The DTM-signature for a geometric comparison of metric-measure spaces from samples
In this paper, we introduce the notion of DTM-signature, a measure on R + that can be associated to any metric-measure space. This signature is based on the distance to a measure (DTM) introduced by Chazal, Cohen-Steiner and M\'erigot. It leads to a …
Authors: Claire Brecheteau
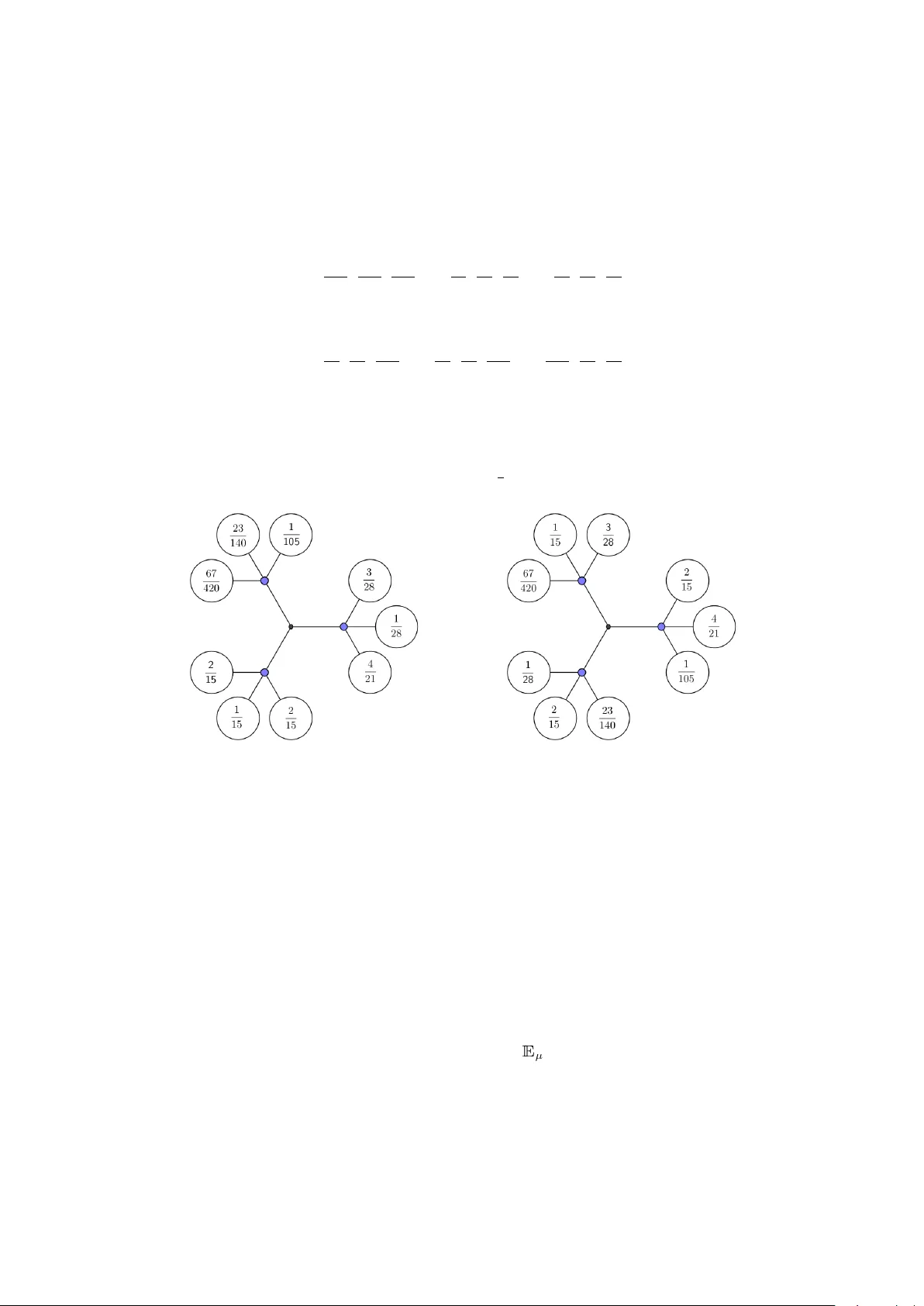
The DTM-signature for a geometric comparison of metric-measure spaces from samples ∗ Claire Bréc heteau Univ ersité P aris-Sud – Inria Sacla y // Univ ersité P aris-Sacla y , F rance claire.brecheteau@inria.fr A ugust 30, 2018 Abstract In this pap er, we in troduce the notion of DTM-signature, a measure on R + that can be asso ciated to an y metric-measure space. This signature is based on the distance to a measure (DTM) introduced by Chazal, Cohen-Steiner and Mérigot. It leads to a pseudo-metric b etw een metric-measure spaces, upp er-b ounded by the Gromo v-W asserstein distance. Under some geometric assumptions, we derive low er b ounds for this pseudo-metric. Giv en tw o N -samples, w e also build an asymptotic statistical test based on the DTM-signature, to reject the hypothesis of equality of the tw o underlying metric- measure spaces, up to a measure-preserving isometry . W e give strong theoretical justifications for this test and prop ose an algorithm for its implementation. 1 In tro duction Among the v ariet y of data av ailable, from astrophysics to biology , including so cial net works and so on, many come as sets of p oints from a metric space. A natural question, giv en tw o sets of suc h data is to decide whether they are similar, that is whether they come from the same distribution, whether their shap e are close, or not. This comparison ma y b e compromised when the data are not em b edded into the same space, or if the tw o systems of co ordinates in whic h the data are represented are differen t. T o o v ercome this issue, a natural idea is to forget ab out this embedding and only consider the set of p oints together with the distances b etw een pairs. A natural framew ork to compare data is then to assume that they come from a measure on a metric space and to consider tw o such metric-measure spaces as b eing the same when they are equal up to some isomorphism, as defined b elo w. Definition 1 (mm-space) . A metric-me asur e sp ac e ( mm-sp ac e ) is a triple ( X , δ, µ ) , with X a set, δ a metric on X and µ a pr ob ability me asur e on X e quipp e d with its Bor el σ -algebr a. Definition 2 (Isomorphism b etw een mm-spaces) . Two mm-sp ac es ( X , δ, µ ) and ( Y , γ , ν ) ar e said to b e isomorphic if their exist Bor el sets X 0 ⊂ X and Y 0 ⊂ Y such that µ ( X \X 0 ) = 0 and ν ( Y \Y 0 ) = 0 , and some one-to-one and onto isometry φ : X 0 → Y 0 pr eserving me asur es, that is satisfying ν ( φ ( A ∩ X 0 )) = µ ( A ∩ X 0 ) for any Bor el set A of X . Such a map φ is c al le d an isomorphism b etwe en the mm-sp ac es ( X , δ, µ ) and ( Y , γ , ν ) . ∗ This w ork was partially supp orted by the ANR pro ject T opData and GUDHI 1 In this pap er, we first address the question of the comparison of general mm-spaces, up to an isomorphism. In other terms, w e aim at designing a metric or at least a pseudo-metric on the quotien t space of mm-spaces b y the relation of isomorphism. A suitable pseudo-distance should b e stable under some p erturbations, under sampling, discriminativ e and easy to implemen t when dealing with discrete spaces. A first c haracterisation of mm-spaces is giv en in [19]. In its Theorem 3 1 2 . 5 , Gromov pro ves that any mm-space can be recov ered, up to an isomorphism, from the knowledge, for all size N , of the distribution of the N × N -matrix of distances asso ciated to a N -sample. More recen tly , in [23], Mémoli proposes metrics on the quotien t space of mm-spaces by the relation of isomorphism, the Gromov–W asserstein distances. Definition 3 (Gromo v–W asserstein distance) . The Gr omov–W asserstein distanc e b etwe en two mm-sp ac es ( X , δ, µ ) and ( Y , γ , ν ) with p ar ameter p ∈ [1 , ∞ ) denote d GW p ( X , Y ) is define d by the expr ession: inf π ∈ Π( µ,ν ) 1 2 Z X ×Y Z X ×Y (Γ X , Y ( x, y , x 0 , y 0 )) p π (d x × d y ) π (d x 0 × d y 0 ) 1 p , with Γ X , Y ( x, y , x 0 , y 0 ) = | δ ( x, x 0 ) − γ ( y , y 0 ) | . Her e Π( µ, ν ) stands for the set of tr ansp ort plans b etwe en µ and ν , that is the set of Bor el pr ob ability me asur es π on X × Y satisfying π ( A × Y ) = µ ( A ) and π ( X × B ) = ν ( B ) for al l Bor el sets A in X and B in Y . Unfortunately , ev en when dealing with discrete mm-spaces, the computation of these Gromo v–W asserstein distances is extremely costly . An alternative is to build a signature from each mm-space, that is an ob ject inv ariant under isomorphism. The mm-spaces are then compared through their signatures. In [23], Mémoli giv es an ov erview of such signatures, as for instance shap e distribution, eccen tricity or what he calls lo cal distribution of distances. In this pap er, w e introduce a new signature that is a probability measure on R , and w e prop ose to compare such signatures using W asserstein distances [26]. Definition 4 (W asserstein distance) . The W asserstein distanc e of p ar ameter p ∈ [1 , ∞ ) b etwe en two Bor el pr ob ability me asur es µ and ν over the same metric sp ac e ( X , δ ) is define d as: W p ( µ, ν ) = inf π ∈ Π( µ,ν ) Z R 2 δ p ( x, y )d π ( x , y ) 1 p . F or tw o probabilit y measures µ and ν o ver R + , the L 1 -W asserstein distance can b e rewritten as the L 1 -norm b et ween the cum ulative distribution functions of the measures, F µ : t 7→ µ (( −∞ , t ]) and F ν , or as well, as the L 1 -norm b etw een the quantile functions, F − 1 µ : s 7→ inf { x ∈ R | F ( x ) ≥ s } and F − 1 ν . Thus, the computation of the L 1 -W asserstein distance b et ween empirical measures is easy , in O ( N log ( N )) for tw o empirical measures from subsets of R of size N , the complexit y of a sort. Shap e signatures are widely used for classification or pre-classification tasks; see for instance [25]. With a more top ological point of view, persistence diagrams hav e b een used for this purp ose in [10, 12]. But, as far as we know, the construction of w ell-founded statistical tests from signatures to compare mm-spaces has not b een considered among the literature. This is the second problem fo cussed in this pap er. Recall that a statistical test is a random v ariable φ N taking v alues in { 0 , 1 } . More precisely φ N is a function of N random data from a distribution L θ dep ending on some unkno wn parameter θ in some set Θ . It is asso ciated to t wo hypotheses H 0 “ θ ∈ Θ 0 ” and H 1 “ θ ∈ Θ 1 ” with Θ 0 and Θ 1 disjoin t subsets of Θ . Ideally , we would like the test φ N to b e equal to 1 if θ is in Θ 1 and to b e 0 if θ is in Θ 0 . 2 The quality of a statistical test is measured in terms of its t yp e I error , that is the function defined for all θ 0 in Θ 0 b y P θ 0 ( φ N = 1) , the probabilit y of pretending θ to b e in Θ 1 when θ = θ 0 is actually in Θ 0 . Moreo ver, a test is of lev el α ∈ (0 , 1) if its type I error is upper-b ounded b y α , that is P θ 0 ( φ N = 1) ≤ α for all θ 0 in Θ 0 . T wo statistical tests with a fixed level α ∈ (0 , 1) can b e compared through their t yp e I I error , that is the function defined for all θ 1 in Θ 1 b y P θ 1 ( φ N = 0) , the probabilit y of pretending θ to b e in Θ 0 when θ = θ 1 is actually in Θ 1 . See [4] for a reference on statistical tests. In this article, we build a test of asymptotic level α , that is a test φ N suc h that for any θ 0 in Θ 0 , P θ 0 ( φ N = 1) → α when the size of the sample N go es to ∞ . Moreo ver, the set Θ we consider is the set of couples of mm-spaces (( X , δ, µ ) , ( Y , γ , ν )) . The set Θ 0 is the subset of Θ made of couples of tw o isomorphic spaces: Θ 0 = { (( X , δ, µ ) , ( Y , γ , ν )) ∈ Θ | ( X , δ, µ ) and ( Y , γ , ν ) are isomorphic } , and Θ 1 = Θ \ Θ 0 . Suc h a test generalises tw o-sample tests, from the precursor Kolmogoro v-Smirnov test to the more recen t tests in [18] or [9]. Our test do es not dep end on the embedding of the data and keeps a trac k of the geometry in some wa y , a point of view that has already b een tak en in the context of density estimation [21]. Th us, it could b e of in terest for proteins, 3D-shap e comparison, etc. Concretely , in this pap er, we propose a new signature based on the distance to a measure (DTM) in tro duced in [11], the DTM-signature . This signature is inv ariant under isomorphism and easy to compute. W e prov e its stabilit y with resp ect to the so- called Gromo v-W asserstein and W asserstein distances with parameter p = 1 . It leads to a stabilit y under sampling, at least for the Euclidean space R d . After deriving framew orks under whic h the knowledge of the distance to a measure determines the measure, we pro ve discriminative properties for the DTM-signature by deriving low er b ounds for the L 1 -W asserstein distance b etw een tw o suc h signatures, under v arious assumptions. Finally , from t w o N -samples, w e deriv e a statistical test, based on b o otstrap metho ds, to reject or not the hypothesis of equalit y of the tw o underlying metric-measure spaces, up to a measure-preserving isometry . This test comes with an easy-to-implemen t algorithm, and a strong theoretical justification. The DTM-signature depends on some parameter m ∈ (0 , 1) . It th us offers a v ariety of new fictures, as well as new lo wer-bounds for the Gromo v-W asserstein distance. As for the statistical test, it presents the adv antage of not dep ending on the em b edding of the data, only the kno wledge of the distances b etw een p oin ts is required. In this sense, it is new. The justification of the v alitidy of the test with the use of the W asserstein distance is quite new as well, and still p o orly used; see [14] for another use. The pap er is organized as follo ws. Section 2 is dev oted to the distance to a measure. An accent is put on its discriminative prop erties. The DTM-signature is then in tro duced in Section 3. The question of discrimination of tw o mm-spaces is also discussed. F or this purp ose, we deriv e low er bounds for our pseudo-distance, the L 1 -W asserstein distance b et ween the tw o DTM-signatures. Finally , in Section 4 we in tro duce the test of isomor- phism, prop ose an algorithm for its implemen tation and then giv e some theoretical results to ensure the v alidity of the pro cedure. Numerical illustrations are given in Section 5. 2 The distance to a measure to discriminate b et w een measures Let ( X , δ ) b e a metric space, equipped with a Borel probabilit y measure µ . Giv en m in [0 , 1] , the pseudo-distance function is defined at any p oint x of X , b y: δ µ,m ( x ) = inf { r > 0 | µ (B( x, r )) > m } . 3 The function distance to the measure µ with mass parameter m and denoted d µ, m is then defined for all x in X by: d µ, m ( x ) = 1 m Z m l = 0 δ µ, l ( x ) d l . The distance to a measure is a generalisation of the function distance to a compact set; see [11]. This function is con tinuous with resp ect to the mass parameter m , and Lipsc hitz with resp ect to µ . Prop osition 5 (Stabilit y , in [11] for R d , in [7] for metric spaces) . F or two mm-sp ac es ( X , δ, µ ) and ( Y , δ, ν ) emb e dde d into the same metric sp ac e, we have that k d µ, m − d ν, m k ∞ , X ∪Y ≤ 1 m W 1 ( µ, ν ) . Moreo ver, for some empirical measure ˆ µ N = 1 N P N i =1 δ X i on a metric space ( X , δ ) , the distance to the measure ˆ µ N with mass parameter k N for some k in [ [0 , N ] ] at a point x of X satisfies: d ˆ µ N , k N ( x ) = 1 k k X i = 1 δ ( X ( i ) , x ) , where X (1) , X (2) , . . . X ( k ) are k nearest neigh b ours of x among the N p oin ts X 1 , X 2 , . . . X N . The distance to the measure ˆ µ N is thus equal to the mean of the distances to k -nearest neigh b ours. In particular, in this case, the computation of the DTM boils down to the computation of the first k -nearest neighbours. The question of determining if the knowledge of the distance to a measure leads to the knowledge of the measure itself is a natural question. Some work has b een done in this direction for discrete measures; see [7]. In the follo wing, w e prop ose results in differen t settings. Prop osition 6. L et ( X , δ ) b e a metric sp ac e, and M 1 ( X ) b e the set of Bor el pr ob ability me asur es over ( X , δ ) . W e define the maps φ and ψ for al l µ in M 1 ( X ) by: φ ( µ ) = (d µ, m ( x )) m ∈ [0 , 1] , x ∈X and ψ ( µ ) = µ B( x, r ) r ∈ R + , x ∈X . Then, the map φ is inje ctive if and only if the map ψ is inje ctive. Pro of F rom the definition of δ µ,m ( x ) , we hav e: µ B( x, r ) = inf { m ≥ 0 | δ µ,m ( x ) > r } . Moreo ver, since m → δ µ,m ( x ) is righ t-contin uous, after the differentiation the distance- to-a-measure function with resp ect to m , w e hav e: m ∂ ∂ m d µ, m ( x ) + d µ, m ( x ) = δ µ, m ( x ) . 4 It means that in spaces on which measures are determined by their v alues on balls, the measures are determined b y the knowled ge of the distance-to-a-measure functions for all parameters m in [0 , 1] , on all x in X . Remark that the Euclidean space R d satisfies suc h a condition, but this is not the case of ev ery metric space, as explained in [8]. Under the follo wing sp ecific framework, w e will establish a stronger identifiabilit y result. F or O a non-empt y b ounded op en subset of R d , w e define the uniform measure µ O for all Borel set A of R d , by: µ O ( A ) = Leb d ( O ∩ A ) Leb d ( O ) , with Leb d the Leb esgue measure on R d . W e also define the medial axis of O , M ( O ) as the set of p oin ts in O ha ving at least t wo pro jections onto ∂ O . That is, M ( O ) = { y ∈ O | ∃ x 0 , x 00 ∈ ∂ O , x 0 6 = x 00 , k y − x 0 k 2 = k y − x 00 k 2 = d( y , ∂ O ) } , with d( y , ∂ O ) = inf {k x − y k 2 | x ∈ ∂ O } . Its reac h , Reach( O ) , is the distance betw een its b oundary ∂ O and its medial axis M ( O ) . That is, Reac h( O ) = inf {k x − y k 2 | x ∈ ∂ O , y ∈ M ( O ) } . If K is a compact subset of R d , it is standard to define its reach as Reac h ( K c ) , the reac h of its complement in R d . See [16] to get more familiar with these notions. Prop osition 7. L et O and O 0 b e two non-empty b ounde d op en subsets of R d with p ositive r e ach, such that O = O ◦ and O 0 = O 0 ◦ . L et m b e some p ositive c onstant satisfying m ≤ min Reac h( O ) d , Reach( O 0 ) d ω d Leb d ( O ) , with ω d = Leb d (B( 0 , 1 )) , the L eb esgue volume of the unit d -dimensional b al l. If for al l x in R d d µ O , m ( x ) = d µ O 0 , m ( x ) , then µ O = µ O 0 . Pro of This is a straightforw ard consequence of Prop osition 26, in the App endix. The pro of relies on the fact that the set of p oin ts in R d minimizing the distance to the measure µ O is equal to { x ∈ O | d ∂ O ( x ) ≥ ( m , O ) } with ( m, O ) = m Leb d ( O ) ω d 1 d , providing that the set is non-empt y . Then, if Reach( O ) is not smaller than ( m, O ) , O equals to the set of p oints at distance smaller than ( m, O ) from { x ∈ O | d ∂ O ( x ) ≥ ( m , O ) } . Thus, the measure µ O can b e recov ered. W e use the notion of sk eleton in [20] for some details in the pro of. It means that for m small enough, the kno wledge of the distance to a measure at an y p oin t x in R d for tw o measures µ O and µ O 0 is discriminative. 5 3 The DTM-signature to discriminate b et ween metric- measure spaces F rom the distance-to-a-measure function, w e derive a new signature. Definition 8 (DTM-signature) . The DTM-signatur e asso ciate d to some mm-sp ac e ( X , δ, µ ) , denote d d µ, m ( µ ) , is the distribution of the r e al-value d r andom variable d µ, m ( X ) wher e X is some r andom variable of law µ . The DTM-signature turns out to b e stable in the following sense. Prop osition 9. W e have that: W 1 (d µ, m ( µ ) , d ν, m ( ν )) ≤ 1 m GW 1 ( X , Y ) . Pro of Pro of in the App endix, in Section B. The pro of is relatively similar to the ones giv en by Mémoli in [23] for other signatures. It follows directly that tw o isomorphic mm-spaces hav e the same DTM-signature. Whenev er the tw o mm-spaces are embedded in to the same metric space, w e also get stabilit y with resp ect to the L 1 -W asserstein distance. Prop osition 10. If ( X , δ, µ ) and ( Y , δ, ν ) ar e two metric sp ac es emb e dde d into some metric sp ac e ( Z , δ ) , then we c an upp er b ound W 1 (d µ, m ( µ ) , d ν, m ( ν )) by W 1 ( µ, ν ) + min k d µ, m − d ν, m k ∞ , Supp( µ ) , k d µ, m − d ν, m k ∞ , Supp( ν ) , and mor e gener al ly by 1 + 1 m W 1 ( µ, ν ) . Pro of First remark that: W 1 (d µ, m ( µ ) , d ν, m ( µ )) ≤ Z X | d µ, m ( x ) − d ν, m ( x ) | d µ ( x ) ≤ k d µ, m − d ν, m k ∞ , Supp( µ ) . Then, for all π in Π( µ, ν ) : W 1 (d ν, m ( µ ) , d ν, m ( ν )) ≤ Z X ×Y | d ν, m ( x ) − d ν, m ( y ) | d π ( x , y ) . Th us, since d ν, m is 1-Lipschitz: W 1 (d ν, m ( µ ) , d ν, m ( ν )) ≤ W 1 ( µ, ν ) . W e use Prop osition 5 to conclude. The DTM-signature is stable but unfortunately do es not alw ays discriminates b etw een mm-spaces. Indeed, in the following coun ter-example from [23] (example 5.6), there are t wo non-isomorphic mm-spaces sharing the same signatures for all v alues of m . 6 Example 11. W e c onsider two gr aphs made of 9 vertic es e ach, cluster e d in thr e e gr oups of 3 vertic es, such that e ach vertex is at distance 1 exactly to e ach vertex of its gr oup and at distanc e 2 to any other vertex. W e assign a mass to e ach vertex, the distribution is the fol lowing, for the first gr aph: µ = 23 140 , 1 105 , 67 420 , 3 28 , 1 28 , 4 21 , 2 15 , 1 15 , 2 15 , and for the se c ond gr aph: ν = 3 28 , 1 15 , 67 420 , 2 15 , 4 21 , 1 105 , 23 140 , 2 15 , 1 28 . The mm-sp ac es ensuing ar e not isomorphic sinc e any one-to-one and onto me asur e- pr eserving map would send at le ast one c ouple of vertic es at distanc e 1 to e ach other, to a c ouple of vertic es at distanc e 2 to e ach other, thus it would not b e an isometry. Mor e over, r emark that the DTM-signatur es asso ciate d to the gr aphs ar e e qual sinc e the total mass of e ach cluster is exactly e qual to 1 3 . Figure 1: µ Figure 2: ν Nev ertheless, the signature can b e discriminativ e in some cases. In the follo wing, we giv e low er b ounds for the L 1 -W asserstein distance betw een t wo signatures under three differen t alternatives. 3.1 When the distances are m ultiplied by some positive real n umber λ Let λ b e some positive real num b er. The DTM-signature discriminates b etw een t wo mm-spaces isomorphic up to a dilatation of parameter λ , for λ 6 = 1 . Prop osition 12. L et ( X , δ , µ ) and ( Y , γ , ν ) = ( X , λδ , µ ) b e two mm-sp ac es. W e have W 1 (d µ, m ( µ ) , d ν, m ( ν )) = | 1 − λ | E µ [d µ, m ( X )] , for X a r andom variable of law µ . 7 Pro of First remark that F − 1 d ν, m ( ν ) = λF − 1 d µ, m ( µ ) . Then, W 1 (d µ, m ( µ ) , d ν, m ( ν )) = Z 1 0 F − 1 d µ, m ( µ ) ( s ) − F − 1 d ν, m ( ν ) ( s ) d s = | 1 − λ | Z 1 0 F − 1 d µ, m ( µ ) ( s ) d s = | 1 − λ | E µ [d µ, m ( X )] . 3.2 The case of uniform measures on non-empt y b ounded op en subsets of R d The DTM-signature discriminates b etw een tw o uniform measures ov er tw o non-empt y b ounded op en subsets of R d with different Leb esgue v olume. Prop osition 13. L et ( O , k · k 2 , µ O ) and ( O 0 , k · k 2 , µ O 0 ) b e two mm-sp ac es, for O and O 0 two non-empty b ounde d op en subsets of R d satisfying O = O ◦ and O 0 = O 0 ◦ , and k . k 2 the euclide an norm. A lower b ound for W 1 (d µ O , m ( µ O ) , d µ O 0 , m ( µ O 0 )) is given by: min µ O O ( m,O ) , µ O 0 O 0 ( m,O 0 ) d d + 1 m ω d 1 d Leb d ( O ) 1 d − Leb d ( O 0 ) 1 d . Her e, O = { x ∈ O | d( x , ∂ O ) ≥ } , and ( m, O ) = m Leb d ( O ) ω d 1 d is the r adius of any b al l of µ O mass m , include d in O . Pro of If the set O ( m,O ) is non-empty , then the minimal v alue of the distance to a measure is giv en by: min x ∈ R d (d µ O , m ( x )) = d min := d d + 1 m Leb d ( O ) ω d 1 d . Moreo ver, the p oints at minimal distance are exactly the p oints of O ( m,O ) . This is Prop osition 25 in the App endix. So, F d µ O , m ( µ O ) (d min ) = µ O O ( m , O ) . T o conclude, w e use the definition of the L 1 -W asserstein distance as the L 1 -norm b etw een the cumulativ e distribution functions. 3.3 The case of t wo measures on the same op en subset of R d with one measure uniform Let ( O , k · k 2 , µ O ) and ( O , k · k 2 , ν ) b e tw o mm-spaces with O a non-empty b ounded op en subset of R d and ν a measure absolutely con tinuous with respect to µ O . Thanks to the Radon-Nik o dym theorem, there is some µ O -measurable function f on O suc h that for all Borel set A in O : ν ( A ) = Z A f ( ω )d µ O ( ω ) . W e can consider the λ -sup er-lev el sets of the function f denoted by { f ≥ λ } . As for the previous part, we will denote b y { f ≥ λ } the set of points b elonging to { f ≥ λ } whose distance to ∂ { f ≥ λ } is at least . Then we get the following low er bound for the L 1 -W asserstein distance b etw een the t wo signatures: 8 Prop osition 14. Under these hyp otheses, a lower b ound for W 1 (d µ O , m ( µ O ) , d ν, m ( ν )) is given by: 1 1 + d 1 Leb d ( O ) m Leb d ( O ) ω d 1 d Z ∞ λ =1 1 λ 1 d max λ 0 ≥ λ Leb d { f ≥ λ 0 } m ω d Leb d ( O ) λ 0 1 d ! d λ. Pro of Pro of in the App endix, in Section A.2. When the density f is Hölder W e assume that f is Hölder on O , with positive parameters χ ∈ (0 , 1] and L > 0 , that is: ∀ x, y ∈ O , | f ( x ) − f ( y ) | ≤ L k x − y k χ 2 . W e also assume that Reach( O ) > 0 . Then for m small enough, the DTM-signature is discriminativ e. Prop osition 15. Under the pr evious assumptions, if one of the fol lowing c onditions is satisfie d, then the quantity W 1 (d µ O , m ( µ O ) , d ν, m ( ν )) is p ositive: m < ω d Leb d ( O ) min ( Reac h( O ) d , k f k ∞ , O − 1 2L d χ ) ; m ∈ ω d Leb d ( O ) (Reac h( O )) d , ( k f k ∞ , O − 2L (Reach( O )) χ ) (Reach( O )) d ω d Leb d ( O ) ; m ∈ " ω d Leb d ( O ) d χ d χ (2 L ) − d χ , min m 0 , ω d Leb d ( O ) (Reac h( O )) d + χ χ d 2L ! , with m 0 = k f k d χ +1 ∞ ,O ω d Leb d ( O ) d χ d χ (2 L ) − d χ χ d + χ χ d + χ . Mor e over, under any of these c onditions, we get the lower b ound for the quantity W 1 (d µ O , m ( µ O ) , d ν, m ( ν )) : 1 1 + d m Leb d ( O ) ω d 1 d Z ∞ λ =1 1 λ 1+ 1 d sup λ 0 ≥ λ ν { f ≥ λ 0 + L ( λ 0 ) χ } ∩ O ( λ 0 ) d λ, with ( λ 0 ) = λ 0− 1 d m Leb d ( O ) ω d 1 d . Pro of Pro of in the App endix, in Section A.2. The previous examples provide several relev ant cases where the DTM-signature turns out to be discriminativ e. It is th us app ealing to use it as a tool to compare mm-spaces up to isomorphism. 4 An algorithm to compare metric-measure spaces from samples In this section, ( X , δ, µ ) and ( Y , γ , ν ) are t wo mm-spaces. W e build a test of the null h yp othesis H 0 “The mm-spaces ( X , δ, µ ) and ( Y , γ , ν ) are isomorphic” , 9 against its alternativ e: H 1 “The mm-spaces ( X , δ, µ ) and ( Y , γ , ν ) are not isomorphic” . 4.1 The algorithm The test we prop ose is based on the fact that the DTM-signatures asso ciated to t wo isomorphic mm-spaces are equal. If so, it leads to a pseudo-distance W 1 (d µ, m ( µ ) , d ν, m ( ν )) equal to zero. Let consider, in this part, a N -sample P from the measure µ , and a N -sample Q from the measure ν . A natural idea for a test is to approximate the pseudo-distance by the statistic W 1 d 1 P , m ( 1 P ) , d 1 Q , m ( 1 Q ) , where 1 P is the uniform probability measure on the set P , and to reject the hypothesis H 0 if this statistic is larger than some critical v alue. The choice of the critical v alue should rely on some parameter α ∈ (0 , 1) and lead to a level α for the test. It strongly dep ends on the measures µ and ν that are unknown. Nonetheless, there exist classical wa ys of approximating a critical v alue, one is to mimic the distribution of the statistic by replacing the distribution µ with the distribution 1 P and ν with 1 Q . Unfortunately , this standard metho d known as b o otstrap fails theoretically and exp erimen tally for our framework. Th us, w e propose another kind of b o otstrap. F or this purp ose, w e need to take P 0 a sub- set of P and Q 0 a subset of Q . The statistic we fo cus on is W 1 d 1 P , m ( 1 P 0 ) , d 1 Q , m ( 1 Q 0 ) . It turns out that in this case, the critical v alue asso ciated to this statistic can b e well appro ximated from the samples P and Q , for a suitable size of P 0 and Q 0 with resp ect to N . This approach leads to the follo wing algorithm. Algorithm 1: T est Procedure I n p u t : P and Q N -samples from µ (respectively ν ), N , n , m , α , N M C ev en ; # C o m p u t e T t h e t e s t s t a t i s t i c T ak e P 0 a random subset of P of size n ; T ak e Q 0 a random subset of Q of size n ; T ← √ nW 1 (d 1 P , m ( 1 P 0 ) , d 1 Q , m ( 1 Q 0 )) ; # C o m p u t e boot a N M C - s a m p l e f r o m t h e b o o t s t r a p l a w dtmP ← (d 1 P , m ( x )) x ∈ P ; dtmQ ← (d 1 Q , m ( x )) x ∈ Q ; Let boot b e empty ; f o r j i n 1 . . b N M C / 2 c : Let dtmP 1 and dtmP 2 b e tw o indep endent n -samples from 1 dtmP ; Let dtmQ 1 and dtmQ 2 b e tw o indep endent n -samples from 1 dtmQ ; A dd √ nW 1 ( 1 dtmP 1 , 1 dtmP 2 ) and √ nW 1 ( 1 dtmQ 1 , 1 dtmQ 2 ) to boot ; # C o m p u t e q alph , t h e α - q u a n t i l e o f boot Let q alph b e the b N M C − N M C × α c th smallest elemen t of boot ; Out put : ( T ≥ q al ph ) Recall that the L 1 -W asserstein distance W 1 is simply the L 1 -norm of the difference b et ween the cum ulative distribution functions. It can b e implemen ted b y the R function emdw from the pac kage emdist . T o compute the distance to an empirical measure at a p oin t x , it is sufficient to searc h for its nearest neigh b ours; see section 2. This can be implemen ted by the R function dtm with tuning parameter r = 1 , from the pac kage TDA [15]. 10 4.2 V alidit y of the metho d In order to prov e the v alidity of our metho d, we need to introduce a statistical framework. First of all, from t wo N -samples from the mm-spaces ( X , δ, µ ) and ( Y , γ , ν ) , w e deriv e four indep enden t empirical measures, ˆ µ n , ˆ µ N − n , ˆ ν n and ˆ ν N − n . W e also denote ˆ µ N (resp ectiv ely ˆ ν N ) the empirical measure asso ciated to the whole N -sample of la w µ (resp ectiv ely ν ), that is ˆ µ N = n N ˆ µ n + N − n N ˆ µ N − n . Then, we define the test statistic as: T N ,n,m ( µ, ν ) = √ nW 1 (d ˆ µ N , m ( ˆ µ n ) , d ˆ ν N , m ( ˆ ν n )) . Its law will be denoted by L N ,n,m ( µ, ν ) . Remark that for tw o isomorphic mm-spaces ( X , δ, µ ) and ( Y , γ , ν ) , the distribution of T N ,n,m ( µ, ν ) is L N ,n,m ( µ, µ ) , L N ,n,m ( ν, ν ) , but also 1 2 L N ,n,m ( µ, µ ) + 1 2 L N ,n,m ( ν, ν ) ; see Lemma 27 in the App endix. F or some α > 0 , we denote b y q α = inf { x ∈ R | F ( x ) ≥ 1 − α } , the α -quan tile of a distribution with cum ulative distribution function F . The α -quan tile q α, N , n of 1 2 L N ,n,m ( µ, µ ) + 1 2 L N ,n,m ( ν, ν ) will b e appro ximated by the α -quan tile ˆ q α,N ,n of 1 2 L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) + 1 2 L ∗ N ,n,m ( ˆ ν N , ˆ ν N ) . Here L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) stands for the distribution of √ nW 1 (d ˆ µ N , m ( µ ∗ n ) , d ˆ µ N , m ( µ 0∗ n )) conditionally to ˆ µ N , where µ ∗ n and µ 0∗ n are tw o empirical measures from indep endent n -samples of law ˆ µ N . The test w e deal with in this pap er is then: φ N = 1 T N,n,m ( µ,ν ) ≥ ˆ q α,N,n . The null hypothesis H 0 is rejected if φ N = 1 , that is if the L 1 -W asserstein distance b et ween the tw o empirical signatures d ˆ µ N , m ( ˆ µ n ) and d ˆ ν N , m ( ˆ ν n ) is to o high. 4.2.1 A test of asymptotic lev el α In this part, we pro ve that the test w e prop ose is of asymptotic level α , that is such that: lim sup N →∞ P ( µ,ν ) ∈ H 0 ( φ N = 1) ≤ α. F or this, w e pro ve that the law of the test statistic 1 2 L N ,n,m ( µ, µ ) + 1 2 L N ,n,m ( ν, ν ) under the hypothesis H 0 and the b o otstrap law 1 2 L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) + 1 2 L ∗ N ,n,m ( ˆ ν N , ˆ ν N ) conv erge w eakly to some fixed distribution when n and N go to ∞ . In order to adopt a non- asymptotic and more visual p oint of view, w e also deriv e upp er b ounds in exp ectation for the L 1 -W asserstein distance b et ween these tw o distributions. Remark that it is sufficient to pro ve w eak conv ergence for L N ,n,m ( µ, µ ) and L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) . Moreo ver, W 1 1 2 L N ,n,m ( µ, µ ) + 1 2 L N ,n,m ( ν, ν ) , 1 2 L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) + 1 2 L ∗ N ,n,m ( ˆ ν N , ˆ ν N ) is upp er b ounded by 1 2 W 1 L N ,n,m ( µ, µ ) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) + 1 2 W 1 L N ,n,m ( ν, ν ) , L ∗ N ,n,m ( ˆ ν N , ˆ ν N ) . This is a straightforw ard consequence of the definition of the L 1 -W asserstein distance with transp ort plans. Th us, this is also sufficient to derive upp er b ounds in exp ectation for the quan tity W 1 L N ,n,m ( µ, µ ) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) . 11 Lemma 16. F or µ a me asur e supp orte d on a c omp act set, we cho ose n as a function of N such that: when N go es to infinity, n go es to infinity, √ n E [ k d µ, m − d ˆ µ N , m k ∞ , X ] go es to zer o or mor e sp e cific al ly √ n m E [ W 1 ( µ, ˆ µ N )] go es to zer o. Then we have that: L N ,n,m ( µ, µ ) L k G µ,m − G 0 µ,m k 1 , when N go es to infinity. Mor e over, if n is chosen such that √ nW 1 (d µ, m ( µ ) , d µ, m ( ˆ µ N )) and √ n k d µ, m − d ˆ µ N , m k ∞ , X go to zer o a.e., we have that for almost every sample X 1 , X 2 , . . . X N . . . : L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) L k G µ,m − G 0 µ,m k 1 , when N go es to infinity; with G µ,m and G 0 µ,m two indep endent Gaussian pr o c esses with c ovarianc e kernel κ ( s, t ) = F d µ, m ( µ ) ( s ) 1 − F d µ, m ( µ ) ( t ) for s ≤ t . Pro of Pro of in the App endix, in Section C.3. Prop osition 17. If the two we ak c onver genc es in lemma 16 o c cur, and if the α -quantile q α of the distribution L ( 1 2 k G µ,m − G 0 µ,m k 1 + 1 2 k G ν,m − G 0 ν,m k 1 ) is a p oint of c ontinuity of its cumulative distribution function, then the asymptotic level of the test at ( µ, ν ) is α . Pro of Pro of in the App endix, in Section C.3. Remark that for uniform measures on any sphere in R d , the con tinuit y assumption for the cumulativ e distribution function of L ( k G µ,m − G 0 µ,m k 1 ) is not satisfied. This is a degenerated case. Thus, the test cannot b e applied to such mm-spaces. W e choose N = cn ρ for some p ositive constants ρ and c . Then the test is asymptoti- cally v alid for tw o measures supp orted on a compact subset of the Euclidean space R d if w e assume that ρ > max { d, 2 } 2 . Prop osition 18. L et µ b e some Bor el pr ob ability me asur e supp orte d on some c omp act subset of R d . Under the assumption ρ > max { d, 2 } 2 , the two we ak c onver genc es of lemma 16 o c cur. Mor e over, a b ound for the exp e ctation of W 1 L N ,n,m ( µ, µ ) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) is of or der: N 1 2 ρ − 1 max { d, 2 } (log(1 + N )) 1 d =2 . A nd, W 1 L N ,n,m ( µ, µ ) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) → 0 a.e. when n go es to ∞ . Pro of This prop osition is based on rates of con vergence for the W asserstein distance betw een a measure µ with v alues in R d and its empirical version ˆ µ N ; see [17] for general dimensions and [6] for d = 1 . Proof in the App endix, in Section C.4. A probability measure µ is ( a, b ) -standard with p ositive parameters a and b , if for all positive radius r and an y p oint x of the supp ort of µ , w e ha v e that µ (B( x , r )) ≥ min { 1 , ar b } . Uniform measures on op en subsets of R d satisfy such a property: 12 Example 19. L et O b e a non-empty b ounde d op en subset of R d . Then, the me asur e µ O is ( a, d ) -standar d with a = ω d Leb d ( O ) Reac h( O ) D ( O ) d . Her e, D ( O ) stands for the diameter of O and ω d for Leb d (B( 0 , 1 )) , the L eb esgue volume of the unit d -dimensional b al l. Pro of Pro of in the App endix, in Section A.1. Similar results can b e obtained for uniform measures on compact submanifolds of dimension d . In [24] (lemma 5.3), the authors give a b ound for a dep ending on the reac h of the submanifold. The test is asymptotically v alid for tw o ( a, b ) -standard measures supp orted on compact connected subsets of R d if ρ > 1 : Prop osition 20. L et µ b e an ( a, b ) -standar d me asur e supp orte d on a c onne cte d c omp act subset of R d . The two we ak c onver genc es of lemma 16 o c cur if the assumption ρ > 1 is satisfie d. Mor e over, a b ound for the exp e ctation of W 1 L N ,n,m ( µ, µ ) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) is of or der N 1 2 ρ − 1 2 up to a lo garithm term. Pro of This prop osition is based on rates of conv ergence for the infinity norm b etw een the distance to a measure and its empirical version; see [13]. Pro of in the App endix, in Section C.5. Remark that we can achiev e a rate close to the parametric rate for Ahlfors regular measures, whereas for general measures, the rate gets w orse when the dimension increases. An ywa y , w e need ρ to b e as big as p ossible for the b o otstrapp ed la w to b e a go o d enough appro ximation of the la w of the statistic, that is to ha ve a type I error close enough to α ; k eeping in mind that n should go to ∞ with N . 4.2.2 The pow er of the test The p o w er of the test φ N = 1 √ nW 1 ( d ˆ µ N , m ( ˆ µ n ) , d ˆ ν N , m ( ˆ ν n ) ) ≥ ˆ q α,N,n is defined for t wo mm- spaces ( X , δ, µ ) and ( Y , γ , ν ) b y: 1 − P ( µ,ν ) ( φ N = 0) . If the spaces are not isomorphic, we wan t the test to reject the n ull with high probability . It means that we wan t the p ow er to b e as big as p ossible. Here, w e give a low er bound for the p ow er, or more precisely an upper bound for P ( µ,ν ) ( φ N = 0) , the t yp e I I error . Prop osition 21. L et µ and ν b e two Bor el me asur es supp orte d on X and Y , two c omp act subsets of R d . W e assume that the mm-sp ac es ( X , δ, µ ) and ( Y , γ , ν ) ar e non-isomorphic and that the DTM- signatur e is discriminative for some m in (0 , 1] , that is such that W 1 (d µ, m ( µ ) , d ν, m ( ν )) > 0 . W e cho ose N = n ρ with ρ > 1 . Then for al l p ositive , ther e exists n 0 dep ending on µ and ν such that for al l n ≥ n 0 , the typ e II err or P ( µ,ν ) √ nW 1 (d ˆ µ N , m ( ˆ µ n ) , d ˆ ν N , m ( ˆ ν n )) < ˆ q α,N ,n is upp er b ounde d by 4 exp − W 2 1 (d µ, m ( µ ) , d ν, m ( ν )) (2 + ) max D 2 µ,m , D 2 ν,m n ! , 13 with D µ,m , the diameter of the supp ort of the me asur e d µ, m ( µ ) . Pro of Pro of in the App endix, in Section C.6. In order to hav e a high pow er, that is to reject H 0 more often when the mm-spaces are not isomorphic, we need n to b e big enough, that is ρ small enough. Recall that n has to b e small enough for the law of the statistic and its b o otstrap version to be close. It means that some compromise should b e done. Moreov er, the choice of m for the test should dep end on the geometry of the mm-spaces. The tuning of these parameters from data is still an op en question. 5 Numerical illustrations Let µ v b e the distribution of the random vector ( R sin ( v R ) + 0 . 03 N , R cos ( v R ) + 0 . 03 N 0 ) with R , N and N 0 indep enden t random v ariables; N and N 0 from the standard normal distribution and R uniform on (0 , 1) . With the notation giv en in the Introduction, w e consider the sets Θ 0 = { ( µ 10 , µ 10 ) } and Θ 1 = { ( µ 10 , µ p ) | p 6 = 10 } . W e sample N = 2000 p oin ts from tw o measure, choose α = 0 . 05 , m = 0 . 05 , n = 20 , and N M C = 1000 . W e giv e an example under whic h our test ( DTM ) is w orking and more p ow erful than ( KS ), whic h consists in applying a Kolmogoro v-Smirnov test to N 2 -samples from L ( δ ( X, X 0 )) and L ( γ ( Y , Y 0 )) with X and X 0 (resp. Y and Y 0 ) independent from µ (resp. ν ). The exp erimen ts are rep eated 1000 times to appro ximate the type I error for our test and the p ow er for b oth tests. 0.05 0.10 0.15 0.20 0.25 0.30 0.0 0.2 0.4 0.6 0.8 1.0 signature, v = 10 signature, v = 20 Figure 3: DTM-signature estimates, m = 0 . 05 0.05 0.10 0.15 0.20 0.0 0.2 0.4 0.6 0.8 1.0 distribution of the statistic bootstap distribution Figure 4: Bo otstrap v alidity , v = 10 , m = 0 . 05 v 15 20 30 40 100 t yp e I error DTM 0.050 0.049 0.051 0.044 0.051 p o wer DTM 0.525 0.884 0.987 0.977 0.985 p o wer KS 0.768 0.402 0.465 0.414 0.422 Figure 5: Type I error and p ow er appro ximations 6 Concluding remarks and p ersp ectiv es This pap er op ens a new horizon of statistical tests based on shap e signatures. It could b e of in terest to adapt these kind of metho ds to other signatures, if possible. In future it could even b e in teresting to build statistical tests based on many different signatures, leading to an ev en b etter discrimination. Regarding the test prop osed in this paper itself, the geometric and statistical problem of the choice of the b est parameters to use in practice is still an op en, tough and engaging question. 14 A c kno wledgemen ts The author is extremely grateful to F rédéric Chazal, P ascal Massart and Bertrand Mic hel for introducing her to the distance to a measure, for their v aluable comments and advises, and for pro ofreading. References [1] Alejandro de Acosta and Ev arist Giné. Conver genc e Of Moments A nd R elate d F unctionals In The Centr al Limit The or em In Banach Sp ac es . Z. W ahrsc h.ver.Geb., 1979. [2] Aloisio Araujo and Ev arist Giné. The Centr al Limit The or em for R e al and Banach V alue d R andom V ariables . John Wiley & Sons Inc, 1980. [3] Eustasio del Barrio, Ev arist Giné, and Carlos Matrán. “Central Limit Theorems F or The W asserstein Distance Betw een The Empirical And The T rue Distributions”. In: The A nnals of Pr ob ability 27.2 (1999), pp. 1009–1071. [4] P eter J. Bic kel and Kjell A. Doksum. Mathematic al statistics : b asic ide as and sele cte d topics . Englew o o d Cliffs, N.J. Prentice Hall, 1977. isbn : 0-13-564147-0. url : http://opac.inria.fr/record=b1089888 . [5] P atrick Billingsley. Conver genc e of Pr ob ability Me asur es . Wiley-In terscience, 1999. [6] Sergey Bobko v and Mic hel Ledoux. “One-Dimensional Empirical Measures, Order Statistics, And K antoro vich T ransp ort Distances”. unpublished. 