디지털 흔적으로 보는 정보 신뢰도와 출처 신뢰성 추정
본 논문은 위키피디아와 Stack Overflow와 같은 온라인 지식 저장소에서 발생하는 ‘추가’와 ‘평가’ 시점을 시간적 점과 프로세스로 모델링한다. 이를 통해 지식 항목의 내재적 신뢰도와 정보를 제공한 출처의 신뢰성을 동시에 추정하고, 학습된 파라미터를 기반으로 미래의 평가 이벤트를 예측한다.
저자: Behzad Tabibian, Isabel Valera, Mehrdad Farajtabar
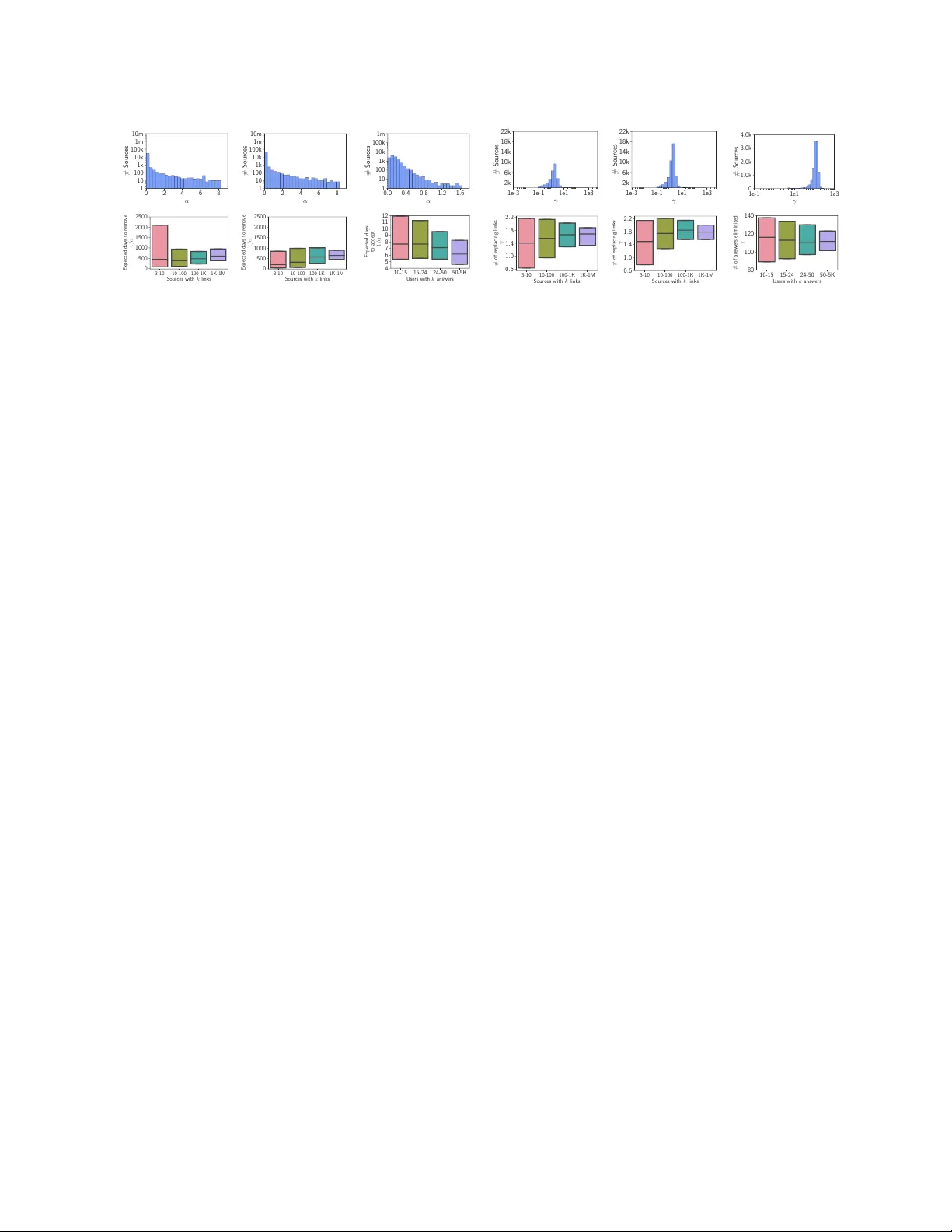
본 논문은 온라인 지식 저장소에서 사용자가 남기는 두 가지 핵심 디지털 흔적—‘문장(또는 답변) 추가 시점’과 ‘그에 대한 검증·반박(평가) 시점’—을 시간적 점과 프로세스로 정형화하여, 정보의 신뢰도와 출처의 신뢰성을 동시에 추정하는 새로운 프레임워크를 제안한다.
1. **문제 정의 및 동기**
위키피디아, Stack Overflow, Quora 등은 사용자·편집자들의 ‘refutation(반박)’과 ‘verification(검증)’ 메커니즘을 통해 콘텐츠 품질을 관리한다. 그러나 이러한 메커니즘은 본질적으로 노이즈가 섞인 관측값이며, 편향된 평가가 존재한다. 기존 연구는 주로 구조화된 삼중항(주제‑객체‑속성)이나 링크 기반 신뢰도 추정에 머물렀으며, (i) 진실이 시간에 따라 변한다는 점, (ii) 지식 항목 자체의 불안정성(내재적 신뢰도)과 출처의 신뢰성을 구분하지 못한다는 한계가 있었다.
2. **모델 설계**
- **지식 항목의 추가 프로세스**: 각 항목 d에 대해 문장 추가 시점을 카운팅 프로세스 N₍d₎(t)로 모델링하고, 그 조건부 강도 λ₍d₎(t)를 ‘항목 내재적 신뢰도’와 ‘과거 평가의 누적 효과’의 합으로 정의한다. λ₍d₎(t) = Σⱼ φ₍d,j₎ k(t‑tⱼ) + Σ_{i∈H₍d₎(t)} γ₍sᵢ₎ g(t‑τᵢ) 로 표현되며, k와 g는 각각 시간적 변화를 포착하는 커널이다. 검증은 γ₍sᵢ₎<0(신뢰도 상승)으로, 반박은 γ₍sᵢ₎>0(신뢰도 하락)으로 매핑된다.
- **문장의 평가 프로세스**: 각 문장 i는 추가 시점 tᵢ에서 시작되는 생존 프로세스 Nᵢ(t)로 모델링한다. 강도 µᵢ(t) = (1‑Nᵢ(t))
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기