신경망 학습의 나쁜 지역 최소점 사례 연구
본 논문은 제한된 크기의 데이터셋과 특정 초기화 조건에서 심층 신경망이 실제로 나쁜 지역 최소점에 빠질 수 있음을 구체적인 예시를 통해 증명한다. 시그모이드 2‑2‑1 구조와 ReLU 기반 회귀·분류 모델을 대상으로 10점 이하의 작은 데이터로 구성된 반례를 제시하고, 이러한 현상이 기존 이론이 요구하는 강한 가정과 어떻게 충돌하는지를 논의한다.
저자: Grzegorz Swirszcz, Wojciech Marian Czarnecki, Razvan Pascanu
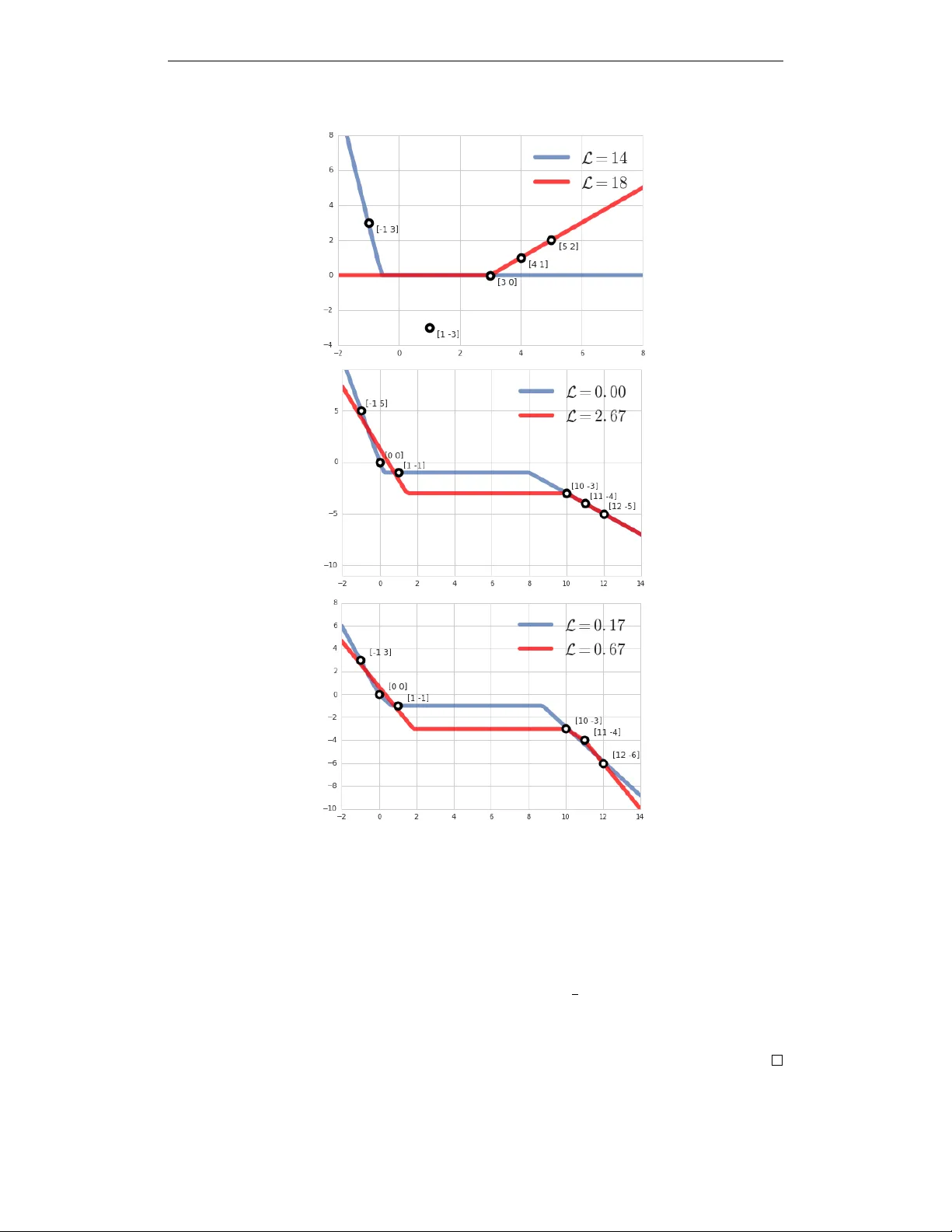
본 논문은 심층 신경망의 손실 표면에 존재할 수 있는 나쁜 지역 최소점(local minima)을 구체적인 사례를 통해 탐구한다. 연구 동기는 “깊은 네트워크는 지역 최소점에 크게 방해받지 않는다”는 가설이 최근 이론적 연구에서 널리 제시되고 있지만, 실제 학습 환경에서는 데이터 양, 초기화, 모델 구조 등에 따라 이 가설이 깨질 가능성이 있다는 점이다.
1. **배경 및 관련 연구**
- Dauphin et al. (2013)와 Sagun et al. (2014)는 고차원 공간에서 임의의 Gaussian 손실 함수가 “모스 지수(index)와 손실이 단조 증가”하는 구조를 가진다고 주장한다.
- Choromanska et al. (2015), Kawaguchi (2016) 등은 이러한 구조를 신경망에 적용하려면 무한 데이터·무한 파라미터, 가우시안 가중치 초기화 등 강력한 가정이 필요함을 인정한다.
- Goodfellow et al. (2016)와 Soudry & Carmon (2016) 등은 실험적으로 손실이 직선 경로를 따라 감소한다는 현상을 보고했지만, 이는 제한된 데이터셋에서는 보장되지 않는다.
2. **시그모이드 네트워크에서의 유한 지역 최소점**
- 저자들은 2‑2‑1 구조(입력 2, 은닉 2, 출력 1) 시그모이드 네트워크에 10개의 2차원 샘플을 배치하였다.
- 데이터는 “8자(figure‑8)” 형태로 배치되어, 양 클래스가 교차하면서도 특정 거리 비율(cross‑ratio)이 정밀하게 맞춰졌다.
- 손실 함수는 이진 교차 엔트로피이며, 특정 가중치 벡터 \(\hat W\) (모든 파라미터가 유한값)에서 그래디언트가 0이고 Hessian의 모든 고유값이 양수임을 수치적으로 확인하였다.
- 해당 최소점의 손실은 0.5777, 정확도 0.4이며, 더 큰 가중치를 갖는 다른 해(손실 0.3819, 정확도 0.8)와 비교해 명백히 열등하다. 이는 “유한한” 지역 최소점이 실제 존재함을 증명한다.
3. **ReLU 기반 회귀 모델에서의 지역 최소점**
- **예시 1 (1 은닉 유닛)**: 1‑차원 입력에 5개의 점을 배치하고, 손실은 평균 제곱 오차이다. 가중치 \((w,b,v,c)=(1,-3,1,0)\)에서 모든 미분이 0이며, 손실 18을 기록한다. 그러나 다른 파라미터 \((-7,-4,1,0)\)에서는 손실 14가 나오므로 전역 최소점이 아니다. 이 최소점은 “블라인드 스팟”(ReLU가 포화된 영역) 때문에 그래디언트가 사라지는 메커니즘으로 형성된다.
- **예시 2 (2 은닉 유닛)**: 6개의 점을 사용해 두 개의 은닉 유닛을 가진 네트워크를 학습한다. 특정 초기화에서는 두 유닛이 서로 다른 구간을 담당해 완벽히 0 오차를 달성(전역 최소점)하지만, 다른 초기화에서는 한 유닛만 활성화된 구간이 비효율적으로 나뉘어 손실이 크게 남는다. 흥미롭게도 전역 해 역시 일부 입력에서 모든 유닛이 포화(블라인드 스팟)하지만 여전히 완전 피팅이 가능하다.
- **예시 3 (3 은닉 유닛)**: 3개의 유닛을 가진 경우에도 동일한 현상이 나타난다. 지역 최소점은 입력 공간을 비대칭적으로 분할해 복잡한 구간에 유닛이 하나만 할당되는 반면, 전역 최소점은 복잡한 구간에 두 개의 유닛을 배치해 더 낮은 손실을 얻는다. 이는 초기 조건에 따라 네트워크가 “잘못된 파티셔닝”에 고정될 수 있음을 보여준다.
4. **플래튼 XOR 데이터셋**
- 전통적인 XOR 문제는 2‑층 네트워크로 쉽게 해결되지만, 저자들은 좌표를 비대칭적으로 이동시켜 (1.0,0.0), (0.2,0.6) 등을 양 클래스, (0.0,1.0), (0.6,0.2) 등을 음 클래스로 구성한 “플래튼 XOR”을 만든다.
- 동일한 네트워크 구조로 학습하면, 초기화에 따라 손실이 큰 지역 최소점에 머무르며, 전역 최소점(완전 분리)으로 수렴하지 못한다. 이는 데이터의 기하학적 배치가 학습 경로에 큰 영향을 미친다는 점을 강조한다.
5. **의의 및 향후 과제**
- 논문은 “지역 최소점이 존재하지 않는다”는 가설이 실제 데이터·모델 설정에서는 성립하지 않을 수 있음을 구체적인 반례를 통해 입증한다.
- 이러한 반례는 기존 수렴 이론이 요구하는 가정(무한 데이터, 무한 파라미터, 특정 초기화 등)을 명시적으로 드러내며, 실제 적용 시 어떤 가정이 위배되는지를 판단하는 기준을 제공한다.
- 또한, 블라인드 스팟, 입력 공간 파티셔닝, 초기화에 의한 “함정” 등 다양한 메커니즘을 식별함으로써, 더 견고한 최적화 알고리즘(예: 사전 학습된 초기화, 스케일링, 활성화 함수 변형) 및 데이터 전처리 전략을 설계할 필요성을 제시한다.
결론적으로, 이 연구는 심층 신경망이 “좋은” 손실 표면을 가진다는 일반적인 믿음에 대한 중요한 경고를 제공한다. 제한된 데이터와 현실적인 초기화 조건 하에서는 나쁜 지역 최소점이 충분히 존재할 수 있으며, 이를 이해하고 회피하는 것이 신뢰성 높은 딥러닝 시스템을 구축하는 데 필수적이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기