Local minima in training of neural networks
There has been a lot of recent interest in trying to characterize the error surface of deep models. This stems from a long standing question. Given that deep networks are highly nonlinear systems optimized by local gradient methods, why do they not s…
Authors: Grzegorz Swirszcz, Wojciech Marian Czarnecki, Razvan Pascanu
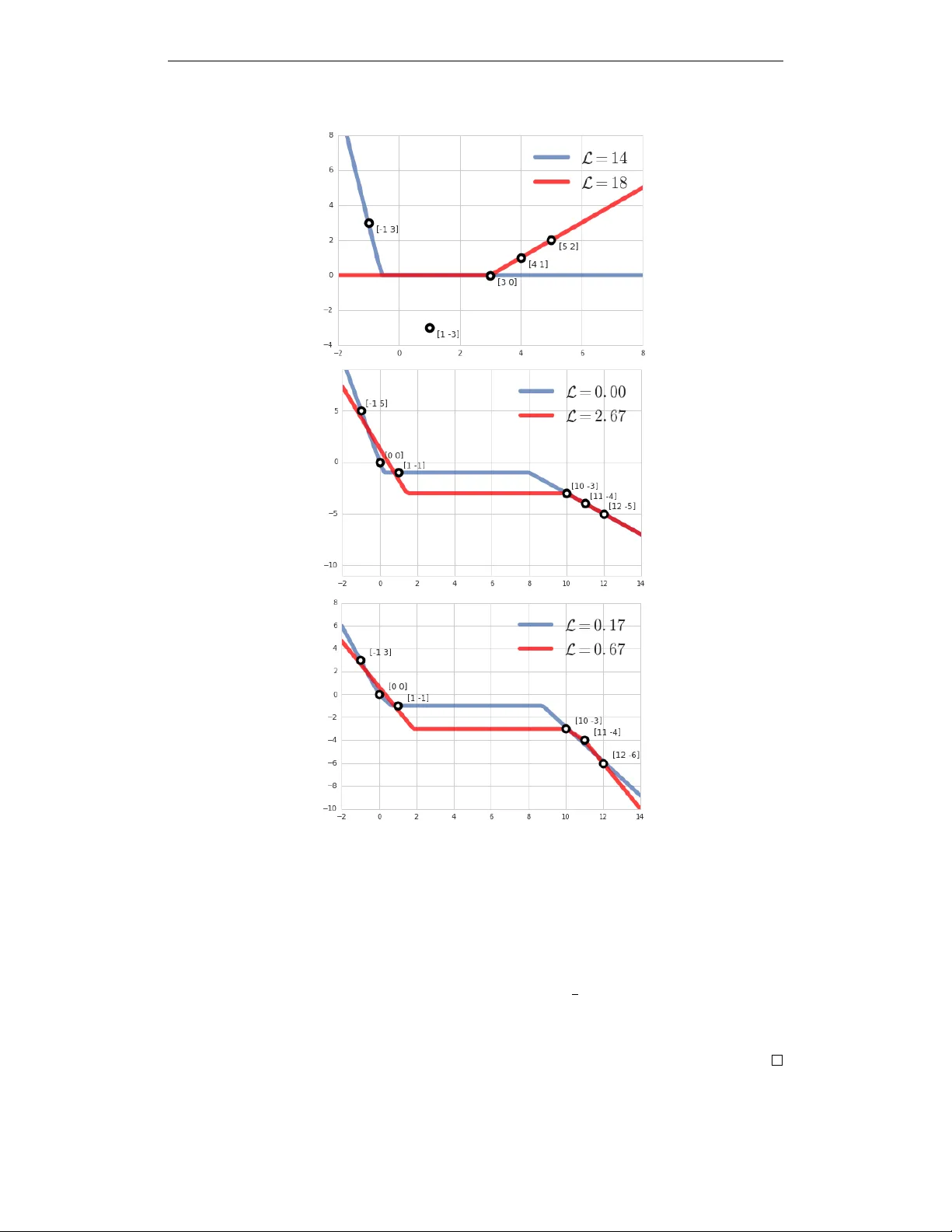
L O C A L M I N I M A I N T R A I N I N G O F N E U R A L N E T W O R K S Grzegorz ´ Swirszcz, W ojciech Marian Czarnecki & Razvan P ascanu DeepMind London, UK { swirszcz,lejlot,razp } @google.com A B S T R AC T T raining of a neural network is often formulated as a task of finding a “good” minimum of an error surface - the graph of the loss expressed as a function of its weights. Due to the gro wing popularity of deep learning, the classical problem of studying the error surfaces of neural networks is now in the focus of many researchers. This stems from a long standing question. Given that deep networks are highly nonlinear systems optimized by local gradient methods, why do they not seem to be affected by bad local minima? As much as it is often observed in practice that training of deep models using gradient methods works well, little is understood about why it happens. A lot of research ef forts has been dedicated recently for pro ving the good beha vior of training neural networks. In this paper we adapt the complementary approach of studying the possible obstacles. W e present several concrete examples of datasets which cause the error surface to hav e a strongly suboptimal local minimum. 1 I N T RO D U C T I O N Deep Learning (LeCun et al., 2015; Schmidhuber, 2015) is a fast growing subfield of machine learning, with many impressiv e results. Images are being classified with super-human accuracy (e.g He et al. (2015); Szegedy et al. (2016)), the quality of machine translation is reaching new heights (e.g. Sutske ver et al. (2014); Bahdanau et al. (2015); W u et al. (2016)). For reinforcement learning, deep architectures had been successfully used to learn to play Atari games (Mnih et al., 2015; 2016) or the game of Go (Silv er et al., 2016). As alw ays, in case of a fast-progressing domain with practical application, our theoretical understanding is moving forwards slo wer than the fast forefront of empirical success. W e are training more and more comple x models, in spite of the fact that this training relies on non-con ve x functions which are optimized using local gradient descent methods. In the light of these empirical results, many ef forts ha ve been made to e xplain why the training of deep networks works so well (see the literature revie w in the next section). The authors believ e, that equally important as it is to try to understand how and why the training of neural networks beha ves well, it is also to understand what can go wrong. There are empirical examples of things not always working well. Learning is susceptible to adver - sarial examples (Nguyen et al., 2015; Goodfello w et al., 2014; Fa wzi et al., 2016). Neural networks identifying road stop signs as an interior of a refrigerator, invis ible to human e yes perturbations make a perfectly good model suddenly misclassify , are some of the well known examples. Additionally , numerous “tricks of the trade”, like batch normalization or skip connections, had to be inv ented to address slo w con ver gence or poor results of learning. That is because, despite the optimism, the “out of the box” gradient descent is often not working well enough. The approach in this paper is to look for fundamental reasons for training not beha ving well. The goal was to construct as small as possible datasets that lead to emergence of bad local minima. The error surface is an e xtremely complicated mathematical object. The authors belie ve, that the strategy for improving our understanding of the structure of error surface is to b uild a knowledge base around it. Constructing examples such as the ones presented serves two main purposed. First, it can help formulate the necessary assumptions behind theorems showing the con vergence of neural network to a good minima, assumptions that will exclude these datasets. The second goal is more practical - to inspire design of better learning algorithms. 1 2 L I T E R A T U R E R E V I E W One hypothesis for why learning is well behav ed in neural networks is put forward in Dauphin et al. (2013). W e will refer to it as the “no bad local minima” hypothesis. The key observ ation of this work is that intuitions from low-dimensional spaces are usually misleading when moving to high-dimensional spaces. The w ork makes a connection with profound results obtained in statistical physics. In particular Fyodoro v & W illiams (2007); Bray & Dean (2007) showed, using the Replica Theory (Parisi, 2007), that random Gaussian error functions hav e a particular friendly structure. Namely , if one looks at all the critical points of the function and plots error v ersus the (Morse) index of the critical point (the number of ne gati ve eigen values of the Hessian), these points align nicely on a monotonically increasing curve. That is, all points with a low index (note that ev ery minimum has this index equal to 0 ) have roughly the same performance, while critical points of high error implicitly hav e a large number of ne gati ve eigen v alue which means they are saddle points. The claim of Dauphin et al. (2013) is that the same structure holds for neural netw orks as well, when they become large enough. This provides an appealing conjecture of not only why learning results in well performing models, b ut also why it does so reliably . Similar claim is put forward in Sagun et al. (2014). These intuitions can also be traced back to the earlier work of Baldi & Hornik (1989), which shows that an MLP with a single linear intermediate layer has no local minima, only saddle points and a global minimum. Extensions of these early results can be found in Saxe et al. (2014; 2013). Choromanska et al. (2015) pro vides a study of the conjecture that rests on recasting a neural network as a spin-glass model. T o obtain this result several assumptions need to be made, which the authors of the work, at that time, acknowledged that were not realistic in practice. The same line of attack is taken by Kawaguchi (2016). Most of these deri v ations do not hold in the practical case of finite size datasets and finite size models. Goodfellow et al. (2016) ar gues and provides some empirical e vidence that while moving from the original initialization of the model along a straight line to the solution (found via gradient descent) the loss seems to be only monotonically decreasing, which speaks towards the apparent con vexity of the problem. Soudry & Carmon (2016); Safran & Shamir (2015) also look at the error surface of the neural network, pro viding theoretical arguments for the error surf ace becoming well-behav ed in the case of ov erparametrized models. A dif ferent vie w , presented in Lin & T egmark (2016); Shamir (2016), is that the underlying easi- ness of optimizing deep networks does not simply rest just in the emerging structures due to high- dimensional spaces, but is rather tightly connected to the intrinsic characteristics of the data these models are run on. 3 E X A M P L E S O F B A D L O C A L M I N I M A In this section we present examples of bad local minima. Speaking more precisely , we present examples of datasets and architectures such that training using a gradient descent can con ver ge to a suboptimal local minumum. 3 . 1 L O C A L M I N I M A I N A S I G M O I D - BA S E D C L A S S I FI C A T I O N One of the main goals the authors set for themselves was to show that a sigmoid-based neural network can ha ve a suboptimal “finite” local minimum. It turned out that no such e xample has been widely known to the community , and that there was no agreement to ev en whether such minimum could exist at all. 3 . 1 . 1 C O N S T R U C T I N G T H E E X A M P L E By a “finite” local minimum we understand a local minimum produced by a set of “finite” weights. That is, a minimum that is not caused by some (or all of) sigmoids saturating - trying to become a step-function. In this sense, the minima presented in section 3.3 are not finite minima. 2 The task of constructing this example turned out to be surprisingly dif ficult. The ability of a sigmoid- based neural network to “wiggle itself out” of the most sophisticated traps the authors were creating was both impressi ve and challenging. What a few first failed attempts made us realize was, that the nature of a successful example would hav e to be both geometric and analytic at the same time. What “deadlocks” a sigmoid-based neural network is not only the geometric configuration of the points, but also the v ery precise cross-ratios of distances between them. The successful construction of the presented example was a combination of studying the failed attempts generated by a guesswork and then trying to block the “escape routes” with a gradient descent in the data space. Once a “close enough” configuration of points was de- duced, the gradient descent was applied to the datapoints (in the data space) in order to minimize the length of the gradient in the weights space of the loss function. This procedure modifies the dataset in such a w ay that the (fixed) set of weights becomes a critical point of the error surf ace, b ut starting from a randomly chosen dataset almost surely produces a saddle point, instead of a minimum. Using the “close enough” configuration yields a higher chance of finding a true local minimum. The authors constructed sev eral examples of local minima for a 2-2-1 (more detailed description below) sigmoid-based neural network, using 16, 14, 12 and 10 datapoints. As of today we know 4 different examples of 10-point datasets that lead to a suboptimal minimum. The authors conjecture this is the minimum amount of points required to “deadlock” this architecture, i.e that it is not possible to construct an example using 9 or less points. All the 10-point examples hav e a geometric configuration resembling a “figure 8 shape”, as presented in Figure 1. 3 . 1 . 2 T H E E X A M P L E Let a dataset D = { ( x i , y i ) } 10 i =1 be defined as x 1 = (2 . 8 , 0 . 4) , x 2 = (3 . 1 , 4 . 3) , x 3 = (0 . 1 , − 3 . 4) , x 4 = ( − 4 . 2 , − 3 . 3) , x 5 = ( − 0 . 5 , 0 . 2) , x 6 = ( − 2 . 7 , − 0 . 4) , x 7 = ( − 3 ., − 4 . 3) , x 8 = ( − 0 . 1 , 3 . 4) , x 9 = (4 . 2 , 3 . 2) , x 10 = (0 . 4 , − 0 . 1) , y 1 = . . . = y 5 = 1 , y 6 = . . . = y 10 = 0 (see Figure 1): Figure 1: A 10 -point dataset causing the error surface of 2 − 2 − 1 sigmoid-based Neural Network to hav e a bad local minimum. Let us consider a neural network (using notation σ ( x ) = (1 + exp( − x )) − 1 ) M (( x 0 , x 1 )) = σ ( v 0 σ ( w 0 , 0 x 0 + w 0 , 1 x 1 + b 0 ) + v 1 σ ( w 1 , 0 x 1 + w 1 , 1 x 2 + b 1 ) + c ) (1) 3 and let us use the standard negati ve log-lik elihood cross-entropy loss L ( v 0 , w 0 , 0 , w 0 , 1 , b 0 v 1 , w 1 , 0 , w 1 , 1 , b 1 , c ) = − 10 X i =1 y i log( M ( x i )) + (1 − y i ) log(1 − M ( x i )) . Then there holds Theorem 1. The point ˆ W in the (9-dimensional) weight space consisting of w 0 , 0 = 1 . 05954587 , w 0 , 1 = − 0 . 05625762 , w 1 , 0 = − 0 . 03749863 , w 1 , 1 = 1 . 09518945 b 0 = − 0 . 050686 , b 1 = − 0 . 06894291 , v 0 = 3 . 76921058 , v 1 = − 3 . 72139955 , c = − 0 . 0148436 . is a local minimum of the err or surface of the neural network (1) with ne gative log-loss value 0.577738 (corr esponding to likelihood = 0.561166). This local minimum has accuracy 0 . 4 . This point is not a global minimum. Pr oof. The gradient of M at ˆ W = 0 and eigen values of the Hessian are 0 . 0007787149706922058671933702882302 0 . 09566127257833993223676197073566 0 . 1737731623214082676475029319782 0 . 22063866543084709867511532964466 0 . 4155934900503221206301551236848 0 . 9246044147479949855459498868096 3 . 803556801786189964831977345844 4 . 572940690876952005351090155283 6 . 391098807223509384191737359951 so by standard theorems from Analysis the point ˆ W is a local minimum. At the point W 0 w 0 , 0 = 5 . 67526388 , w 0 , 0 = 0 . 50532424 w 1 , 0 = − 68 . 69289398 , w 1 , 1 = − 5 . 17422295 b 0 = 3 . 23905253 , b 1 = 0 . 24047163 v 0 = − 44 . 49337769 , v 1 = 45 . 87974167 , c = − 0 . 69310206 the performance of the model is: accuracy = 0 . 8 , loss = 0 . 381913 , likelihood = 0 . 682555 , therefore ˆ W is not a global minimum. Remark 1. It is worth noting that we ar e not claiming that W 0 is a global minimum. In fact it is not even a minimum at all. Note the very high values of v 0 and v 1 . It happens because the final sigmoid is struggling to appr oximate a step function. It is a common phenomenon in tr aining neur al networks, the tr aining does not con ver ge to a minimum, but gets stopped while trying to con ver ge to a point at infinity . Remark 2. The point w 0 , 0 = 22 . 3641243 , w 0 , 1 = − 12 . 53928375 , w 1 , 0 = − 44 . 85849762 , w 1 , 1 − 3 . 51257443 b 0 = − 35 . 75595093 , b 1 = − 23 . 58968163 v 0 = 15 . 43178844 , v 1 − 15 . 02632332 , c = − 0 . 40546528 with loss = 0 . 475135 , likelihood = 0 . 621801 accur acy = 0 . 7 is yet another suboptimal point of con ver gence of the tr aining. 4 3 . 2 L O C A L M I N I M A I N A R E C T I FI E R - B A S E D R E G R E S S I O N Rectifier-based models are the de facto standard in most applications of neural networks. In this section we present 3 e xamples of local minima for regression using a single layer with 1, 2 and 3 hidden rectifier units on 1 -dimensional data (see Figure 2). Remark 3. F or the ReLU-s, the activation function is simply the max between 0 and the linear pr ojection of the input. Hence, it has two modes of operation, it is either in the linear r e gime or the saturated r e gime. Obviously , no gradient flows thr ough a saturated unit, hence a particular simple mechanism for loc king a network in a suboptimal solution is to have a subset of datapoints suc h that all units (e.g. on a given layer) ar e saturated, and there is no gradient for fitting those points. W e will refer to such points as being in the blind spot of the model and explor e this phenomenon mor e pr operly in section 4. Remark 4. The examples pr esented in this section go be yond r elying solely on the of blind-spots of the model. For the sake of simplicity of our presentation we will describe in detail the case with 1 hidden neuron, the other two cases can be treated similarly . In case of one hidden neuron the regression problem becomes arg min w,b,v ,c L ( w , b, v, c ) = n X i =1 ( v · ReLU( w x i + b ) + c − y i ) 2 . (2) Consider a dataset D 1 (see Figure 2 (a)): ( x 1 , y 1 ) = (5 , 2) , ( x 2 , y 2 ) = (4 , 1) , ( x 3 , y 3 ) = (3 , 0) , ( x 4 , y 4 ) = (1 , − 3) , ( x 5 , y 5 ) = ( − 1 , 3) . Proposition 1. F or the dataset D 1 and L defined in Equation (2) the point v = 1 , b = − 3 , w = 1 , c = 0 is a local minimum of L , whic h is not a global minimum. Pr oof. There holds L (1 , − 3 , 1 , 0) = 0 + 0 + 0 + 9 + 9 = 18 , and L ( − 7 , − 4 , 1 , 0) = 4 + 1+ 0+ 9+ 0 = 14 , thus (1 , − 3 , 1 , 0) cannot be a global minimum. It remains to pro ve that (1 , − 3 , 1 , 0) is a local minimum, i.e. that L (1 + δ w , − 3 + δ b , 1 + δ v , δ c ) ≥ L (1 , − 3 , 1 , 0) for | δ w | , | δ b | , | δ v | , | δ c | suf ficiently small. W e need to consider two cases: ReLU activated at x 3 . In that case L (1 + δ w , − 3 + δ b , 1 + δ v , δ c ) = ((1 + δ v )(3 + 3 δ w − 3 + δ b ) + δ c ) 2 + ((1 + δ v )(4 + 4 δ w − 3 + δ b ) + δ c − 1) 2 + ((1 + δ v )(5 + 5 δ w − 3 + δ b ) + δ c − 2) 2 + ( δ c + 3) 2 + ( δ c − 3) 2 . W e introduce ne w variables x = ( δ w + 1)(1 + δ v ) − 1 , y = ( δ b − 3)(1 + δ v ) + 3 , z = δ c . The formula becomes (3 x + y + z ) 2 + (4 x + y + z ) 2 + (5 x + y + z ) 2 + 2 z 2 + 18 ≥ 18 , which ends the proof in this case. ReLU deactivated at x 3 . In that case L (1 + δ w , − 3 + δ b , 1 + δ v , δ c ) = δ 2 c + ((1 + δ v )(4 + 4 δ w − 3 + δ b ) + δ c − 1) 2 + ((1 + δ v )(5 + 5 δ w − 3 + δ b ) + δ c − 2) 2 + ( δ c + 3) 2 + ( δ c − 3) 2 = (4 x + y + z ) 2 + (5 x + y + z ) 2 + 3 z 2 + 18 ≥ 18 (we used x = ( δ w + 1)(1 + δ v ) − 1 , y = ( δ b − 3)(1 + δ v ) + 3 , z = δ c again). Note that due to the assumption that | δ w | , | δ b | , | δ v | , | δ c | are suf ficiently small the ReLU is always activ ated at x 1 , x 2 and deactiv ated at x 4 , x 5 . Remark 5. The point (1 , − 3 , 1 , 0) is a minimum, b ut it is not a “strict” minimum - it is not isolated, but lies on a 1-dimensional manifold at whic h L ≡ 18 instead. Remark 6. The following e xamples show that blind spots ar e not the only r eason a model can be stuck in a suboptimal solution. Even more surprisingly , they also show that the blind spots can be completely absent in the local optima, while at the same time being pr esent in the global solution. 5 a) b) c) Figure 2: Local minima for ReLU-based regression. Both lines represent local optima, where the blue one is better than the red one. a) 1 hidden neuron b) 2 hidden neurons c) 3 hidden neurons. Proposition 2. Let us consider a dataset D 2 with d = 1 , given by points ( x 1 , y 1 ) = ( − 1 , 5) , ( x 2 , y 2 ) = (0 , 0) , ( x 3 , y 3 ) = (1 , − 1) , ( x 4 , y 4 ) = (10 , − 3) , ( x 5 , y 5 ) = (11 , − 4) , ( x 6 , y 6 ) = (12 , − 5) (F igur e 2 (b)). Then, for a rectifier network with m = 2 hidden units and a squar ed err or loss the set of weights w = ( − 5 , − 1) , b = (1 , − 8) , v = (1 , − 1) , c = − 1 is a global minimum (with perfect fit) and the set of weights w = ( − 3 , − 1) , b = (4 + 1 3 , − 10) , v = (1 , − 1) , c = − 3 is a suboptimal local minimum. Pr oof. Analogous to the previous one. Maybe surprisingly , the global solution has a blind spot - all neurons deacti v ate in x 3 . Nevertheless, the network still has a 0 training error . 6 Proposition 3. Let us consider a dataset D 3 with d = 1 , given by points ( x 1 , y 1 ) = ( − 1 , 3) , ( x 2 , y 2 ) = (0 , 0) , ( x 3 , y 3 ) = (1 , − 1) , ( x 4 , y 4 ) = (10 , − 3) , ( x 5 , y 5 ) = (11 , − 4) , ( x 6 , y 6 ) = (12 , − 6) (F igur e 2 (c)). Then, for a rectifier network with m = 3 hidden units and a squared err or loss the set of weights w = ( − 1 . 5 , − 1 . 5 , 1 . 5) , b = (1 , 0 , − 13 − 1 6 ) , v = (1 , 1 , − 1) , c = − 1 is a bet- ter local minimum than the local minimum obtained for w = ( − 2 , 1 , 1) , b = (3+ 2 3 , − 10 , − 11) , v = (1 , − 1 , − 1) , c = − 3 . Pr oof. Completely analogous, using the fact that in each part of the space linear models are either optimal linear regression fits (if there is just one neuron active) or perfect (0 error) fit when two neurons are activ e and combined. Note that again that the abov e construction is not relying on the blind spot phenomenon. The idea behind this example is that if, due to initial conditions, the model partitions the input space in a suboptimal way , it might become impossible to find the optimal partitioning using gradient descent. Let us call ( −∞ , 6) the re gion I, and [6 , ∞ ) region II. Both solutions in Proposition 3 are constructed in such way that each one has the best fit for the points assigned to any given region, the only difference being the number of hidden units used to describe each of them. In the local optimum two neurons are used to describe re gion II, while only one describes region I. Symmetrically , the better solution assigns two neurons to region I (which is more comple x) and only one to region II. Conjecture 1. W e conjectur e that the cor e idea behind this construction can be generalized (in a non-trivial way) to high-dimensional pr oblems. 3 . 3 T H E FL A T T E N E D X O R - S U B O P T I M A L M O D E L S I N C L A S S I FI C A T I O N U S I N G R E L U A N D S I G M O I D S In this section we look at a slight v ariation on one of the most theoretically well-studied datasets, the XOR problem. By exploiting observ ations made in the failure modes observed for the XOR problem, we were able to construct a similar dataset, the “flattened XOR”, that results in suboptimal learning dynamics. The dataset is formed of four datapoints, where the positive class is gi ven by (1 . 0 , 0 . 0) , (0 . 2 , 0 . 6) and the negati ve one by (0 . 0 , 1 . 0) , (0 . 6 , 0 . 2) , see Figure 3. W e analyze the Figure 3: The “flattened XOR” dataset. dataset using a single hidden layer network (with either ReLU or sigmoid units). A first observ ation is that while SGD can solve the task with only 2 hidden units, full batch methods do not always succeed. Replacing gradient descent with more aggressive optimizers like Adam does not seem to help, but rather tends to make it more likely to get stuck in suboptimal solutions (T able 1). 7 a) b) Figure 4: Examples of different outcomes of learning on the flattened XOR dataset. a) Optimally con ver ged net for flattened XOR. b) Stuck net for flattened XOR. h XOR XOR fXOR fXOR XOR XOR fXOR fXOR ReLU Sigmoid ReLU Sigmoid ReLU Sigmoid ReLU Sigmoid 2 Adam 28% 79% 7% 0% GD 23% 90% 16% 62% 3 Adam 52% 98% 34% 0% GD 47% 100% 33% 100% 4 Adam 68% 100% 50% 2% GD 70% 100% 66% 100% 5 Adam 81% 100% 51% 27% GD 80% 100% 68% 100% 6 Adam 91% 100% 61% 17% GD 89% 100% 69% 100% 7 Adam 97% 100% 69% 58% GD 89% 100% 86% 100% T able 1: “Conv ergence” rate for 2- h -1 network with random initializations on simple 2-dimensional datasets using either Adam or Gradient Descent (GD) as an optimizer . Comparison between “regu- lar” XOR and fXOR - the flattened XOR Compared to the XOR problem it seems the flattened XOR problem poses e ven more issues, espe- cially for ReLU units, where with 4 hidden units one still only gets 2 out of 3 runs to end with 0 training error (when using GD). One particular observation (see Figure 4) is that in contrast with good solutions, when the model fails on this dataset, its behaviour close to the datapoints is almost linear . W e argue hence, that the f ailure mode might come from having most datapoints concentrated in the same linear region of the model (in ReLU case), hence forcing the model to suboptimally fit these points. Remark 7. In the examples we used ReLU and sigmoid activation functions, as they are the most common used in practice . The similar examples can be constructed for differ ent activation functions, however the constructions need some modifications and get mor e technically complicated. 4 B A D I N I T I A L I Z A T I O N In this section we pro ve formally a seemingly ob vious, b ut often o verlooked fact that for any re gres- sion dataset a rectifier model has at least one local minimum. The construction relies on the f act that the dataset is finite. As such, it is bounded, and one can compute conditions for the weights of any given layer of the model such that for an y datapoint all the units of that layer are saturated. Furthermore, we show that one can obtain a better solution than the one reached from such a state. The formalization of this result is as follows. W e consider a k -layer deep regression model using m ReLU units ReLU( x ) = max(0 , x ) . Our dataset is a collection ( x i , y i ) ∈ R d × R , i = 1 , . . . , N . W e denote h n ( x i ) = ReLU( W n h n − 1 ( x i ) + b n ) where the the ReLU functions are applied component-wise to the vec- 8 tor W n h n − 1 ( x i ) and h 0 ( x i ) = x i . W e also denote the final output of the model by M ( x i ) = W k h k − 1 + b k . Solving the regression problem means finding arg min ( W n ) k n =1 , ( b n ) k n =1 L (( W n ) k n =1 , ( b n ) k n =1 ) = N X i =1 [ M ( x i ) − y i ] 2 . (3) Let us state two simple yet in our opinion useful Lemmata. Lemma 1 (Constant input) . If x 1 = . . . = x N , then the solution to r egr ession (3) has a constant output M ≡ y 1 + ... + y N N (the mean of the values in data). Pr oof. Obvious from the definitions and the fact, that y 1 + ... + y N N = arg min c P N i =1 ( c − y i ) 2 . Lemma 2. If there holds W 1 x i < − b 1 for all i -s, then the model M has a constant output. Mor eover , applying local optimization does not c hange the values of W 1 , b 1 . Pr oof. Straightforward from the definitions. Combining these two lemmata yields: Corollary 1. If for any 1 ≤ j ≤ k ther e holds W n h n − 1 < − b n for all i -s then, after the training, the model M will output y 1 + ... + y N N . W e will denote M ( { a 1 , . . . , a L } ) = a 1 + ... + a L L the mean of the numbers a 1 , . . . , a L . Definition 1. W e say that the dataset ( x i , y i ) is decent if ther e e xists r such that M ( { y p : x p = x r } 6 = M ( { y p : p = 1 , . . . , N } ) . Theorem 2. Let θ = (( W n ) k n =1 , ( b n ) k n =1 ) be any point in the parameter space satisfying W n h n ( x i ) < − b n (coor dinate-wise) for all i -s. Then i) θ is a local minimum of the err or surface, ii) if the first layer contains at least 3 neurons and if the dataset ( x i , y i ) is decent, then θ is not a global minimum. Pr oof. Claim i) is a direct consequence of Corollary 1. It remains to prove ii). For that it is suf ficient to sho w an example of a set of weighs ˆ θ = (( ˆ W n ) k n =1 , ( ˆ b n ) k n =1 ) such that L (( W n ) k n =1 , ( b n ) k n =1 ) > L (( ˆ W n ) k n =1 , ( ˆ b n ) k n =1 ) . Let r be such that M ( { y p : x p = x r } ) 6 = M ( { y p : p = 1 , . . . , N } ) . Such point exists by assumption that the dataset is decent. Let H be a hyperplane passing through x r such that none of the points x s 6 = x r lies on H . Then there ex- ists a vector v such that | v T ( x s − x r ) | > 2 for all x s 6 = x r . Let γ = v T x r . W e define W 1 in such a way that the first row of W 1 is v , the second row is 2 v and the third one is v again, and if the first layer has more than 3 neurons, we put all the remaining rows of W 1 to be equal zero. W e choose the first three biases of b 1 to be − γ + 1 , − 2 γ and − γ − 1 respectiv ely . W e denote µ = M ( { y p : x p 6 = x r } ) and ν = M ( { y p : x p = x r } ) . W e then choose W 2 to be a matrix whose first row is ( ν − µ, µ − ν, ν − µ, 0 , . . . , 0) and the other rows are equal to 0 . Finally , we choose the bias vector b 2 = ( µ, 0 , . . . , 0) T . If our network has only one layer the output is ( ν − µ )ReLU( v T x p − γ + 1) − ( ν − µ )ReLU(2 v T x p − 2 γ ) + ( ν − µ )ReLU( v T x p − γ − 1) + µ. For e very x p = x r this yields ( ν − µ ) · 1 − 0 + 0 + µ = ν . For any x p 6 = x r we either hav e v T x p − γ < − 2 yielding 0 − 0 + 0 + µ = µ or v T x p − γ > 2 yielding ( ν − µ )( v T x p − γ + 1) − ( ν − µ )(2 v T x p − 2 γ ) + ( ν − µ )( v T x p − γ − 1) + µ = µ . In case the network has more than 1 hidden layer we set all W n = I (identity matrix) and b n = 0 for n = 3 , . . . , k . If we denote ¯ µ = M ( { y p : p = 1 , . . . , N } ) (mean of all labels), we get: L (( ˆ W n ) k n =1 , ( ˆ b n ) k n =1 ) = X x p 6 = x r ( y i − µ ) 2 + X x p = x r ( y i − ν ) 2 < X x p 6 = x r ( y i − ¯ µ ) 2 + X x p = x r ( y i − ¯ µ ) 2 = X y i ( y i − ¯ µ ) 2 = L (( W n ) k n =1 , ( b n ) k n =1 ) . 9 W e used the fact that for any finite set A the value M ( A ) is a strict minimum of f ( c ) = P a ∈ A ( a − c ) 2 and the assumption that ν 6 = ¯ µ . 5 D I S C U S S I O N Previous results (Dauphin et al., 2013; Saxe et al., 2014; Choromanska et al., 2015) pro vide insight- ful description of the error surface of deep models under general assumptions divorced from the specifics of the architecture or data. While such analysis is very valuable not only for building up the intuition but also for the de velopment of the tools for studying neural networks, it only pro- vides one facade of the problem. In this work focused on constructing scenarios in which learning fails, in the hope that they will help setting up right assumptions for con vergence theorems of neural networks in practical scenarios. Similar to Lin & T egmark (2016) we put forward a hypothesis that the learning is only well beha ved conditioned on the structure of the data. Understanding of the structure of the error surface is an extremely challenging problem. W e believ e that as such, in agreement with a scientific tradition, it should be approached by gradually building up a related kno wledge base, both by trying to obtain positiv e results (possibly under weakened assumptions, as it was done so f ar) and by studying the obstacles and limitations arising in concrete examples. A C K N O W L E D G M E N T S W e would want to thank Neil Rabino witz for insightful discussions. R E F E R E N C E S Bahdanau, Dzmitry , Cho, Kyunghyun, and Bengio, Y oshua. Neural machine translation by jointly learning to align and translate. In ICLR , 2015. URL 0473v6.pdf . Baldi, P . and Hornik, K. Neural networks and principal component analysis: Learning from exam- ples without local minima. Neural Networks , 2(1):53–58, 1989. Bray , Alan J. and Dean, Da vid S. Statistics of critical points of g aussian fields on lar ge-dimensional spaces. Physics Revie w Letter , 98:150201, Apr 2007. Choromanska, Anna, Henaff, Mikael, Mathieu, Micha ¨ el, Arous, G ´ erard Ben, and LeCun, Y ann. The loss surfaces of multilayer networks. In AIST A TS , 2015. Dauphin, Y ann, Pascanu, Razvan, Gulcehre, Caglar , Cho, K yunhyun, Ganguli, Surya, and Bengio, Y oshua. Identifying and attacking the saddle point problem in high dimensional non-conv ex optimization. NIPS , 2013. Fa wzi, Alhussein, Moosavi-Dezfooli, Se yed-Mohsen, and Frossard, P ascal. Robustness of classi- fiers: from adversarial to random noise. In Lee, D. D., Sugiyama, M., Luxbur g, U. V ., Guyon, I., and Garnett, R. (eds.), Advances in Neur al Information Pr ocessing Systems 29 , pp. 1632–1640. 2016. Fyodorov , Y an V . and W illiams, Ian. Replica symmetry breaking condition exposed by random matrix calculation of landscape complexity . Journal of Statistical Physics , 129(5-6):1081–1116, 2007. Goodfellow , Ian J., Shlens, Jonathon, and Sze gedy , Christian. Explaining and harnessing adv ersarial examples. CoRR , abs/1412.6572, 2014. Goodfellow , Ian J, V inyals, Oriol, and Saxe, Andre w M. Qualitatively characterizing neural network optimization problems. Int’l Confer ence on Learning Repr esentations, ICLR , 2016. 10 He, Kaiming, Zhang, Xiangyu, Ren, Shaoqing, and Sun, Jian. Delving deep into rectifiers: Surpass- ing human-lev el performance on imagenet classification. In 2015 IEEE International Confer ence on Computer V ision, ICCV 2015, Santiago, Chile, December 7-13, 2015 , pp. 1026–1034, 2015. Kawaguchi, K enji. Deep learning without poor local minima. CoRR , abs/1605.07110, 2016. LeCun, Y ann, Bengio, Y oshua, and Hinton, Geoffre y . Deep learning. Natur e , 521(7553):436–444, 5 2015. ISSN 0028-0836. doi: 10.1038/nature14539. Lin, Henry W . and T egmark, Max. Why does deep and cheap learning work so well?, 2016. URL http://arxiv.org/abs/1608.08225 . Mnih, V olodymyr , Kavukcuoglu, K oray , Silver , David, Rusu, Andrei A, V eness, Joel, Bellemare, Marc G, Gra ves, Alex, Riedmiller , Martin, Fidjeland, Andreas K, Ostrovski, Georg, et al. Human- lev el control through deep reinforcement learning. Nature , 518(7540):529–533, 2015. Mnih, V olodymyr , Badia, Adria Puigdomenech, Mirza, Mehdi, Graves, Alex, Lillicrap, Timoth y P , Harley , T im, Silver , David, and Ka vukcuoglu, K oray . Asynchronous methods for deep reinforce- ment learning. arXiv pr eprint arXiv:1602.01783 , 2016. Nguyen, Anh Mai, Y osinski, Jason, and Clune, Jeff. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In IEEE Conference on Computer V ision and P attern Recognition, CVPR 2015, Boston, MA, USA, J une 7-12, 2015 , pp. 427–436, 2015. Parisi, Giorgio. Mean field theory of spin glasses: statistics and dynamics. T echnical Report Arxiv 0706.0094, 2007. Safran, Itay and Shamir, Ohad. On the quality of the initial basin in ov erspecified neural networks. CoRR , abs/1511.04210, 2015. Sagun, Levent, Guney , Ugur , Arous, Gerard Ben, and LeCun, Y ann. Explorations on high dimen- sional landscapes. CoRR , abs/1412.6615, 2014. Saxe, Andre w , McClelland, James, and Ganguli, Surya. Learning hierarchical category structure in deep neural networks. Pr oceedings of the 35th annual meeting of the Cognitive Science Society , pp. 1271–1276, 2013. Saxe, Andrew , McClelland, James, and Ganguli, Surya. Exact solutions to the nonlinear dynamics of learning in deep linear neural network. In International Confer ence on Learning Repr esentations , 2014. Schmidhuber , J. Deep learning in neural networks: An overvie w . Neur al Networks , 61:85–117, 2015. doi: 10.1016/j.neunet.2014.09.003. Published online 2014; based on TR arXi v:1404.7828 [cs.NE]. Shamir , Ohad. Distribution-specific hardness of learning neural networks. CoRR , abs/1609.01037, 2016. Silver , David, Huang, Aja, Maddison, Chris J., Guez, Arthur, Sifre, Laurent, van den Driessche, George, Schrittwieser , Julian, Antonoglou, Ioannis, Panneershelv am, V eda, Lanctot, Marc, Diele- man, Sander , Gre we, Dominik, Nham, John, Kalchbrenner , Nal, Sutske ver , Ilya, Lillicrap, Tim- othy , Leach, Madeleine, Kavukcuoglu, Koray , Graepel, Thore, and Hassabis, Demis. Mastering the game of Go with deep neural netw orks and tree search. Natur e , 529(7587):484–489, January 2016. Soudry , Daniel and Carmon, Y air . No bad local minima: Data independent training error guarantees for multilayer neural networks. CoRR , abs/1605.08361, 2016. Sutske ver , Ilya, V inyals, Oriol, and Le, Quoc V . Sequence to sequence learning with neural net- works. In Pr oceedings of the 27th International Conference on Neural Information Processing Systems , NIPS’14, pp. 3104–3112, 2014. 11 Szegedy , Christian, V anhoucke, V incent, Ioffe, Sergey , Shlens, Jonathon, and W ojna, Zbignie w . Rethinking the inception architecture for computer vision. In 2016 IEEE Confer ence on Com- puter V ision and P attern Recognition, CVPR 2016, Las V e gas, NV , USA, J une 27-30, 2016 , pp. 2818–2826, 2016. W u, Y onghui, Schuster, Mike, Chen, Zhifeng, Le, Quoc V ., Norouzi, Mohammad, Macherey , W olf- gang, Krikun, Maxim, Cao, Y uan, Gao, Qin, Macherey , Klaus, Klingner, Jef f, Shah, Apurva, Johnson, Melvin, Liu, Xiaobing, Kaiser , Lukasz, Gouws, Stephan, Kato, Y oshikiyo, K udo, T aku, Kazawa, Hideto, Ste vens, Keith, K urian, Geor ge, P atil, Nishant, W ang, W ei, Y oung, Clif f, Smith, Jason, Riesa, Jason, Rudnick, Alex, V inyals, Oriol, Corrado, Greg, Hughes, Macduff, and Dean, Jeffre y . Google’ s neural machine translation system: Bridging the gap between human and ma- chine translation. CoRR , abs/1609.08144, 2016. URL 08144 . 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment