Adversarial Attacks on Neural Network Policies
Machine learning classifiers are known to be vulnerable to inputs maliciously constructed by adversaries to force misclassification. Such adversarial examples have been extensively studied in the context of computer vision applications. In this work,…
Authors: S, y Huang, Nicolas Papernot
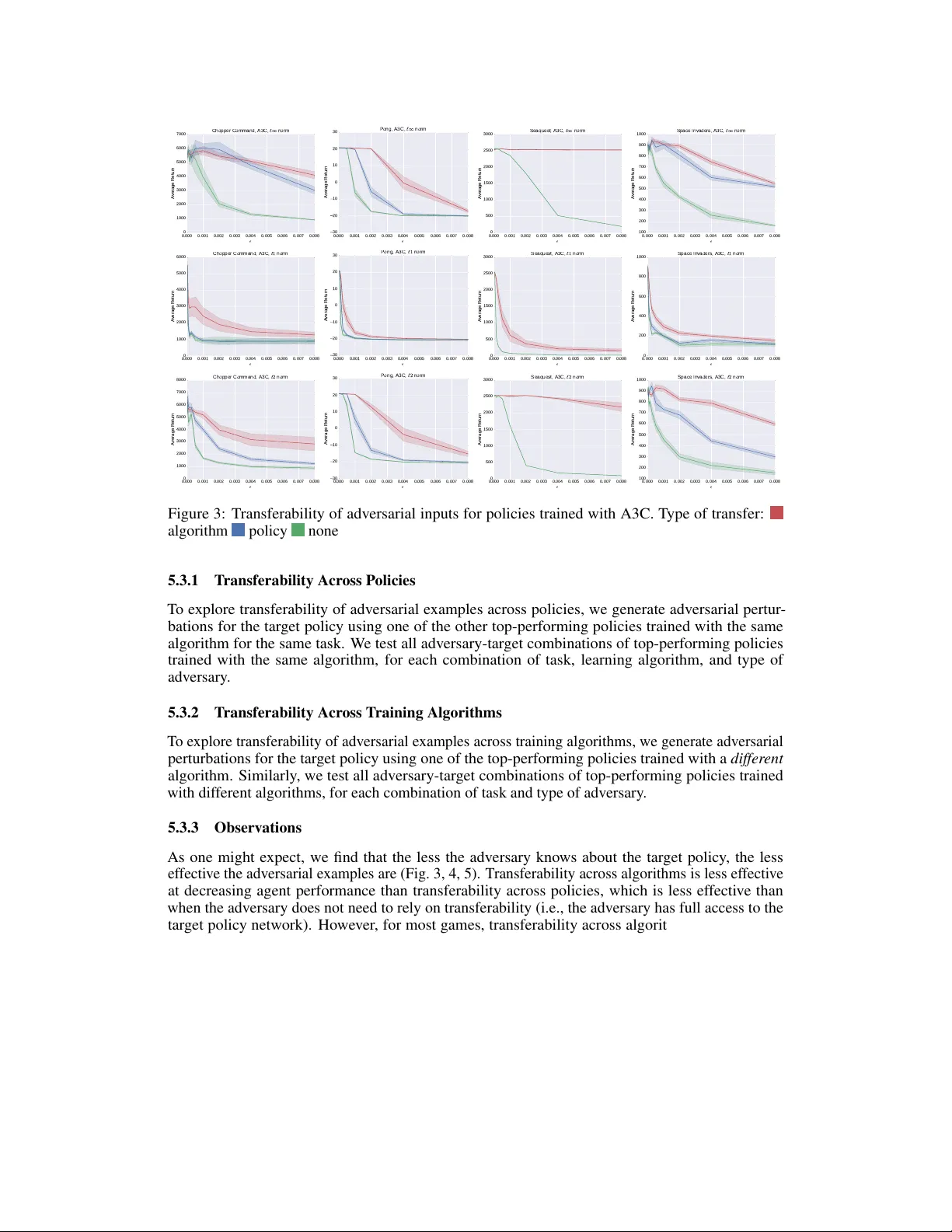
Adversarial Attacks on Neural Network Policies Sandy Huang † , Nicolas Papernot ‡ , Ian Goodfellow § , Y an Duan † § , Pieter Abbeel † § † Univ ersity of California, Berkeley , Department of Electrical Engineering and Computer Sciences ‡ Pennsylvania State Uni versity , School of Electrical Engineering and Computer Science § OpenAI Abstract Machine learning classifiers are known to be vulnerable to inputs maliciously constructed by adversaries to force misclassification. Such adversarial e xamples hav e been extensi vely studied in the conte xt of computer vision applications. In this work, we show adv ersarial attacks are also ef fecti ve when targeting neural network policies in reinforcement learning. Specifically , we show e xisting adv ersarial exam- ple crafting techniques can be used to significantly degrade test-time performance of trained policies. Our threat model considers adversaries capable of introducing small perturbations to the raw input of the policy . W e characterize the degree of vulnerability across tasks and training algorithms, for a subclass of adversarial- example attacks in white-box and black-box settings. Re gardless of the learned task or training algorithm, we observ e a significant drop in performance, e ven with small adversarial perturbations that do not interfere with human perception. V ideos are av ailable at http://rll.berkeley.edu/adversarial . 1 Introduction Recent adv ances in deep learning and deep reinforcement learning (RL) hav e made it possible to learn end-to-end policies that map directly from raw inputs (e.g., images) to a distrib ution o ver actions to take. Deep RL algorithms ha ve trained policies that achiev e superhuman performance on Atari games [ 15 , 19 , 16 ] and Go [ 21 ], perform complex robotic manipulation skills [ 13 ], learn locomotion tasks [19, 14], and driv e in the real world [7]. These policies are parametrized by neural networks, which ha ve been sho wn to be vulnerable to adversarial attacks in supervised learning settings. For e xample, for con volutional neural netw orks trained to classify images, perturbations added to the input image can cause the network to classify the adversarial image incorrectly , while the two images remain essentially indistinguishable to humans [ 22 ]. In this work, we in vestigate whether such adv ersarial examples af fect neural network policies , which are trained with deep RL. W e consider a fully trained policy at test time, and allow the adversary to mak e limited changes to the raw input percei ved from the en vironment before it is passed to the policy . Unlike supervised learning applications, where a fix ed dataset of training e xamples is processed during learning, in reinforcement learning these examples are gathered throughout the training process. In other words, the algorithm used to train a polic y , and even the random initialization of the polic y network’ s weights, affects the states and actions encountered during training. Policies trained to do the same task could concei v ably be significantly different (e.g., in terms of the high-le vel features they e xtract from the raw input), depending on ho w they were initialized and trained. Thus, particular learning algorithms may result in policies more resistant to adversarial attacks. One could also imagine that the differences between supervised learning and reinforcement learning might prev ent an adversary from mounting a successful attack in the black-box scenario, where the attacker does not hav e access to the target polic y network. action taken: down original input action taken: noop adversarial input action taken: up original input action taken: down adversarial input Figure 1: T w o approaches for generating adversarial e xamples, applied to a policy trained using DQN [ 15 ] to play Pong. The dotted arro w starts from the ball and denotes the direction it is tra veling in, and the green rectangle highlights the action that maximizes the Q-v alue, for the giv en input. In both cases, the policy chooses a good action given the original input, but the adv ersarial perturbation results in missing the ball and losing the point. T op: This adversarial example is computed using the fast gradient sign method (FGSM) [10] with an ` ∞ -norm constraint on the adversarial perturbation; the adversarial input is equiv alent to the original input when con verted to 8-bit image encodings, b ut is still able to harm performance. Bottom: FGSM with an ` 1 -norm constraint; the optimal perturbation is to create a “fake” ball lo wer than the position of the actual ball. Our main contribution is to characterize ho w the effecti veness of adv ersarial examples is impacted by two factors: the deep RL algorithm used to learn the policy , and whether the adversary has access to the policy network itself (white-box vs. black-box). W e first analyze three types of white-box attacks on four Atari games trained with three deep reinforcement learning algorithms (DQN [ 15 ], TRPO [ 19 ], and A3C [ 16 ]). W e show that across the board, these trained policies are vulnerable to adversarial e xamples. Howe ver , policies trained with TRPO and A3C seem to be more resistant to adversarial attacks. Fig. 1 shows tw o examples of adversarial attacks on a Pong policy trained with DQN, each at a specific time step during test-time ex ecution. Second, we explore black-box attacks on these same policies, where we assume the adv ersary has access to the training en vironment (e.g., the simulator) but not the random initialization of the target polic y , and additionally may not kno w what the learning algorithm is. In the context of computer vision, Szegedy et al. [ 22 ] observed the transferability pr operty : an adv ersarial example designed to be misclassified by one model is often misclassified by other models trained to solve the same task. W e observe that the cross-dataset transferability property also holds in reinforcement learning applications, in the sense that an adv ersarial example designed to interfere with the operation of one polic y interferes with the operation of another policy , so long as both policies have been trained to solve the same task. Specifically , we observe that adversarial examples transfer between models trained using different trajectory rollouts and between models trained with dif ferent training algorithms. 2 2 Related W ork Adversarial machine learning [ 2 ], and more generally the security and priv acy of machine learn- ing [ 18 ], encompasses a line of w ork that seeks to understand the beha vior of models and learning algorithms in the presence of adv ersaries. Such malicious individuals can target machine learning systems either during learning by tampering with the training data [ 6 ], or during inference by ma- nipulating inputs on which the model is making predictions [5]. Among the perturbations crafted at test time, a class of adversarial inputs kno wn as adversarial e xamples was introduced by [ 22 ]. This first demonstration of the vulnerability of — then state-of-the-art — architectures to perturbations indistinguishable to the human eye led to a series of follo w-up work showing that perturbations could be produced with minimal computing resources [ 10 ] and/or with access to the model label predictions only (thus enabling black-box attacks) [ 17 ], and that these perturbations can also be applied to physical objects [11, 20]. Most work on adversarial e xamples so far has studied their ef fect on supervised learning algorithms. A recent technical report studied the scenario of an adversary interfering with the training of an agent, with the intent of pre venting the agent from learning an ything meaningful [ 3 ]. Our work is the first to study the ability of an adversary to interfere with the operation of an RL agent by presenting adversarial e xamples at test time. 3 Preliminaries In this section, we describe technical background on adversarial example crafting and deep reinforce- ment learning, which are used throughout the paper . 3.1 Adversarial Example Crafting with the Fast Gradient Sign Method T echniques for crafting adversarial examples generally focus on maximizing some measure of harm caused by an adversarial perturbation, constrained by some limit on the size of the perturbation intended to make it less noticeable to a human observer . A range of crafting techniques exist, allowing the attacker to choose an attack that makes the right tradeof f between computational cost and probability of success. For exploratory research purposes, it is common to use a computationally cheap method of generating adversarial perturbations, e ven if this reduces the attack success rate somewhat. W e therefore use the Fast Gradient Sign Method (FGSM) [ 10 ], an existing method for ef ficiently generating adversarial examples in the context of computer vision classification. The FGSM is fast because it makes a linear approximation of a deep model and solv es the maximization problem analytically , in closed form. Despite this approximation, it is still able to reliably fool man y classifiers for computer vision problems, because deep models often learn piece-wise linear functions with surprisingly lar ge pieces. FGSM focuses on adversarial perturbations where each pixel of the input image is changed by no more than . Giv en a linear function g ( x ) = w > x , the optimal adversarial perturbation η that satisfies k η k ∞ < is η = sign ( w ) , (1) since this perturbation maximizes the change in output for the adversarial example ˜ x , g ( ˜ x ) = w > x + w > η . Giv en an image classification network with parameters θ and loss J ( θ , x, y ) , where x is an image and y is a distrib ution over all possible class labels, linearizing the loss function around the input x results in a perturbation of η = sign ( ∇ x J ( θ , x, y )) . (2) 3.2 Deep Reinfor cement Learning Reinforcement learning algorithms train a policy π to optimize the expected cumulativ e re ward receiv ed ov er time. For a giv en state space S and action space A , the policy may be a deterministic function mapping each state to an action: π : S → A , or it may be a stochastic function mapping each state to a distrib ution over actions: π : S → ∆ A , where ∆ A is the probability simplex on A . Here, the state space may consist of images or lo w-dimensional state representations. W e choose to 3 represent π by a function parametrized by θ , for instance θ may be a weighting on features of the state [ 1 ]. In the case of deep reinforcement learning, θ are the weights of a neural network. Over the past few years, a large number of algorithms for deep RL hav e been proposed, including deep Q-networks (DQN) [ 15 ], trust region policy optimization (TRPO) [ 19 ], and asynchronous advantage actor-critic (A3C) [ 16 ]. W e compare the effecti veness of adversarial examples on feed-forward policies trained with each of these three algorithms. 3.2.1 Deep Q-Networks Instead of modeling the policy directly , a DQN [ 15 ] approximately computes, for each state, the Q-v alues for the av ailable actions to take in that state. The Q-value Q ∗ ( s, a ) for a state s and action a is the expected cumulative discounted rew ard obtained by taking action a in state s , and follo wing the optimal policy thereafter . A DQN represents the Q-value function via a neural network trained to minimize the squared Bellman error , using a v ariant of Q-learning. As this is of f-policy learning, it employs an -greedy exploration strate gy . T o reduce the variance of Q-learning updates, e xperience r eplay is used: samples are randomly drawn from a replay buf fer (where all recent transitions are stored) so that they are not correlated due to time. The corresponding policy for a DQN is obtained by choosing the action with the maximum Q-value for each state, hence it is deterministic. 3.2.2 T rust Region Policy Optimization TRPO [ 19 ] is an on-polic y batch learning algorithm. At each training iteration, whole-trajectory rollouts of a stochastic polic y are used to calculate the update to the polic y parameters θ , while controlling the change in the policy as measured by the KL diver gence between the old and new policies. 3.2.3 Asynchronous Advantage Actor -Critic A3C [ 16 ] uses asynchronous gradient descent to speed up and stabilize learning of a stochastic policy . It is based on the actor-critic approach, where the actor is a neural network policy π ( a | s ; θ ) and the critic is an estimate of the value function V ( s ; θ v ) . During learning, small batches of on- policy samples are used to update the policy . The correlation between samples is reduced due to asynchronous training, which stabilizes learning. 4 Adversarial Attacks In our work, we use FGSM both as a white-box attack to compute adversarial perturbations for a trained neural network polic y π θ whose architecture and parameters are a v ailable to the adversary , and as a black-box attack by computing gradients for a separately trained policy π 0 θ to attack π θ using adversarial e xample transferability [22, 10, 17]. 4.1 Applying FGSM to Policies FGSM requires calculating ∇ x J ( θ , x, y ) , the gradient of the cost function J ( θ , x, y ) with respect to the input x . In reinforcement learning settings, we assume the output y is a weighting over possible actions (i.e., the policy is stochastic: π θ : S → ∆ A ). When computing adv ersarial perturbations with FGSM for a trained polic y π θ , we assume the action with the maximum weight in y is the optimal action to take: in other words, we assume the policy performs well at the task. Thus, J ( θ , x, y ) is the cross-entropy loss between y and the distribution that places all weight on the highest-weighted action in y . 1 Of the three learning algorithms we consider , TRPO and A3C both train stochastic policies. Howe ver , DQN produces a deterministic policy , since it al ways selects the action that maximizes the computed Q-v alue. This is problematic because it results in a gradient ∇ x J ( θ , x, y ) of zero for almost all inputs x . Thus, when calculating J ( θ , x, y ) for policies trained with DQN, we define y as a softmax of the computed Q-v alues (with a temperature of 1). Note that we only do this for creating adversarial examples; during test-time e xecution, policies trained with DQN are still deterministic. 1 Functionally , this is equi valent to a technique introduced in the conte xt of image classification, to generate adversarial e xamples without access to the true class label [12]. 4 4.2 Choosing a Norm Constraint Let η be the adversarial perturbation. In certain situations, it may be desirable to change all input features by no more than a tin y amount (i.e., constrain the ` ∞ -norm of η ), or it may be better to change only a small number of input features (i.e., constrain the ` 1 -norm of η ). Thus we consider variations of FGSM that restrict the ` 1 - and ` 2 -norm of η , as well as the original v ersion of FGSM that restricts the ` ∞ -norm (Sec. 3.1). Linearizing the cost function J ( θ , x, y ) around the current input x , the optimal perturbation for each type of norm constraint is: η = sign ( ∇ x J ( θ , x, y )) for constraint k η k ∞ ≤ √ d ∗ ∇ x J ( θ ,x,y ) k∇ x J ( θ ,x,y ) k 2 for constraint k η k 2 ≤ k 1 d k 2 maximally perturb highest-impact dimensions with budget d for constraint k η k 1 ≤ k 1 d k 1 (3) where d is the number of dimensions of input x . Note that the ` 2 -norm and ` 1 -norm constraints ha ve adjusted to be the ` 2 - and ` 1 -norm of the v ector 1 d , respectiv ely , since that is the amount of perturbation under the ` ∞ -norm constraint. In addition, the optimal perturbation for the ` 1 -norm constraint either maximizes or minimizes the feature value at dimensions i of the input, ordered by decreasing |∇ θ J ( θ , x, y ) i | . For this norm, the adv ersary’ s budget — the total amount of perturbation the adv ersary is allowed to introduce in the input — is d . 5 Experimental Evaluation W e ev aluate our adversarial attacks on four Atari 2600 games in the Arcade Learning En vironment [ 4 ]: Chopper Command, Pong, Seaquest, and Space Inv aders. W e choose these games to encompass a variety of interesting en vironments; for instance, Chopper Command and Space In vaders include multiple enemies. 5.1 Experimental Setup W e trained each game with three deep reinforcement learning algorithms: A3C [ 16 ], TRPO [ 19 ], and DQN [15]. For DQN, we use the same pre-processing and neural network architecture as in [ 15 ] (Appendix A). W e also use this architecture for the stochastic policies trained by A3C and TRPO. Specifically , the input to the neural network policy is a concatenation of the last 4 images, conv erted from RGB to luminance (Y) and resized to 84 × 84 . Luminance values are rescaled to be from 0 to 1. The output of the policy is a distrib ution over possible actions. For each game and training algorithm, we train fiv e policies starting from dif ferent random initial- izations. For our e xperiments, we focus on the top-performing trained policies, which we define as all policies that perform within 80% of the maximum score for the last ten training iterations. W e cap the number of policies at three for each g ame and training algorithm. Certain combinations (e.g., Seaquest with A3C) had only one policy meet these requirements. In order to reduce the variance of our experimental results, the average return for each result reported is the av erage cumulative re ward across ten rollouts of the target policy , without discounting rew ards. 5.2 V ulnerability to White-Box Attacks First, we are interested in ho w vulnerable neural netw ork policies are to white-box adversarial- example attacks, and how this is affected by the type of adv ersarial perturbation and by how the policy is trained. If these attacks are ef fecti ve, ev en small adversarial perturbations (i.e., small for FGSM) will be able to significantly lower the performance of the tar get trained network, as observed in [ 10 ] for image classifiers. W e ev aluate multiple settings of across all four games and three training algorithms, for the three types of norm-constraints for FGSM. 5 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 1000 2000 3000 4000 5000 6000 7000 Average Return Chopper Command, A3C 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 30 20 10 0 10 20 30 Average Return Pong, A3C 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 500 1000 1500 2000 2500 3000 Average Return Seaquest, A3C 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 200 400 600 800 1000 Average Return Space Invaders, A3C 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 1000 2000 3000 4000 5000 6000 7000 8000 Average Return Chopper Command, TRPO 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 30 20 10 0 10 20 30 Average Return Pong, TRPO 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 200 300 400 500 600 700 800 900 1000 1100 Average Return Seaquest, TRPO 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 200 400 600 800 1000 1200 1400 Average Return Space Invaders, TRPO 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 400 600 800 1000 1200 1400 1600 1800 2000 2200 Average Return Chopper Command, DQN 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 25 20 15 10 5 0 5 10 15 20 Average Return Pong, DQN 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 500 1000 1500 2000 2500 Average Return Seaquest, DQN 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 100 200 300 400 500 600 700 800 Average Return Space Invaders, DQN Figure 2: Comparison of the effecti veness of ` ∞ , ` 2 , and ` 1 FGSM adversaries on four Atari games trained with three learning algorithms. The a verage return is taken across ten trajectories. Constraint on FGSM perturbation: ` ∞ -norm ` 2 -norm ` 1 -norm 5.2.1 Observations W e find that re gardless of which game the polic y is trained for or ho w it is trained, it is indeed possible to significantly decrease the policy’ s performance through introducing relati vely small perturbations in the inputs (Fig. 2). Notably , in many cases an ` ∞ -norm FGSM adversary with = 0 . 001 decreases the agent’ s per- formance by 50% or more; when con verted to 8-bit image encodings, these adversarial inputs are indistinguishable from the original inputs. In cases where it is not essential for changes to be imperceptible, using an ` 1 -norm adversary may be a better choice: giv en the same , ` 1 -norm adv ersaries are able to achiev e the most significant decreases in agent performance. They are able to sharply decrease the agent’ s performance just by changing a few pix els (by large amounts). W e see that policies trained with A3C, TRPO, and DQN are all susceptible to adversarial inputs. Inter- estingly , policies trained with DQN are more susceptible, especially to ` ∞ -norm FGSM perturbations on Pong, Seaquest, and Space In vaders. 5.3 V ulnerability to Black-Box Attacks In practice, it is often the case that an adv ersary does not have complete access to the neural network of the target policy [ 17 ]. This threat model is frequently referred to as a black-box scenario. W e in vestigate how vulnerable neural network policies are to black-box attacks of the follo wing two variants: 1. The adversary has access to the training en vironment and knowledge of the training algorithm and hyperparameters. It knows the neural network architecture of the target policy netw ork, but not its random initialization. W e will refer to this as transferability across policies. 2. The adversary additionally has no kno wledge of the training algorithm or hyperparameters. W e will refer to this as transferability across algorithms. 6 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 1000 2000 3000 4000 5000 6000 7000 Average Return C h o p p e r C o m m a n d , A 3 C , ` ∞ n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 30 20 10 0 10 20 30 Average Return P o n g , A 3 C , ` ∞ n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 500 1000 1500 2000 2500 3000 Average Return S e a q u e s t , A 3 C , ` ∞ n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 100 200 300 400 500 600 700 800 900 1000 Average Return S p a c e I n v a d e r s , A 3 C , ` ∞ n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 1000 2000 3000 4000 5000 6000 Average Return C h o p p e r C o m m a n d , A 3 C , ` 1 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 30 20 10 0 10 20 30 Average Return P o n g , A 3 C , ` 1 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 500 1000 1500 2000 2500 3000 Average Return S e a q u e s t , A 3 C , ` 1 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 200 400 600 800 1000 Average Return S p a c e I n v a d e r s , A 3 C , ` 1 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 1000 2000 3000 4000 5000 6000 7000 8000 Average Return C h o p p e r C o m m a n d , A 3 C , ` 2 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 30 20 10 0 10 20 30 Average Return P o n g , A 3 C , ` 2 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 500 1000 1500 2000 2500 3000 Average Return S e a q u e s t , A 3 C , ` 2 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 100 200 300 400 500 600 700 800 900 1000 Average Return S p a c e I n v a d e r s , A 3 C , ` 2 n o r m Figure 3: T ransferability of adversarial inputs for policies trained with A3C. T ype of transfer: algorithm policy none 5.3.1 T ransferability Across Policies T o e xplore transferability of adversarial examples across policies, we generate adversarial pertur - bations for the tar get policy using one of the other top-performing policies trained with the same algorithm for the same task. W e test all adversary-tar get combinations of top-performing policies trained with the same algorithm, for each combination of task, learning algorithm, and type of adversary . 5.3.2 T ransferability Across T raining Algorithms T o explore transferability of adversarial examples across training algorithms, we generate adversarial perturbations for the tar get policy using one of the top-performing policies trained with a differ ent algorithm. Similarly , we test all adversary-target combinations of top-performing policies trained with different algorithms, for each combination of task and type of adv ersary . 5.3.3 Observations As one might e xpect, we find that the less the adversary knows about the tar get polic y , the less effecti v e the adversarial examples are (Fig. 3, 4, 5). Transferability across algorithms is less effecti ve at decreasing agent performance than transferability across policies, which is less effecti ve than when the adversary does not need to rely on transferability (i.e., the adv ersary has full access to the target policy network). Howe ver , for most games, transferability across algorithms is still able to significantly decrease the agent’ s performance, especially for lar ger values of . Notably for ` 1 -norm adversaries, transferability across algorithms is nearly as ef fectiv e as no transfer - ability , for most game and algorithm combinations. 6 Discussion and Future W ork This direction of work has significant implications for both online and real-world deployment of neural network policies. Our experiments show it is fairly easy to confuse such policies with computationally-efficient adversarial examples, e ven in black-box scenarios. Based on [ 11 ], it is possible that these adversarial perturbations could be applied to objects in the real world, for 7 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 1000 2000 3000 4000 5000 6000 7000 8000 Average Return C h o p p e r C o m m a n d , T R P O , ` ∞ n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 30 20 10 0 10 20 30 Average Return P o n g , T R P O , ` ∞ n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 300 400 500 600 700 800 900 1000 1100 Average Return S e a q u e s t , T R P O , ` ∞ n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 200 400 600 800 1000 1200 1400 Average Return S p a c e I n v a d e r s , T R P O , ` ∞ n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 1000 2000 3000 4000 5000 6000 7000 8000 Average Return C h o p p e r C o m m a n d , T R P O , ` 1 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 30 20 10 0 10 20 30 Average Return P o n g , T R P O , ` 1 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 200 400 600 800 1000 Average Return S e a q u e s t , T R P O , ` 1 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 200 400 600 800 1000 1200 1400 Average Return S p a c e I n v a d e r s , T R P O , ` 1 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 1000 2000 3000 4000 5000 6000 7000 8000 Average Return C h o p p e r C o m m a n d , T R P O , ` 2 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 30 20 10 0 10 20 30 Average Return P o n g , T R P O , ` 2 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 200 300 400 500 600 700 800 900 1000 1100 Average Return S e a q u e s t , T R P O , ` 2 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 200 400 600 800 1000 1200 1400 Average Return S p a c e I n v a d e r s , T R P O , ` 2 n o r m Figure 4: T ransferability of adversarial inputs for policies trained with TRPO. T ype of transfer: algorithm policy none 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 400 600 800 1000 1200 1400 1600 1800 2000 2200 Average Return C h o p p e r C o m m a n d , D Q N , ` ∞ n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 25 20 15 10 5 0 5 10 15 20 Average Return P o n g , D Q N , ` ∞ n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 500 1000 1500 2000 2500 Average Return S e a q u e s t , D Q N , ` ∞ n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 100 200 300 400 500 600 700 800 Average Return S p a c e I n v a d e r s , D Q N , ` ∞ n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 400 600 800 1000 1200 1400 1600 1800 2000 2200 Average Return C h o p p e r C o m m a n d , D Q N , ` 1 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 25 20 15 10 5 0 5 10 15 20 Average Return P o n g , D Q N , ` 1 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 500 1000 1500 2000 2500 Average Return S e a q u e s t , D Q N , ` 1 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 100 200 300 400 500 600 700 Average Return S p a c e I n v a d e r s , D Q N , ` 1 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 600 800 1000 1200 1400 1600 1800 2000 2200 Average Return C h o p p e r C o m m a n d , D Q N , ` 2 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 25 20 15 10 5 0 5 10 15 20 Average Return P o n g , D Q N , ` 2 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 500 1000 1500 2000 2500 Average Return S e a q u e s t , D Q N , ` 2 n o r m 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 ² 0 100 200 300 400 500 600 700 Average Return S p a c e I n v a d e r s , D Q N , ` 2 n o r m Figure 5: T ransferability of adversarial inputs for policies trained with DQN. T ype of transfer: algorithm policy none example adding strate gically-placed paint to the surface of a road to confuse an autonomous car’ s lane-following polic y . Thus, an important direction of future work is de veloping defenses against adversarial attacks. This could in volv e adding adversarially-perturbed e xamples during training time (as in [ 10 ]), or it could in volv e detecting adversarial input at test time, to be able to deal with it appropriately . 8 References [1] P . Abbeel and A. Y . Ng. Apprenticeship learning via inv erse reinforcement learning. In Pr oceedings of the T wenty-F irst International Confer ence on Machine Learning , 2004. [2] M. Barreno, B. Nelson, R. Sears, A. D. Joseph, and J. D. T ygar . Can machine learning be secure? In Pr oceedings of the 2006 A CM Symposium on Information, Computer and Communications Security , pages 16–25, 2006. [3] V . Behzadan and A. Munir . V ulnerability of deep reinforcement learning to policy induction attacks. arXiv preprint , 2017. [4] M. G. Bellemare, Y . Naddaf, J. V eness, and M. Bo wling. The arcade learning en vironment: An ev aluation platform for general agents. J ournal of Artificial Intelligence Resear ch , 47:253–279, 06 2013. [5] B. Biggio, I. Corona, D. Maiorca, B. Nelson, N. Šrndi ´ c, P . Laskov , G. Giacinto, and F . Roli. Evasion attacks against machine learning at test time. In Machine Learning and Knowledge Discovery in Databases , pages 387–402, 2013. [6] B. Biggio, B. Nelson, and L. Pa vel. Poisoning attacks against support vector machines. In Pr oceedings of the T wenty-Ninth International Confer ence on Machine Learning , 2012. [7] M. Bojarski, D. D. T esta, D. Dworako wski, B. Firner , B. Flepp, P . Go yal, L. D. Jack el, M. Mon- fort, U. Muller , J. Zhang, X. Zhang, J. Zhao, and K. Zieba. End to end learning for self-driving cars. arXiv preprint , 2016. [8] G. Brockman, V . Cheung, L. Pettersson, J. Schneider , J. Schulman, J. T ang, and W . Zaremba. Openai gym, 2016. [9] Y . Duan, X. Chen, R. Houthooft, J. Schulman, and P . Abbeel. Benchmarking deep reinforcement learning for continuous control. In Pr oceedings of the Thirty-Thir d International Confer ence on Machine Learning , 2016. [10] I. J. Goodfello w , J. Shlens, and C. Szegedy . Explaining and harnessing adversarial examples. In Pr oceedings of the Thir d International Confer ence on Learning Repr esentations , 2015. [11] A. Kurakin, I. Goodfello w , and S. Bengio. Adversarial e xamples in the physical world. arXiv pr eprint arXiv:1607.02533 , 2016. [12] A. Kurakin, I. Goodfello w , and S. Bengio. Adversarial machine learning at scale. Pr oceedings of the F ifth International Confer ence on Learning Repr esentations , 2017. [13] S. Levine, C. Finn, T . Darrell, and P . Abbeel. End-to-end training of deep visuomotor policies. Journal of Mac hine Learning Resear ch , 17(39):1–40, 2016. [14] T . P . Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T . Erez, Y . T assa, D. Silv er , and D. W ierstra. Continuous control with deep reinforcement learning. In Pr oceedings of the F ourth International Confer ence on Learning Repr esentations , 2016. [15] V . Mnih, K. Kavukcuoglu, D. Silv er , A. Graves, I. Antonoglou, D. W ierstra, and M. Riedmiller . Playing atari with deep reinforcement learning. In NIPS W orkshop on Deep Learning , 2013. [16] V . Mnih, A. Puigdomenech Badia, M. Mirza, A. Graves, T . P . Lillicrap, T . Harley , D. Silver , and K. Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In Pr oceedings of the Thirty-Thir d International Confer ence on Machine Learning , 2016. [17] N. Papernot, P . McDaniel, I. Goodfellow , S. Jha, Z. B. Celik, and A. Swami. Practical black-box attacks against deep learning systems using adversarial examples. arXiv preprint arXiv:1602.02697 , 2016. [18] N. P apernot, P . McDaniel, A. Sinha, and M. W ellman. T o wards the science of security and priv acy in machine learning. arXiv pr eprint arXiv:1611.03814 , 2016. 9 [19] J. Schulman, S. Le vine, P . Moritz, M. I. Jordan, and P . Abbeel. T rust region polic y optimization. In Pr oceedings of the Thirty-Second International Confer ence on Machine Learning , 2015. [20] M. Sharif, S. Bhagav atula, L. Bauer , and M. K. Reiter . Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. In Pr oceedings of the 2016 ACM SIGSA C Confer ence on Computer and Communications Security , pages 1528–1540, 2016. [21] D. Silver , A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. v an den Driessche, J. Schrittwieser , I. Antonoglou, V . Panneershelv am, M. Lanctot, S. Dieleman, D. Gre we, J. Nham, N. Kalch- brenner , I. Sutsk ev er , T . Lillicrap, M. Leach, K. Kavukcuoglu, T . Graepel, and D. Hassabis. Mastering the game of go with deep neural networks and tree search. Nature , 529:484–503, 2016. [22] C. Szegedy , W . Zaremba, I. Sutske ver , J. Bruna, D. Erhan, I. Goodfellow , and R. Fergus. Intriguing properties of neural networks. In Pr oceedings of the Second International Confer ence on Learning Repr esentations , 2014. A Experimental Setup W e set up our e xperiments within the rllab [ 9 ] framework. W e use a parallelized v ersion of the rllab implementation of TRPO, and inte grate outside implementations of DQN 2 and A3C 3 . W e use OpenAI Gym en vironments [8] as the interface to the Arcade Learning En vironment [4]. The policies use the netw ork architecture from [ 15 ]: a con volutional layer with 16 filters of size 8 × 8 with a stride of 4, followed by a con volutional layer with 32 filters of size 4 × 4 with a stride of 2. The last layer is a fully-connected layer with 256 hidden units. All hidden layers are follo wed by a rectified nonlinearity . For all games, we set the frame skip to 4 as in [ 15 ]. The frame skip specifies the number of times the agent’ s chosen action is repeated. A.1 T raining W e trained policies with TRPO and A3C on Amazon EC2 c4.8xlar ge machines. For each policy , we ran TRPO for 2,000 iterations of 100,000 steps each, which took 1.5 to 2 days. W e set the bound on the KL div ergence to 0.01, as in [19]. For A3C, we used 18 actor -learner threads and a learning rate of 0.0004. As in [ 16 ], we use an entropy regularization weight of 0.01, use RMSProp for optimization with a decay factor of 0.99, update the policy and v alue networks e very 5 time steps, and share all weights except the output layer between the policy and v alue networks. For each policy , we ran A3C for 200 iterations of 1,000,000 steps each, which took 1.5 to 2 days. For DQN, we trained policies on Amazon EC2 p2.xlarge machines. W e used 100,000 steps per epoch and trained for two days. 2 github.com/spragunr/deep_q_rl 3 github.com/muupan/async- rl 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment