A General Retraining Framework for Scalable Adversarial Classification
Traditional classification algorithms assume that training and test data come from similar distributions. This assumption is violated in adversarial settings, where malicious actors modify instances to evade detection. A number of custom methods have…
Authors: Bo Li, Yevgeniy Vorobeychik, Xinyun Chen
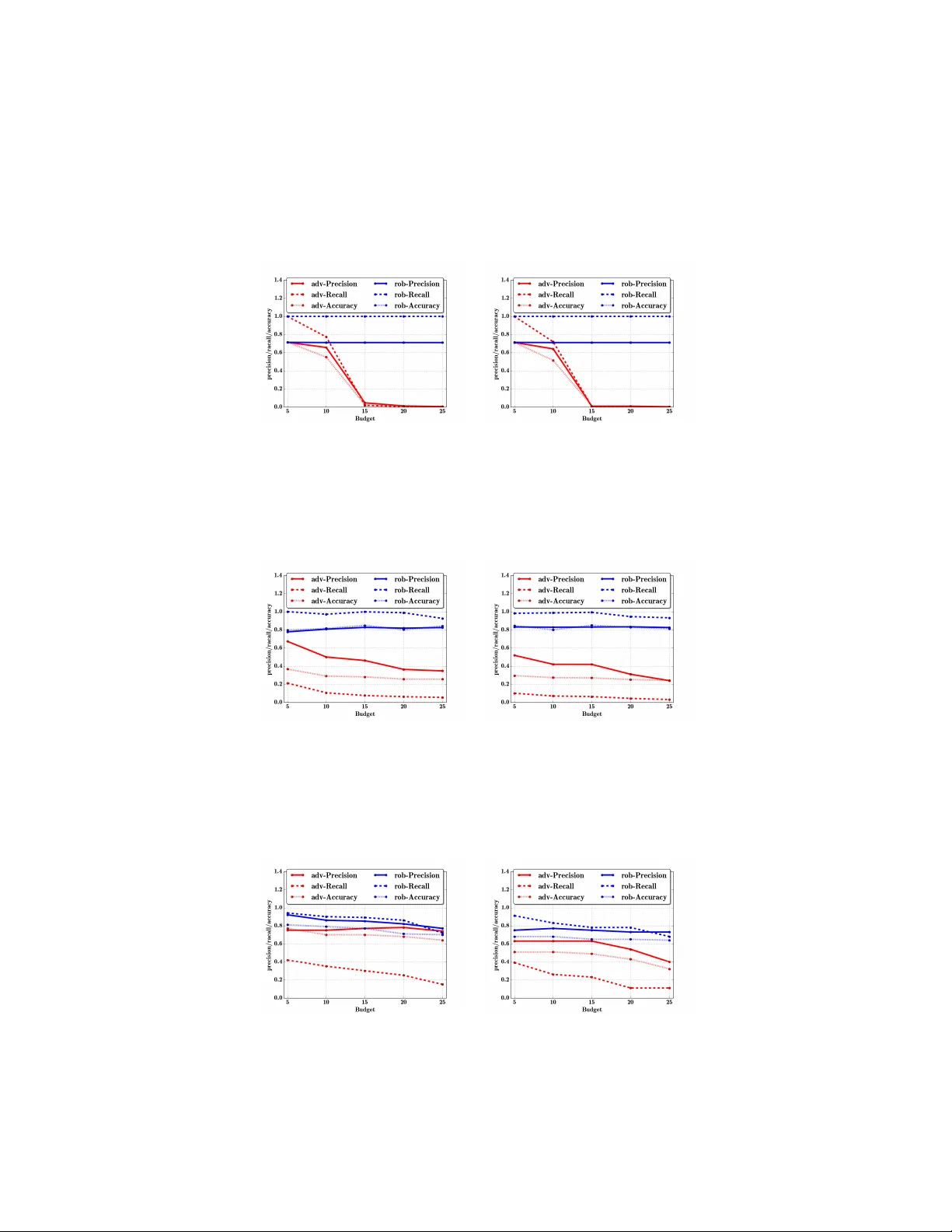
A General Retraining Framework f or Scalable Adversarial Classification Bo Li bo.li.2@vanderbilt.edu V anderbilt Univ ersity Y evgeniy V orobeychik yevgeniy.vorobeychik@vanderbilt.edu V anderbilt Univ ersity Xinyun Chen jungyhuk@gmail.com Shanghai Jiaotong Univ ersity Abstract T raditional classification algorithms assume that training and test data come from similar distributions. This assumption is violated in adversarial settings, where malicious actors modify instances to ev ade detection. A number of custom methods hav e been de veloped for both adversarial ev asion attacks and robust learning. W e propose the first systematic and general-purpose retraining frame work which can: a) boost robustness of an arbitrary learning algorithm, in the face of b) a broader class of adversarial models than any prior methods. W e show that, under natural conditions, the retraining framework minimizes an upper bound on optimal adversarial risk, and show ho w to e xtend this result to account for approximations of e vasion attacks. Extensive experimental e valuation demonstrates that our retraining methods are nearly indistinguishable from state-of-the-art algorithms for optimizing adversarial risk, but are mor e general and far mor e scalable . The experiments also confirm that without retraining, our adversarial frame work dramatically reduces the effecti veness of learning. In contrast, retraining significantly boosts robustness to ev asion attacks without significantly compromising overall accurac y . 1 Introduction Machine learning has been used ubiquitously for a wide v ariety of security tasks, such as intrusion detection, malware detection, spam filtering, and web search [ 1 , 2 , 3 , 4 , 5 ]. T raditional machine learning systems, ho wev er , do not account for adversarial manipulation. For example, in spam detection, spammers commonly change spam email text to e vade filtering. As a consequence, there hav e been a series of efforts to both model adversarial manipulation of learning, such as ev asion and data poisoning attacks [ 6 , 7 , 8 ], as well as detecting such attacks [ 2 , 9 ] or enhancing rob ustness of learning algorithms to these [ 10 , 11 , 12 , 13 , 14 ]. One of the most general of these, due to Li and V orobe ychik [ 10 ], admits e vasion attacks modeled through a broad class of optimization problems, giving rise to a Stackelber g game, in which the learner minimizes an adversarial risk function which accounts for optimal attacks on the learner . The main limitation of this approach, ho wev er, is scalability: it can solve instances with only 10-30 features. Indeed, most approaches to date also offer solutions that build on specific learning models or algorithms. For e xample, specific e vasion attacks hav e been dev eloped for linear or con vex-inducing classifiers [ 6 , 7 , 8 ], as well as neural networks for continuous feature spaces [ 15 ]. Similarly , robust algorithms ha ve typically in volv ed non-trivial modifications of underlying learning algorithms, and either assume a specific attack model or modify a specific algorithm. The more general algorithms that admit a wide array of attack models, on the other hand, hav e poor scalability . W orkshop on Adversarial T raining, NIPS 2016, Barcelona, Spain. W e propose a v ery general retraining framework, RAD , which can boost e vasion robustness of arbitrary learning algorithms using arbitrary e vasion attack models. W e sho w that RAD minimizes an upper bound on optimal adversarial risk. This is significant: whereas adversarial risk minimization is a hard bi-le vel optimization problem and poor scalabili ty properties (indeed, no methods exist to solve it for general attack models), RAD itself is extremely scalable in practice, as our experiments show . W e dev elop RAD for a more specific, but v ery broad class of adversarial models, offering a theoretical connection to adversarial risk minimization e ven when the adversarial model is only approximate. In the process, we offer a simple and v ery general class of local search algorithms for approximating ev asion attacks, which are e xperimentally quite effecti ve. Perhaps the most appealing aspect of the proposed approach is that it r equires no modification of learning algorithms : rather , it can wrap any learning algorithm “out-of-the-box”. Our work connects to, and systematizes, se veral previous approaches which used training with adversarial examples to either e valuate robustness of learning algorithms, or enhance learning robustness. For example, Goodfello w et al. [ 16 ] and Kantchelian et al. [ 17 ] make use of adv ersarial examples. In the former case, howe ver , these were essentially randomly chosen. The latter offered an iterati ve retraining approach more in the spirit of RAD , but did not systematically develop or analyze it. T eo et al. [ 12 ] do not make an explicit connection to retraining, b ut suggest equi valence between their general in variance-based approach using column generation and retraining. Howe ver , the two are not equi valent, and T eo et al. did not study their relationship formally . In summary , we make the follo wing contributions: 1. RAD , a nov el systematic framew ork for adversarial retraining, 2. analysis of the relationship between RAD and empirical adversarial risk minimization, 3. extension of the analysis to account for approximate adv ersarial ev asion, within a specific broad class of adversarial models, 4. extensi ve experimental e valuation of RAD and the adv ersarial ev asion model. W e illustrate the applicability and ef ficiency of our method on both spam filtering and handwritten digit recognition tasks, where ev asion attacks are extremely salient [18, 19]. 2 Learning and Ev asion Attacks Let X ⊆ R n be the feature space, with n the number of features. For a feature vector x i ∈ X , we let x i j denote the j th feature. Suppose that the training set ( x i , y i ) is comprised of feature vectors x i ∈ X generated according to some unkno wn distribution x i ∼ F , with y i ∈ {− 1 , +1 } the corresponding binary labels, where − 1 means the instance x i is benign, while +1 indicates a malicious instance. The learner aims to learn a classifier with parameters β , g β : X → {− 1 , +1 } , to label instances as malicious or benign, using a training data set of labeled instance D = { ( x 1 , y 1 ) , ..., ( x m , y m ) } . Let I bad be the subset of datapoints i with y i = +1 . W e assume that g β ( x ) = sgn( f β ( x )) for some real-valued function f β ( x ) . T raditionally , machine learning algorithms commonly minimize regularized empirical risk: min β L ( β ) ≡ X i l ( g β ( x i ) , y i ) + α k β k p p , (1) where l ( ˆ y , y ) is the loss associated with predicting ˆ y when true classification is y . An important issue in adversarial settings is that instances classified as malicious (in our con vention, corresponding to g β ( x ) = +1 ) are associated with malicious agents who subsequently modify such instances in order to ev ade the classifier (and be classified as benign). Suppose that adversarial ev asion behavior is captured by an oracle, O ( β , x ) , which returns, for a giv en parameter vector β and original feature vector (in the training data) x , an alternati ve feature v ector x 0 . Since the adversary modifies malicious instances according to this oracle, the resulting ef fectiv e risk for the defender is no longer captured by Equation 1 , but must account for adv ersarial response. Consequently , the defender would seek to minimize the following adver sarial risk (on training data): min β L A ( β ; O ) = X i : y i = − 1 l ( g β ( x i ) , − 1) + X i : y i =+1 l ( g β ( O ( β , x i ) , +1) + α k β k p p . (2) 2 The adversarial risk function in Equation 2 is extremely general: we make, at the moment, no assumptions on the nature of the attacker oracle, O . This oracle may capture ev asion attack models based on minimizing e vasion cost [6, 10, 15], or based on actual attack er ev asion behavior obtained from experimental data [20]. 3 Adversarial Lear ning through Retraining A number of approaches ha ve been proposed for making learning algorithms more rob ust to adver- sarial ev asion attacks [ 21 , 10 , 11 , 12 , 14 ]. Ho wever , these approaches typically suf fer from three limitations: 1) they usually assume specific attack models, 2) they require substantial modifications of learning algorithms, and 3) they commonly suf fer from significant scalability limitations. For example, a recent, general, adversarial learning algorithm proposed by Li and V orobe ychik [ 10 ] makes use of constraint generation, b ut does not scale beyond 10-30 features. Recently , retraining with adversarial data has been proposed as a means to increase robustness of learning [16, 17, 12]. 1 Howe ver , to date such approaches have not been systematic. W e present a new algorithm, RAD , for retraining with adversarial data (Algorithm 1 ) which system- atizes some of the prior insights, and enables us to provide a formal connection between retraining with adversarial data, and adversarial risk minimization in the sense of Equation 2 . The RAD al- Algorithm 1 RAD: Retraining with ADversarial Examples 1: Input : training data X 2: N i ← ∅ ∀ i ∈ I bad 3: repeat 4: β ← T rain( X ∪ i N i ) 5: new ← ∅ 6: for i ∈ I bad do 7: x 0 = O ( β , x i ) 8: if x 0 / ∈ N i then 9: new ← new ∪ x 0 10: end if 11: N i ← N i ∪ x 0 12: end for 13: until new = ∅ 14: Output : Parameter vector β gorithm is quite general. At the high lev el, it starts with the original training data X and iterates between computing a classifier and adding adv ersarial instances to the training data that ev ade the previously computed classifier , if they are not already a part of the data. A baseline termination condition for RAD is that no ne w adversarial instances can be added (either because instances generated by O hav e already been pre viously added, or because the adv ersary’ s can no longer benefit from e vasion, as discussed more formally in Section 4.1 ). If the range of O is finite (e.g., if the feature space is finite), RAD with this termination condition w ould always terminate. In practice, our experiments demonstrate that when termination conditions are satisfied, the number of RAD iterations is quite small (between 5 and 20). Moreov er , while RAD effecti ve increases the importance of malicious instances in training, this does not appear to significantly harm classification performance in a non-adversarial setting. In general, we can also control the number of rounds directly , or use an additional termination condition, such as that the parameter vector β changes little between successiv e iterations. Howe ver , we assume henceforth that there is no fixed iteration limit or con vergence check. T o analyze what happens if the algorithm terminates, define the re gularized empirical risk in the last iteration of RAD as: L R N ( β , O ) = X i ∈ D ∪ N l ( g β ( x i ) , y i ) + α || β || p p , (3) 1 Indeed, neither T eo et al. [ 12 ] nor Kantchelian et al. [ 17 ] focus on retraining as a main contribution, but observe its ef fectiveness. 3 where a set N = ∪ i N i of data points has been added by the algorithm (we omit its dependence on O to simplify notation). W e now characterize the relationship between L R N ( β , O ) and L ∗ A ( O ) = min β L A ( β , O ) . Proposition 3.1. L ∗ A ( O ) ≤ L R N ( β , O ) for all β , O . Pr oof. Let ¯ β ∈ arg min β L R N ( β , O ) . Consequently , for any β , L R N ( β , O ) ≥ L R N ( ¯ β , O ) = X i : y i = − 1 l ( g ¯ β ( x i ) , − 1) + X i : y i =+1 X j ∈ N i ∪ x i l ( g ¯ β ( x i ) , +1) + α || ¯ β || p p ≥ X i : y i = − 1 l ( g ¯ β ( x i ) , − 1) + X i : y i =+1 l ( g ¯ β ( O ( ¯ β , x i )) , +1) + α || ¯ β || p p ≥ min β L A ( β ; O ) = L ∗ A ( O ) , where the second inequality follows because in the last iteration of the algorithm, new = ∅ (since it must terminate after this iteration), which means that O ( β , x i ) ∈ N i for all i ∈ I bad . In words, retraining, systematized in the RAD algorithm, ef fectively minimizes an upper bound on optimal adv ersarial risk. 2 This of fers a conceptual e xplanation for the pre viously observed effecti veness of such algorithms in boosting robustness of learning to adv ersarial ev asion. Formally , howe ver , the result above is limited for se veral reasons. First, for many adversarial models in prior literature, adversarial e vasion is NP-Hard. While some effecti ve approaches exist to compute optimal ev asion for specific learning algorithms [ 17 ], this is not true in general. Although approximation algorithms for these models exist, using them as oracles in RAD is problematic, since actual attackers may compute better solutions, and Proposition 3.1 no longer applies. Second, we assume that O returns a unique result, but when ev asion is modeled as optimization, optima need not be unique. Third, there do not e xist effecti ve general-purpose adversarial ev asion algorithms the use of which in RAD would allow reasonable theoretical guarantees. Below , we in vestigate an important and very general class of adv ersarial ev asion models and associated algorithms which allow us to obtain practically meaningful guarantees for RAD . Clustering Malicious Instances: A significant enhancement in speed of the approach can be obtained by clustering malicious instances: this would reduce both the number of iterations, as well as the number of data points added per iteration. Experiments (in the supplement) sho w that this is indeed quite effecti ve. Stochastic gradient descent: RAD works particularly well with online methods, such as stochastic gradient descent. Indeed, in this case we need only to make gradient descent steps for ne wly added malicious instances, which can be added one at a time until con vergence. 4 Modeling Attackers 4.1 Evasion Attack as Optimization In prior literature, ev asion attacks have almost uni versally been modeled as optimization problems in which attackers balance the objectiv e of ev ading the classifier (by changing the label from +1 to − 1 ) and the cost of such ev asion [ 6 , 10 ]. Our approach is in the same spirit, but is formally somewhat distinct. In particular, we assume that the adversary has the follo wing two competing objecti ves: 1) appear as benign as possible to the classifier , and 2) minimize modification cost. It is also natural to assume that the attacker obtains no v alue from a modification to the original feature vector if the result is still classified as malicious. T o formalize, consider an attacker who in the original training data uses a feature vector x i ( i ∈ I bad ) ). The adversary i is solving the follo wing optimization problem: min x ∈ X min { 0 , f ( x ) } + c ( x, x i ) . (4) 2 Note that the bound relies on the fact that we are only adding adv ersarial instances, and terminate once no more instances can be added. In particular , natural variations, such as removing or re-weighing added adversarial instances to retain original malicious-benign balance lose this guarantee. 4 W e assume that c ( x, x i ) ≥ 0 , c ( x, x i ) = 0 iff x = x i , and c is strictly increasing in k x − x i k 2 and strictly con vex in x . 3 Because Problem 4 is non-con vex, we instead minimize an upper bound: min x Q ( x ) ≡ f ( x ) + c ( x, x i ) . (5) In addition, if f ( x i ) < 0 , we return x i before solving Problem 5 . If Problem 5 returns an optimal solution x ∗ with f ( x ∗ ) ≥ 0 , we return x i ; otherwise, return x ∗ . Problem 5 has two adv antages. First, if f ( x ) is conv ex and x real-valued, this is a (strictly) con vex optimization problem, has a unique solution, and we can solve it in polynomial time. An important special case is when f ( x ) = w T x . The second one we formalize in the following lemma. Lemma 4.1. Suppose x ∗ is the optimal solution to Pr oblem 4 , x i is suboptimal, and f ( x ∗ ) < 0 . Let ¯ x be the optimal solution to Pr oblem 5. Then f ( ¯ x ) + c ( ¯ x, x i ) = f ( x ∗ ) + c ( x ∗ , x i ) , and f ( ¯ x ) < 0 . The following corollary then follo ws by uniqueness of optimal solutions for strictly conv ex objecti ve functions ov er a real vector space. Corollary 4.1. If f ( x ) is con vex and x continuous, x ∗ is the optimal solution to Pr oblem 4 , ¯ x is the optimal solution to Pr oblem 5, and f ( x ∗ ) < 0 , then ¯ x = x ∗ . A direct consequence of this corollary is that when we use Problem 5 to approximate Problem 4 and this approximation is con vex, we alw ays return either the optimal e vasion, or x i if no cost-ef fectiv e ev asion is possible. An oracle O constructed on this basis will therefore return a unique solution, and supports the theoretical characterization of RAD abov e. The results abov e are encouraging, but man y learning problems do not feature a con vex f ( x ) , or a continuous feature space. Next, we consider sev eral general algorithms for adversarial ev asion. 4.2 Coordinate Greedy W e propose a very general local search framework, Coor dinateGr eedy (CG) (Algorithm 2 for approximating optimal attacker e vasion. The high-lev el idea is to iterati vely choose a feature, and Algorithm 2 CoordinateGreedy( CG ): O ( β , x ) 1: Input : Parameter vector β , malicious instance x 2: Set k ← 0 and let x 0 ← x 3: repeat 4: Randomly choose index i k ∈ { 1 , 2 , ..., n } 5: x k +1 ← GreedyImprov e( i k ) 6: k ← k + 1 7: until ln Q ( x k ) ln Q ( x k − 1 ) ≤ 8: if f ( x k ) ≥ 0 then 9: x k ← x 10: end if 11: Output : Adversarially optimal instance x k . greedily update this feature to incrementally improve the attack er’ s utility (as defined by Problem 5 ). In general, this algorithm will only con verge to a locally optimal solution. W e therefore propose a version with random restarts: run CG from L random starting points in feature space. As long as a global optimum has a basin of attraction with positi ve Lebesgue measure, or the feature space is finite, this process will asymptotically conv erge to a globally optimal solution as we increase the number of random restarts. Thus, as we increase the number of random restarts, we expect to increase the frequency that we actual return the global optimum. Let p L denote the probability that the oracle based on coordinate greedy with L random restarts returns a suboptimal solution to Problem 5 . The next result generalizes the bound on RAD to allow for this, restricting ho wever that the risk function which we bound from above uses the 0 / 1 loss. Let L ∗ A, 01 ( O ) correspond to the total adversarial risk in Equation 2 , where the loss function l ( g β ( x ) , y ) is the 0 / 1 loss. Suppose that O L uses coordinate greedy with L random restarts. 3 Here we exhibit a particular general attack model, but many alternati ves are possible, such as using constrained optimization. W e found experimentally that the results are not particularly sensiti ve to the choice of the attack model. 5 Proposition 4.2. Let B = | I bad | . L ∗ A, 01 ( O ) ≤ L R N ( β , O L ) + δ ( p ) with pr obability at least 1 − p , wher e δ ( p ) = B p L + √ log 2 p − 8 B p l log p − log p 2 B , and L R N ( β , O L ) uses any loss function l ( g β ( x ) , y ) whic h is an upper bound on the 0 / 1 loss. Experiments suggest that p L → 0 quite rapidly for an array of learning algorithms, and for either discrete or continuous features, as we increase the number of restarts L (see the supplement for details). Consequently , in practice retraining with coordinate greedy nearly minimizes an upper bound on minimal adversarial risk for a 0/1 loss with fe w restarts of the approximate attacker oracle. Continuous Feature Space: For continuous feature space, we assume that both f ( x ) and c ( x, · ) are differentiable in x , and propose using the coor dinate descent algorithm, which is a special case of coordinate greedy , where the GreedyImprove step is: x k +1 ← x k − τ k e i k ∂ Q ( x k ) ∂ x k i k , where τ k is the step size and e i k the direction of i k th coordinate. Henceforth, let the origial adversarial instance x i be gi ven; we then simplify cost function to be only a function of x , denoted c ( x ) . If the function f ( x ) is conv ex and differentiable, our coordinate descent based algorithm 2 can always find the global optima which is the attacker best response x ∗ [ 22 ], and Proposition 3.1 applies, by Corollary 4.1 . If f ( x ) is not con vex, then coordinate descent will only con ver ge to a local optimum. Discrete Featur e Space: In the case of discrete feature space, GreedyImpro ve step of CG can simply enumerate all options for feature j , and choose the one most improving the objecti ve. 5 Experimental Results The results abov e suggest that the proposed systematic retraining algorithm is lik ely to be ef fectiv e at increasing resilience to adversarial ev asion. W e now offer an experimental ev aluation of this (additional results are pro vided in the supplement). W e present the results for the exponential cost model, where c ( x, x i ) = exp λ ( P j ( x j − x ij ) 2 + 1) 1 / 2 . Additionally , we simulated attacks using Problem 5 formulation. Results for other cost functions and attack models are similar , as sho wn in the supplement. Moreover , the supplement demonstrates that the approach is robust to cost function misspecification. Comparison to Optimal: The first comparison we draw is to a recent algorithm, SMA , which minimizes l 1 -regularized adversarial risk function (2) using the hinge loss function. Specifically , SMA formulates the problem as a large mixed-inte ger linear program which it solves using constraint generation [ 10 ]. The main limitation of SMA is scalability . Because retraining methods use out-of- the-box learning tools and does not inv olve non-con vex bi-le vel optimization, it is considerably more scalable. (a) (b) Figure 1: Comparison between RAD and SMA based on the Enron dataset with 30 binary features. (a) The F 1 score of different algorithms corresponding to various λ ; (b) the average runtime for each algorithm. W e compared SMA and RAD using Enron data [ 18 ]. As Figure 1 (a) demonstrates, retraining solutions of RAD are nearly as good as SMA , particularly for a non-tri vial adversarial cost sensitiv e λ . In contrast, a baseline implementation of SVM is significantly more fragile to ev asion attacks. Howe ver , the runtime comparison for these algorithms in Figure 1 (b) sho ws that RAD is much more scalable than SMA . 