2014. url : http: //perso. math.univ - toulouse.fr /ledoux/ files/2014 /04/ Order.statistics. pdf . [7] Mic kaël Buchet. “T op ological Inference F rom Measures”. PhD thesis. Univ ersité P aris-Sud – Paris XI, 2014. [8] Blanc he Buet and Gian P aolo Leonardi. “Reco vering Measures F rom Approximate V alues On Balls”. unpublished. 2015. url : . [9] F rédéric Cazals and Alix Lhéritier. “Bey ond T wo-sample-tests: Lo calizing Data Discrepancies in High-dimensional Spaces”. In: IEEE/A CM DSAA . 2015. [10] F Chazal et al. “Gromov- H ausdorff Stable Signatures for Shap es using Persistence”. In: Computer Gr aphics F orum (pr o c. SGP 2009) (2009), pp. 1393–1403. [11] F rédéric Chazal, Da vid Cohen-Steiner, and Quentin Mérigot. “Geometric Inference for Probabilit y Measures”. In: F oundations of Computational Mathematics 11.6 (2011), pp. 733–751. [12] F rédéric Chazal, Vin De Silv a, and Steve Oudot. “Persistence stabilit y for geometric complexes”. In: Ge ometriae De dic ata 173.1 (2014), pp. 193–214. [13] F rédéric Chazal, Pascal Massart, and Bertrand Mic hel. “Rates Of Con vergence F or Robust Geometric Inference”. In: Ele ctr onic Journal of Statistics 10.2 (2016), pp. 2243–2286. [14] Eustasio Del Barrio, Hélène Lescornel, and Jean-Mic hel Loub es. “A statistical anal- ysis of a deformation mo del with W asserstein barycen ters : estimation pro cedure and go o dness of fit test”. unpublished. 2015. url : 06465v2.pdf . [15] Brittan y T erese F asy et al. “In tro duction to the R pac kage TDA”. In: CoRR abs/1411.1830 (2014). url : . [16] Herb ert F ederer. “Curv ature Measures”. In: T r ansactions of the A meric an Mathe- matic al So ciety 93.3 (1959), pp. 418–491. 15 [17] Nicolas F ournier and Arnaud Guillin. “On The Rate Of Conv ergence In W asserstein Distance Of The Empirical Measure”. In: Pr ob ability The ory & R elate d Fields 162 (3 2015), pp. 707–738. [18] Arth ur Gretton et al. “A Kernel T wo-Sample T est”. In: Journal of Machine L e arning R ese ar ch 13 (2012), pp. 723–773. [19] Mikhail Gromov. Metric Structur es for R iemannian and Non- R iemannian Sp ac es . Birkhäuser Basel, 2003. [20] André Lieutier. “An y Op en Bounded Subset of R n Has the Same Homotopy T yp e Than Its Medial Axis”. In: Computer Aide d Ge ometric Design 36.11 (2004), pp. 1029–1046. [21] Ulrik e von Luxburg and Morteza Alamgir. “Densit y estimation from unw eighted k-nearest neighbor graphs: a roadmap”. In: NIPS . 2013. [22] P ascal Massart. “The Tigh t Constan t in the D v oretzky- K iefer- W olfowitz Inequal- it y”. In: The A nnals of Pr ob ability 18.3 (1990), pp. 1269–1283. [23] F acundo Mémoli. “Gromov– W asserstein Distances and the Metric Approach to Ob ject Matching”. In: F oundations of Computational Mathematics 11.4 (2011), pp. 417–487. [24] P artha Niyogi, Steven Smale, and Shmuel W ein b erger. “Finding the Homology of Submanifolds with High Confidence from Random Samples”. In: Discr ete and Computational Ge ometry 39 (1 2008), pp. 419–441. [25] Rob ert Osada et al. “Shap e Distributions”. In: A CM T r ansactions on Gr aphics 21 (4 2002), pp. 807–832. [26] Cédric Villani. T opics in Optimal T r ansp ortation . American Mathematical So ciet y, 2003. 16 App endix A Uniform measures on op en subsets of R d In this part, we fo cus on some mm-spaces ( O , k · k 2 , µ O ) where O stands for a non-empty b ounded op en subset of R d satisfying O ◦ = O . The measure µ O , the medial axis M ( O ) and the reac h Reach( O ) hav e been defined in Section 2. The ob ject ( m, O ) is defined for some mass parameter m in [0 , 1] by ( m, O ) = m Leb d ( O ) ω d 1 d . This is the radius of a ball included in O , with µ O measure equal to m . F or some p ositive , O stands for the set of p oints in O whic h distance to ∂ O is not smaller than : O = x ∈ O , inf y ∈ ∂ O k x − y k 2 ≥ . A.1 The distance to uniform measures Here, we derive some properties of the spaces ( O , k · k 2 , µ O ) . W e give a low er b ound for the minimum of the distance to the measure µ O and give a description of the p oin ts attaining this b ound. Then, we use such considerations to pro ve identifiabilit y of the measure µ O from its distance-to-a-measure function. That is, to prov e Prop osition 7 of the pap er. First, we state some technical lemma prop osed b y Lieutier in [20]. Lemma 22. If we define the skeleton Sk( O ) of the op en set O as the set of c entr es of maximal b al ls (for the inclusion) include d in O , then we get: M ( O ) ⊂ Sk( O ) ⊂ M ( O ) . No w we can form ulate some technical lemma: Lemma 23. F or any x in O , ther e exist a maximal b al l for the inclusion, include d in O and c ontaining x . Pro of Let us consider the class S = { B( y , r ) | r > 0 and x ∈ B( y , r ) ⊂ O } of all non-empty op en balls included in O and containing x . W e are going to show that this class con tains a maximal element by using the Zorn’s lemma. F or this, w e need to show that the partially-ordered set S is inductive, which means that any non-empty totally-ordered sub class T of S is upp er b ounded b y some elemen t of S . Let T b e a non-empty totally- ordered sub class of S . Set R = sup { r > 0 | ∃ y ∈ O , B( y , r ) ∈ T } the supremum of the radii of all balls in T . Since T is non-empty and O is b ounded, R if p ositive and finite. Let ( y k ) k ∈ N b e a sequence of centres of balls in T con verging to a p oint y in R d suc h that the sequence of asso ciated radii ( r k ) k ∈ N is non decreasing with R as a limit. Since T is totally-ordered and the radii non decreasing, the union S k ∈ N B( y k , r k ) is non decreasing, equal to B( y , R ) . Thus, B( y , R ) b elongs to S and upp er b ounds T . So the class S is inductiv e and thanks to the Zorn’s lemma, it con tains a maximal element. 17 Pro of of Example 19: F or any p oin t x in O and r > 0 , thanks to Lemma 23 there exist a maximal ball B( x 0 , r 0 ) included in O ∩ B( x , r ) whic h contains x . Assume for the sak e of contradiction that r 0 < min r 2 , Reach( O ) . Since r 0 < r 2 , the ball B ( x 0 , r 0 ) is included in B( x , r ) thus B( x 0 , r 0 ) is maximal in O . So x 0 b elongs to Sk( O ) , and thanks to Lemma 22, to M ( O ) . But r 0 < Reac h( O ) ; this is absurd. It follows that: µ O (B( x , r )) ≥ µ O B x 0 , min n Reac h( O ) , r 2 o . So, for r ≤ 2Reac h( O ) , since 2Reach( O ) ≤ D ( O ) b y considering a p oin t on Sk( O ) , w e get: µ O (B( x , r )) ≥ r d Reac h( O ) D ( O ) d ω d Leb d ( O ) , whic h is also true for r in [2Reach( O ) , D ( O )] , whereas for r ≥ D ( O ) we ha ve µ O (B( x , r )) = 1 . The c hoice of a in the lemma is thus relev ant. W e now fo cus on the set of p oints in R d minimizing the distance to the measure µ O . F or this, w e need some lemma. Lemma 24. If x in R d satisfies µ O (B( x , )) = ω d d Leb d ( O ) , then B( x , ) ⊂ O . Pro of If x in R d satisfies µ O (B( x , )) = ω d d Leb d ( O ) , then, Leb d ( O c ∩ B( x , )) = 0 . Assume for the sake of contradiction that the set O c ∩ B( x , ) is not empty . Since O ◦ = O , then the op en subset ( O c ) ◦ ∩ B( x , ) of O c ∩ B( x , ) is not empty , thus of p ositiv e Leb esgue measure, which is absurd. So B( x , ) ⊂ O . Prop osition 25. The c onstant d min = d d + 1 m Leb d ( O ) ω d 1 d is a lower b ound for the distanc e to the me asur e µ O over R d . Mor e over, the set of p oints attaining this b ound is exactly O ( m,O ) . Pro of Remark that for all p ositiv e l smaller than m , w e hav e: δ µ,l ( x ) ≥ l Leb d ( O ) ω d 1 d . Moreo ver, these inequalities are equalities for all p oints x in O ( m,O ) . By integrating, we get the lo wer b ound d min for x 7→ d µ, m ( x ) , and it is attained on O ( m,O ) . No w take some point x in R d satisfying d µ, m ( x ) = d min . F or almost all l smaller than m , w e hav e: δ µ,l ( x ) = l Leb d ( O ) ω d 1 d . In particular we get for these v alues of l that: µ B x, m Leb d ( O ) ω d 1 d !! > l . So, µ B x , m Leb d ( O ) ω d 1 d = m , and thanks to Lemma 24, we get that x ∈ O ( m,O ) . 18 Prop osition 26. If Reach( O ) ≥ ( m , O ) , then: { x ∈ R d | d µ, m ( x ) = d min } ( m , O ) = O , wher e for any set A , the notation A stands for S x ∈ A B( x, ) , the -offset of A . Pro of Remind thanks to Prop osition 25 that { x ∈ R d | d µ, m ( x ) = d min } = O ( m , O ) . Moreo ver, O ( m,O ) ( m,O ) ⊂ O . Assume for the sak e of contradiction that the set O \ O ( m,O ) ( m,O ) is non-empty . T ak e a p oin t x in this set and consider B( x 0 , r 0 ) a maximal ball containing x and included in O giv en by Lemma 23. Since x / ∈ O ( m,O ) ( m,O ) , we get that r 0 < ( m, O ) . Moreov er, x 0 b elongs to Sk( O ) and so, thanks to Lemma 22, to M ( O ) . Then, by contin uity of the function distance to the compact set ∂ O , r 0 = d ∂ O ( x 0 ) ≥ Reac h( O ) ≥ ( m , O ) , which is a contradiction. So, O ( m,O ) ( m,O ) = O . A.2 The DTM-signature to discriminate b et w een uniform and non uniform measures. Pro of of Proposition 14: As for Prop osition 25, we get that for any p oint x in O : d µ O , m ( x ) ≥ d min := m Leb d ( O ) ω d 1 d d 1 + d . W e will low er b ound the L 1 -W asserstein distance b etw een d µ O , m ( µ O ) and d ν, m ( ν ) by the integral of F d ν, m ( ν ) o ver the in terv al [0 , d min ] , since F d µ O , m ( µ O ) equals zero on this in terv al. W e thus need to low er b ound F d ν, m ( ν ) ( t ) for all t ≤ d min . As for Prop osition 25, for λ ≥ 1 , any point x of { f ≥ λ } λ − 1 d m Leb d ( O ) ω d 1 d satisfies d ν, m ( x ) ≤ d min λ 1 d . Th us, F d ν, m ( ν ) d min λ 1 d ≥ ν { f ≥ λ } λ − 1 d m Leb d ( O ) ω d 1 d ! . And we get b y denoting λ ( t ) the real n um b er λ satisfying t = d min λ 1 d , that: W 1 (d µ O , m ( µ O ) , d ν, m ( ν )) ≥ Z d min t = 0 ν { f ≥ λ ( t ) } λ ( t ) − 1 d m Leb d ( O ) ω d 1 d ! d t . Since a cum ulative distribution function in non decreasing, w e get: W 1 (d µ O , m ( µ O ) , d ν, m ( ν )) ≥ Z d min t =0 sup t 0 ≤ t ν { f ≥ λ ( t 0 ) } λ ( t 0 ) − 1 d m Leb d ( O ) ω d 1 d ! d t = Z ∞ λ =1 d min 1 d 1 λ 1 d 1 λ sup λ 0 ≥ λ ν { f ≥ λ 0 } λ 0− 1 d m Leb d ( O ) ω d 1 d ! d λ ≥ 1 d + 1 m Leb d ( O ) ω d 1 d Z ∞ λ =1 1 λ 1 d sup λ 0 ≥ λ µ O { f ≥ λ 0 } m Leb d ( O ) λ 0 ω d 1 d ! d λ. No w we assume that the densit y f is Hölder o ver O with parameters χ in [0 , 1] and L in R ∗ + . 19 Pro of of Prop osition 15: First remark that for all p ositive λ , with ( λ ) = λ − 1 d m Leb d ( O ) ω d 1 d w e hav e: { f ≥ λ + L ( λ ) χ } ∩ O ( λ ) ⊂ { f ≥ λ } ( λ ) . A ccording to Prop osition 14, the aim is thus to sho w that for some λ bigger than 1, the set { f ≥ λ + L ( λ ) χ } ∩ O ( λ ) is non-empt y . W e th us fo cus on the supremum of f o ver O ( λ ) , which we denote by k f k ∞ , ( λ ) . Remind that if Reac h( O ) ≥ ( λ ) , then thanks to Prop osition 26, the set O ( λ ) ( λ ) equals O . Since f is Hölder, we can th us build some sequence ( y n ) n ∈ N ∗ in O ( λ ) , suc h that f ( y n ) ≥ k f k ∞ ,O − 1 n − L ( λ ) χ . Finally we get: k f k ∞ , ( λ ) ≥ k f k ∞ ,O − L ( λ ) χ . So the quan tity W 1 (d µ O , m ( µ O ) , d ν, m ( ν )) is p ositive whenev er: k f k ∞ ,O > inf { λ + 2 L ( λ ) χ | λ ≥ 1 , ( λ ) ≤ Reach( O ) } . With λ 0 = 1 , we hav e λ 0 + 2 L ( λ 0 ) χ = 1 + 2 L m Leb d ( O ) ω d χ d . With λ 1 satisfying ( λ 1 ) = Reac h( O ) , we hav e: λ 1 + 2 L ( λ 1 ) χ = 1 (Reac h( O )) d m Leb d ( O ) ω d + 2 L (Reac h( O ) χ ) . W e also ha ve that inf { λ + 2 L ( λ ) χ | λ > 0 } = (2 L ) d d + χ Leb d ( O ) ω d χ d + χ m χ d + χ χ d d χ + d + χ d − χ d + χ . The infimum is attained at λ 2 = χ d d χ + d (2 L ) d χ + d m Leb d ( O ) ω d χ χ + d . It prov es the first part of the prop osition. The second part is a straightforw ard consequence of the pro of of Prop osition 14. B Stabilit y of the DTM-signature Pro of of Proposition 9: The pro of is relativ ely similar to the ones given by Mémoli in [23] for other signatures. F or any map plan π b et ween µ and ν Borel measures on ( X , δ ) and ( Y , γ ) , w e get: 20 W 1 (d µ, m ( µ ) , d ν, m ( ν )) ≤ Z X ×Y | d µ, m ( x ) − d ν, m ( y ) | d π ( x , y ) = Z X ×Y 1 m Z m 0 δ µ,l ( x )d l − 1 m Z m 0 δ ν, l ( y )d l d π ( x , y ) ≤ Z X ×Y 1 m Z m 0 | δ µ,l ( x ) − δ ν,l ( y ) | d l d π ( x , y ) = 1 m Z X ×Y Z m 0 inf { r > 0 | µ (B( x, r )) > l } − inf { r > 0 | ν (B( y , r )) > l } d l d π ( x , y ) = 1 m Z X ×Y Z m 0 Z + ∞ 0 1 µ (B( x,r )) ≤ l − 1 ν (B( y ,r )) ≤ l d r d l d π ( x , y ) ≤ 1 m Z X ×Y Z + ∞ 0 Z m 0 1 µ ( B( x,r )) ≤ l − 1 ν (B( y ,r )) ≤ l d l d r d π ( x , y ) ≤ 1 m Z X ×Y Z + ∞ 0 µ (B( x, r )) ∧ m − ν (B( y , r )) ∧ m d r d π ( x , y ) ≤ 1 m Z X ×Y Z + ∞ 0 Z X ×Y 1 δ ( x,x 0 ) ≤ r − 1 γ ( y ,y 0 ) ≤ r d π ( x 0 , y 0 ) ∧ m d r d π ( x , y ) ≤ 1 m Z X ×Y Z X ×Y Z + ∞ 0 1 δ ( x,x 0 ) ≤ r − 1 γ ( y ,y 0 ) ≤ r d r d π ( x 0 , y 0 ) d π ( x , y ) = 1 m Z X ×Y Z X ×Y | δ ( x, x 0 ) − γ ( y , y 0 ) | d π ( x 0 , y 0 ) d π ( x , y ) , whic h concludes. C The test C.1 A lemma Lemma 27 ( Equality of empirical signa tures under the isomorphic assump- tion) . If ( X , δ, µ ) and ( Y , γ , ν ) ar e two isomorphic mm-sp ac es, then the distributions of the r andom variables √ nW 1 (d ˆ µ N , m ( ˆ µ n ) , d ˆ µ 0 N , m ( ˆ µ 0 n )) and √ nW 1 (d ˆ µ N , m ( ˆ µ n ) , d ˆ ν N , m ( ˆ ν n )) ar e e qual. Her e the empiric al me asur es ar e al l indep endent and the me asur es ˆ µ 0 N and ˆ µ 0 n ar e fr om samples fr om µ . Pro of Remark that for ( X 0 1 , X 0 2 , . . . , X 0 N ) a N -sample of law µ and φ an isomorphism b etw een ( X , δ, µ ) and ( Y , γ , ν ) , the tuple ( φ ( X 0 1 ) , φ ( X 0 2 ) , . . . , φ ( X 0 N )) is a N -sample of law ν . Moreo ver, δ ( X 0 i , X 0 j ) = γ ( φ ( X 0 i ) , φ ( X 0 j )) for all i and j in [ [ 1 , N ] ] . It follows that the distances and the nearest neigh b ours are preserv ed. Th us, the distributions of (d ˆ µ N , m ( X 0 i )) i ∈ [ [ 1 , n ] ] and (d ˆ ν N , m ( Y i )) i ∈ [ [ 1 , n ] ] are equal. 21 The lemma follo ws from the equality: W 1 (d ˆ µ N , m ( ˆ µ n ) , d ˆ ν N , m ( ˆ ν n )) = Z + ∞ 0 1 n n X i =1 1 d ˆ µ N , m ( X i ) ≤ s − n X i =1 1 d ˆ ν N , m ( Y i ) ≤ s d s , with ( X 1 , X 2 , . . . , X N ) a N -sample from µ . C.2 L 1 -W asserstein distance b et ween the la ws of in terest Lemma 28. The quantity W 1 L N ,n,m ( µ, µ ) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) is upp er b ounde d by: 2 √ n ( E [ k d ˆ µ N , m − d µ, m k ∞ , X ] + W 1 (d µ, m ( µ ) , d µ, m ( ˆ µ N )) + k d µ, m − d ˆ µ N , m k ∞ , X ) . Pro of Let ( X 1 , X 2 , . . . X N ) b e a N -sample of law µ , and ˆ µ N the asso ciated empirical mea- sure. W e can upp er bound the L 1 -W asserstein distance b etw een the b o otstrap law L ∗ ( √ nW 1 (d ˆ µ N , m ( µ ∗ n ) , d ˆ µ N , m ( µ 0∗ n )) | ˆ µ N ) and the law of interest L ( √ nW 1 (d ˆ µ N , m ( ˆ µ n ) , d ˆ µ 0 N , m ( ˆ µ 0 n ))) , b y: W 1 L √ nW 1 (d ˆ µ N , m ( µ ∗ n ) , d ˆ µ N , m ( µ 0∗ n )) | ˆ µ N , L √ nW 1 (d µ, m ( µ ∗ n ) , d µ, m ( µ 0∗ n )) | ˆ µ N (1) + W 1 L √ nW 1 (d µ, m ( µ ∗ n ) , d µ, m ( µ 0∗ n )) | ˆ µ N , L √ nW 1 (d µ, m ( ˆ µ n ) , d µ, m ( ˆ µ 0 n )) (2) + W 1 L √ nW 1 (d µ, m ( ˆ µ n ) , d µ, m ( ˆ µ 0 n )) , L √ nW 1 d ˆ µ N , m ( ˆ µ n ) , d ˆ µ 0 N , m ( ˆ µ 0 n ) . (3) W e b ound the term 1 by: 2 √ n k d µ, m − d ˆ µ N , m k ∞ , X . the term 2 by 2 √ nW 1 (d µ, m ( µ ) , d µ, m ( ˆ µ N )) and the term 3 b y 2 √ n E [ k d µ, m − d ˆ µ N , m k ∞ , X ] . This is pro ved in the three follo wing lemmata. Lemma 29 (Study of term 3) . W e have W 1 L ( √ nW 1 (d ˆ µ N , m ( ˆ µ n ) , d ˆ µ 0 N , m ( ˆ µ 0 n ))) , L ( √ n W 1 (d µ, m ( ˆ µ n ) , d µ, m ( ˆ µ 0 n ))) ≤ 2 √ n E [ k d µ, m − d ˆ µ N , m k ∞ , X ] . Pro of T o b ound this L 1 -W asserstein distance, we c ho ose as a transp ort plan the law of the random vector ( √ nW 1 (d ˆ µ N , m ( ˆ µ n ) , d ˆ µ 0 N , m ( ˆ µ 0 n )) , √ n W 1 (d µ, m ( ˆ µ n ) , d µ, m ( ˆ µ 0 n ))) , with ˆ µ n , ˆ µ 0 n , ˆ µ N − n and ˆ µ 0 N − n indep enden t empirical measures of la w µ . Then the L 1 -W asserstein distance is b ounded b y: E [ | √ nW 1 (d ˆ µ N , m ( ˆ µ n ) , d ˆ µ 0 N , m ( ˆ µ 0 n )) − √ n W 1 (d µ, m ( ˆ µ n ) , d µ, m ( ˆ µ 0 n )) | ] , 22 whic h is not bigger than: √ n E [ W 1 (d ˆ µ N , m ( ˆ µ n ) , d µ, m ( ˆ µ n )) + W 1 (d ˆ µ 0 N , m ( ˆ µ 0 n ) , d µ, m ( ˆ µ 0 n ))] . W e b ound the term E [ W 1 (d ˆ µ N , m ( ˆ µ n ) , d µ, m ( ˆ µ n ))] by E [ k d µ, m − d ˆ µ N , m k ∞ , X ] , thanks to Lemma 32. Lemma 30 (Study of term 2) . W e have W 1 L ( √ nW 1 (d µ, m ( ˆ µ n ) , d µ, m ( ˆ µ 0 n )) , L ( √ n W 1 (d µ, m ( µ ∗ n ) , d µ, m ( µ 0∗ n )) | ˆ µ N ) ≤ 2 √ nW 1 (d µ, m ( µ ) , d µ, m ( ˆ µ N )) . Pro of Let π b e the optimal transp ort plan asso ciated to W 1 (d µ, m ( µ ) , d µ, m ( ˆ µ N )) ; see the definition of the L 1 -W asserstein with transp ort plans. F rom a n -sample of law π , we get tw o empirical distributions d µ, m ( ˆ µ n ) and d µ, m ( µ ∗ n ) . Indep enden tly , from another n -sample of law π , w e get d µ, m ( ˆ µ 0 n ) and d µ, m ( µ 0∗ n ) . The L 1 -W asserstein distance is then bounded by: √ n E π ⊗ n ⊗ π ⊗ n [ W 1 (d µ, m ( ˆ µ n ) , d µ, m ( µ ∗ n )) + W 1 (d µ, m ( ˆ µ 0 n ) , d µ, m ( µ 0∗ n ))] . No w remark that, if w e denote ˆ µ n = P n i =1 1 n δ Y i and µ ∗ n = P n i =1 1 n δ Z i , we hav e: W 1 (d µ, m ( ˆ µ n ) , d µ, m ( µ ∗ n )) = Z + ∞ t =0 1 n n X i =1 1 d µ, m ( Y i ) ≤ t − 1 n n X i =1 1 d µ, m ( Z i ) ≤ t d t ≤ 1 n n X i =1 Z + ∞ t =0 1 d µ, m ( Y i ) ≤ t − 1 d µ, m ( Z i ) ≤ t d t = 1 n n X i =1 | d µ, m ( Y i ) − d µ, m ( Z i ) | . So, the L 1 -W asserstein distance is not bigger than 2 √ n E [ | d µ, m ( Y ) − d µ, m ( Z ) | ] , with (d µ, m ( Y ) , d µ, m ( Z )) of law π , so we get the upp er b ound: 2 √ n ( W 1 (d µ, m ( µ ) , d µ, m ( ˆ µ N )) . Lemma 31 (Study of term 1) . W e have W 1 L ( √ nW 1 (d µ, m ( µ ∗ n ) , d µ, m ( µ 0∗ n )) | ˆ µ N ) , L ( √ n W 1 (d ˆ µ N , m ( µ ∗ n ) , d ˆ µ N , m ( µ 0∗ n )) | ˆ µ N ) ≤ 2 √ n k d µ, m − d ˆ µ N , m k ∞ , X . Pro of It is the same pro of as for the first lemma, except that ˆ µ N is fixed. Lemma 32. L et ν , µ and µ 0 b e some me asur es over some metric sp ac e ( X , δ ) , we have: W 1 (d µ, m ( ν ) , d µ 0 , m ( ν )) ≤ Z X | d µ, m ( x ) − d µ 0 , m ( x ) | d ν ( x ) ≤ k d µ, m − d µ 0 , m k ∞ , Supp( ν ) . 23 Pro of W e chose the transport plan (d µ, m ( Y ) , d µ 0 , m ( Y )) for Y of la w ν . Thanks to Prop osition 5 and to the fact that the distance to a measure is 1-Lipsc hitz, w e can derive another upp er b ound dep ending only on the L 1 -W asserstein distance b et ween the measure µ and its empirical versions: Corollary 33. The quantity W 1 L N ,n,m ( µ, µ ) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) is upp er b ounde d by: 2 √ n m E [ W 1 ( ˆ µ N , µ )] + 2 √ n 1 + 1 m W 1 ( ˆ µ N , µ ) . The rates of con vergence of the L 1 -W asserstein distance b etw een a Borel probabilit y measure on the Euclidean space R d and its empirical version are faster when the dimension d is low; see [17]. Th us, we prefer to use the first b ound for regular measures. In this case, w e use rates of con vergence for the distance to a measure, derived in [13]. F or regular measures, in some cases, the b ound in Lemma 28 is b etter than the bound in Corollary 33. C.3 An asymptotic result with the con v ergence to the la w of k G µ,m − G 0 µ,m k 1 Pro of of Lemma 16: The random function √ n F d µ, m ( µ ) − F d µ, m ( ˆ µ n ) con verges weakly in L 1 to some gaussian prossess G µ,m with cov ariance kernel κ ( s, t ) = F d µ, m ( µ ) ( s ) 1 − F d µ, m ( µ ) ( t ) for s ≤ t ; see [3] or part 3.3 of [6]. Thanks to Theorem 2.8 in [5], since L 1 × L 1 is separable and ˆ µ n and ˆ µ 0 n are indep endent, the random vector √ n F d µ, m ( µ ) − F d µ, m ( ˆ µ n ) , √ n F d µ, m ( µ ) − F d µ, m ( ˆ µ 0 n ) con verges weakly to ( G µ,m , G 0 µ,m ) with G µ,m and G 0 µ,m indep enden t Gaussian pro cesses. Since the map ( x, y ) 7→ x − y is contin uous in L 1 , the mapping theorem states that √ n F d µ, m ( ˆ µ 0 n ) − F d µ, m ( ˆ µ n ) con verges weakly to the Gaussian pro cess G µ,m − G 0 µ,m in L 1 . Once more we use the mapping theorem with the contin uous map x 7→ k x k 1 and the definition of the L 1 -W asserstein distance as the L 1 -norm of the cum ulative distribution functions to get that: √ nW 1 (d µ, m ( ˆ µ n ) , d µ, m ( ˆ µ 0 n )) k G µ, m − G 0 µ, m k 1 . W e then get the conv ergence of momen ts following the same metho d as for Theorem 2.4 in [3]. W e hav e the b ound E [ k t 7→ 1 d µ, m ( X i ) ≤ t − 1 d µ, m ( Y i ) ≤ t k 1 ] ≤ D µ < ∞ . Moreo ver, the random function √ n F d µ, m ( ˆ µ 0 n ) − F d µ, m ( ˆ µ n ) con verges weakly to the gaussian pro cess G µ,m − G 0 µ,m in L 1 . So, thanks to Theorem 5.1 in [1] (cited in [2] p.136), w e hav e: E [ √ nW 1 (d µ, m ( ˆ µ n ) , d µ, m ( ˆ µ 0 n ))] → E [ k G µ, m − G 0 µ, m k 1 ] . W e deduce that: W 1 L √ nW 1 (d µ, m ( ˆ µ n ) , d µ, m ( ˆ µ 0 n )) , L k G µ,m − G 0 µ,m k 1 → 0 . Moreo ver, we hav e the b ound: W 1 L √ nW 1 (d µ, m ( ˆ µ n ) , d µ, m ( ˆ µ 0 n )) , L N ,n,m ( µ, µ ) ≤ 2 √ n E [ k d µ, m − d ˆ µ N , m k ∞ , X ] . So, if √ n E [ k d µ, m − d ˆ µ N , m k ∞ , X ] → 0 when N → ∞ , we hav e that: W 1 L N ,n,m ( µ, µ ) , L k G µ,m − G 0 µ,m k 1 → 0 . 24 Finally , with the same argumen ts as for Lemma 28, we get that: W 1 L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) , L k G µ,m − G 0 µ,m k 1 ≤ W 1 L √ nW 1 (d µ, m ( ˆ µ n ) , d µ, m ( ˆ µ 0 n )) , L k G µ,m − G 0 µ,m k 1 + 2 √ nW 1 (d µ, m ( µ ) , d µ, m ( ˆ µ N )) + 2 √ n k d µ, m − d ˆ µ N , m k ∞ , X . Pro of of Proposition 17: Let < α and η b e t wo p ositiv e num b ers. The probability P ( µ,ν ) ( φ N = 1) is upp er b ounded b y P √ nW 1 (d ˆ µ N , m ( ˆ µ n ) , d ˆ ν N , m ( ˆ ν n )) ≥ q α + − η + P ( ˆ q α < q α + − η ) . With a dra wing, we see that P ( ˆ q α < q α + − η ) is upp er bounded b y P W 1 L 1 2 k G µ,m − G 0 µ,m k 1 + 1 2 k G ν,m − G 0 ν,m k 1 , L ∗ ≥ η , where L ∗ = 1 2 L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) + 1 2 L ∗ N ,n,m ( ˆ ν N , ˆ ν N ) . Thanks to the weak conv ergences in Lemma 16 of the paper and the Portman teau lemma, lim sup N →∞ P ( µ,ν ) ( φ N = 1) is th us upp er b ounded by P 1 2 k G µ,m − G 0 µ,m k 1 + 1 2 k G ν,m − G 0 ν,m k 1 ≥ q α + − η . W e no w make η and go to zero and under the contin uity assumption, lim sup N →∞ P ( µ,ν ) ( φ N = 1) ≤ α . As well, we get that lim inf N →∞ P ( µ,ν ) ( φ N = 1) ≥ α . C.4 The case of measures supp orted on a compact subset of R d Pro of of part 2 of Prop osition 18: W e may assume that the diameter D µ of the sup- p ort of the measure µ equals 1. Indeed, if w e apply a dilatation to the measure to make the diameter of its supp ort b e equal to 1, then the quantit y W 1 L N ,n,m ( µ, µ ) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) is simply multiplied b y the parameter of the dilatation. By using Corollary 33 and Theorem 1 of [17], w e hav e a b ound for the exp ectation: E W 1 L N ,n,m ( µ, µ ) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) ≤ C √ n m N − 1 d if d>2 C √ n m N − 1 2 log(1 + N ) if d=2 C √ n m N − 1 2 if d<2 for some p ositiv e constant C dep ending on µ . Pro of of part 3 of Prop osition 18: First remark that for λ > 1 , P W 1 L N ,n,m ( µ, µ ) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) ≥ λ = 0 under the assumption D µ = 1 . W e thus fo cus on v alues of λ not bigger than 1. In this case, with the Theorem 2 of [17], we get easily that: 25 P W 1 L N ,n,m ( µ, µ ) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) ≥ λ ≤ C exp − C 0 λ N 1 d m √ n − C 00 d ! for d>2 C exp − C 0 √ N m √ n λ − C 00 p N N − n log(1+ N − n ) log 2+ 2 √ N √ N m √ n λ − C 00 √ N N − n log(1+ N − n ) 2 for d=2 C exp − C 0 λ √ N m √ n − C 00 2 for d<2 for some p ositiv e constants C , C 0 and C 00 dep ending on µ . W e conclude the pro of with the Borel–Can telli lemma. Pro of of part 1 of Prop osition 18: W e need to sho w that under the assumption ρ > max { d, 2 } 2 , the follo wing prop erties are satisfied: √ n E [ k d µ, m − d ˆ µ N , m k ∞ , X ] → 0 , √ nW 1 (d µ, m ( µ ) , d µ, m ( ˆ µ N )) → 0 a.e. , and √ n k d µ, m − d ˆ µ N , m k ∞ , X → 0 a.e. . W e treat the case d > 2 . The cases d < 2 and d = 2 are similar. Thanks to Theorem 1 of [17], there is some p ositiv e constan t C dep ending on µ suc h that for N big enough: E [ W 1 ( ˆ µ N , µ )] ≤ C N − 1 d . Th us, thanks to part 2 of Proposition 18, the quantit y √ n E [ k d µ, m − d ˆ µ N , m k ∞ , X ] go es to zero if √ n m N − 1 d go es to zero when N go es to infinity . So, this con vergence o ccurs under the assumption ρ > d 2 . W e get from Theorem 2 of [17] that for x ≤ 1 , there are some p ositive constants C and c dep ending on µ such that: P ( W 1 ( ˆ µ N , µ ) ≥ x ) ≤ C exp( − cN x d ) . W e use this inequality with x = m √ n 1 K for p ositive integers K . Thanks to the Borel– Can telli lemma, under the assumption ρ > d 2 , we get that: √ n m W 1 ( µ, ˆ µ N ) → 0 a.e. . So, thanks to Prop osition 5, the third prop erty is true. T o finish, remark that d µ, m ( ˆ µ N ) is the empirical measure asso ciated to d µ, m ( µ ) . Once more we use Theorem 2 of [17] and get that for x ≤ 1 , P ( √ nW 1 (d µ, m ( ˆ µ N ) , d µ, m ( µ )) ≥ x ) ≤ C exp ( − c N n x 2 ) . Thanks to the Borel–Can telli lemma, under the assumption ρ > 1 , the a.e. conv ergence to zero of √ nW 1 (d µ, m ( µ ) , d µ, m ( ˆ µ N )) o ccurs. 26 C.5 The case of ( a, b ) -standard measures Let µ b e a Borel probability measure supported on a connected compact subset X of R d . W e assume this measure to be ( a, b ) -standard for some p ositive n umbers a and b . In this part, we derive rates of con vergence in probability and in exp ectation for the quan tity k d ˆ µ N , m − d µ, m k ∞ , X . Thanks to these results, we can derive upp er b ounds and rates of con vergence in exp ectation for W 1 L N ,n,m ( µ, µ ) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) . W e finally prop ose a choice for the parameter N dep ending on n for which the w eak conv ergences L N ,n,m ( µ, µ ) k G µ,m − G 0 µ,m k 1 and L ∗ N ,n,m ( ˆ µ N , ˆ µ 0 N ) k G µ,m − G 0 µ,m k 1 o ccur. C.5.1 Upp er b ounds for P ( √ n k d ˆ µ N , m − d µ, m k ∞ , X ≥ λ ) W e use the b ounds given in Theorem 1 of [13], with the bound for the modulus of con tinuit y given by Lemma 3 in [13]: ω ( h ) = h a 1 b . W e directly get the following lemma: Lemma 34 (Upp er bound for | d ˆ µ N , m ( x ) − d µ, m ( x ) | ) . L et x b e a fixe d p oint in X and λ a p ositive numb er. W e have, 1 2 P ( | d ˆ µ N , m ( x ) − d µ, m ( x ) | ≥ λ ) ≤ exp − 2 a 2 b N m 2 b − 2 b λ 2 + exp − a 2 b − 1 N b +1 2 m b λ b + exp − a 1 b N b +1 2 b mλ . In order to derive an upp er b ound for k d ˆ µ N , m − d µ, m k ∞ , X , like in [13], we use the fact that the function distance to a measure is 1-Lipschitz and that X is compact, which means that w e can compute a b ound b y upper-b ounding the difference | d ˆ µ N , m ( x ) − d µ, m ( x ) | o ver a finite n umber of p oints x of X . Thanks to the follo wing lemma, the minimal n umber of p oints needed for this purp ose is not bigger than (4 D µ √ d + λ ) d λ d : Lemma 35. L et µ is a me asur e supp orte d on X a c omp act subset of R d , and for λ > 0 denote N ( µ, λ ) = inf { N ∈ N , ∃ x 1 , x 2 . . . x N ∈ X , S i ∈ [ [1 ,N ] ] B( x i , λ ) ⊃ X } . Then, we have: N ( µ, λ ) ≤ D µ √ d + λ d λ d . Pro of The idea is to put a grid on the hypercub e containing X with edges of length D µ . The grid is a union of small hypercub es with edges of length equal to λ √ d , so that the num b er of such small h yp ercub es in to which the big one is split is not sup erior to D µ √ d λ + 1 d . Then, we decide that eac h time the intersection b etw een X and some small hypercub e is non-empty , we keep one of the elemen ts of the in tersection. W e denote x i the element asso ciated to the i -th hypercub e. Finally , each p oint x in X b elongs to a small hypercub e, and its distance to the corresp onding x i is smaller than q P d k =1 λ 2 d = λ . W e thus derive upp er b ounds for √ n k d ˆ µ N , m − d µ, m k ∞ , X : Prop osition 36 (Upper b ound for √ n k d ˆ µ N , m − d µ, m k ∞ , X ) . 27 W e have, λ d 2 4 D µ √ d + λ d P ( √ n k d ˆ µ N , m − d µ, m k ∞ , X ≥ λ ) ≤ exp − a 2 b 2 N m 2 b − 2 b n λ 2 ! + exp − a 2 2 b − 1 N b +1 2 m b n b 2 λ b ! + exp − a 1 b 2 N b +1 2 b m n 1 2 λ ! . Pro of Since the function distance to a measure is 1-Lipsc hitz, we get that: k d ˆ µ N , m − d µ, m k ∞ , X ≤ λ 2 + sup i {| d ˆ µ N , m ( x i ) − d µ, m ( x i ) |} , for the family ( x i ) i asso ciated to a grid which sides are of length equal to λ 4 √ d . W e can th us b ound the probability P ( k d ˆ µ N , m − d µ, m k ∞ , X ≥ λ ) b y: N ( µ, λ 4 ) X i =1 P | d ˆ µ N , m ( x i ) − d µ, m ( x i ) | ≥ λ 2 , with N µ, λ 4 ≤ ( 4 D µ √ d + λ ) d λ d thanks to Lemma 35. C.5.2 Upp er b ounds for the exp ectation E [ k d ˆ µ N , m − d µ, m k ∞ , X ] In order to get upp er b ounds for E [ k d ˆ µ N , m − d µ, m k ∞ , X ] , we use the same tric k as used in [13], whic h is: Lemma 37. L et X a r andom variable such that: P ( X ≥ λ ) ≤ 1 ∧ D λ − q exp( − cλ s ) for some inte gers q and s and some D > 0 . W e have: E [ X ] ≤ ln c c 1 s q s 1 s " 1 + D q s − q − s s (ln c ) − q − s s s # . Mor e p articularly, if c ≥ exp D s q + s s q , then: E [ X ] ≤ 2 ln c c 1 s q s 1 s . Pro of 28 F or any λ 0 > 0 , that we can choose as λ 0 = [ln K ] 1 s c 1 s , we get that: E [ X ] ≤ λ 0 + Z ∞ λ 0 D λ − q exp( − cλ s )d λ ≤ λ 0 + D λ − q − s +1 0 cs exp − cλ s 0 = [ln K ] 1 s c 1 s + D [ln K ] − q − s +1 s scc − q − s +1 s 1 K = [ln K ] 1 s c 1 s + [ln K ] 1 s c 1 s D [ln K ] − q − s s sc − q s 1 K = [ln K ] 1 s c 1 s " 1 + D [ln K ] − q − s s sK c − q s # Finally , if w e choose K = c q s , we get: E [ X ] ≤ q s 1 s ln c c 1 s " 1 + D h q s i − q − s s (ln c ) − q − s s s # . F rom this lemma, we can deriv e the following lemma. Lemma 38. W e have, E [ √ n k d ˆ µ N , m − d µ, m k ∞ , X ] ≤ 0 1 n 1 2 N 1 2 m b − 1 b log N m 2 b − 2 b n !! 1 2 + 0 2 n 1 2 N b +1 2 b m log N b +1 2 m b n b 2 !! 1 b + 0 3 n 1 2 N b +1 2 b m log N b +1 2 b m n 1 2 ! . for some c onstants dep ending on a and b . C.5.3 Upp er bounds for the exp ectation of W 1 L N ,n,m ( µ, µ ) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) Pro of of part 2 of Prop osition 20: F or all λ > 0 , for an y measure µ Ahlfors b -regular with parameters ( a, ∞ ) supp orted on a connected compact subset of R d , w e can use Lemma 28 and Lemma 38 together with the rates of conv ergence of the L 1 -W asserstein distance b etw een empirical and true distribution in [6] to get the following result. 29 If m ≥ 1 2 , then for n big enough w e hav e, for some constants dep ending on a and b : E W 1 L N ,n,m ( µ, µ ) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) ≤ 0 1 n 1 2 ( N ) 1 2 m b − 1 b log N m 2 b − 2 b n !! 1 2 + 0 2 n 1 2 ( N ) b +1 2 b m log N b +1 2 m b n b 2 !! 1 b + 0 3 n 1 2 ( N ) b +1 2 b m log N b +1 2 b m n 1 2 ! + 0 4 n 1 2 N 1 2 . C.5.4 Con v ergence to the law of k G µ,m − G 0 µ,m k 1 Pro of of part 1 of Prop osition 20: In order to get these tw o results, we use Lemma 16. The con vergence to zero of √ n E [ k d µ, m − d ˆ µ N − n , m k ∞ , X ] is a direct consequence of Lemma 38. W e can derive a b ound of its rate of conv ergence in n 1 2 − ρ 2 , up to a logarithm term. The a.e. conv ergence of √ nW 1 (d µ, m ( µ ) , d µ, m ( ˆ µ N )) to zero is deriv ed as in the pro of of Prop osition 18, with the assumption ρ > 1 . Finally , the a.e. conv ergence of √ n k d µ, m − d ˆ µ N , m k ∞ , X to zero is a consequence of Prop osition 36 and of the Borel–Cantelli lemma. It o ccurs under the assumption ρ > 1 . C.6 The p o w er of the test Pro of of Proposition 21 Lemma 39. L et α , κ b e two p ositive numb ers and L and L ∗ two laws of r e al r andom variables. W e denote q α (r esp e ctively q ∗ α ) the α -quantile of the law L (r esp e ctively L ∗ ). If W 1 ( L , L ∗ ) < κ then: q ∗ α ≤ 2 κ α + q α 2 . Pro of With a dra wing, since the L 1 -norm b etw een F L and F L ∗ is smaller than κ , w e hav e: F L ∗ q α 2 + 2 κ α > 1 − α. In this part w e assume that m is fixed in [0 , 1] and N = cn ρ for some ρ > 1 and c > 0 . Recall that our aim is to upper b ound the type I I error, that is: P ( µ,ν ) √ nW 1 (d ˆ µ N , m ( ˆ µ n ) , d ˆ ν N , m ( ˆ ν n )) < ˆ q α . F or some κ = n γ with γ in 0 , 1 2 to b e chosen later, we first upp er b ound the quantile ˆ q α with high probabilit y . As noticed in the proof of Lemma 16, the law of √ nW 1 (d µ, m ( ˆ µ n ) , d µ, m ( ˆ µ 0 n )) con verges to L ( k G µ,m − G 0 µ,m k 1 ) , there is also the conv ergence of the first momen ts. So, for n big enough, we hav e: W 1 ( L √ nW 1 (d µ, m ( ˆ µ n ) , d µ, m ( ˆ µ 0 n )) , L ( k G µ,m − G 0 µ,m k 1 )) ≤ 1 . 30 Then, under the assumption W 1 ( L √ nW 1 (d µ, m ( ˆ µ n ) , d µ, m ( ˆ µ 0 n )) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N )) ≤ κ, w e hav e W 1 ( L ( k G µ,m − G 0 µ,m k 1 ) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N )) ≤ κ + 1 . W e can do the same thing for ν . Th us we get that for n big enough and under the previous assumptions: W 1 1 2 L ( k G µ,m − G 0 µ,m k 1 ) + 1 2 L ( k G ν,m − G 0 ν,m k 1 ) , 1 2 L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) + 1 2 L ∗ N ,n,m ( ˆ ν N , ˆ ν N ) ≤ κ +1 . And thanks to Lemma 39, ˆ q α ≤ ˜ q α 2 + 2 κ + 1 α , with ˜ q α the α -quantile of the law 1 2 L ( k G µ,m − G 0 µ,m k 1 ) + 1 2 L ( k G ν,m − G 0 ν,m k 1 ) . W e need to remark that with similar arguments as for Lemma 28, w e hav e: W 1 L √ nW 1 (d µ, m ( ˆ µ n ) , d µ, m ( ˆ µ 0 n )) , L ∗ N ,n,m ( ˆ µ N , ˆ µ N ) ≤ 2 √ n D µ k F d µ, m ( µ ) − F d µ, m ( ˆ µ N ) k ∞ , (0 , D µ ) + 2 √ n m W 1 ( µ, ˆ µ N ) . No w remark that √ nW 1 (d ˆ µ N , m ( ˆ µ n ) , d ˆ ν N , m ( ˆ ν n )) ≥ √ nW 1 (d µ, m ( µ ) , d ν, m ( ν )) − √ nW 1 (d ˆ µ N , m ( ˆ µ n ) , d µ, m ( µ )) − √ nW 1 (d ˆ ν N , m ( ˆ ν n ) , d ν, m ( ν )) , but as well, thanks to Lemma 32, the definition of the L 1 -W asserstein distance as the L 1 -norm b etw een the cumulativ e distribution functions and to Prop osition 5: √ nW 1 (d ˆ µ N , m ( ˆ µ n ) , d µ, m ( µ )) ≤ √ n m W 1 ( µ, ˆ µ N ) + √ n D µ,m k F d µ, m ( ˆ µ n ) − F d µ, m ( µ ) k ∞ , (0 , D µ ) , with D µ,m the diameter of the supp ort of the measure d µ, m ( µ ) . So, we can finally upp er b ound P ( µ,ν ) √ nW 1 d ˆ µ N − n , m ( ˆ µ n ) , d ˆ ν N − n , m ( ˆ ν n ) < ˆ q α b y P √ n D µ k F d µ, m ( µ ) − F d µ, m ( ˆ µ N ) k ∞ , (0 , D µ ) ≥ κ 4 + P √ n D ν k F d ν, m ( ν ) − F d ν, m ( ˆ ν N ) k ∞ , (0 , D ν ) ≥ κ 4 + 2 P √ n m W 1 ( µ, ˆ µ N ) ≥ κ 4 + 2 P √ n m W 1 ( ν, ˆ ν N ) ≥ κ 4 + P k F d µ, m ( ˆ µ n ) − F d µ, m ( µ ) k ∞ , (0 , D µ ) ≥ W 1 (d µ, m ( µ ) , d ν, m ( ν )) 2 D µ,m − ˜ q α 2 2 D µ,m √ n − (4 + α ) κ + 4 4 D µ,m α √ n + P k F d ν, m ( ˆ ν n ) − F d ν, m ( ν ) k ∞ , (0 , D ν ) ≥ W 1 (d µ, m ( µ ) , d ν, m ( ν )) 2 D ν,m − ˜ q α 2 2 D ν,m √ n − (4 + α ) κ + 4 4 D ν,m α √ n . F or all p ositive , for n big enough, remark that the sum of the last t wo terms can be b ounded thanks to the DKW-Massart inequality [22], b y 4 exp − W 2 1 (d µ, m ( µ ) , d ν, m ( ν )) (2 + ) max D 2 µ , D 2 ν n ! . 31 Remark also that thanks to the DKW-Massart inequality , the first term can b e upp er b ounded by 2 exp − 1 8 D 2 µ cn ρ − 1+2 γ . The second term is similar. Thanks to Theorem 2 in [17], the third term is upp er b ounded b y c 1 exp − c 2 m d n ρ + dγ − d 2 , for some fixed constants c 1 and c 2 . The remaining terms are similar. Since ρ > 1 , we can choose a p ositive γ satisfying: γ < 1 2 , ρ + dγ − d 2 > 1 and ρ − 1 + 2 γ > 1 . So the t w o last expressions are negligible in comparison to the first one. So, for n big enough, P ( µ,ν ) ( √ nW 1 (d ˆ µ N , m ( ˆ µ n ) , d ˆ ν N , m ( ˆ ν n )) < ˆ q α ) is upp er b ounded b y 4 exp − W 2 1 (d µ, m ( µ ) , d ν, m ( ν )) 3 max D 2 µ,m , D 2 ν,m n ! . C.7 Numerical illustrations In this section, we give details on the sim ulations presen ted in Section 5. Recall that we consider the measure µ v , that is, the distribution of the random vector ( R sin ( v R ) + 0 . 03 N , R cos ( v R ) + 0 . 03 N 0 ) with R , N and N 0 indep enden t random v ariables; N and N 0 from the standard normal distribution and R uniform on (0 , 1) . F rom the measure µ 10 w e get a N -sample P = { X 1 , X 2 , . . . , X N } , where N = 2000 . As well, we get a N -sample Q = { Y 1 , Y 2 , . . . , Y N } from the measure µ 20 . It leads to the empirical measures ˆ µ 10 ,N and ˆ µ 20 ,N . On Figure 3, w e plot the cumulativ e distribution function of the measure d ˆ µ 10 , N , m ( ˆ µ 10 , N ) , that is, the function F defined for all t in R b y the proportion of the X i in P satisfying d ˆ µ 10 , N , m ( X i ) ≤ t . It approximates the true cum ulative distribution function asso ciated to the DTM-signature d µ, m ( µ ) . As well, w e plot the cum ulative distribution function of the measure d ˆ µ 20 , N , m ( ˆ µ 20 , N ) . Observe that the signatures are different. Thus, for the choice of parameter m = 0 . 05 , the DTM-signature discriminates w ell b etw een the measures µ 10 and µ 20 . In Figure 4, for m = 0 . 05 and n = 20 , we first generate N M C = 1000 indep endent real- isations of the random v ariable √ nW 1 (d ˆ µ 10 , N − n , m ( ˆ µ 10 , n ) , d ˆ µ 0 10 , N − n , m ( ˆ µ 0 20 , n )) , where ˆ µ 10 ,N and ˆ µ 0 10 ,N are indep endent empirical measures from µ 10 , ˆ µ 10 ,N = n N ˆ µ 10 ,n + N − n N ˆ µ 10 ,N and ˆ µ 0 10 ,N = n N ˆ µ 0 10 ,n + N N ˆ µ 0 10 ,N − n . W e plot the empirical cumulativ e distribution function asso ciated to this N -sample. As well, from tw o fixed N -samples from the la w µ 10 , P and Q , we generate a set boot of N M C random v ariables, as explained in the Algorithm in Section 4.1, and we plot its cumulativ e distribution function. Remark that the too cumu- lativ e distribution functions are close. It means that the α -quan tile of the distribution of the test statistic is w ell approximated by the α -quantile of the b o otstrap distribution. The Figure 5 is obtained by applying the test DTM and the test KS to t wo indep enden t N -samples, 1000 times indep endently , and b y av eraging the n umber of rejections of the hypothesis H 0 . F or the type-I error, the N -samples are b oth from µ 10 , as for the p ow er, a sample is from µ 10 and the other one from µ v . 32
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment