신경망 정책을 겨냥한 적대적 공격: 강화학습의 새로운 위협
본 논문은 이미지 분류에서 입증된 적대적 예제 기법을 강화학습(RL) 에 적용해, 학습된 신경망 정책이 작은 입력 교란에도 크게 성능이 저하되는 현상을 실험적으로 입증한다. 화이트박스·블랙박스 상황 모두에서 Atari 4종 게임과 DQN, TRPO, A3C 세 알고리즘을 대상으로 FGSM 기반 공격을 수행했으며, 특히 TRPO와 A3C가 DQN보다 상대적으로 강인함을 보였다. 또한 정책 간 교차 전이(transferability) 현상이 존재함…
저자: S, y Huang, Nicolas Papernot
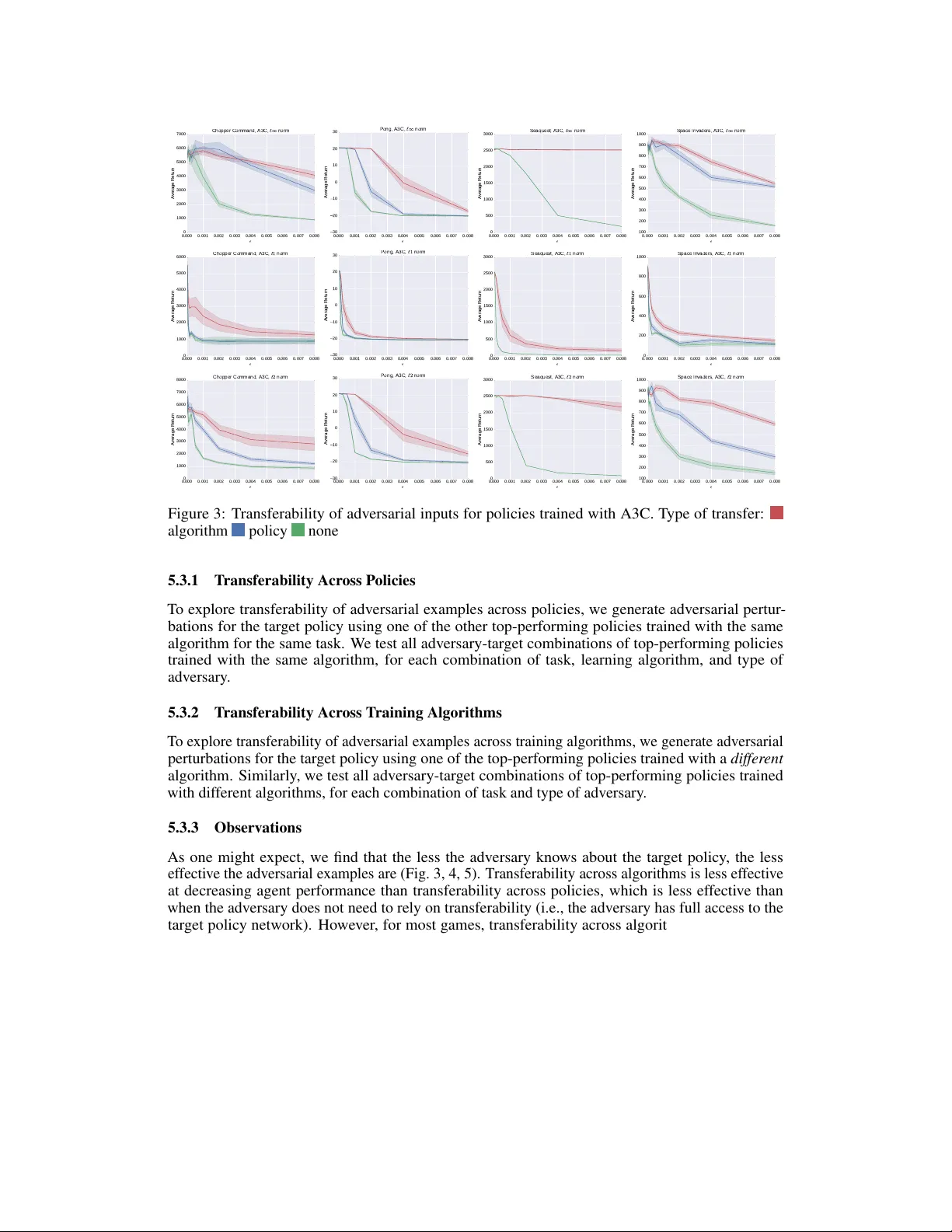
본 논문은 “Adversarial Attacks on Neural Network Policies”라는 제목 아래, 강화학습(RL)에서 사용되는 신경망 기반 정책이 적대적 예제(Adversarial Example) 공격에 얼마나 취약한지를 체계적으로 조사한다. 연구 동기는 이미지 분류 분야에서 적대적 교란이 널리 알려진 반면, RL에서는 아직 충분히 탐구되지 않았다는 점이다. 저자들은 기존의 Fast Gradient Sign Method(FGSM)를 활용해, 정책 네트워크에 작은 입력 교란을 가함으로써 테스트 시 성능이 크게 저하되는 현상을 실험한다.
**위협 모델 및 공격 방법**
- **위협 모델**: 공격자는 정책이 관찰하는 원시 입력(예: 게임 화면)에 제한된 크기의 교란을 삽입할 수 있다. 교란은 인간이 구분하기 어려운 수준으로 제한한다(‑∞, ‑2, ‑1 노름 제약).
- **화이트박스 공격**: 공격자는 목표 정책의 구조와 파라미터에 완전 접근한다. 손실 함수는 정책이 가장 높은 확률을 부여한 행동을 정답으로 가정한 교차 엔트로피이며, 이를 입력에 대해 미분해 FGSM 교란을 계산한다. DQN처럼 결정적 정책일 경우, Q값을 소프트맥스로 변환해 확률 분포를 만든 뒤 동일 절차를 적용한다.
- **블랙박스 공격**: 공격자는 목표 정책에 대한 직접적인 접근 권한이 없으며, 대신 동일 환경에서 별도로 학습된 대체 정책(또는 다른 알고리즘)으로부터 교란을 생성한다. 생성된 교란을 목표 정책에 그대로 적용해 전이성을 검증한다.
**실험 설정**
- **환경**: Atari 2600 게임 4종(Chopper Command, Pong, Seaquest, Space Invaders) – 다양한 시각·동적 복잡성을 제공.
- **알고리즘**: DQN, TRPO, A3C – 각각 값 기반, 정책 기반, 비동기 정책 기반을 대표한다.
- **학습**: 각 게임·알고리즘 조합마다 5번 무작위 초기화로 학습하고, 마지막 10 에피소드 평균 점수가 최고 점수의 80% 이상인 정책을 “상위 정책”으로 선정한다. 각 조합당 최대 3개의 상위 정책을 대상으로 공격을 수행한다.
- **평가**: 교란 적용 후 10번 롤아웃을 수행해 평균 반환값을 기록한다. ε(교란 크기)는 0.000~0.008 범위에서 ‑∞, ‑2, ‑1 노름 각각에 대해 변동한다.
**화이트박스 결과**
- **전반적 취약성**: 모든 정책이 교란에 의해 성능이 크게 감소한다. 특히 DQN 정책은 ε≈0.002에서 평균 점수가 50% 이상 급락한다.
- **노름 별 차이**: ‑∞ 노름 제약(전역 교란)이 가장 파괴적이며, ‑1 노름(희소 교란)은 상대적으로 덜 효과적이다. 이는 전체 픽셀을 조금씩 바꾸는 것이 중요한 시각적 특징을 왜곡하기 때문으로 해석된다.
- **알고리즘 별 차이**: TRPO와 A3C 정책은 동일 ε에서도 DQN보다 완만한 성능 저하를 보인다. 이는 두 알고리즘이 정책을 확률적으로 학습하고, KL 제한(TRPO)이나 비동기 업데이트(A3C)와 같은 정규화가 정책을 더 평탄한 손실 지형에 위치시켜 교란에 대한 민감도를 낮추는 것으로 추정된다.
**블랙박스 결과**
- **전이성 확인**: 한 정책(예: DQN)으로 만든 교란이 다른 정책(예: TRPO)에도 동일하게 성능 저하를 일으킨다. 이는 “전이성(transferability)”이 RL에서도 존재함을 의미한다.
- **알고리즘 간 전이**: 서로 다른 학습 알고리즘으로 학습된 정책 간에도 교란이 효과적으로 전달된다. 이는 정책이 동일한 상태-행동 매핑을 학습하면서도 비슷한 특징 표현을 공유하기 때문이다.
**시각적 사례**
Figure 1에서는 Pong 게임에서 DQN 정책에 대한 두 종류의 FGSM 교란을 보여준다. ‑∞ 노름 교란은 8‑bit 이미지로 변환해도 인간이 구분하기 어려운 수준이지만, 공의 위치를 왜곡해 정책이 공을 놓치게 만든다. ‑1 노름 교란은 실제 공보다 낮은 가짜 공을 생성해 정책이 잘못된 행동을 선택하도록 만든다.
**논문의 의의 및 향후 과제**
1. **RL에서도 적대적 공격이 실질적 위협** – 작은 교란만으로도 인간이 인지하기 어려운 수준에서 정책을 무력화한다.
2. **알고리즘 선택이 방어에 영향** – 정책 기반(TRPO, A3C)이 값 기반(DQN)보다 상대적으로 강인함을 보이며, 이는 향후 안전한 RL 설계에 참고될 수 있다.
3. **전이성 활용 가능성** – 블랙박스 상황에서도 교란을 재사용할 수 있기에, 실제 시스템에 대한 공격 비용이 낮아진다.
4. **방어 연구 필요** – 적대적 훈련(adversarial training), 정책 정규화, 입력 검증 등 방어 메커니즘 개발이 시급하다.
5. **물리적 적용 확대** – 현재는 시뮬레이션(Atari)에서 검증했지만, 로봇, 자율주행 등 실제 센서 입력을 갖는 시스템에서도 동일한 위협이 존재한다는 점을 강조한다.
결론적으로, 이 논문은 강화학습 정책이 기존 이미지 분류와 마찬가지로 적대적 예제에 매우 취약함을 실험적으로 입증하고, 학습 알고리즘과 전이성이라는 두 가지 중요한 변수를 통해 공격 성공률을 설명한다. 이는 RL 시스템의 보안·안전성을 논의할 때 반드시 고려해야 할 핵심 요소임을 강조한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기