6 (a) (b) (c) Figure 2: Performance of baseline ( adv- ) and RAD ( rob- ) as a function of cost sensitivity λ for Enron (top) and MNIST (bottom) datasets with continuous features testing on adversarial instances. (a) logistic regression, (b) SVM, (c) 3-layer NN. (a) (b) (c) Figure 3: Performance of baseline ( adv- ) and RAD ( r ob- ) as a function of cost sensiti vity λ for MNIST dataset with continuous features testing on non-adversarial instances. (a) logistic regression, (b) SVM, (c) 3-layer NN. Effectiveness of Retraining: In this section we use the Enron dataset [ 18 ] and MNIST [ 19 ] dataset to ev aluate the robustness of three common algorithms in their standard implementation, and in RAD : logistic regression, SVM (using a linear kernel), and a neural network (NN) with 3 hidden layers. In Enron data, features correspond to relativ e word frequencies. 2000 features were used for the Enron and 784 for MNIST datasets. Throughout, we use precision, recall, and accuracy as metrics. W e present the results for a continuous feature space here. Results for binary features are similar and provided in the supplement. Figure 2 (a) shows the performance of logistic re gression, with and without retraining, on Enron and MNIST . The increased robustness of RAD is immediately evident: performance of RAD is essentially independent of λ on all three measures, and substantially e xceeds baseline algorithm performance for small λ . Interestingly , we observe that the baseline algorithms are significantly more fragile to ev asion attacks on Enron data compard to MNIST : benign and malicious classes seem far easier to separate on the latter than the former . This qualitativ e comparison between the Enron and MNIST datasets is consistent for other classification methods as well (SVM, NN). These results also illustrate that the neural-network classifiers, in their baseline implementation, are significantly more rob ust to ev asion attacks than the (generalized) linear classifiers (logistic re gression and SVM): ev en with a relativ ely small attack cost attacks become ineffecti ve relati vely quickly , and the differences between the performance on Enron and MNIST data are far smaller . Throughout, howe ver , RAD significantly improv es rob ustness to e vasion, maintaining extremely high accurac y , precision, and recall essentially independently of λ , dataset, and algorithm used. In order to explore whether RAD would sacrifice accuracy when no adversary is present, Figure 3 shows the performance of the baseline algorithms and RAD on a test dataset sans ev asions. Surpris- 7 ingly , RAD is ne ver significantly worse, and in some cases better than non-adversarial baselines: adding malicious instances appears to increase o verall generalization ability . This is also consistent with the observation by Kantchelian et al. [17]. Oracles based on Human Evasion Beha vior: T o e valuate the considerable generality of RAD , we now use a non-optimization-based threat model, making use instead of observed human e vasion behavior in human subject e xperiments . The data for this ev aluation was obtained from the human subject experiment by K e et al. [ 20 ] in which subjects were tasked with the goal of ev ading an SVM- based spam filter , manipulating 10 spam/phishing email instances in the process. In these experiments, Ke et al. used machine learning to dev elop a model of human subject ev asion behavior . W e now adopt this model as the e vasion oracle, O , injected in our RAD retraining frame work, ex ecuting the synthetic model for 0-10 iterations to obtain ev asion examples. Figure 4(a) shows the recall results for the dataset of 10 malicious emails (the classifiers are trained on Enron data, but ev aluated on these 10 emails, including ev asion attacks). Figure 4 (b) sho ws the classifier performance for the Enron dataset by applying the synthetic adversarial model as the oracle. W e can make two high-level observ ations. First, notice that human adversaries appear (a) (b) Figure 4: RAD ( r ob- ) and baseline SVM ( adv- ) performance based on human subject behavior data ov er 20 queries, (a) using experimental data with actual human subject experiment submissions, (b) using Enron data and a synthetic model of human ev ader . significantly less powerful in e vading the classifier than the automated optimization-based attacks we pre viously considered. This is a testament to both the effecti veness of our general-purpose adv ersarial ev aluation approach, and the likelihood that such automated attacks likely significantly ov erestimate adversarial ev asion risk in many settings. Nev ertheless, we can observe that the synthetic model used in RAD leads to a significantly more rob ust classifier . Moreover , as our ev aluation used actual ev asions, while the synthetic model was used only in training the classifier as a part of RAD , this experiment suggests that the synthetic model can be relativ ely effecti ve in modeling behavior of human adversaries. Figure 4 (b) performs a more systematic study using the synthetic model of adversarial beha vior on the Enron dataset. The findings are consistent with those only considering the 10 spam instances: retraining significantly boosts robustness to ev asion, with classifier effecti veness essentially independent of the number of queries made by the oracle. 6 Conclusion W e proposed a general-purpose systematic retraining algorithm against e vasion attacks of classifiers for arbitrary oracle-based ev asion models. W e first demonstrated that this algorithm effecti vely minimizes an upper bound on optimal adversarial risk, which is typically extremely dif ficult to compute (indeed, no approach exists for minimizing adv ersarial loss for an arbitrary ev asion oracle). Experimentally , we sho wed that the performance of our retraining approach is nearly indistinguishable from optimal, whereas scalability is dramatically improved: indeed, with RAD , we are able to easily scale the approach to thousands of features, whereas a state-of-the-art adv ersarial risk optimization method can only scale to 15-30 features. W e generalize our results to show that a probabilistic upper bound on minimal adversarial loss can be obtained ev en when the oracle is computed approximately by le veraging random restarts, and an empirical e valuation which confirms that the resulting bound relaxation is tight in practice. W e also of fer a general-purpose framework for optimization-based oracles using variations of coordi- nate greedy algorithm on both discrete and continuous feature spaces. Our experiments demonstrate 8 that our adversarial oracle approach is e xtremely effecti ve in corrupting the baseline learning algo- rithms. On the other hand, extensi ve experiments also sho w that the use of our retraining methods significantly boosts robustness of algorithms to e vasion. Indeed, retrained algorithms become nearly insensitiv e to adversarial e vasion attacks, at the same time maintaining extremely good learning performance on data ov erall. Perhaps the most significant strength of the proposed approach is that it can make use of arbitrary learning algorithms essentially “out-of-the-box”, and effecti vely and quickly boost their robustness, in contrast to most prior adversarial learning methods which were algorithm-specific. References [1] T om Fawcett and Foster Prov ost. Adaptiv e fraud detection. Data mining and knowledge discovery , 1(3):291–316, 1997. [2] Matthew V Mahoney and Philip K Chan. Learning nonstationary models of normal network traf fic for detecting novel attacks. In Pr oceedings of the eighth ACM SIGKDD international confer ence on Knowledge discovery and data mining , pages 376–385. A CM, 2002. [3] Prahlad Fogla, Monirul I Sharif, Roberto Perdisci, Oleg M K olesnikov , and W enke Lee. Polymorphic blending attacks. In USENIX Security , 2006. [4] Ling Huang, Anthony D Joseph, Blaine Nelson, Benjamin IP Rubinstein, and JD T ygar . Adversarial machine learning. In W orkshop on Security and Artificial Intelligence , pages 43–58. A CM, 2011. [5] Aleksander K ołcz and Choon Hui T eo. Feature weighting for improved classifier robustness. In CEAS’09: sixth confer ence on email and anti-spam , 2009. [6] Daniel Lowd and Christopher Meek. Adversarial learning. In Pr oceedings of the eleventh A CM SIGKDD international confer ence on Knowledge discovery in data mining , pages 641–647. A CM, 2005. [7] Christoph Karlberger , Günther Bayler , Christopher Kruegel, and Engin Kirda. Exploiting redundancy in natural language to penetrate bayesian spam filters. W OO T , 7:1–7, 2007. [8] Blaine Nelson, Benjamin IP Rubinstein, Ling Huang, Anthony D Joseph, Ste ven J Lee, Satish Rao, and JD T ygar . Query strategies for ev ading conv ex-inducing classifiers. The Journal of Machine Learning Resear ch , 13(1):1293–1332, 2012. [9] Laurent El Ghaoui, Gert René Georges Lanckriet, Georges Natsoulis, et al. Robust classification with interval data . Computer Science Di vision, Univ ersity of California, 2003. [10] Bo Li and Y evgeniy V orobeychik. Feature cross-substitution in adversarial classification. In Advances in Neural Information Pr ocessing Systems , pages 2087–2095, 2014. [11] Bo Li and Y evgeniy V orobeychik. Scalable optimization of randomized operational decisions in adv ersarial classification settings. In Pr oceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics , pages 599–607, 2015. [12] Choon H T eo, Amir Globerson, Sam T Roweis, and Ale x J Smola. Con ve x learning with in variances. In Advances in neural information pr ocessing systems , pages 1489–1496, 2007. [13] Amir Globerson and Sam Roweis. Nightmare at test time: robust learning by feature deletion. In Pr oceedings of the 23rd international confer ence on Machine learning , pages 353–360. A CM, 2006. [14] Michael Brückner and T obias Scheffer . Stackelberg games for adversarial prediction problems. In Pr oceedings of the 17th A CM SIGKDD international conference on Knowledg e discovery and data mining , pages 547–555. A CM, 2011. [15] Battista Biggio, Giorgio Fumera, and Fabio Roli. Security ev aluation of pattern classifiers under attack. Knowledge and Data Engineering, IEEE T ransactions on , 26(4):984–996, 2014. [16] Ian J Goodfello w , Jonathon Shlens, and Christian Szegedy . Explaining and harnessing adv ersarial e xamples. arXiv pr eprint arXiv:1412.6572 , 2014. [17] A. Kantchelian, J. D. T ygar, and A. D. Joseph. Evasion and hardening of tree ensemble classifiers. arXi v pre-print, 2015. [18] Bryan Klimt and Y iming Y ang. The enron corpus: A new dataset for email classification research. In Machine learning: ECML 2004 , pages 217–226. Springer , 2004. 9 [19] Y ann LeCun and Corinna Cortes. Mnist handwritten digit database. A T&T Labs [Online]. A vailable: http://yann. lecun. com/exdb/mnist , 2010. [20] Liyiming Ke, Bo Li, and Y evgeniy V orobeychik. Behavioral experiments in email filter e vasion. In AAAI Confer ence on Artificial Intelligence , 2016. [21] Nilesh Dalvi, Pedro Domingos, Sumit Sanghai, Deepak V erma, et al. Adversarial classification. In Pr oceedings of the tenth ACM SIGKDD international confer ence on Knowledg e discovery and data mining , pages 99–108. A CM, 2004. [22] Zhi-Quan Luo and Paul Tseng. On the con vergence of the coordinate descent method for con vex dif feren- tiable minimization. J ournal of Optimization Theory and Applications , 72(1):7–35, 1992. [23] Stephen Boyd and Lie ven V andenberghe. Conve x Optimization . Cambridge University Press, 2004. 10 Supplement T o: A General Retraining Framework f or Scalable Adversarial Classification Proof of Lemma 4.1 If f ( x ∗ ) < 0 , then min { 0 , f ( x ∗ ) } + c ( x ∗ , x i ) = f ( x ∗ ) + c ( x ∗ , x i ) . By optimality of ¯ x , f ( ¯ x ) + c ( ¯ x, x i ) ≤ f ( x ∗ ) + c ( x ∗ , x i ) . Since x i is suboptimal in Problem (4) and c strictly positi ve in all other cases, f ( x ∗ ) + c ( x ∗ , x i ) < min { 0 , f ( x i ) } + c ( x i , x i ) = 0 . By optimality of x ∗ , f ( x ∗ ) + c ( x ∗ , x i ) ≤ min { 0 , f ( ¯ x ) } + c ( ¯ x, x i ) ≤ f ( ¯ x ) + c ( ¯ x, x i ) , which implies that f ( ¯ x ) + c ( ¯ x, x i ) = f ( x ∗ ) + c ( x ∗ , x i ) . Consequently , f ( ¯ x ) + c ( ¯ x, x i ) < 0 , and, therefore, f ( ¯ x ) < 0 . Proof of Pr oposition 4.2 Let ¯ β ∈ arg min β L R N ( β , O L ) . Consequently , for any β , L ∗ A, 01 ( O L ) = min β L A, 01 ( β ; O L ) ≤ X i : y i = − 1 l 01 ( g ¯ β ( x i ) , − 1) + X i : y i =+1 l 01 ( g ¯ β ( O ( ¯ β , x i )) , +1) + α || ¯ β || p p . Now , X i : y i =+1 l 01 ( g ¯ β ( O ( ¯ β , x i )) , +1) ≤ X i : y i =+1 l 01 ( g ¯ β ( O L ( ¯ β , x i )) , +1) + δ ( p ) with probability at least 1 − p , where δ ( p ) = B p L + √ log 2 p − 8 B p l log p − log p 2 , by the Chernof f bound, and Lemma 4.1, which assures that an optimal solution to Problem (5) can only o ver -estimate mistakes. Moreover , X i : y i =+1 l 01 ( g ¯ β ( O L ( ¯ β , x i )) , +1) ≤ X i : y i =+1 X j ∈ N i l ( g ¯ β ( O L ( ¯ β , x i )) , +1) , since O L ( ¯ β , x i ) ∈ N i for all i by construction, and l is an upper bound on l 01 . Putting ev erything together , we get the desired result. Con vergence of p L with Increasing Number of Restarts L (a) (b) Figure 5: The conv ergence of p L based on different number of starting points for (a) Binary , (b) Continuous feature space. Attacks as Constrained Optimization A variation on the attack models in the main paper is when the attacker is solving the follo wing constrained optimization problem: min x min { 0 , f ( x ) } (6a) s . t . : c ( x, x i ) ≤ B (6b) 11 for some cost budget constraint B and query budget constraint Q . While this problem is, again, non-con vex, we can instead minimize the conv ex upper bound, f ( x ) , as before, if we assume that f ( x ) is con vex. In this case, if the feature space is continuous, the problem can be solv ed optimally using standard con vex optimization methods [ 23 ]. If the feature space is binary and f ( x ) is linear or con vex-inducing, algorithms proposed by Lo wd and Meek [ 6 ] and Nelson et al. [ 8 ]. Figure 6 , 7 and 8 show the performance of RAD based on the optimized adversarial strategies for v arious learning models, respectiv ely . (a) (b) Figure 6: Performance of baseline ( adv- ) and RAD ( r ob- ) as a function of adversarial budget for Enron dataset with binary features testing on adversarial instances using Nai ve Bayesian. (a) query budget Q = 30 , (b) query budget Q = 40 . (a) (b) Figure 7: Performance of baseline ( adv- ) and RAD ( r ob- ) as a function of adversarial budget for Enron dataset with binary features testing on adversarial instances using SVM with RBF kernel. (a) query budget Q = 30 , (b) query budget Q = 40 . (a) (b) Figure 8: Performance of baseline ( adv- ) and RAD ( r ob- ) as a function of adversarial budget for Enron dataset with binary features testing on adv ersarial instances using 3-layer NN. (a) query b udget Q = 30 , (b) query budget Q = 40 . 12 Experiments with Continuous Featur e Space Figure 9: Example modification of digit images (MNIST data) as λ decreases (left-to-right) for logistic regression, SVM, 1-layer NN, and 3-layer NN (ro ws 1-4 respectively). In Figure 9 we visualize the relativ e vulnerability of the different classifiers, as well as ef fectiv eness of our general-purpose ev asion methods based on coordinate greedy . Each row corresponds to a classifier , and moving right within a row represents decreasing λ (allowing attacks to make more substantial modifications to the image in an ef fort to e vade correct classification). W e can observe that NN classifiers require more substantial changes to the images to ev ade, ultimately making these entirely unlike the original. In contrast, logistic regression is quite vulnerable: the digit remains largely recognizable e ven after ev asion attacks. Experiments with Discrete F eature Space Considering no w data sets with binary features, we use the Enron data with a bag-of-words feature representation, for a total of 2000 features. W e compare Naiv e Bayes (NB), logistic regression, SVM, and a 3-layer neural network. Our comparison inv olves both the baseline, and RAD implementations of these, using the same metrics as abov e. (a) (b) (c) (d) Figure 10: Performance of baseline ( adv- ) and RAD ( r ob- ) implementations of (a) Naiv e Bayes, (b) logistic regression, (c) SVM, and (d) 3-layer NN, using binary features testing on adversarial instances. Figure 10 confirms the effecti veness of RAD : ev ery algorithm is substantially more robust to e vasion with retraining, compared to baseline implementation. Most of the algorithms can obtain extremely 13 high accuracy on this data with the bag-of-words feature representation. Howev er, a 3-layer neural network is now less rob ust than the other algorithms, unlike in the experiments with continuous features. Indeed, Goodfellow et al. [ 16 ] similarly observe the relative fragility of NN to ev asion attacks. Experiments with Multi-class Classification Discussion so far dealt entirely with binary classification. W e no w observe that e xtending it to multi-class problems is quite direct. Specifically , while previously the attacker aimed to make an instance classified as +1 (malicious) into a benign instance ( − 1 ), for a general label set Y , we can define a malicious set M ⊂ Y and a target set T ⊂ Y , with M ∩ T = ∅ , where every entity represented by a feature vector x with a label y ∈ M aims to transform x so that its label is changed to T . In this setting, let g ( x ) = arg max y ∈ Y f ( x, y ) . W e can then use the follo wing empirical risk function: X i : y i / ∈ M l ( g β ( x i ) , y i ) + X i : y i ∈ M l ( g β ( O ( β , x i )) , y i ) + λ || β || p , (7) where O aims to transform instances x i so that g β ( O ( β , x i )) ∈ T . The relax ed version of the adversarial problem can then be generalized to min x,y ∈ T − f ( x, y ) + c ( x, x i ) . For a finite tar get set T , this problem is equiv alent to taking the best solution of a finite collection of problems identical to Problem 5. T o ev aluate the effecti veness of RAD , and resilience of baseline algorithms, in multi-class classification settings, we use the MNIST dataset and aim to correctly identify digits based on their images. Our comparison in volves SVM and 3-layer neural network (results for NN-1 are similar). W e use M = { 1 , 4 } as the malicious class (that is, instances corresponding to digits 1 and 4 are malicious), and T = { 2 , 7 } is the set of benign labels (what malicious instances wish to be classified as). The Figure 11: Performance of baseline ( adv- ) and RAD ( rob- ) implementations of (a) multi-class SVM and (b) multi-class 3-layer NN, using MNIST dataset testing on adversarial instances. results, shown in Figure 11 are largely consistent with our previous observations: both SVM and 3-layer NN perform well when retrained with RAD , with near-perfect accuracy despite adv ersarial ev asion attempts. Moreov er, RAD significantly boosts rob ustness to ev asion, particularly when λ is small (adversary who is not v ery sensitiv e to ev asion costs). Figure 12: V isualization of modification attacks with decreasing the cost sensitivity parameter λ (from left to right), to change 1 to the set {2,7}. The rows correspond to SVM and 3-layer NN, respectiv ely . Figure 12 offers a visual demonstration of the relative ef fectiveness of attacks on the baseline implementation of SVM and 1- and 3-layer neural networks. Here, we can observe that a significant 14 change is required to ev ade the linear SVM, with the digit having to nearly resemble a 2 after modification. In contrast, significantly less noise is added to the neural network in effecting e vasion. Evaluation of Cost Function V ariations and Robustness to Misspecification Considering the variations of cost functions, here we ev aluate the classification efficiency for v arious cost functions as well as different cost functions for defender and adv ersary , respectively . Figure 13 sho ws the empirical ev aluation results based on Enron dataset with binary features. It is shown that if both the defender and adversary apply the L1 (a) or quadratic cost functions (b), it is easy to defend the malicious manipulations. Even the defender mistak enly ev aluate the adversarial cost models as shown in Figure 13 (c), RAD frame work can still defend the attack strategies ef ficiently . (a) (b) (c) Figure 13: Performance of baseline ( adv- ) and RAD ( rob- ) as a function of cost sensiti vity λ for Enron dataset with binary features testing on adv ersarial instances. (a) both defender and adversary use the L1 distance cost function, (b) both defender and adversary use the quadratic distance cost function, (c) adversary uses quadratic cost function while defender estimates it based on exponential cost. (a) (b) Figure 14: Performance of baseline ( adv- ) and RAD ( rob- ) as a function of cost sensiti vity λ for Enron dataset with binary features testing on adv ersarial instances. (a) both defender and adversary use the equi valence-based cost function, (b) adv ersary uses equi valence-based cost function while defender estimates it based on exponential cost. Experiments for Clustering Malicious Instances T o efficiently speed up the proposed algorithm, here we cluster the malicious instances and use the center of each cluster to generate the potential “ev asion" instances for the retraining framework. Figure 15 shows that the running time can be reduced by applying the clustering algorithm to the original malicious instances and the classification performance stays pretty stable for dif ferent learning models. 15 (a) (b) Figure 15: Performance of different learning models based on the number of clusters for Enron dataset testing on adversarial instances. (a) Running time, (b) classification accuracy of RAD . 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment