보이니치 원고의 문자 통계와 유럽 언어 군집 분석
** 본 논문은 10만 자 이상 규모의 유럽 언어 텍스트에서 문자 빈도 분포를 분석하고, 로그 의존성 및 L1 거리 척도를 이용해 언어군을 군집화한다. 동일한 방법을 보이니치 원고(EVA·타카하시 전사)에도 적용해 두 전사가 서로 다른 언어군에 가까움을 보이며, 로그 모델 적합도가 낮아 단일 알파벳 암호로 보기 어렵다는 결론을 제시한다. **
저자: Andronik Arutyunov, Leonid Borisov, Sergey Fedorov
**
본 연구는 유럽 언어들의 문자 빈도 분포를 정량적으로 분석하고, 이를 보이니치 원고(Voynich Manuscript, 이하 VM)의 두 주요 전사(EVA와 타카하시)와 비교함으로써 VM의 언어적 특성을 통계적으로 규명하고자 한다.
1. **연구 배경 및 목적**
- 문자 빈도는 언어 고유의 통계적 특성으로, 저자들은 이를 이용해 언어군을 구분하고, 두 언어가 혼합된 텍스트에서도 안정적인 패턴을 찾을 수 있다고 가정한다.
- VM은 16세기 필사본으로, 22개의 독특한 기호로 이루어져 있으며, 아직까지도 해독되지 않은 암호 혹은 허구라는 논쟁이 있다. 저자들은 VM이 실제 의미 있는 텍스트인지, 혹은 단순히 무작위 기호의 집합인지 통계적으로 판단하고자 한다.
2. **데이터와 방법**
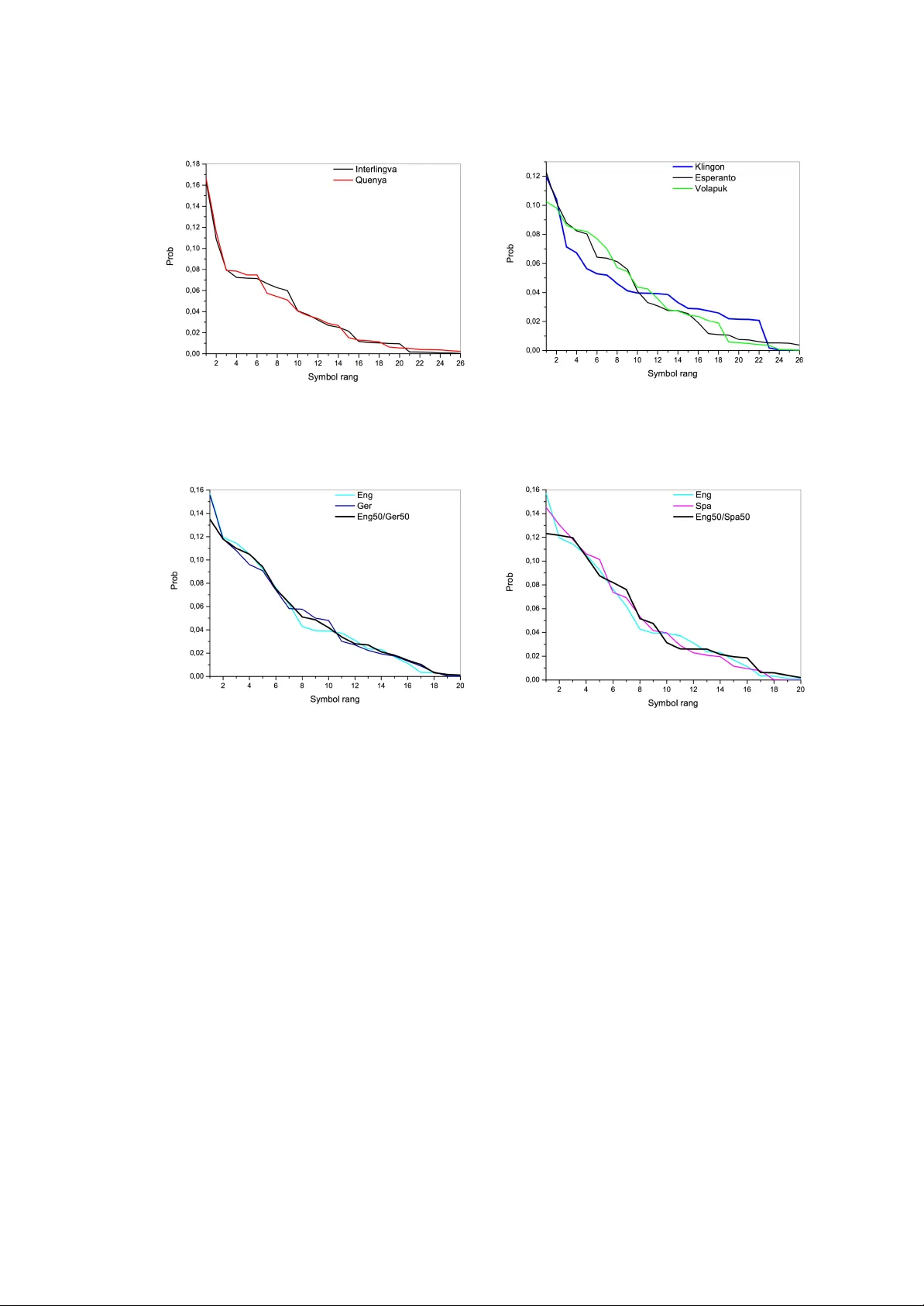
- 10만 자 이상 규모의 문학 텍스트를 22개 이상의 언어(인도-유럽·우랄어족)에서 수집하였다.
- 각 텍스트에 대해 문자(대소문자 구분 없이) 빈도를 계산하고, 빈도 순서에 따라 로그 함수 f(k)=A + B·log k 로 회귀시켜 결정계수(R²)와 L1 거리(실제 빈도와 모델 간 절대값 차의 합)를 측정하였다.
- 두 언어가 혼합된 텍스트에 대해서는 동일한 절차를 적용해 로그 모델 적합도와 거리 변화를 관찰하였다.
- VM 전사(EVA와 타카하시)의 경우, 전사별로 문자 빈도를 추출하고, 위와 동일한 로그 회귀와 L1 거리 분석을 수행하였다.
- 또한 2-문자 조합(빅람) 빈도 행렬을 구성하고, 고유값 스펙트럼을 시각화하여 언어적 구조를 탐색하였다.
3. **주요 결과**
- **유럽 언어들의 로그 적합도**: 대부분의 언어에서 R²≥0.96을 기록했으며, 특히 독일어·영어·네덜란드어 등 서게르만어군은 0.98에 달했다. 이는 문자 사용이 로그 형태로 강하게 규칙화됨을 의미한다.
- **언어군 간 거리**: L1 거리 기준으로 같은 언어군 내 언어들은 0.08~0.13, 다른 군 사이에서는 0.14~0.22의 차이를 보였다. 예를 들어, 러시아어와 불가리아어는 0.06으로 가장 가깝고, 그 외 슬라브어군 내에서도 유사성이 확인되었다.
- **VM 전사 분석**: EVA와 타카하시 전사는 각각 R²≈0.93을 보였지만, L1 거리(실제와 로그 모델 간 차이)는 0.17로 일반 언어보다 크게 나타났다. 이는 VM이 단일 알파벳 암호가 아니라는 강력한 증거이다.
- **전사별 언어군 매칭**: EVA 전사는 서게르만어군(특히 독일어·네덜란드어)과 가장 가까운 패턴을 보였고, 타카하시 전사는 슬라브·로맨스어군(특히 폴란드어·체코어)과 유사했다. 두 전사 간 L1 거리 차이는 0.26으로, 동일 원고에 대한 전사 선택이 통계적 해석에 큰 영향을 미친다.
- **문자 수 추정**: 로그 모델에 대한 최적 파라미터 o를 조정한 결과, EVA 전사에서는 o = −2가 가장 적합했으며, 이는 실제 사용되는 문자가 20개임을 시사한다. 즉, 22개의 기호 중 가장 드문 두 개를 제외하면 로그 적합도가 최적화된다.
- **2-문자 스펙트럼**: VM의 2-문자 빈도 행렬 고유값 분포는 다국어 혼합 텍스트에서 나타나는 다중 피크와 유사했으며, 이는 텍스트가 두 개 이상의 언어 혹은 인위적인 규칙에 의해 생성되었을 가능성을 제시한다.
4. **논의**
- VM이 단일 언어의 알파벳을 단순히 치환한 암호라면 로그 모델 적합도가 0.96 이상이어야 하지만, 실제로는 0.93에 불과하고 L1 거리가 크게 나타난다. 따라서 기존 유럽 언어와 통계적으로 일치하지 않는다.
- 두 전사가 서로 다른 언어군에 가까운 점은 전사 과정에서 기호 매핑이 크게 달라졌음을 의미한다. 이는 전사 자체가 언어적 해석에 편향을 일으킬 수 있음을 경고한다.
- 언어군 클러스터링 결과는 전통적인 언어학적 분류와 높은 일치도를 보였으며, 문자 빈도 통계가 언어군 구분에 유용한 도구임을 재확인한다.
- VM이 다언어 혼합 텍스트(예: 영어와 라틴어 혼합)일 경우, 클러스터링에서 관찰된 거리 패턴과 유사한 형태가 나타날 수 있다. 그러나 현재 데이터만으로는 구체적인 언어 조합을 확정하기 어렵다.
5. **결론**
- 문자 빈도와 로그 모델, L1 거리, 2-문자 스펙트럼 등 다중 통계 지표를 종합하면, VM은 기존 유럽 언어와는 통계적으로 일치하지 않으며, 단순한 단일 알파벳 암호가 아니라 복합적인 구조(다언어 혼합, 인위적 변형, 혹은 완전한 허구)일 가능성이 높다.
- 향후 연구에서는 보다 큰 코퍼스와 다양한 전사 방식을 적용하고, 기계학습 기반의 언어 모델을 활용해 다언어 혼합 가능성을 정량화하는 것이 필요하다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기