Parallelizing Word2Vec in Multi-Core and Many-Core Architectures
Word2vec is a widely used algorithm for extracting low-dimensional vector representations of words. State-of-the-art algorithms including those by Mikolov et al. have been parallelized for multi-core CPU architectures, but are based on vector-vector …
Authors: Shihao Ji, Nadathur Satish, Sheng Li
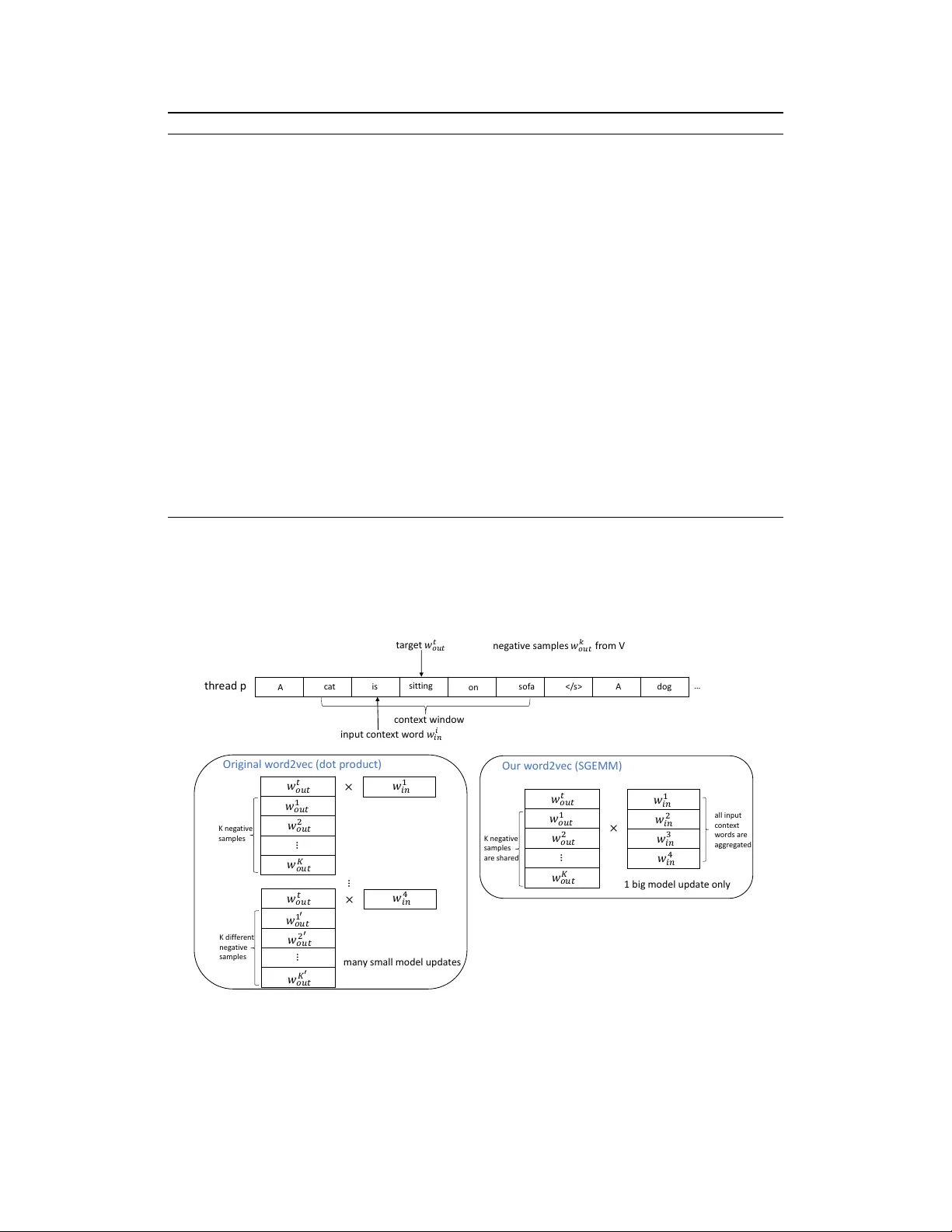
Parallelizing W ord2V ec in Multi-Cor e and Many-Cor e Architectur es Shihao Ji, Nadathur Satish, Sheng Li, Pradeep Dubey Parallel Computing Lab, Intel Labs, USA {shihao.ji, nadathur.rajagopalan.satish, sheng.r.li, pradeep.dubey}@intel.com Abstract W ord2vec is a widely used algorithm for e xtracting low-dimensional v ector rep- resentations of words. State-of-the-art algorithms including those by Mikolov et al. [ 5 , 6 ] have been parallelized for multi-core CPU architectures, but are based on vector -vector operations with “Hogwild" updates that are memory-bandwidth intensiv e and do not efficiently use computational resources. In this paper , we propose “HogBatch" by impro ving reuse of v arious data structures in the algorithm through the use of minibatching and negati v e sample sharing, hence allowing us to express the problem using matrix multiply operations. W e also explore dif ferent techniques to distribute w ord2vec computation across nodes in a compute cluster , and demonstrate good strong scalability up to 32 nodes. The new algorithm is particularly suitable for modern multi-core/many-core architectures, especially Intel’ s latest Knights Landing processors, and allo ws us to scale up the compu- tation near linearly across cores and nodes, and process hundreds of millions of words per second, which is the fastest word2v ec implementation to the best of our knowledge. 1 From Hogwild to HogBatch W e refer the reader to [ 5 , 6 ] for an introduction to word2v ec and its optimization problem. The original implementation of word2vec by Mikolov et al. 1 uses Hogwild [ 7 ] to parallelize SGD. Hogwild is a parallel SGD algorithm that seeks to ignore conflicts between model updates on dif ferent threads and allo ws updates to proceed e ven in the presence of conflicts. The psuedocode of word2vec Hogwild SGD is shown in Algorithm 1. The algorithm takes in a matrix M V × D in that contains the word representations for each input word, and a matrix M V × D out for the word representations of each output word. Each word is represented as an array of D floating point numbers, corresponding to one ro w of the two matrices. These matrices are updated during the training. W e take in a target word, and a set of N input context w ords around the target as depicted in the top of Figure 1. The algorithm iterates over the N input words in Lines 2-3. In the loop at Line 6, we pick either the positiv e e xample (the tar get word in Line 8) or a negati ve example at random (Line 10). Lines 13-15 compute the gradient of the objective function with respect to the choice of input word and positiv e/neg ativ e example. Lines 17–20 perform the update to the entries M out [ pos/neg e xample ] and M in [ input context ] . The psuedocode only sho ws a single thread; in Hogwild, the loop in Line 2 is parallelized ov er threads without any additional change in the code. Algorithm 1 reads and updates entries corresponding to the input context and positi ve/ne gati ve words at each iteration of the loop at Line 6. This means that there is a potential dependence between successiv e iterations - the y may happen to touch the same word representations, and each iteration must potentially wait for the update from the pre vious iteration to complete. Hogwild ignores such 1 https://code.google.com/archive/p/word2vec/ 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain. Algorithm 1 word2vec Hogwild SGD in one thread. 1: Giv en model parameter Ω = { M in , M out } , learning rate α , 1 tar get word w t out , and N input words { w 0 in , w 1 in , · · · , w N − 1 in } 2: for (i = 0; i < N; i++) { 3: input_word = w i in ; 4: for (j = 0; j < D; j++) temp[j] = 0; 5: // negati v e sampling 6: for (k = 0; k < negati v e + 1; k++) { 7: if (k = 0) { 8: target_w ord = w t out ; label = 1; 9: } else { 10: target_w ord = sample one word from V ; label = 0; 11: } 12: inn = 0; 13: for (j = 0; j < D; j++) inn += M in [input_word][j] * M out [target_w ord][j]; 14: err = label - σ (inn); 15: for (j = 0; j < D; j++) temp[j] += err * M out [target_w ord][j]; 16: // update output matrix 17: for (j = 0; j < D; j++) M out [target_w ord][j] += α * err * M in [input_word][j]; 18: } 19: // update input matrix 20: for (j = 0; j < D; j++) M in [input_word][j] += α * temp[j]; 21: } dependencies and proceeds with updates re gardless of conflicts. In theory , this can reduce the rate of con v ergence of the algorithm as compared to a sequential run. Howe ver , the Hogwild approach has been shown to w ork well in case the updates across threads are unlikely to be to the same word; and indeed for lar ge v ocabulary sizes , conflicts are relati vely rare and con v ergence is not typically affected. t ar g e t 𝑤 𝑜𝑢 𝑡 𝑡 i npu t c on t e x t w or d 𝑤 𝑖𝑛 𝑖 c on t e x t win do w n eg a ti v e samples 𝑤 𝑜𝑢 𝑡 𝑘 fr om V thr ead p 𝑤 𝑜𝑢𝑡 𝐾 … A c a t on so f a A is sit tin g … d og 𝑤 𝑜𝑢𝑡 𝑡 𝑤 𝑜𝑢𝑡 1 𝑤 𝑜𝑢𝑡 2 𝑤 𝑖𝑛 1 𝑤 𝑜𝑢𝑡 𝐾 … 𝑤 𝑜𝑢𝑡 𝑡 𝑤 𝑜𝑢𝑡 1 𝑤 𝑜𝑢𝑡 2 × × … 𝑤 𝑜𝑢𝑡 𝑡 𝑤 𝑜𝑢𝑡 1 ′ 𝑤 𝑜𝑢𝑡 2 ′ 𝑤 𝑖𝑛 4 × 𝑤 𝑖𝑛 1 𝑤 𝑖𝑛 4 𝑤 𝑖𝑛 3 𝑤 𝑖𝑛 2 𝑤 𝑜𝑢𝑡 𝐾 ′ … K n eg a t iv e samp les K d if f er en t n eg a t iv e samp les K n eg a t iv e s amp les ar e sh ar ed a ll in p u t c ont e x t w or d s ar e ag gr eg a t ed Or i ginal w or d2v ec (dot pr oduct) Our w or d2v ec ( SG EM M) man y sm al l mode l upd a t es 1 bi g m ode l upda t e only Figure 1: The parallelization schemes of the original w ord2vec (left) and our optimization (right). 1.1 Shared Memory Parallelization: HogBatch Howe v er , the original word2v ec algorithm suffers from two main dra wbacks that significantly affect runtimes. First, since multiple threads can update the same cache line containing a specific model entry , there can be significant ping-ponging of cache lines across cores. This leads to high access 2 latency and significant drop in scalability . Second and perhaps e v en more importantly , there is a significant amount of locality in the model updates that is not exploited in the Hogwild algorithm. As an example, we can easily see that the same target word w t out is used in the model updates for sev eral input words. By performing a single update at a time, this locality information is lost, and the algorithm performs a series of dot-products that are lev el-1 BLAS operations [ 1 ] and limited by memory bandwidth. It is indeed, as we show ne xt, possible to batch these operations into a le v el-3 BLAS call [ 1 ] which can more ef ficiently utilize the compute capabilities and the instruction sets of modern multi-core and many-core architectures. W e exploit locality in two steps. As a motiv ation, consider Figure 1. The figure to the left sho ws the parallelization scheme of the original word2vec. Note that we compute dot products of the word vectors for a gi v en input word w i in with both the target word w t out as well as a set of K negati v e samples { w 1 out , · · · , w K out } . Rather than doing these one at a time, it is rather simple to batch these dot products into a matrix vector multiply , a level-2 BLAS operation [ 1 ], as shown in the left side of Figure 1. Howe ver , this alone does not buy significant performance improv ement. Indeed, most likely the shared input word vector may come from cache. In order to conv ert this to a lev el-3 BLAS operation, we also need to batch the input context words. Doing this is non-trivial since the negati ve samples for each input word could be dif ferent in the original word2vec implementation. W e hence propose “negativ e sample sharing” as a strategy , where we share negati v e samples across a small batch of input words. Doing so allows us to con vert the original dot-product based multiply into a matrix-matrix multiply call (GEMM) as shown on the right side of Figure 1. At the end of the GEMM, the model updates for all the w ord vectors of all input words and tar get/sample words that are computed need to be written back. Performing matrix-matrix multiplies (GEMMs) rather than dot-products allo ws us to lev erage all the compute capabilities of modern architectures including vector units and instruction set features such as multiply-add instructions in the Intel A VX2 instruction set. It also allo ws us to le verage hea vily optimized linear algebra libraries. For multi-threading across the GEMM calls, we follo w the same “Hogwild"-style philosophy - each thread performs its o wn GEMM call independently to other threads, and we allow for threads to potentially conflict when updating the models at the end of the GEMM operation. W e therefore call our new parallelization scheme “HogBatch". While the original word2vec performs model updates after each dot product, our HogBatch scheme performs a number of dot products as a GEMM call before performing model updates. It is important to note that this locality optimization has a secondary but important benefit - we cut down on the total number of updates to the model. This happens since the GEMM operation performs a reduction (in registers/local cache) to an update to a single entry in the output matrix; while in the original word2vec scheme such updates to the same entry (same input word representation, for instance) happen at distinct periods of time with potential ping-pong traffic happening in between. As we will see in Sec. 2 when we present results, this leads to a much better scaling of HogBatch than the original word2vec. 1.2 Distributed Memory Parallelization T o scale out word2v ec, we also explore dif ferent techniques to distrib ute its computation across nodes in a compute cluster . Essentially , we employ data parallelism for distributed computation. Due to limited space, we skip the details here and will report it in a full paper . 2 Experiments W e compare the performances of three different implementations of word2v ec: (1) the original implementation from Google that is based on Hogwild SGD on shared memory systems ( https:// code.google.com/archive/p/word2vec/ ), (2) BIDMach ( https://github.com/BIDData/ BIDMach ) which achie v es the best known performance of word2vec on Nvidia GPUs, and (3) our optimized implementation on Intel architectures, including (1) 36-core Intel Xeon E5-2697 v4 Broadwell (BD W) CPUs, and (2) the latest Intel Xeon Phi 68-core Knights Landing (KNL) processors. W e train the algorithm on the one billion word benchmark [ 3 ] with the same parameter settings of BIDMatch (dim=300, neg ativ e samples=5, windo w=5, sample=1e-4, v ocab ulary of 1,115,011 words). W e ev aluate the model accuracy on the standard wor d similarity benchmark WS-353 [ 4 ] and Google wor d analogy benchmark [ 5 ]. Since all the implementations achiev e similar accuracy and due to 3 lack of space, in the following we only report their performances in term of throughput, measured as million words/sec. More details of the experimental comparison will be reported in a full paper . Our implementation and scripts are open sourced at https://github.com/IntelLabs/pWord2Vec . 1 2 4 8 18 36 72 0 1 2 3 4 5 6 Number of Threads (from a single BDW node) (Million) Words/Sec Original Our 1 2 4 8 16 32 0 20 40 60 80 100 120 140 160 Number of Nodes (Million) Words/Sec Our distributed w2v on Intel BDW Our distributed w2v on Intel KNL BIDMach on NVidia Titan−X Figure 2: (a) Scalabilities of the original word2v ec and our optimization on all threads of an Intel Broadwell CPU; (b) Scalabilities of our distrib uted word2v ec on multiple Intel Broadwell and Knights Landing nodes, and BIDMach on N = 1 , 4 NV idia T itan-X nodes as reported in [2]. Figure 2 shows the throughputs measured as million words/sec of our algorithm and the original word2vec, scaling across cores and nodes of Intel BD W and KNL processors. When scaling to multiple threads (Figure 2(a)), our algorithm achie v es near linear speedup until 36 threads. In contract, the original word2vec scales linearly only until 8 threads and slows down significantly after that. In the end, the original word2vec deli vers about 1.6 million w ords/sec, while our code deli vers 5.8 million words/sec or a 3.6X speedup over the original word2vec. The superior performance highlights the effecti v eness of our optimization in reducing unnecessary inter-thread communications and utilizing computation resource of modern multi-core architecture. When scaling across multiple nodes (Figure 2(b)), our distrib uted word2v ec achie ves near linear scaling until 16 BD W nodes or 8 KNL nodes while maintaining a similar accuracy to that of the original word2v ec. As the number of nodes increases, to maintain a comparable accuracy , we need to increase the model synchronization frequency to mitigate the loss of con vergence rate. Howe ver , this takes a toll on the scalability and leads to a sub-linear scaling at 32 BDW nodes or 16 KNL nodes. Despite of this, our distributed w ord2vec deli vers o ver 100 million words/sec with a small 1% accuracy loss. T o the best of our knowledge, this is the best performance reported so far on this benchmark. Finally , T able 1 summarizes the best performances of the state-of-the-art implementations on different architectures, demonstrating superior performance of our algorithm. T able 1: Performance comparison of the state-of-the-art implementations of word2v ec on dif ferent architectures. Processor Code W ords/Sec Intel BD W (Xeon E5-2697 v4) Original 1.6M Intel BD W (Xeon E5-2697 v4) BIDMach 2.5M Nvdia K40 BIDMach 4.2M 1 Intel BD W (Xeon E5-2697 v4) Our 5.8M Nvdia GeForce T itan-X BIDMach 8.5M 1 Intel KNL Our 8.9M Nvdia GeForce T itan-X (4 nodes) BIDMach 20M 1 Intel KNL (4 nodes) Our 29.4M 1 Data from [2]. 3 Conclusion A high performance word2vec algorithm “HogBatch" is proposed for shared memory and distributed memory systems. The algorithm is particularly suitable for modern multi-core/many-core architec- tures, especially Intel’ s KNL, on which we deliver the best kno wn performance reported so far . Our implementation is publicly av ailable for general usage. 4 References [1] L. S. Blackford, J. Demmel, J. Dongarra, I. Duff, S. Hammarling, G. Henry , M. Heroux, L. Kaufman, A. Lumsdaine, A. Petitet, R. Pozo, K. Remington, and R. C. Whale y . An updated set of basic linear algebra subprograms (blas). A CM T rans. Mathematical Software , 28(2): 135–151, 2002. [2] J. Canny , H. Zhao, Y . Chen, B. Jaros, and J. Mao. Machine learning at the limit. In IEEE International Confer ence on Big Data . 2015. [3] C. Chelba, T . Mikolo v , M. Schuster , Q. Ge, T . Brants, P . K oehn, and T . Robinson. One billion word benchmark for measuring progress in statistical l anguage modeling. In INTERSPEECH , pages 2635–2639, 2014. [4] L. Finkelstein, E. Gabrilovich, Y . Matias, E. Rivlin, Z. Solan, G. W olfman, and E. Ruppin. Placing search in context: The concept re visited. ACM T r ansactions on Information Systems , 20: 116–131, 2002. [5] T . Mikolov , K. Chen, G. Corrado, and J. Dean. Efficient estimation of w ord representations in vector space. Pr oceedings of W orkshop at ICLR , 2013. [6] T . Mikolov , I. Sutske ver , K. Chen, G. S. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality . In Advances in Neural Information Processing Systems 26 , pages 3111–3119. 2013. [7] F . Niu, B. Recht, C. Re, and S. J. Wright. Hogwild: A lock-free approach to parallelizing stochastic gradient descent. In Advances in Neural Information Processing Systems , pages 693–701. 2011. 5
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment