Statistical Properties of European Languages and Voynich Manuscript Analysis
The statistical properties of letters frequencies in European literature texts are investigated. The determination of logarithmic dependence of letters sequence for one-language and two-language texts are examined. The pare of languages is suggested …
Authors: Andronik Arutyunov, Leonid Borisov, Sergey Fedorov
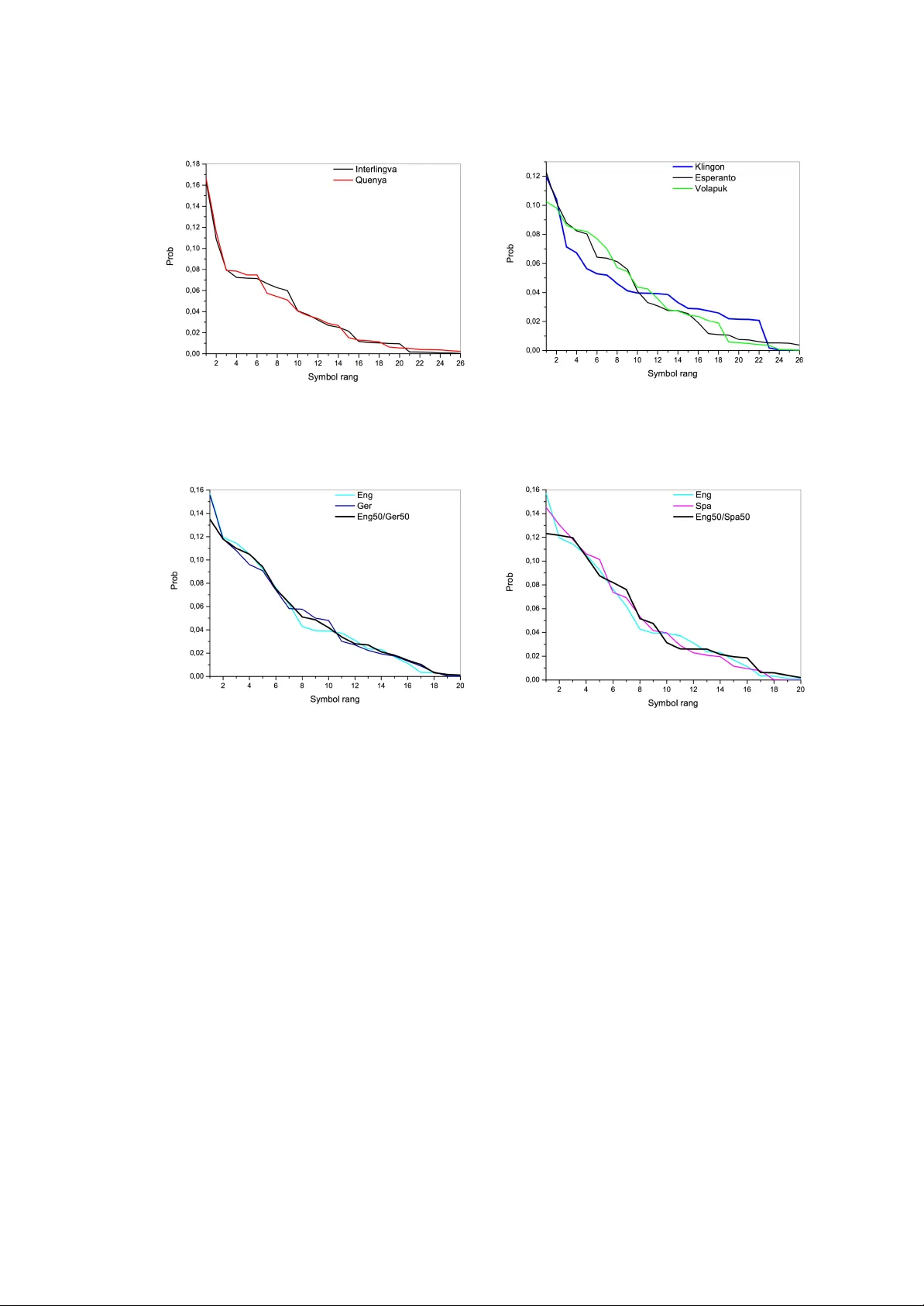
Statistical Properties of European Languages and V oynich Manuscript Analysis Andronik Arutyunov 1 , Leonid Borisov 2 , Serge y Fedorov 2 , Anastasiya Ivchenko 2 , Elizabeth Kirina-Lilinskaya 2 , Y urii Orlov 2 ∗ , K onstantin Osminin 2 , Serge y Shilin 3 , Dmitriy Zeniuk 2 1 Peoples’ Friendship Uni versity of Russia, Mosco w , Russia 2 K eldysh Institute of Applied Mathematics of RAS, Moscow , Russia 3 Mosco w Institute of Physics and T echnology , Mosco w , Russia 2 ∗ Corresponding e-mail: yuno@kiam.ru Abstract The statistical properties of letters frequencies in European literature texts are in vestigated. The determination of logarithmic dependence of letters sequence for one-language and two- language texts are e xamined. The pare of languages is suggested for V oynich Manuscript. The internal structure of Manuscript is considered. The spectral portraits of two-letters distrib ution are constructed. K eywords: letters frequency distribution, European language groups, V oynich Manuscript, spec- tral portrait. 1 Contents 1 Introduction 3 2 Manuscript transcriptions statistics 4 3 Distribution of distances among pairs of the identical letters 12 4 Constructed languages symbols statistics 15 5 T wo-languages symbols statistics 16 6 Identification of the Manuscript fragment language 20 7 Spectral portrait of V oynich Manuscript 22 8 V oynich Manuscript structure 25 9 Conclusion 28 2 1 Intr oduction The main aim of the present paper is a statistic analysis of literary texts written in European languages (we will consider Indo-European and Uralic language families). W e construct a letter distribution using lar ge texts (more than 100,000 characters) in order to identify similar properties in the rele vant le xicons. This paper is partly based on results obtained in the preprint [1] and methods from the mono- graph [2] where it could be found some results of letter frequenc y anylisis in European languages. In particular , it was found that for the most languages the dependence of ordered frequencies is accuratly logarithmic, its determination is more than 0.98. Parameters of the logarithmic depen- dence are determined by the number of characters in an alphabet and allo w the interpretation of the redundancy or the f ailure. Our interest is in a de viation from log arithmic dependence in letter statistics for bilingual texts (written in a full alphabet / consonants only / written in a constructed language). W ould it be correct using statistics of the frequency of letters to make sufficiently reliable supposition about texts language? This question has arisen from paper authors’ V o ynich manuscript discussion. The V oynich manuscript (VM [3]) – is a hand-written codex, dating from the XVI c. It consists of o ver 170,000 characters referred to as letters, which are united by transcriptioners in 22 distinct characters. These characters are not elements of any kno wn alphabet. At the present time the manuscript is kept in the Beinecke Library and has the status of a cryptographic puzzle. Numerous studies in order to decrypt the text carried out more than a hundred years and are still unsuccessfully . V ersions of the authorship, content and language of the manuscript (you can found a revie w in [4-6]) in our opinion are not supported enough by the full-fledged statistical studies. W e hav e to emphasize that our aim is not to decode the manuscript. W e do not analyze the vocab ulary so we do not discuss the semantic component of the text. W e will try to get the answer to the follo wing question: Is the VM a encrypted meaningful text (and so in what language is it written?) or is a hoax, i. e. meaningless set of characters? It may seem that the answer is required a decryption of the text but in reality this is not necessary . Firstly it is important to find out if there is a common statistical properties in texts without kno wledge of which it is impossible to make the necessary simulation. Our studies sho w that such properties exist. There is no consensus ho w man y characters VM is consists of. W e will consider two transcrip- tions of VM: “European transcription” (EV A [7]) and transcription T akahashi [8]. Both of them translate manuscript symbols into Latin alphabet, b ut with different frequencies of symbols. (the fact is we can not interpret man y of caracters in MV uniquely). An any case we will not discuss a correctness of these transcriptions. Our goal is to study statistic properties of them. Therefore it should be remembered by speaking about the “MV structure” or “language of its parts” we will intend exactly these transcriptions. Researchers ha ve proposed numerous hypotheses about the structure of the Manuscript. There are some kno wn theories: • it was written with permutation of letters • two letters of the well-kno wn alphabet correspond to one character of the manuscript; • There is a key without which you can not read the text because the same characters in dif ferent parts of the manuscript correspond to different letters • the manuscript is an encoded two-language te xt; • vo wels ha ve been remov ed from the originally meaningful text ; 3 • the text contains f alse spaces between words. At the same time in various concepts (unprov en in the statistical sense) for the role of the original language are proposed: Hebre w , Spanish, Russian, Manchurian, V ietnamese and much more (e ven Arabic or “something Indian”). At the same time we can consider the existence of false spaces as a real component of Manuscript structure. In this instance a decryption may be very problematic. In addition, it should be noted that if the text contains no vo wels, the v owel recov ery is not uniquely . One further remark is that pages of Manuscript could be numbered not by the author and the oder of “words” can be changed. There are also no any evidences that VM is a one te xt, not two or three texts under one co ver – throughout the te xt a handwriting is not the same. One must refrain from the idea of seeing words in VM. W e can consider only character statis- tics assuming that e very character is a letter . Studies [2] hav e sho wn that symbol distrib ution of frequenc y of occurrence is a strong charac- teristic of language not an author or a text theme. It is assumed that the distribution of te xt mixtures in tw o languages will be equally stable. It will be judged by the lev el of its determination with some model distribution the equity participa- tion of dif ferent languages in these bilingual texts It is possible that the text character distrib utions are stable within the same language group and for texts written in mix ed language from two different language groups (e.g. one part is written in English, another in French), distributions will be unstable. In this case we can talk about nat- ural clusterization of kindred languages for texts written in arbitrary two-language mixture. This Clusterization is based on the principle of the text closeness by frequency-ordered characters dis- tribution. It is also very interesting to compare texts written in languages from different language groups but in the one alphabetic system, for example, in Hungarian (Uralic family , Finno-Ugric branch) and English (Indo-European family , the W est Germanic branch). In addition we will con- sider some constructed languages in oder to consider the case when VM is written in a constructed laguage. In this way , our paper deals with the analysis of those assumptions and study in v ariant prop- erties of European languages. F or finding linguistic in variants the follo wing statistics are used: the distance between distributions of odered empirical frequencies of letter combinations in norm L 1 ; determination lev el of logarithmic approximations of one-letter distributions for texts without vocalisation; Hurst inde x distribution for a series of the number of letters concluded between the two most frequently encountered same letters; spectral matrix portrait of two-letter combinations. These indicators ha ve allowed to mak e the formal clusterization of languages from Indo-European family . As result our clusters ha ve coincided with groups formed on the basis of studies in Histor - ical Linguistics. 2 Manuscript transcriptions statistics There are frequencies for MV symbols in T able 1 which are obtained as a transcription of manuscript characters into the Latin alphabet. There are tw o v ersions of transcription: EV A and T akahashi. In calculating we did not distinguish uppercase and lowercase letters and did not treat empty spaces as special symbols. In our further analysis we will focus on the construction of the VM symbol distribution of frequency of occurrence. W e will compare it with analogical distributions in European languages and will revial the deviation from the lev el of determination of approximated dependence. Then we will determine the distance between actual distribution and its approximation in norm L 1 . 4 T able 1: MV frequencies Symbol EV A T akahashi a 0.07456 0.07641 b 0.00051 c 0.06951 0.00254 d 0.06773 0.00269 e 0.10478 0.12940 f 0.00264 0.00598 g 0.00050 0.00019 h 0.09322 0.11559 i 0.06125 0.01472 k 0.05708 0.02901 l 0.05491 0.05624 m 0.00583 0.03713 n 0.03206 0.03988 o 0.13296 0.13616 p 0.00851 q 0.02831 0.00870 r 0.03893 0.02402 s 0.03857 0.01541 t 0.03625 0.12789 u 0.00011 v 0.00005 w 0.08296 x 0.00018 y 0.09217 0.09445 z 0.00001 0.00001 5 There are symbol descending ordered frequencies in Fig.1. These distributions are closed in sens of determination le vel of approximated dependence (0.93), but they are dif ferent substantially in details . According to the studies [2], the EV A graph (red line) is typical for Germanic group, or rather W est Germanic languages. T akahashi graph (green line) is typical for Sla vic and Ro- mance languages (Fig. 2) and also for North Germanic languages. The distance between these transcriptions (with descending ordered frequencies) in norm L 1 is equal to 0.26 that is in 3 times more than between distributions of texts without vocalisation in one language family , in 10 times more between texts with full alphabet. It means that each of such transcriptions corresponds with fundamentally dif ferent analysis of VM, so there is no possibility for use both translations in oder to statistics elboration. Figure 1: Ordered frequency of two VM-transcriptions and logarithmic model approximation For most of modern languages in Indo-European family logarithmic dependence of letter fre- quency on its rang is typical with accuracy more than 0.98. The le vel of determination in texts without vocalisation is slightly lower – 0.96 (Fig 2-5, T able 2). Actual distrib ution of odered fre- quencies for texts written in the same language differs from log arithmic approximation in L 1 norm within 0.08–0.13. Distances between real distribution e xcluding language characteristic are in the same interv al (T able 3). 90- % confidence interv al is here with [0 . 085; 0 . 115] Note that deviations in norm L 1 of corresponded approximations for both MV -transcriptions are about the same and equal to 0.17. It testifies that a logarithmic model for this te xt is not ade- quate enough in case we consider it as an alphabetic cipher from one of any European languages. In order to demonstrate our language group recognition method, which is based on the sta- tistical analysis of ordered symbols, we consider literary texts in Latin [lat] and Cyrillic [cyr] transcription written in the follo wing languages: 1. Indo-European languages: (a) Slavic: East (Russian [rus]), W est (Polish [pol], Czech[che]), South (Serbian [serb], Croatian [hr], Bulgarian [b ul]); 6 T able 2: Determination of logarithmic approximation of texts without vocalization for some Eu- ropean languages [rus-kir] 0.97 [ger] 0.98 [hr] 0.91 [bol-kir] 0.97 [eng] 0.98 [pol] 0.96 [serb-kir] 0.92 [hol] 0.98 [che] 0.96 [gre-kir] 0.96 [dan] 0.93 [lat] 0.96 [fin] 0.96 [swe] 0.96 [ita] 0.96 [est] 0.98 [nor] 0.96 [fra] 0.96 [hung] 0.96 [gre] 0.96 [spa] 0.96 [bask] 0.96 [serb] 0.84 [rom] 0.90 (b) Germanic: North (Danish[dan], Swedish [swe], Norwegian [nor]), W est (German [ger], English [eng], Dutch [hol]); (c) Romance: Italian [it], Spanish [spa], French [fra], Romanian[rom]; (d) Greek [gre]; (e) Basque [bask]; (f) Latin [lat]; 2. Uralic, Finno-Ugric languages: (a) Ugric: Hungarian [hung]; (b) Baltic-Finnic: Finnish [fin], Estonian [est]; 3. Constructed languages: (a) Esperanto [esp], V olapuk [vol]; (b) Interlingua [int]; (c) Klingon [kl] (language spoken by the Klingons in the Star T rek uni verse); (d) Quenya [qu] (“Elvish language”). Approximately 90 % of considered languages hav e the determination of model logarithmic dependence of frequenc y odered letters than 0.96. Only letter frequency for Danish, Serbian (Latin and Cirillyc alphabets), Croatian and Romanian texts without vocalization ha ve a much lo wer approximation accuracy . Distances between frequenc y distributions for te xts in Cirillic for Sla vic group sho w that Rus- sian, Bulgarian and Serbian are related: the closest are Russian and Bulgarian (with a distance 0.06), Russian and Serbian as well as Bulg arian and Serbian ha ve a distance 0.12. Note that Greek in Cirillyc transcription hav e a distance more than 0.20 and in that sense not similar with an y of Slavic languages. For texts with the latin alphabet distances between frequenc y distributions form clusters (T able 3) in accordance with language groups in sense of closeness between themselves in norm L 1 . It was found that Indo-European languages united in groups and subgroups have close statistical properties. The distance in norm L 1 between frequencies from one language group vary quite narro w (0.08–0.13). Between different groups the distance is 0.14–0.22 7 T able 3: Distance between frequency distributions in te xts without vocalization (Latin alphabet) in norm L 1 , % ge en ho da sw no la it sp fr ro bs gr fi es hu po ch hr se ge 8 11 13 11 12 12 13 11 15 19 18 27 29 14 12 28 26 23 24 en 12 13 12 13 12 13 11 15 19 18 26 26 12 16 32 29 28 27 ho 10 11 11 19 21 19 22 27 25 23 27 20 18 31 28 27 32 da 11 10 13 13 9 14 13 18 27 27 12 16 35 31 30 25 sw 11 15 15 10 14 18 19 26 30 14 13 28 24 23 22 no 13 13 10 15 14 18 27 27 13 17 34 32 31 26 la 5 10 7 12 13 23 22 14 21 39 35 34 32 it 10 7 12 15 23 23 14 20 37 35 34 33 sp 11 13 16 22 25 14 16 36 32 30 28 fr 13 16 25 25 18 22 38 35 34 33 ro 20 30 31 21 18 41 38 33 25 bs 19 15 15 27 42 39 39 37 gr 14 21 31 48 45 44 43 fi 22 38 55 52 52 49 es 18 36 32 31 28 hu 25 22 17 15 po 5 12 22 ch 9 20 hr 12 se The same color in T able 3 is used for language groups were languages are close in pairs in sens of ordered frequencies of consonant letters in L 1 . Red color is used for une xpectedly close language pairs. Clusterization was made on the basis of pair closeness for all units in the cluster . In contro versial cases unit was applied to a cluster with the largest number of units. There are some examples of ordered frequencies of consonant letters in texts in European languages (Fig. 2-6). W e have another situation with Uralic family (fig. 6). Frequencies of consonant letters for Finnish and Estonian languages are markedly different (they have the distance 0.22) while they are both in Baltic-Finnic branch. The line corresponded with Hungarian has a distance from these languages 0.38 and 0.18 respecti vely and is closer to Germanic languages with distance 0.16. This result is probably caused by the fact that vo wels have more significant structure value in these languages. Note that the Latin alphabet is used in Southeast Asia, for example in V ietnam. Ho we ver , frequency of consonant letters in V ietnamese texts has a distance from European texts more than 0.25. V ietnamese is not united with any of European languages from Indo-European or Uralic families. MV language is also not similar with V ietnamese. V irtually , Latin used in V ietnamese texts (without diacritical marks) has a minimum distance 0.28 (in T akahashi transcription) from VM. Latin without vocalization has a distance e ven more – 0.35. In this way “V ietnamese v ersion” about VM is not confirmed. Constructed language texts will be discussed in a later section. The results can be commented by these allegations: • Languages, which are linguistically attributable to one group, for the most part are in the same cluster with a distance less than 0.13. This applies to German, Romance and Slavic groups. • Greek language in the Latin transcription is aside from the rest of the languages, as, indeed, Finnish language, b ut to each other they were closer than each of them to other languages. The distance between them was only 0.14, which marked in red in the table. 3. 8 Figure 2: Ordered frequencies of consonant letters in texts (Cyrillic) • Estonian and Finnish languages obviously hav e different statistical properties though they are united in the same group by linguists. Statistically , Estonian and Hungarian are closer to the German group, the distance to which they amounted to 0.12–0.14. • Latin transcription of the Serbian language is only close to the Croatian language with 0.12 distance between them. • Slavic group of languages (Czech, Polish and Croatian), that use the Latin alphabet, are tightly clustered. • Although the Mediev al Latin is out of use, it is close to all languages in the Romance group. Basque language, who has an uncertain status, is aw ay from all the languages in question except from the Latin, to which the distance w as only 0.13. Both languages ha ve the same determination of the logarithmic model (0.96) with the same number of effecti vely used consonants (16). Thus, clustering method on the principle of the pairwise proximity between distributions al- lo wed to obtain meaningful results of linguistic classification of languages. As mentioned abov e, these distributions ha ve high log arithmic profile accuracy . The logarithmic model of symbol distribution has been deriv ed by S. M. Gusein-Zade [9]. It is based on the assumption of a constant distrib ution density of the random point P ( p 1 , ...., p n ) on n -dimensional simplex n P i =1 p i = 1 , where p i is the frequenc y of use the order of i letter in the te xt. In [2] this model was modified and used to e valuate the completeness of the alphabet in the te xts in dif ferent languages. It represents f ( k ) = 1 n 1 + 1 n + o ln n ! k n (1) In this formula n is the number of letters in the alphabet. The parameter o is the nearest integer , corresponding to the value with the smallest error of approximation of the actual distribution of 9 Figure 3: Ordered frequencies of consonant letters in texts , Germanic Language the formula (1). The point of this parameter consists that the te xt under consideration has the most adequate text alphabet with n + o the number of symbols. Empirical relationships for Russian, German, English and Hungarian languages in Fig. 2 are best modeled by relation (1) wherein o = 0 ; this option is shown in Fig. 1 as legend model . F or French, Spanish and Italian, Danish and Swedish o = − 1 . For Finnish o = − 6 and for Estonian language o = − 4 . Applied to EV A transcription, for which n = 22 , the best approximation is achiev ed when o = − 2 . This means that in MV has only 20 symbol in use. The elimination two of the rarest letters obtains a logarithmic approximation with 0.93 determination and a deviation in the L 1 norm of the actual distrib ution at the le vel of 0.167. The same observation is true for T akahashi transcription. Appropriate depending were presented in Fig. 1. Observe now that the number of consonants in most European languages is 20. It could be assumed that the MV is written on one of them, but without vo wels. Necessary in a statistical sense, but not a suf ficient condition for this is, firstly , the proximity of one of the transcriptions’ distributions to the selected language distrib ution (deviation in the L 1 norm does not exceed 0.10). Secondly , it has to be a roughly equal distance from transcription and from selected language to approximating model dependence (about 0.17). Analysis of the data in Fig. 3, 4, 6, lead to the conclusion that from the considered options there is only one suitable – Danish language. T akahashi T ranscription has 0.10 diver gence in L 1 norm from the empirical distribution of the Danish language (Fig. 7). What is more, the determination of the logarithmic approximation of Danish language without vo wels is 0.93, the same to T akahashi transcription. Swedish and Norwegian (Bokmal) languages that close to the Danish are much less suited to the role of the language of the original MV . Distances between all the languages of the North German group are the same and is equal to 0.11 (dif ferences are only in the third decimal place), and the dif ference between the Swedish and Norwegian from this transcription is 0.14 instead of 0.10 for the Danish language. It is worth noting that Latin can be considered as the language of MV because a de viation T akahashi transcription in this case is 0.11, which is also within the allow able distance between distributions of related language groups. 10 Figure 4: Ordered frequencies of consonant letters in texts (Romance languages, Latin and Basque) For EV A transcription a suitable language among discussed European was not found. The findings are based on a statistical analysis of modern texts. T ransferring selected proper- ties on manuscripts XVI-XVII centuries can be made only under the assumption that the use of the lexicon consonants during that time has not changed significantly . Unfortunately , the number of the original texts were not av ailable in suf ficient amount to analysis, so the expressed hypothesis is only illustrates the method of analysis of texts, and is very preliminary . Howe ver , it should be noted that the analysis of the texts in Medie v al Latin led to a similar dependence: 0.966 determi- nation of the logarithmic model without vo wels. This finding suggests that the logarithmic model in some sense is in v ariant, and can be used to compare the distrib utions of symbol in both old and modern texts. It has to be emphasized that conjectural identification of the language does not mean readabil- ity of the manuscript, since an in v ariant of language is the curve, rather than a position specific letters on it. In dif ferent te xts in the same language the ordered sequence of letters is “floating”, although, the most frequently used symbols in one text are not become rarely used in another . Ne v- ertheless in an y language there is no unambiguous correspondence between the rank and the letter . The width of “migration windo w” rank for text on the length of the order of 200 thousand signs is 5. Therefore, e ven if the original language manuscripts has been specified, it cannot guarantee the transcript. Extra analysis on a large set of texts is required in order to establish the possible combinations of letters in their orderly distribution. One argument in fa vor to fact that the manuscript is written in a language without vo wels was gi ven. Ho we ver , considering the Danish language, the possibility that MV was written in language with a full alphabet, b ut excluding diacritical marks, by which North German languages (and not only) group are saturated with , should take into account. At the same time the number of actually used consonants may be less than 20, as the letters Q, X, W , Z are used in Danish only in borrowed words, which could simply not to be in a manuscript. Then, the number of different symbols would be 22, but for other reasons. Ho wev er , revie wed belo w analysis of other statistics still evidence in fa vor of concept of the manuscript as “with v owels e xcluded”. 11 Figure 5: Comparison of standard distribution of Germanic and Romance lan- guages 3 Distrib ution of distances among pairs of the identical letters In this section we will treat a text as a time series with values x ( t ) , where t is the ordinal number of symbol x counted from the beginning, and x itself belongs to some fix ed alphabet. The length of a symbol sequence, which do not contain particular letter , is an important property of the underlying language, as its distribution does not change remarkably between various texts. In particular , it was shown in [2] that for Russian texts distances between the same symbols, i.e. the number of all other letters between them, hav e the follo wing properties: − Autocorrelation function is near zero for ev ery value of time lag, but increments are depen- dent; distribution of distances is preserv ed across texts of dif ferent authors and styles; − After multiplication by normalization constant equal to the frequency of the symbol occur- rence this distribution does not depend on the symbol. It should be noted that symbols in a te xt does not appear spontaneously , b ut in accordance with the narration and author’ s conceptions. Hence distances between the same letters cannot be purely random, and there could be a parameter governing the effects of long-range memory in symbol appearance. As it was mentioned in [10], the order of deriv ativ es in the fractional Fokker –Planck equation for empirical probability densities of arbitrary time series might play the same role. Let us analyze numerical time series of distances between some predefined symbols. For the sake of computational simplicity we will use the well-kno wn Hurst exponent [11] instead of the fractional deri v ativ e statistics from [10]. A v alue of the Hurst exponent agrees well with fractional deri vati ve order in case of self-similar time series. The Hurst exponent can be estimated as follo ws. Procedure is applied to the time series formed by first dif ferences x ( t ) = b ( t + 1) − b ( t ) of the original time series b ( t ) . Firstly , one calculates the moving av erage values and constructs ne w 12 Figure 6: Ordered frequencies of consonant letters in texts (Uralic vs Germanic) series of accumulated de viations from the moving a verage for sub-frames of length k : x ( t, k ) = 1 k t X i = t − k +1 x ( i ) Then the range, which is defined as the difference between the maximum and the minimum v alues of this auxiliary series, and the standard deviation of the original time series b ( t ) . Firstly , one calculates the moving a verage values and constructs new series of accumulated deviations from the moving a verage for sub-frames of length k : R ( t, k ) = max j ≤ t t X t − k +1 ( x ( i ) − x ( t, k )) ! − min j ≤ t j X t − k +1 ( x ( i ) − x ( t, k )) ! (2) σ 2 x ( t, k ) = 1 k j X t − k +1 ( x ( i ) − x ( t, k )) 2 Each range is divided by the corresponding standard deviation, then the arithmetic mean of loga- rithms of rescaled ranges is calculated: ξ ( t, k ) = ln( R ( t, k ) σ x ( t, k ) ) , ξ N ( t ) = 1 N N X k =1 ξ ( t, k ) The Hurst exponent H N ( t ) at time-step t is estimated as the slope in linear regression model of ξ ( t, k ) on logarithms of k : H N ( t ) = 1 N N X k =1 ξ ( t, k ) − ξ N ( t ) (1 + ln( k / N )) (3) As calculations showed, distances between identical symbols for all considered languages, independently of the presence or absence of v owel letters, form the so-called antipersistent time 13 Figure 7: Distrib ution of symbols frequencies in T akahashi transcription and Dan- ish texts without v owels series, because their Hurst exponents are significantly lo wer than 0.5, which corresponds to the standard W iener process. Empirical distributions of Hurst exponents obtained by the rescaled range technique for se veral languages with N = 5000 are depicted on Fig. 8. In the figure “eng-tot” denotes the distribution for an English text written in the full alphabet, and “eng-consonant” corresponds to the same te xt without v owel letters. As one can see, distribu- tions for Russian and English hav e sharp maximums in different locations. Probably , distribution of Hurst exponents can be used to identify a language (or at least language group) of a text, but this topic is beyond the scope of the present paper . No w it can be stated only that our preliminary conjecture made in section 1 about Danish (or Spanish) as the original language of the Manuscript should be discarded. The reason is that the distributions of Hurst exponents for the Manuscript and ordinary texts are completely different. In case of the Manuscript observed distributions are shifted to the right and hav e much less acute maximum compared to all other curves on Fig.8. This means that statistics of the Manuscript does not agree with statistics of texts written in one particular language. Roughly speaking, symbols in the Manuscript are placed “more randomly” compared to the latter . Further analysis of these issues will be presented in the following sections of the paper . There are two main options here: the Manuscript is written in a special constructed language or it is written in se veral languages. It should be pointed out that in the case of multilingual texts (i.e. sev eral languages are mixed together) the Hurst exponent is inef fecti ve as a language indicator , because one does not know in adv ance which parts are written in each language. Distributions of Hurst exponents are almost similar for texts with and without vo wels, hence they cannot indicate presence or absence of the latter . Nev ertheless, provided that the distrib ution of Hurst e xponents is clearly unimodal, one can state that the text is written in one particular language. 14 Figure 8: Empirical distributions of Hurst exponents for time series formed by distances between pairs of the most frequent letters for sev eral languages 4 Constructed languages symbols statistics One of explanation for the de viation statistics of symbols of Manuscript from the statistics of “or- dinary” language can consist in the fact, that the Manuscript language could be constructed. There are about hundreds of constructed languages. Most of them are built on a v ariety of ideas, com- bining natural languages howe ver there are fiction languages in literary works. These languages, ho wev er , are not very dif ferent from the natural in terms of their statistical properties. Fig. 9–10 sho ws the distributions for some of them. It appeared that the “Elvish” language Quenya is very close to interlingua language and Es- peranto and V olapuk close to Latin, Klingon language stands alone. Distances between all these distributions is relatively small – from 0.09 to 0.13, but it must be noted that in this example, the complete alphabets were considered. Their distances vary from 0.03 to 0.05 in the case of close natural languages. Observe no w that the same factor of the presence of chains of three identical symbol in a row can be interpreted both in terms of reading the without vo wel MV and as part of hypothesis of an constructed language manuscript, where symbols can have a syntactic role. In this meaning the text in Esperanto is very close to EV A transcription (Fig. 11). The distance between them in L 1 norm was only 0.11, with the main dif ference in the lo w frequencies, rather than larger ones. The reliability of the logarithmic approximation in constructed languages is some what worse than in the te xts on Indo-European languages, and stays at the le vel of determination of “without vo wels” texts. The determination of the Klingon language is 0.95; Elvish – 0.96; Esperanto – 0.97. This does not mean that any constructed language has the same high determination, b ut all the same determination MV significantly belo w these values. This work is not aimed to highlight detailed analysis of constructed languages. The purpose was to giv e some particular demonstration of an assumptions that statistical properties similar to properties of natural languages are expected from the language which is sufficient to write meaningful text of a lar ge size. Fig. 12 sho ws the distribution of the Hurst exponent for ro ws of distances between the same 15 Figure 9: Distrib ution of symbols of ordering some con- structed languages Figure 10: Distribution of symbols of ordering some constructed languages symbols for constructed languages. The graph of the distrib ution of the Hurst e xponent for MV in T akahashi transcription is also presented. The fact that Hurst exponent for texts on natural and constructed languages beha ve roughly the same, and this behavior is dif ferent from the MV can be observed from Fig.8 and Fig.12. It seems that for the case of a sufficient elaboration of constructed languages they have antipersistent behavior of a number of distances between same letters in the texts. Consequently , the option of constructed language of the manuscript at this stage should be excluded. As already mentioned above, more accliv ous shape of the Hurst exponent for MV and the absence of its unimodal distribution can be the result of mixing se veral languages in the text, in particular two languages. 5 T wo-languages symbols statistics The version of the language, that we found in Sec.1 and in which the Manuscript could have been written, doesn’t cover other ways to b uild a text with a symbol statistics close to T akahashi transcription. The de viation of the VM logarithmic approximation of frequencies from an actual distribution approximately equals to 0.17, which is substantially more than the deviation from the majority of texts in European languages. This fact indicates that VM might hav e been written in two languages with a common alphabet. The last condition is not required but simplifies our research. Non-vo wels text determination, observed in most European languages at 0.96 rate, can be de- creased to 0.93, which is similar to VM determination, assuming a te xt is bilingual, written in two languages with a common alphabet, e.g. roman. After the remov al of vo wels and decoding this text turns into so-called V oynich Manuscript. W e expect that similar letters in both languages are not designated as different symbols in the Manuscript, which certainly narrows the search area. Still, it is worth mentioning that the probability of different alphabets usage is low , as T akahashi transcription determination is greater than 0.9. For such usage it is necessary to know symbol frequencies in each alphabet and group reassigned symbols properly , which seems to be rather un- realistic for the XVI century , especially considering the fact that regression analysis was inv ented much later . For this reason one should assume that the Manuscript te xt is meaningful, otherwise a de viation from specific letter statistics for the natural le xicon would hav e been much greater . Thus, in this section we accept the follo wing working hypotheses reg arding the VM: 16 Figure 11: Distribution of symbol by ordering text in Esperanto and EV A tran- scription Figure 12: Distrib ution of the Hurst exponent for the rows of distances of between same letters in the texts on the constructed languages 17 Figure 13: The mixture of Russian & Bulgarian Cyrillic texts 1. The manuscript is a bilingual text with a common alphabet. 2. V owels ha ve been deleted from the text before the decoding. 3. Decoding was a bijecti ve letter replacing by a symbol 4. Spaces in the text are not considered as characters Then we need to find out which pairs of languages with a common alphabet and in which pro- portion could be considered as the Manuscript languages, whether the y hav e the same or different linguistic groups and which goups exactly . In addition to that, we need to discov er how much a thematic aspect affects the statistical properties of the texts. A genre influence on alphabetic (not frequency-ordered) distrib ution in Russian texts was considered in [12], where a definite relation- ship has been observed. W e will show here the results of statistical analysis of the frequency in modern texts written in two different languages but with the same alphabets. It should be done in any case to test the hypothesis of the model determination reduction (1) by mixing te xts languages. T o test this hypothesis, we join two texts with about equal volumes, each one written in its own language but with the same alphabets in both te xts. W e will analyze texts without vo wels. W e consider texts with the same language group first. Russian and Bulgarian non-vo wel texts distribution av erage can be seen in Fig.13. Also there is a model dependency graph (1) for 20-letters alphabet for zero value of the parameter . It was found that pure and 50/50 Russian and Bulgarian mixed texts both hav e similar distributions with the similar determination, which equals to 0.96, and an actual distrib ution deviation from the model, which is equal to 0.10. This mixture, ob viously , has dif ferent statistical properties from the VM in either of the two transcriptions. Similar distrib utions for English-German texts are sho wn in the Fig.14. For these language pair as well as for French/Italian pair and for all text with the same language groups or subgroups (among the following three groups: Sla vic, Germanic and Romance) mixture determination of logarithmic approximation coincides with the determination of texts in one language at the same rate of 0.96. 18 Figure 14: Distribution of symbols of ordering some constructed languages Figure 15: Distribution of symbols of ordering some constructed languages Figure 16: The mixture of English/German texts Figure 17: The mixture of English/Spanish texts Thus, languages with the same group not only ha ve close ordered frequenc y distrib ution in the texts without vo wels, but also a mixture of these languages has the same logarithmic approximation determination to its components. It might to be interesting to check this observation against the texts of the XVI century , but in this paper we stick to the analysis of modern te xts statistics only , realizing that the findings are not strictly conclusi ve with respect to the VM. W e now consider examples of texts mixture of a dif ferent language group of Indo-European family . In the Fig.15 the frequency distributions in Spanish-English texts without vo wels are sho wn. Notice that a mixture of equal proportions of English and Spanish leads to a determination at 0.92 with a de viation of 0.17 from an actual distribution in the L 1 -norm approximation. Ac- cording to the statistics this mixture looks like T akahashi transcription, the distance between two distributions is 0.12. Ho wev er , the T akahashi transcription is e ven closer to the mixture of Latin and Danish lan- guages in ratio 2:1, the distance between them is 0.9 (Fig.16) The analysis revealed that the texts written in dif ferent languages of the same group do not change its ordered frequencies symbol distribution when mixing te xts in all possible proportions. For texts in different language groups either the mixture distribution changes, compared to the original distributions; or distances between distributions become more significant than the ob- served clustering le vel. W e emphasize that these findings relate only to book-style texts (written 19 Figure 18: The mixture of Danish-Latin texts by professional writers) where vo wels and softening symbols had been remov ed. W e also notice that while mixing English and Hungarian texts without vo wels, the distance between pure and mixed texts remained unchanged (equal to 0.16), whereas the logarithmic model determination for the mixture was higher (0.99) than for the text components separately (Hungarian 0.96 and En- glish 0.98, Fig. 17). This e xample shows that the preservation of determination of the languages mixture is not a necessary and sufficient condition for their affinity . In [1] and [2] it is shown that the full distribution of symbols depends on professional te xts specifics. Nuances between different texts are unimportant, determination lev el fluctuates at around 0.96 and difference between actual distributions and model dependency (1) changes with the range of 0.09–0.13, that approximately coincides with similar characteristics of literary texts. Consequently , we can assume that the text subject has no significant effect on the distribution of its ordered consonants and, therefore, conclusions dra wn from the research on literary texts can be applied for texts on specialized topics. 6 Identification of the Manuscript fragment language Distributions, constructed in Sec. 2 can be used to answer the question, where in the Manuscript text one language is mainly used and where there is a mixture. For this we need to apply a method proposed in [13] of identifying selectiv e distribution functions for small samples. This method is described as follows. Suppose we ha ve reference distrib ution functions (patterns) F i ( x ) and a fragment of the time series with selecti ve distribution function G ( x ) .Then this fragment is considered to be a sample from the distribution F j ( x ) with the number j = arg min k F i ( x ) − G ( x ) k (4) The norm, in which the distance between features are calculated in is chosen with the aim of identification the minimum error in the test data set. It was found out in that for small samples with lengths about 50–200 values and for distribution densities, integrally de viating from each other in the L 1 norm at about 0.1–0.2, the best norm between the distribution functions is L 1 : 20 Figure 19: The mixture of English and Hungarian texts k F ( x ) − G ( x ) k = Z | F ( x ) − G ( x ) | dx (5) In order to facilitate comparison with previously calculated distances between the distributions, we use the L 1 norm between the probability densities. In other w ords, we calculate the distance between the references and the sample density distribution function g n ( k , t ) , which is found from the sample of length n by moving a frame with a single time step: p i ( n, t ) = 20 X k =1 | f i ( k ) − g n ( k , t ) | (6) The argument t corresponds to a character number in the Manuscript text, with which the sample ends, and the index i means a reference number in accordance with the language. There are two reference e xamples of the density distribution for the VM: the first is the empirical distribution f i ( k ) of one European language text using the Latin alphabet, the second example is two mixtures mentioned abov e (English/Spanish and Latin/Danish). Comparing simultaneous distances ρ i ( n, t ) , corresponding fragments may be identified as being written mainly in the language with ρ i ( n, t ) = min . Ho wev er , one should keep in mind that this identification method is effecti ve only when we hav e a complete set of references. Otherwise, the identification will be incorrect. Proposed method of identification is suf ficiently accurate if there is a correct reference among the reference distrib u- tions. If it is not the case, the most similar reference will be found, b ut there is no guarantee of the correct recognition of course. Once again we would like to emphasize that we are talking about the European language that is the closest to the transcription T akahashi, instead of discussing which language the VM is actually written on. W e next perform language identification by gradually reducing the length of the text fragment. The whole text in T akahashi transcription is closest to the mixture of Latin and Danish. The distance to the mixture reference equals to 0.09, which is the lowest value among all possible combinations of modern European language pairs, including Latin. 21 W e further divide the VM into four parts approximately with 45 thousand symbols each. It turns out that the first two parts are ultimately close to the Danish language reference with a distance of 0.08, the third part is close to Latin with distance 0.10, and the fourth one is close again to a mixture of Latin and Danish with distance 0.07. It should be noted that this result does not mean that the first half of the text is written only in Danish. The fact is that, among the considered references, Danish turned out to be ev en closer than the reference “70 % Latin and 30 % Danish”, which was used as a mixture reference. Just subsequent text fragments specification allo ws to discover more accurately , which language each fragment is mainly written in. By further reducing the length of the considered fragment the distance to the closest reference increases with the growth of the statistical uncertainty of the sampling distribution and for the frag- ments of the length 10000 symbols this measure equals to 0.1. Notice that in all cases the distance to the closest reference was smaller than 0.13 which corresponds to the discov ered distance of the language groups splitting. 9 out of 17 fragments were identified as written in Dutch (these were the fragments 1,2,3,4,5,7,8,12 and 15 with the length of 10000 symbols), 6 – in Latin (fragments 6,9,10,11,14 and 16), 2 fragments (13 and 17) were identified as written in Dutch/Latin mix. In addition to that, the first position in 10 of the cases was taken by the letter “O”, symbol “E” was encountered 4 times and “T” - 3 times. The second place took the symbols “T” (7 times), “E” (6 times), “O” (3 times), “W” (once). It sho ws that the distrib ution of the ordered frequencies can not provide the precise information about the most common symbol, which prev ents from decoding of the text under the assumption of its e xact language. Consider now the fragments of the length 1000 digits (approximately 2.5 pages of the script). The same algorithm as abo ve mentioned allo ws us to argue which European language each frag- ment is close to, regarding the ordering of its symbols. The corresponding language “coloring” is shown in the Fig 18. Ho wev er , it should be taken into consideration, that if the distance to the nearest reference distrib ution becomes too lar ge, it is highly lik ely that the intended distrib ution is missing in the library . It seems interesting that along with the e xpected Dutch and Latin one can observe German and Spanish. As it was already mentioned, the distrib utions of the ordered fre- quencies correspond to the language group, therefore it mak es sense to identify Spanish and Latin as a single Roman language group, and German and Dutch as a single German group. Howe ver we should mention, that about 15 % of the fragments were identified at the low level of confidence, because the distances to the closest references turned out to be sufficient (more that 0.15). It can be the case, that the reference distributions were constructed with the help of contemporary texts; another reason can be that we were not able to find the actual reference. Ne vertheless, an abundance of arguments support the fact that the text to be written in tw o or more European languages. 7 Spectral portrait of V oynich Manuscript Considering matrix P ij of empirical conditional probabilities of the fact that at some point of the text is a symbol j , pro vided that to the left of it is a symbol i This matrix is described by double- letter distribution F ( ij ) and single-letter distrib ution f ( i ) as follo ws: P ij = F ( i, j ) f ( i ) , f ( i ) = X j F ( i, j ) (7) According to (7) it follows that matrix P ij has eigen value, which is equal to unit, and corre- sponding eigen vector is a symbol distribution f ( i ) . Other eigen values of this matrix characterize the stability of the frequencies of pairs of letters for fragments of the text. Conforming to S.K. Godunov [14], the value λ belongs to the -range Λ ( P ) of matrix P , if consists such disturbing 22 Figure 20: The closest distributions to the fragments of the length 1000 digits matrix ∆ , that δ ≤ P and det( λI − p − ∆) = 0 . The resolvent of the matrix P is defined as R ( λ ) = ( λI − P ) − 1 (8) Using the concept of resolvent the Epsilon-range is determinated this way: value λ appended to the Epsilon-range Λ ( P ) if the following condition is v alid: R ( λ ) ≥ 1 P (9) In practice, one of numerical algorithms using to determine regions in the complex plane of parameter λ is based on formula (9). The closed smooth curves γ that are isolines of the - spectrum are interesting in the research of the spectrum of point locations. The circuit γ separates the whole -spectrum Λ ( P ) into two parts lying inside and outside. The option K γ ( P ) of the dichotomy is e valuated by the norm square of the resolv ent (9) at the giv en curve: K γ ( P ) = P 2 l γ I γ R ( λ ) 2 dλ. (10) Here l γ is the length of the contour γ . The value K γ ( P ) is selected as the accuracy indicator of the separation of the spectrum. If certain curv e γ has no points of the spectrum λ ( P ) , the norm of the resolvent of a on such a curve is finite R ( λ ) γ < ∞ along with the integral ov er this curve. If some eigen v alues are belonged to the region bounded by the curve γ it is natural to consider them coincident with the specified accuracy . In this case the subspace with basis consisting of eigen vector and adjoined vector for such multiple eigenv alue is an in v ariant subspace for the operator P . 23 It is con venient to consider the radial dichotomy that is dichotomy is shaped by the curve λ = r e iφ with a fix ed value r . In this case the option K r ( P ) of the dichotomy is the norm of the Hermitian matrix H r ( P ) with the integral representation H r ( P ) = 1 2 π 2 π Z 0 ( P + − r e − iφ I ) − 1 ( P − r e iφ I ) − 1 dφ, K r ( P ) = P 2 H r ( P ) (11) The integral (11) conv erges only if on the circle λ = r e iφ there are no eigen v alues of the matrix P . This formula is used in finding the numerical -spectrum of the matrix in the form of le vel lines for the L 2 -norm of the resolvent. The y are giv en below . It makes sense to compare the spectral portraits of the matrices (7) for two transcriptions of the VM, as well as for texts of the Germanic and Romanic groups without a vo wel. The calculation results are sho wn on the figures 19–22. The areas with the same color hav e eigen v alues of the matrices if the elements of these matrices are kno wn with the precision noted in the legend. All matrices of the form (7) have one separate eigen value equal to one. The remaining eigen- v alues form a structure which are characteristic of one or the other languages. It makes sense to consider real eigen values, kernel close to zero and large in absolute value comple x eigen values. For all European languages the area of the spectrum is approximately limited by the circle with the radius 0.2 (the green region is sho wn on the Fig.19 and Fig.20). According to the paper [1] the area of the spectrum for the te xts with the full alphabet has the form not of a circle but of an ellipse with semimajor axis equal to approximately 0.5 and semiminor axis still equal to 0.2. Figure 21: Spectral portrait of text without v owel is written in English Comparing figures 19–20 and figures 21–22, we see that the regions with equal accuracy are markedly different in finding eigen v alues of the matrices (7) for the VM and con v entional texts (it conserns both texts in the full alphabet and without the v owel). For the both transcriptions of 24 Figure 22: Spectral portrait of text without v owel is written in Latin the VM the circle (it is not an ellipse!) of the location of the eigen v alues has approximately two times larger radius than for natural languages. It has fundamental importance. The spectrum of the EV A shifted to the left and spectrum of the T akahashi to the right. The dif ference of the spectral portraits of the transcriptions corresponds to dif ferences in the distrib utions of ordered frequencies (the red and the green curv es are shown at the Fig.1). The b ulge of these curves vary in opposite phase. Notably , the both transcriptions ha ve fiv e disjoint spectral zones of equal accuracy 10 − 2 (the light green is sho wn at the figures 21–22). It is important to emphasize that all these arguments are fundamentally dif ferent, i.e. they express the peculiar properties of independent statistics, indicating that the interpretation of the VM as part of the composite manuscript is acceptable. 8 V oynich Manuscript structure At the end of our research let us speak about the fundamental possibility of statistical detection of the manuscript fragments written in “a similar manner”, if such a term could be applied to the te xt in an unknown language. Back to the Introduction it is not guaranteed that the V oincih Manuscript has the correct ordering. The statistical research of the fragments of the V oincih Manuscript from the Chapter 5 in a sliding window found that the V oincih Manuscript cannot be treated as a sin- gle document. It can be treated as a number of independent works written for example by the “brotherhood” with their secret language. In this section we look at the statistical aspects of the VM analysis – the homogeneity of individual sheets. Follo wing the technique [2] we will use the functional distance between the distributions of characters in their alphabetical ordering to solve this problem. W e analyze the transcription T akahashi to av oid uncertainty . The analysis of literary texts in European languages, which was carried out in work [2], sho wed that between two fairly large (10 thousand characters) te xts by the same author on the same lan- 25 Figure 23: Spectral portrait of the transcription EV A T able 4: The distances between the distributions of characters in the VM Botany Bodies Astrology Mortars Botany 0.30 0.20 0.25 Bodies 0.18 0.27 Astrology 0.20 Mortars guage the distance in the sense of the norm L 1 for alphabetical ordered distributions of characters is 0.03–0.07. This distance for dif ferent authors is in the range of 0.04–0.13, and for dif ferent lan- guages regardless authors the distance between the texts is 0.20–0.50. With re gard to the VM [3], it makes sense to check ho w close the distrib utions of conditioned parts of the manuscript in accor- dance with the existing illustrations. Without pretending to be original, we separate the traditional “botanical” part of the VM (sheets 1–57 of the Manuscript), “female body” (sheets 75–85) and “astrology” (sheets 103–116). On the possible violations of the sequential numbering of the sheets indicates that the sheets 87, 90, 93–96 hav e clearly “botanical” type, the sheets 58, 68, 69 are similar to the subsequent “astrological” part, and the sheets 65, 66 would be con venient to refer to the “women’ s bodies”. The thematic belonging of the sheets 67, 70–73, 86, 88, 89, 99–102 ornamented by some “mortars” and plants. T able number 4 shows the distance between the sep- arated parts of the VM. It understood as the distance in the norm L 1 between the distributions of the ordered frequencies. The distances from the T able 4 are characterized by texts written in different languages. This texts may be the same or dif ferent. For example, a novel written in English and this is novel written in French. The most important that the text written in the same language differ not more than 0.13 26 Figure 24: Spectral portrait of the transcription T akahashi in the norm L 1 . The length of each of the fragments of the VM more than 10 thousand signs, so that the conclusion of the linguistic disparity of the VM seems reasonable. Note that half of each part is dif ferent from the other half on 0.10, so the allocation of parts of the VM in accordance with drawings is logically . Let’ s analyze, which parts of the VM are close to the indi vidual sheets, what do not have an unambiguous interpretation. One sheet of the VM has two pages and contains from 500 to 2000 symbols, depending on size of the images. The sheet of “its” part is separated from this part by a distance of 0.10–0.30, and by “foreign” part to 0.25–0.50. Let’ s try to identify the affiliation of the abov e ambiguous sheets by the proximity of their distribution to parts of the VM. The “Botanical” part is the nearest to the following sheets: 69 (the distance to the standard is 0.36), 86 (the distance is 0.16), 87 (the distance is 0.30), 93–96 (the distance is 0.15). T o the “Bodies” are close sheets 65 (the distance is 0.32) and 66 (the distance is 0.17). T o the “ Astrology” part are close the sheet 58 (the distance is 0.33). The rest ambiguous sheets 67, 68, 70–73, 88–90 are close to the “Mortar” part (99–102 sheets) with distances 0.17–0.32. Thus, the 4 sheets of the 23 ha ve been identified not as it should be in accordance with drawings. This lists are 68 (mortars instead of the expected astrology), 69 (botany instead of astrology), 86 (botany instead of mortars) and 90 (botany instead of mortar). But this fact is not so important as the fact that some 4 sheets (not all of them are those that are identified as “wrong”) are spaced from closest standards at very lar ge distances exceeding 0.32 (the last distance decile to recognize “significantly” sheets). This indicates insufficient reliability about their output. The share of such fragments among considered 23 sheets is 0.16. The accuracy of the similar identification of literary texts [2] is 0.15, which is close to estimates made for the VM and typical for this method. So, the marked fragments may claim to a thematic association with the fragments with the distance significantly less than to others. It is essential that these distances are approximately equal distances between the parts of fragments that are considered internally 27 homogeneous. This demonstrates the correctness of the proposed merger . Thus, the new point of vie w on the VM as a manuscript written in se veral languages, not only , but as no one, b ut two or three dif ferent manuscripts is possible. It is necessary to indicate the accuracy of the results presented in this paper . W e work on statistical pattern recognition by comparison with the standard. The critical point is the accuracy with standard itself known. In this case standard refers to the probability distribution of text characters. If the text is made up of N signs and written by alphabet of n signs, the distrib ution of these characters in the text is determined with a precision that find numerically from equation [15]: u 1 − / 2 = √ N Σ N ( n ) , Σ N ( n ) = n X j =1 p f N ( j )(1 − f N ( j )) (12) There u γ is a γ -quantile of the normal distribution. The quantile of Student’ s distribution order N at large v alues of N is approximated by corresponding u γ , and f N ( j ) is the empirical frequency of symbol j in this te xt with length N . In particular , for the logarithmic ordering model (1) when n = 20 and o = 0 the value of the sum in (12) is equal to 3.93; in relation to the VM with the number of signs N = 1 . 7 · 10 5 its actual distribution leads to Σ N ( n ) = 3 . 65 . The right side of the equation with respect to (12) for a theoretical model is equal to 105, and for the VM is equal to 113. These v alues correspond to similar accuracies = 0 . 02 , which dif fer in the third decimal place. It is similarly found out that the accuracy of the frequency distrib ution for a single page (1500 characters) is 0.1. Consequently , the differences between the distributions of the fragments at the lev el of 0.08–0.13, and sheets of fragments at the level of 0.20–0.40 are not caused by statistical noise of samples, they caused by objecti ve reasons. According to the estimates of accuracy , reliable field at the spectral portraits of the VM in the figures 21–22 correspond to the light green legend icons. Thus, the difference between the samples with the specified accuracy of statistical estimates is well defined. 9 Conclusion The results of presented statistical in vestig ations can be summarized as follows. The classification of the Indo-European languages into distinct groups can be performed ac- cording to a formal statistical procedure, i.e., pairwise clusterization of symbol frequencies distri- butions in te xts without v o wel letters. W ithin these sub-groups languages can be mixed together without any significant change in the frequency distribution. It should be noted howe ver that this rule is not uni versal, e.g. languages of the Uralic family do not clasterize well. It was shown that the distribution of Hurst exponents can be treated as a language in v ariant. Spectral portraits of texts written in the Indo-European languages ha ve close similarities in layout of eigen values. Concerning the Manuscript, it seems most plausible that it was written in two languages hav- ing the same alphabet without vo wel letters: 30 % of the text is written in one of the Germanic languages (Danish or German) and the rest 70 % – in one of the Romance languages (Latin or Spanish). The reasoning behind this statement relies on the observation that the distribution of symbol frequencies for the Manuscript resembles the features of meaningful texts, but the distri- bution of Hurst exponents for time series of distances between pairs of identical letters behav e completely different compared to texts written in one language (natural or constructed). In addi- tion, distances between alphabet distrib utions of large fragments of the Manuscript are also typical of texts written in se veral dif ferent languages. Proposed statistical techniques can be used to refine the pagination of the Manuscript according to its thematic sectioning. Ho wev er , it remains unclear whether the parts of the Manuscript are 28 distinct works or the same work: large distances between the fragments are typical for the case of dif ferent languages, not different w orks; in the latter case these distances are much lower . Y et the most intriguing questions “what are the origins of the Manuscript, who wrote it, what is it about, and, most importantly , why it was written” cannot be answered here. Only a rigorous and accurate translation of the Manuscript might shed some light on these issues. W e can propose (as a historical reconstruction) only a conjecture about the original purpose of the Manuscript and the creation of its peculiar alphabet. Probably , the alphabet itself was designed by a small group of scholars (presumably alchemists) on the basis of contemporary script. After some practice the y reached desired fluenc y in it (judging by the ease with which the Manuscript w as scribed); se veral treaties were written. Ho we ver , this is not the only possibility , e.g. they might have prepared a draft of translation from ordinary language into the cipher , and then made a copy of it, which is kno wn now as the Manuscript. After some time this scholar group v anished for some unknown reason. But some of their works (botanical, anatomical and astrological tractates) surviv ed. They were stored, probably , together and were not used by other scholars, because no one was able to decipher them. All consequent owners of these treaties did not have a clear understanding of what was written there. Probably at this time se veral pages were accidentally placed in the wrong order , and to prevent further shuffle page numbers were added. The rest of the story is well-known: all texts were sent to the library of Colle gio Romano where they were discov ered by W . V oynich who ga ve the first detailed description of the Manuscript. It is obvious that the results presented here tell nothing about the possible subjects of the Manuscript. W e might never find out what exactly happened to the scholars who created it in an attempt to conceal their knowledge. But we hope that ev entually the Manuscript itself shall be interpreted, with the help of statistical methods proposed here or any other research techniques and approaches. Refer ences [1] Arutyunov A.A., Borisov L.A., Zeniuk D.A., Ivc henko A.Y u., Kirina-Lilinskaya E.P ., Orlov Y u.N., Osminin K.P ., F edor ov S.L., Shilin S.A. Statistical regularity of European lan- guages and V oynich Manuscript analysis (in Russian). – Preprint KIAM of RAS, 2016, 52. http://library .keldysh.ru/preprint.asp?id=2016-52 [2] Orlov Y u.N., Osminin K.P . Methods of Statistical Analysis of Literature T exts (in Russian). – Mosco w: Editorial URSS, 2012. – 326 p. [3] Shailor B.A. V oynich catalog record. Y ale University Beinecke Rare Book & Manuscript Li- brary . [4] P elling N. J. The curse of the V oynich: the secret history of the world’ s most mysterious manuscript. – Surbiton, Surrey: Compelling Press, 2006. – 230 p. [5] Barabe J.G. Materials analysis of the V oynich Manuscript. Y ale Univ ersity Beinecke Rare Book & Manuscript Library . [6] Levito v L. Solution of the V oynich Manuscript: A liturgical Manual for the Endura Rite of the Cathari Heresy , the Cult of Isis.– W alnut Creek, California: Aegean Park Press, 1987.– 182p. [7] Landini G., Zandber gen R. A well-kept secret of mediaev al science: The V oynich manuscript //Aesculapius. – 1998. – V . 18., P . 77–82. [8] T akahashi transcription. http://voynich.no-ip.com/folios/ 29 [9] Gusein-Zade S.M. On the distribution of Russian language letters by frequencies (in Russian) // Information T ransfer Problems, 1988, V . 24. – P . 102. [10] Zenuk D.A., Klochko va L.V ., Orlov Y u.N. Simulation of non-stationary random processes by kinetic equations with fractional deriv ativ es (in Russian). Zhurnal Srednev olzhskogo Matem- aticheskogo Obschestv a, 2016. – V .18, 1. [11] Kirillov D.S., Kor ob O.V ., Mitin N.A., Orlov Y u.N., Pleshakov R.V . On the stationary distrib u- tions of the Hurst indicator for the non-stationary marked time series (in Russian). – Preprint KIAM of RAS, 2013, 11. http://library .keldysh.ru/preprint.asp?id=2013-11 [12] Orlov Y u.N., Osminin K.P . Genre and Author of Literature T ext Determination by Statistical Methods (in Russian). Applied Informatics, 2010. V . 26. P . 95–108. [13] Vlasyuk A.A., Orlov Y u.N. Identification accuracy of sample distribution functions for time series depending on distribution type, norm and sample length (in Russian). Preprint KIAM of RAS, 2015, 17. http://library .keldysh.ru/preprint.asp?id=2015-17 [14] Godunov S.K. Actual Aspects of Linear Algebra (in Russian). Novosibirsk: Nauchnaya Kniga, 1997. 388 p. [15] Orlov Y u.N. Kinetic Methods of Non-Stationary T ime-Series Analysis (in Russian). – Dol- goprudny: MIPT , 2014. 276 p. 30
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment