orthiness in Wikip e dia and user trustw orthiness in Stack Overflow . Finally , we demonstrate that our mo del can b e used to: (i) pinp oint the changes on the intrinsic reliability of a Wikip e dia article ov er time and these changes match external notew orthy contro versial even ts; and, (ii) find questions and answ ers in Stack Overflow with similar lev els of in trinsic reliabilit y , which in this case corresp ond to p opularity and difficulty . Data description and metho dology . T o build our Wikip edia dataset, w e gather complete edit history , up to July 8, 2014, for 1 million Wikip e dia English articles and track all the references (or links) to sources within each of the edits. Then, for each article d , we record for each added statement, its asso ciated source s i , its addition time t i , and its refutation (deletion) time τ i , if any . Such recorded data allows us to reconstruct the history of eac h article (or knowledge item), as given by Eq. 5. Moreo v er, since w e can only exp ect our mo del estimation metho d to provide reliable and accurate results for articles and web sources with enough n umber of even ts, we only consider articles with at least 20 link additions and w eb sources that are used in at least 10 references. After these prepro cessing steps, our dataset consists of ∼ 50 thousand w eb sources that app eared in ∼ 100 thousand articles, by means of ∼ 10 . 4 million addition even ts and ∼ 9 million 8 Music P olitics Rank domain Pr. rm. in domain Pr rm. in 6 mon ths 6 mon ths 1 guardian.co.uk 0 . 15 n ytimes.com 0 . 18 2 rollingstone.com 0 . 17 guardian.co.uk 0 . 19 3 n ytimes.com 0 . 17 go ogle.com 0 . 20 6 billb oard.com 0 . 26 usato da y .com 0 . 24 13 m tv.com 0 . 32 whitehouse.go v 0 . 29 Last t witter.com 0 . 56 cia.com 0 . 45 T able 1: T op 20 most p opular w eb sources from Wikip e dia in each topic ranked by the probability that a link from them is remov ed within 6 months (Most reliable on top). refutation (deletion) even ts. The significant drop in the num b er of articles can b e attributed to the large n umber of incomplete articles on Wikip edia, which lack reasonable num b er of citations. Finally , we run the (Python library) Gensim [ 24 ] on the latest revision of all do cumen ts in the dataset, with 10 topics and default parameters, to obtain the topic weigh t vectors w d , and apply our mo del estimation metho d, describ ed in Section 4. Both in Eqs. 8 and 9, w e used 19 RBF kernels, spaced ev ery 9 months w ith standard deviation of 3 mon ths. In Eq. 8, we used exp onen tial triggering kernels with ω = 0 . 5 hours − 1 . T o build our Stack Overflow dataset, w e gathered history of answ ers from Jan uary 1, 2011 up to June 30, 2011, for ∼ 500 thousand questions 6 . Then, for each answer, we record the question d it b elongs to, the user s i who p osted the answer, its addition time t i , and its verification (acceptance) time τ i , if any . Similarly as in the Wikip e dia dataset, such recorded data allo ws us to reconstruct the history of each question (or kno wledge item), as giv en by Eq. 5. Again, since our mo del estimation metho d can only provide reliable and accurate results for questions and users with enough num b er of even ts, we only consider questions with an accepted answer (if any exist) within 4 da ys of publication time and users who p osted at least 4 accepted answ ers. After these prepro cessing steps, our data consists of ∼ 378 thousand questions which accumulate ∼ 724 thousand addition even ts (answers) and ∼ 224 thousand v erification even ts (accepted answers). In this case, we assume a single topic and therefore the w eight vector w d b ecomes a scalar v alue of 1 . Finally , we apply our mo del estimation metho d, describ ed in Section 4. In this case, in Eqs. 8 and 9, we used single constan t kernels β d and φ d , resp ectiv ely , since the intrinsic reliability of questions in Stack Overflow does not t ypically change ov er time. In Eq. 8, we used step functions as triggering kernels, since the inhibiting effect of an accepted answer do es not decay ov er time. In b oth datasets, our parameter estimation metho d runs in ∼ 4 hours using a single machine with 10 cores and 64 GB RAM. Can we predict if a statemen t will b e remov ed from Wikip edia? Our mo del can answ er this question b y solving a binary classification problem: predict whether a statement will b e remov ed (refuted) within a time p eriod of T after it is p osted. — Exp erimental setup: W e first split all addition even ts into a training set ( 90 % of the data) and a test set (the remaining 10 %) at random, then fit the parameters of the information surviv al pro cesses given b y Eq. 9 using only the ev aluation times of the addition even ts from the training set, and finally predict whether particular statements in the test set will b e remov ed within a tim e p erio d of T after it is p osted. W e compare the p erformance of our mo del with three baselines: “In trinsic", “Source" and “Logistic Regression." “In trinsic" attributes all changes in an article to the intrinsic (un)reliability of that do cumen t. W e can capture this assumption in our mo del by assuming that the parameter α s in Eq. 9 is set to zero. Inspired by the mo del prop osed b y Adler and De Alfaro [ 2 ], we implement the baseline “Source”, which only accoun ts for the trustw orthiness of the source that supp orts a statement, i.e. , it assumes that the intrinsic reliability of the article, parametrized by β d in Eq. 9, is set to zero. Finally , “Logistic Regression" is a logistic regression mo del that uses the source identit y (in one-hot representation), the do cument topic vector and the addition 6 Dataset av ailable at https://archive.o rg/details/stackexchange . 9 Stac k Overflo w Rank user-id ranking P accept in 4 da ys 1 318425 top 0.30% 0 . 93 2 405015 top 0.07% 0 . 81 3 224671 top 0.01% 0 . 81 138 246342 top 0.12% 0 . 53 139 616700 top 0.36% 0 . 53 Last 344491 top 0.97% 0 . 53 T able 2: Stack Overflow users with more than 100 answers (140 users) ranked by the probabilit y that answer they provide is verified within 4 da ys (Most reliable on top). The table also shows the ranking pro vided by Stack Overflow . time of links as features. Here, we train a different logistic regression mo del p er time window. — R esults: Since the dataset is highly unbalanced (only 25% of statements in the test set survive longer than 6 months), we ev aluate the classification accuracy in terms of the area under the ROC curve (AUC), a standard metric for quantifying classification p erformance on unbalanced data. Figure 2(a) shows the AUC ac hieved by our mo del and the baselines for differen t v alues of T . Our mo del alwa ys ac hieves AUC v alues o ver 0 . 69 , it impro ves its p erformance as T increases, and outp erforms all baselines across the full sp ectrum of v alues of T . The “Source" baseline exhibits a comparable p erformance to our metho d for low v alues of T , how ever, its p erformance barely improv es as T increases, in contrast, the “Intrinsic" baseline p erforms p oorly for low v alues of T but exhibits a comparable p erformance to our metho d for high v alues of T . Finally , “Logistic Regression" achiev es an AUC low er than our metho d across the full sp ectrum of v alues of T . The ab o ve results suggest that refutations that o ccur quickly after a statement is p osted, are mainly due to the untrust worthiness of the source; while refutations that occur later in time are due to the intrinsic unreliabilit y of the article. As a consequence, our model, by accounting for b oth source trustw orthiness and in trinsic reliability of information, can predict b oth quick and slow refutations more accurately than mo dels based only on one of these tw o factors. Can we predict which of the an sw ers to a question in Stac k Ov erflow will b e accepted? Unlik e Wikip edia where each article receives multiple ev aluations ( i.e. , deleted links), w e hav e only one ev aluation ( i.e. , accepted answer) for every question in Stack Overflo w. This prop ert y preven ts us from estimating question difficulty in the test set and subsequently making predictions similar to that of Wikip e dia . Ho wev er, w e can estimate users’ reliability from all the questions in the training set and predict which of several comp eting answers to a question will b e most likely v erified. — Exp erimental setup: W e first split all questions (and corresp onding answers) into a training set (90% of the questions) and test set (the remaining 10%) at random, then fit the parameters of the ev aluation pro cess given by Eq. 9 using only the ev aluation times of the answers in the training set, and finally predict whic h answers will b e accepted in the test set by computing the exp ected verification time for all answers to a question using the fitted mo del and selecting the earliest estimated v erification time. W e compare the p erformance of our mo del with tw o baselines: “Source” and “Correct Answers". “Source” only accounts for the trustw orthiness of the sources (users) and ignores the intrinsic reliability (difficult y) of the ques tions. Th us, it computes the exp ected verification time of an answer in the test set as th e av erage verification time of all the answers provided by its asso ciated source user in the training set. Then, for each question in the test set, this baseline selects the answer with the low est exp ected v erification time. “Correct Answers" ranks sources (users) according to the num b er of accepted answers p osted by each user in the training set. Then, for eac h question in the test set, it selects the answer with the highest ranked asso ciated source. — R esults: Figure 2(b) summarizes the results by means of success rate for different training set sizes. Note that, unlik e in the Wikip e dia exp eriment, this prediction task do es not corresp ond to a binary classification problem and therefore AUC is not a suitable metric in this case. Our mo del alwa ys achiev es a rate of success o ver 0 . 47 , consistently b eats b oth baselines and, as exp ected, it b ecomes more accurate as w e feed more 10 0 2 4 6 8 α 1 10 100 1k 10k 100k 1m 10m # Sources 0 2 4 6 8 α 1 10 100 1k 10k 100k 1m 10m # Sources 0.0 0.4 0.8 1.2 1.6 α 1 10 100 1k 10k 100k 1m # Sources 3-10 10-100 100-1K 1K-1M Sources with k links 0 500 1000 1500 2000 2500 Exp ected da ys to remove 1 /α 3-10 10-100 100-1K 1K-1M Sources with k links 0 500 1000 1500 2000 2500 Exp ected da ys to remove 1 /α 10-15 15-24 24-50 50-5K Users with k answ ers 4 5 6 7 8 9 10 11 12 Exp ected da ys to accept 1 /α Music P olitics Stack Overflow (a) Analysis of parameter α 1e-3 1e-1 1e1 1e3 γ 2k 6k 10k 14k 18k 22k # Sources 1e-3 1e-1 1e1 1e3 γ 2k 6k 10k 14k 18k 22k # Sources 1e-1 1e1 1e3 γ 0 1.0k 2.0k 3.0k 4.0k # Sources 3-10 10-100 100-1K 1K-1M Sources with k links 0.6 1.0 1.4 1.8 2.2 # of replacing links γ 3-10 10-100 100-1K 1K-1M Sources with k links 0.6 1.0 1.4 1.8 2.2 # of replacing links γ 10-15 15-24 24-50 50-5K Users with k answ ers 80 100 120 140 # of answ ers eliminited γ Music P olitics Stack Overflow (b) Analysis of parameter γ Figure 3: Source T rustw orthiness. Panels (a) and (b) show the distributions of the parameters α and γ for the W eb sources in Wikip e dia for the topics “m usic” and “p olitics” and for the Stack Overflow users, resp ectiv ely . In b oth panels, the top row shows the distributions across all sources, while the b ottom row sho ws the distributions for four set of sources, group ed by their p opularit y in the case of Wikip e dia and b y the n umber of answered questions in the case of Stack Overflow users. In Wikip e dia , the ev aluation mechanism is refutation and thus larger v alues of 1 / α corresp ond to more trustw orthy users whose contributed conten t is refuted more rarely . In Stack Overflow , the ev aluation mechanism is verification and thus smaller v alues of 1 / α corresp ond to more trust worth y users whose contributed conten t is verified quick er. In b oth cases, higher v alues of γ imply a larger impact on the ov erall reliability of the kno wledge item ( i.e. , article and question) after an ev aluation. ev ents into the estimation pro cedure. Note that, for most questions, there are more than t wo answers and the success rate of a random baseline is 0 . 41 . The ab ov e results suggest that one needs to account for b oth the users’ trustw orthiness and the difficulty of the questions to b e able to accurately predict which answ er will b e accepted, in agreement with previous work [3]. Do our mo del parameters pro vide a meaningful and in terpretable measure of source trustw or- thiness? W e answer this question by analyzing the source parameters γ s and α s estimated b y our parameter estimation metho d, b oth in Wikip e dia and Stack Overflow . First, we pay atten tion to the 20 most used web sources in Wikip e dia for t wo topics, i.e. , p olitics and music, and activ e users in Stack Overflow with ov er 100 answers, and rank them in terms of source trustw orthiness ( i.e. , in Wikip e dia , higher trustw orthiness means low er α s , while in Stack Overflow higher trustw orthiness means higher α s ). Then, we compute the probability that a statement supp orted by each source is refuted in less than 6 months in Wikip e dia or verified in less than 4 days in Stack Overflow due to only the source trust worthiness ( i.e. , setting β = 0 ). T able 1 and 2 summarize the results, which reveal sev eral interesting patterns. F or example, our mo del identifies so cial netw orking sites such as T witter, which often accumulate questionable facts and opinionated information, as untrust w orthy sources for music in Wikip e dia . Similarly , for articles related to p olitics, some notable news agencies close to the left of the p olitical sp ectrum are considered to b e more trust worth y , in agreement with previous studies on p olitical bias in Wikip edia [ 16 ]. Moreo ver, users with high reputation, as computed b y Stack Overflow itself, are indeed identified in our framew ork as trustw orth y . Ho wev er, the ranking among these users in terms of reputation do es not alwa ys matc h our measure of trustw orthiness since it also takes into account other factors such as num b er of up-votes on questions and answers. Next, we lo ok at the source parameters at an aggregate lev el b y means of their empirical distribution across users. Figure 3 summarizes the results, which show that: (i) the distributions are remark ably alike across b oth topics in Wikip edia and (ii) γ v alues are distributed similarly both for Stack Overflow and Wikip e dia , how ever, α v alues are distributed differen tly since they capture a different mechanism, verification instead of refutation. Finally , we group web sources in Wikip e dia b y p opularity and users of Stack Overflow b y num b er of contributed answers, and analyze the source parameters. W e summarize the results in Figure 3, 11 2005 2007 2009 2011 2013 0.0 0.5 1.0 1.5 addition 0.0 0.1 0.2 evaluation 2003 2005 2007 2009 2011 2013 0.0 2.0 4.0 addition 0.0 2.0 4.0 evaluation (a) Barac k Obama’s biography (b) George W. Bush’s biography 2011-07 2011-11 2012-03 2012-07 2012-11 0.0 1.0 2.0 addition 0.0 0.01 0.02 evaluation 2006 2008 2010 2012 2014 0.0 0.2 0.4 addition 0.0 0.02 0.04 evaluation (c) “2011 military interv ention" in Liby a (d) TV show Prison Break Figure 4: T emporal evolution of the article intrinsic reliability for four Wikip e dia articles. The blue (red) line sho ws intensit y of statement addition (ev aluation) pro cess. Changes on the in trinsic reliability closely matc h external notew orthy even ts, often con trov ersial, related to the corresp onding article. whic h show that: (i) more p opular web sources in Wikip e dia and more active users in Stack Overflow tend to b e more trustw orthy , i.e. , lo wer (higher) α in Wikip e dia ( Stack Overflow ); (ii) p opular sources in Wikip e dia ha ve a larger impact on the reliability of the article, triggering a larger num b er of new statements additions ( i.e. , larger v alues of γ ) after a refutation; and, (iii) there is ample v ariation across sources in terms of trust worthiness within all groups. What do the temp oral ev olution of the intrinsic reliabilit y of Wikipedia articles tell us? In this section, we show that changes on the intrinsic reliability of a Wikip e dia article closely match external notew orthy even ts, often con trov ersial, related to the article. Figure 4 shows the intrinsic reliability b oth in the statement addition pro cess (first term in Eq. 8), which captures the arriv al of new information, and the verification pro cess (first term in Eq. 9), which captures the contro v ersy of the article, for four differen t articles – Barack Obama’s biography , 7 George W. Bush’s biograph y , 8 an article on 2011 military interv en tion in Liby a, 9 and an article on the TV show Prison Break. 10 Eac h of the articles exhibits different characteristic temp oral patterns. In the tw o biographical articles and the article on the TV sho w, we find several p eaks in the arriv al of new information and contro versy ov er time, whic h typically match remark able real-world ev ents. F or example, in Barack Obama’s article, the p eaks in early 2007 and mid-2008 coincide with the time in which he won the Demo cratic nomination and the 2008 US election campaign; and, in the Prison Break’s article, the p eaks coincide with the broadcasting of the four seasons. In contrast, in the article ab out 2011 military interv ention in Lib ya, we only find one p eak, lo calized at the b eginning of the article life cycle, which is follow ed by a steady decline in which the contro v ersy lasts for a few months longer than the arriv al of new information. A comparison of the temp oral patterns of new information arriv als and con trov ersy within an article reveals a more subtle phenomenon: while sometimes a p eak in the arriv al of new information also results in a p eak of contro v ersy , there are p eaks in the arriv al that do not trigger contro versy and vice-versa. What do the in trinsic reliabilit y of Stac k Ov erflow questions tell us? W e answer this question by analyzing the parameters β d and φ d estimated by our parameter estimation metho d for questions in Stack Overflow . F or each question, such parameters are unidimensional since, unlik e Wikip e dia , the reliability of questions in Stack Overflow does not typically change ov er time. Moreov er, the parameters hav e natural in terpretation: β reflects the easiness of a question and φ reflects its p opularity . Figures 5(a-b) sho w the empirical marginal distribution of the parameters across questions and Figure 5(c) sho ws the joint distribution for questions with β > 0 . The results rev eal four clusters: questions which are 7 https://en.wikipedia.org/wiki/Barack_Obama 8 https://en.wikipedia.org/wiki/George_W._Bush 9 https://en.wikipedia.org/wiki/2011_military_intervention_in_Lib ya 10 https://en.wikipedia.org/wiki/Prison_Break 12 0.0 0.04 0.08 0.12 Easiness, β 10k 1m # Sources (a) P ( β ) 0 40 80 120 P opula rit y , φ 10k 40k 70k 100k # Sources (b) P ( φ ) 0 20 40 60 80 100 P opula rit y , φ 0.00 0.02 0.04 0.06 0.08 0.10 0.12 Easiness, β (c) P ( φ, β ) Figure 5: Difficult y vs. p opularit y in Stack Overflow questions. P anels (a) and (b) show the distribution of the parameters β and φ , whic h represent resp ectively the difficult y and the p opularity of Stack Overflow questions. Panel (c) shows the joint distribution of b oth parameters β and φ . Higher v alue of β ( φ ) implies easier (more p opular) questions. p opular and easy , questions which are p opular but difficult, questions that are not p opular and difficult, and questions that are not p opular but easy . 7 Conclusion In this pap er, we prop osed a temp oral p oint pro cess modeling framework of refutation and verification in online kno wledge rep ositories and dev elop ed an efficient conv ex optimization pro cedure to fit the parameters of our framew ork from historical traces of the refutations and verifications provided by the users of a knowledge rep ository . Then, w e exp erimented with real-world data gathered from Wikip e dia and Stack Overflow and sho wed that our framework accurately predicts refutation and verification even ts, pro vides an interpretable measure of information reliability and source trust worthiness, and yields in teresting insights ab out real-world ev ents. Our work also op ens many interesting directions for future work. F or example, natural follow-ups to p oten tially improv e the expressiveness of our mo deling framework include: 1. Consider sources can change their trustw orthiness ov er time due to, e.g. , increasing their exp ertise [ 25 ]. 2. Allo w for non-binary refutation and verification even ts, e.g. , partial refutations, ratings. 3. Augmen t our mo del to consider the trustw orthiness of the user who refutes or verifies a statement. 4. Reduce n umber of parameters in the mo del b y clustering sources and knowledge items. Moreo ver, we exp erimen ted with data gathered from Wikip edia and Stack Overflow , how ever, it w ould b e interesting to apply our mo del (or augmented versions of our mo del) to other knowledge repositories ( e.g. , Quor a ), other types of online collab orative platforms ( e.g. , Github ), and the W eb at large. Finally , one can think of using our measure of trustw orthiness, as inferred by our estimation metho d, to p erform credit assignmen t in online collab orative platforms—in Wikip e dia , one could use our mo del to identify trustw orthy users (or dedicated editors) who can p otentially make an article more reliable and stable. 8 A c kno wledgmen ts Authors w ould like to thank Martin Thoma for his comments in impro ving the quality of pap er. 13 References [1] O. Aalen, O. Borgan, and H. K. Gjessing. Survival and event history analysis: a pr o c ess p oint of view . Springer, 2008. [2] B. T. Adler and L. De Alfaro. A conten t-driven reputation system for the wikip edia. In WWW , 2007. [3] A. Anderson, J. Kleinberg, and S. Mullainathan. Assessing Human Error Against a Benc hmark of P erfection. In KDD , 2016. [4] A. Boro din, G. O. Rob erts, J. S. Rosenthal, and P . T saparas. Link analysis ranking: algorithms, theory , and exp erimen ts. A CM T r ansactions on Internet T e chnolo gy , 5(1):231–297, 2005. [5] H. Daneshmand, M. Gomez-Rodriguez, L. Song, and B. Schölk opf. Estimating diffusion net work structures: Recov ery conditions, sample complexity & soft-thresholding algorithm. In ICML , 2014. [6] A. De, I. V alera, N. Ganguly , S. Bhattachary a, and M. Gomez-Ro driguez. Learning and forecasting opinion dynamics in so cial netw orks. In NIPS , 2016. [7] S. Diamond and S. Boyd. CVXPY: A Python-embedded mo deling language for conv ex optimization. Journal of Machine L e arning R ese ar ch , 2016. [8] X. L. Dong, E. Gabrilovic h, G. Heitz, W. Horn, K. Murph y , S. Sun, and W. Zhang. F rom data fusion to kno wledge fusion. VLDB , 2014. [9] X. L. Dong, E. Gabrilovic h, K. Murph y , V. Dang, W. Horn, C. Lugaresi, S. Sun, and W. Zhang. Kno wledge-based trust: Estimating the trustw orthiness of w eb sources. VLDB , 2015. [10] N. Du, H. Dai, R. T rivedi, U. Upadhy a y , M. Gomez-Ro driguez, and L. Song. Recurrent Marked T emp oral P oint Pro cess: Em b edding Even t History to V ector. In KDD , 2016. [11] N. Du, L. Song, M. Gomez-Ro driguez, and H. Zha. Scalable influence estimation in contin uous-time diffusion net works. In NIPS , 2013. [12] M. F ara jtabar, N. Du, M. Gomez-Ro driguez, I. V alera, H. Zha, and L. Song. Shaping so cial activity by incen tivizing users. In NIPS , 2014. [13] M. F ara jtabar, Y. W ang, M. Gomez-Ro driguez, S. Li, H. Zha, and L. Song. Co ev olve: A joint p oint pro cess mo del for information diffusion and netw ork co-evolution. In NIPS , 2015. [14] M. F ara jtabar, X. Y e, S. Harati, L. Song, and H. Zha. Multistage campaigning in so cial netw orks. In NIPS , 2016. [15] M. Gomez-Ro driguez, D. Balduzzi, and B. Schölk opf. Uncov ering the tem poral dynamics of diffusion net works. In ICML , 2011. [16] S. Greenstein and F. Zhu. Is wikip edia biased? The Americ an e c onomic r eview , 102(3):343–348, 2012. [17] Z. Gyöngyi, H. Garcia-Molina, and J. Pedersen. Combating web spam with trustrank. In VLDB , 2004. [18] D. Hun ter, P . Smyth, D. Q. V u, and A. U. Asuncion. Dynamic ego centric mo dels for citation netw orks. In ICML , 2011. [19] M. Karimi, E. T av akoli, M. F ara jtabar, L. Song, and M. Gomez-Ro driguez. Smart Broadcasting: Do y ou wan t to b e seen? In KDD , 2016. [20] Y. Li, Q. Li, J. Gao, L. Su, B. Zhao, W. F an, and J. Han. On the discov ery of ev olving truth. In KDD , 2015. 14 [21] X. Liu, X. L. Dong, B. C. Ooi, and D. Sriv asta v a. Online data fusion. VLDB , 2011. [22] A. Pal, V. Rastogi, A. Mac hanav a jjhala, and P . Bohannon. Information integration o ver time in unreliable and uncertain environmen ts. In WWW , 2012. [23] J. P asternack and D. Roth. Laten t credibilit y analysis. In WWW , 2013. [24] R. Řehůřek and P . So jk a. Softw are F ramework for T opic Mo delling with Large Corp ora. In LREC , 2010. [25] U. Upadh ya y , I. V alera, and M. Gomez-Ro driguez. Uncov ering the dynamics of crowdlearning and the v alue of knowledge. In WSDM , 2017. [26] I. V alera and M. Gomez-Rodriguez. Modeling adoption and usage of comp eting pro ducts. In ICDM , 2015. [27] S. W ang, D. W ang, L. Su, L. Kaplan, and T. F. Ab delzaher. T o wards cyb er-ph ysical systems in so cial spaces: The data reliability challenge. In R TSS , 2014. [28] M. W u and A. Marian. Corroborating answers from multiple w eb sources. In W ebDB , 2007. [29] H. Xiao, J. Gao, Q. Li, F. Ma, L. Su, Y. F eng., and A. Zhang. T ow ards confidence in the truth: A b ootstrapping based truth discov ery approach. In KDD , 2016. [30] X. Yin and W. T an. Semi-supervised truth discov ery . In WWW , 2011. [31] B. Zhao and J. Han. A probabilistic mo del for estimating real-v alued truth from conflicting sources. Pr o c e e dings of QDB , 2012. [32] B. Zhao, B. I. Rubinstein, J. Gemmell, and J. Han. A bay esian approach to discov ering truth from conflicting sources for data integration. VLDB , 2012. [33] K. Zhou, H. Zha, and L. Song. Learning triggering k ernels for multi-dimensional hawk es pro cesses. In ICML , 2013. 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment