멀티코어·다중코어 환경을 위한 Word2Vec 고속 병렬화
본 논문은 기존 Word2Vec 구현이 메모리 대역폭에 의존하는 Hogwild 방식으로 제한되는 문제를 해결하고자, 미니배치와 부정 샘플 공유를 통한 “HogBatch” 기법을 제안한다. 이를 통해 레벨‑3 BLAS 연산인 GEMM으로 변환함으로써 현대 CPU·Xeon Phi(KNL) 아키텍처에서 연산 효율을 크게 향상시킨다. 또한 데이터 병렬 방식을 이용해 클러스터 환경에서도 32노드까지 거의 선형 확장을 보이며, 수백 백만 단어/초 처리 속…
저자: Shihao Ji, Nadathur Satish, Sheng Li
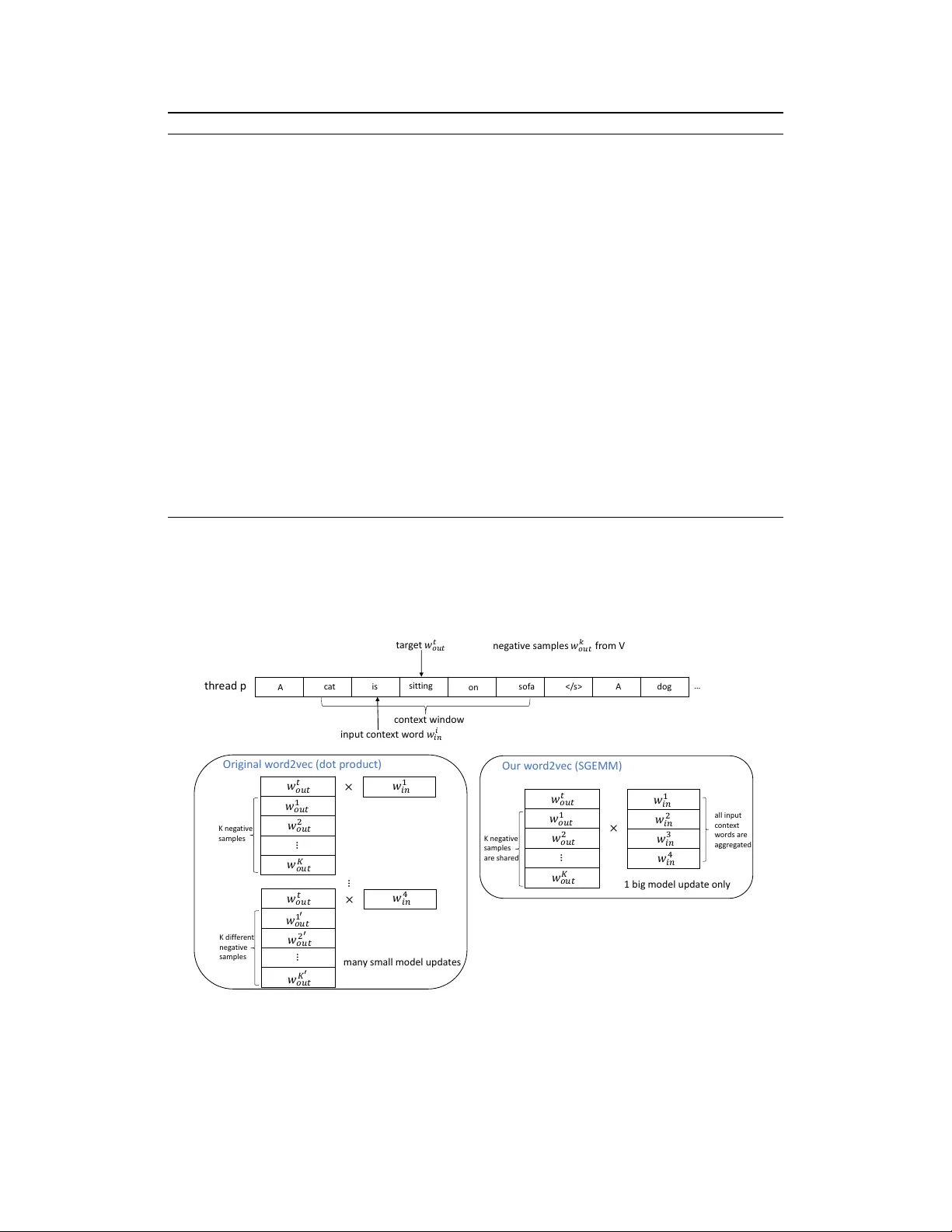
본 논문은 Word2Vec 훈련 과정에서 발생하는 메모리 대역폭 병목을 해소하고, 현대 멀티코어·다중코어 시스템에서 효율적인 병렬화를 달성하기 위해 새로운 알고리즘 “HogBatch”를 제안한다. 기존 Word2Vec 구현은 Mikolov 등에 의해 제시된 Hogwild 방식을 사용해 스레드 간 충돌을 무시하고 각 단어 쌍에 대한 내적과 업데이트를 순차적으로 수행한다. 이 방식은 각 스레드가 동일 행렬 원소에 접근할 때 캐시 라인 경쟁이 발생하고, 연산이 주로 메모리 로드·스토어에 의존하게 되어 확장성이 제한된다.
HogBatch은 두 가지 핵심 아이디어로 이를 극복한다. 첫째, **미니배치화**를 통해 여러 입력 컨텍스트를 동시에 처리한다. 입력 단어 집합을 행렬 형태로 모아, 목표 단어와 부정 샘플 집합과의 내적을 행렬‑벡터 곱(Level‑2 BLAS)으로 변환한다. 둘째, **부정 샘플 공유** 전략을 도입해 배치 내 모든 입력에 동일한 부정 샘플 집합을 사용한다. 이렇게 하면 입력 배치와 부정 샘플을 동시에 묶어 행렬‑행렬 곱(GEMM, Level‑3 BLAS)으로 변환할 수 있다. GEMM은 고성능 BLAS 라이브러리에서 최적화된 루틴으로, SIMD·FMA와 같은 현대 CPU·Xeon Phi의 벡터 연산 유닛을 최대한 활용한다.
GEMM을 사용함으로써 얻는 장점은 다음과 같다. (1) 연산이 메모리 대역폭보다 FLOPS에 의해 지배되는 컴퓨팅 바인드 형태로 전환되어, 메모리 접근 비용이 크게 감소한다. (2) 동일 입력 단어에 대한 업데이트가 레지스터 혹은 L2 캐시에서 부분 합산된 뒤 한 번에 적용되므로, 기존에 발생하던 중복된 메모리 쓰기와 캐시 라인 ping‑pong 현상이 크게 억제된다. (3) 배치 규모가 커질수록 GEMM 효율이 증가해, 코어 수가 많은 시스템에서 거의 선형적인 스케일업을 기대할 수 있다.
멀티스레드 환경에서는 여전히 Hogwild‑style의 무잠금 업데이트를 유지한다. 각 스레드는 독립적인 배치를 처리하고, GEMM 연산이 끝난 뒤 모델 파라미터를 업데이트한다. 충돌 가능성을 허용하지만, 어휘 크기가 수백만 단어에 달하는 경우 동일 파라미터에 대한 동시 접근 빈도가 낮아 수렴 속도에 큰 영향을 주지 않는다. 실험 결과, 36코어 Intel Xeon E5‑2697 v4(Broadwell)에서 36스레드까지 거의 선형적인 속도 향상을 보였으며, 1.6 M words/sec을 기록하던 기존 구현 대비 5.8 M words/sec, 즉 3.6배의 처리량을 달성했다.
클러스터 확장성을 위해서는 **데이터 병렬** 방식을 적용한다. 전체 코퍼스를 여러 노드에 균등하게 분할하고, 각 노드가 로컬 모델을 독립적으로 학습한다. 일정 주기로 파라미터를 All‑Reduce 방식으로 동기화함으로써 전역 모델 일관성을 유지한다. 노드 수가 증가함에 따라 동기화 빈도를 조절해 수렴률 저하를 방지한다. 32노드(또는 16 KNL 노드)까지 확장했을 때 100 M words/sec 이상의 처리량을 기록했으며, WS‑353와 Google Analogy 벤치마크에서 1 % 이하의 정확도 손실만 보였다.
다양한 하드웨어에서의 성능을 비교한 결과, Intel Broadwell CPU와 Xeon Phi(KNL)에서 각각 5.8 M, 8.9 M words/sec을 달성했으며, KNL 4노드 구성에서는 29.4 M words/sec까지 확장했다. 이는 동일 벤치마크에서 GPU 기반 BIDMach 구현(최대 20 M words/sec)보다도 높은 수치이며, 특히 KNL 클러스터에서 가장 높은 효율을 보였다.
결론적으로, HogBatch은 Word2Vec 훈련을 메모리‑바운드에서 컴퓨팅‑바운드로 전환시켜, 현대 멀티코어·다중코어 아키텍처의 연산 능력을 최대한 활용한다. 미니배치와 부정 샘플 공유를 통한 GEMM 변환은 캐시 효율을 높이고 업데이트 횟수를 감소시켜, 스레드·노드 규모가 커질수록 선형에 가까운 확장성을 제공한다. 또한 구현 코드를 오픈소스로 공개함으로써, 연구자와 엔지니어가 다양한 환경에서 손쉽게 적용하고 확장할 수 있도록 지원한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기